 了解NeRF 神經輻射場
了解NeRF 神經輻射場
介紹
NeRF(Neural Radiance Fields)是一種先進的計算機圖形學技術,能夠生成高度逼真的3D場景。它通過深度學習的方法從2D圖片中學習,并生成連續的3D場景模型。NeRF的工作原理是自監督的,通過在有限的輸入視圖上訓練數據,可以用較少的數據集生成高質量的渲染。相比傳統方法中使用離散化的網格或體素表示場景,NeRF的連續函數表示具有優勢,并能夠從任意角度渲染,產生令人驚嘆的高質量渲染效果。
NeRF的引入在2020年由 Ben Mildenhall 等人的論文 "NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis"中提出。這項研究是在加州大學伯克利分校與谷歌的聯合項目中完成的。NeRF不僅可以從訓練時使用的輸入視圖角度渲染場景,還能夠從任意角度進行渲染,創造出優于現有渲染方法的高質量可視效果。
NeRF 提出的動機
NeRF的出現源于對傳統的3D重建技術的局限性的觀察。傳統的3D重建技術,如立體重建和深度學習的3D卷積神經網絡,主要依賴于離散的3D體素或點云表示來對3D空間進行建模。這些方法雖然取得了一些進展,但都存在著各種問題,比如模型精細度的限制、處理透明和半透明物體的困難等。
模型精細度的限制:對于基于體素或者點云的方法,它們的精細度往往受到計算能力和內存限制。對于體素,你需要在三維空間中創建一個網格并存儲每個格子的信息。如果你想要增加模型的精細度,你需要增加網格的密度,這會使得所需的內存呈立方級增長。對于點云,雖然可以適應不同的形狀和大小,但是精細的細節需要大量的點來表示,這也會導致計算和內存的需求增加。
處理透明和半透明物體的困難:傳統的3D重建方法通常假設每個3D點都是完全不透明的,即它們完全吸收或反射所有到達的光線。這忽略了物體的透明度或半透明度,因此在處理玻璃、水或氣體等物體時會導致錯誤的結果。
NeRF是為了解決現有3D重建方法的一些局限性而提出的。傳統的3D重建方法通常需要在離散的3D體素或三角網格上操作,這可能導致模型的分辨率和細節程度受到限制。而NeRF的方法是在連續的3D空間中操作,這意味著它可以生成具有任意分辨率和任意細節的模型。
此外,NeRF的方法還可以自然地處理場景中的透明度和混合色,這是許多傳統方法難以處理的問題。另外,由于NeRF使用的是神經網絡,所以它可以利用深度學習的強大能力,從一系列2D圖像中學習出復雜的3D場景。
具體來說:
對于模型精細度的限制:NeRF通過將場景建模為連續的輻射場并使用神經網絡進行參數化,避免了離散表示帶來的精細度限制。神經網絡能夠學習到連續的函數,所以可以以任意精度渲染場景。此外,所有的信息都嵌入到神經網絡的權重中,所以內存使用量主要取決于網絡的大小,而不是場景的復雜度或分辨率。
對于處理透明和半透明物體的困難:NeRF通過為每個3D位置分配一個密度值來解決這個問題。這個密度值描述了光線通過該位置時的衰減程度,所以可以自然地表示透明和半透明效果。在體積渲染過程中,NeRF會考慮到每個3D位置上的密度值,并計算光線在通過場景時的累積影響,從而能夠準確地渲染透明和半透明物體。
總的來說,NeRF通過使用神經網絡和體積渲染的方法,克服了傳統3D重建方法的一些主要限制,從而能夠以高精度和高細節級別重建和渲染3D場景。

什么是3D輻射場(Radiance Field)?
在深入地理解3D輻射場之前,首先需要理解“輻射”和“輻射場”的概念。
“輻射”
在光學中,“輻射”一詞通常用于描述光(或更一般地,電磁波)的傳播。具體來說,給定空間中的一個點和一個方向,"輻射"描述的是從這個點沿這個方向傳播的光的強度或能量。在許多情況下,我們更關心的是“光度”,即人眼對光的感知,這包括光的顏色和亮度。
“輻射場”
“輻射場”則是一個更高級別的概念。一個輻射場實際上是一個定義在空間中的函數,它給出了在每一個空間點、每一個方向上的輻射(或光度)。這就是3D輻射場的定義。
舉個例子,假設你在一個室內環境中,有一個亮度和顏色都在變化的燈光源。你現在想要用一個函數來描述整個空間中的光度情況。這個函數應該能告訴你在每個位置,從每個方向看過去的光的顏色和亮度是什么。這個函數就是3D輻射場。
具體到計算機圖形學和計算機視覺中,3D輻射場被用來表示和渲染3D場景。
它能夠準確地描述場景中的光照、陰影、反射和折射等復雜光學現象。
通過對3D輻射場的采樣和計算,我們可以從任意視角渲染出場景的圖像,甚至可以模擬出透明和半透明物體,以及復雜的光線傳播效果,如散射和吸收等。
例如,虛擬現實(VR)和增強現實(AR)就是3D輻射場的一種應用。在VR和AR中,我們需要根據用戶的視角動態地渲染3D場景。通過3D輻射場,我們可以快速地從任意視角計算出場景的圖像,從而實現實時的、自由的視角切換。
另一個例子是電影制作。在電影中,通常需要創建一些復雜的3D場景,并從不同視角進行渲染。通過使用3D輻射場,我們可以創建出高質量的、具有真實光線傳播效果的3D場景,使得電影的視覺效果更加逼真。
3D輻射場描述了 3D空間中光的分布和行為的方式。具體來說,它為3D空間中的每一個點分配了一個顏色和一個透明度(或者說體密度)值。顏色描述了從該點射出的光的顏色,而透明度描述了光線穿過該點時被吸收或散射的程度。
