") 當LLM遇到Database:阿里達摩院聯(lián)合HKU推出Text-to-SQL新基準?
當LLM遇到Database:阿里達摩院聯(lián)合HKU推出Text-to-SQL新基準?
在新基準 BIRD 上,ChatGPT 僅能達到 40.08%,相比人類 92.96% 還有很大差距。
背景
大模型(LLM)為通用人工智能(AGI)的發(fā)展提供了新的方向,其通過海量的公開數(shù)據(jù),如互聯(lián)網(wǎng)、書籍等語料進行大規(guī)模自監(jiān)督訓練,獲得了強大的語言理解、語言生成、推理等能力。然而,大模型對于私域數(shù)據(jù)的利用仍然面臨一些挑戰(zhàn),私域數(shù)據(jù)是指由特定企業(yè)或個人所擁有的數(shù)據(jù),通常包含了領(lǐng)域特定的知識,將大模型與私域知識進行結(jié)合,將會發(fā)揮巨大價值。
私域知識從數(shù)據(jù)形態(tài)上又可以分為非結(jié)構(gòu)化與結(jié)構(gòu)化數(shù)據(jù)。對于非結(jié)構(gòu)化數(shù)據(jù),例如文檔,通常都通過檢索的方式進行增強,可以利用 langchain 等工具可以快速實現(xiàn)問答系統(tǒng)。而結(jié)構(gòu)化數(shù)據(jù),如數(shù)據(jù)庫(DB),則需要大模型與數(shù)據(jù)庫進行交互,查詢和分析來獲取有用的信息。圍繞大模型與數(shù)據(jù)庫,近期也衍生出一系列的產(chǎn)品與應用,譬如利用 LLM 打造智能數(shù)據(jù)庫、執(zhí)行 BI 分析、完成自動表格構(gòu)建等。其中,text-to-SQL 技術(shù),即以自然語言的方式與數(shù)據(jù)庫進行交互,一直以來都是一個備受期待的方向。
在學術(shù)界,過去的 text-to-SQL 基準僅關(guān)注小規(guī)模數(shù)據(jù)庫,最先進的 LLM 已經(jīng)可以達到 85.3% 的執(zhí)行準確率,但這是否意味著 LLM 已經(jīng)可以作為數(shù)據(jù)庫的自然語言接口?
新一代數(shù)據(jù)集
最近,阿里巴巴聯(lián)合香港大學等機構(gòu)推出了面向大規(guī)模真實數(shù)據(jù)庫的全新基準 BIRD (Can LLM Already Serve as A Database Interface? A BIg Bench for Large-Scale Database Grounded Text-to-SQLs), 包含 95 個大規(guī)模數(shù)據(jù)庫及高質(zhì)量的 Text-SQL pair,數(shù)據(jù)存儲量高達 33.4 GB。之前最優(yōu)的模型在 BIRD 上評估僅達到 40.08%,與人類 92.96% 的結(jié)果還有很大差距,這證明挑戰(zhàn)仍然存在。除了評估 SQL 正確性外,作者還增加了 SQL 執(zhí)行效率的評估,期待模型不僅可以寫正確的 SQL,還能夠?qū)懗龈咝У?SQL。

論文:https://arxiv.org/abs/2305.03111
主頁:https://bird-bench.github.io
代碼:https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/bird

目前,BIRD 的數(shù)據(jù)、代碼、榜單都已經(jīng)開源,在全球的下載量已超10000。BIRD在推出之始,就引發(fā)了 Twitter 上的廣泛關(guān)注與討論。


海外用戶的評論也非常精彩:

不容錯過的 LLM 項目

非常有用的檢查點,提升的溫床
AI 可以幫助你,但還不能取代你

我的工作暫時是安全的...

方法概述
 ???
???
