") 如何從Linux內(nèi)核角度探秘Java NIO文件并讀寫本質(zhì)呢?
如何從Linux內(nèi)核角度探秘Java NIO文件并讀寫本質(zhì)呢?
1. 前言
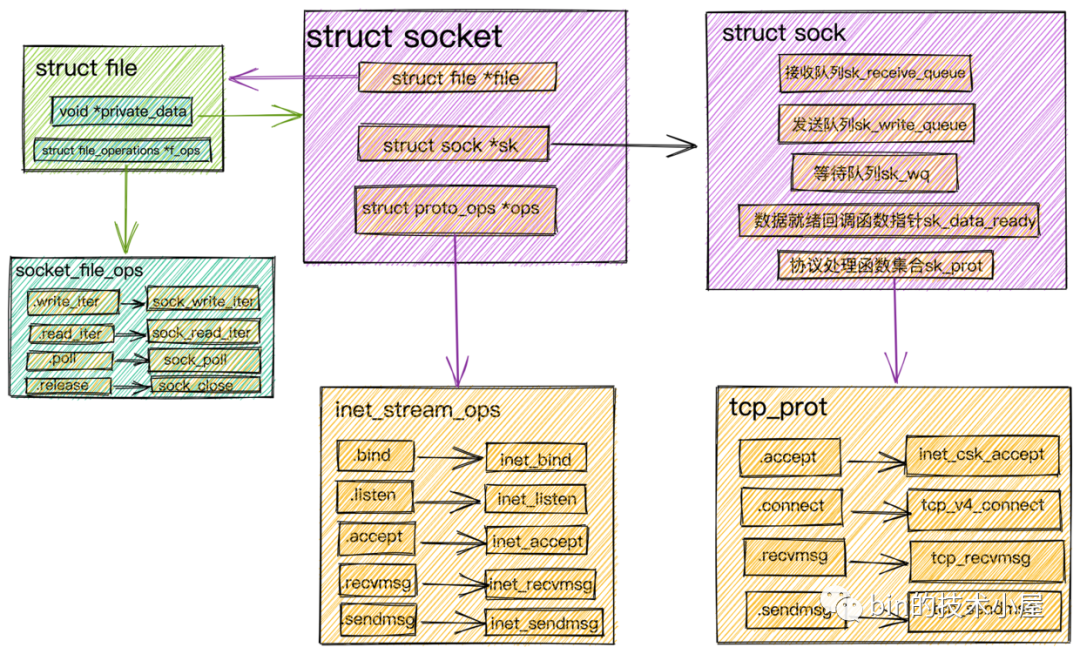
筆者在 《聊聊Netty那些事兒之從內(nèi)核角度看IO模型》一文中曾對(duì) Socket 文件在內(nèi)核中的相關(guān)數(shù)據(jù)結(jié)構(gòu)為大家做了詳盡的闡述。
Socket內(nèi)核結(jié)構(gòu).png
又在此基礎(chǔ)之上介紹了針對(duì) socket 文件的相關(guān)操作及其對(duì)應(yīng)在內(nèi)核中的處理流程:
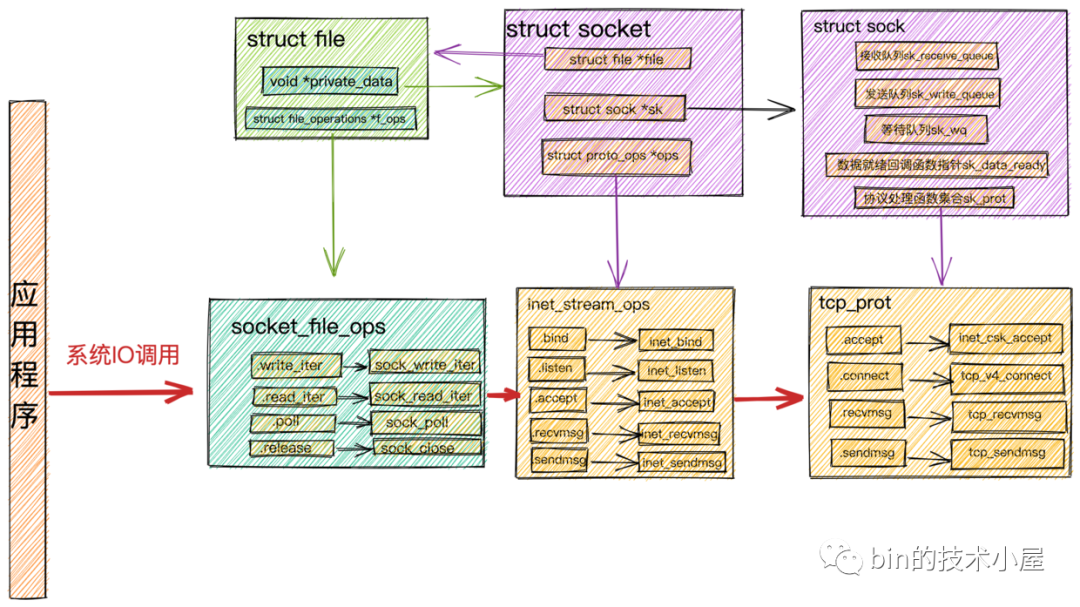
系統(tǒng)IO調(diào)用結(jié)構(gòu).png
并與 epoll 的工作機(jī)制進(jìn)行了串聯(lián):
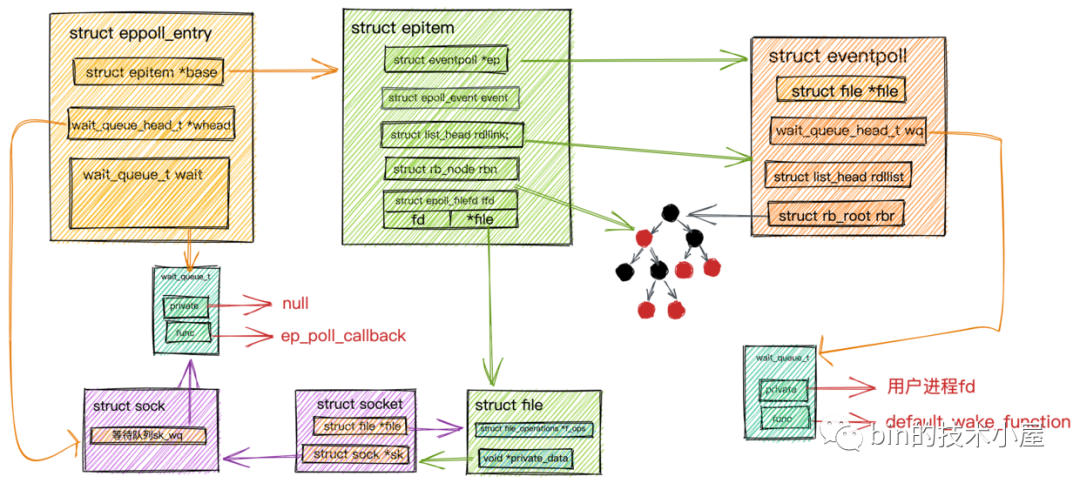
數(shù)據(jù)到來epoll_wait流程.png
通過這些內(nèi)容的串聯(lián)介紹,我想大家現(xiàn)在一定對(duì) socket 文件非常熟悉了,在我們利用 socket 文件接口在與內(nèi)核進(jìn)行網(wǎng)絡(luò)數(shù)據(jù)讀取,發(fā)送的相關(guān)交互的時(shí)候,不可避免的涉及到一個(gè)新的問題,就是我們?nèi)绾卧谟脩艨臻g設(shè)計(jì)一個(gè)字節(jié)緩沖區(qū)來高效便捷的存儲(chǔ)管理這些需要和 socket 文件進(jìn)行交互的網(wǎng)絡(luò)數(shù)據(jù)。
于是筆者又在 《一步一圖帶你深入剖析 JDK NIO ByteBuffer 在不同字節(jié)序下的設(shè)計(jì)與實(shí)現(xiàn)》 一文中帶大家從 JDK NIO Buffer 的頂層設(shè)計(jì)開始,詳細(xì)介紹了 NIO Buffer 中的頂層抽象設(shè)計(jì)以及行為定義,隨后我們選取了在網(wǎng)絡(luò)應(yīng)用程序中比較常用的 ByteBuffer 來詳細(xì)介紹了這個(gè)Buffer具體類型的實(shí)現(xiàn),并以 HeapByteBuffer 為例說明了JDK NIO 在不同字節(jié)序下的 ByteBuffer 實(shí)現(xiàn)。
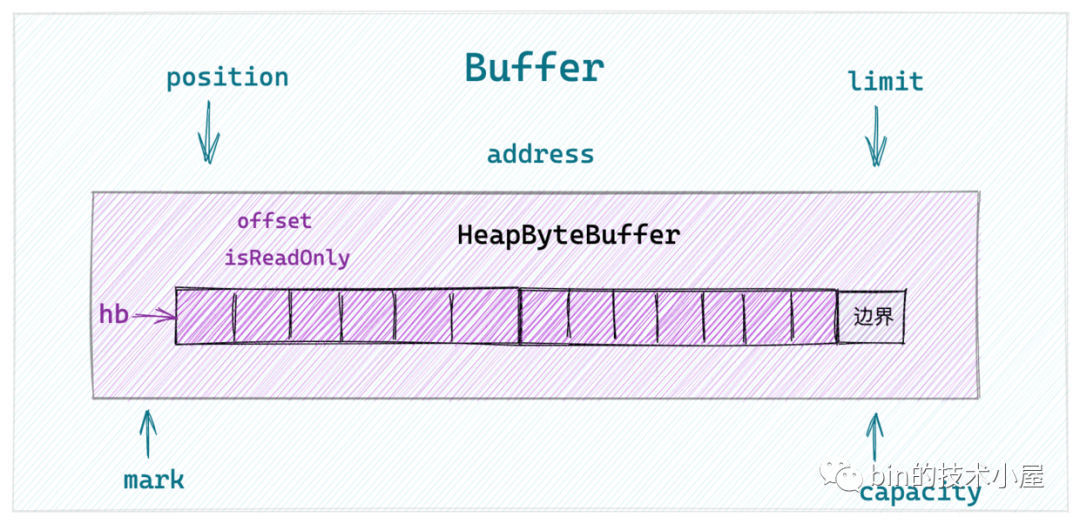
HeapByteBuffer結(jié)構(gòu).png
現(xiàn)在我們已經(jīng)熟悉了 socket 文件的相關(guān)操作及其在內(nèi)核中的實(shí)現(xiàn),但筆者覺得這還不夠,還是有必要在為大家介紹一下 JDK NIO 如何利用 ByteBuffer 對(duì)普通文件進(jìn)行讀寫的相關(guān)原理及其實(shí)現(xiàn),為大家徹底打通 Linux 文件操作相關(guān)知識(shí)的系統(tǒng)脈絡(luò),于是就有了本文的內(nèi)容。
下面就讓我們從一個(gè)普通的 IO 讀寫操作開始聊起吧~~~

本文概要.png
2. JDK NIO 讀取普通文件
我們先來看一個(gè)利用 NIO FileChannel 來讀寫普通文件的例子,由這個(gè)簡(jiǎn)單的例子開始,慢慢地來一步一步深入本質(zhì)。
JDK NIO 中的 FileChannel 比較特殊,它只能是阻塞的,不能設(shè)置非阻塞模式。FileChannel的讀寫方法均是線程安全的。
注意:下面的例子并不是最佳實(shí)踐,之所以這里引入 HeapByteBuffer 是為了將上篇文章的內(nèi)容和本文銜接起來。事實(shí)上,對(duì)于 IO 的操作一般都會(huì)選擇 DirectByteBuffer ,關(guān)于 DirectByteBuffer 的相關(guān)內(nèi)容筆者會(huì)在后面的文章中詳細(xì)為大家介紹。
FileChannelfileChannel=newRandomAccessFile(newFile("file-read-write.txt"),"rw").getChannel();
ByteBufferheapByteBuffer=ByteBuffer.allocate(4096);
fileChannel.read(heapByteBuffer);
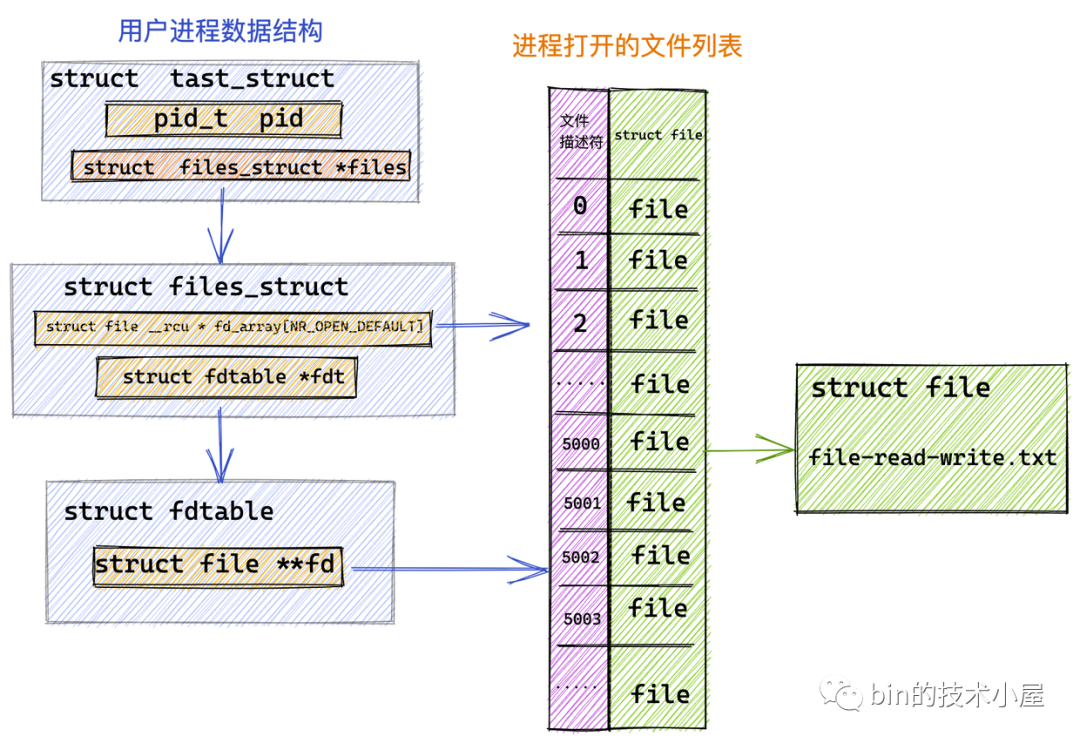
我們首先利用 RandomAccessFile 在內(nèi)核中打開指定的文件 file-read-write.txt 并獲取到它的文件描述符 fd = 5000。
隨后我們?cè)?JVM 堆中開辟一塊 4k 大小的虛擬內(nèi)存 heapByteBuffer,用來讀取文件中的數(shù)據(jù)。
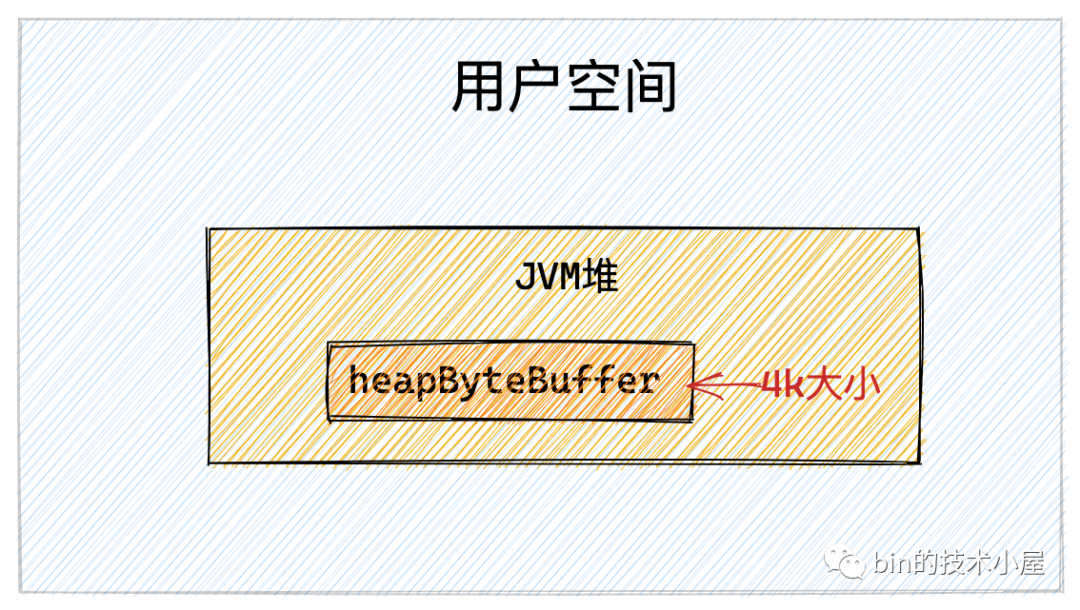
操作系統(tǒng)在管理內(nèi)存的時(shí)候是將內(nèi)存分為一頁(yè)一頁(yè)來管理的,每頁(yè)大小為 4k ,我們?cè)诓僮鲀?nèi)存的時(shí)候一定要記得進(jìn)行頁(yè)對(duì)齊,也就是偏移位置以及讀取的內(nèi)存大小需要按照 4k 進(jìn)行對(duì)齊。具體為什么?文章后邊會(huì)從內(nèi)核角度詳細(xì)為大家介紹。
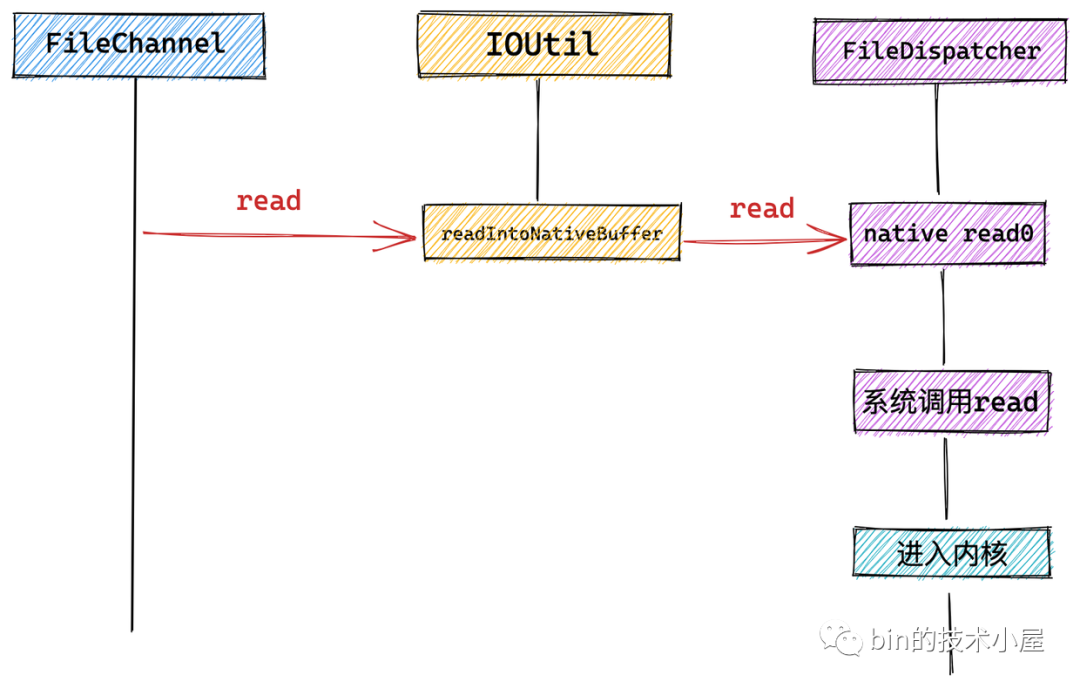
最后通過 FileChannel#read 方法觸發(fā)底層系統(tǒng)調(diào)用 read。進(jìn)行文件讀取。
publicclassFileChannelImplextendsFileChannel{ //前邊介紹打開的文件描述符5000 privatefinalFileDescriptorfd; //NIO中用它來觸發(fā)nativeread和write的系統(tǒng)調(diào)用 privatefinalFileDispatchernd; //讀寫文件時(shí)加鎖,前邊介紹FileChannel的讀寫方法均是線程安全的 privatefinalObjectpositionLock=newObject(); publicintread(ByteBufferdst)throwsIOException{ synchronized(positionLock){ ..........省略....... try{ ..........省略....... do{ n=IOUtil.read(fd,dst,-1,nd); }while((n==IOStatus.INTERRUPTED)&&isOpen()); returnIOStatus.normalize(n); }finally{ ..........省略....... } } } }
我們看到在 FileChannel 中會(huì)調(diào)用 IOUtil 的 read 方法,NIO 中的所有 IO 操作全部封裝在 IOUtil 類中。
而 NIO 中的 SocketChannel 以及這里介紹的 FileChannel 底層依賴的系統(tǒng)調(diào)用可能不同,這里會(huì)通過 NativeDispatcher 對(duì)具體 Channel 操作實(shí)現(xiàn)分發(fā),調(diào)用具體的系統(tǒng)調(diào)用。對(duì)于 FileChannel 來說 NativeDispatcher 的實(shí)現(xiàn)類為 FileDispatcher。對(duì)于 SocketChannel 來說 NativeDispatcher 的實(shí)現(xiàn)類為 SocketDispatcher。
下面我們進(jìn)入 IOUtil 里面來一探究竟~~
publicclassIOUtil{
staticintread(FileDescriptorfd,ByteBufferdst,longposition,
NativeDispatchernd)
throwsIOException
{
..........省略.......
....創(chuàng)建一個(gè)臨時(shí)的directByteBuffer....
try{
intn=readIntoNativeBuffer(fd,directByteBuffer,position,nd);
..........省略.......
....將directByteBuffer中讀取到的內(nèi)容再次拷貝到heapByteBuffer中給用戶返回....
returnn;
}finally{
..........省略.......
}
}
privatestaticintreadIntoNativeBuffer(FileDescriptorfd,ByteBufferbb,
longposition,NativeDispatchernd)
throwsIOException
{
intpos=bb.position();
intlim=bb.limit();
assert(pos<=?lim);
????????int?rem?=?(pos?<=?lim???lim?-?pos?:?0);
????????..........?省略?.......
????????if?(position?!=?-1)?{
??????????..........?省略?.......
????????}?else?{
????????????n?=?nd.read(fd,?((DirectBuffer)bb).address()?+?pos,?rem);
????????}
????????if?(n?>0)
bb.position(pos+n);
returnn;
}
}
我們看到 FileChannel 的 read 方法最終會(huì)調(diào)用到 NativeDispatcher 的 read 方法。前邊我們介紹了這里的 NativeDispatcher 就是 FileDispatcher 在 NIO 中的實(shí)現(xiàn)類為 FileDispatcherImpl,用來觸發(fā) native 方法執(zhí)行底層系統(tǒng)調(diào)用。
classFileDispatcherImplextendsFileDispatcher{
intread(FileDescriptorfd,longaddress,intlen)throwsIOException{
returnread0(fd,address,len);
}
staticnativeintread0(FileDescriptorfd,longaddress,intlen)
throwsIOException;
}
最終在 FileDispatcherImpl 類中觸發(fā)了 native 方法 read0 的調(diào)用,我們繼續(xù)到 FileDispatcherImpl.c 文件中去查看 native 方法的實(shí)現(xiàn)。
//FileDispatcherImpl.c文件 JNIEXPORTjintJNICALLJava_sun_nio_ch_FileDispatcherImpl_read0(JNIEnv*env,jclassclazz, jobjectfdo,jlongaddress,jintlen) { jintfd=fdval(env,fdo); void*buf=(void*)jlong_to_ptr(address); //發(fā)起read系統(tǒng)調(diào)用進(jìn)入內(nèi)核 returnconvertReturnVal(env,read(fd,buf,len),JNI_TRUE); }
系統(tǒng)調(diào)用 read(fd, buf, len) 最終是在 native 方法 read0 中被觸發(fā)的。下面是系統(tǒng)調(diào)用 read 在內(nèi)核中的定義。
SYSCALL_DEFINE3(read,unsignedint,fd,char__user*,buf,size_t,count){
......省略......
}
這樣一來我們就從 JDK NIO 這一層逐步來到了用戶空間與內(nèi)核空間的邊界處 --- OS 系統(tǒng)調(diào)用 read 這里,馬上就要進(jìn)入內(nèi)核了。
下面我們就來看一下當(dāng)系統(tǒng)調(diào)用 read 發(fā)起之后,用戶進(jìn)程在內(nèi)核態(tài)具體做了哪些事情?