顏色: 對于空間中的一個點p和一個方向 d ,顏色描述了從點p沿著方向d射出的光的顏色。這個顏色是由在點 p 處的所有光源(包括直接的和間接的)在方向d上的光線的顏色組成的。
例如,如果在p處有一個紅色的光源,那么 將會包含紅色的成分。如果在p處沒有光源,但是在d方向上有一個反射面,那么 將會包含反射面反射過來的光的顏色。
體密度(透明度): 體密度 σ(p) 描述了在點p處光線的吸收或散射的程度。
如果 σ(p) 較高,那么在點p處的光線將會被大量吸收或散射,這意味著在p處的物體是不透明的或者是高度散射的(例如霧或云)。
如果 σ(p) 較低,那么在點p處的光線將會被較少吸收或散射,這意味著在p處的物體是透明的或者是低度散射的(例如清晰的空氣或水)。
3D輻射場是一個函數 ,其輸入是一個3D坐標 p 和一個方向 d ,輸出是在那個坐標和方向上的顏色和體密度,即 c(p, d) 和 σ(p) 。這個函數描述了3D空間中的光的分布和行為:它告訴我們在空間中的任意一個點,沿著任意一個方向,我們可以看到什么顏色的光,以及這個光線被吸收或散射的程度。
輸入:函數的輸入由兩部分組成:一個3D空間中的點和一個方向。
這里的3D空間可以是任何你希望描述其光照屬性的空間,例如一個室內環境、一個城市街道,或者整個宇宙。方向可以是任何方向,你可以想象這是一個從觀察者眼睛發出的光線的方向。
因此,這個函數實際上是在描述:在3D空間中的任何點,沿著任何方向,我們能看到什么。
輸出:函數的輸出是在輸入點和方向上的顏色和體密度值。
顏色值描述了你在指定的點和方向上看到的光的顏色。
體密度值描述了光線穿過指定點時的吸收或散射程度。
更具體地說,如果你在一個3D場景中選擇一個點p和一個方向d,那么函數L(p, d)將會告訴你:如果你站在點p,朝著方向d看過去,你將會看到什么顏色的光(c(p, d)),以及這個光線被穿過的物體吸收或散射的程度(σ(p))。
這種描述方法使得3D輻射場可以對3D空間中的光照情況進行高度精細的描述,包括復雜的光線傳播效果,如陰影、反射、折射、透明和半透明效果等。這也是為什么3D輻射場在計算機圖形學和計算機視覺中如此重要,因為它可以用于渲染高質量、逼真的3D場景。

NeRF 和 3D輻射場之間的關系
NeRF(Neural Radiance Fields)和3D輻射場是緊密關聯的,實際上,NeRF就是利用深度神經網絡來建模和學習3D輻射場。
NeRF提出的方法是以神經網絡來模擬連續的3D輻射場,即將一個3D坐標點和一個視線方向映射到一個顏色和密度。
這種表示方式對應于真實世界的物理特性,使得3D模型可以自然地表達物體的顏色和透明度,也使得3D模型可以以任意的精度和分辨率來表示。
根據前面的描述可知,3D輻射場是一個描述3D空間中光的分布和行為的函數,它將每個3D空間中的點和一個方向映射到一個顏色和體密度值。然而,在實際應用中,我們通常并不能直接得到這個函數,因此我們需要找到一種方法來逼近或學習這個函數。這就是NeRF的任務。
NeRF提出了一種基于深度神經網絡的方法,該網絡接受一個3D空間中的點和一個方向作為輸入,輸出該點和方向上的顏色和體密度值。通過在一組2D圖片上訓練,NeRF能夠學習到這個深度神經網絡的參數,從而學習到3D輻射場的近似表示。
NeRF的目標是通過一組2D圖片重建3D場景。
它不是直接在像素或三維體素上進行操作,而是在連續的三維空間中學習和推斷一個函數,這個函數可以用來描述空間中的場景。
NeRF建立了一個完全由神經網絡表示的3D場景模型,這個模型旨在描述一個場景中所有3D位置(由世界坐標表示)以及從任何觀察角度看到的顏色。
具體來說,NeRF訓練的過程是這樣的:它將一組2D圖片(通常是同一個3D場景的不同視角的圖片)作為輸入,然后通過優化算法調整網絡的參數,使得網絡輸出的3D輻射場能夠最好地重現這組2D圖片。訓練結束后,我們就得到了一個能夠描述3D場景的深度神經網絡,這個網絡實際上就是3D輻射場的近似表示。
因此,可以說NeRF是一種用深度神經網絡來學習和建模3D輻射場的方法。這種方法有許多優點,例如它能夠生成連續、全景的3D場景模型,可以自然地表達物體的顏色和透明度,可以以任意的精度和分辨率來表示3D模型,等等。這使得NeRF在3D重建和視圖合成等任務上具有非常高的性能。
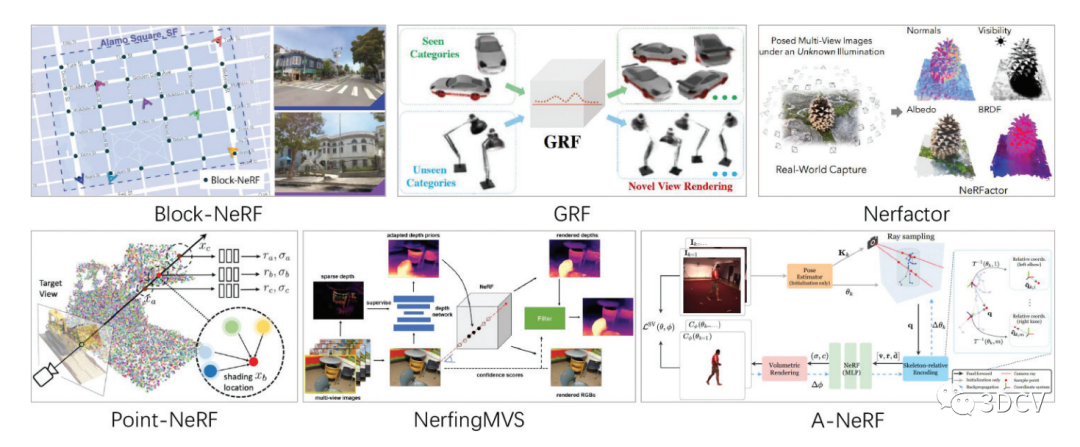
NeRF的核心思想
NeRF(Neural Radiance Fields)的核心思想是使用深度神經網絡來學習3D空間中任意一點在給定視線(由觀察點和方向定義)下的顏色和體密度。主要依賴于神經網絡來建模和學習3D空間中的輻射場,而這個神經網絡的學習過程是通過觀察一系列2D訓練圖片來完成的。
NeRF的核心思想可以用以下幾點來表述:
建模3D輻射場:NeRF使用深度神經網絡來建模3D空間中的輻射場。
這個神經網絡接受3D空間中的坐標點和一個方向作為輸入,輸出對應點和方向的顏色和體密度。在物理上,顏色代表從這個3D坐標點沿著指定方向射出的光的顏色,而體密度則表示光線在穿過這個點時被吸收或散射的程度。