新的挑戰(zhàn)
該研究主要面向真實數(shù)據(jù)庫的 Text-to-SQL 評估,過去流行的測試基準,比如 Spider 和 WikiSQL,僅關(guān)注具有少量數(shù)據(jù)庫內(nèi)容的數(shù)據(jù)庫 schema,導致學術(shù)研究與實際應用之間存在鴻溝。BIRD 重點關(guān)注海量且真實的數(shù)據(jù)庫內(nèi)容、自然語言問題與數(shù)據(jù)庫內(nèi)容之間的外部知識推理以及在處理大型數(shù)據(jù)庫時 SQL 的效率等新三個挑戰(zhàn)。
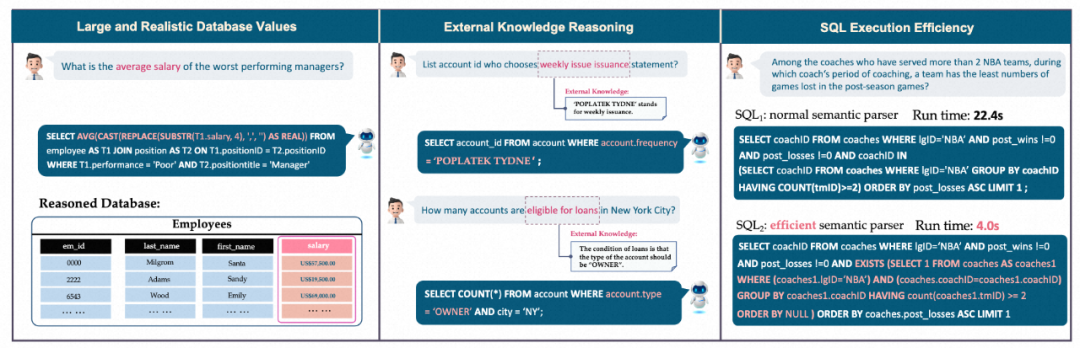
首先,數(shù)據(jù)庫包含海量且嘈雜數(shù)據(jù)的值。在左側(cè)示例中,平均工資的計算需要通過將數(shù)據(jù)庫中的字符串(String)轉(zhuǎn)化為浮點值 (Float) 之后再進行聚合計算(Aggregation);
其次,外部知識推斷是很必要的,在中間示例中,為了能準確地為用戶返回答案,模型必須先知道有貸款資格的賬戶類型一定是 “擁有者”(“OWNER”),這代表巨大的數(shù)據(jù)庫內(nèi)容背后隱藏的奧秘有時需要外部知識和推理來揭示;
最后,需要考慮查詢執(zhí)行效率。在右側(cè)示例中,采用更高效的 SQL 查詢可以顯著提高速度,這對于工業(yè)界來講具有很大價值,因為用戶不僅期待寫出正確的 SQL,還期待 SQL 執(zhí)行的高效,尤其是在大型數(shù)據(jù)庫的情況下;
數(shù)據(jù)標注