3. 從內(nèi)核角度探秘文件讀取本質(zhì)
內(nèi)核將文件的 IO 操作根據(jù)是否使用內(nèi)存(頁(yè)高速緩存 page cache)做磁盤熱點(diǎn)數(shù)據(jù)的緩存,將文件 IO 分為:Buffered IO 和 Direct IO 兩種類型。
進(jìn)程在通過系統(tǒng)調(diào)用 open() 打開文件的時(shí)候,可以通過將參數(shù) flags 賦值為 O_DIRECT 來指定文件操作為 Direct IO。默認(rèn)情況下為 Buffered IO。
intopen(constchar*pathname,intflags,mode_tmode);
而 Java 在 JDK 10 之前一直是不支持 Direct IO 的,到了 JDK 10 才開始支持 Direct IO。但是在 JDK 10 之前我們可以使用第三方的 Direct IO 框架 Jaydio 來通過 Direct IO 的方式對(duì)文件進(jìn)行讀寫操作。
Jaydio GitHub :https://github.com/smacke/jaydio
下面筆者就帶大家從內(nèi)核角度深度剖析下這兩種 IO 類型各自的特點(diǎn):
3.1 Buffered IO
大部分文件系統(tǒng)默認(rèn)的文件 IO 類型為 Buffered IO,當(dāng)進(jìn)程進(jìn)行文件讀取時(shí),內(nèi)核會(huì)首先檢查文件對(duì)應(yīng)的頁(yè)高速緩存 page cache 中是否已經(jīng)緩存了文件數(shù)據(jù),如果有則直接返回,如果沒有才會(huì)去磁盤中去讀取文件數(shù)據(jù),而且還會(huì)根據(jù)非常精妙的預(yù)讀算法來預(yù)先讀取后續(xù)若干文件數(shù)據(jù)到 page cache 中。這樣等進(jìn)程下一次順序讀取文件時(shí),想要的數(shù)據(jù)已經(jīng)預(yù)讀進(jìn) page cache 中了,進(jìn)程直接返回,不用再到磁盤中去龜速讀取了,這樣一來就極大地提高了 IO 性能。
比如一些著名的消息隊(duì)列中間件 Kafka , RocketMq 對(duì)消息日志文件進(jìn)行順序讀取的時(shí)候,訪問速度接近于內(nèi)存。這就是 Buffered IO 中頁(yè)高速緩存 page cache 的功勞。在本文的后面,筆者會(huì)為大家詳細(xì)的介紹這一部分內(nèi)容。
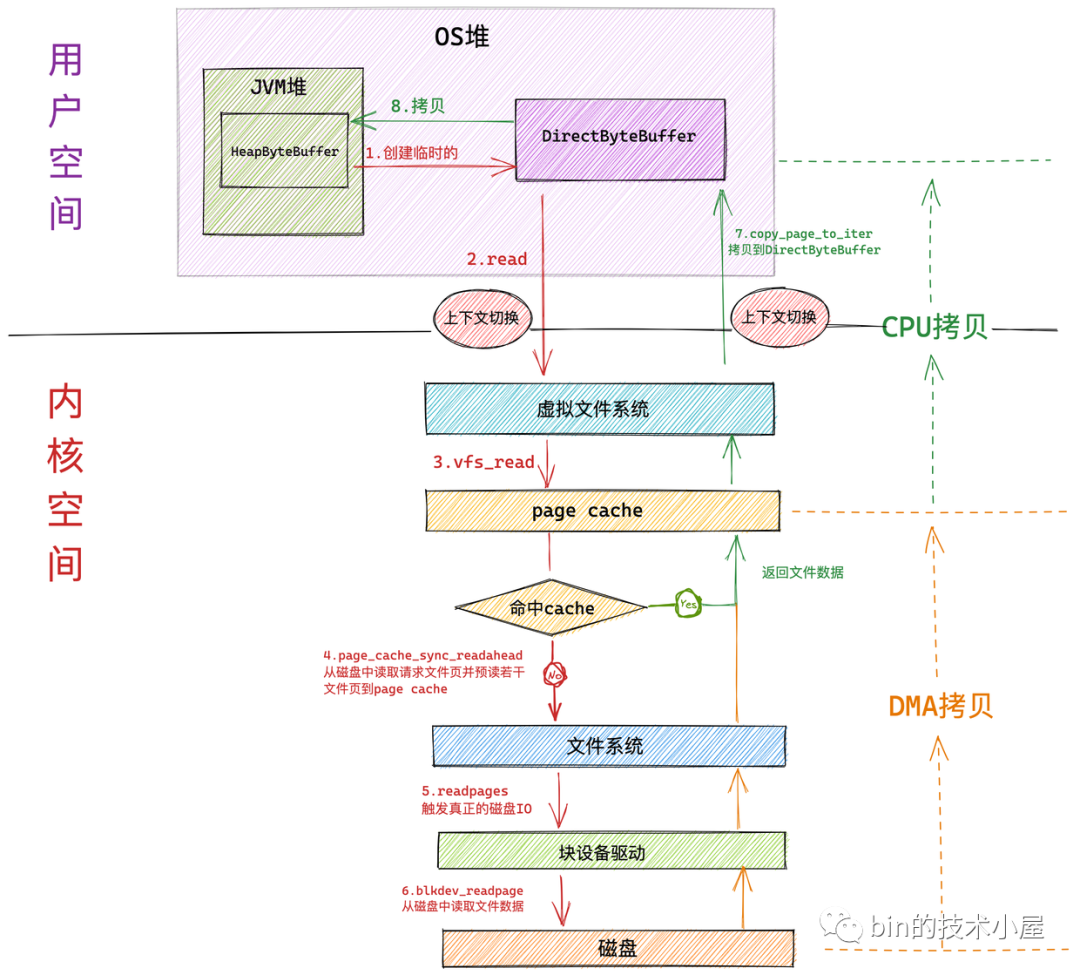
如果我們使用在上篇文章 《一步一圖帶你深入剖析 JDK NIO ByteBuffer 在不同字節(jié)序下的設(shè)計(jì)與實(shí)現(xiàn)》 中介紹的 HeapByteBuffer 來接收 NIO 讀取文件數(shù)據(jù)的時(shí)候,整個(gè)文件讀取的過程分為如下幾個(gè)步驟:
NIO 首先會(huì)將創(chuàng)建一個(gè)臨時(shí)的 DirectByteBuffer 用于臨時(shí)接收文件數(shù)據(jù)。
具體為什么會(huì)創(chuàng)建一個(gè)臨時(shí)的 DirectByteBuffer 來接收數(shù)據(jù)以及關(guān)于 DirectByteBuffer 的原理筆者會(huì)在后面的文章中為大家詳細(xì)介紹。這里大家可以把它簡(jiǎn)單看成在 OS 堆中的一塊虛擬內(nèi)存地址。
隨后 NIO 會(huì)在用戶態(tài)調(diào)用系統(tǒng)調(diào)用 read 向內(nèi)核發(fā)起文件讀取的請(qǐng)求。此時(shí)發(fā)生第一次上下文切換。
用戶進(jìn)程隨即轉(zhuǎn)到內(nèi)核態(tài)運(yùn)行,進(jìn)入虛擬文件系統(tǒng)層,在這一層內(nèi)核首先會(huì)查看讀取文件對(duì)應(yīng)的頁(yè)高速緩存 page cache 中是否含有請(qǐng)求的文件數(shù)據(jù),如果有直接返回,避免一次磁盤 IO。并根據(jù)內(nèi)核預(yù)讀算法從磁盤中異步預(yù)讀若干文件數(shù)據(jù)到 page cache 中(文件順序讀取高性能的關(guān)鍵所在)。
在內(nèi)核中,一個(gè)文件對(duì)應(yīng)一個(gè) page cache 結(jié)構(gòu),注意:這個(gè) page cache 在內(nèi)存中只會(huì)有一份。
如果進(jìn)程請(qǐng)求數(shù)據(jù)不在 page cache 中,則會(huì)進(jìn)入文件系統(tǒng)層,在這一層調(diào)用塊設(shè)備驅(qū)動(dòng)程序觸發(fā)真正的磁盤 IO。并根據(jù)內(nèi)核預(yù)讀算法同步預(yù)讀若干文件數(shù)據(jù)。請(qǐng)求的文件數(shù)據(jù)和預(yù)讀的文件數(shù)據(jù)將被一起填充到 page cache 中。
在塊設(shè)備驅(qū)動(dòng)層完成真正的磁盤 IO。在這一層會(huì)從磁盤中讀取進(jìn)程請(qǐng)求的文件數(shù)據(jù)以及內(nèi)核預(yù)讀的文件數(shù)據(jù)。
磁盤控制器 DMA 將從磁盤中讀取的數(shù)據(jù)拷貝到頁(yè)高速緩存 page cache 中。發(fā)生第一次數(shù)據(jù)拷貝。
隨后 CPU 將 page cache 中的數(shù)據(jù)拷貝到 NIO 在用戶空間臨時(shí)創(chuàng)建的緩沖區(qū) DirectByteBuffer 中,發(fā)生第二次數(shù)據(jù)拷貝。
最后系統(tǒng)調(diào)用 read 返回。進(jìn)程從內(nèi)核態(tài)切換回用戶態(tài)。發(fā)生第二次上下文切換。
NIO 將 DirectByteBuffer 中臨時(shí)存放的文件數(shù)據(jù)拷貝到 JVM 堆中的 HeapBytebuffer 中。發(fā)生第三次數(shù)據(jù)拷貝。
我們看到如果使用 HeapByteBuffer 進(jìn)行 NIO 文件讀取的整個(gè)過程中,一共發(fā)生了 兩次上下文切換和三次數(shù)據(jù)拷貝,如果請(qǐng)求的數(shù)據(jù)命中 page cache 則發(fā)生兩次數(shù)據(jù)拷貝省去了一次磁盤的 DMA 拷貝。
3.2 Direct IO
在上一小節(jié)中,筆者介紹了 Buffered IO 的諸多好處,尤其是在進(jìn)程對(duì)文件進(jìn)行順序讀取的時(shí)候,訪問性能接近于內(nèi)存。
但是有些情況,我們并不需要 page cache。比如一些高性能的數(shù)據(jù)庫(kù)應(yīng)用程序,它們?cè)谟脩艨臻g自己實(shí)現(xiàn)了一套高效的高速緩存機(jī)制,以充分挖掘?qū)?shù)據(jù)庫(kù)獨(dú)特的查詢?cè)L問性能。所以這些數(shù)據(jù)庫(kù)應(yīng)用程序并不希望內(nèi)核中的 page cache起作用。否則內(nèi)核會(huì)同時(shí)處理 page cache 以及預(yù)讀相關(guān)操作的指令,會(huì)使得性能降低。
另外還有一種情況是,當(dāng)我們?cè)陔S機(jī)讀取文件的時(shí)候,也不希望內(nèi)核使用 page cache。因?yàn)檫@樣違反了程序局部性原理,當(dāng)我們隨機(jī)讀取文件的時(shí)候,內(nèi)核預(yù)讀進(jìn) page cache 中的數(shù)據(jù)將很久不會(huì)再次得到訪問,白白浪費(fèi) page cache 空間不說,還額外增加了預(yù)讀的磁盤 IO。
基于以上兩點(diǎn)原因,我們很自然的希望內(nèi)核能夠提供一種機(jī)制可以繞過 page cache 直接對(duì)磁盤進(jìn)行讀寫操作。這種機(jī)制就是本小節(jié)要為大家介紹的 Direct IO。
下面是內(nèi)核采用 Direct IO 讀取文件的工作流程:
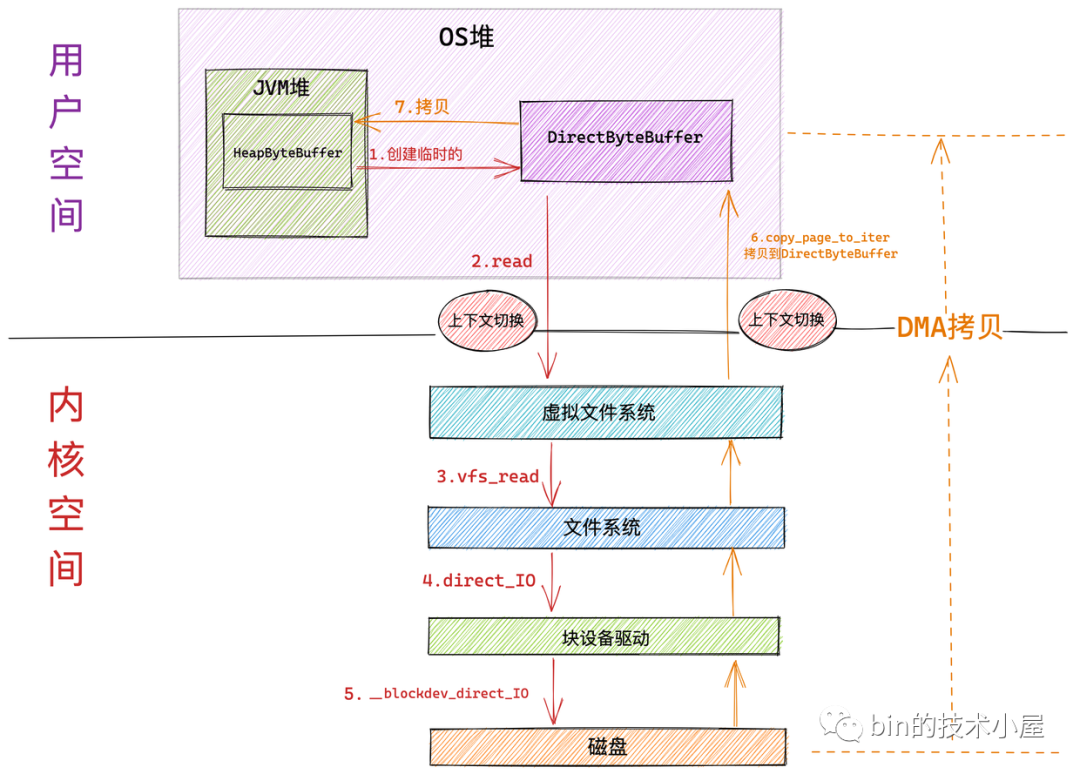
Direct IO 和 Buffered IO 在進(jìn)入內(nèi)核虛擬文件系統(tǒng)層之前的流程全部都是一樣的。區(qū)別就是進(jìn)入到虛擬文件系統(tǒng)層之后,Direct IO 會(huì)繞過 page cache 直接來到文件系統(tǒng)層通過 direct_io 調(diào)用來到塊驅(qū)動(dòng)設(shè)備層,在塊設(shè)備驅(qū)動(dòng)層調(diào)用 __blockdev_direct_IO 對(duì)磁盤內(nèi)容直接進(jìn)行讀寫。
和 Buffered IO 一樣,在系統(tǒng)調(diào)用 read 進(jìn)入內(nèi)核以及 Direct IO 完成從內(nèi)核返回的時(shí)候各自會(huì)發(fā)生一次上下文切換。共兩次上下文切換
磁盤控制器 DMA 從磁盤中讀取數(shù)據(jù)后直接拷貝到用戶空間緩沖區(qū) DirectByteBuffer 中。只發(fā)生一次 DMA 拷貝
隨后 NIO 將 DirectByteBuffer 中臨時(shí)存放的數(shù)據(jù)拷貝到 JVM 堆 HeapByteBuffer 中。發(fā)生第二次數(shù)據(jù)拷貝。
注意塊設(shè)備驅(qū)動(dòng)層的 __blockdev_direct_IO 需要等到所有的 Direct IO 傳送數(shù)據(jù)完成之后才會(huì)返回,這里的傳送指的是直接從磁盤拷貝到用戶空間緩沖區(qū)中,當(dāng) Direct IO 模式下的 read() 或者 write() 系統(tǒng)調(diào)用返回之后,進(jìn)程就可以安全放心地去讀取用戶緩沖區(qū)中的數(shù)據(jù)了。
從整個(gè) Direct IO 的過程中我們看到,一共發(fā)生了兩次上下文的切換,兩次的數(shù)據(jù)拷貝。
4. Talk is cheap ! show you the code
下面是系統(tǒng)調(diào)用 read 在內(nèi)核中的完整定義:
SYSCALL_DEFINE3(read,unsignedint,fd,char__user*,buf,size_t,count){
//根據(jù)文件描述符獲取文件對(duì)應(yīng)的structfile結(jié)構(gòu)
structfdf=fdget_pos(fd);
.....
//獲取當(dāng)前文件的讀取位置offset
loff_tpos=file_pos_read(f.file);
//進(jìn)入虛擬文件系統(tǒng)層,執(zhí)行具體的文件操作
ret=vfs_read(f.file,buf,count,&pos);
......
}
首先會(huì)根據(jù)文件描述符 fd 通過 fdget_pos 方法獲取 struct fd 結(jié)構(gòu),進(jìn)而可以獲取到文件的 struct file 結(jié)構(gòu)。
structfd{
structfile*file;
intneed_put;
};
file_pos_read 獲取當(dāng)前文件的讀取位置 offset,并通過 vfs_read 進(jìn)入虛擬文件系統(tǒng)層。
ssize_t__vfs_read(structfile*file,char__user*buf,size_tcount,loff_t*pos){
if(file->f_op->read)
returnfile->f_op->read(file,buf,count,pos);
elseif(file->f_op->read_iter)
returnnew_sync_read(file,buf,count,pos);
else
return-EINVAL;
}
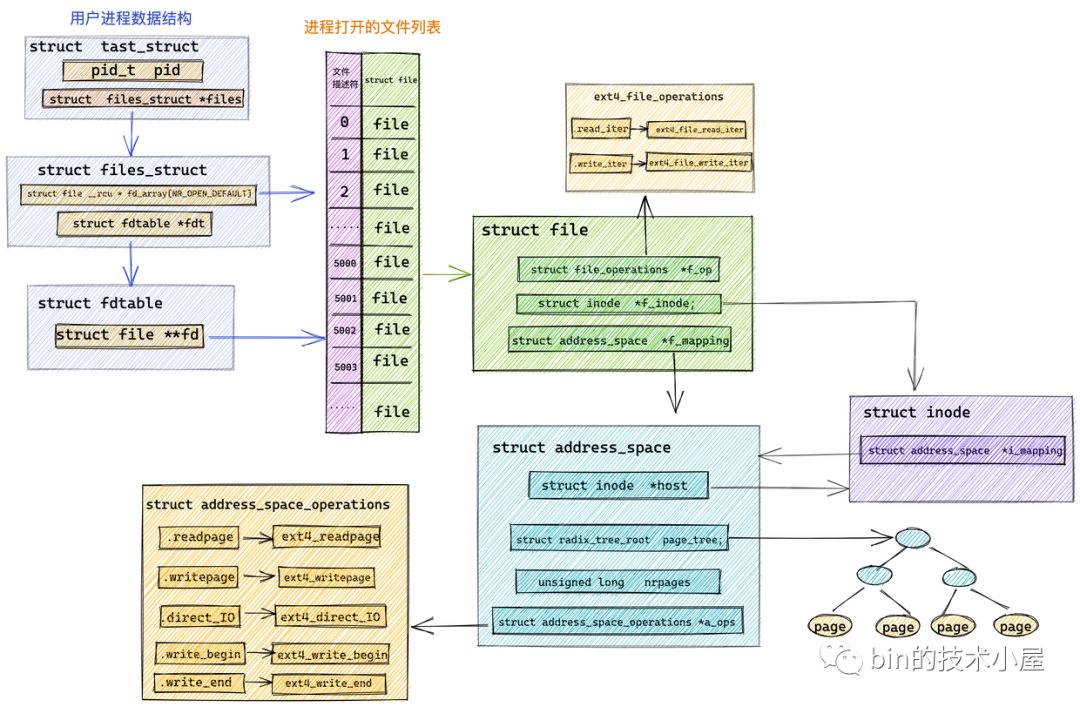
這里我們看到內(nèi)核對(duì)文件的操作全部定義在 struct file 結(jié)構(gòu)中的 f_op 字段中。
structfile{
conststructfile_operations*f_op;
}
對(duì)于 Java 程序員來說,file_operations 大家可以把它當(dāng)做內(nèi)核針對(duì)文件相關(guān)操作定義的一個(gè)公共接口(其實(shí)就是一個(gè)函數(shù)指針),它只是一個(gè)接口。具體的實(shí)現(xiàn)根據(jù)不同的文件類型有所不同。
比如我們?cè)凇读牧腘etty那些事兒之從內(nèi)核角度看IO模型》一文中詳細(xì)介紹過的 Socket 文件。針對(duì) Socket 文件類型,這里的 file_operations 指向的是 socket_file_ops。
staticconststructfile_operationssocket_file_ops={
.owner=THIS_MODULE,
.llseek=no_llseek,
.read_iter=sock_read_iter,
.write_iter=sock_write_iter,
.poll=sock_poll,
.unlocked_ioctl=sock_ioctl,
.mmap=sock_mmap,
.release=sock_close,
.fasync=sock_fasync,
.sendpage=sock_sendpage,
.splice_write=generic_splice_sendpage,
.splice_read=sock_splice_read,
};
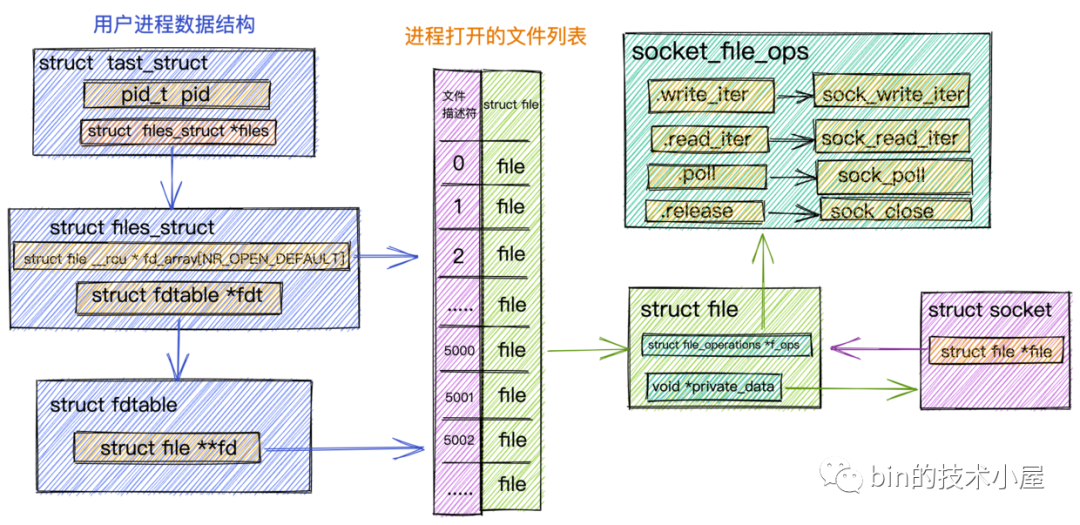
進(jìn)程中管理文件列表結(jié)構(gòu).png
而本小節(jié)中我們討論的是對(duì)普通文件的操作,針對(duì)普通文件的操作定義在具體的文件系統(tǒng)中,這里我們以 Linux 中最為常見的 ext4 文件系統(tǒng)為例說明:
在 ext4 文件系統(tǒng)中管理的文件對(duì)應(yīng)的 file_operations 指向 ext4_file_operations,專門用于操作 ext4 文件系統(tǒng)中的文件。
conststructfile_operationsext4_file_operations={
......省略........
.read_iter=ext4_file_read_iter,
.write_iter=ext4_file_write_iter,
......省略.........
}
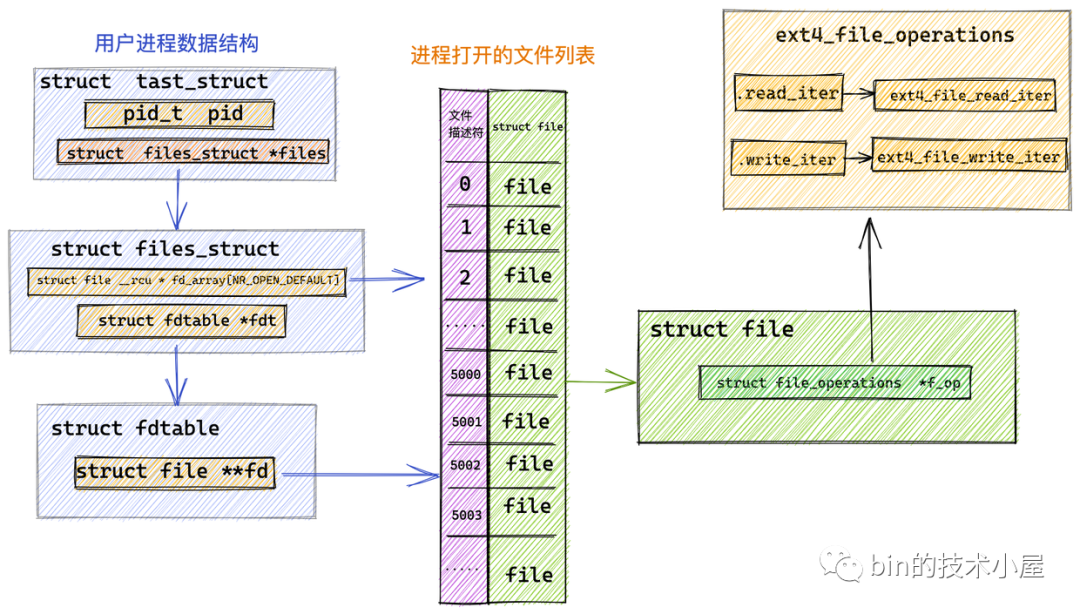
從圖中我們可以看到 ext4 文件系統(tǒng)定義的相關(guān)文件操作 ext4_file_operations 并未定義 .read 函數(shù)指針。而是定義了 .read_iter 函數(shù)指針,指向 ext4_file_read_iter 函數(shù)。
ssize_t__vfs_read(structfile*file,char__user*buf,size_tcount,loff_t*pos){
if(file->f_op->read)
returnfile->f_op->read(file,buf,count,pos);
elseif(file->f_op->read_iter)
returnnew_sync_read(file,buf,count,pos);
else
return-EINVAL;
}
所以在虛擬文件系統(tǒng) VFS 中,__vfs_read 調(diào)用的是 new_sync_read 方法,在該方法中會(huì)對(duì)系統(tǒng)調(diào)用傳進(jìn)來的參數(shù)進(jìn)行重新封裝。比如:
struct file *filp :要讀取文件的 struct file 結(jié)構(gòu)。
char __user *buf :用戶空間的 Buffer,這里指的我們例子中 NIO 創(chuàng)建的臨時(shí) DirectByteBuffer。
size_t count :進(jìn)行讀取的字節(jié)數(shù)。也就是我們傳入的用戶態(tài)緩沖區(qū) DirectByteBuffer 剩余可容納的容量大小。
loff_t *pos :文件當(dāng)前讀取位置偏移 offset。
將這些參數(shù)重新封裝到 struct iovec 和 struct kiocb 結(jié)構(gòu)體中。
ssize_tnew_sync_read(structfile*filp,char__user*buf,size_tlen,loff_t*ppos)
{
//將DirectByteBuffer以及要讀取的字節(jié)數(shù)封裝進(jìn)iovec結(jié)構(gòu)體中
structioveciov={.iov_base=buf,.iov_len=len};
structkiocbkiocb;
structiov_iteriter;
ssize_tret;
//利用文件structfile初始化kiocb結(jié)構(gòu)體
init_sync_kiocb(&kiocb,filp);
//設(shè)置文件讀取偏移
kiocb.ki_pos=*ppos;
//讀取文件字節(jié)數(shù)
kiocb.ki_nbytes=len;
//初始化iov_iter結(jié)構(gòu)
iov_iter_init(&iter,READ,&iov,1,len);
//最終調(diào)用ext4_file_read_iter
ret=filp->f_op->read_iter(&kiocb,&iter);
.......省略......
returnret;
}
struct iovec 結(jié)構(gòu)體主要用來封裝用來接收文件數(shù)據(jù)用的用戶緩存區(qū)相關(guān)的信息:
structiovec
{
void__user*iov_base;//用戶空間緩存區(qū)地址這里是DirectByteBuffer的地址
__kernel_size_tiov_len;//緩沖區(qū)長(zhǎng)度
}
但是內(nèi)核中一般會(huì)使用 struct iov_iter 結(jié)構(gòu)體對(duì) struct iovec 進(jìn)行包裝,iov_iter 中可以包含多個(gè) iovec。這一點(diǎn)從 struct iov_iter 結(jié)構(gòu)體的命名關(guān)鍵字 iter 上可以看得出來。
structiov_iter{
......省略.....
conststructiovec*iov;
}
之所以使用 struct iov_iter 結(jié)構(gòu)體來包裝 struct iovec 是為了兼容 readv() 系統(tǒng)調(diào)用,它允許用戶使用多個(gè)用戶緩存區(qū)去讀取文件中的數(shù)據(jù)。JDK NIO Channel 支持的 scatter 操作底層原理就是 readv 系統(tǒng)調(diào)用。
FileChannelfileChannel=newRandomAccessFile(newFile("file-read-write.txt"),"rw").getChannel();
ByteBufferheapByteBuffer1=ByteBuffer.allocate(4096);
ByteBufferheapByteBuffer2=ByteBuffer.allocate(4096);
ByteBuffer[]scatter={heapByteBuffer1,heapByteBuffer2};
fileChannel.read(scatter);
struct kiocb 結(jié)構(gòu)體則是用來封裝文件 IO 相關(guān)操作的狀態(tài)和進(jìn)度信息:
structkiocb{
structfile*ki_filp;//要讀取的文件structfile結(jié)構(gòu)
loff_tki_pos;//文件讀取位置偏移,表示文件處理進(jìn)度
void(*ki_complete)(structkiocb*iocb,longret);//IO完成回調(diào)
intki_flags;//IO類型,比如是DirectIO還是BufferedIO
........省略.......