連續的3D場景表示:NeRF的一個關鍵特點是它對3D場景的表示是連續的,而不是離散的。
這是通過使用全連接的神經網絡來實現的,這種網絡可以接受任意的實數輸入,并輸出相應的顏色和體密度。因此,NeRF可以以任意的精度和分辨率來表示3D模型。
視角無關性:NeRF對3D場景的表示是視角無關的。
這是因為它是在3D空間中建模的,而不是在2D圖像空間中。這意味著,一旦NeRF模型被訓練好,就可以從任何角度對其進行渲染,而不需要重新訓練模型。
通過2D圖像訓練:NeRF通過觀察一系列2D訓練圖片來學習這個深度神經網絡的參數。
具體來說,它會將一組2D圖片(通常是同一個3D場景的不同視角的圖片)作為輸入,然后通過優化算法調整網絡的參數,使得網絡輸出的3D輻射場能夠最好地重現這組2D圖片。
處理透明和半透明物體:NeRF的另一個重要特點是它能夠處理透明和半透明物體。
這是通過預測每個3D坐標點的體密度來實現的,體密度可以表示光線在穿過這個點時被吸收或散射的程度。
總的來說,NeRF的核心思想是通過深度學習來學習和預測3D空間中任意一點在給定視線下的顏色和體密度,從而從一系列2D訓練圖片中生成連續、詳細、全景的3D場景表示。這一過程中涉及到對3D輻射場的建模、連續的3D場景表示、視角無關性以及透明度處理等多個關鍵環節。
全連接神經網絡作為場景的連續3D表示:這是NeRF的一項創新,通過神經網絡建立了3D坐標點及觀察方向與光線密度和顏色之間的映射關系。
這種表示形式可以更好地處理細節,并且在新的視角下更加準確,因為它允許任意的視角插值,而無需再進行訓練。
體積渲染公式:NeRF使用體積渲染公式對沿視線路徑上的顏色和密度進行積分,以生成最終的2D圖像。這考慮了物體透明度的影響,并且可以通過改變路徑上的積分步數來適應不同的場景。
分解顏色和體密度的表示:NeRF的另一個關鍵思想是將顏色和體密度的表示進行分解,顏色與觀察方向有關,體密度與觀察方向無關。
這允許NeRF可以在視線方向上處理復雜的光線效果,例如高光和反射。
優化和訓練:NeRF優化的目標是減小由神經網絡生成的圖像和訓練集圖像之間的差異。訓練數據是一組同一場景的2D圖像,每張圖像都有相應的相機參數(包括位置和方向)。這些數據足以訓練網絡預測3D輻射場,并能夠從任意新的視角渲染出場景圖像。
NeRF(Neural Radiance Fields)的訓練過程通常被認為是自監督學習,因為它使用的監督信號是輸入數據自身,而不是外部提供的標簽。
具體來說,NeRF的訓練過程使用了一組2D圖像和相應的相機參數(包括位置和方向)。神經網絡的目標是預測能夠產生訓練圖像的3D場景的輻射場。這種情況下,監督信號(即目標輸出)就是輸入的2D圖像自身,因此可以認為這是一種自監督學習。
NeRF的實現技術
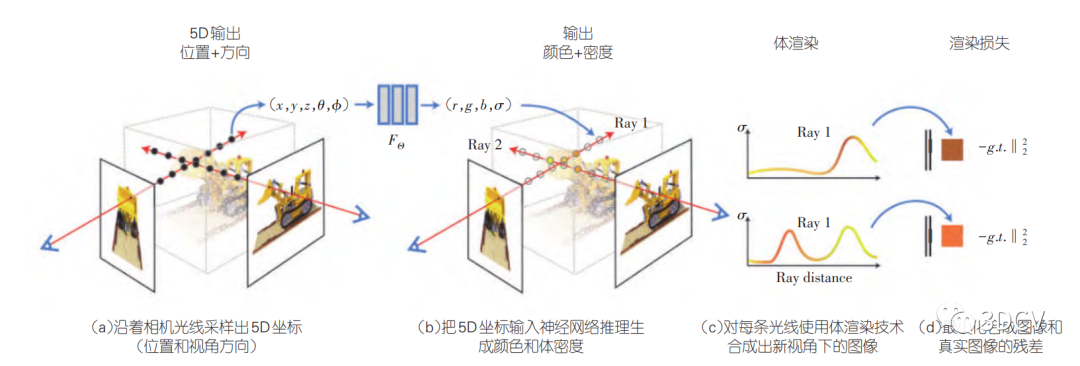
根據前面的介紹可知,NeRF的主要目標是從一組2D圖片中學習出3D場景的連續表示。而這個表示方式被稱為3D輻射場,它用一個函數來描述3D空間中光的行為。給定一個3D點和一個視線方向,這個函數可以輸出那個3D點在那個視線方向上的顏色以及光線被吸收或者散射的程度。
那么NeRF是如何做到這一點的呢?它采用了深度學習的方法。具體來說,NeRF訓練一個深度神經網絡,使得這個神經網絡能夠學習和近似上述的3D輻射場函數。神經網絡的輸入是一個3D坐標和一個視線方向,輸出是那個3D點在那個視線方向上的顏色和體密度。
為了訓練這個神經網絡,先收集一系列從不同角度和位置拍攝的2D圖像,然后用這些圖像來訓練網絡。
通過優化神經網絡,使得從訓練圖像中的每一個像素向場景中射出的光線的顏色和真實圖像盡可能一致,神經網絡就可以學習到場景的3D表示。
整個NeRF的流程是這樣:它通過深度學習的方法學習3D場景的連續表示,然后使用這個表示來從新的視角渲染場景圖像。這是一個從2D到3D,再到2D的過程,但是這個過程中獲得的是對3D場景的連續和詳細的描述,這對于3D場景的重建和渲染都是非常有用的。這個過程可以進一步分解如下:
數據收集:收集一組2D圖像,這些圖像從不同的角度和位置捕獲了同一場景。
這些圖片都是對同一3D場景的拍攝,所以在這個場景中,每個物體都會在多個圖像中出現,只是視角和位置不同。
預處理:對于每張圖像,我們需要知道相機的參數,包括相機的位置和方向。
這些參數可以用來確定從相機位置出發,經過圖像上每個像素,向場景中射出的視線的方向。
神經網絡訓練:我們使用這些數據訓練一個深度神經網絡。這個網絡的目標是能夠根據3D坐標和視線方向預測出那個位置的顏色和體密度。
在訓練過程中,使網絡預測的顏色值和真實的2D圖像盡可能一致,神經網絡就能學習到場景的3D表示。而為了實現這個目標,我們通過比較網絡預測的顏色和圖像中的真實顏色來計算誤差,然后通過反向傳播算法來更新網絡的參數。
神經網絡的輸入是每個3D位置和相應的視線方向,輸出是預測的顏色和密度值。
顏色值代表了該3D位置的顏色。
密度值代表了從相機向該3D位置射出的光線在途中被吸收或散射的程度。
渲染:當神經網絡訓練完畢后,我們就得到了一個可以描述3D場景的模型。我們可以使用訓練好的神經網絡從任意新的視角渲染場景圖像。
給定一個新的視角,我們可以通過這個模型來渲染出新的場景圖像。