BIRD 在標注的過程中解耦了問題生成和 SQL 標注。同時加入專家來撰寫數(shù)據(jù)庫描述文件,以此幫助問題和 SQL 標注人員更好的理解數(shù)據(jù)庫。
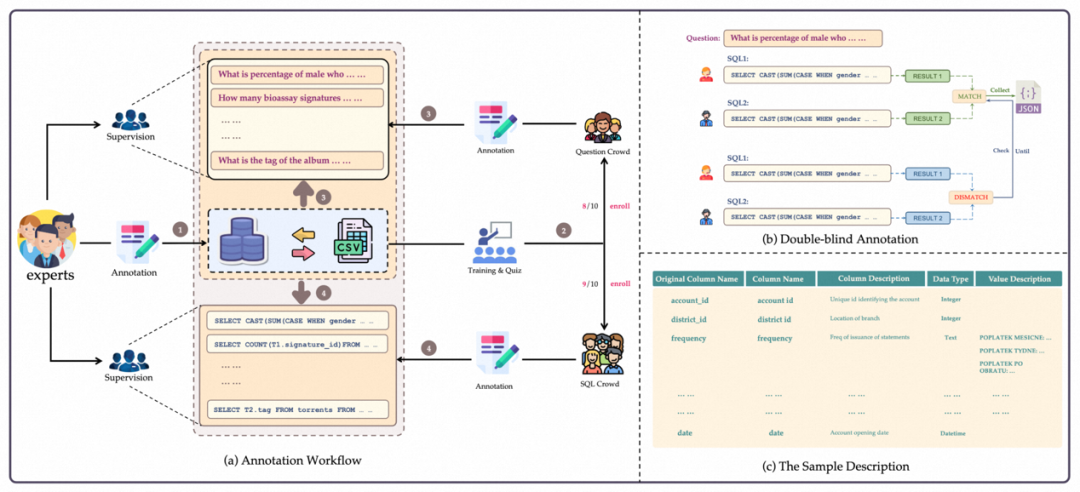
1. 數(shù)據(jù)庫采集:作者從開源數(shù)據(jù)平臺(如 Kaggle 和 CTU Prague Relational Learning Repository)收集并處理了 80 個數(shù)據(jù)庫。通過收集真實表格數(shù)據(jù)、構(gòu)建 ER 圖以及設(shè)置數(shù)據(jù)庫約束等手動創(chuàng)建了 15 個數(shù)據(jù)庫作為黑盒測試,來避免當前數(shù)據(jù)庫被當前的大模型學習過。BIRD 的數(shù)據(jù)庫包含了多個領(lǐng)域的模式和值, 37 個領(lǐng)域,涵蓋區(qū)塊鏈、體育、醫(yī)療、游戲等。
2. 問題收集:首先作者雇傭?qū)<蚁葹閿?shù)據(jù)庫撰寫描述文件,該描述文件包括完整的表明列名、數(shù)據(jù)庫值的描述,以及理解值所用到的外部知識等。然后招募了 11 個來自美國,英國,加拿大,新加坡等國家的 native speaker 為 BIRD 產(chǎn)生問題。每一位 speaker 都至少具備本科及以上的學歷。
3.SQL 生成:面向全球招募了由數(shù)據(jù)工程師和數(shù)據(jù)庫課程學生組成的標注團隊為 BIRD 生成 SQL。在給定數(shù)據(jù)庫和參考數(shù)據(jù)庫描述文件的情況下,標注人員需生成 SQL 以正確回答問題。采用雙盲(Double-Blind)標注方法,要求兩位標注人員對同一個問題進行標注。雙盲標注可以最大程度減少單一標注人員所帶來的錯誤。