};
當(dāng) struct iovec 和 struct kiocb 在 new_sync_read 方法中被初始化好之后,最終通過 file_operations 中定義的函數(shù)指針 .read_iter 調(diào)用到 ext4_file_read_iter 方法中,從而進(jìn)入 ext4 文件系統(tǒng)執(zhí)行具體的讀取操作。
staticssize_text4_file_read_iter(structkiocb*iocb,structiov_iter*to)
{
........省略........
returngeneric_file_read_iter(iocb,to);
}
ssize_tgeneric_file_read_iter(structkiocb*iocb,structiov_iter*iter)
{
........省略........
if(iocb->ki_flags&IOCB_DIRECT){
........DirectIO........
//獲取pagecache
structaddress_space*mapping=file->f_mapping;
........省略........
//繞過pagecache直接從磁盤中讀取數(shù)據(jù)
retval=mapping->a_ops->direct_IO(iocb,iter);
}
........BufferedIO........
//從pagecache中讀取數(shù)據(jù)
retval=generic_file_buffered_read(iocb,iter,retval);
}
generic_file_read_iter 會(huì)根據(jù) struct kiocb 中的 ki_flags 屬性判斷文件 IO 操作是 Direct IO 還是 Buffered IO。
4.1 Direct IO
我們可以通過 open 系統(tǒng)調(diào)用在打開文件的時(shí)候指定相關(guān) IO 操作的模式是 Direct IO 還是 Buffered IO:
intopen(constchar*pathname,intflags,mode_tmode);
char *pathname :指定要文件的路徑。
int flags :指定文件的訪問模式。比如:O_RDONLY(只讀),O_WRONLY,(只寫), O_RDWR(讀寫),O_DIRECT(Direct IO)。默認(rèn)為 Buffered IO。
mode_t mode :可選,指定打開文件的權(quán)限
而 Java 在 JDK 10 之前一直是不支持 Direct IO,到了 JDK 10 才開始支持 Direct IO。
Pathpath=Paths.get("file-read-write.txt");
FileChannel fc = FileChannel.open(p, ExtendedOpenOption.DIRECT);
如果在文件打開的時(shí)候,我們?cè)O(shè)置了 Direct IO 模式,那么以后在對(duì)文件進(jìn)行讀取的過程中,內(nèi)核將會(huì)繞過 page cache,直接從磁盤中讀取數(shù)據(jù)到用戶空間緩沖區(qū) DirectByteBuffer 中。這樣就可以避免一次數(shù)據(jù)從內(nèi)核 page cache 到用戶空間緩沖區(qū)的拷貝。
當(dāng)應(yīng)用程序期望使用自定義的緩存算法從而可以在用戶空間實(shí)現(xiàn)更加高效更加可控的緩存邏輯時(shí)(比如數(shù)據(jù)庫(kù)等應(yīng)用程序),這時(shí)應(yīng)該使用直接 Direct IO。在隨機(jī)讀取,隨機(jī)寫入的場(chǎng)景中也是比較適合用 Direct IO。
操作系統(tǒng)進(jìn)程在接下來使用 read() 或者 write() 系統(tǒng)調(diào)用去讀寫文件的時(shí)候使用的是 Direct IO 方式,所傳輸?shù)臄?shù)據(jù)均不經(jīng)過文件對(duì)應(yīng)的高速緩存 page cache (這里就是網(wǎng)上常說的內(nèi)核緩沖區(qū))。
我們都知道操作系統(tǒng)是將內(nèi)存分為一頁(yè)一頁(yè)的單位進(jìn)行組織管理的,每頁(yè)大小 4K ,那么同樣文件中的數(shù)據(jù)在磁盤中的組織形式也是按照一塊一塊的單位來組織管理的,每塊大小也是 4K ,所以我們?cè)谑褂?Direct IO 讀寫數(shù)據(jù)時(shí)必須要按照文件在磁盤中的組織單位進(jìn)行磁盤塊大小對(duì)齊,緩沖區(qū)的大小也必須是磁盤塊大小的整數(shù)倍。具體表現(xiàn)在如下幾點(diǎn):
文件的讀寫位置偏移需要按照磁盤塊大小對(duì)齊。
用戶緩沖區(qū) DirectByteBuffer 起始地址需要按照磁盤塊大小對(duì)齊。
使用 Direct IO 進(jìn)行數(shù)據(jù)讀寫時(shí),讀寫的數(shù)據(jù)大小需要按照磁盤塊大小進(jìn)行對(duì)齊。這里指 DirectByteBuffer 中剩余數(shù)據(jù)的大小。
當(dāng)我們采用 Direct IO 直接讀取磁盤中的文件數(shù)據(jù)時(shí),內(nèi)核會(huì)從 struct file 結(jié)構(gòu)中獲取到該文件在內(nèi)存中的 page cache。而我們多次提到的這個(gè) page cache 在內(nèi)核中的數(shù)據(jù)結(jié)構(gòu)就是 struct address_space 。我們可以根據(jù) file->f_mapping 獲取。
structfile{
//pagecache
structaddress_space*f_mapping;
}
和前面我們介紹的 struct file 結(jié)構(gòu)中的 file_operations 一樣,內(nèi)核中將 page cache 相關(guān)的操作全部定義在 struct address_space_operations 結(jié)構(gòu)中。這里和前邊介紹的 file_operations 的作用是一樣的,只是內(nèi)核針對(duì) page cache 操作定義的一個(gè)公共接口。
structaddress_space{
conststructaddress_space_operations*a_ops;
}
具體的實(shí)現(xiàn)會(huì)根據(jù)文件系統(tǒng)的不同而不同,這里我們還是以 ext4 文件系統(tǒng)為例:
staticconststructaddress_space_operationsext4_aops={
.direct_IO=ext4_direct_IO,
};
內(nèi)核通過 struct address_space_operations 結(jié)構(gòu)中定義的 .direct_IO 函數(shù)指針,具體函數(shù)為 ext4_direct_IO 來繞過 page cache 直接對(duì)磁盤進(jìn)行讀寫。
采用 Direct IO 的方式對(duì)文件的讀寫操作全部是在 ext4_direct_IO 這一個(gè)函數(shù)中完成的。
由于磁盤文件中的數(shù)據(jù)是按照塊為單位來組織管理的,所以文件系統(tǒng)其實(shí)就是一個(gè)塊設(shè)備,通過 ext4_direct_IO 繞過 page cache 直接來到了文件系統(tǒng)的塊設(shè)備驅(qū)動(dòng)層,最終在塊設(shè)備驅(qū)動(dòng)層調(diào)用 __blockdev_direct_IO 來完成磁盤的讀寫操作。
注意:塊設(shè)備驅(qū)動(dòng)層的 __blockdev_direct_IO 需要等到所有的 Direct IO 傳送數(shù)據(jù)完成之后才會(huì)返回,這里的傳送指的是直接從磁盤拷貝到用戶空間緩沖區(qū)中,當(dāng) Direct IO 模式下的 read() 或者 write() 系統(tǒng)調(diào)用返回之后,進(jìn)程就可以安全放心地去讀取用戶緩沖區(qū)中的數(shù)據(jù)了。
4.2 Buffered IO
Buffered IO 相關(guān)的讀取操作封裝在 generic_file_buffered_read 函數(shù)中,其核心邏輯如下:
由于文件在磁盤中是以塊為單位組織管理的,每塊大小為 4k,內(nèi)存是按照頁(yè)為單位組織管理的,每頁(yè)大小也是 4k。文件中的塊數(shù)據(jù)被緩存在 page cache 中的緩存頁(yè)中。所以首先通過 find_get_page 方法查找我們要讀取的文件數(shù)據(jù)是否已經(jīng)緩存在了 page cache 中。
如果 page cache 中不存在文件數(shù)據(jù)的緩存頁(yè),就需要通過 page_cache_sync_readahead 方法從磁盤中讀取數(shù)據(jù)并緩存到 page cache 中。于此同時(shí)還需要同步預(yù)讀若干相鄰的數(shù)據(jù)塊到 page cache 中。這樣在下一次順序讀取的時(shí)候,直接就可以從 page cache 中讀取了。
如果此次讀取的文件數(shù)據(jù)已經(jīng)存在于 page cache 中了,就需要調(diào)用 PageReadahead 來判斷是否需要進(jìn)一步預(yù)讀數(shù)據(jù)到緩存頁(yè)中。如果是,則從磁盤中異步預(yù)讀若干頁(yè)到 page cache 中。具體預(yù)讀多少頁(yè)是根據(jù)內(nèi)核相關(guān)預(yù)讀算法來動(dòng)態(tài)調(diào)整的。
經(jīng)過上面幾個(gè)流程,此時(shí)文件數(shù)據(jù)已經(jīng)存在于 page cache 中的緩存頁(yè)中了,最后內(nèi)核調(diào)用 copy_page_to_iter 方法將 page cache 中的數(shù)據(jù)拷貝到用戶空間緩沖區(qū) DirectByteBuffer 中。
staticssize_tgeneric_file_buffered_read(structkiocb*iocb,
structiov_iter*iter,ssize_twritten)
{
//獲取文件在內(nèi)核中對(duì)應(yīng)的structfile結(jié)構(gòu)
structfile*filp=iocb->ki_filp;
//獲取文件對(duì)應(yīng)的pagecache
structaddress_space*mapping=filp->f_mapping;
//獲取文件的inode
structinode*inode=mapping->host;
...........省略...........
//開始BufferedIO讀取邏輯
for(;;){
//用于從pagecache中獲取緩存的文件數(shù)據(jù)page
structpage*page;
//根據(jù)文件讀取偏移計(jì)算出第一個(gè)字節(jié)所在物理頁(yè)的索引
pgoff_tindex;
//根據(jù)文件讀取偏移計(jì)算出第一個(gè)字節(jié)所在物理頁(yè)中的頁(yè)內(nèi)偏移
unsignedlongoffset;
//在pagecache中查找是否有讀取數(shù)據(jù)在內(nèi)存中的緩存頁(yè)
page=find_get_page(mapping,index);
if(!page){
if(iocb->ki_flags&IOCB_NOWAIT){
.......如果設(shè)置的是異步IO,則直接返回-EAGAIN......
}
//要讀取的文件數(shù)據(jù)在pagecache中沒有對(duì)應(yīng)的緩存頁(yè)
//則從磁盤中讀取文件數(shù)據(jù),并同步預(yù)讀若干相鄰的數(shù)據(jù)塊到pagecache中
page_cache_sync_readahead(mapping,
ra,filp,
index,last_index-index);
//再一次觸發(fā)緩存頁(yè)的查找,這一次就可以找到了
page=find_get_page(mapping,index);
if(unlikely(page==NULL))
gotono_cached_page;
}
//如果讀取的文件數(shù)據(jù)已經(jīng)在pagecache中了,則判斷是否進(jìn)行近一步的預(yù)讀操作
if(PageReadahead(page)){
//異步預(yù)讀若干文件數(shù)據(jù)塊到pagecache中
page_cache_async_readahead(mapping,
ra,filp,page,
index,last_index-index);
}
..............省略..............
//將pagecache中的數(shù)據(jù)拷貝到用戶空間緩沖區(qū)DirectByteBuffer中
ret=copy_page_to_iter(page,offset,nr,iter);
}
}
到這里關(guān)于文件讀取的兩種模式 Buffered IO 和 Direct IO 在內(nèi)核中的主干邏輯流程筆者就為大家介紹完了。
但是大家可能會(huì)對(duì) Buffered IO 中的兩個(gè)細(xì)節(jié)比較感興趣:
如何在 page cache 中查找我們要讀取的文件數(shù)據(jù) ?也就是說上面提到的 find_get_page 函數(shù)是如何實(shí)現(xiàn)的?
文件預(yù)讀的過程是怎么樣的??jī)?nèi)核中的預(yù)讀算法又是什么樣的呢?
在為大家解答這兩個(gè)疑問之前,筆者先為大家介紹一下內(nèi)核中的頁(yè)高速緩存 page cache。
5. 頁(yè)高速緩存 page cache
筆者在《一文聊透對(duì)象在 JVM 中的內(nèi)存布局,以及內(nèi)存對(duì)齊和壓縮指針的原理及應(yīng)用》 文章中為大家介紹 CPU 的高速緩存時(shí)曾提到過,根據(jù)摩爾定律:芯片中的晶體管數(shù)量每隔 18 個(gè)月就會(huì)翻一番。導(dǎo)致 CPU 的性能和處理速度變得越來越快,而提升 CPU 的運(yùn)行速度比提升內(nèi)存的運(yùn)行速度要容易和便宜的多,所以就導(dǎo)致了 CPU 與內(nèi)存之間的速度差距越來越大。
CPU 與內(nèi)存之間的速度差異到底有多大呢?我們知道寄存器是離 CPU 最近的,CPU 在訪問寄存器的時(shí)候速度近乎于 0 個(gè)時(shí)鐘周期,訪問速度最快,基本沒有時(shí)延。而訪問內(nèi)存則需要 50 - 200 個(gè)時(shí)鐘周期。
所以為了彌補(bǔ) CPU 與內(nèi)存之間巨大的速度差異,提高 CPU 的處理效率和吞吐,于是我們引入了 L1 , L2 , L3 高速緩存集成到 CPU 中。CPU 訪問高速緩存僅需要用到 1 - 30 個(gè)時(shí)鐘周期,CPU 中的高速緩存是對(duì)內(nèi)存熱點(diǎn)數(shù)據(jù)的一個(gè)緩存。
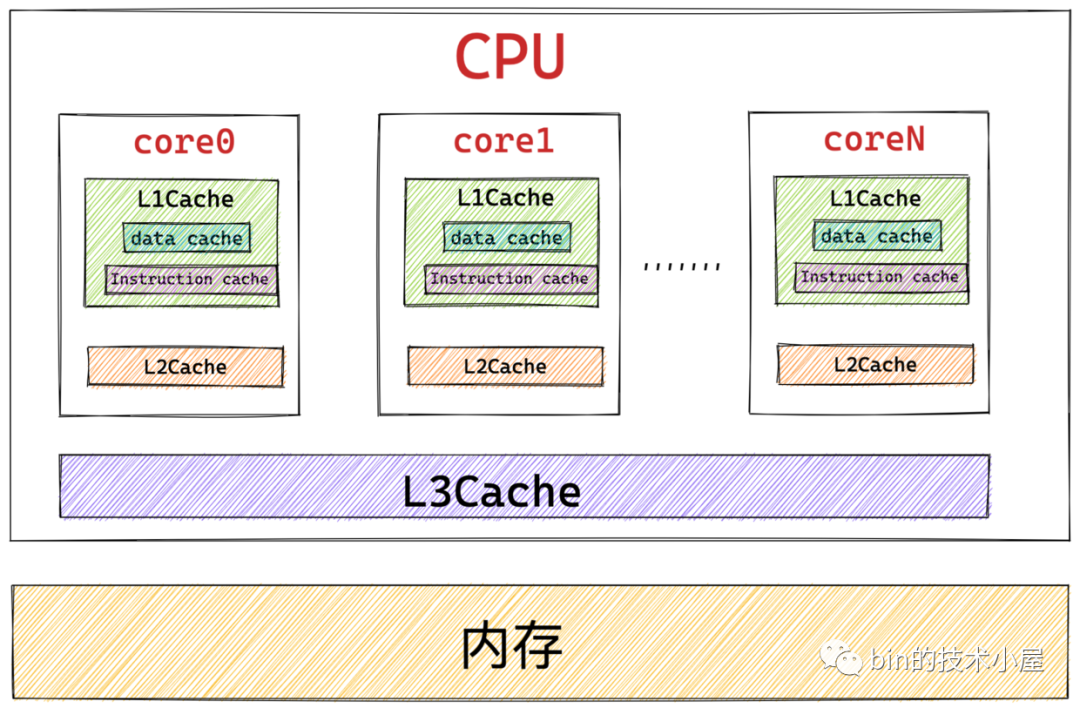
CPU緩存結(jié)構(gòu).png
而本文我們討論的主題是內(nèi)存與磁盤之間的關(guān)系,CPU 訪問磁盤的速度就更慢了,需要用到大概約幾千萬個(gè)時(shí)鐘周期.
我們可以看到 CPU 訪問高速緩存的速度比訪問內(nèi)存的速度快大約10倍,而訪問內(nèi)存的速度要比訪問磁盤的速度快大約 100000 倍。
引入 CPU 高速緩存的目的在于消除 CPU 與內(nèi)存之間的速度差距,CPU 用高速緩存來存放內(nèi)存中的熱點(diǎn)數(shù)據(jù)。那么同樣的道理,本小節(jié)中我們引入的頁(yè)高速緩存 page cache 的目的是為了消除內(nèi)存與磁盤之間的巨大速度差距,page cache 中緩存的是磁盤文件的熱點(diǎn)數(shù)據(jù)。
另外我們根據(jù)程序的時(shí)間局部性原理可以知道,磁盤文件中的數(shù)據(jù)一旦被訪問,那么它很有可能在短期被再次訪問,如果我們?cè)L問的磁盤文件數(shù)據(jù)緩存在 page cache 中,那么當(dāng)進(jìn)程再次訪問的時(shí)候數(shù)據(jù)就會(huì)在 page cache 中命中,這樣我們就可以把對(duì)磁盤的訪問變?yōu)閷?duì)物理內(nèi)存的訪問,極大提升了對(duì)磁盤的訪問性能。
程序局部性原理表現(xiàn)為:時(shí)間局部性和空間局部性。時(shí)間局部性是指如果程序中的某條指令一旦執(zhí)行,則不久之后該指令可能再次被執(zhí)行;如果某塊數(shù)據(jù)被訪問,則不久之后該數(shù)據(jù)可能再次被訪問。空間局部性是指一旦程序訪問了某個(gè)存儲(chǔ)單元,則不久之后,其附近的存儲(chǔ)單元也將被訪問。
在前邊的內(nèi)容中我們多次提到操作系統(tǒng)是將物理內(nèi)存分為一個(gè)一個(gè)的頁(yè)面來組織管理的,每頁(yè)大小為 4k ,而磁盤中的文件數(shù)據(jù)在磁盤中是分為一個(gè)一個(gè)的塊來組織管理的,每塊大小也為 4k。
page cache 中緩存的就是這些內(nèi)存頁(yè)面,頁(yè)面中的數(shù)據(jù)對(duì)應(yīng)于磁盤上物理塊中的數(shù)據(jù)。page cache 中緩存的大小是可以動(dòng)態(tài)調(diào)整的,它可以通過占用空閑內(nèi)存來擴(kuò)大緩存頁(yè)面的容量,當(dāng)內(nèi)存不足時(shí)也可以通過回收頁(yè)面來緩解內(nèi)存使用的壓力。
正如我們上小節(jié)介紹的 read 系統(tǒng)調(diào)用在內(nèi)核中的實(shí)現(xiàn)邏輯那樣,當(dāng)用戶進(jìn)程發(fā)起 read 系統(tǒng)調(diào)用之后,內(nèi)核首先會(huì)在 page cache 中檢查請(qǐng)求數(shù)據(jù)所在頁(yè)面是否已經(jīng)緩存在 page cache 中。
如果緩存命中,內(nèi)核直接會(huì)把 page cache 中緩存的磁盤文件數(shù)據(jù)拷貝到用戶空間緩沖區(qū) DirectByteBuffer 中,從而避免了龜速的磁盤 IO。
如果緩存沒有命中,內(nèi)核會(huì)分配一個(gè)物理頁(yè)面,將這個(gè)新分配的頁(yè)面插入 page cache 中,然后調(diào)度磁盤塊 IO 驅(qū)動(dòng)從磁盤中讀取數(shù)據(jù),最后用從磁盤中讀取的數(shù)據(jù)填充這個(gè)物里頁(yè)面。
根據(jù)前面介紹的程序時(shí)間局部性原理,當(dāng)進(jìn)程在不久之后再來讀取數(shù)據(jù)的時(shí)候,請(qǐng)求的數(shù)據(jù)已經(jīng)在 page cache 中了。極大地提升了文件 IO 的性能。
page cache 中緩存的不僅有基于文件的緩存頁(yè),還會(huì)緩存內(nèi)存映射文件,以及磁盤塊設(shè)備文件。這里大家只需要有這個(gè)概念就行,本文我們主要聚焦于基于文件的緩存頁(yè)。在筆者后面的文章中,我們還會(huì)再次介紹到這些剩余類型的緩存頁(yè)。
在我們了解了 page cache 引入的目的以及 page cache 在磁盤 IO 中所發(fā)揮的作用之后,大家一定會(huì)很好奇這個(gè) page cache 在內(nèi)核中到底是怎么實(shí)現(xiàn)的呢?
讓我們先從 page cache 在內(nèi)核中的數(shù)據(jù)結(jié)構(gòu)開始聊起~~~~
6. page cache 在內(nèi)核中的數(shù)據(jù)結(jié)構(gòu)
page cache 在內(nèi)核中的數(shù)據(jù)結(jié)構(gòu)是一個(gè)叫做 address_space 的結(jié)構(gòu)體:struct address_space。
這個(gè)名字起的真是有點(diǎn)詞不達(dá)意,從命名上根本無法看出它是表示 page cache 的,所以大家在日常開發(fā)中一定要注意命名的精準(zhǔn)規(guī)范。
每個(gè)文件都會(huì)有自己的 page cache。struct address_space 結(jié)構(gòu)在內(nèi)存中只會(huì)保留一份。
什么意思呢?比如我們可以通過多個(gè)不同的進(jìn)程打開一個(gè)相同的文件,進(jìn)程每打開一個(gè)文件,內(nèi)核就會(huì)為它創(chuàng)建 struct file 結(jié)構(gòu)。這樣在內(nèi)核中就會(huì)有多個(gè) struct file 結(jié)構(gòu)來表示同一個(gè)文件,但是同一個(gè)文件的 page cache 也就是 struct address_space 在內(nèi)核中只會(huì)有一個(gè)。
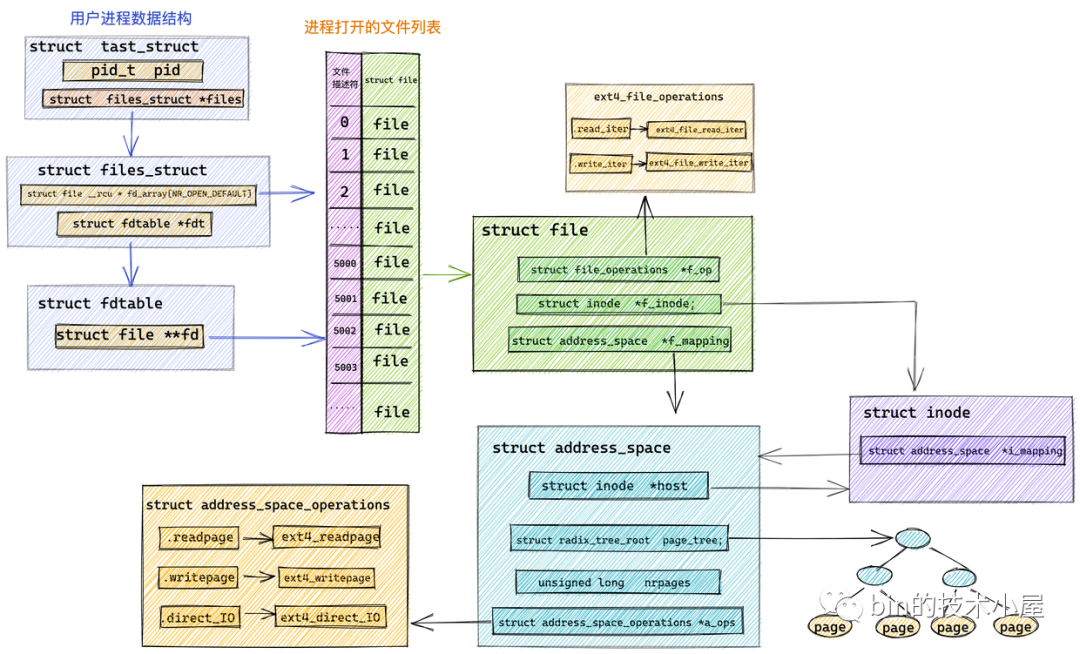
structaddress_space{
structinode*host;//關(guān)聯(lián)pagecache對(duì)應(yīng)文件的inode
structradix_tree_rootpage_tree;//這里就是 page cache。里邊緩存了文件的所有緩存頁(yè)面
spinlock_ttree_lock;//訪問page_tree時(shí)用到的自旋鎖
unsignedlongnrpages;//pagecache中緩存的頁(yè)面總數(shù)
..........省略..........
conststructaddress_space_operations*a_ops;//定義對(duì)pagecache中緩存頁(yè)的各種操作方法
..........省略..........
}
struct inode *host :一個(gè)文件對(duì)應(yīng)一個(gè) page cache 結(jié)構(gòu) struct address_space ,文件的 inode 描述了一個(gè)文件的所有元信息。在 struct address_space 中通過 host 指針與文件的 inode 關(guān)聯(lián)。而在 inode 結(jié)構(gòu)體 struct inode 中又通過 i_mapping 指針與文件的 page cache 進(jìn)行關(guān)聯(lián)。
structinode{
structaddress_space*i_mapping;//關(guān)聯(lián)文件的pagecache
}
struct radix_tree_root page_tree : page cache 中緩存的所有文件頁(yè)全部存儲(chǔ)在 radix_tree 這樣一個(gè)高效搜索樹結(jié)構(gòu)當(dāng)中。在文件 IO 相關(guān)的操作中,內(nèi)核需要頻繁大量地在 page cache 中搜索請(qǐng)求頁(yè)是否已經(jīng)緩存在頁(yè)高速緩存中,所以針對(duì) page cache 的搜索操作必須是高效的,否則引入 page cache 所帶來的性能提升將會(huì)被低效的搜索開銷所抵消掉。
unsigned long nrpages :記錄了當(dāng)前文件對(duì)應(yīng)的 page cache 緩存頁(yè)面的總數(shù)。
const struct address_space_operations *a_ops :a_ops 定義了 page cache 中所有針對(duì)緩存頁(yè)的 IO 操作,提供了管理 page cache 的各種行為。比如:常用的頁(yè)面讀取操作 readPage() 以及頁(yè)面寫入操作 writePage() 等。保證了所有針對(duì)緩存頁(yè)的 IO 操作必須是通過 page cache 進(jìn)行的。
structaddress_space_operations{
//寫入更新頁(yè)面緩存
int(*writepage)(structpage*page,structwriteback_control*wbc);
//讀取頁(yè)面緩存
int(*readpage)(structfile*,structpage*);
//設(shè)置緩存頁(yè)為臟頁(yè),等待后續(xù)內(nèi)核回寫磁盤
int(*set_page_dirty)(structpage*page);
//DirectIO繞過pagecache直接操作磁盤
ssize_t(*direct_IO)(structkiocb*,structiov_iter*iter);
........省略..........
