") Redis的主從、哨兵、Redis Cluster集群
Redis的主從、哨兵、Redis Cluster集群
前言
今天跟小伙伴們一起學(xué)習(xí)Redis的主從、哨兵、Redis Cluster集群。
Redis主從
Redis哨兵
Redis Cluster集群
基于 Spring Boot + MyBatis Plus + Vue & Element 實(shí)現(xiàn)的后臺管理系統(tǒng) + 用戶小程序,支持 RBAC 動態(tài)權(quán)限、多租戶、數(shù)據(jù)權(quán)限、工作流、三方登錄、支付、短信、商城等功能
項(xiàng)目地址:https://github.com/YunaiV/ruoyi-vue-pro
視頻教程:https://doc.iocoder.cn/video/
1. Redis 主從
面試官經(jīng)常會問到Redis的高可用。Redis高可用回答包括兩個層面,一個就是數(shù)據(jù)不能丟失,或者說盡量減少丟失 ;另外一個就是保證Redis服務(wù)不中斷 。
對于盡量減少數(shù)據(jù)丟失,可以通過AOF和RDB保證。
對于保證服務(wù)不中斷的話,Redis就不能單點(diǎn)部署,這時候我們先看下Redis主從。
1.1 Redsi主從概念
Redis主從模式,就是部署多臺Redis服務(wù)器,有主庫和從庫,它們之間通過主從復(fù)制,以保證數(shù)據(jù)副本的一致。
主從庫之間采用的是讀寫分離 的方式,其中主庫負(fù)責(zé)讀操作和寫操作,從庫則負(fù)責(zé)讀操作。
如果Redis主庫掛了,切換其中的從庫成為主庫。
1.2 Redis 主從同步過程
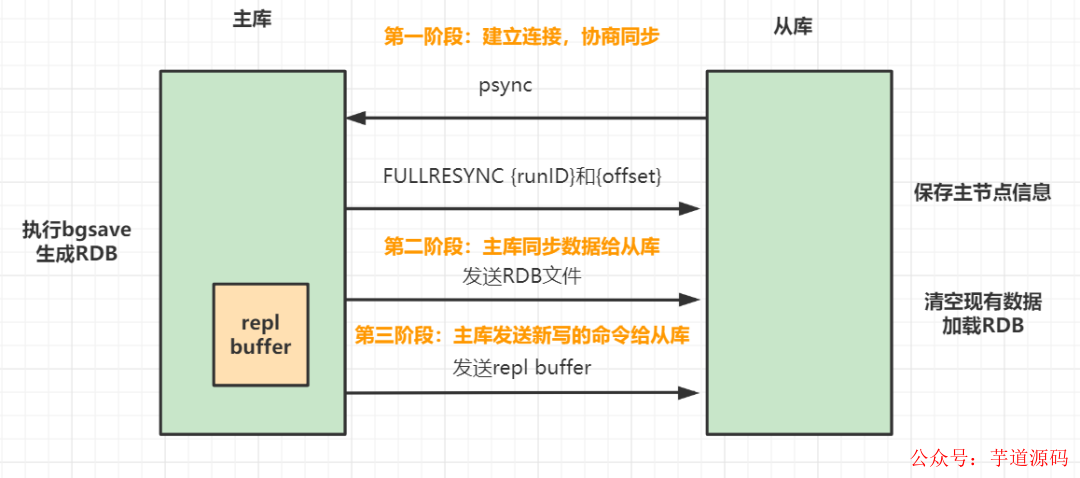
Redis主從同步包括三個階段。
第一階段:主從庫間建立連接、協(xié)商同步。
從庫向主庫發(fā)送psync 命令,告訴它要進(jìn)行數(shù)據(jù)同步。
主庫收到 psync 命令后,響應(yīng)FULLRESYNC命令(它表示第一次復(fù)制采用的是全量復(fù)制 ),并帶上主庫runID和主庫目前的復(fù)制進(jìn)度offset。
第二階段:主庫把數(shù)據(jù)同步到從庫,從庫收到數(shù)據(jù)后,完成本地加載。
主庫執(zhí)行bgsave命令,生成RDB文件,接著將文件發(fā)給從庫。從庫接收到RDB 文件后,會先清空當(dāng)前數(shù)據(jù)庫,然后加載 RDB 文件。
主庫把數(shù)據(jù)同步到從庫的過程中,新來的寫操作,會記錄到replication buffer。
第三階段,主庫把新寫的命令,發(fā)送到從庫。
主庫完成RDB發(fā)送后,會把replication buffer中的修改操作發(fā)給從庫,從庫再重新執(zhí)行這些操作。這樣主從庫就實(shí)現(xiàn)同步啦。
1.3 Redis主從的一些注意點(diǎn)
1.3.1 主從數(shù)據(jù)不一致
因?yàn)橹鲝膹?fù)制是異步進(jìn)行的,如果從庫滯后執(zhí)行,則會導(dǎo)致主從數(shù)據(jù)不一致 。
主從數(shù)據(jù)不一致一般有兩個原因:
主從庫網(wǎng)路延遲。
從庫收到了主從命令,但是它正在執(zhí)行阻塞性的命令(如hgetall等)。
如何解決主從數(shù)據(jù)不一致問題呢?