4. 質(zhì)量檢測:質(zhì)量檢測分為結(jié)果執(zhí)行的有效性和一致性兩部分。有效性不僅要求執(zhí)行的正確性,還要求執(zhí)行結(jié)果不能是空值(NULL)。專家將逐步修改問題條件,直至 SQL 執(zhí)行結(jié)果有效。
5. 難度劃分:text-to-SQL 的難度指標可以為研究人員提供優(yōu)化算法的參考。Text-to-SQL 的難度不僅取決于 SQL 的復雜程度,還與問題難度、額外知識易理解程度以及數(shù)據(jù)庫復雜程度等因素有關(guān)。因此作者要求 SQL 標注人員在標注過程中對難易程度進行評分,并將難度分為三類:簡單、適中和具有挑戰(zhàn)性。
數(shù)據(jù)統(tǒng)計
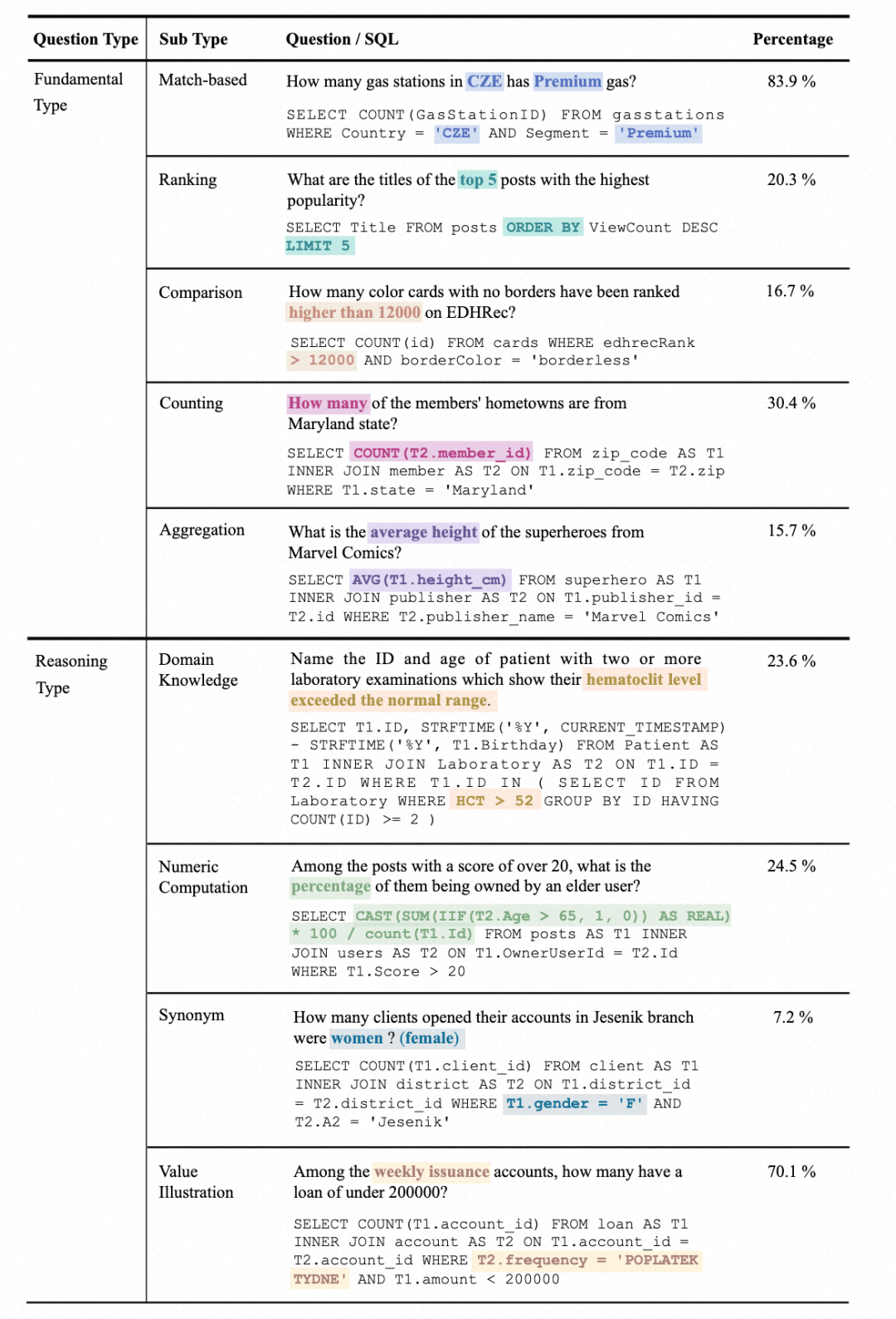
1. 問題類型統(tǒng)計:問題分為兩大類,基礎(chǔ)問題類型(Fundamental Type)和推理問題類型(Reasoning Type)。基礎(chǔ)問題類型包括傳統(tǒng) Text-to-SQL 數(shù)據(jù)集中涵蓋的問題類型,而推理問題類型則包括需要外部知識來理解值的問題:
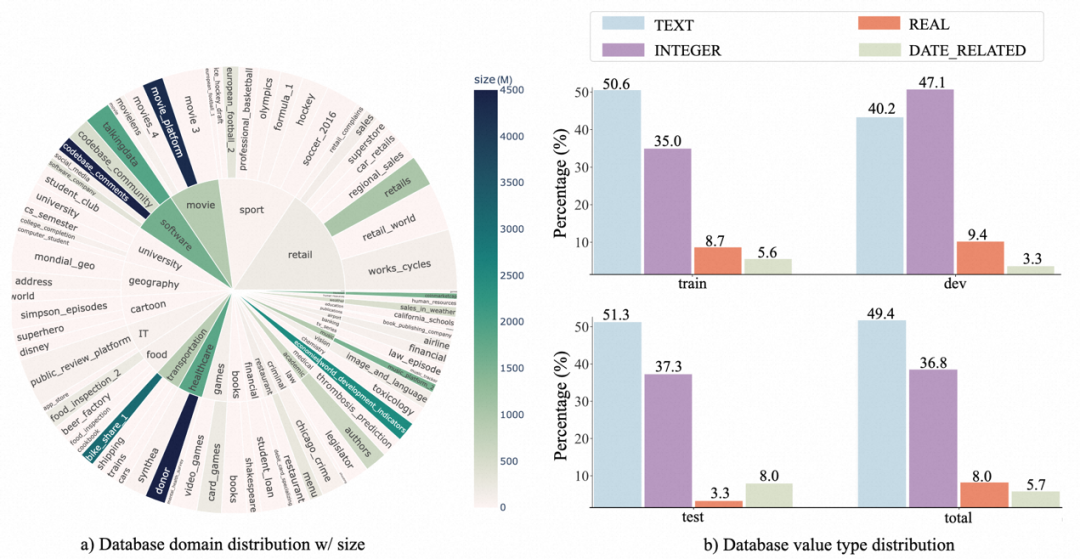
2. 數(shù)據(jù)庫分布:作者用 sunburst 圖顯示了數(shù)據(jù)庫 domain 及其數(shù)據(jù)量大小之間的關(guān)系。越大的半徑意味著,基于該數(shù)據(jù)庫的 text-SQL 較多,反之亦然。越深的顏色則是指該數(shù)據(jù)庫 size 越大,比如 donor 是該 benchmark 中最大的數(shù)據(jù)庫,所占空間: 4.5GB。