}
前邊我們提到 page cache 中緩存的不僅僅是基于文件的頁(yè),它還會(huì)緩存內(nèi)存映射頁(yè),以及磁盤塊設(shè)備文件,況且基于文件的內(nèi)存頁(yè)背后也有不同的文件系統(tǒng)。所以內(nèi)核只是通過 a_ops 定義了操作 page cache 緩存頁(yè) IO 的通用行為定義。而具體的實(shí)現(xiàn)需要各個(gè)具體的文件系統(tǒng)通過自己定義的 address_space_operations 來描述自己如何與 page cache 進(jìn)行交互。比如前邊我們介紹的 ext4 文件系統(tǒng)就有自己的 address_space_operations 定義。
staticconststructaddress_space_operationsext4_aops={
.readpage=ext4_readpage,
.writepage=ext4_writepage,
.direct_IO=ext4_direct_IO,
........省略.....
};
在我們從整體上了解了 page cache 在內(nèi)核中的數(shù)據(jù)結(jié)構(gòu) struct address_space 之后,我們接下來看一下 radix_tree 這個(gè)數(shù)據(jù)結(jié)構(gòu)是如何支持內(nèi)核來高效搜索文件頁(yè)的,以及 page cache 中這些被緩存的文件頁(yè)是如何組織管理的。
7. 基樹 radix_tree
正如前邊我們提到的,在文件 IO 相關(guān)的操作中,內(nèi)核會(huì)頻繁大量地在 page cache 中查找請(qǐng)求頁(yè)是否在頁(yè)高速緩存中。還有就是當(dāng)我們?cè)L問大文件時(shí)(linux 能支持大到幾個(gè) TB 的文件),page cache 中將會(huì)充斥著大量的文件頁(yè)。
基于上面提到的兩個(gè)原因:一個(gè)是內(nèi)核對(duì) page cache 的頻繁搜索操作,另一個(gè)是 page cache 中會(huì)緩存大量的文件頁(yè)。所以內(nèi)核需要采用一個(gè)高效的搜索數(shù)據(jù)結(jié)構(gòu)來組織管理 page cache 中的緩存頁(yè)。
本小節(jié)我們就來介紹下,page cache 中用來存儲(chǔ)緩存頁(yè)的數(shù)據(jù)結(jié)構(gòu) radix_tree。
在 linux 內(nèi)核 5.0 版本中 radix_tree 已被替換成 xarray 結(jié)構(gòu)。感興趣的同學(xué)可以自行了解下。
在 page cache 結(jié)構(gòu) struct address_space 中有一個(gè)類型為 struct radix_tree_root 的字段 page_tree,它表示的是 radix_tree 的根節(jié)點(diǎn)。
structaddress_space{
structradix_tree_rootpage_tree;//這里就是 page cache。里邊緩存了文件的所有緩存頁(yè)面
..........省略..........
}
structradix_tree_root{
gfp_tgfp_mask;
structradix_tree_node__rcu*rnode;//radix_tree根節(jié)點(diǎn)
};
radix_tree 中的節(jié)點(diǎn)類型為 struct radix_tree_node。
structradix_tree_node{
void__rcu*slots[RADIX_TREE_MAP_SIZE];//包含 64 個(gè)指針的數(shù)組。用于指向下一層節(jié)點(diǎn)或者緩存頁(yè)
unsignedcharoffset;//父節(jié)點(diǎn)中指向該節(jié)點(diǎn)的指針在父節(jié)點(diǎn)slots數(shù)組中的偏移
unsignedcharcount;//記錄當(dāng)前節(jié)點(diǎn)的slots數(shù)組指向了多少個(gè)節(jié)點(diǎn)
structradix_tree_node*parent;//父節(jié)點(diǎn)指針
structradix_tree_root*root;//根節(jié)點(diǎn)
..........省略.........
unsignedlongtags[RADIX_TREE_MAX_TAGS][RADIX_TREE_TAG_LONGS];// radix_tree 中的二維標(biāo)記數(shù)組,用于標(biāo)記子節(jié)點(diǎn)的狀態(tài)。
};
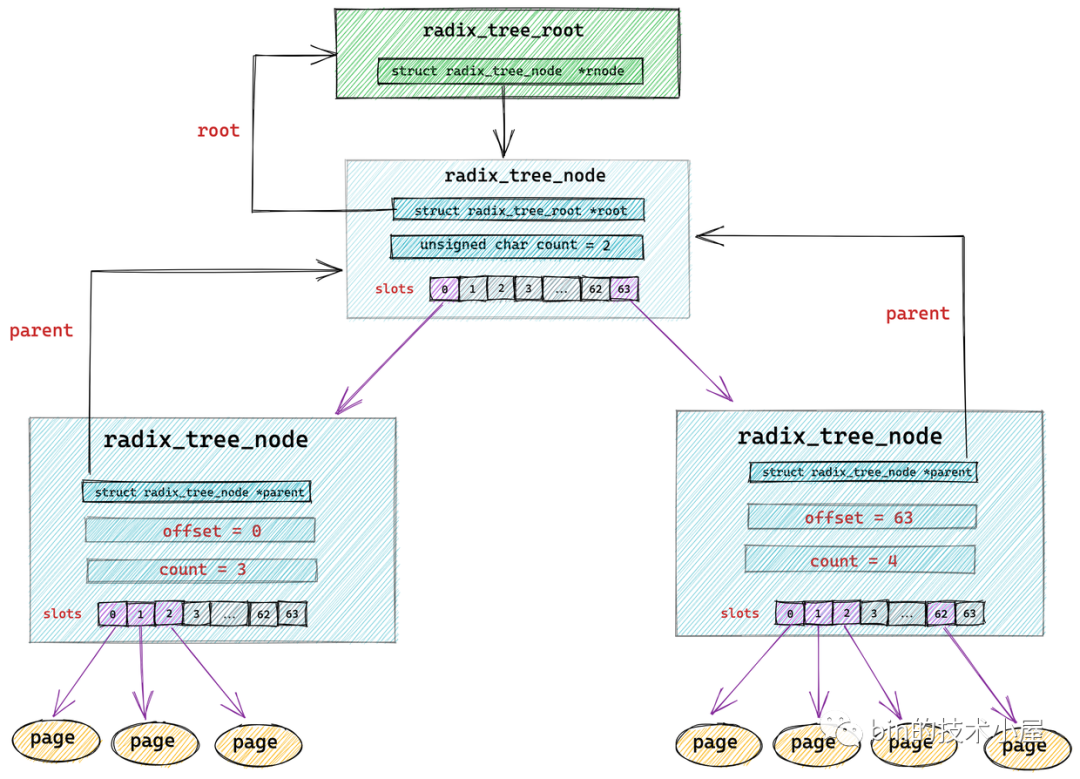
void __rcu *slots[RADIX_TREE_MAP_SIZE] :radix_tree 樹中的每個(gè)節(jié)點(diǎn)中包含一個(gè) slots ,它是一個(gè)包含 64 個(gè)指針的數(shù)組,每個(gè)指針指向它的下一層節(jié)點(diǎn)或者緩存頁(yè)描述符 struct page。
radix_tree 將緩存頁(yè)全部存放在它的葉子結(jié)點(diǎn)中,所以它的葉子結(jié)點(diǎn)類型為 struct page。其余的節(jié)點(diǎn)類型為 radix_tree_node。最底層的 radix_tree_node 節(jié)點(diǎn)中的 slots 指向緩存頁(yè)描述符 struct page。
unsigned char offset 用于表示父節(jié)點(diǎn)的 slots 數(shù)組中指向當(dāng)前節(jié)點(diǎn)的指針,在父節(jié)點(diǎn)的slots數(shù)組中的索引。
unsigned char count 用于記錄當(dāng)前 radix_tree_node 的 slots 數(shù)組中指向的節(jié)點(diǎn)個(gè)數(shù),因?yàn)?slots 數(shù)組中的指針有可能指向 null 。
這里大家可能已經(jīng)注意到了在 struct radix_tree_node 結(jié)構(gòu)中還有一個(gè) long 型的 tags 二維數(shù)組 tags[RADIX_TREE_MAX_TAGS][RADIX_TREE_TAG_LONGS]。那么這個(gè)二維數(shù)組到底是用來干嘛的呢?我們接著往下看~~
7.1 radix_tree 的標(biāo)記
經(jīng)過前面的介紹我們知道,頁(yè)高速緩存 page cache 的引入是為了在內(nèi)存中緩存磁盤的熱點(diǎn)數(shù)據(jù)盡可能避免龜速的磁盤 IO。
而在進(jìn)行文件 IO 的時(shí)候,內(nèi)核會(huì)頻繁大量的在 page cache 中搜索請(qǐng)求數(shù)據(jù)是否已經(jīng)緩存在 page cache 中,如果是,內(nèi)核就直接將 page cache 中的數(shù)據(jù)拷貝到用戶緩沖區(qū)中。從而避免了一次磁盤 IO。
這就要求內(nèi)核需要采用一種支持高效搜索的數(shù)據(jù)結(jié)構(gòu)來組織管理這些緩存頁(yè),所以引入了基樹 radix_tree。
到目前為止,我們還沒有涉及到緩存頁(yè)的狀態(tài),不過在文章的后面我們很快就會(huì)涉及到,這里提前給大家引出來,讓大家腦海里先有個(gè)概念。
那么什么是緩存頁(yè)的狀態(tài)呢?
我們知道在 Buffered IO 模式下,對(duì)于文件 IO 的操作都是需要經(jīng)過 page cache 的,后面我們即將要介紹的 write 系統(tǒng)調(diào)用就會(huì)將數(shù)據(jù)直接寫到 page cache 中,并將該緩存頁(yè)標(biāo)記為臟頁(yè)(PG_dirty)直接返回,隨后內(nèi)核會(huì)根據(jù)一定的規(guī)則來將這些臟頁(yè)回寫到磁盤中,在會(huì)寫的過程中這些臟頁(yè)又會(huì)被標(biāo)記為 PG_writeback,表示該頁(yè)正在被回寫到磁盤。
PG_dirty 和 PG_writeback 就是緩存頁(yè)的狀態(tài),而內(nèi)核不僅僅是需要在 page cache 中高效搜索請(qǐng)求數(shù)據(jù)所在的緩存頁(yè),還需要高效搜索給定狀態(tài)的緩存頁(yè)。
比如:快速查找 page cache 中的所有臟頁(yè)。但是如果此時(shí) page cache 中的大部分緩存頁(yè)都不是臟頁(yè),那么順序遍歷 radix_tree 的方式就實(shí)在是太慢了,所以為了快速搜索到臟頁(yè),就需要在 radix_tree 中的每個(gè)節(jié)點(diǎn) radix_tree_node中加入一個(gè)針對(duì)其所有子節(jié)點(diǎn)的臟頁(yè)標(biāo)記,如果其中一個(gè)子節(jié)點(diǎn)被標(biāo)記被臟時(shí),那么這個(gè)子節(jié)點(diǎn)對(duì)應(yīng)的父節(jié)點(diǎn) radix_tree_node 結(jié)構(gòu)中的對(duì)應(yīng)臟頁(yè)標(biāo)記位就會(huì)被置 1 。
而用來存儲(chǔ)臟頁(yè)標(biāo)記的正是上小節(jié)中提到的 tags 二維數(shù)組。其中第一維 tags[] 用來表示標(biāo)記類型,有多少標(biāo)記類型,數(shù)組大小就為多少,比如 tags[0] 表示 PG_dirty 標(biāo)記數(shù)組,tags[1] 表示 PG_writeback 標(biāo)記數(shù)組。
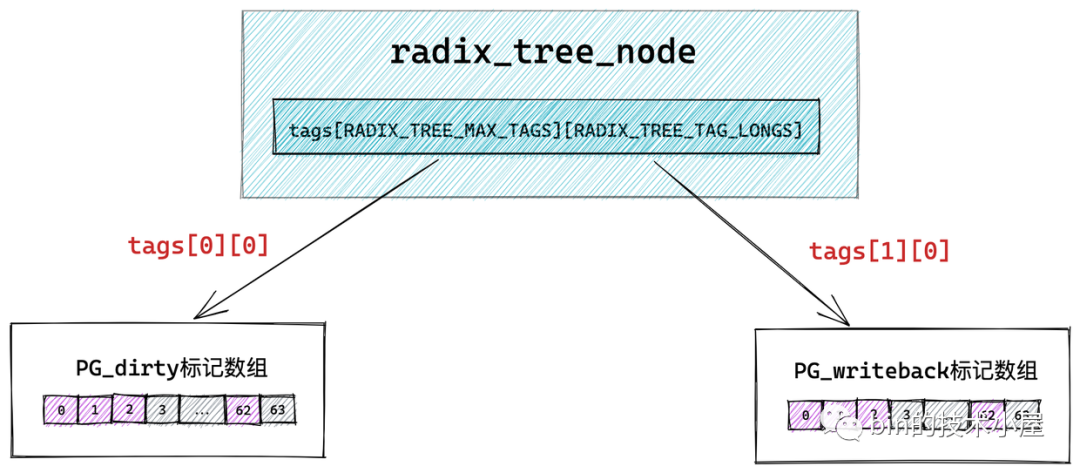
第二維 tags[][] 數(shù)組則表示對(duì)應(yīng)標(biāo)記類型針對(duì)每一個(gè)子節(jié)點(diǎn)的標(biāo)記位,因?yàn)橐粋€(gè) radix_tree_node 節(jié)點(diǎn)中包含 64 個(gè)指針指向?qū)?yīng)的子節(jié)點(diǎn),所以二維 tags[][] 數(shù)組的大小也為 64 ,數(shù)組中的每一位表示對(duì)應(yīng)子節(jié)點(diǎn)的標(biāo)記。tags[0][0] 指向 PG_dirty 標(biāo)記數(shù)組,tags[1][0] 指向PG_writeback 標(biāo)記數(shù)組。
而緩存頁(yè)( radix_tree 中的葉子結(jié)點(diǎn))這些標(biāo)記是存放在其對(duì)應(yīng)的頁(yè)描述符 struct page 里的 flag 中。
structpage{
unsignedlongflags;
}
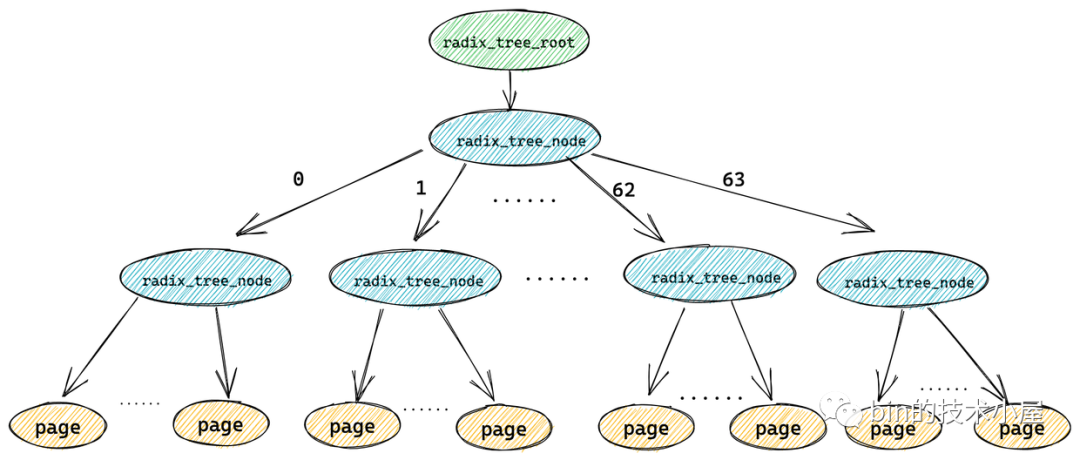
只要一個(gè)緩存頁(yè)(葉子結(jié)點(diǎn))被標(biāo)記,那么從這個(gè)葉子結(jié)點(diǎn)一直到 radix_tree 根節(jié)點(diǎn)的路徑將會(huì)全部被標(biāo)記。這就好比你在一盆清水中滴入一滴墨水,不久之后整盆水就會(huì)變?yōu)楹谏?/p>
這樣內(nèi)核在 radix_tree 中搜索被標(biāo)記的臟頁(yè)(PG_dirty)或者正在回寫的頁(yè)(PG_writeback)時(shí),就可以迅速跳過哪些標(biāo)記為 0 的中間節(jié)點(diǎn)的所有子樹,中間節(jié)點(diǎn)對(duì)應(yīng)的標(biāo)記為 0 說明其所有的子樹中包含的緩存頁(yè)(葉子結(jié)點(diǎn))都是干凈的(未標(biāo)記)。從而達(dá)到在 radix_tree 中迅速搜索指定狀態(tài)的緩存頁(yè)的目的。
8. page cache 中查找緩存頁(yè)
在我們明白了 radix_tree 這個(gè)數(shù)據(jù)結(jié)構(gòu)之后,接下來我們來看一下在《4.2 Buffered IO》小節(jié)中遺留的問題:內(nèi)核如何通過 find_get_page 在 page cache 中高效查找緩存頁(yè)?
在介紹 find_get_page 之前,筆者先來帶大家看看 radix_tree 具體是如何組織和管理其中的緩存頁(yè) page 的。
經(jīng)過上小節(jié)相關(guān)內(nèi)容的介紹,我們了解到在 radix_tree 中每個(gè)節(jié)點(diǎn) radix_tree_node 包含一個(gè)大小為 64 的指針數(shù)組 slots 用于指向它的子節(jié)點(diǎn)或者緩存頁(yè)描述符(葉子節(jié)點(diǎn))。
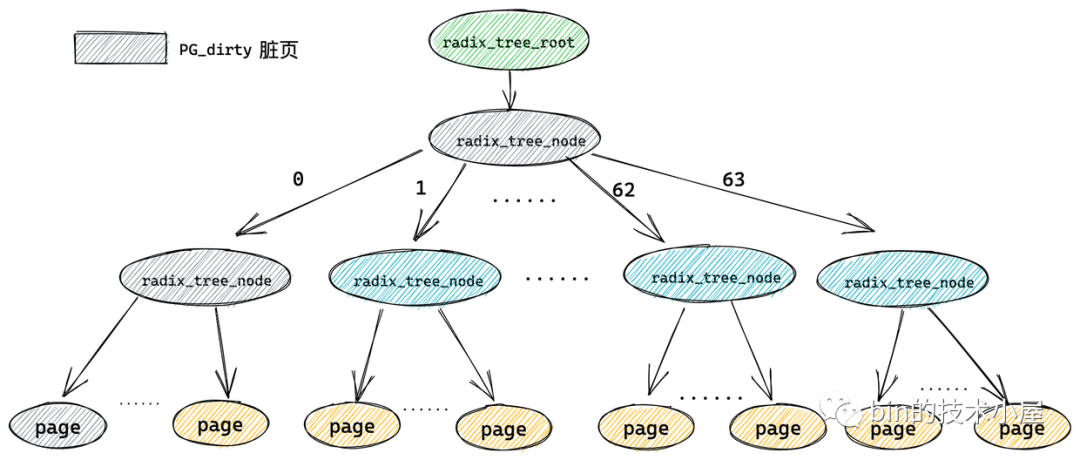
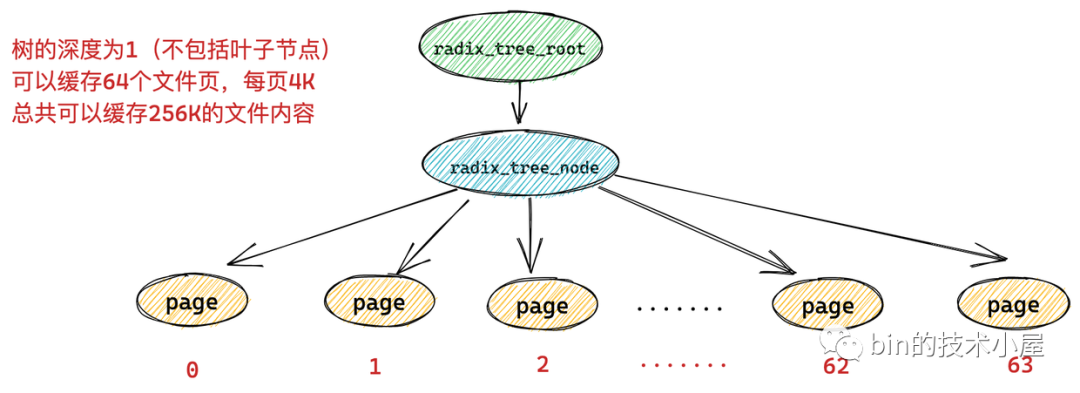
一個(gè) radix_tree_node 節(jié)點(diǎn)下邊最多可容納 64 個(gè)子節(jié)點(diǎn),如果 radix_tree 的深度為 1 (不包括葉子節(jié)點(diǎn)),那么這顆 radix_tree 就可以緩存 64 個(gè)文件頁(yè)。而每頁(yè)大小為 4k,所以一顆深度為 1 的 radix_tree 可以緩存 256k 的文件內(nèi)容。
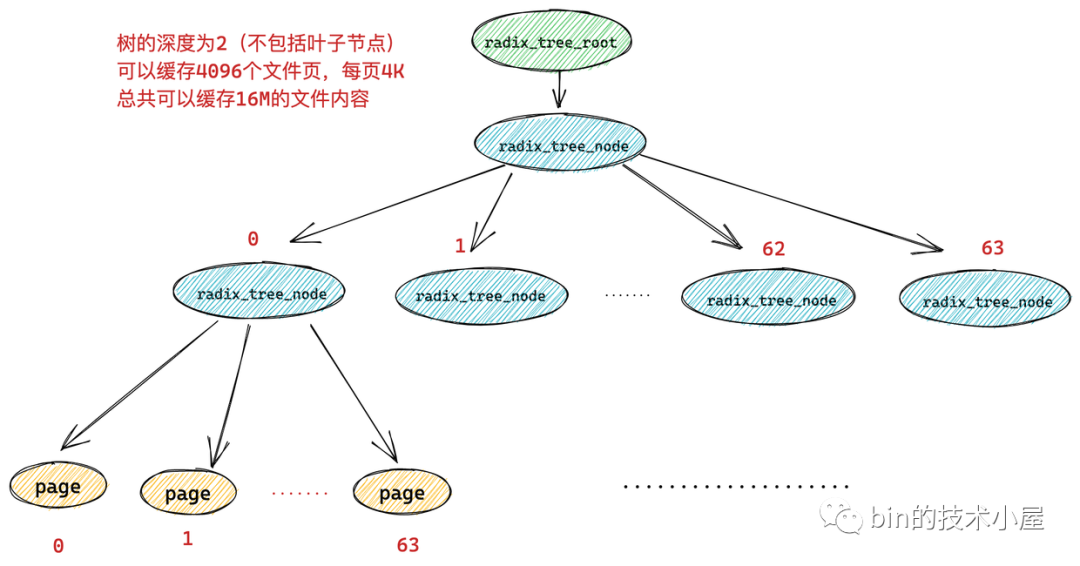
而如果一顆 radix_tree 的深度為 2,那么它就可以緩存 64 * 64 = 4096 個(gè)文件頁(yè),總共可以緩存 16M 的文件內(nèi)容。
依次類推我們可以得到不同的 radix_tree 深度可以緩存多大的文件內(nèi)容:
| radix_tree 深度 | page 最大索引值 | 緩存文件大小 |
|---|---|---|
| 1 | 2^6 - 1 = 63 | 256K |
| 2 | 2^12 - 1 = 4095 | 16M |
| 3 | 2^18 - 1 = 262143 | 1G |
| 4 | 2^24 -1 =16777215 | 64G |
| 5 | 2^30 - 1 | 4T |
| 6 | 2^36 - 1 | 64T |
通過以上內(nèi)容的介紹,我們看到在 radix_tree 是根據(jù)緩存頁(yè)的 index (索引)來組織管理緩存頁(yè)的,內(nèi)核會(huì)根據(jù)這個(gè) index 迅速找到對(duì)應(yīng)的緩存頁(yè)。在緩存頁(yè)描述符 struct page 結(jié)構(gòu)中保存了其在 page cache 中的索引 index。
structpage{
unsignedlongflags;//緩存頁(yè)標(biāo)記
structaddress_space*mapping;//緩存頁(yè)所在的pagecache
unsignedlongindex;//頁(yè)索引
...
}
事實(shí)上 find_get_page 函數(shù)也是根據(jù)緩存頁(yè)描述符中的這個(gè) index 來在 page cache 中高效查找對(duì)應(yīng)的緩存頁(yè)。
staticinlinestructpage*find_get_page(structaddress_space*mapping,
pgoff_toffset)
{
returnpagecache_get_page(mapping,offset,0,0);
}
struct address_space *mapping : 為讀取文件對(duì)應(yīng)的 page cache 頁(yè)高速緩存。
pgoff_t offset :為所請(qǐng)求的緩存頁(yè)在 page cache 中的索引 index,類型為 long 型。
那么在內(nèi)核是如何利用這個(gè) long 型的 offset 在 page cache 中高效搜索指定的緩存頁(yè)呢?