可以換更好的硬件配置,保證網(wǎng)絡(luò)暢通。
監(jiān)控主從庫間的復(fù)制進(jìn)度
1.3.2 讀取過期數(shù)據(jù)
Redis刪除數(shù)據(jù)有這幾種策略:
惰性刪除:只有當(dāng)訪問一個key時,才會判斷該key是否已過期,過期則清除。
定期刪除:每隔一定的時間,會掃描一定數(shù)量的數(shù)據(jù)庫的expires字典中一定數(shù)量的key,并清除其中已過期的key。
主動刪除:當(dāng)前已用內(nèi)存超過最大限定時,觸發(fā)主動清理策略。
如果使用Redis版本低于3.2,讀從庫時,并不會判斷數(shù)據(jù)是否過期,而是會返回過期數(shù)據(jù) 。而3.2 版本后,Redis做了改進(jìn),如果讀到的數(shù)據(jù)已經(jīng)過期了,從庫不會刪除,卻會返回空值,避免了客戶端讀到過期數(shù)據(jù) 。
因此,在主從Redis模式下,盡量使用 Redis 3.2 以上的版本。
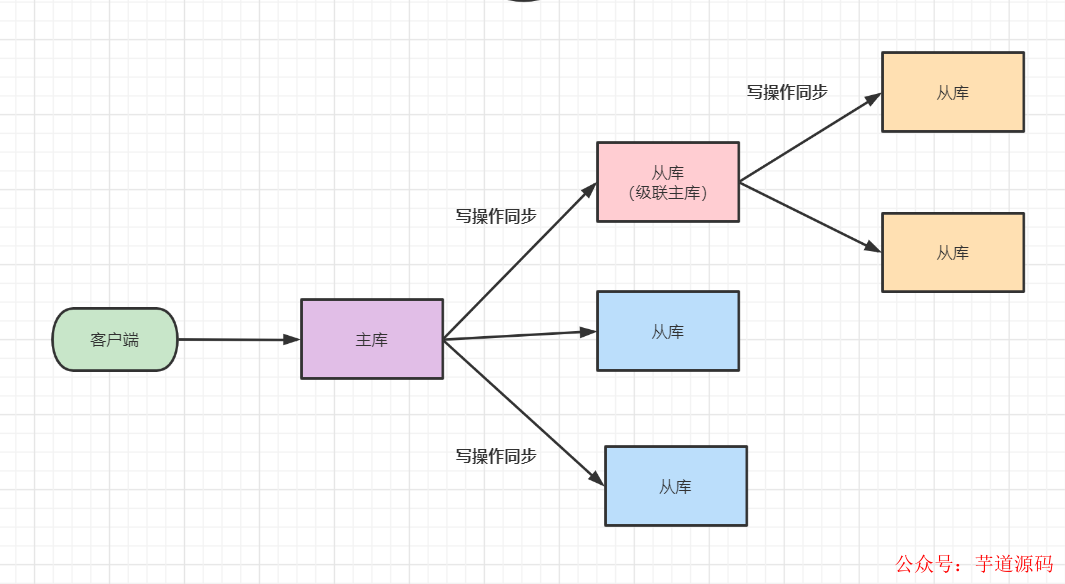
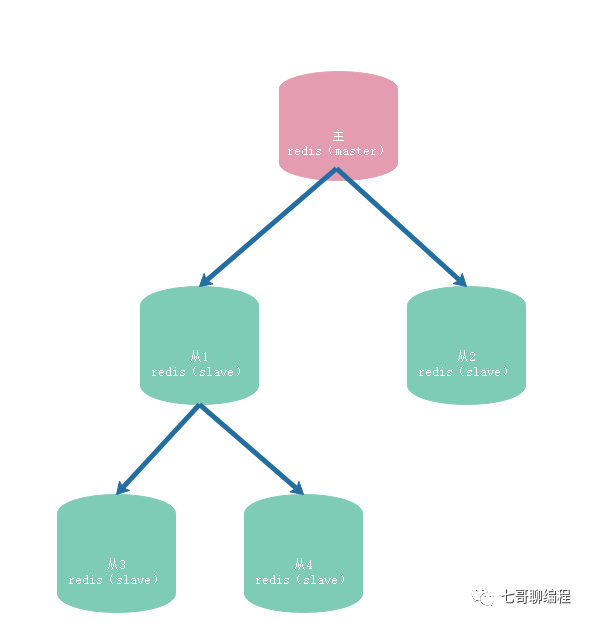
1.3.3 一主多從,全量復(fù)制時主庫壓力問題
如果是一主多從模式,從庫很多的時候,如果每個從庫都要和主庫進(jìn)行全量復(fù)制的話,主庫的壓力是很大的。因?yàn)橹鲙靎ork進(jìn)程生成RDB,這個fork的過程是會阻塞主線程處理正常請求的。同時,傳輸大的RDB文件也會占用主庫的網(wǎng)絡(luò)寬帶。
可以使用主-從-從 模式解決。什么是主從從模式呢?其實(shí)就是部署主從集群時,選擇硬件網(wǎng)絡(luò)配置比較好的一個從庫,讓它跟部分從庫再建立主從 關(guān)系。如圖:
1.3.4 主從網(wǎng)絡(luò)斷了怎么辦呢?
主從庫完成了全量復(fù)制后,它們之間會維護(hù)一個網(wǎng)絡(luò)長連接,用于主庫后續(xù)收到寫命令傳輸?shù)綇膸欤梢员苊忸l繁建立連接的開銷。但是,如果網(wǎng)絡(luò)斷開重連后,是否還需要進(jìn)行一次全量復(fù)制呢?
