 谷歌DeepMind發現更快排序算法,已集成到C++庫
谷歌DeepMind發現更快排序算法,已集成到C++庫
接觸過基礎計算機科學課程的朋友們,肯定都曾親自動手設計排序算法——也就是借助代碼將無序列表中的各個條目按升序或降序方式重新排列。這是個有趣的挑戰,可行的操作方法也多種多樣。人們曾投入大量時間探索如何更高效地完成排序任務。
作為一項基礎操作,大多數編程語言的標準庫中都內置有排序算法。世界各地的代碼庫中使用了許多不同的排序技術和算法來在線組織大量數據,但至少就與 LLVM 編譯器配套使用的 C++ 庫而言,排序代碼已經有十多年沒有任何變化了。
近日,谷歌 DeepMind AI 小組如今開發出一種強化學習工具 AlphaDev,能夠在無需通過人類代碼示例做預訓練的情況下,開發出極限優化的算法。如今,這些算法已經集成到 LLVM 標準 C++ 排序庫中,這是十多年來排序庫部分第一次發生變化,也是第一次將通過強化學習設計的算法添加到該庫中。
把編程過程視為“游戲”
由于不必預先接觸任何人類游戲策略,DeepMind 系統往往能發現人類從未設想過的攻關思路。當然,由于完全依靠自我對抗來學習經驗,DeepMind 在某些情況下也會形成可被人類利用的盲點。
這種方法跟編程其實非常相似。大語言模型之所以能夠編寫出有效代碼,就是因為它們看到過大量人類代碼示例。但也正因為如此,語言模型很難產出人類之前沒做過的東西。如果我們希望對普遍存在的現有算法(例如排序函數)做進一步優化,那么繼續依賴現有人類代碼將很難突破固有思路的束縛。那么,如何才能讓 AI 找到真正的新方向?
DeepMind 的研究人員采用了與國際象棋和圍棋相同的方法:把代碼優化任務轉化成單人“組裝游戲”。AlphaDev 系統開發出一種 x86 匯編算法,會將代碼的運行延遲視為一個分數,在努力將該分數最小化的同時確保代碼能夠順暢跑通。通過強化學習,AlphaDev 逐漸具備了編寫緊湊、高效代碼的能力。
AlphaDev 基于 AlphaZero。DeepMind 向來以開發能自學游戲規則的 AI 軟件而聞名。這種思路被證明效果拔群,也先后攻克了國際象棋、圍棋和《星際爭霸》等諸多游戲難題。雖然具體細節因所玩游戲而異,但 DeepMind 軟件確實能在重復游玩中不斷學習,持續探索能令得分最大化的辦法。