經(jīng)過前邊我們對(duì) radix_tree 結(jié)構(gòu)的介紹,我們已經(jīng)知道 radix_tree 中每個(gè)節(jié)點(diǎn) radix_tree_node 包含一個(gè)大小為 64 的指針數(shù)組 slots 用于指向它的子節(jié)點(diǎn)或者緩存頁(yè)描述符。
一個(gè) radix_tree_node 節(jié)點(diǎn)下邊最多可容納 64 個(gè)子節(jié)點(diǎn),如果 radix_tree 的深度為 1 (不包括葉子節(jié)點(diǎn)),那么這顆 radix_tree 就可以緩存 64 個(gè)文件頁(yè)。只能表示 0 - 63 的索引范圍,所以 long 型的緩存頁(yè) offset 的低 6 位可以表示這個(gè)范圍,對(duì)應(yīng)于第一層 radix_tree_node 節(jié)點(diǎn)的 slots 數(shù)組下標(biāo)。
如果一顆 radix_tree 的深度為 2(不包括葉子節(jié)點(diǎn)),那么它就可以緩存 64 * 64 = 4096 個(gè)文件頁(yè),表示的索引范圍為 0 - 4095,在這種情況下,緩存頁(yè)索引 offset 的低 12 位可以分成 兩個(gè) 6 位的字段,高位的字段用來表示第一層節(jié)點(diǎn)的 slots 數(shù)組的下標(biāo),低位字段用于表示第二層節(jié)點(diǎn)的 slots 數(shù)組下標(biāo)。
依次類推,如果 radix_tree 的深度為 6 那么它可以緩存 64T 的文件頁(yè),表示的索引范圍為:0 到 2^36 - 1。緩存頁(yè)索引 offset 的低 36 位可以分成 六 個(gè) 6 位的字段。緩存頁(yè)索引的最高位字段來表示 radix_tree 中的第一層節(jié)點(diǎn)中的 slots 數(shù)組下標(biāo),接下來的 6 位字段表示第二層節(jié)點(diǎn)中的 slots 數(shù)組下標(biāo),這樣一直到最低的 6 位字段表示第 6 層節(jié)點(diǎn)中的 slots 數(shù)組下標(biāo)。
通過以上根據(jù)緩存頁(yè)索引 offset 的查找過程,我們看出內(nèi)核在 page cache 查找緩存頁(yè)的時(shí)間復(fù)雜度和 radix_tree 的深度有關(guān)。
在我們理解了內(nèi)核在 radix_tree 中的查找緩存頁(yè)邏輯之后,再來看 find_get_page 的代碼實(shí)現(xiàn)就變得很簡(jiǎn)單了~~
structpage*pagecache_get_page(structaddress_space*mapping,pgoff_toffset,
intfgp_flags,gfp_tgfp_mask)
{
structpage*page;
repeat:
//在radix_tree中根據(jù)緩存頁(yè)offset查找緩存頁(yè)
page=find_get_entry(mapping,offset);
//緩存頁(yè)不存在的話,跳轉(zhuǎn)到no_page處理邏輯
if(!page)
gotono_page;
.......省略.......
no_page:
if(!page&&(fgp_flags&FGP_CREAT)){
//分配新頁(yè)
page=__page_cache_alloc(gfp_mask);
if(!page)
returnNULL;
if(fgp_flags&FGP_ACCESSED)
//增加頁(yè)的引用計(jì)數(shù)
__SetPageReferenced(page);
//將新分配的內(nèi)存頁(yè)加入到頁(yè)高速緩存pagecache中
err=add_to_page_cache_lru(page,mapping,offset,gfp_mask);
.......省略.......
}
returnpage;
}
內(nèi)核首先調(diào)用 find_get_entry 方法根據(jù)緩存頁(yè)的 offset 到 page cache 中去查找看請(qǐng)求的文件頁(yè)是否已經(jīng)在頁(yè)高速緩存中。如果存在直接返回。
如果請(qǐng)求的文件頁(yè)不在 page cache 中,內(nèi)核則會(huì)首先會(huì)在物理內(nèi)存中分配一個(gè)內(nèi)存頁(yè),然后將新分配的內(nèi)存頁(yè)加入到 page cache 中,并增加頁(yè)引用計(jì)數(shù)。
隨后會(huì)通過 address_space_operations 重定義的 readpage 激活塊設(shè)備驅(qū)動(dòng)從磁盤中讀取請(qǐng)求數(shù)據(jù),然后用讀取到的數(shù)據(jù)填充新分配的內(nèi)存頁(yè)。
staticconststructaddress_space_operationsext4_aops={
.readpage=ext4_readpage,
.writepage=ext4_writepage,
.direct_IO=ext4_direct_IO,
........省略.....
};
9. 文件頁(yè)的預(yù)讀
之前我們?cè)谝?page cache 的時(shí)候提到過,根據(jù)程序時(shí)間局部性原理:如果進(jìn)程在訪問某一塊數(shù)據(jù),那么在訪問的不久之后,進(jìn)程還會(huì)再次訪問這塊數(shù)據(jù)。所以內(nèi)核引入了 page cache 在內(nèi)存中緩存磁盤中的熱點(diǎn)數(shù)據(jù),從而減少對(duì)磁盤的 IO 訪問,提升系統(tǒng)性能。
而本小節(jié)我們要介紹的文件頁(yè)預(yù)讀特性是根據(jù)程序空間局部性原理:當(dāng)進(jìn)程訪問一段數(shù)據(jù)之后,那么在不就的將來和其臨近的一段數(shù)據(jù)也會(huì)被訪問到。所以當(dāng)進(jìn)程在訪問文件中的某頁(yè)數(shù)據(jù)的時(shí)候,內(nèi)核會(huì)將它和臨近的幾個(gè)頁(yè)一起預(yù)讀到 page cache 中。這樣當(dāng)進(jìn)程再次訪問文件的時(shí)候,就不需要進(jìn)行龜速的磁盤 IO 了,因?yàn)樗?qǐng)求的數(shù)據(jù)已經(jīng)預(yù)讀進(jìn) page cache 中了。
我們常提到的當(dāng)你順序讀取文件的時(shí)候,性能會(huì)非常的高,因?yàn)橄喈?dāng)于是在讀內(nèi)存,這就是文件預(yù)讀的功勞。
但是在我們隨機(jī)訪問文件的時(shí)候,文件預(yù)讀不僅不會(huì)提高性能,返回會(huì)降低文件讀取的性能,因?yàn)殡S機(jī)讀取文件并不符合程序空間局部性原理,因此預(yù)讀進(jìn) page cache 中的文件頁(yè)通常是無效的,下一次根本不會(huì)再去讀取,這無疑是白白浪費(fèi)了 page cache 的空間,還額外增加了不必要的預(yù)讀磁盤 IO。
事實(shí)上,在我們對(duì)文件進(jìn)行隨機(jī)讀取的場(chǎng)景下,更適合用 Direct IO 的方式繞過 page cache 直接從磁盤中讀取文件,還能減少一次從 page cache 到用戶緩沖區(qū)的拷貝。
所以內(nèi)核需要一套非常精密的預(yù)讀算法來根據(jù)進(jìn)程是順序讀文件還是隨機(jī)讀文件來精確地調(diào)控預(yù)讀的文件頁(yè)數(shù),或者直接關(guān)閉預(yù)讀。
進(jìn)程在讀取文件數(shù)據(jù)的時(shí)候都是逐頁(yè)進(jìn)行讀取的,因此在預(yù)讀文件頁(yè)的時(shí)候內(nèi)核并不會(huì)考慮頁(yè)內(nèi)偏移,而是根據(jù)請(qǐng)求數(shù)據(jù)在文件內(nèi)部的頁(yè)偏移進(jìn)行讀取。
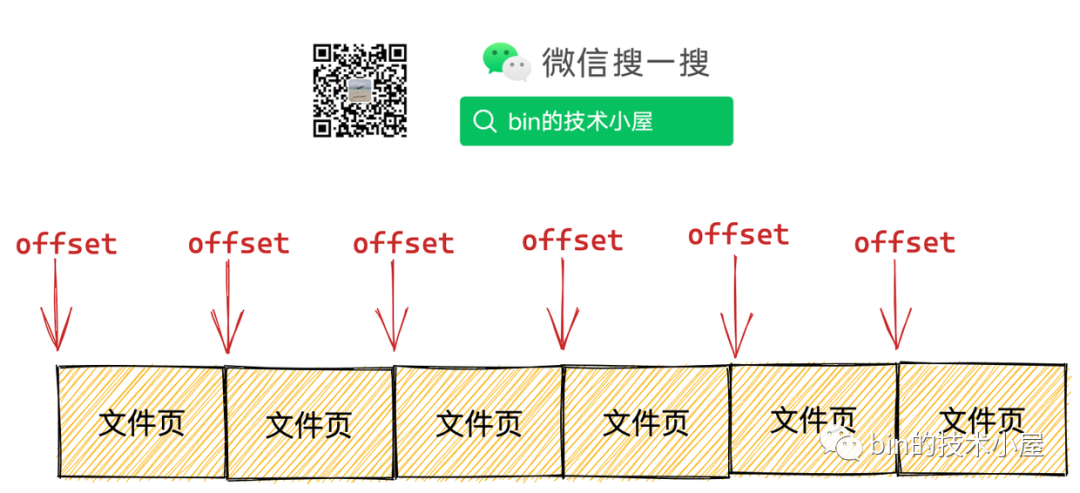
如果進(jìn)程持續(xù)的順序訪問一個(gè)文件,那么預(yù)讀頁(yè)數(shù)也會(huì)隨著逐步增加。
當(dāng)發(fā)現(xiàn)進(jìn)程開始隨機(jī)訪問文件了(當(dāng)前訪問的文件頁(yè)和最后一次訪問的文件頁(yè) offset 不是連續(xù)的),內(nèi)核就會(huì)逐步減少預(yù)讀頁(yè)數(shù)或者徹底禁止預(yù)讀。
當(dāng)內(nèi)核發(fā)現(xiàn)進(jìn)程再重復(fù)的訪問同一文件頁(yè)時(shí)或者文件中的文件頁(yè)已經(jīng)幾乎全部緩存在 page cache 中了,內(nèi)核此時(shí)就會(huì)禁止預(yù)讀。
以上幾點(diǎn)就是內(nèi)核的預(yù)讀算法的核心邏輯,從這個(gè)預(yù)讀邏輯中我們可以看出,進(jìn)程在進(jìn)行文件讀取的時(shí)候涉及到兩種不同類型的頁(yè)面集合,一個(gè)是進(jìn)程可以請(qǐng)求的文件頁(yè)(已經(jīng)緩存在 page cache 中的文件頁(yè)),另一個(gè)是內(nèi)核預(yù)讀的文件頁(yè)。
而內(nèi)核也確實(shí)按照這兩種頁(yè)面集合分為兩個(gè)窗口:
當(dāng)前窗口(current window): 表示進(jìn)程本次文件請(qǐng)求可以直接讀取的頁(yè)面集合,這個(gè)集合中的頁(yè)面全部已經(jīng)緩存在 page cache 中,進(jìn)程可以直接讀取返回。當(dāng)前窗口中包含進(jìn)程本次請(qǐng)求的文件頁(yè)以及上次內(nèi)核預(yù)讀的文件頁(yè)集合。表示進(jìn)程本次可以從 page cache 直接獲取的頁(yè)面范圍。
預(yù)讀窗口(ahead window):預(yù)讀窗口的頁(yè)面都是內(nèi)核正在預(yù)讀的文件頁(yè),它們此時(shí)并不在 page cache 中。這些頁(yè)面并不是進(jìn)程請(qǐng)求的文件頁(yè),但是內(nèi)核根據(jù)空間局部性原理假定它們遲早會(huì)被進(jìn)程請(qǐng)求。預(yù)讀窗口內(nèi)的頁(yè)面緊跟著當(dāng)前窗口后面,并且內(nèi)核會(huì)動(dòng)態(tài)調(diào)整預(yù)讀窗口的大小(有點(diǎn)類似于 TCP 中的滑動(dòng)窗口)。
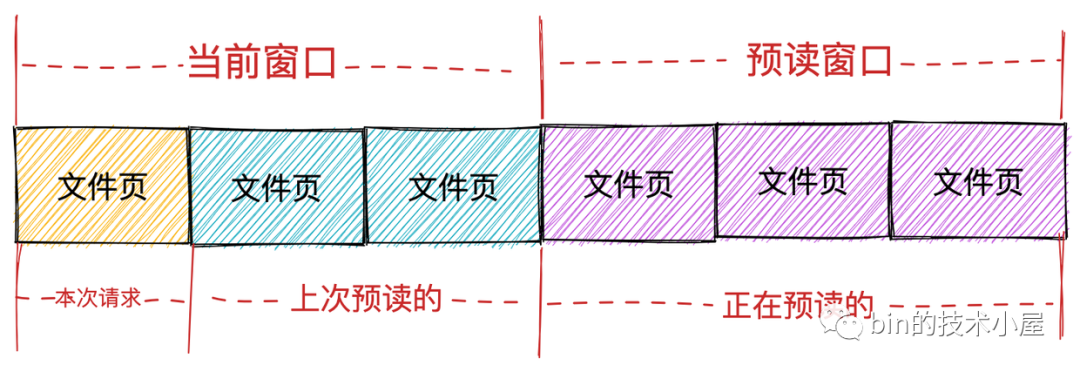
如果進(jìn)程本次文件請(qǐng)求的第一頁(yè)的 offset,緊跟著上一次文件請(qǐng)求的最后一頁(yè)的 offset,內(nèi)核就認(rèn)為是順序讀取。在順序讀取文件的場(chǎng)景下,如果請(qǐng)求的第一頁(yè)在當(dāng)前窗口內(nèi),內(nèi)核隨后就會(huì)檢查是否建立了預(yù)讀窗口,如果沒有就會(huì)創(chuàng)建預(yù)讀窗口并觸發(fā)相應(yīng)頁(yè)的讀取操作。
在理想情況下,進(jìn)程會(huì)繼續(xù)在當(dāng)前窗口內(nèi)請(qǐng)求頁(yè),于此同時(shí),預(yù)讀窗口內(nèi)的預(yù)讀頁(yè)同時(shí)異步傳送著,這樣進(jìn)程在順序讀取文件的時(shí)候就相當(dāng)于直接讀取內(nèi)存,極大地提高了文件 IO 的性能。
以上包含的這些文件預(yù)讀信息,比如:如何判斷進(jìn)程是順序讀取還是隨機(jī)讀取,當(dāng)前窗口信息,預(yù)讀窗口信息。全部保存在 struct file 結(jié)構(gòu)中的 f_ra 字段中。
structfile{
structfile_ra_statef_ra;
}
用于描述文件預(yù)讀信息的結(jié)構(gòu)體在內(nèi)核中用 struct file_ra_state 結(jié)構(gòu)體來表示:
structfile_ra_state{
pgoff_tstart;//當(dāng)前窗口第一頁(yè)的索引
unsignedintsize;//當(dāng)前窗口的頁(yè)數(shù),-1表示臨時(shí)禁止預(yù)讀
unsignedintasync_size;//異步預(yù)讀頁(yè)面的頁(yè)數(shù)
unsignedintra_pages;//文件允許的最大預(yù)讀頁(yè)數(shù)
loff_tprev_pos;//進(jìn)程最后一次請(qǐng)求頁(yè)的索引
};
內(nèi)核可以根據(jù) start 和 prev_pos 這兩個(gè)字段來判斷進(jìn)程是否在順序訪問文件。
ra_pages 表示當(dāng)前文件允許預(yù)讀的最大頁(yè)數(shù),進(jìn)程可以通過系統(tǒng)調(diào)用 posix_fadvise() 來改變已打開文件的 ra_page 值來調(diào)優(yōu)預(yù)讀算法。
intposix_fadvise(intfd,off_toffset,off_tlen,intadvice);
該系統(tǒng)調(diào)用用來通知內(nèi)核,我們將來打算以特定的模式 advice 訪問文件數(shù)據(jù),從而允許內(nèi)核執(zhí)行適當(dāng)?shù)膬?yōu)化。
advice 參數(shù)主要有下面幾種數(shù)值:
POSIX_FADV_NORMAL :設(shè)置文件最大預(yù)讀頁(yè)數(shù) ra_pages 為默認(rèn)值 32 頁(yè)。
POSIX_FADV_SEQUENTIAL :進(jìn)程期望順序訪問指定的文件數(shù)據(jù),ra_pages 值為默認(rèn)值的兩倍。
POSIX_FADV_RANDOM :進(jìn)程期望以隨機(jī)順序訪問指定的文件數(shù)據(jù)。ra_pages 設(shè)置為 0,表示禁止預(yù)讀。
后來人們發(fā)現(xiàn)當(dāng)禁止預(yù)讀后,這樣一頁(yè)一頁(yè)的讀取性能非常的低下,于是 linux 3.19.8 之后 POSIX_FADV_RANDOM 的語(yǔ)義被改變了,它會(huì)在 file->f_flags 中設(shè)置 FMODE_RANDOM 屬性(后面我們分析內(nèi)核預(yù)讀相關(guān)源碼的時(shí)候還會(huì)提到),當(dāng)遇到 FMODE_RANDOM 的時(shí)候內(nèi)核就會(huì)走強(qiáng)制預(yù)讀的邏輯,按最大 2MB 單元大小的 chunk 進(jìn)行預(yù)讀。
Thisfixesinefficientpage-by-pagereadsonPOSIX_FADV_RANDOM. POSIX_FADV_RANDOMusedtosetra_pages=0,whichleadstopoor performance:a16Kreadwillbecarriedoutin4_sync_1-pagereads.
POSIX_FADV_WILLNEED :通知內(nèi)核,進(jìn)程指定這段文件數(shù)據(jù)將在不久之后被訪問。
而觸發(fā)內(nèi)核進(jìn)行文件預(yù)讀的場(chǎng)景,分為以下幾種:
當(dāng)進(jìn)程采用 Buffered IO 模式通過系統(tǒng)調(diào)用 read 進(jìn)行文件讀取時(shí),內(nèi)核會(huì)觸發(fā)預(yù)讀。
通過 POSIX_FADV_WILLNEED 參數(shù)執(zhí)行系統(tǒng)調(diào)用 posix_fadvise,會(huì)通知內(nèi)核這個(gè)指定范圍的文件頁(yè)不就將會(huì)被訪問。觸發(fā)預(yù)讀。
當(dāng)進(jìn)程顯示執(zhí)行 readahead() 系統(tǒng)調(diào)用時(shí),會(huì)顯示觸發(fā)內(nèi)核的預(yù)讀動(dòng)作。
當(dāng)內(nèi)核為內(nèi)存文件映射區(qū)域分配一個(gè)物理頁(yè)面時(shí),會(huì)觸發(fā)預(yù)讀。關(guān)于內(nèi)存映射的相關(guān)內(nèi)容,筆者會(huì)在后面的文章為大家詳細(xì)介紹。
和 posix_fadvise 一樣的道理,系統(tǒng)調(diào)用 madvise 主要用來指定內(nèi)存文件映射區(qū)域的訪問模式。可通過 advice = MADV_WILLNEED 通知內(nèi)核,某個(gè)文件內(nèi)存映射區(qū)域中的指定范圍的文件頁(yè)在不久將會(huì)被訪問。觸發(fā)預(yù)讀。
intmadvise(caddr_taddr,size_tlen,intadvice);
從觸發(fā)內(nèi)核預(yù)讀的這幾種場(chǎng)景中我們可以看出,預(yù)讀分為主動(dòng)觸發(fā)和被動(dòng)觸發(fā),在《4.2 Buffered IO》小節(jié)中遺留的 page_cache_sync_readahead 函數(shù)為被動(dòng)觸發(fā),接下來我們來看下它在內(nèi)核中的實(shí)現(xiàn)邏輯。
9.1 page_cache_sync_readahead
voidpage_cache_sync_readahead(structaddress_space*mapping,
structfile_ra_state*ra,structfile*filp,
pgoff_toffset,unsignedlongreq_size)
{
//禁止預(yù)讀,直接返回
if(!ra->ra_pages)
return;
if(blk_cgroup_congested())
return;
//通過posix_fadvise設(shè)置了POSIX_FADV_RANDOM,內(nèi)核走強(qiáng)制預(yù)讀邏輯
if(filp&&(filp->f_mode&FMODE_RANDOM)){
//按最大2MB單元大小的chunk進(jìn)行預(yù)讀
force_page_cache_readahead(mapping,filp,offset,req_size);
return;
}
//執(zhí)行預(yù)讀邏輯
ondemand_readahead(mapping,ra,filp,false,offset,req_size);
}
!ra->ra_pages 表示 ra_pages 設(shè)置為 0 ,預(yù)讀被禁止,直接返回。
如果進(jìn)程通過前邊介紹的 posix_fadvise 系統(tǒng)調(diào)用并且 advice 參數(shù)設(shè)置為 POSIX_FADV_RANDOM。在 linux 3.19.8 之后文件的 file->f_flags 屬性會(huì)被設(shè)置為 FMODE_RANDOM,這樣內(nèi)核會(huì)走強(qiáng)制預(yù)讀邏輯,按最大 2MB 單元大小的 chunk 進(jìn)行預(yù)讀。
intposix_fadvise(intfd,off_toffset,off_tlen,intadvice);
//mm/fadvise.c
switch(advice){
.........省略........
casePOSIX_FADV_RANDOM:
.........省略........
file->f_flags|=FMODE_RANDOM;
.........省略........
break;
.........省略........
}
而真正的預(yù)讀邏輯封裝在 ondemand_readahead 函數(shù)中。
9.2 ondemand_readahead
該方法中封裝了前邊介紹的預(yù)讀算法邏輯,動(dòng)態(tài)的調(diào)整當(dāng)前窗口以及預(yù)讀窗口的大小。
/*
*Aminimalreadaheadalgorithmfortrivialsequential/randomreads.
*/
staticunsignedlong
ondemand_readahead(structaddress_space*mapping,
structfile_ra_state*ra,structfile*filp,
boolhit_readahead_marker,pgoff_toffset,
unsignedlongreq_size)
{
structbacking_dev_info*bdi=inode_to_bdi(mapping->host);
unsignedlongmax_pages=ra->ra_pages;//默認(rèn)32頁(yè)
unsignedlongadd_pages;
pgoff_tprev_offset;
........預(yù)讀算法邏輯,動(dòng)態(tài)調(diào)整當(dāng)前窗口和預(yù)讀窗口.........
//根據(jù)條件,計(jì)算本次預(yù)讀最大預(yù)讀取多少個(gè)頁(yè),一般情況下是max_pages=32個(gè)頁(yè)
if(req_size>max_pages&&bdi->io_pages>max_pages)
max_pages=min(req_size,bdi->io_pages);
//offset即pageindex,如果pageindex=0,表示這是文件第一個(gè)頁(yè),
//內(nèi)核認(rèn)為是順序讀,跳轉(zhuǎn)到initial_readahead進(jìn)行處理
if(!offset)
gotoinitial_readahead;
initial_readahead:
//當(dāng)前窗口第一頁(yè)的索引
ra->start=offset;
//get_init_ra_size初始化第一次預(yù)讀的頁(yè)的個(gè)數(shù),一般情況下第一次預(yù)讀是4個(gè)頁(yè)
ra->size=get_init_ra_size(req_size,max_pages);
//異步預(yù)讀頁(yè)面?zhèn)€數(shù)也就是預(yù)讀窗口大小
ra->async_size=ra->size>req_size?ra->size-req_size:ra->size;
//默認(rèn)情況下是ra->start=0,ra->size=0,ra->async_size=0ra->prev_pos=0
//但是經(jīng)過第一次預(yù)讀后,上面三個(gè)值會(huì)出現(xiàn)變化
if((offset==(ra->start+ra->size-ra->async_size)||
offset==(ra->start+ra->size))){
ra->start+=ra->size;
ra->size=get_next_ra_size(ra,max_pages);
ra->async_size=ra->size;
gotoreadit;
}
//異步預(yù)讀的時(shí)候會(huì)進(jìn)入這個(gè)判斷,更新ra的值,然后預(yù)讀特定的范圍的頁(yè)
//異步預(yù)讀的調(diào)用表示Readahead出來的頁(yè)連續(xù)命中
if(hit_readahead_marker){
pgoff_tstart;
rcu_read_lock();
//這個(gè)函數(shù)用于找到offset+1開始到offset+1+max_pages這個(gè)范圍內(nèi),第一個(gè)不在pagecache的頁(yè)的index
start=page_cache_next_miss(mapping,offset+1,max_pages);
rcu_read_unlock();
if(!start||start-offset>max_pages)
return0;
ra->start=start;
ra->size=start-offset;/*oldasync_size*/
ra->size+=req_size;
//由于連續(xù)命中,get_next_ra_size會(huì)加倍上次的預(yù)讀頁(yè)數(shù)
//第一次預(yù)讀了4個(gè)頁(yè)
//第二次命中以后,預(yù)讀8個(gè)頁(yè)
//第三次命中以后,預(yù)讀16個(gè)頁(yè)
//第四次命中以后,預(yù)讀32個(gè)頁(yè),達(dá)到默認(rèn)情況下最大的讀取頁(yè)數(shù)
//第五次、第六次、第N次命中都是預(yù)讀32個(gè)頁(yè)
ra->size=get_next_ra_size(ra,max_pages);
ra->async_size=ra->size;
gotoreadit;
........省略.........
return__do_page_cache_readahead(mapping,filp,offset,req_size,0);
}
struct address_space *mapping : 讀取文件對(duì)應(yīng)的 page cache 結(jié)構(gòu)。
struct file_ra_state *ra : 文件對(duì)應(yīng)的預(yù)讀狀態(tài)信息,封裝在 file->f_ra 中。
struct file *filp : 讀取文件對(duì)應(yīng)的 struct file 結(jié)構(gòu)。
pgoff_t offset : 本次請(qǐng)求文件頁(yè)在 page cache 中的索引。(文件頁(yè)偏移)
long req_size : 要完成當(dāng)前讀操作還需要讀取的頁(yè)數(shù)。
在預(yù)讀算法邏輯中,內(nèi)核通過 struct file_ra_state 結(jié)構(gòu)中封裝的文件預(yù)讀信息來判斷文件的讀取是否為順序讀。比如:
通過檢查 ra->prev_pos 和 offset 是否相同,來判斷當(dāng)前請(qǐng)求頁(yè)是否和最近一次請(qǐng)求的頁(yè)相同,如果重復(fù)訪問同一頁(yè),預(yù)讀就會(huì)停止。
通過檢查 ra->prev_pos 和 offset 是否相鄰,來判斷進(jìn)程是否順序讀取文件。如果是順序訪問文件,預(yù)讀就會(huì)增加。
當(dāng)進(jìn)程第一次訪問文件時(shí),并且請(qǐng)求的第一個(gè)文件頁(yè)在文件中的偏移量為 0 時(shí)表示進(jìn)程從頭開始讀取文件,那么內(nèi)核就會(huì)認(rèn)為進(jìn)程想要順序的訪問文件,隨后內(nèi)核就會(huì)從文件的第一頁(yè)開始創(chuàng)建一個(gè)新的當(dāng)前窗口,初始的當(dāng)前窗口總是 2 的次冪,窗口具體大小與進(jìn)程的讀操作所請(qǐng)求的頁(yè)數(shù)有一定的關(guān)系。請(qǐng)求頁(yè)數(shù)越大,當(dāng)前窗口就越大,直到最大值 ra->ra_pages 。
staticunsignedlongget_init_ra_size(unsignedlongsize,unsignedlongmax)
{
unsignedlongnewsize=roundup_pow_of_two(size);
if(newsize<=?max?/?32)
??newsize?=?newsize?*?4;
?else?if?(newsize?<=?max?/?4)
??newsize?=?newsize?*?2;
?else
??newsize?=?max;
?return?newsize;
}
相反,當(dāng)進(jìn)程第一次訪問文件,但是請(qǐng)求頁(yè)在文件中的偏移量不為 0 時(shí),內(nèi)核就會(huì)假定進(jìn)程不準(zhǔn)備順序讀取文件,函數(shù)就會(huì)暫時(shí)禁止預(yù)讀。
一旦內(nèi)核發(fā)現(xiàn)進(jìn)程在當(dāng)前窗口內(nèi)執(zhí)行了順序讀取,那么預(yù)讀窗口就會(huì)被建立,預(yù)讀窗口總是緊挨著當(dāng)前窗口的最后一頁(yè)。
預(yù)讀窗口的大小和當(dāng)前窗口有關(guān),如果已經(jīng)被預(yù)讀的頁(yè)不在 page cache 中(可能內(nèi)存緊張,預(yù)讀頁(yè)被回收),那么預(yù)讀窗口就會(huì)是 當(dāng)前窗口大小 - 2,最小值為 4。否則預(yù)讀窗口就會(huì)是當(dāng)前窗口的4倍或者2倍。
當(dāng)進(jìn)程繼續(xù)順序訪問文件時(shí),最終預(yù)讀窗口就會(huì)變?yōu)楫?dāng)前窗口,隨后新的預(yù)讀窗口就會(huì)被建立,隨著進(jìn)程順序地讀取文件,預(yù)讀會(huì)越來越大,但是內(nèi)核一旦發(fā)現(xiàn)對(duì)于文件的訪問 offset 相對(duì)于上一次的請(qǐng)求頁(yè) ra->prev_pos 不是順序的時(shí)候,當(dāng)前窗口和預(yù)讀窗口就會(huì)被清空,預(yù)讀被暫時(shí)禁止。
當(dāng)內(nèi)核通過以上介紹的預(yù)讀算法確定了預(yù)讀窗口的大小之后,就開始調(diào)用 __do_page_cache_readahead 從磁盤去預(yù)讀指定的頁(yè)數(shù)到 page cache 中。
9.3 __do_page_cache_readahead
unsignedint__do_page_cache_readahead(structaddress_space*mapping,
structfile*filp,pgoff_toffset,unsignedlongnr_to_read,
unsignedlonglookahead_size)
{
structinode*inode=mapping->host;
structpage*page;
unsignedlongend_index;/*Thelastpagewewanttoread*/
intpage_idx;
unsignedintnr_pages=0;
loff_tisize=i_size_read(inode);
end_index=((isize-1)>>PAGE_SHIFT);
/*
*盡可能的一次性分配全部需要預(yù)讀的頁(yè)nr_to_read
*注意這里是盡可能的分配,意思就是能分配多少就分配多少,并不一定要全部分配
*/
for(page_idx=0;page_idxend_index)
break;
.......省略.....