如果是Redis 2.8之前,從庫和主庫重連后,確實(shí)會再進(jìn)行一次全量復(fù)制,但是這樣開銷就很大。而Redis 2.8之后做了優(yōu)化,重連后采用增量復(fù)制方式,即把主從庫網(wǎng)絡(luò)斷連期間主庫收到的寫命令,同步給從庫。
主從庫重連后,就是利用repl_backlog_buffer 實(shí)現(xiàn)增量復(fù)制。
當(dāng)主從庫斷開連接后,主庫會把斷連期間收到的寫操作命令,寫入replication buffer ,同時也會把這些操作命令寫入repl_backlog_buffer 這個緩沖區(qū)。repl_backlog_buffer是一個環(huán)形緩沖區(qū),主庫會記錄自己寫到的位置,從庫則會記錄自己已經(jīng)讀到的位置。
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 實(shí)現(xiàn)的后臺管理系統(tǒng) + 用戶小程序,支持 RBAC 動態(tài)權(quán)限、多租戶、數(shù)據(jù)權(quán)限、工作流、三方登錄、支付、短信、商城等功能
項(xiàng)目地址:https://github.com/YunaiV/yudao-cloud
視頻教程:https://doc.iocoder.cn/video/
2. Redis哨兵
主從模式中,一旦主節(jié)點(diǎn)由于故障不能提供服務(wù),需要人工將從節(jié)點(diǎn)晉升為主節(jié)點(diǎn),同時還要通知應(yīng)用方更新主節(jié)點(diǎn)地址。顯然,多數(shù)業(yè)務(wù)場景都不能接受這種故障處理方式。Redis從2.8開始正式提供了Redis哨兵機(jī)制 來解決這個問題。
哨兵作用
哨兵模式簡介
哨兵如何判定主庫下線
哨兵模式如何工作
哨兵是如何選主的
由哪個哨兵執(zhí)行主從切換呢?