AlphaDev 的兩個核心組件是學習算法和表示函數。
AlphaDev 學習算法可以結合 DRL 和隨機搜索優化算法來玩組裝游戲。AlphaDev 中的主要學習算法是 AlphaZero 33 的擴展,AlphaZero 33 是一種著名的 DRL 算法,其中訓練神經網絡以指導搜索完成游戲。
表示函數,負責跟蹤代碼開發時的整體性能,其中包括算法的常規結構以及對 x86 寄存器和內存的使用。該系統會單獨添加匯編指令,通過蒙特卡洛樹搜索(同樣是一種從游戲系統中借用的方法)進行選擇。樹狀結構允許系統快速將搜索范圍縮小至包含大量潛在指令的有限區域,而蒙特卡洛方法則以一定程度的隨機性從這個分支區域內選擇具體指令。(請注意,這里所說的“指令”是為創建有效、完整程序集而選擇特定寄存器等操作。)
之后,系統會評估匯編代碼的延遲和有效性狀態,為其打分并與前一次得分進行比較。而通過強化學習,系統會在給定的程序狀態之下保留樹結構中不同分支的工作信息。隨著時間推移,系統將逐漸“學會”如何以最高得分(代表最低延遲)獲得游戲勝利(成功完成排序)。AlphaDev 的主要表示函數基于 Transformer。
為了訓練 AlphaDev 發現新算法,AlphaDev 在每輪中都會觀察它生成的算法和中央處理器 (CPU) 中包含的信息,然后通過選擇要添加到算法中的指令完成游戲。AlphaDev 必須有效地搜索大量可能的指令組合,以找到可以排序的算法,并且還要比當前最好的算法更快,同時代理模型可以根據算法的正確性和延遲獲得獎勵。
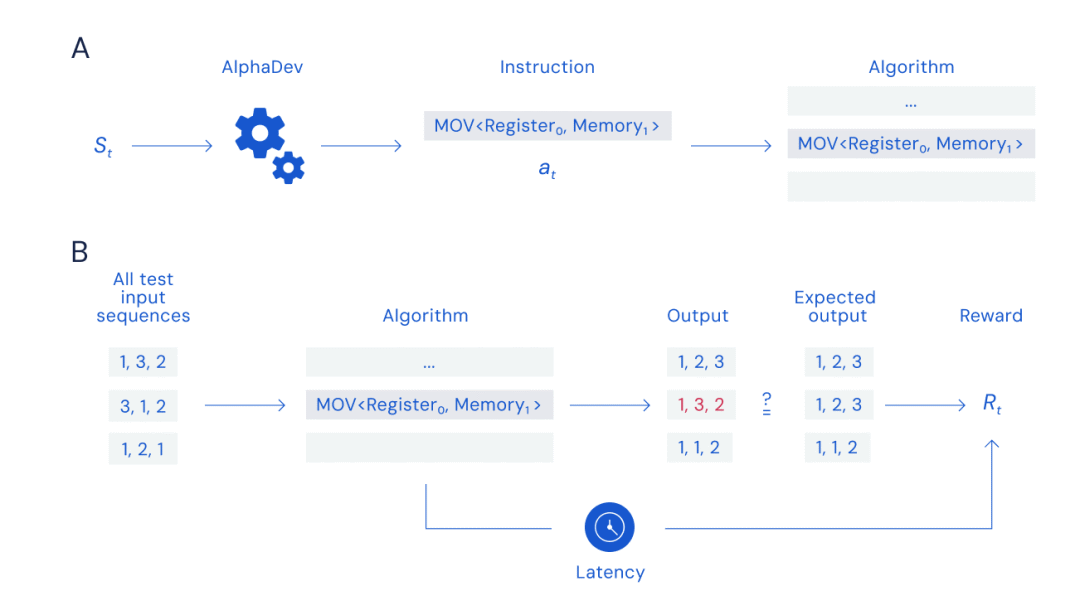
圖 A:組裝游戲,圖 B:獎勵計算
最終,AlphaDev 發現了新的排序算法,這些算法可以讓 LLVM libc++ 排序庫得到改進:對于較短的序列,排序庫的速度提高了 70%;對于超過 250,000 個元素的序列,速度提高了約 1.7%。
具體而言,該算法的創新主要在于兩種指令序列:AlphaDev Swap Move(交換移動)和 AlphaDev Copy Move(復制移動),通過這兩個指令,AlphaDev 跳過了一個步驟,以一種看似錯誤但實際上是捷徑的方式連接項目。
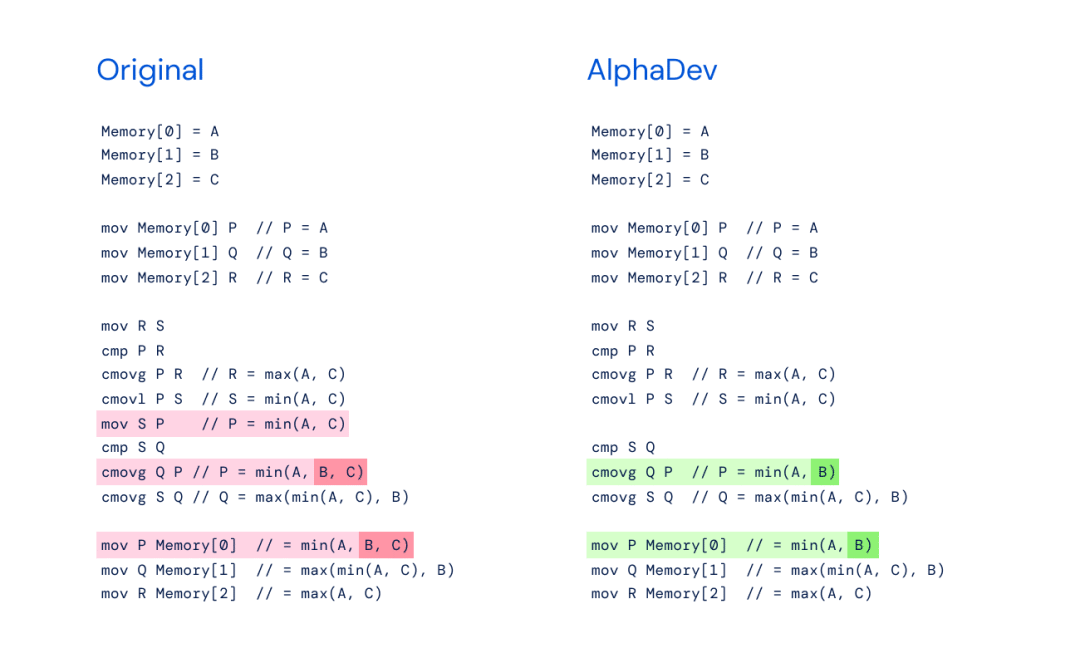
左圖:帶有 min(A,B,C) 的原始 sort3 實現。?
