") ICLR 2023 Spotlight|節(jié)省95%訓練開銷,清華黃隆波團隊提出強化學習專用稀疏訓練框架RLx2
ICLR 2023 Spotlight|節(jié)省95%訓練開銷,清華黃隆波團隊提出強化學習專用稀疏訓練框架RLx2
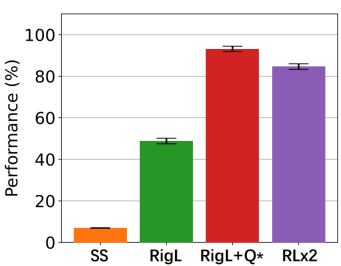
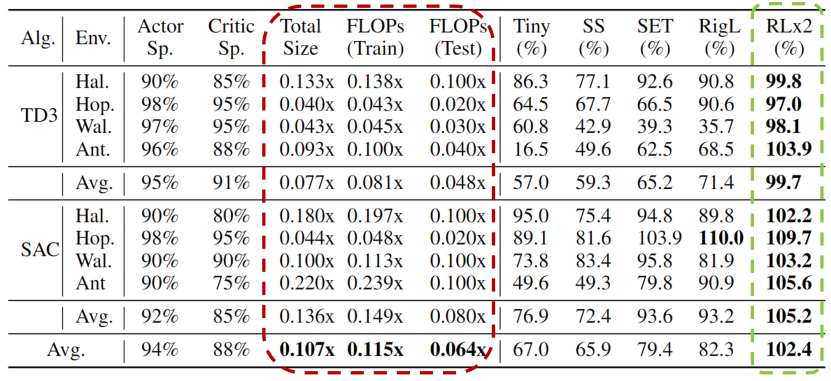
深度強化學習模型的訓練通常需要很高的計算成本,因此對深度強化學習模型進行稀疏化處理具有加快訓練速度和拓展模型部署的巨大潛力。然而現有的生成小型模型的方法主要基于知識蒸餾,即通過迭代訓練稠密網絡,訓練過程仍需要大量的計算資源。另外,由于強化學習自舉訓練的復雜性,訓練過程中全程進行稀疏訓練在深度強化學習領域尚未得到充分的研究。 清華大學黃隆波團隊提出了一種強化學習專用的動態(tài)稀疏訓練框架,“Rigged Reinforcement Learning Lottery”(RLx2),可適用于多種離策略強化學習算法。它采用基于梯度的拓撲演化原則,能夠完全基于稀疏網絡訓練稀疏深度強化學習模型。RLx2 引入了一種延遲多步差分目標機制,配合動態(tài)容量的回放緩沖區(qū),實現了在稀疏模型中的穩(wěn)健值學習和高效拓撲探索。在多個 MuJoCo 基準任務中,RLx2 達到了最先進的稀疏訓練性能,顯示出 7.5 倍至 20 倍的模型壓縮,而僅有不到 3% 的性能降低,并且在訓練和推理中分別減少了高達 20 倍和 50 倍的浮點運算數。大模型時代,模型壓縮和加速顯得尤為重要。傳統(tǒng)監(jiān)督學習可通過稀疏神經網絡實現模型壓縮和加速,那么同樣需要大量計算開銷的強化學習任務可以基于稀疏網絡進行訓練嗎?本文提出了一種強化學習專用稀疏訓練框架,可以節(jié)省至多 95% 的訓練開銷。

- 論文主頁:https://arxiv.org/abs/2205.15043
- 論文代碼:https://github.com/tyq1024/RLx2
圖:基于強化學習的 AlphaGo-Zero 在圍棋游戲中擊敗了已有的圍棋 AI 和人類專家 高昂的資源消耗限制了深度強化學習在資源受限設備上的訓練和部署。為了解決這一問題,作者引入了稀疏神經網絡。稀疏神經網絡最初在深度監(jiān)督學習中提出,展示出了對深度強化學習模型壓縮和訓練加速的巨大潛力。在深度監(jiān)督學習中,SET [Mocanu et al. 2018] 和 RigL [Evci et al. 2020] 等常用的基于網絡結構演化的動態(tài)稀疏訓練(Dynamic sparse training - DST)框架可以從頭開始訓練一個 90% 稀疏的神經網絡,而不會出現性能下降。
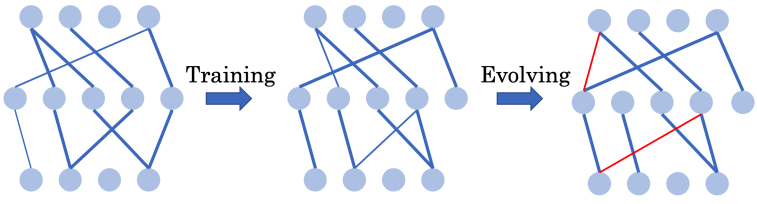
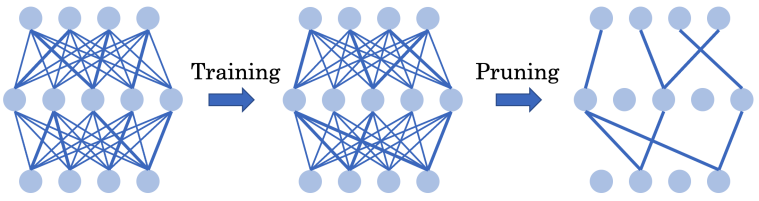
能否通過全程使用超稀疏網絡從頭訓練出高效的深度強化學習智能體?