哨兵下的故障轉(zhuǎn)移
2.1 哨兵作用
哨兵其實(shí)是一個運(yùn)行在特殊模式下的Redis進(jìn)程。它有三個作用,分別是:監(jiān)控、自動選主切換(簡稱選主)、通知 。
哨兵進(jìn)程在運(yùn)行期間,監(jiān)視所有的Redis主節(jié)點(diǎn)和從節(jié)點(diǎn)。它通過周期性給主從庫 發(fā)送PING命令,檢測主從庫是否掛了。如果從庫 沒有在規(guī)定時間內(nèi)響應(yīng)哨兵的PING命令,哨兵就會把它標(biāo)記為下線狀態(tài) ;如果主庫沒有在規(guī)定時間內(nèi)響應(yīng)哨兵的PING命令,哨兵則會判定主庫下線,然后開始切換到選主 任務(wù)。
所謂選主 ,其實(shí)就是從多個從庫中,按照一定規(guī)則,選出一個當(dāng)做主庫。至于通知 呢,就是選出主庫后,哨兵把新主庫的連接信息發(fā)給其他從庫,讓它們和新主庫建立主從關(guān)系。同時,哨兵也會把新主庫的連接信息通知給客戶端,讓它們把請求操作發(fā)到新主庫上。
2.2 哨兵模式
因?yàn)镽edis哨兵也是一個Redis進(jìn)程,如果它自己掛了呢,那是不是就起不了監(jiān)控的作用啦。我們一起來看下Redis哨兵模式
哨兵模式,就是由一個或多個哨兵實(shí)例組成的哨兵系統(tǒng),它可以監(jiān)視所有的Redis主節(jié)點(diǎn)和從節(jié)點(diǎn),并在被監(jiān)視的主節(jié)點(diǎn)進(jìn)入下線狀態(tài)時,自動將下線主服務(wù)器屬下的某個從節(jié)點(diǎn)升級為新的主節(jié)點(diǎn)。,一個哨兵進(jìn)程對Redis節(jié)點(diǎn)進(jìn)行監(jiān)控,就可能會出現(xiàn)問題(單點(diǎn)問題)。因此,一般使用多個哨兵來進(jìn)行監(jiān)控Redis節(jié)點(diǎn),并且各個哨兵之間還會進(jìn)行監(jiān)控。
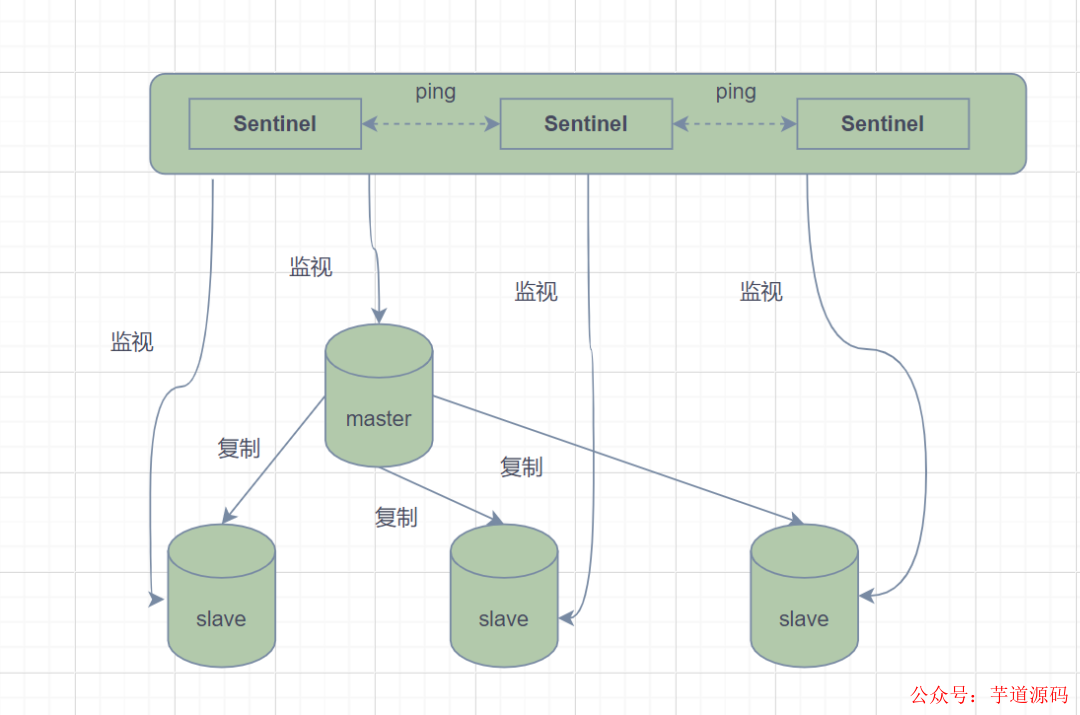
其實(shí)哨兵之間是通過發(fā)布訂閱機(jī)制 組成集群的,同時,哨兵又通過INFO命令,獲得了從庫連接信息,也能和從庫建立連接,從而進(jìn)行監(jiān)控。
