") NUS&深大提出VisorGPT:為可控文本圖像生成定制空間條件
NUS&深大提出VisorGPT:為可控文本圖像生成定制空間條件

代碼:https://github.com/Sierkinhane/VisorGPT
論文:https://arxiv.org/abs/2305.13777
論文簡(jiǎn)介
可控?cái)U(kuò)散模型如ControlNet、T2I-Adapter和GLIGEN等可通過(guò)額外添加的空間條件如人體姿態(tài)、目標(biāo)框來(lái)控制生成圖像中內(nèi)容的具體布局。使用從已有的圖像中提取的人體姿態(tài)、目標(biāo)框或者數(shù)據(jù)集中的標(biāo)注作為空間限制條件,上述方法已經(jīng)獲得了非常好的可控圖像生成效果。那么如何更友好、方便地獲得空間限制條件?或者說(shuō)如何自定義空間條件用于可控圖像生成呢?例如自定義空間條件中物體的類(lèi)別、大小、數(shù)量、以及表示形式(目標(biāo)框、關(guān)鍵點(diǎn)、和實(shí)例掩碼)。
本文將空間條件中物體的形狀、位置以及它們之間的關(guān)系等性質(zhì)總結(jié)為視覺(jué)先驗(yàn)(Visual Prior),并使用Transformer Decoder以Generative Pre-Training的方式來(lái)建模上述視覺(jué)先驗(yàn)。因此,我們可以從學(xué)習(xí)好的先驗(yàn)中通過(guò)Prompt從多個(gè)層面,例如表示形式(目標(biāo)框、關(guān)鍵點(diǎn)、實(shí)例掩碼)、物體類(lèi)別、大小和數(shù)量,來(lái)采樣空間限制條件。我們?cè)O(shè)想,隨著可控?cái)U(kuò)散模型生成能力的提升,以此可以針對(duì)性地生成圖像用于特定場(chǎng)景下的數(shù)據(jù)補(bǔ)充,例如擁擠場(chǎng)景下的人體姿態(tài)估計(jì)和目標(biāo)檢測(cè)。
方法介紹
表1 訓(xùn)練數(shù)據(jù)
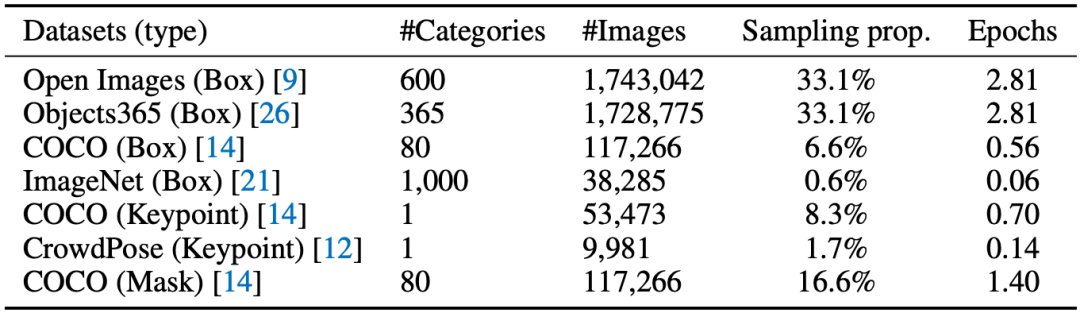
本文從當(dāng)前公開(kāi)的數(shù)據(jù)集中整理收集了七種數(shù)據(jù),如表1所示。為了以Generative Pre-Training的方式學(xué)習(xí)視覺(jué)先驗(yàn)并且添加序列輸出的可定制功能,本文提出以下兩種Prompt模板:

使用上述模板可以將表1中訓(xùn)練數(shù)據(jù)中每一張圖片的標(biāo)注格式化成一個(gè)序列x。在訓(xùn)練過(guò)程中,我們使用BPE算法將每個(gè)序列x編碼成tokens={u1,u2,…,u3},并通過(guò)極大化似然來(lái)學(xué)習(xí)視覺(jué)先驗(yàn),如下式:
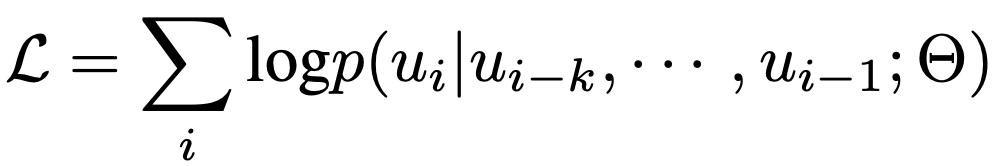
最后,我們可以從上述方式學(xué)習(xí)獲得的模型中定制序列輸出,如下圖所示。
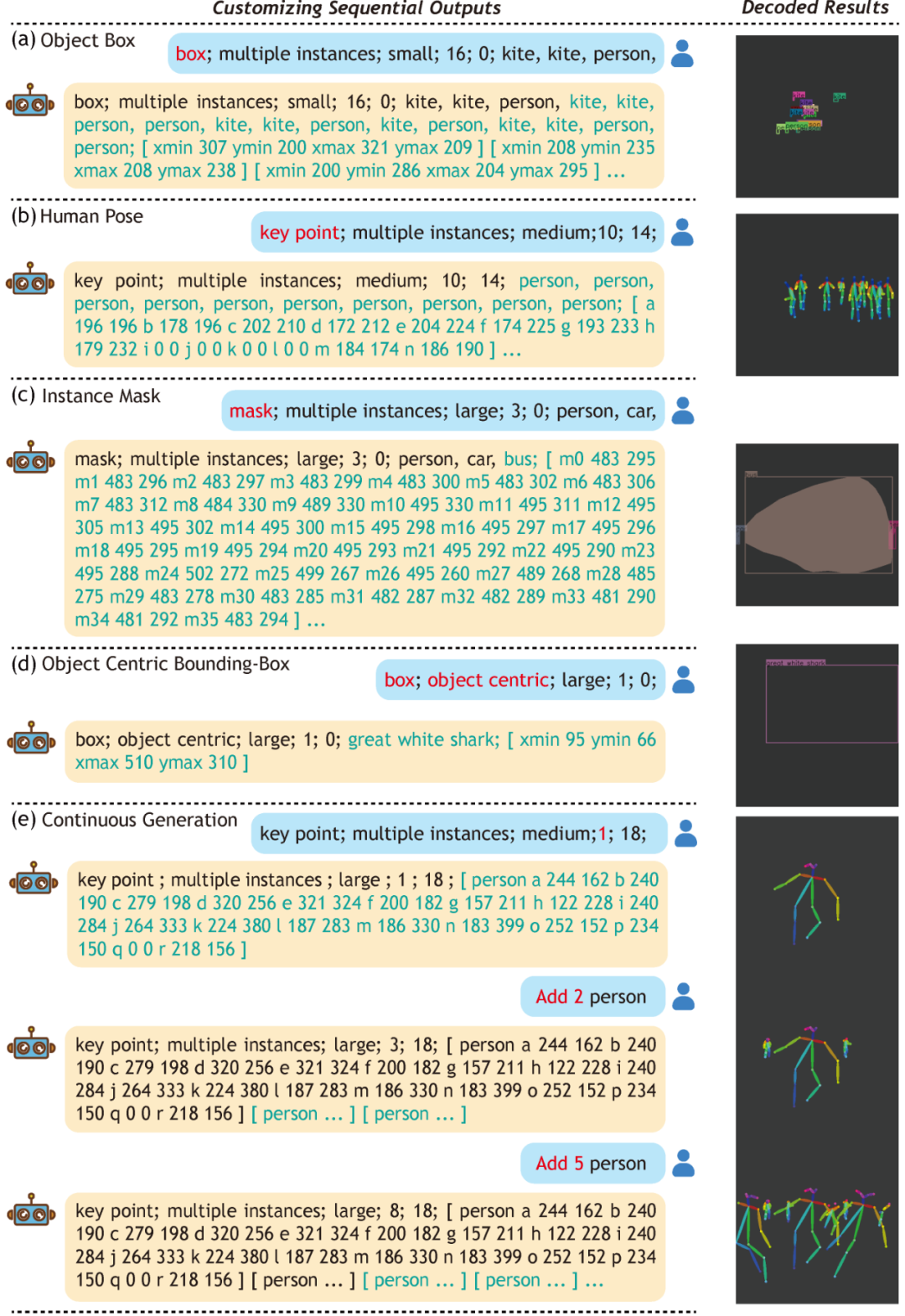
圖1 定制序列輸出
效果展示



-
模型
+關(guān)注
關(guān)注
1文章
3172瀏覽量
48714 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1205瀏覽量
24644 -
圖像生成
+關(guān)注
關(guān)注
0文章
22瀏覽量
6883
原文標(biāo)題:NUS&深大提出VisorGPT:為可控文本圖像生成定制空間條件
文章出處:【微信號(hào):CVer,微信公眾號(hào):CVer】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
基于擴(kuò)散模型的圖像生成過(guò)程

一種有效的文本圖像二值化方法
基于相容粗集的二值文本圖像數(shù)字水印方法
基于多小波變換的文本圖像文種識(shí)別
基于嶺回歸的稀疏編碼文本圖像復(fù)原方法
基于Hash函數(shù)的文本圖像脆弱水印算法
如何去解決文本到圖像生成的跨模態(tài)對(duì)比損失問(wèn)題?
Labview&SQLSever如何自動(dòng)生成查詢(xún)語(yǔ)句
復(fù)旦&amp;微軟提出?OmniVL:首個(gè)統(tǒng)一圖像、視頻、文本的基礎(chǔ)預(yù)訓(xùn)練模型
如何區(qū)分Java中的&amp;和&amp;&amp;
微軟提出Control-GPT:用GPT-4實(shí)現(xiàn)可控文本到圖像生成!

基于文本到圖像模型的可控文本到視頻生成

HarmonyOS &amp;amp;amp;潤(rùn)和HiSpark 實(shí)戰(zhàn)開(kāi)發(fā),“碼”上評(píng)選活動(dòng),邀您來(lái)賽!!!

NUS&;amp;深大提出VisorGPT:為可控文本圖像生成定制空間條件
能力再次提升! 迅為RK3588/RK3568開(kāi)發(fā)板&amp;amp;核心板新增定制分區(qū)鏡像






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論