右圖:AlphaDev Swap Move - AlphaDev 發現你只需要 min(A,B)。
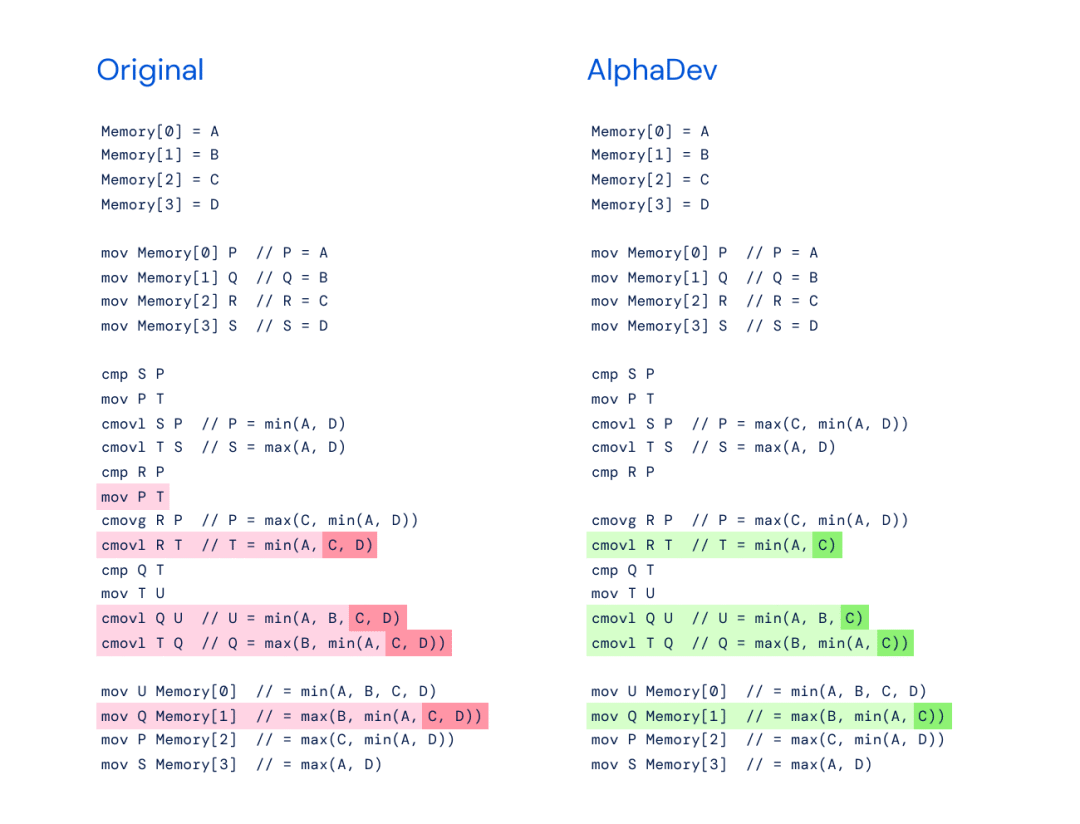
左:max (B, min (A, C)) 的原始實現用于對八個元素進行排序的更大排序算法。
?右:AlphaDev 發現在使用其復制移動時只需要 max (B, min (A, C))。
這套系統的主要優勢在于,其訓練過程不借助任何代碼示例。相反,系統會自主生成代碼示例,然后對其做出評估。過程當中,它也就逐漸掌握了關于有效排序的指令組合信息。
從排序到散列
在發現更快的排序算法后,DeepMind 測試了 AlphaDev 是否可以概括和改進不同的計算機科學算法:散列。
哈希是計算中用于檢索、存儲和壓縮數據的基本算法。就像使用分類系統來定位某本書的圖書管理員一樣,散列算法可以幫助用戶知道他們正在尋找什么以及在哪里可以找到它。這些算法獲取特定密鑰的數據(例如用戶名“Jane Doe”)并對其進行哈希處理——這是一個將原始數據轉換為唯一字符串(例如 1234ghfty)的過程。計算機使用此散列來快速檢索與密鑰相關的數據,而不是搜索所有數據。
DeepMind 將 AlphaDev 應用于數據結構中最常用的散列算法之一,以嘗試發現更快的算法。當將其應用于散列函數的 9-16 字節范圍時,AlphaDev 發現的算法速度提高了 30%。
今年,AlphaDev 的新哈希算法被發布到開源 Abseil 庫中,可供全球數百萬開發人員使用,該庫現在每天被數萬億次使用。
實際可用的代碼
復雜程序中的排序機制能夠處理大量任意條目的集合。但在標準庫層面來看,這種能力源自一系列高度限定的具體函數。這些函數各自只能處理一種或幾種情況。例如,某些單獨算法只能對 3、4 或 5 個條目做排序。我們也可以同時使用一組函數對任意數量的條目作排序,但原則上每一次函數調用最多只能對 4 個條目做排序。
DeepMind 在每個函數上都設置了 AlphaDev,其實際運行方式有著很大區別。對于負責處理特定數量條目的函數,可以編寫出不含任何分支的代碼,即根據變量狀態執行不同的代碼。因此代碼性能往往與所涉及的指令數量成反比。
AlphaDev 已經成功將 sort-3、sort-5 和 sort-8 的指令數量各減一,在 sort-6 和 sort-7 中的指令削減量甚至更多。只有 sort-4 上沒能找到改進現有代碼的方法。而在實際系統上的重復運行測試證明,更少的指令確實帶來了更好的性能。
至于對可變數量條目進行排序,則要求代碼中包含分支,而不同處理器專用于處理這些分支的元件數量也有區別。
對于這類情況,研究人員在 100 臺不同的計算設備上對代碼性能做出了評估。AlphaDev 在這類場景下同樣找到了進一步榨取性能的方法,下面我們以一次最多排序 4 個條目的函數為例,看看它到底是怎么操作的。
在 C++ 庫的現有實現中,代碼需要進行一系列測試來確認具體需要對多少個條目做排序,再根據條目數量調用相應的排序函數。