//首先在內(nèi)存中為預(yù)讀數(shù)據(jù)分配物理頁(yè)面
page=__page_cache_alloc(gfp_mask);
if(!page)
break;
//設(shè)置新分配的物理頁(yè)在pagecache中的索引
page->index=page_offset;
//將新分配的物理頁(yè)面加入到pagecache中
list_add(&page->lru,&page_pool);
if(page_idx==nr_to_read-lookahead_size)
//設(shè)置頁(yè)面屬性為PG_readahead后續(xù)會(huì)開啟異步預(yù)讀
SetPageReadahead(page);
nr_pages++;
}
/*
*當(dāng)需要預(yù)讀的頁(yè)面分配完畢之后,開始真正的IO動(dòng)作,從磁盤中讀取
*數(shù)據(jù)填充 page cache 中的緩存頁(yè)。
*/
if(nr_pages)
read_pages(mapping,filp,&page_pool,nr_pages,gfp_mask);
BUG_ON(!list_empty(&page_pool));
out:
returnnr_pages;
}
內(nèi)核調(diào)用 read_pages 方法激活磁盤塊設(shè)備驅(qū)動(dòng)程序從磁盤中讀取文件數(shù)據(jù)之前,需要為本次進(jìn)程讀取請(qǐng)求所需要的所有頁(yè)面盡可能地一次性全部分配,如果不能一次性分配全部頁(yè)面,預(yù)讀操作就只在分配好的緩存頁(yè)面上進(jìn)行,也就是說只從磁盤中讀取數(shù)據(jù)填充已經(jīng)分配好的頁(yè)面。
10. JDK NIO 對(duì)普通文件的寫入
注意:下面的例子并不是最佳實(shí)踐,之所以這里引入 HeapByteBuffer 是為了將上篇文章的內(nèi)容和本文銜接起來。事實(shí)上,對(duì)于 IO 的操作一般都會(huì)選擇 DirectByteBuffer ,關(guān)于 DirectByteBuffer 的相關(guān)內(nèi)容筆者會(huì)在后面的文章中詳細(xì)為大家介紹。
FileChannelfileChannel=newRandomAccessFile(newFile("file-read-write.txt"),"rw").getChannel();
ByteBufferheapByteBuffer=ByteBuffer.allocate(4096);
fileChannel.write(heapByteBuffer);
在對(duì)文件進(jìn)行讀寫之前,我們需要首先利用 RandomAccessFile 在內(nèi)核中打開指定的文件 file-read-write.txt ,并獲取到它的文件描述符 fd = 5000。
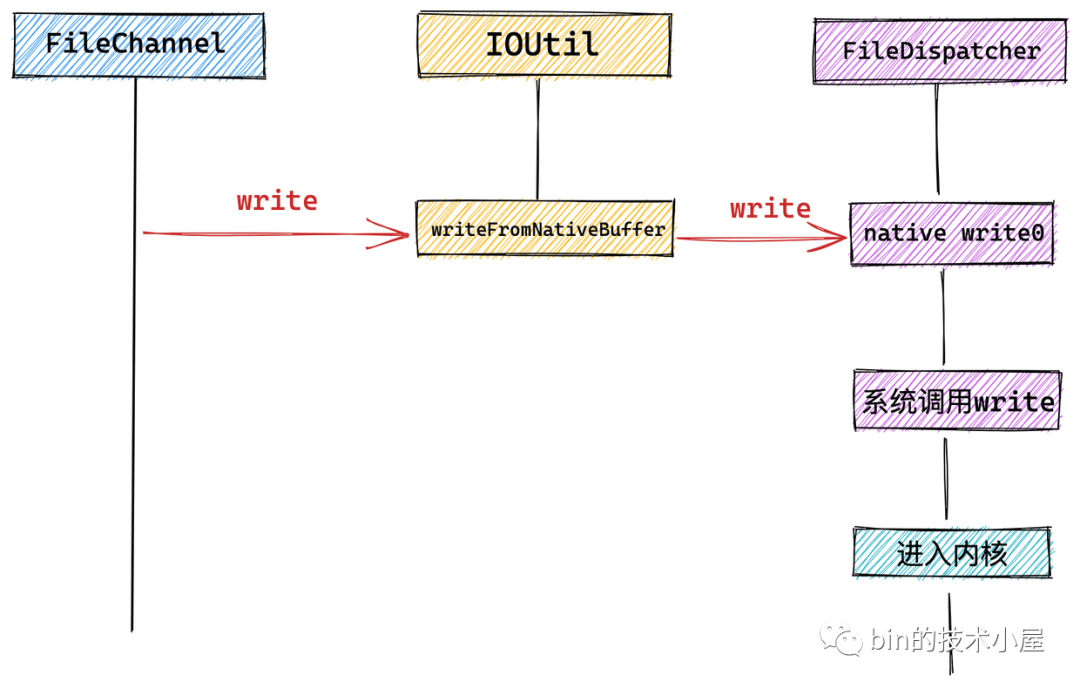
本例 heapByteBuffer 中存放著需要寫入文件的內(nèi)容,隨后來到 FileChannelImpl 實(shí)現(xiàn)類調(diào)用 IOUtil 觸發(fā)底層系統(tǒng)調(diào)用 write 來寫入文件。
publicclassFileChannelImplextendsFileChannel{
//前邊介紹打開的文件描述符5000
privatefinalFileDescriptorfd;
//NIO中用它來觸發(fā)nativeread和write的系統(tǒng)調(diào)用
privatefinalFileDispatchernd;
//讀寫文件時(shí)加鎖,前邊介紹FileChannel的讀寫方法均是線程安全的
privatefinalObjectpositionLock=newObject();
publicintwrite(ByteBuffersrc)throwsIOException{
ensureOpen();
if(!writable)
thrownewNonWritableChannelException();
synchronized(positionLock){
//寫入的字節(jié)數(shù)
intn=0;
try{
......省略......
if(!isOpen())
return0;
do{
n=IOUtil.write(fd,src,-1,nd);
}while((n==IOStatus.INTERRUPTED)&&isOpen());
//返回寫入的字節(jié)數(shù)
returnIOStatus.normalize(n);
}finally{
......省略......
}
}
}
}
NIO 中的所有 IO 操作全部封裝在 IOUtil 類中,而 NIO 中的 SocketChannel 以及這里介紹的 FileChannel 底層依賴的系統(tǒng)調(diào)用可能不同,這里會(huì)通過 NativeDispatcher 對(duì)具體 Channel 操作實(shí)現(xiàn)分發(fā),調(diào)用具體的系統(tǒng)調(diào)用。對(duì)于 FileChannel 來說 NativeDispatcher 的實(shí)現(xiàn)類為 FileDispatcher。對(duì)于 SocketChannel 來說 NativeDispatcher 的實(shí)現(xiàn)類為 SocketDispatcher。
publicclassIOUtil{
staticintwrite(FileDescriptorfd,ByteBuffersrc,longposition,
NativeDispatchernd)
throwsIOException
{
//標(biāo)記傳遞進(jìn)來的heapByteBuffer的position位置用于后續(xù)恢復(fù)
intpos=src.position();
//獲取heapByteBuffer的limit用于計(jì)算寫入字節(jié)數(shù)
intlim=src.limit();
assert(pos<=?lim);
????????//?寫入的字節(jié)數(shù)
????????int?rem?=?(pos?<=?lim???lim?-?pos?:?0);
????????//?創(chuàng)建臨時(shí)的?DirectByteBuffer,用于通過系統(tǒng)調(diào)用?write?寫入數(shù)據(jù)到內(nèi)核
????????ByteBuffer?bb?=?Util.getTemporaryDirectBuffer(rem);
????????try?{
????????????//?將?heapByteBuffer?中的內(nèi)容拷貝到臨時(shí)?DirectByteBuffer?中
????????????bb.put(src);
????????????//?DirectByteBuffer?切換為讀模式,用于后續(xù)發(fā)送數(shù)據(jù)
????????????bb.flip();
????????????//?恢復(fù)?heapByteBuffer?中的?position
????????????src.position(pos);
????????????int?n?=?writeFromNativeBuffer(fd,?bb,?position,?nd);
????????????if?(n?>0){
//此時(shí)heapByteBuffer中的內(nèi)容已經(jīng)發(fā)送完畢,更新它的postion+n
//這里表達(dá)的語(yǔ)義是從heapByteBuffer中讀取了n個(gè)字節(jié)并發(fā)送成功
src.position(pos+n);
}
//返回發(fā)送成功的字節(jié)數(shù)
returnn;
}finally{
//釋放臨時(shí)創(chuàng)建的DirectByteBuffer
Util.offerFirstTemporaryDirectBuffer(bb);
}
}
privatestaticintwriteFromNativeBuffer(FileDescriptorfd,ByteBufferbb,
longposition,NativeDispatchernd)
throwsIOException
{
intpos=bb.position();
intlim=bb.limit();
assert(pos<=?lim);
????????//?要發(fā)送的字節(jié)數(shù)
????????int?rem?=?(pos?<=?lim???lim?-?pos?:?0);
????????int?written?=?0;
????????if?(rem?==?0)
????????????return?0;
????????if?(position?!=?-1)?{
?????????????........省略.......
????????}?else?{
????????????written?=?nd.write(fd,?((DirectBuffer)bb).address()?+?pos,?rem);
????????}
????????if?(written?>0)
//發(fā)送完畢之后更新DirectByteBuffer的position
bb.position(pos+written);
//返回寫入的字節(jié)數(shù)
returnwritten;
}
}
在 IOUtil 中首先創(chuàng)建一個(gè)臨時(shí)的 DirectByteBuffer,然后將本例中 HeapByteBuffer 中的數(shù)據(jù)全部拷貝到這個(gè)臨時(shí)的 DirectByteBuffer 中。這個(gè) DirectByteBuffer 就是我們?cè)?IO 系統(tǒng)調(diào)用中經(jīng)常提到的用戶空間緩沖區(qū)。
隨后在 writeFromNativeBuffer 方法中通過 FileDispatcher 觸發(fā) JNI 層的native 方法執(zhí)行底層系統(tǒng)調(diào)用 write 。
classFileDispatcherImplextendsFileDispatcher{
intwrite(FileDescriptorfd,longaddress,intlen)throwsIOException{
returnwrite0(fd,address,len);
}
staticnativeintwrite0(FileDescriptorfd,longaddress,intlen)
throwsIOException;
}
NIO 中關(guān)于文件 IO 相關(guān)的系統(tǒng)調(diào)用全部封裝在 JNI 層中的 FileDispatcherImpl.c 文件中。里邊定義了各種 IO 相關(guān)的系統(tǒng)調(diào)用的 native 方法。
//FileDispatcherImpl.c文件
JNIEXPORTjintJNICALL
Java_sun_nio_ch_FileDispatcherImpl_write0(JNIEnv*env,jclassclazz,
jobjectfdo,jlongaddress,jintlen)
{
jintfd=fdval(env,fdo);
void*buf=(void*)jlong_to_ptr(address);
//發(fā)起write系統(tǒng)調(diào)用進(jìn)入內(nèi)核
returnconvertReturnVal(env,write(fd,buf,len),JNI_FALSE);
}
系統(tǒng)調(diào)用 write 在內(nèi)核中的定義如下所示:
SYSCALL_DEFINE3(write,unsignedint,fd,constchar__user*,buf,
size_t,count)
{
structfdf=fdget_pos(fd);
......
loff_tpos=file_pos_read(f.file);
ret=vfs_write(f.file,buf,count,&pos);
......
}
現(xiàn)在我們就從用戶空間的 JDK NIO 這一層逐步來到了內(nèi)核空間的邊界處 --- OS 系統(tǒng)調(diào)用 write 這里,馬上就要進(jìn)入內(nèi)核了。
這一次我們來看一下當(dāng)系統(tǒng)調(diào)用 write 發(fā)起之后,用戶進(jìn)程在內(nèi)核態(tài)具體做了哪些事情?
11. 從內(nèi)核角度探秘文件寫入本質(zhì)
現(xiàn)在讓我們?cè)俅芜M(jìn)入內(nèi)核,來看一下內(nèi)核中具體是如何處理文件寫入操作的,這個(gè)過程會(huì)比文件讀取要復(fù)雜很多,大家需要有點(diǎn)耐心~~
再次強(qiáng)調(diào)一下,本文所舉示例中用到的 HeapByteBuffer 只是為了與上篇文章 《一步一圖帶你深入剖析 JDK NIO ByteBuffer 在不同字節(jié)序下的設(shè)計(jì)與實(shí)現(xiàn)》介紹的內(nèi)容做出呼應(yīng),并不是最佳實(shí)踐。筆者會(huì)在后續(xù)的文章中一步一步為大家展開這塊內(nèi)容的最佳實(shí)踐。
11.1 Buffered IO
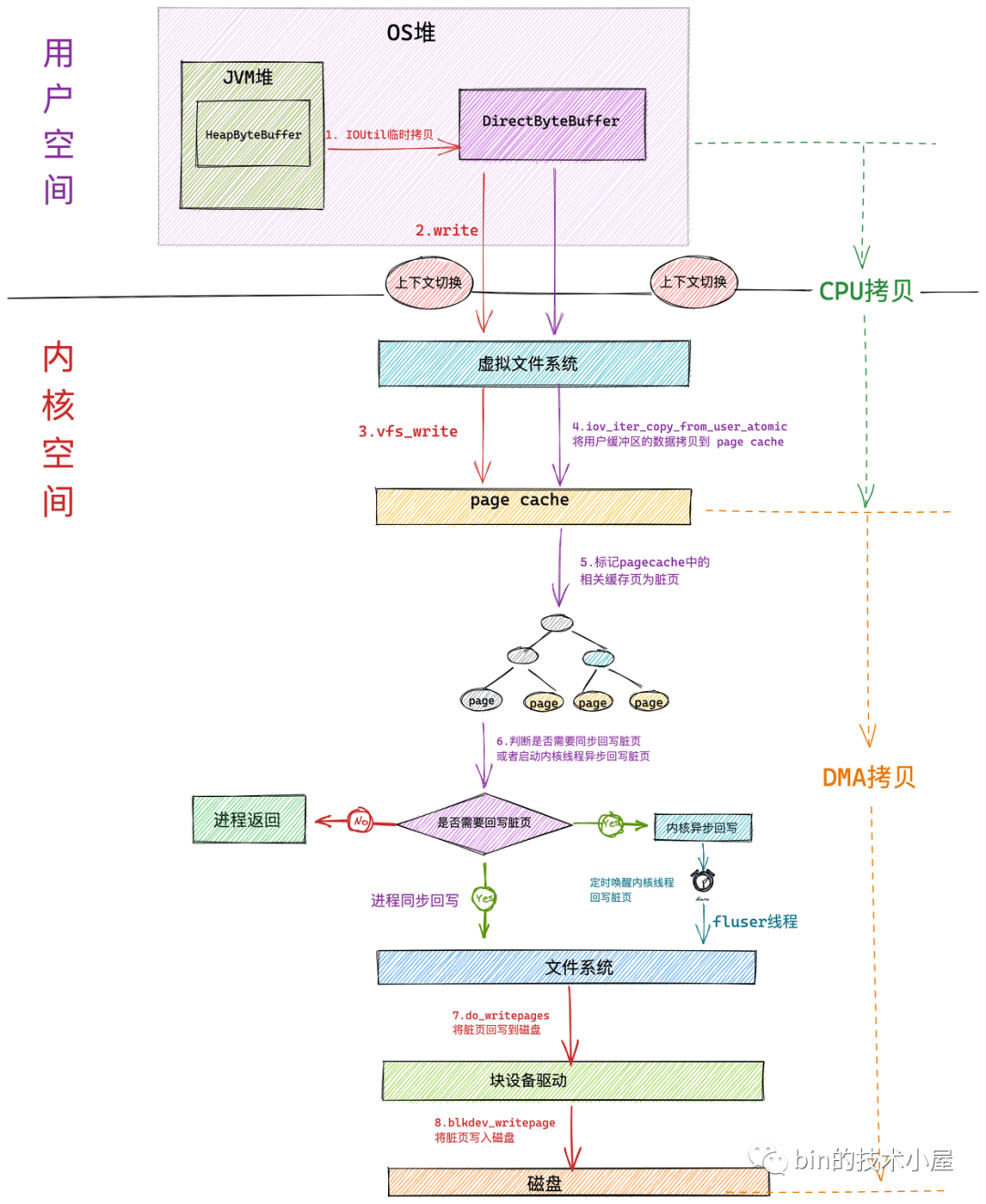
使用 JDK NIO 中的 HeapByteBuffer 在對(duì)文件進(jìn)行寫入的過程,主要分為如下幾個(gè)核心步驟:
首先會(huì)在用戶空間的 JDK 層將位于 JVM 堆中的 HeapByteBuffer 中的待寫入數(shù)據(jù)拷貝到位于 OS 堆中的 DirectByteBuffer 中。這里發(fā)生第一次拷貝
隨后 NIO 會(huì)在用戶態(tài)通過系統(tǒng)調(diào)用 write 發(fā)起文件寫入的請(qǐng)求,此時(shí)發(fā)生第一次上下文切換。
隨后用戶進(jìn)程進(jìn)入內(nèi)核態(tài),在虛擬文件系統(tǒng)層調(diào)用 vfs_write 觸發(fā)對(duì) page cache 寫入的操作。相關(guān)操作封裝在 generic_perform_write 函數(shù)中。這個(gè)后面筆者會(huì)細(xì)講,這里我們只關(guān)注核心總體流程。
內(nèi)核調(diào)用 iov_iter_copy_from_user_atomic 函數(shù)將用戶空間緩沖區(qū) DirectByteBuffer 中的待寫入數(shù)據(jù)拷貝到 page cache 中。發(fā)生第二次拷貝動(dòng)作,這里的操作就是我們常說的 CPU 拷貝。
當(dāng)待寫入數(shù)據(jù)拷貝到 page cache 中時(shí),內(nèi)核會(huì)將對(duì)應(yīng)的文件頁(yè)標(biāo)記為臟頁(yè)。
臟頁(yè)表示內(nèi)存中的數(shù)據(jù)要比磁盤中對(duì)應(yīng)文件數(shù)據(jù)要新。
此時(shí)內(nèi)核會(huì)根據(jù)一定的閾值判斷是否要對(duì) page cache 中的臟頁(yè)進(jìn)行回寫,如果不需要同步回寫,進(jìn)程直接返回。文件寫入操作完成。這里發(fā)生第二次上下文切換
從這里我們看到在對(duì)文件進(jìn)行寫入時(shí),內(nèi)核只會(huì)將數(shù)據(jù)寫入到 page cache 中。整個(gè)寫入過程就完成了,并不會(huì)寫到磁盤中。
臟頁(yè)回寫又會(huì)根據(jù)臟頁(yè)數(shù)量在內(nèi)存中的占比分為:進(jìn)程同步回寫和內(nèi)核異步回寫。當(dāng)臟頁(yè)太多了,進(jìn)程自己都看不下去的時(shí)候,會(huì)同步回寫內(nèi)存中的臟頁(yè),直到回寫完畢才會(huì)返回。在回寫的過程中會(huì)發(fā)生第三次拷貝,通過DMA 將 page cache 中的臟頁(yè)寫入到磁盤中。
所謂內(nèi)核異步回寫就是內(nèi)核會(huì)定時(shí)喚醒一個(gè) flusher 線程,定時(shí)將內(nèi)存中的臟頁(yè)回寫到磁盤中。這部分的內(nèi)容筆者會(huì)在后續(xù)的章節(jié)中詳細(xì)講解。
在 NIO 使用 HeapByteBuffer 在對(duì)文件進(jìn)行寫入的過程中,一般只會(huì)發(fā)生兩次拷貝動(dòng)作和兩次上下文切換,因?yàn)閮?nèi)核將數(shù)據(jù)拷貝到 page cache 中后,文件寫入過程就結(jié)束了。如果臟頁(yè)在內(nèi)存中的占比太高了,達(dá)到了進(jìn)程同步回寫的閾值,那么就會(huì)發(fā)生第三次 DMA 拷貝,將臟頁(yè)數(shù)據(jù)回寫到磁盤文件中。
如果進(jìn)程需要同步回寫臟頁(yè)數(shù)據(jù)時(shí),在本例中是要發(fā)生三次拷貝動(dòng)作。但一般情況下,在本例中只會(huì)發(fā)生兩次,沒有第三次的 DMA 拷貝。
11.2 Direct IO
在 JDK 10 中我們可以通過如下的方式采用 Direct IO 模式打開文件:
FileChannelfc=FileChannel.open(p,StandardOpenOption.WRITE, ExtendedOpenOption.DIRECT)
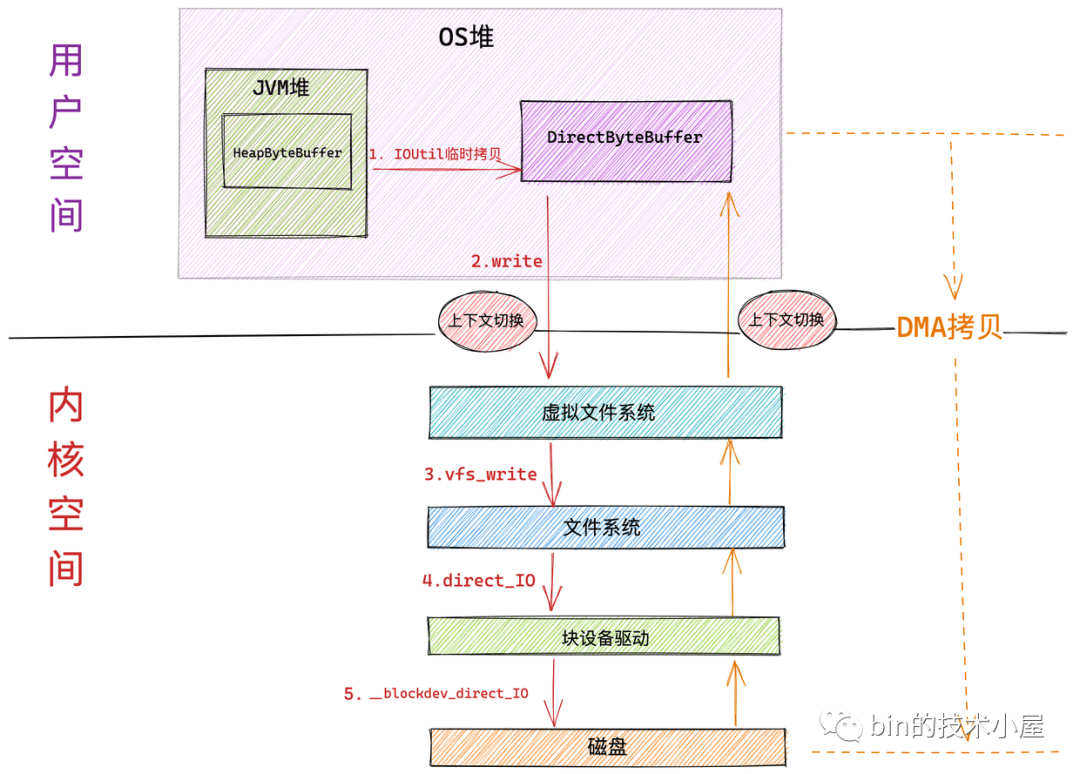
在 Direct IO 模式下的文件寫入操作最明顯的特點(diǎn)就是繞過 page cache 直接通過 DMA 拷貝將用戶空間緩沖區(qū) DirectByteBuffer 中的待寫入數(shù)據(jù)寫入到磁盤中。
同樣發(fā)生兩次上下文切換、
在本例中只會(huì)發(fā)生兩次數(shù)據(jù)拷貝,第一次是將 JVM 堆中的 HeapByteBuffer 中的待寫入數(shù)據(jù)拷貝到位于 OS 堆中的 DirectByteBuffer 中。第二次則是 DMA 拷貝,將用戶空間緩沖區(qū) DirectByteBuffer 中的待寫入數(shù)據(jù)寫入到磁盤中。
12. Talk is cheap ! show you the code
下面是系統(tǒng)調(diào)用 write 在內(nèi)核中的完整定義:
SYSCALL_DEFINE3(write,unsignedint,fd,constchar__user*,buf,
size_t,count)
{
//根據(jù)文件描述符獲取文件對(duì)應(yīng)的structfile結(jié)構(gòu)
structfdf=fdget_pos(fd);
......
//獲取當(dāng)前文件的寫入位置offset
loff_tpos=file_pos_read(f.file);
//進(jìn)入虛擬文件系統(tǒng)層,執(zhí)行具體的文件寫入操作
ret=vfs_write(f.file,buf,count,&pos);
......