我們只需要對每個像素確定出一個視線,然后使用神經網絡預測沿著這個視線的所有3D點的顏色,最后把這些顏色組合起來,就可以得到新的圖像。
體積渲染 (volume rendering)
為了從這個網絡生成2D圖像,NeRF使用了一種稱為體積渲染 (volume rendering) 的技術。這是一種處理半透明物體的技術,它將光線沿視線路徑的所有顏色貢獻加權求和來生成最終的像素顏色。
簡單來說,體積渲染是通過將沿著每個像素的射線上的所有顏色值加權求和(其中權重由密度值決定)來生成圖像的。
這個過程可以很自然地處理透明度和混合色,從而生成真實的圖像。
這個過程基本上就是沿著每個像素的射線方向,積分所有3D點的顏色和密度。
體積渲染 (volume rendering) 技術是一個關鍵步驟,因為它允許我們通過從每個像素的射線上積分所有顏色和密度來創建2D圖像。
體積渲染過程首先確定出射線路徑(從相機位置通過每個像素),然后在這些射線上采樣一系列3D點,并通過神經網絡獲取這些點的顏色和密度值。
然后,將這些顏色值根據相應的密度值進行加權疊加,從而得到最終的像素顏色。這個過程可以很好地處理顏色混合和透明物體。
這個過程充分考慮了光線在物體間傳播的物理規則,因此,通過NeRF生成的圖像不僅可以高度逼真,而且可以從任何新的視角渲染出來。
這種技術的潛力非常大,因為它不僅可以用于3D渲染和虛擬現實,也可以用于計算機視覺和機器學習等其他領域。
體積渲染是一種處理3D數據的技術,它可以生成從任意視角觀察3D場景的2D圖像。這種技術在許多領域都有應用,比如醫療成像(例如CT掃描和MRI掃描)、科學可視化(例如氣候模型和電子云模型),以及電影和電視特效制作等。
在體積渲染中,每個3D數據點通常有一個或多個屬性,比如顏色、透明度、密度或其他的物理性質。渲染的目標是將這些3D數據點轉化為2D圖像上的像素,同時考慮視點、光線傳播和物體間的相互作用。
NeRF(神經輻射場)中的體積渲染方法是一種特殊的體積渲染方法。在這種方法中,3D空間中的每一個點都由神經網絡預測的一個顏色值和一個體密度值描述。然后,沿著每個像素的射線,積分所有3D點的顏色和體密度,從而生成2D圖像。
具體來說,對于每個像素,首先確定一個射線,然后在射線上采樣一系列3D點,對這些點的顏色值進行加權求和,權重由體密度決定,從而得到最終的像素顏色。
需要通過體積渲染來計算像素的顏色。體積渲染的公式可以表示為:
其中:
是渲染出的顏色;
表示的是從相機位置到3D空間點s之間的媒介透射率。
T(s) 是從視點到3D點的透明度函數,可以理解為從相機到當前3D點之間所有點的體密度的指數積;
透射率衡量了光線在通過物質后保持其強度的能力。
在這個公式中,透射率等于路徑上所有點的體密度的負指數積分,這意味著密度越大,透射率越小,更多的光線會被吸收。
是3D空間點s的體密度。
是在3D空間點s處視線方向的顏色。
上面的公式是體積渲染的核心公式,它說明了生成每個像素的顏色是如何由沿射線方向的一系列3D點的顏色和體密度決定的。
位置編碼和方向編碼
為了幫助神經網絡捕獲微妙的幾何細節以及復雜的光線傳輸現象,如反射和透射,NeRF引入了對3D空間位置和觀察方向的編碼。位置編碼和方向編碼是一種強制神經網絡學習場景中幾何和光線傳播細節的方法。
這是NeRF中用于處理3D空間位置和觀察方向的技術。它使用正弦和余弦函數對輸入的坐標和方向進行編碼,從而更好地處理幾何細節和光線傳播。
在訓練網絡時,3D位置和觀察方向首先會被編碼為更高維的向量,然后才輸入到神經網絡中。
這種編碼使用的是一個簡單的正弦和余弦函數的系列,這種編碼方式可以使得神經網絡能夠更好地捕捉到細微的空間和方向變化。
通過對輸入的3D坐標和視線方向進行一系列正弦和余弦函數變換,生成的多尺度頻率編碼可以幫助神經網絡更好地建模場景的復雜細節。
它的目的是以更高的頻率捕獲物體的幾何細節和光線傳播。基于位置和方向的原始坐標和編碼坐標,神經網絡可以學習到不同的幾何和光學特性。
NeRF 利用傅里葉級數來編碼輸入位置和視線方向。
傅里葉級數是一種分析數學工具,可以將任何周期性函數表示為正弦和余弦的和。
通過對空間和方向進行傅里葉編碼,NeRF 增加了神經網絡對幾何和光照變化的感知能力。
具體來說,對于一個給定的 3D 點位置 和方向 ,它們都可以被分解為其對應的頻域表示。這個頻域表示就是嵌入向量。嵌入向量包含了原始的點和方向,以及一系列正弦和余弦函數對它們進行編碼后的結果。
位置 和方向 轉換為嵌入向量 和 ,其位置編碼和方向編碼公式如下:
其中,決定了編碼的頻率,這是一個可以調整的超參數,它控制了正弦和余弦函數的頻率的上限。一般來說,較大的 會讓神經網絡學習到更豐富的幾何和光照細節,但也會增加計算復雜度。
嵌入向量中的正弦和余弦項給神經網絡提供了處理周期性和反射性質的能力,這對于描述復雜的幾何形狀和光線傳播特別重要。
例如,對于一個周期性的紋理,如果只使用原始的點和方向作為輸入,神經網絡可能很難學習到這個周期性。但如果使用了傅立葉編碼,神經網絡就可以通過調節對應頻率的權重來表示這個周期性。
這種編碼方式的靈感來源于傅立葉變換和傅立葉級數的性質,它們能夠將任何函數表示為一系列正弦和余弦函數的和。通過將這種性質應用到神經渲染中,NeRF 可以生成更真實的圖像,并且對于幾何和光照的處理也更加精確。