而 AlphaDev 修改后的代碼則采取更加“神奇”的思路:它先測試是不是 2 個條目,如果是則調用相應函數立即做排序。如果數量大于 2 個,則代碼會先對前 3 個條目做排序。這樣如果確實只有 3 個條目,則返回排序結果。由于實際是有 4 個條目要做排序,所以 AlphaDev 會運行專門代碼,以非常高效的方式將第 4 個條目插入到前 3 個已經排序完成的條目中的適當位置。
這種辦法聽起來有點怪異,但事實證明其性能確實始終優于現有代碼。
由于 AlphaDev 確實生成了更高效的代碼,所以研究團隊打算把這些成果重新合并到 LLVM 標準 C++ 庫中。但問題是這些代碼為匯編格式,而非 C++。所以他們必須通過逆向計算找到能夠生成相同程序集的 C++ 代碼。
現如今,代碼成果已經被合并至 LLVM 工具鏈內,成為十多年來這部分代碼的首次更新。研究人員估計,AlphaDev 生成的新代碼正每天被執行數萬億次。
結束語
“太棒了!將我們程序員很早就學會的這種基本排序任務的速度提高了 70%。看到 AI 在我們都依賴的算法和庫中提供重大加速,真是令人興奮。”有開發者對谷歌 DeepMind 的成果表示振奮。
但也有開發者并不買賬:“相當令人失望……1.7% 的改善?5 個元素的序列 70%?可能是最不受歡迎、最不切實際的應用研究……”也有開發者表示:“說發現了新算法是不是有點誤導人?似乎更像是算法優化。無論如何這仍然很酷。”
-
算法
+關注
關注
23文章
4599瀏覽量
92641 -
編程語言
+關注
關注
10文章
1938瀏覽量
34594 -
C++
+關注
關注
22文章
2104瀏覽量
73489 -
強化學習
+關注
關注
4文章
266瀏覽量
11213
原文標題:AI幫助人類打破十年算法瓶頸:谷歌 DeepMind 發現更快排序算法,已集成到C++庫
文章出處:【微信號:AI前線,微信公眾號:AI前線】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
時間復雜度為 O(n^2) 的排序算法

基于OpenHarmony標準系統的C++公共基礎類庫案例:SafeQueue

基于OpenHarmony標準系統的C++公共基礎類庫案例:SafeStack
基于OpenHarmony標準系統的C++公共基礎類庫案例:SafeBlockQueue
OpenHarmony標準系統C++公共基礎類庫案例:HelloWorld

谷歌DeepMind發布人工智能模型AlphaFold最新版本
鴻蒙OS開發實例:【Native C++】
FPGA實現雙調排序算法的探索與實踐

C語言實現經典排序算法概覽

谷歌捐款100萬美元給Rust基金會,以增強C++與Rust的交互性
谷歌DeepMind資深AI研究員創辦AI Agent創企
C++簡史:C++是如何開始的






 工商網監
工商網監
評論