}
這里和文件讀取的流程基本一樣,也是通過 vfs_write 進(jìn)入虛擬文件系統(tǒng)層。
ssize_t__vfs_write(structfile*file,constchar__user*p,size_tcount,
loff_t*pos)
{
if(file->f_op->write)
returnfile->f_op->write(file,p,count,pos);
elseif(file->f_op->write_iter)
returnnew_sync_write(file,p,count,pos);
else
return-EINVAL;
}
在虛擬文件系統(tǒng)層,通過 struct file 中定義的函數(shù)指針 file_operations 在具體的文件系統(tǒng)中執(zhí)行相應(yīng)的文件 IO 操作。我們還是以 ext4 文件系統(tǒng)為例。
structfile{
conststructfile_operations*f_op;
}
在 ext4 文件系統(tǒng)中 .write_iter 函數(shù)指針指向的是 ext4_file_write_iter 函數(shù)執(zhí)行具體的文件寫入操作。
conststructfile_operationsext4_file_operations={
......省略........
.read_iter=ext4_file_read_iter,
.write_iter=ext4_file_write_iter,
......省略.........
}
由于 ext4_file_operations 中只定義了 .write_iter 函數(shù)指針,所以在 __vfs_write 函數(shù)中流程進(jìn)入 else if {......} 分支來到 new_sync_write 函數(shù)中:
staticssize_tnew_sync_write(structfile*filp,constchar__user*buf,size_tlen,loff_t*ppos)
{
//將DirectByteBuffer以及要寫入的字節(jié)數(shù)封裝進(jìn)iovec結(jié)構(gòu)體中
structioveciov={.iov_base=(void__user*)buf,.iov_len=len};
//用來封裝文件 IO 相關(guān)操作的狀態(tài)和進(jìn)度信息:
structkiocbkiocb;
//用來封裝用用戶緩存區(qū)DirectByteBuffer的相關(guān)的信息
structiov_iteriter;
ssize_tret;
//利用文件structfile初始化kiocb結(jié)構(gòu)體
init_sync_kiocb(&kiocb,filp);
//設(shè)置文件寫入偏移位置
kiocb.ki_pos=(ppos?*ppos:0);
iov_iter_init(&iter,WRITE,&iov,1,len);
//調(diào)用ext4_file_write_iter
ret=call_write_iter(filp,&kiocb,&iter);
BUG_ON(ret==-EIOCBQUEUED);
if(ret>0&&ppos)
*ppos=kiocb.ki_pos;
returnret;
}
在文件讀取的相關(guān)章節(jié)中,我們介紹了用于封裝傳遞進(jìn)來的用戶空間緩沖區(qū) DirectByteBuffer 相關(guān)信息的 struct iovec 結(jié)構(gòu)體,也介紹了用于封裝文件 IO 相關(guān)操作的狀態(tài)和進(jìn)度信息的 struct kiocb 結(jié)構(gòu)體,這里筆者不在贅述。
不過在這里筆者還是想強(qiáng)調(diào)的一下,內(nèi)核中一般會(huì)使用 struct iov_iter 結(jié)構(gòu)體對(duì) struct iovec 進(jìn)行包裝,iov_iter 中包含多個(gè) iovec。
structiov_iter{
......省略.....
conststructiovec*iov;
}
這是為了兼容 readv() ,writev() 等系統(tǒng)調(diào)用,它允許用戶使用多個(gè)緩存區(qū)去讀取文件中的數(shù)據(jù)或者從多個(gè)緩沖區(qū)中寫入數(shù)據(jù)到文件中。
JDK NIO Channel 支持的 Scatter 操作底層原理就是 readv 系統(tǒng)調(diào)用。
JDK NIO Channel 支持的 Gather 操作底層原理就是 writev 系統(tǒng)調(diào)用。
FileChannelfileChannel=newRandomAccessFile(newFile("file-read-write.txt"),"rw").getChannel();
ByteBufferheapByteBuffer1=ByteBuffer.allocate(4096);
ByteBufferheapByteBuffer2=ByteBuffer.allocate(4096);
ByteBuffer[]gather={heapByteBuffer1,heapByteBuffer2};
fileChannel.write(gather);
最終在 call_write_iter 中觸發(fā) ext4_file_write_iter 的調(diào)用,從虛擬文件系統(tǒng)層進(jìn)入到具體文件系統(tǒng) ext4 中。
staticinlinessize_tcall_write_iter(structfile*file,structkiocb*kio,
structiov_iter*iter)
{
returnfile->f_op->write_iter(kio,iter);
}
staticssize_t
ext4_file_write_iter(structkiocb*iocb,structiov_iter*from)
{
..........省略..........
ret=__generic_file_write_iter(iocb,from);
returnret;
}
我們看到在文件系統(tǒng) ext4 中調(diào)用的是 __generic_file_write_iter 方法。內(nèi)核針對(duì)文件寫入的所有邏輯都封裝在這里。
ssize_t__generic_file_write_iter(structkiocb*iocb,structiov_iter*from)
{
structfile*file=iocb->ki_filp;
structaddress_space*mapping=file->f_mapping;
structinode*inode=mapping->host;
ssize_twritten=0;
ssize_terr;
ssize_tstatus;
........省略基本校驗(yàn)邏輯和更新文件原數(shù)據(jù)邏輯........
if(iocb->ki_flags&IOCB_DIRECT){
loff_tpos,endbyte;
//DirectIO
written=generic_file_direct_write(iocb,from);
.......省略......
}else{
//BufferedIO
written=generic_perform_write(file,from,iocb->ki_pos);
if(likely(written>0))
iocb->ki_pos+=written;
}
.......省略......
//返回寫入文件的字節(jié)數(shù)或者錯(cuò)誤
returnwritten?written:err;
}
這里和我們?cè)诮榻B文件讀取時(shí)候提到的 generic_file_read_iter 函數(shù)中的邏輯是一樣的。都會(huì)處理 Direct IO 和 Buffered IO 的場(chǎng)景。
這里對(duì)于 Direct IO 的處理都是一樣的,在 generic_file_direct_write 中也是會(huì)調(diào)用 address_space 中的 address_space_operations 定義的 .direct_IO 函數(shù)指針來繞過 page cache 直接寫入磁盤。
structaddress_space{
conststructaddress_space_operations*a_ops;
}
written=mapping->a_ops->direct_IO(iocb,from);
在 ext4 文件系統(tǒng)中實(shí)現(xiàn) Direct IO 的函數(shù)是 ext4_direct_IO,這里直接會(huì)調(diào)用到塊設(shè)備驅(qū)動(dòng)層,通過 do_blockdev_direct_IO 直接將用戶空間緩沖區(qū) DirectByteBuffer 中的內(nèi)容寫入磁盤中。do_blockdev_direct_IO 函數(shù)會(huì)等到所有的 Direct IO 寫入到磁盤之后才會(huì)返回。
staticconststructaddress_space_operationsext4_aops={
.direct_IO=ext4_direct_IO,
};
Direct IO 是由 DMA 直接從用戶空間緩沖區(qū) DirectByteBuffer 中拷貝到磁盤中。
下面我們主要介紹下 Buffered IO 的寫入邏輯 generic_perform_write 方法。
12.1 Buffered IO
ssize_tgeneric_perform_write(structfile*file,
structiov_iter*i,loff_tpos)
{
//獲取 page cache。數(shù)據(jù)將會(huì)被寫入到這里
structaddress_space*mapping=file->f_mapping;
//獲取pagecache相關(guān)的操作函數(shù)
conststructaddress_space_operations*a_ops=mapping->a_ops;
longstatus=0;
ssize_twritten=0;
unsignedintflags=0;
do{
//用于引用要寫入的文件頁(yè)
structpage*page;
//要寫入的文件頁(yè)在pagecache中的index
unsignedlongoffset;/*Offsetintopagecachepage*/
unsignedlongbytes;/*Bytestowritetopage*/
size_tcopied;/*Bytescopiedfromuser*/
offset=(pos&(PAGE_SIZE-1));
bytes=min_t(unsignedlong,PAGE_SIZE-offset,
iov_iter_count(i));
again:
//檢查用戶空間緩沖區(qū)DirectByteBuffer地址是否有效
if(unlikely(iov_iter_fault_in_readable(i,bytes))){
status=-EFAULT;
break;
}
//從pagecache中獲取要寫入的文件頁(yè)并準(zhǔn)備記錄文件元數(shù)據(jù)日志工作
status=a_ops->write_begin(file,mapping,pos,bytes,flags,
&page,&fsdata);
//將用戶空間緩沖區(qū)DirectByteBuffer中的數(shù)據(jù)拷貝到pagecache中的文件頁(yè)中
copied=iov_iter_copy_from_user_atomic(page,i,offset,bytes);
flush_dcache_page(page);
//將寫入的文件頁(yè)標(biāo)記為臟頁(yè)并完成文件元數(shù)據(jù)日志的寫入
status=a_ops->write_end(file,mapping,pos,bytes,copied,
page,fsdata);
//更新文件ppos
pos+=copied;
written+=copied;
//判斷是否需要回寫臟頁(yè)
balance_dirty_pages_ratelimited(mapping);
}while(iov_iter_count(i));
//返回寫入字節(jié)數(shù)
returnwritten?written:status;
}
由于本文中筆者是以 ext4 文件系統(tǒng)為例來介紹文件的讀寫流程,本小節(jié)中介紹的文件寫入流程涉及到與文件系統(tǒng)相關(guān)的兩個(gè)操作:write_begin,write_end。這兩個(gè)函數(shù)在不同的文件系統(tǒng)中都有不同的實(shí)現(xiàn),在不同的文件系統(tǒng)中,寫入每一個(gè)文件頁(yè)都需要調(diào)用一次 write_begin,write_end 這兩個(gè)方法。
staticconststructaddress_space_operationsext4_aops={
......省略.......
.write_begin=ext4_write_begin,
.write_end=ext4_write_end,
......省略.......
}
下圖為本文中涉及文件讀寫的所有內(nèi)核數(shù)據(jù)結(jié)構(gòu)圖:
經(jīng)過前邊介紹文件讀取的章節(jié)我們知道在讀取文件的時(shí)候都是先從 page cache 中讀取,如果 page cache 正好緩存了文件頁(yè)就直接返回。如果沒有在進(jìn)行磁盤 IO。
文件的寫入過程也是一樣,內(nèi)核會(huì)將用戶緩沖區(qū) DirectByteBuffer 中的待寫數(shù)據(jù)先拷貝到 page cache 中,寫完就直接返回。后續(xù)內(nèi)核會(huì)根據(jù)一定的規(guī)則把這些文件頁(yè)回寫到磁盤中。
從這個(gè)過程我們可以看出,內(nèi)核將數(shù)據(jù)先是寫入 page cache 中但是不會(huì)立刻寫入磁盤中,如果突然斷電或者系統(tǒng)崩潰就可能導(dǎo)致文件系統(tǒng)處于不一致的狀態(tài)。
為了解決這種場(chǎng)景,于是 linux 內(nèi)核引入了 ext3 , ext4 等日志文件系統(tǒng)。而日志文件系統(tǒng)比非日志文件系統(tǒng)在磁盤中多了一塊 Journal 區(qū)域,Journal 區(qū)域就是存放管理文件元數(shù)據(jù)和文件數(shù)據(jù)操作日志的磁盤區(qū)域。
文件元數(shù)據(jù)的日志用于恢復(fù)文件系統(tǒng)的一致性。
文件數(shù)據(jù)的日志用于防止系統(tǒng)故障造成的文件內(nèi)容損壞,
ext3 , ext4 等日志文件系統(tǒng)分為三種模式,我們可以在掛載的時(shí)候選擇不同的模式。
日志模式(Journal 模式):這種模式在將數(shù)據(jù)寫入文件系統(tǒng)前,必須等待元數(shù)據(jù)和數(shù)據(jù)的日志已經(jīng)落盤才能發(fā)揮作用。這樣性能比較差,但是最安全。
順序模式(Order 模式):在 Order 模式不會(huì)記錄數(shù)據(jù)的日志,只會(huì)記錄元數(shù)據(jù)的日志,但是在寫元數(shù)據(jù)的日志前,必須先確保數(shù)據(jù)已經(jīng)落盤。這樣可以減少文件內(nèi)容損壞的機(jī)會(huì),這種模式是對(duì)性能的一種折中,是默認(rèn)模式。
回寫模式(WriteBack 模式):WriteBack 模式 和 Order 模式一樣它們都不會(huì)記錄數(shù)據(jù)的日志,只會(huì)記錄元數(shù)據(jù)的日志,不同的是在 WriteBack 模式下不會(huì)保證數(shù)據(jù)比元數(shù)據(jù)先落盤。這個(gè)性能最好,但是最不安全。
而 write_begin,write_end 正是對(duì)文件系統(tǒng)中相關(guān)日志的操作,在 ext4 文件系統(tǒng)中對(duì)應(yīng)的是 ext4_write_begin,ext4_write_end。下面我們就來看一下在 Buffered IO 模式下對(duì)于 ext4 文件系統(tǒng)中的文件寫入的核心步驟。
12.2 ext4_write_begin
staticintext4_write_begin(structfile*file,structaddress_space*mapping,
loff_tpos,unsignedlen,unsignedflags,
structpage**pagep,void**fsdata)
{
structinode*inode=mapping->host;
structpage*page;
pgoff_tindex;
...........省略.......
retry_grab:
//從pagecache中查找要寫入文件頁(yè)
page=grab_cache_page_write_begin(mapping,index,flags);
if(!page)
return-ENOMEM;
unlock_page(page);
retry_journal:
//相關(guān)日志的準(zhǔn)備工作
handle=ext4_journal_start(inode,EXT4_HT_WRITE_PAGE,needed_blocks);
...........省略.......
在寫入文件數(shù)據(jù)之前,內(nèi)核在 ext4_write_begin 方法中調(diào)用 ext4_journal_start 方法做一些相關(guān)日志的準(zhǔn)備工作。
還有一個(gè)重要的事情是在 grab_cache_page_write_begin 方法中從 page cache 中根據(jù) index 查找要寫入數(shù)據(jù)的文件緩存頁(yè)。
structpage*grab_cache_page_write_begin(structaddress_space*mapping,
pgoff_tindex,unsignedflags)
{
structpage*page;
intfgp_flags=FGP_LOCK|FGP_WRITE|FGP_CREAT;
//在pagecache中查找寫入數(shù)據(jù)的緩存頁(yè)
page=pagecache_get_page(mapping,index,fgp_flags,
mapping_gfp_mask(mapping));
if(page)
wait_for_stable_page(page);
returnpage;
}
通過 pagecache_get_page 在 page cache 中查找要寫入數(shù)據(jù)的緩存頁(yè)。如果緩存頁(yè)不在 page cache 中,內(nèi)核則會(huì)首先會(huì)在物理內(nèi)存中分配一個(gè)內(nèi)存頁(yè),然后將新分配的內(nèi)存頁(yè)加入到 page cache 中。
相關(guān)的查找過程筆者已經(jīng)在 《8. page cache 中查找緩存頁(yè)》小節(jié)中詳細(xì)介紹過了,這里不在贅述。
12.3 iov_iter_copy_from_user_atomic
這里就是寫入過程的關(guān)鍵所在,圖中描述的 CPU 拷貝是將用戶空間緩存區(qū) DirectByteBuffer 中的待寫入數(shù)據(jù)拷貝到內(nèi)核里的 page cache 中,這個(gè)過程就發(fā)生在這里。
size_tiov_iter_copy_from_user_atomic(structpage*page,
structiov_iter*i,unsignedlongoffset,size_tbytes)
{
//將緩存頁(yè)臨時(shí)映射到內(nèi)核虛擬地址空間的高端地址上
char*kaddr=kmap_atomic(page),
*p=kaddr+offset;
//將用戶緩存區(qū)DirectByteBuffer中的待寫入數(shù)據(jù)拷貝到文件緩存頁(yè)中
iterate_all_kinds(i,bytes,v,
copyin((p+=v.iov_len)-v.iov_len,v.iov_base,v.iov_len),
memcpy_from_page((p+=v.bv_len)-v.bv_len,v.bv_page,
v.bv_offset,v.bv_len),
memcpy((p+=v.iov_len)-v.iov_len,v.iov_base,v.iov_len)
)
//解除內(nèi)核虛擬地址空間與緩存頁(yè)之間的臨時(shí)映射,這里映射只是為了拷貝數(shù)據(jù)用
kunmap_atomic(kaddr);
returnbytes;
}
但是這里不能直接進(jìn)行拷貝,因?yàn)榇藭r(shí)從 page cache 中取出的緩存頁(yè) page 是物理地址,而在內(nèi)核中是不能夠直接操作物理地址的,只能操作虛擬地址。
那怎么辦呢?所以就需要調(diào)用 kmap_atomic 將緩存頁(yè)臨時(shí)映射到內(nèi)核空間的一段虛擬地址上,然后將用戶空間緩存區(qū) DirectByteBuffer 中的待寫入數(shù)據(jù)通過這段映射的虛擬地址拷貝到 page cache 中的相應(yīng)緩存頁(yè)中。這時(shí)文件的寫入操作就已經(jīng)完成了。
從這里我們看出,內(nèi)核對(duì)于文件的寫入只是將數(shù)據(jù)寫入到 page cache 中就完事了并沒有真正地寫入磁盤。
由于是臨時(shí)映射,所以在拷貝完成之后,調(diào)用 kunmap_atomic 將這段映射再解除掉。
12.4 ext4_write_end
staticintext4_write_end(structfile*file,
structaddress_space*mapping,
loff_tpos,unsignedlen,unsignedcopied,
structpage*page,void*fsdata)
{
handle_t*handle=ext4_journal_current_handle();
structinode*inode=mapping->host;
......省略.......
//將寫入的緩存頁(yè)在pagecache中標(biāo)記為臟頁(yè)
copied=block_write_end(file,mapping,pos,len,copied,page,fsdata);
......省略.......
//完成相關(guān)日志的寫入
ret2=ext4_journal_stop(handle);
......省略.......
}
在這里會(huì)對(duì)文件的寫入流程做一些收尾的工作,比如在 block_write_end 方法中會(huì)調(diào)用 mark_buffer_dirty 將寫入的緩存頁(yè)在 page cache 中標(biāo)記為臟頁(yè)。后續(xù)內(nèi)核會(huì)根據(jù)一定的規(guī)則將 page cache 中的這些臟頁(yè)回寫進(jìn)磁盤中。
具體的標(biāo)記過程筆者已經(jīng)在《7.1 radix_tree 的標(biāo)記》小節(jié)中詳細(xì)介紹過了,這里不在贅述。
另一個(gè)核心的步驟就是調(diào)用 ext4_journal_stop 完成相關(guān)日志的寫入。這里日志也只是會(huì)先寫到緩存里,不會(huì)直接落盤。
12.5 balance_dirty_pages_ratelimited
當(dāng)進(jìn)程將待寫數(shù)據(jù)寫入 page cache 中之后,相應(yīng)的緩存頁(yè)就變?yōu)榱伺K頁(yè),我們需要找一個(gè)時(shí)機(jī)將這些臟頁(yè)回寫到磁盤中。防止斷電導(dǎo)致數(shù)據(jù)丟失。
本小節(jié)我們主要聚焦于臟頁(yè)回寫的主體流程,相應(yīng)細(xì)節(jié)部分以及內(nèi)核對(duì)臟頁(yè)的回寫時(shí)機(jī)我們放在下一小節(jié)中在詳細(xì)為大家介紹。
voidbalance_dirty_pages_ratelimited(structaddress_space*mapping)
{
structinode*inode=mapping->host;
structbacking_dev_info*bdi=inode_to_bdi(inode);
structbdi_writeback*wb=NULL;
intratelimit;
......省略......
if(unlikely(current->nr_dirtied>=ratelimit))
balance_dirty_pages(mapping,wb,current->nr_dirtied);
......省略......
}
在 balance_dirty_pages_ratelimited 會(huì)判斷如果臟頁(yè)數(shù)量在內(nèi)存中達(dá)到了一定的規(guī)模 ratelimit 就會(huì)觸發(fā) balance_dirty_pages 回寫臟頁(yè)邏輯。
staticvoidbalance_dirty_pages(structaddress_space*mapping,
structbdi_writeback*wb,
unsignedlongpages_dirtied)
{
.......根據(jù)內(nèi)核異步回寫閾值判斷是否需要喚醒flusher線程異步回寫臟頁(yè)...
if(nr_reclaimable>gdtc->bg_thresh)
wb_start_background_writeback(wb);
}
如果達(dá)到了臟頁(yè)回寫的條件,那么內(nèi)核就會(huì)喚醒 flusher 線程去將這些臟頁(yè)異步回寫到磁盤中。
voidwb_start_background_writeback(structbdi_writeback*wb)
{
/*
*Wejustwakeuptheflusherthread.Itwillperformbackground
*writebackassoonasthereisnootherworktodo.
*/
wb_wakeup(wb);
}
13. 內(nèi)核回寫臟頁(yè)的觸發(fā)時(shí)機(jī)
經(jīng)過前邊對(duì)文件寫入過程的介紹我們看到,用戶進(jìn)程在對(duì)文件進(jìn)行寫操作的時(shí)候只是將待寫入數(shù)據(jù)從用戶空間的緩沖區(qū) DirectByteBuffer 寫入到內(nèi)核中的 page cache 中就結(jié)束了。后面內(nèi)核會(huì)對(duì)臟頁(yè)進(jìn)行延時(shí)寫入到磁盤中。
當(dāng) page cache 中的緩存頁(yè)比磁盤中對(duì)應(yīng)的文件頁(yè)的數(shù)據(jù)要新時(shí),就稱這些緩存頁(yè)為臟頁(yè)。
延時(shí)寫入的好處就是進(jìn)程可以多次頻繁的對(duì)文件進(jìn)行寫入但都是寫入到 page cache 中不會(huì)有任何磁盤 IO 發(fā)生。隨后內(nèi)核可以將進(jìn)程的這些多次寫入操作轉(zhuǎn)換為一次磁盤 IO ,將這些寫入的臟頁(yè)一次性刷新回磁盤中,這樣就把多次磁盤 IO 轉(zhuǎn)換為一次磁盤 IO 極大地提升文件 IO 的性能。
那么內(nèi)核在什么情況下才會(huì)去觸發(fā) page cache 中的臟頁(yè)回寫呢?
內(nèi)核在初始化的時(shí)候,會(huì)創(chuàng)建一個(gè) timer 定時(shí)器去定時(shí)喚醒內(nèi)核 flusher 線程回寫臟頁(yè)。
當(dāng)內(nèi)存中臟頁(yè)的數(shù)量太多了達(dá)到了一定的比例,就會(huì)主動(dòng)喚醒內(nèi)核中的 flusher 線程去回寫臟頁(yè)。
臟頁(yè)在內(nèi)存中停留的時(shí)間太久了,等到 flusher 線程下一次被喚醒的時(shí)候就會(huì)回寫這些駐留太久的臟頁(yè)。
用戶進(jìn)程可以通過 sync() 回寫內(nèi)存中的所有臟頁(yè)和 fsync() 回寫指定文件的所有臟頁(yè),這些是進(jìn)程主動(dòng)發(fā)起臟頁(yè)回寫請(qǐng)求。
在內(nèi)存比較緊張的情況下,需要回收物理頁(yè)或者將物理頁(yè)中的內(nèi)容 swap 到磁盤上時(shí),如果發(fā)現(xiàn)通過頁(yè)面置換算法置換出來的頁(yè)是臟頁(yè),那么就會(huì)觸發(fā)回寫。
現(xiàn)在我們了解了內(nèi)核回寫臟頁(yè)的一個(gè)大概時(shí)機(jī),這里大家可能會(huì)問了:
內(nèi)核通過 timer 定時(shí)喚醒 flush 線程回寫臟頁(yè),那么到底間隔多久喚醒呢?
內(nèi)存中的臟頁(yè)數(shù)量太多會(huì)觸發(fā)回寫,那么這里的太多指的具體是多少呢?
臟頁(yè)在內(nèi)存中駐留太久也會(huì)觸發(fā)回寫,那么這里的太久指的到底是多久呢?
其實(shí)這三個(gè)問題中涉及到的具體數(shù)值,內(nèi)核都提供了參數(shù)供我們來配置。這些參數(shù)的配置文件存在于 proc/sys/vm 目錄下:
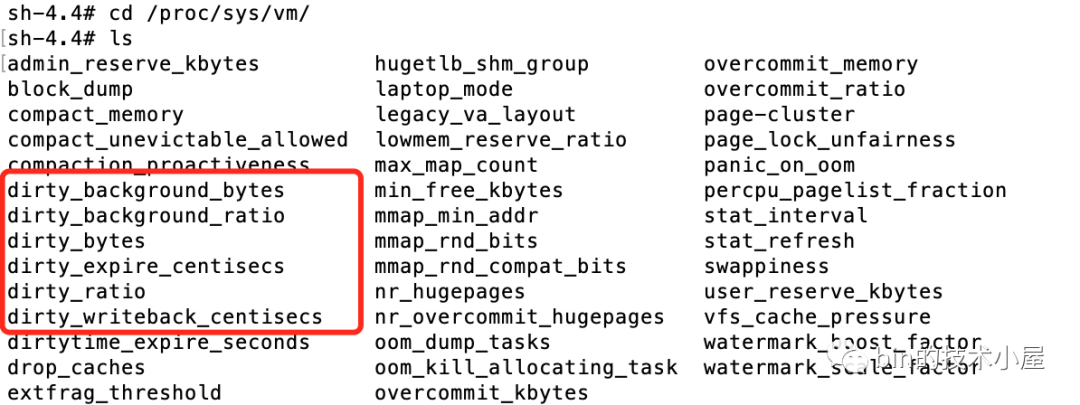
下面筆者就為大家介紹下內(nèi)核回寫臟頁(yè)涉及到的這 6 個(gè)參數(shù),并解答上面我們提出的這三個(gè)問題。
13.1 內(nèi)核中的定時(shí)器間隔多久喚醒 flusher 線程
內(nèi)核中通過 dirty_writeback_centisecs 參數(shù)來配置喚醒 flusher 線程的間隔時(shí)間。

該參數(shù)可以通過修改 /proc/sys/vm/dirty_writeback_centisecs 文件來配置參數(shù),我們也可以通過 sysctl 命令或者通過修改 /etc/sysctl.conf 配置文件來對(duì)這些參數(shù)進(jìn)行修改。
這里我們先主要關(guān)注這些內(nèi)核參數(shù)的含義以及源碼實(shí)現(xiàn),文章后面筆者有一個(gè)專門的章節(jié)來介紹這些內(nèi)核參數(shù)各種不同的配置方式。
dirty_writeback_centisecs 內(nèi)核參數(shù)的默認(rèn)值為 500。單位為 0.01 s。也就是說內(nèi)核會(huì)每隔 5s 喚醒一次 flusher 線程來執(zhí)行相關(guān)臟頁(yè)的回寫。該參數(shù)在內(nèi)核源碼中對(duì)應(yīng)的變量名為 dirty_writeback_interval。
筆者這里在列舉一個(gè)生活中的例子來解釋下這個(gè) dirty_writeback_interval 的作用。
假設(shè)大家的工作都非常繁忙,于是大家就到家政公司請(qǐng)了專門的保潔阿姨(內(nèi)核 flusher 回寫線程)來幫助我們打掃房間衛(wèi)生(回寫臟頁(yè))。你和保潔阿姨約定每周(dirty_writeback_interval)來你房間(內(nèi)存)打掃一次衛(wèi)生(回寫臟頁(yè)),保潔阿姨會(huì)固定每周日按時(shí)來到你房間打掃。記住這個(gè)例子,我們后面還會(huì)用到~~~
13.2 內(nèi)核中如何使用 dirty_writeback_interval 來控制 flusher 喚醒頻率
在磁盤中數(shù)據(jù)是以塊的形式存儲(chǔ)于扇區(qū)中的,前邊在介紹文件讀寫的章節(jié)中,讀寫流程的最后都會(huì)從文件系統(tǒng)層到塊設(shè)備驅(qū)動(dòng)層,由塊設(shè)備驅(qū)動(dòng)程序?qū)?shù)據(jù)寫入對(duì)應(yīng)的磁盤塊中存儲(chǔ)。
內(nèi)存中的文件頁(yè)對(duì)應(yīng)于磁盤中的一個(gè)數(shù)據(jù)塊,而這塊磁盤就是我們常說的塊設(shè)備。而每個(gè)塊設(shè)備在內(nèi)核中對(duì)應(yīng)一個(gè) backing_dev_info 結(jié)構(gòu)用于存儲(chǔ)相關(guān)信息。其中最重要的信息是 workqueue_struct *bdi_wq 用于緩存塊設(shè)備上所有的回寫臟頁(yè)異步任務(wù)的隊(duì)列。
/*bdi_wqservesallasynchronouswritebacktasks*/
structworkqueue_struct*bdi_wq;
staticint__initdefault_bdi_init(void)
{
interr;
//創(chuàng)建bdi_wq隊(duì)列
bdi_wq=alloc_workqueue("writeback",WQ_MEM_RECLAIM|WQ_FREEZABLE|
WQ_UNBOUND|WQ_SYSFS,0);
if(!bdi_wq)
return-ENOMEM;
//初始化backing_dev_info
err=bdi_init(&noop_backing_dev_info);
returnerr;
}
在系統(tǒng)啟動(dòng)的時(shí)候,內(nèi)核會(huì)調(diào)用 default_bdi_init 來創(chuàng)建 bdi_wq 隊(duì)列和初始化 backing_dev_info。
staticintbdi_init(structbacking_dev_info*bdi)
{
intret;
bdi->dev=NULL;
//初始化backing_dev_info相關(guān)信息
kref_init(&bdi->refcnt);
bdi->min_ratio=0;
bdi->max_ratio=100;
bdi->max_prop_frac=FPROP_FRAC_BASE;
INIT_LIST_HEAD(&bdi->bdi_list);
INIT_LIST_HEAD(&bdi->wb_list);
init_waitqueue_head(&bdi->wb_waitq);
//這里會(huì)設(shè)置flusher線程的定時(shí)器timer
ret=cgwb_bdi_init(bdi);
returnret;
}
在 bdi_init 中初始化 backing_dev_info 結(jié)構(gòu)的相關(guān)信息,并在 cgwb_bdi_init 中調(diào)用 wb_init 初始化回寫臟頁(yè)任務(wù) bdi_writeback *wb,并創(chuàng)建一個(gè) timer 用于定時(shí)啟動(dòng) flusher 線程。
staticintwb_init(structbdi_writeback*wb,structbacking_dev_info*bdi,
intblkcg_id,gfp_tgfp)
{
.........初始化bdi_writeback結(jié)構(gòu)該結(jié)構(gòu)表示回寫臟頁(yè)任務(wù)相關(guān)信息.....