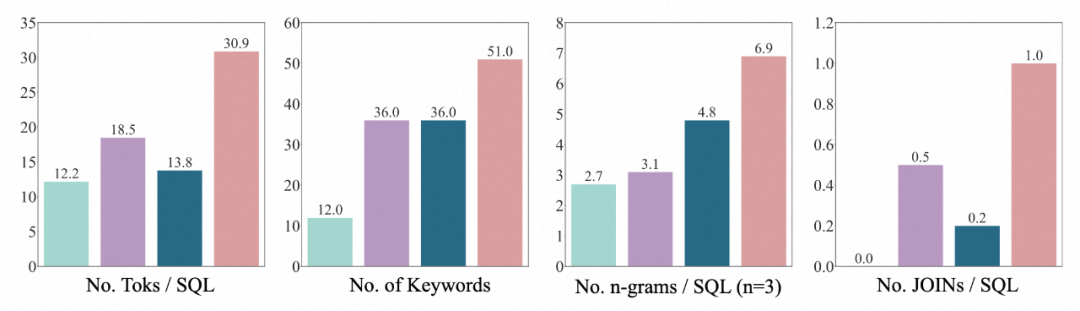
3.SQL 分布:作者通過 SQL 的 token 數(shù)量,關(guān)鍵詞數(shù)量,n-gram 類型數(shù)量,JOIN 的數(shù)量等 4 個維度來證明 BIRD 的 SQL 是迄今為止最多樣最復雜的。
評價指標
1. 執(zhí)行準確率:對比模型預測的 SQL 執(zhí)行結(jié)果與真實標注 SQL 執(zhí)行結(jié)果的差異;
2. 有效效率分數(shù):同時考慮 SQL 的準確性與高效性,對比模型預測的 SQL 執(zhí)行速度與真實標注 SQL 執(zhí)行速度的相對差異,將運行時間視為效率的主要指標。
實驗分析
作者選擇了在之前基準測試中,表現(xiàn)突出的訓練式 T5 模型和大型語言模型(LLM)作為基線模型:Codex(code-davinci-002)和 ChatGPT(gpt-3.5-turbo)。為了更好地理解多步推理是否能激發(fā)大型語言模型在真實數(shù)據(jù)庫環(huán)境下的推理能力,還提供了它們的思考鏈版本(Chain-of-Thought)。并在兩種設(shè)置下測試基線模型:一種是完全的 schema 信息輸入,另一種是人類對涉及問題的數(shù)據(jù)庫值的理解,總結(jié)成自然語言描述(knowledge evidence)輔助模型理解數(shù)據(jù)庫。
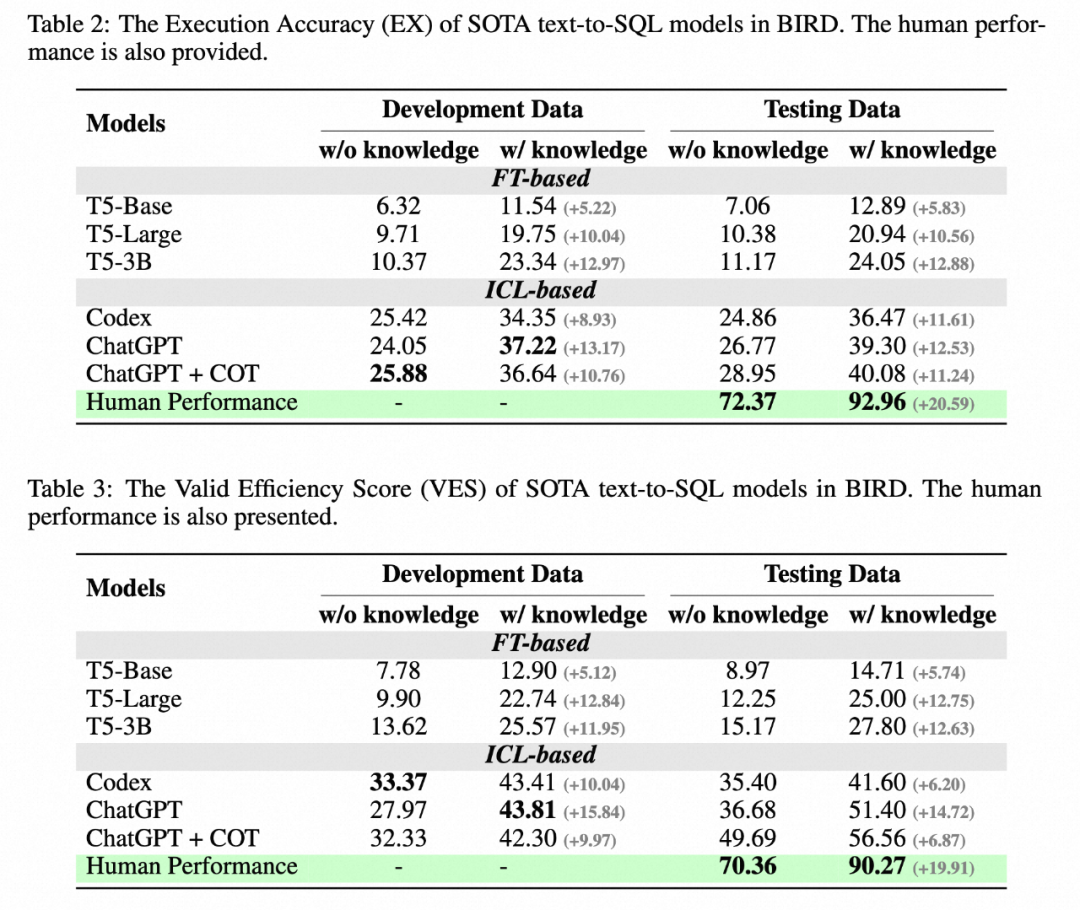