分層采樣策略 (Hierarchical Sampling Strategy)
在渲染過程中,光線會穿過許多不同的體素(體積元素),一條射線可能穿過多個物體或者穿過一個物體的多個部分,每個部分都會對最終像素顏色產生貢獻。
由于體積渲染涉及對光線路徑上的所有體素進行積分,因此需要對這些體素進行采樣。
然而,不是所有的體素對于生成最終的圖像都相同重要。
有些體素可能包含了大量的細節信息,比如對象的邊緣或是紋理的詳細部分,而其他的體素可能只包含了空氣或是非常平滑的表面。
對于這后者,我們并不需要進行很密集的采樣。
為了解決這個問題,為了有效地利用采樣點,NeRF使用了一種分層采樣策略來更高效地進行體積渲染。這是一種用于體積渲染的技術,用于優化渲染效率。
NeRF利用分層采樣策略對預測的體密度較高的區域進行更密集、更精細的采樣采樣。在這種策略中,首先在整個射線上均勻地采樣一些點,然后在預測的體密度高的區域再進行更細致的采樣。
首先進行均勻的粗采樣 (coarse sampling) ,獲取預測的體密度分布。根據這些粗采樣點的密度預測結果,根據這個分布,再在預測的體密度高的區域進行更細粒度的采樣 (fine sampling)。
這樣可以更有效地使用采樣點,更準確地估計每個像素的顏色值。
這種策略可以使得采樣過程更加集中在重要的區域,可以將計算資源更有效地分配到圖像的重要部分,可以更有效地利用采樣點,從而提高渲染效率,并提高渲染質量。
分層采樣策略的優點是它可以顯著提高渲染的效率和質量。因為它將計算資源集中在了那些對生成圖像質量最重要的區域,所以它可以在有限的計算資源下生成更高質量的圖像。
這種策略的靈感來源于計算機圖形學中的重要性采樣技術 (importance sampling)。
重要性采樣是一種選擇性地對那些對結果有重大影響的部分進行采樣的方法。
通過將這種方法應用到體積渲染中,NeRF能夠更高效地渲染復雜的3D場景。
光線投射(Ray Casting)
這是一種在3D場景中生成2D圖像的技術,它將每個像素看作從相機位置出發的一條光線,并使用神經網絡預測沿著光線路徑的顏色和體密度。
NeRF使用光線投射來確定每個像素的射線方向。給定相機位置和像素位置,可以計算出射線的起點和方向。
然后,NeRF在射線上采樣一系列3D點,并通過神經網絡預測這些點的顏色和體密度。
具體來說,將每個像素視為從相機位置出發的一條光線,每個像素都有一條從相機位置出發、通過像素中心、指向場景的射線。然后沿這條光線采樣多個3D點,輸入神經網絡得到顏色和體密度,最后使用體積渲染技術得到最終的像素顏色。這個過程可以形式化為一個積分問題,公式如下:
其中 是射線 的顏色, 是到 3D 點的透射度, 是 3D 點的體密度, 是 3D 點的顏色。
差分渲染(Differential Rendering)
由于NeRF的目標是使生成的圖像盡可能接近真實的2D圖像,這需要計算圖像的梯度并進行反向傳播。然而,由于體積渲染是通過積分操作得到像素顏色,直接計算梯度是非常困難的。
差分渲染是指對渲染結果進行微分,得到結果關于輸入參數的梯度。這對于神經網絡的訓練非常重要,因為梯度信息可以用來優化神經網絡的參數。
差分渲染是一種重要的計算機圖形學技術,允許我們計算圖像關于其輸入參數(例如光源位置、物體表面材質等)的梯度。
差分渲染在NeRF中的實現,主要涉及對體積渲染公式的微分。NeRF利用差分渲染技術,這使得神經網絡生成的圖像可以進行反向傳播,從而優化網絡參數。具體來說,NeRF通過對體積渲染的公式進行微分,得到每個像素顏色關于神經網絡參數的梯度,實現了光線的顏色和神經網絡參數之間的導數計算。
這樣,就可以通過梯度下降算法來優化神經網絡,使得生成的圖像盡可能接近訓練數據中的真實圖像。由于神經網絡和體積渲染過程都是可微的,NeRF可以計算生成圖像與真實圖像之間的誤差關于神經網絡參數的梯度。
我們可以簡單地看這個問題為最小化損失函數的問題,其中損失函數定義為生成圖像與真實圖像之間的誤差。如果我們把神經網絡的參數表示為,那么我們的目標就是找到一組參數,使得損失函數L最小。為了實現這一目標,我們需要計算損失函數關于參數的梯度,然后通過梯度下降算法來更新參數。
在具體的計算過程中,我們首先需要計算每個像素的顏色c關于體積密度σ和顏色c的導數,然后通過鏈式法則,可以計算出損失函數L關于網絡參數θ的梯度。然后,我們可以使用這些梯度來更新網絡參數。這種差分渲染技術使得NeRF可以利用已有的深度學習框架進行訓練(如TensorFlow或PyTorch的自動微分功能),同時也使得NeRF可以從少量的2D圖像中學習出3D場景的連續表示。
假設神經網絡的參數為,光線在處的顏色可以通過下面的公式進行計算:
其中,是光線在處之前的傳輸函數,是處的體積密度,是處的顏色。
那么,我們的目標就是最小化生成的圖像和真實圖像之間的差異,也就是最小化損失函數。
然后,我們可以通過計算損失函數關于參數的梯度來更新參數,即,其中,是學習率。
通過這種方法,NeRF可以逐步改進神經網絡的性能,使生成的圖像越來越接近真實的圖像。這種技術的靈感來源于深度學習中的反向傳播算法,是一種將神經網絡應用于計算機圖形學的有效方法。