//創(chuàng)建timer定時(shí)執(zhí)行flusher線程
INIT_DELAYED_WORK(&wb->dwork,wb_workfn);
......
}
#define__INIT_DELAYED_WORK(_work,_func,_tflags)
do{
INIT_WORK(&(_work)->work,(_func));
__setup_timer(&(_work)->timer,delayed_work_timer_fn,
(unsignedlong)(_work),
bdi_writeback 有個(gè)成員變量 struct delayed_work dwork,bdi_writeback 就是把 delayed_work 結(jié)構(gòu)掛到 bdi_wq 隊(duì)列上的。
而 wb_workfn 函數(shù)則是 flusher 線程要執(zhí)行的回寫核心邏輯,全部封裝在 wb_workfn 函數(shù)中。
/*
*Handlewritebackofdirtydataforthedevicebackedbythisbdi.Also
*reschedulesperiodicallyanddoeskupdatedstyleflushing.
*/
voidwb_workfn(structwork_struct*work)
{
structbdi_writeback*wb=container_of(to_delayed_work(work),
structbdi_writeback,dwork);
longpages_written;
set_worker_desc("flush-%s",bdi_dev_name(wb->bdi));
current->flags|=PF_SWAPWRITE;
.......在循環(huán)中不斷的回寫臟頁(yè)..........
//如果work-list中還有回寫臟頁(yè)的任務(wù),則立即喚醒flush線程
if(!list_empty(&wb->work_list))
wb_wakeup(wb);
//如果回寫任務(wù)已經(jīng)被全部執(zhí)行完畢,但是內(nèi)存中還有臟頁(yè),則延時(shí)喚醒
elseif(wb_has_dirty_io(wb)&&dirty_writeback_interval)
wb_wakeup_delayed(wb);
current->flags&=~PF_SWAPWRITE;
}
在 wb_workfn 中會(huì)不斷的循環(huán)執(zhí)行 work_list 中的臟頁(yè)回寫任務(wù)。當(dāng)這些回寫任務(wù)執(zhí)行完畢之后調(diào)用 wb_wakeup_delayed 延時(shí)喚醒 flusher線程。大家注意到這里的 dirty_writeback_interval 配置項(xiàng)終于出現(xiàn)了,后續(xù)會(huì)根據(jù) dirty_writeback_interval 計(jì)算下次喚醒 flusher 線程的時(shí)機(jī)。
voidwb_wakeup_delayed(structbdi_writeback*wb)
{
unsignedlongtimeout;
//使用dirty_writeback_interval配置設(shè)置下次喚醒時(shí)間
timeout=msecs_to_jiffies(dirty_writeback_interval*10);
spin_lock_bh(&wb->work_lock);
if(test_bit(WB_registered,&wb->state))
queue_delayed_work(bdi_wq,&wb->dwork,timeout);
spin_unlock_bh(&wb->work_lock);
}
13.3 臟頁(yè)數(shù)量多到什么程度會(huì)主動(dòng)喚醒 flusher 線程
這一節(jié)的內(nèi)容中涉及到四個(gè)內(nèi)核參數(shù)分別是:
drity_background_ratio :當(dāng)臟頁(yè)數(shù)量在系統(tǒng)的可用內(nèi)存 available 中占用的比例達(dá)到 drity_background_ratio 的配置值時(shí),內(nèi)核就會(huì)調(diào)用 wakeup_flusher_threads 來喚醒 flusher 線程異步回寫臟頁(yè)。默認(rèn)值為:10。表示如果 page cache 中的臟頁(yè)數(shù)量達(dá)到系統(tǒng)可用內(nèi)存的 10% 的話,就主動(dòng)喚醒 flusher 線程去回寫臟頁(yè)到磁盤。
 image.png
image.png
系統(tǒng)的可用內(nèi)存 = 空閑內(nèi)存 + 可回收內(nèi)存。可以通過 free 命令的 available 項(xiàng)查看。

dirty_background_bytes :如果 page cache 中臟頁(yè)占用的內(nèi)存用量絕對(duì)值達(dá)到指定的 dirty_background_bytes。內(nèi)核就會(huì)調(diào)用 wakeup_flusher_threads 來喚醒 flusher 線程異步回寫臟頁(yè)。默認(rèn)為:0。
 image.png
image.png
dirty_background_bytes 的優(yōu)先級(jí)大于 drity_background_ratio 的優(yōu)先級(jí)。
dirty_ratio :dirty_background_* 相關(guān)的內(nèi)核配置參數(shù)均是內(nèi)核通過喚醒 flusher 線程來異步回寫臟頁(yè)。下面要介紹的 dirty_* 配置參數(shù),均是由用戶進(jìn)程同步回寫臟頁(yè)。表示內(nèi)存中的臟頁(yè)太多了,用戶進(jìn)程自己都看不下去了,不用等內(nèi)核 flusher 線程喚醒,用戶進(jìn)程自己主動(dòng)去回寫臟頁(yè)到磁盤中。當(dāng)臟頁(yè)占用系統(tǒng)可用內(nèi)存的比例達(dá)到 dirty_ratio 配置的值時(shí),用戶進(jìn)程同步回寫臟頁(yè)。默認(rèn)值為:20 。
dirty_bytes :如果 page cache 中臟頁(yè)占用的內(nèi)存用量絕對(duì)值達(dá)到指定的 dirty_bytes。用戶進(jìn)程同步回寫臟頁(yè)。默認(rèn)值為:0。
*_bytes 相關(guān)配置參數(shù)的優(yōu)先級(jí)要大于 *_ratio 相關(guān)配置參數(shù)。
我們繼續(xù)使用上小節(jié)中保潔阿姨的例子說明:
之前你們已經(jīng)約定好了,保潔阿姨會(huì)每周日固定(dirty_writeback_centisecs)來到你的房間打掃衛(wèi)生(臟頁(yè)),但是你周三回家的時(shí)候,發(fā)現(xiàn)屋子里太臟了,實(shí)在是臟到一定程度了(drity_background_ratio ,dirty_background_bytes),你實(shí)在是看不去了,這時(shí)你就不會(huì)等這周日(dirty_writeback_centisecs)保潔阿姨過來才打掃,你會(huì)直接給阿姨打電話讓阿姨周三就來打掃一下(內(nèi)核主動(dòng)喚醒 flusher 線程異步回寫臟頁(yè))。
還有一種更極端的情況就是,你的房間已經(jīng)臟到很夸張的程度了(dirty_ratio ,dirty_byte)連你自己都忍不了了,于是你都不用等保潔阿姨了(內(nèi)核 flusher 回寫線程),你自己就乖乖的開始打掃房間衛(wèi)生了。這就是用戶進(jìn)程同步回寫臟頁(yè)。
13.4 內(nèi)核如何主動(dòng)喚醒 flusher 線程
通過 《12.5 balance_dirty_pages_ratelimited》小節(jié)的介紹,我們知道在 generic_perform_write 函數(shù)的最后一步會(huì)調(diào)用 balance_dirty_pages_ratelimited 來判斷是否要觸發(fā)臟頁(yè)回寫。
voidbalance_dirty_pages_ratelimited(structaddress_space*mapping)
{
................省略............
if(unlikely(current->nr_dirtied>=ratelimit))
balance_dirty_pages(mapping,wb,current->nr_dirtied);
wb_put(wb);
}
這里會(huì)觸發(fā) balance_dirty_pages 函數(shù)進(jìn)行臟頁(yè)回寫。
staticvoidbalance_dirty_pages(structaddress_space*mapping,
structbdi_writeback*wb,
unsignedlongpages_dirtied)
{
..................省略.............
for(;;){
//獲取系統(tǒng)可用內(nèi)存
gdtc->avail=global_dirtyable_memory();
//根據(jù)*_ratio或者*_bytes相關(guān)內(nèi)核配置計(jì)算臟頁(yè)回寫觸發(fā)的閾值
domain_dirty_limits(gdtc);
.............省略..........
}
.............省略..........
在 balance_dirty_pages 中首先通過 global_dirtyable_memory() 獲取系統(tǒng)當(dāng)前可用內(nèi)存。在 domain_dirty_limits 函數(shù)中根據(jù)前邊我們介紹的 *_ratio 或者 *_bytes 相關(guān)內(nèi)核配置計(jì)算臟頁(yè)回寫觸發(fā)的閾值。
staticvoiddomain_dirty_limits(structdirty_throttle_control*dtc)
{
//獲取可用內(nèi)存
constunsignedlongavailable_memory=dtc->avail;
//封裝觸發(fā)臟頁(yè)回寫相關(guān)閾值信息
structdirty_throttle_control*gdtc=mdtc_gdtc(dtc);
//這里就是內(nèi)核參數(shù)dirty_bytes指定的值
unsignedlongbytes=vm_dirty_bytes;
//內(nèi)核參數(shù)dirty_background_bytes指定的值
unsignedlongbg_bytes=dirty_background_bytes;
//將內(nèi)核參數(shù)dirty_ratio指定的值轉(zhuǎn)換為以頁(yè)為單位
unsignedlongratio=(vm_dirty_ratio*PAGE_SIZE)/100;
//將內(nèi)核參數(shù)dirty_background_ratio指定的值轉(zhuǎn)換為以頁(yè)為單位
unsignedlongbg_ratio=(dirty_background_ratio*PAGE_SIZE)/100;
//進(jìn)程同步回寫dirty_*相關(guān)閾值
unsignedlongthresh;
//內(nèi)核異步回寫direty_background_*相關(guān)閾值
unsignedlongbg_thresh;
structtask_struct*tsk;
if(gdtc){
//系統(tǒng)可用內(nèi)存
unsignedlongglobal_avail=gdtc->avail;
//這里可以看出bytes相關(guān)配置的優(yōu)先級(jí)大于ratio相關(guān)配置的優(yōu)先級(jí)
if(bytes)
//將bytes相關(guān)的配置轉(zhuǎn)換為以頁(yè)為單位的內(nèi)存占用比例ratio
ratio=min(DIV_ROUND_UP(bytes,global_avail),
PAGE_SIZE);
//設(shè)置dirty_backgound_*相關(guān)閾值
if(bg_bytes)
bg_ratio=min(DIV_ROUND_UP(bg_bytes,global_avail),
PAGE_SIZE);
bytes=bg_bytes=0;
}
//這里可以看出bytes相關(guān)配置的優(yōu)先級(jí)大于ratio相關(guān)配置的優(yōu)先級(jí)
if(bytes)
//將bytes相關(guān)的配置轉(zhuǎn)換為以頁(yè)為單位的內(nèi)存占用比例ratio
thresh=DIV_ROUND_UP(bytes,PAGE_SIZE);
else
thresh=(ratio*available_memory)/PAGE_SIZE;
//設(shè)置dirty_background_*相關(guān)閾值
if(bg_bytes)
//將dirty_background_bytes相關(guān)的配置轉(zhuǎn)換為以頁(yè)為單位的內(nèi)存占用比例ratio
bg_thresh=DIV_ROUND_UP(bg_bytes,PAGE_SIZE);
else
bg_thresh=(bg_ratio*available_memory)/PAGE_SIZE;
//保證異步回寫backgound的相關(guān)閾值要比同步回寫的閾值要低
if(bg_thresh>=thresh)
bg_thresh=thresh/2;
dtc->thresh=thresh;
dtc->bg_thresh=bg_thresh;
..........省略..........
}
domain_dirty_limits 函數(shù)會(huì)分別計(jì)算用戶進(jìn)程同步回寫臟頁(yè)的相關(guān)閾值 thresh 以及內(nèi)核異步回寫臟頁(yè)的相關(guān)閾值 bg_thresh。邏輯比較好懂,筆者將每一步的注釋已經(jīng)為大家標(biāo)注出來了。這里只列出幾個(gè)關(guān)鍵核心點(diǎn):
從源碼中的 if (bytes) {....} else {.....} 分支以及 if (bg_bytes) {....} else {.....} 我們可以看出內(nèi)核配置 *_bytes 相關(guān)的優(yōu)先級(jí)會(huì)高于 *_ratio 相關(guān)配置的優(yōu)先級(jí)。
*_bytes 相關(guān)配置我們只會(huì)指定臟頁(yè)占用內(nèi)存的 bytes 閾值,但在內(nèi)核實(shí)現(xiàn)中會(huì)將其轉(zhuǎn)換為 頁(yè) 為單位。(每頁(yè) 4K 大小)。
內(nèi)核中對(duì)于臟頁(yè)回寫閾值的判斷是通過 ratio 比例來進(jìn)行判斷的。
內(nèi)核異步回寫的閾值要小于進(jìn)程同步回寫的閾值,如果超過,那么內(nèi)核異步回寫的閾值將會(huì)被設(shè)置為進(jìn)程通過回寫的一半。
staticvoidbalance_dirty_pages(structaddress_space*mapping,
structbdi_writeback*wb,
unsignedlongpages_dirtied)
{
..................省略.............
for(;;){
//獲取系統(tǒng)可用內(nèi)存
gdtc->avail=global_dirtyable_memory();
//根據(jù)*_ratio或者*_bytes相關(guān)內(nèi)核配置計(jì)算臟頁(yè)回寫觸發(fā)的閾值
domain_dirty_limits(gdtc);
.............省略..........
}
//根據(jù)進(jìn)程同步回寫閾值判斷是否需要進(jìn)程直接同步回寫臟頁(yè)
if(writeback_in_progress(wb))
return
//根據(jù)內(nèi)核異步回寫閾值判斷是否需要喚醒flusher異步回寫臟頁(yè)
if(nr_reclaimable>gdtc->bg_thresh)
wb_start_background_writeback(wb);
如果是異步回寫,內(nèi)核則喚醒 flusher 線程開始異步回寫臟頁(yè),直到臟頁(yè)數(shù)量低于閾值或者全部回寫到磁盤。
voidwb_start_background_writeback(structbdi_writeback*wb)
{
/*
*Wejustwakeuptheflusherthread.Itwillperformbackground
*writebackassoonasthereisnootherworktodo.
*/
trace_writeback_wake_background(wb);
wb_wakeup(wb);
}
13.5 臟頁(yè)到底在內(nèi)存中能駐留多久
內(nèi)核為了避免 page cache 中的臟頁(yè)在內(nèi)存中長(zhǎng)久的停留,所以會(huì)給臟頁(yè)在內(nèi)存中的駐留時(shí)間設(shè)置一定的期限,這個(gè)期限可由前邊提到的 dirty_expire_centisecs 內(nèi)核參數(shù)配置。默認(rèn)為:3000。單位為:0.01 s。

也就是說在默認(rèn)配置下,臟頁(yè)在內(nèi)存中的駐留時(shí)間為 30 s。超過 30 s 之后,flusher 線程將會(huì)在下次被喚醒的時(shí)候?qū)⑦@些臟頁(yè)回寫到磁盤中。
這些過期的臟頁(yè)最終會(huì)在 flusher 線程下一次被喚醒時(shí)候被 flusher 線程回寫到磁盤中。而前邊我們也多次提到過 flusher 線程執(zhí)行邏輯全部封裝在 wb_workfn 函數(shù)中。接下來的調(diào)用鏈為 wb_workfn->wb_do_writeback->wb_writeback。在 wb_writeback 中會(huì)判斷根據(jù) dirty_expire_interval 判斷哪些是過期的臟頁(yè)。
/* *Explicitflushingorperiodicwritebackof"old"data. * *Define"old":thefirsttimeoneofaninode'spagesisdirtied,wemarkthe *dirtying-timeintheinode'saddress_space.Sothisperiodicwritebackcode *justwalksthesuperblockinodelist,writingbackanyinodeswhichare *olderthanaspecificpointintime. * *Trytorunonceperdirty_writeback_interval.Butifawritebackevent *takeslongerthanadirty_writeback_intervalinterval,thenleavea *one-secondgap. * *older_than_thistakesprecedenceovernr_to_write.Sowe'llonlywriteback *alldirtypagesiftheyareallattachedto"old"mappings. */ staticlongwb_writeback(structbdi_writeback*wb, structwb_writeback_work*work) { ........省略....... work->older_than_this=&oldest_jif; for(;;){ ........省略....... if(work->for_kupdate){ oldest_jif=jiffies- msecs_to_jiffies(dirty_expire_interval*10); }elseif(work->for_background) oldest_jif=jiffies; } ........省略....... }
13.6 臟頁(yè)回寫參數(shù)的相關(guān)配置方式
前面的幾個(gè)小節(jié)筆者結(jié)合內(nèi)核源碼實(shí)現(xiàn)為大家介紹了影響內(nèi)核回寫臟頁(yè)時(shí)機(jī)的六個(gè)參數(shù)。
內(nèi)核越頻繁的觸發(fā)臟頁(yè)回寫,數(shù)據(jù)的安全性就越高,但是同時(shí)系統(tǒng)性能會(huì)消耗很大。所以我們?cè)谌粘9ぷ髦行枰Y(jié)合數(shù)據(jù)的安全性和 IO 性能綜合考慮這六個(gè)內(nèi)核參數(shù)的配置。
本小節(jié)筆者就為大家介紹一下配置這些內(nèi)核參數(shù)的方式,前面的小節(jié)中也提到過,內(nèi)核提供的這些參數(shù)存在于 proc/sys/vm 目錄下。
比如我們直接將要配置的具體數(shù)值寫入對(duì)應(yīng)的配置文件中:
echo"value">/proc/sys/vm/dirty_background_ratio
我們還可以使用 sysctl 來對(duì)這些內(nèi)核參數(shù)進(jìn)行配置:
sysctl-wvariable=value
sysctl 命令中定義的這些變量 variable 全部定義在內(nèi)核 kernel/sysctl.c 源文件中。
其中 .procname 定義的就是 sysctl 命令中指定的配置變量名字。
.data 定義的是內(nèi)核源碼中引用的變量名字。這在前邊我們介紹內(nèi)核代碼的時(shí)候介紹過了。比如配置參數(shù) dirty_writeback_centisecs 在內(nèi)核源碼中的變量名為 dirty_writeback_interval , dirty_ratio 在內(nèi)核中的變量名為 vm_dirty_ratio。
staticstructctl_tablevm_table[]={
........省略........
{
.procname="dirty_background_ratio",
.data=&dirty_background_ratio,
.maxlen=sizeof(dirty_background_ratio),
.mode=0644,
.proc_handler=dirty_background_ratio_handler,
.extra1=SYSCTL_ZERO,
.extra2=SYSCTL_ONE_HUNDRED,
},
{
.procname="dirty_background_bytes",
.data=&dirty_background_bytes,
.maxlen=sizeof(dirty_background_bytes),
.mode=0644,
.proc_handler=dirty_background_bytes_handler,
.extra1=SYSCTL_LONG_ONE,
},
{
.procname="dirty_ratio",
.data=&vm_dirty_ratio,
.maxlen=sizeof(vm_dirty_ratio),
.mode=0644,
.proc_handler=dirty_ratio_handler,
.extra1=SYSCTL_ZERO,
.extra2=SYSCTL_ONE_HUNDRED,
},
{
.procname="dirty_bytes",
.data=&vm_dirty_bytes,
.maxlen=sizeof(vm_dirty_bytes),
.mode=0644,
.proc_handler=dirty_bytes_handler,
.extra1=(void*)&dirty_bytes_min,
},
{
.procname="dirty_writeback_centisecs",
.data=&dirty_writeback_interval,
.maxlen=sizeof(dirty_writeback_interval),
.mode=0644,
.proc_handler=dirty_writeback_centisecs_handler,
},
{
.procname="dirty_expire_centisecs",
.data=&dirty_expire_interval,
.maxlen=sizeof(dirty_expire_interval),
.mode=0644,
.proc_handler=proc_dointvec_minmax,
.extra1=SYSCTL_ZERO,
}
........省略........
}
而前邊介紹的這兩種配置方式全部是臨時(shí)的,我們可以通過編輯 /etc/sysctl.conf 文件來永久的修改內(nèi)核相關(guān)的配置。
我們也可以在目錄 /etc/sysctl.d/下創(chuàng)建自定義的配置文件。
vi/etc/sysctl.conf
在 /etc/sysctl.conf 文件中直接以 variable = value 的形式添加到文件的末尾。
最后調(diào)用 sysctl -p /etc/sysctl.conf 使 /etc/sysctl.conf 配置文件中新添加的那些配置生效。
總結(jié)
本文筆者帶大家從 Linux 內(nèi)核的角度詳細(xì)解析了 JDK NIO 文件讀寫在 Buffered IO 以及 Direct IO 這兩種模式下的內(nèi)核源碼實(shí)現(xiàn),探秘了文件讀寫的本質(zhì)。并對(duì)比了 Buffered IO 和 Direct IO 的不同之處以及各自的適用場(chǎng)景。
在這個(gè)過程中又詳細(xì)地介紹了與 Buffered IO 密切相關(guān)的文件頁(yè)高速緩存 page cache 在內(nèi)核中的實(shí)現(xiàn)以及相關(guān)操作。
最后我們?cè)敿?xì)介紹了影響文件 IO 的兩個(gè)關(guān)鍵步驟:文件預(yù)讀和臟頁(yè)回寫的詳細(xì)內(nèi)核源碼實(shí)現(xiàn),以及內(nèi)核中影響臟頁(yè)回寫時(shí)機(jī)的 6 個(gè)關(guān)鍵內(nèi)核配置參數(shù)相關(guān)的實(shí)現(xiàn)及應(yīng)用。
dirty_background_bytes
dirty_background_ratio
dirty_bytes
dirty_ratio
dirty_expire_centisecs
dirty_writeback_centisecs
以及關(guān)于內(nèi)核參數(shù)的三種配置方式:
通過直接修改 proc/sys/vm 目錄下的相關(guān)參數(shù)配置文件。
使用 sysctl 命令來對(duì)相關(guān)參數(shù)進(jìn)行修改。
通過編輯 /etc/sysctl.conf 文件來永久的修改內(nèi)核相關(guān)配置。
好了,本文的內(nèi)容到這里就結(jié)束了,能夠看到這里的大家一定是個(gè)狠人兒,但是辛苦的付出總會(huì)有所收獲,恭喜大家現(xiàn)在已經(jīng)徹底打通了 Linux 文件操作相關(guān)知識(shí)的系統(tǒng)脈絡(luò)。感謝大家的耐心觀看,我們下篇文章見~~~
審核編輯:劉清
-
JAVA
+關(guān)注
關(guān)注
19文章
2960瀏覽量
104565 -
Socket
+關(guān)注
關(guān)注
0文章
211瀏覽量
34637 -
dma
+關(guān)注
關(guān)注
3文章
559瀏覽量
100446 -
LINUX內(nèi)核
+關(guān)注
關(guān)注
1文章
316瀏覽量
21619 -
vfs
+關(guān)注
關(guān)注
0文章
14瀏覽量
5249
原文標(biāo)題:從 Linux 內(nèi)核角度探秘 Java NIO 文件讀寫本質(zhì)
文章出處:【微信號(hào):小林coding,微信公眾號(hào):小林coding】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
Java NIO編程理論基礎(chǔ)之Java IO及linux網(wǎng)絡(luò)IO模型發(fā)展
i/o本質(zhì)與庫(kù)函數(shù)的本質(zhì)分別是什么
JAVA教程之從從網(wǎng)絡(luò)取得文件
Linux中文件及文件描述符概述
linux內(nèi)核啟動(dòng)流程

Linux 內(nèi)核/sys 文件系統(tǒng)介紹
需要了解的Linux內(nèi)核讀寫文件
JAVA中NIO通過MappedByteBuffer操作大文件
linux內(nèi)核是什么_linux內(nèi)核學(xué)習(xí)路線
如何使用Linux內(nèi)核實(shí)現(xiàn)USB驅(qū)動(dòng)程序框架
Linux內(nèi)核文件Cache機(jī)制






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論