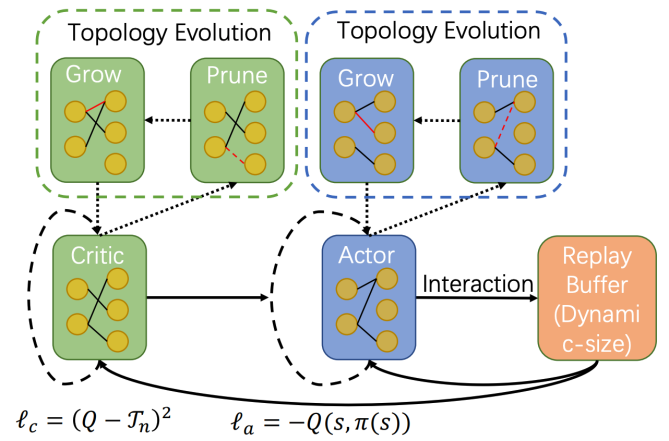
方法 清華大學黃隆波團隊對這一問題給出了肯定的答案,并提出了一種強化學習專用的動態(tài)稀疏訓練框架,“Rigged Reinforcement Learning Lottery”(RLx2),用于離策略強化學習(Off-policy RL)。這是第一個在深度強化學習領域以 90% 以上稀疏度進行全程稀疏訓練,并且僅有微小性能損失的算法框架。RLx2 受到了在監(jiān)督學習中基于梯度的拓撲演化的動態(tài)稀疏訓練方法 RigL [Evci et al. 2020] 的啟發(fā)。然而,直接應用 RigL 無法實現高稀疏度,因為稀疏的深度強化學習模型由于假設空間有限而導致價值估計不可靠,進而干擾了網絡結構的拓撲演化。 因此,RLx2 引入了延遲多步差分目標(Delayed multi-step TD target)機制和動態(tài)容量回放緩沖區(qū)(Dynamic capacity buffer),以實現穩(wěn)健的價值學習(Value learning)。這兩個新組件解決了稀疏拓撲下的價值估計問題,并與基于 RigL 的拓撲演化準則一起實現了出色的稀疏訓練性能。為了闡明設計 RLx2 的動機,作者以一個簡單的 MuJoCo 控制任務 InvertedPendulum-v2 為例,對四種使用不同價值學習和網絡拓撲更新方案的稀疏訓練方法進行了比較。
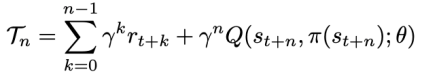

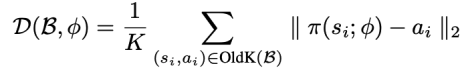
原文標題:ICLR 2023 Spotlight|節(jié)省95%訓練開銷,清華黃隆波團隊提出強化學習專用稀疏訓練框架RLx2
文章出處:【微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發(fā)燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規(guī)問題,請聯系本站處理。
舉報投訴
-
物聯網
+關注
關注
2904文章
44306瀏覽量
371473
原文標題:ICLR 2023 Spotlight|節(jié)省95%訓練開銷,清華黃隆波團隊提出強化學習專用稀疏訓練框架RLx2
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
清華光芯片取得新突破,邁向AI光訓練
電子發(fā)燒友網報道(文/吳子鵬)近日,清華大學發(fā)布官方消息稱,清華大學電子工程系方璐教授課題組、自動化系戴瓊海院士課題組另辟蹊徑,首創(chuàng)了全前向智能光計算訓練架構,研制了“太極-II”光訓練
PyTorch GPU 加速訓練模型方法
在深度學習領域,GPU加速訓練模型已經成為提高訓練效率和縮短訓練時間的重要手段。PyTorch作為一個流行的深度學習
如何使用 PyTorch 進行強化學習
強化學習(Reinforcement Learning, RL)是一種機器學習方法,它通過與環(huán)境的交互來學習如何做出決策,以最大化累積獎勵。PyTorch 是一個流行的開源機器學習庫,