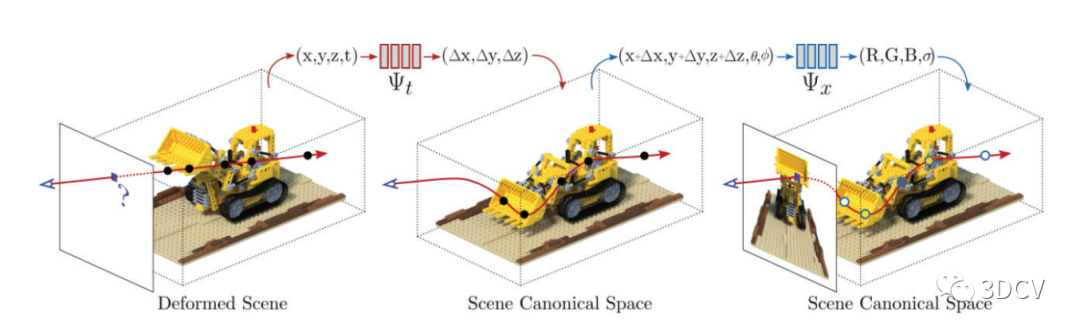
NeRF的基本原理
NeRF的核心概念是用一個深度神經網絡來表示一個場景的3D輻射場(radiance field)。這個輻射場可以被理解為一個函數,其輸入是一個3D位置和一個視線方向,輸出是在該位置和方向下的顏色和密度
NeRF的基本原理其實是建立在經典的體積渲染理論之上,而NeRF的主要創新點在于將一個深度神經網絡用于預測3D空間中的顏色和密度信息。
NeRF模型中的主要函數可以表示為:
這里,是一個深度神經網絡,它接收一個3D空間點和一個視線方向作為輸入,并輸出該點的顏色和體密度。
在NeRF的框架中,神經網絡是用來學習和表示場景的3D顏色和密度信息的工具。它的輸入是一個3D坐標和一個方向,輸出是在該坐標處的顏色和體密度。這種表示方式允許網絡對3D空間中的每個點進行細粒度的建模,同時保持了對視角的感知,因為顏色輸出是依賴于方向的。
函數實際上是神經網絡對場景的表示。這里的是神經網絡的參數,可以通過訓練學習得到。
具體來說,訓練過程是這樣的:
給定一系列2D圖像和對應的攝像機參數(包括攝像機位置和視角等),首先將攝像機參數轉換為3D空間中的射線。
對于每一條射線,通過一定的方法(如均勻采樣或重要性采樣)選取一些點,然后計算出這些點到攝像機的方向。將這些點的坐標和方向作為輸入,送入神經網絡,得到每個點的顏色和體密度。
在訓練過程中,給定一系列2D圖像和對應的攝像機參數,我們可以將每個2D圖像上的像素想象成從相機位置出發的一條射線。為了預測這條射線的顏色,我們需要在3D空間中沿著這條射線采樣多個點。
例如,我們可以選擇沿著射線等間距地采樣10個點,然后將這10個點的3D坐標和對應的視線方向作為輸入,輸入到神經網絡中,得到這10個點的顏色和體密度。值得注意的是,射線的方向是一個重要的輸入,因為在許多場景中,物體的顏色會隨著觀察的角度變化,這被稱為視差效應。
然后,使用上面的體積渲染公式,從這些顏色和體密度計算出射線的顏色。
得到顏色和體密度之后,就可以利用體積渲染公式來計算出射線的顏色。這個公式基本上是將沿射線的所有點的顏色進行加權疊加,其中權重是通過體密度來計算的。具體來說,一個點的體密度越高,它對最終顏色的貢獻就越大。
最后,將計算出的射線顏色與2D圖像上對應的像素顏色進行比較,計算出誤差,通過梯度下降等優化算法來更新神經網絡的參數,使得預測的顏色盡可能接近真實的顏色。
將計算出的射線顏色與2D圖像上對應的像素顏色進行比較,計算出誤差。這個誤差可以看作是神經網絡預測的顏色與真實顏色之間的差距。通過反向傳播這個誤差,我們可以計算出神經網絡參數的梯度,并使用優化算法(如梯度下降)來更新參數,使得預測的顏色更接近真實的顏色。
通過大量的2D圖像和對應的攝像機參數進行訓練,神經網絡可以逐漸學會如何根據3D位置和視線方向來預測顏色和體密度,實現了從2D圖像到3D場景的學習和重建,從而形成對3D場景的理解。
這種方法的好處是,它不需要對場景進行顯式的3D建模,而是通過一個可微的神經網絡隱式地學習場景的3D表示,這使得它能夠處理非常復雜和詳細的場景。同時,由于其基于射線的渲染方式,它也能自然地處理復雜的光線效應,如陰影、反射和折射等。
NeRF的整體流程
NeRF方法使得它可以從一系列2D圖片中學習并生成一個連續、全景的3D場景模型,能夠處理透明度和復雜的光照條件,而且可以以任意的精度和細節級別來表示。這使得NeRF在3D重建和視圖合成的領域具有廣泛的潛力和應用前景。
數據收集:NeRF使用一系列從不同角度和位置拍攝的2D圖片作為輸入。這些圖片可以是實際拍攝的,也可以是通過計算機圖形學生成的。
首先,收集一系列在不同角度和視點下拍攝的2D圖像作為輸入數據。這些圖像應盡可能包含足夠的視角覆蓋,以覆蓋整個3D場景。
神經網絡訓練:NeRF使用一個深度神經網絡來表示3D輻射場(radiance field)。這個網絡接收一個3D坐標和一個方向作為輸入,輸出該坐標處的顏色和體密度。這個網絡是通過最小化模型預測的顏色和實際圖像的顏色之間的誤差來訓練的。
在NeRF中,通常使用一個全連接的多層感知機(MLP)神經網絡來表達3D空間中的顏色和密度。給定一個3D坐標和一個方向,神經網絡會輸出在坐標處的顏色和體密度。具體的函數表示如下:
其中代表神經網絡,是神經網絡的參數。這個網絡通過最小化預測的顏色和實際圖像的顏色之間的誤差來進行訓練。
體積渲染:訓練好神經網絡之后,NeRF會通過體積渲染的技術,從神經輻射場生成2D圖像。具體來說,它計算沿每個像素射線方向的顏色和體密度的加權和,生成最終的2D圖像。
對于給定的一條射線,我們需要計算出這條射線上每一點對于最后形成的像素顏色的貢獻。其顏色計算公式如下:
這個公式表示沿射線的顏色的積分,其中每個位置的顏色被其體密度和沿射線的可見性所加權。
在這個公式中:
這個公式的基本思想是,我們沿著射線方向,對射線上每一點的顏色按照其體密度和透射函數進行加權,然后累積這些顏色,得到的就是射線最終的顏色。這個過程相當于模擬了真實世界中光線穿過物體并被物體顏色影響的過程。
而其中, 表示光線穿過點之前的所有點的累積透明度,計算公式為:
這個公式的意思是,光線在到達某一點時,其顏色已經因為途徑點的體積密度而衰減,所以需要一個衰減因子來表示這種衰減。
在這個公式中,是在點的體密度,計算的是從攝像機(在處)到的光線路徑中所有點的體密度之和。這個和被認為是光線在到達前被吸收的程度,其負指數就是光線在到達前剩余的光線強度,也就是。
這里,被稱為透射函數(transmittance function),代表了從攝像機出發,到達空間中點時,光線的衰減程度。光線在經過某一點前,如果途徑的介質(例如空氣、水、玻璃、煙霧等)密度較大或者路徑較長,那么光線就會發生更大的衰減。
因此,如果路徑上的總體密度大(表示有很多物質可以吸收或散射光線),那么就會接近于0,表示光線大部分被吸收;相反,如果路徑上的總體密度小(表示只有少量物質吸收或散射光線),那么就會接近于1,表示大部分光線沒有被吸收。
表示射線在處的空間坐標。
表示在處的體密度。體密度越大,說明該處物質越密集,對光線的影響也就越大。
表示在處的顏色。
表示從射線起點到點的透射函數,也就是(下面解釋)光線衰減程度。
可見性是通過計算光線從攝像機到當前位置之間所有位置的體密度的積分來計算的,表示了光線在到達當前位置之前有多少光被吸收了。
新視圖生成:一旦訓練好神經網絡,就可以根據用戶指定的新視點和視角,生成新的2D圖像,這些圖像可以是從訓練數據中未出現過的角度和位置觀察的。
由于NeRF的場景表達是全局的和連續的,因此可以很自然地生成新視圖,包括訓練數據中未曾出現過的視角。這對于許多應用如虛擬現實、增強現實和3D打印等都很有用。
請注意,在實際應用中,可能還需要進行其他一些步驟,例如前處理(如圖像對齊和標準化)、后處理(如圖像融合和濾波)、超參數調整等。但在概念上,上面這些步驟已經涵蓋了NeRF的核心整體流程。
NeRF的優勢與局限性
NeRF的主要優勢在于其能夠生成高度詳細和高度真實的3D模型,而且這些模型可以從任何角度渲染出新的2D圖像。
這一特性使得NeRF在許多領域有很大的潛力,包括虛擬和增強現實、游戲開發、3D打印、電影制作以及更廣泛的圖形學應用。
此外,因為NeRF生成的是連續的3D模型,而不是像傳統的3D重建方法那樣生成離散的3D體素或三角形網格,所以NeRF生成的模型可以具有更高的解析度和更細的細節。
具體如下:
高質量渲染:NeRF通過學習場景的3D輻射場來生成圖像,而這種方式可以非常好地恢復場景的細節,如紋理、光照和遮擋等。NeRF在渲染出的圖像中,不僅物體的形狀和紋理細節表現得生動逼真,而且光照和陰影效果也展現得十分真實,這都得益于NeRF的深度神經網絡在學習過程中對場景中的復雜關系進行了高度抽象和理解。
例如,你想生成一張圖片,圖片的場景是一個裝滿各種水果的籃子。如果你使用NeRF技術,生成的圖片不僅會真實地展現出水果的形狀、顏色和紋理,還會準確地展現出陰影和反射等光照效果。你可以清楚地看到水果表面的紋理,例如蘋果的光滑表面、橙子的粗糙皮,甚至可以看到籃子的編織細節。這種高質量的渲染效果是因為NeRF通過學習場景的3D輻射場,精確地模擬了物體和光線之間的交互。
連續性:NeRF表示的是一個連續的3D模型,這與傳統的3D重建方法(如基于體素或三角網格的方法)有很大區別。這種連續的表示方式使NeRF可以在任意位置給出顏色和體密度的信息,因此能夠捕捉到場景中的細微細節,例如物體邊緣的微小變化,或者物體表面的精細紋理等。
假設使用NeRF來模擬一座古老的建筑。傳統的3D重建方法可能會生成一個由多個小方塊(體素)或三角形網格組成的模型,這種模型可能無法準確地展現建筑的某些細節,例如雕刻的線條或磚塊的質感。然而,NeRF生成的是一個連續的3D模型,這意味著你可以在任意位置得到顏色和體密度的信息,因此可以清晰地看到建筑表面的每一個細節。
全景場景建模:NeRF使用深度神經網絡來表示整個場景的3D輻射場,因此它可以處理全景的場景建模。這一特性使NeRF可以捕捉和重建大范圍內的3D場景,包括室內、室外、城市景觀等各種環境。
假設有一個項目需要重建一個城市街景。使用NeRF,你可以生成一個完整的3D模型,包括街道、建筑、車輛,甚至是人行道上的灌木和樹木。你可以從任何角度查看這個模型,甚至可以像在Google Street View中那樣,自由地在街景中移動和旋轉。
任意視角渲染:NeRF的另一個重要優點是,一旦訓練好,它可以在任意視點和視角生成2D圖像。這意味著,我們可以在任意位置、任意角度觀察NeRF重建的3D場景,甚至可以在場景中自由移動和旋轉,從而觀察場景中的不同部分。這對于許多應用,如虛擬現實(VR)、增強現實(AR)等,都是非常有價值的。
例如,你可能有一個3D模型的古堡,并希望生成一系列從不同角度看古堡的圖像。使用NeRF,你可以輕松地做到這一點。你甚至可以在古堡的模型中自由移動和旋轉,生成從古堡內部看向外部的圖像。
對光照和材質的建模:NeRF不僅可以捕捉場景的3D結構,而且可以捕捉場景的復雜光照和材質信息。這意味著,NeRF不僅可以重建物體的形狀,還可以重建物體的表面紋理和光照效果。這也是NeRF能夠生成高質量渲染圖像的一個重要原因。
假設正在重建一個室內場景,場景中有一個木質的桌子和一個金屬的燈。使用NeRF,你可以不僅重建出桌子和燈的形狀,還可以重建出它們的材質和光照效果。你可以看到木桌的木紋,感受到它的質感;你也可以看到金屬燈反射的光線,感受到它的光澤。