作者給出了一些結(jié)論:
1. 額外知識的增益:增加對數(shù)據(jù)庫值理解的知識(knowledge evidence)有明顯的效果提升,這證明在真實的數(shù)據(jù)庫場景中,僅依賴語義解析能力是不夠的,對數(shù)據(jù)庫值的理解會幫助用戶更準確地找到答案。
2. 思維鏈不一定完全有益:在模型沒有給定數(shù)據(jù)庫值描述和零樣本(zero-shot)情況下,模型自身的 COT 推理可以更準確地生成答案。然而,當給定額外的知識(knowledge evidence)后,讓 LLM 進行 COT,發(fā)現(xiàn)效果并不顯著,甚至會下降。因此在這個場景中, LLM 可能會產(chǎn)生知識沖突。如何解決這種沖突,使模型既能接受外部知識,又能從自身強大的多步推理中受益,將是未來重點的研究方向。
3. 與人類的差距:BIRD 還提供了人類指標,作者以考試的形式測試標注人員在第一次面對測試集的表現(xiàn),并將其作為人類指標的依據(jù)。實驗發(fā)現(xiàn),目前最好的 LLM 距離人類仍有較大的差距,證明挑戰(zhàn)仍然存在。作者執(zhí)行了詳細的錯誤分析,給未來的研究提供了一些潛在的方向。

結(jié)論
LLM 在數(shù)據(jù)庫領(lǐng)域的應用將為用戶提供更智能、更便捷的數(shù)據(jù)庫交互體驗。BIRD 的出現(xiàn)將推動自然語言與真實數(shù)據(jù)庫交互的智能化發(fā)展,為面向真實數(shù)據(jù)庫場景的 text-to-SQL 技術(shù)提供了進步空間,有助于研究人員開發(fā)更先進、更實用的數(shù)據(jù)庫應用。
-
數(shù)據(jù)庫