什么是協議分析儀和訓練器
協議分析儀和訓練器是兩種不同但相關的設備或工具,它們在網絡通信、電子設計和測試等領域發(fā)揮著重要作用。以下是對這兩種設備的詳細解釋:一、協議分析儀
定義:協議分析儀(Protocol Analyzer
發(fā)表于 10-29 14:33
冠軍說|第二屆OpenHarmony競賽訓練營冠軍團隊專訪
在剛剛結束的第三屆OpenHarmony技術大會上
今年的OpenHarmony競賽訓練營獲獎團隊
舉行了星光熠熠的頒獎儀式
10月11日,經過激烈的現場決賽角逐共有10個賽隊脫穎而出
其中來自
發(fā)表于 10-28 17:11

預訓練和遷移學習的區(qū)別和聯系
預訓練和遷移學習是深度學習和機器學習領域中的兩個重要概念,它們在提高模型性能、減少訓練時間和降低對數據量的需求方面發(fā)揮著關鍵作用。本文將從定
如何理解機器學習中的訓練集、驗證集和測試集
理解機器學習中的訓練集、驗證集和測試集,是掌握機器學習核心概念和流程的重要一步。這三者不僅構成了模型學習與評估的基礎框架,還直接關系到模型性
PyTorch如何訓練自己的數據集
PyTorch是一個廣泛使用的深度學習框架,它以其靈活性、易用性和強大的動態(tài)圖特性而聞名。在訓練深度學習模型時,數據集是不可或缺的組成部分。然而,很多時候,我們可能需要使用自己的數據集
深度學習模型訓練過程詳解
深度學習模型訓練是一個復雜且關鍵的過程,它涉及大量的數據、計算資源和精心設計的算法。訓練一個深度學習模型,本質上是通過優(yōu)化算法調整模型參數,使模型能夠更好地擬合數據,提高預測或分類的準
基于毫米波的人體跟蹤和識別算法
。雷達已被提議作為粗粒度活動識別的替代模式,使用微多普勒頻譜圖捕捉環(huán)境信息的最小子集。然而,由于低成本毫米波雷達系統(tǒng)產生稀疏和不均勻的點云,訓練細粒度、準確的活動分類器是一個挑戰(zhàn)。在本文中,我們
發(fā)表于 05-14 18:40
名單公布!【書籍評測活動NO.30】大規(guī)模語言模型:從理論到實踐
和強化學習展開,詳細介紹各階段使用的算法、數據、難點及實踐經驗。
預訓練階段需要利用包含數千億甚至數萬億單詞的訓練數據,并借助由數千塊高性能GPU 和高速網絡組成的超級計算機,花費數十天完成深度神經網絡
發(fā)表于 03-11 15:16
谷歌發(fā)布ASPIRE訓練框架,提升AI選擇性預測能力
該框架分為三步驟:“特定任務調整”、“答案采樣”以及“自我評估學習”。首先,“特定任務調整”階段針對基本訓練的大型語言模型進一步深化訓練,重點提高預測能力。其次,“答案采樣”階段模型會
如何使用Python進行圖像識別的自動學習自動訓練?
如何使用Python進行圖像識別的自動學習自動訓練? 使用Python進行圖像識別的自動學習和自動訓練需要掌握一些重要的概念和技術。在本文中,我們將介紹如何使用Python中的一些常用
深度學習如何訓練出好的模型
算法工程、數據派THU深度學習在近年來得到了廣泛的應用,從圖像識別、語音識別到自然語言處理等領域都有了卓越的表現。但是,要訓練出一個高效準確的深度學習模型并不容易。不僅需要有高質量的數據、合適的模型






 工商網監(jiān)
工商網監(jiān)
評論