2.3 哨兵如何判定主庫下線
哨兵是如何判斷主庫是否下線的呢?我們先來了解兩個基礎(chǔ)概念哈:主觀下線和客觀下線 。
哨兵進(jìn)程向主庫、從庫 發(fā)送PING命令,如果主庫或者從庫沒有在規(guī)定的時間內(nèi)響應(yīng)PING命令,哨兵就把它標(biāo)記為主觀下線 。
如果是主庫被標(biāo)記為主觀下線 ,則正在監(jiān)視這個主庫的所有哨兵 要以每秒一次的頻率,以確認(rèn)主庫是否真的進(jìn)入了主觀下線 。當(dāng)有多數(shù) 的哨兵(一般少數(shù)服從多數(shù),由 Redis 管理員自行設(shè)定的一個值 )在指定的時間范圍內(nèi)確認(rèn)主庫的確進(jìn)入了主觀下線狀態(tài),則主庫會被標(biāo)記為客觀下線 。這樣做的目的就是避免對主庫的誤判 ,以減少沒有必要的主從切換,減少不必要的開銷。
假設(shè)我們有N個哨兵實(shí)例,如果有N/2+1個實(shí)例判斷主庫主觀下線 ,此時就可以把節(jié)點(diǎn)標(biāo)記為客觀下線 ,就可以做主從切換了。
2.4 哨兵的工作模式
每個哨兵以每秒鐘一次的頻率向它所知的主庫、從庫以及其他哨兵實(shí)例發(fā)送一個PING命令。
如果一個實(shí)例節(jié)點(diǎn)距離最后一次有效回復(fù)PING命令的時間超過down-after-milliseconds選項(xiàng)所指定的值, 則這個實(shí)例會被哨兵標(biāo)記為主觀下線。
如果主庫 被標(biāo)記為主觀下線,則正在監(jiān)視這個主庫的所有哨兵要以每秒一次的頻率確認(rèn)主庫的確進(jìn)入了主觀下線狀態(tài)。
當(dāng)有足夠數(shù)量的哨兵(大于等于配置文件指定的值 )在指定的時間范圍內(nèi)確認(rèn)主庫的確進(jìn)入了主觀下線狀態(tài), 則主庫會被標(biāo)記為客觀下線 。
當(dāng)主庫被哨兵標(biāo)記為客觀下線 時,就會進(jìn)入選主模式 。
若沒有足夠數(shù)量的哨兵同意主庫已經(jīng)進(jìn)入主觀下線, 主庫的主觀下線狀態(tài)就會被移除 ;若主庫重新向哨兵的PING命令返回有效回復(fù),主庫的主觀下線狀態(tài)就會被移除。
2.5 哨兵是如何選主的?