無需顯式的3D重建:盡管NeRF的內部工作機制是通過學習一個3D輻射場,但在訓練和推理過程中,NeRF并不需要進行顯式的3D建模,也不需要估計深度信息。這使得NeRF的訓練和使用過程更為簡單和直接。
例如,可能有一系列從不同角度拍攝的物體的2D圖片,你想用這些圖片來生成新的視圖。使用NeRF,你可以直接輸入這些2D圖片,然后生成新的視圖,而不需要先重建一個3D模型,或者估計圖片中的深度信息。這使得NeRF的使用更為簡單和直接。
當然,這種方法也有一些局限性,例如訓練和渲染過程需要大量的計算資源,而且對于有大量動態內容和復雜反射的場景,NeRF可能無法處理得很好。
NeRF的局限性,主要包括:
計算成本高:NeRF的訓練和推理過程需要大量的計算資源。這是因為,NeRF需要對整個3D輻射場進行建模,并且需要渲染大量的2D圖像。因此,NeRF在大規模的場景中的應用可能會受到限制。
處理動態場景困難:目前的NeRF主要適用于靜態場景,對動態場景的處理能力有限。這是因為,NeRF的訓練過程需要大量的時間,而在這個過程中,場景中的物體和光照條件可能會發生變化。
處理反射和透明度復雜的物體困難:雖然NeRF可以處理一些反射和透明度的效果,但對于具有復雜反射和透明度的物體,NeRF可能無法處理得很好。這是因為,這些效果依賴于物體的視角和光照條件,而這些因素在NeRF的訓練過程中是難以考慮的。
需求高質量的輸入數據:NeRF依賴于高質量的輸入數據,如高分辨率的圖片和準確的相機參數。如果這些數據的質量不高,那么NeRF的效果可能會受到影響。
訓練時間長:盡管NeRF可以生成高質量的渲染圖像,但其訓練過程通常需要大量的時間和計算資源。這可能會限制NeRF在實時應用中的使用。
NeRF的應用
NeRF(Neural Radiance Fields)是一種新興的3D重建和視圖合成技術,雖然研究起步不久,但已經在許多領域顯示出巨大的潛力。至2023年為止,以下是一些NeRF已經應用或可能應用的領域:
影視制作:在電影制作中,特效是非常關鍵的一部分。傳統的3D模型創建和渲染方法通常需要大量的人力和時間,而且結果的質量也會受到限制。
NeRF提供了一種新的方法,可以通過學習一系列照片來自動創建和渲染3D模型。這種方法不僅可以提高效率,而且可以生成非常高質量的結果。例如,NeRF可以用于創建真實的角色或場景模型,然后在任何角度渲染這些模型,以便在電影中使用。
游戲開發:在游戲開發中,環境建模是一個重要的部分。傳統的建模方法通常需要大量的手工作業,而且結果的質量也會受到限制。
NeRF提供了一種新的方法,可以通過學習一系列照片來自動創建3D環境模型。這種方法不僅可以提高效率,而且可以生成非常詳細和真實的環境模型。例如,NeRF可以用于創建游戲中的城市景觀,森林,山脈等環境。
虛擬現實(VR)和增強現實(AR):VR和AR是最能體現NeRF優勢的領域。在VR和AR中,用戶可以在虛擬世界中自由移動和查看,因此需要在任何角度都能生成高質量的2D圖像。
NeRF正好滿足這個需求,它可以用來創建高質量的3D場景模型,然后在任何視點和視角渲染這些模型。例如,NeRF可以用于創建VR游戲的場景,或者在AR應用中生成虛擬物體。
3D打印:NeRF生成的3D模型具有高精度和連續性,這使得這些模型非常適合用于3D打印。傳統的3D建模方法通常需要大量的手工作業,并且難以捕捉到物體的細微細節。
NeRF提供了一種新的方法,可以通過學習一系列照片來自動創建3D模型,這些模型不僅具有高精度,而且能夠捕捉到物體的細微細節。例如,NeRF可以用于創建復雜的工藝品或機械零件的3D模型,然后直接使用這些模型進行3D打印。
這些僅僅是NeRF的幾個潛在應用,其在更多領域的應用還在探索和發展中。例如,在建筑設計,地理信息系統(GIS),醫療成像等領域,NeRF都可能發揮重要的作用。
責任編輯:彭菁
-
3D
+關注
關注
9文章
2862瀏覽量
107324 -
輻射
+關注
關注
1文章
595瀏覽量
36306 -
建模
+關注
關注
1文章
299瀏覽量
60733
原文標題:一文詳解 | 你還沒了解NeRF 神經輻射場嗎?
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
NeRF的基本概念及工作原理
Block nerf:可縮放的大型場景神經視圖合成
基于BlockNeRF的大場景規模化神經視圖合成
NeRF的研究目的是合成同一場景不同視角下的圖像
NerfingMVS:引導優化神經輻射場實現室內多視角三維重建
介紹一種神經場成對配準的技術NeRF2NeRF
基于NeRF的隱式GAN架構
基于神經輻射場(NeRFs)的自動駕駛模擬器

WACV 2023 I從ScanNeRF到元宇宙:神經輻射場的未來

利用PyTorch實現NeRF代碼詳解
NeurlPS'23開源 | 大規模室外NeRF也可以實時渲染

基于幾何分析的神經輻射場編輯方法

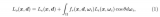





 工商網監
工商網監
評論