+關(guān)注
關(guān)注
7文章
3767瀏覽量
64280 -
自然語言
+關(guān)注
關(guān)注
1文章
287瀏覽量
13335 -
阿里達摩院
+關(guān)注
關(guān)注
0文章
29瀏覽量
3322 -
LLM
+關(guān)注
關(guān)注
0文章
276瀏覽量
306
原文標題:當LLM遇到Database:阿里達摩院聯(lián)合HKU推出Text-to-SQL新基準?
文章出處:【微信號:AI智勝未來,微信公眾號:AI智勝未來】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
亞馬遜推新,阿里達摩院退出,融資規(guī)模大幅下滑后量子計算還是好生意嗎?
阿里達摩院發(fā)布玄鐵R908 CPU
什么是LLM?LLM的工作原理和結(jié)構(gòu)
阿里達摩院提出“知識鏈”框架,降低大模型幻覺
Snowflake推出面向企業(yè)AI的大語言模型
Snowflake推出企業(yè)級AI模型
潤開鴻榮膺達摩院“玄鐵優(yōu)選伙伴”獎
玄鐵RISC-V生態(tài)大會深圳召開,達摩院引領(lǐng)RISC-V創(chuàng)新應用

達摩院院長張建鋒:RISC-V迎來蝶變,進入應用爆發(fā)期
達摩院牽頭成立“無劍聯(lián)盟”,探索RISC-V產(chǎn)業(yè)合作新范式

阿里達摩院北京公司新增AI業(yè)務(wù)
阿里達摩院在上海成立新公司,聚焦人工智能與軟件開發(fā)
了解鴻蒙OS Text組件






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論