如果明確主庫已經(jīng)客觀下線了,哨兵就開始了選主模式。
哨兵選主包括兩大過程,分別是:過濾和打分 。其實(shí)就是在多個從庫中,先按照一定的篩選條件,把不符合條件的從庫過濾 掉。然后再按照一定的規(guī)則,給剩下的從庫逐個打分,將得分最高的從庫選為新主庫
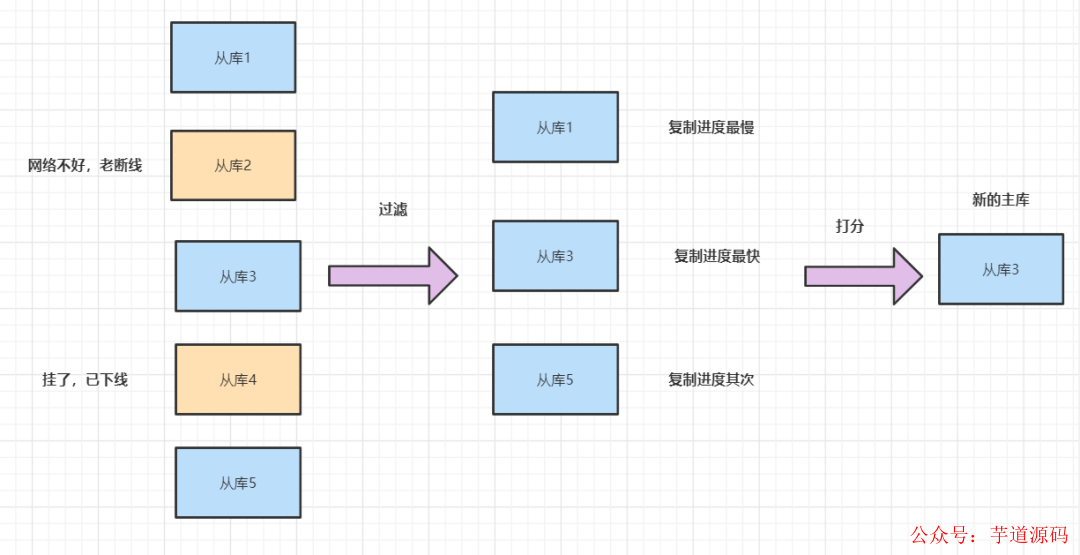
選主時,會判斷從庫的狀態(tài),如果已經(jīng)下線,就直接過濾 。
如果從庫網(wǎng)絡(luò)不好,老是超時,也會被過濾掉。看這個參數(shù)down-after-milliseconds,它表示我們認(rèn)定主從庫斷連的最大連接超時時間。
過濾掉了不適合做主庫的從庫后,就可以給剩下的從庫打分,按這三個規(guī)則打分:從庫優(yōu)先級、從庫復(fù)制進(jìn)度以及從庫ID號 。
從庫優(yōu)先級最高的話,打分就越高,優(yōu)先級可以通過slave-priority配置。如果優(yōu)先級一樣,就選與舊的主庫復(fù)制進(jìn)度最快的從庫。如果優(yōu)先級和從庫進(jìn)度都一樣,從庫ID 號小的打分高。
2.6 由哪個哨兵執(zhí)行主從切換呢?
一個哨兵標(biāo)記主庫為主觀下線 后,它會征求其他哨兵的意見,確認(rèn)主庫是否的確進(jìn)入了主觀下線狀態(tài)。它向其他實(shí)例哨兵發(fā)送is-master-down-by-addr命令。其他哨兵會根據(jù)自己和主庫的連接情況,回應(yīng)Y或N(Y 表示贊成,N表示反對票)。如果這個哨兵獲取得足夠多的贊成票數(shù)(quorum配置),主庫會被標(biāo)記為客觀下線 。
標(biāo)記主庫客觀下線的這個哨兵,緊接著向其他哨兵發(fā)送命令,再發(fā)起投票 ,希望它可以來執(zhí)行主從切換。這個投票過程稱為Leader 選舉 。因?yàn)樽罱K執(zhí)行主從切換的哨兵稱為Leader,投票過程就是確定Leader。一個哨兵想成為Leader需要滿足兩個條件:
需要拿到num(sentinels)/2+1的贊成票。
并且拿到的票數(shù)需要大于等于哨兵配置文件中的quorum值。
舉個例子,假設(shè)有3個哨兵。配置的quorum值為2。即一個一個哨兵想成為Leader至少需要拿到2張票。為了更好理解,大家可以看下
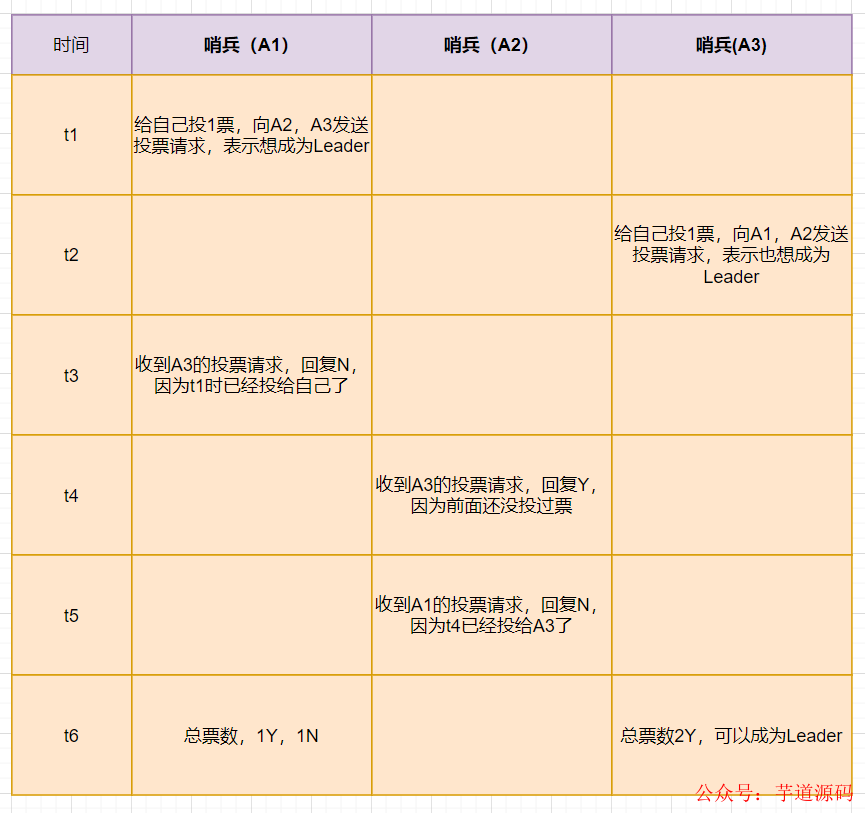
在t1時刻,哨兵A1判斷主庫為客觀下線 ,它想成為主從切換的Leader,于是先給自己投一張贊成票,然后分別向哨兵A2 和A3發(fā)起投票命令,表示想成為 Leader。
在 t2 時刻,A3 判斷主庫為客觀下線 ,它也想成為 Leader,所以也先給自己投一張贊成票,再分別向 A1 和 A2 發(fā)起投票命令,表示也要成為 Leader。
在 t3 時刻,哨兵A1 收到了A3 的Leader投票請求。因?yàn)锳1已經(jīng)把票Y投給自己了,所以它不能再給其他哨兵投贊成票了,所以A1投票N給A3。
在 t4時刻,哨兵A2收到A3 的Leader投票請求,因?yàn)樯诒鳤2之前沒有投過票,它會給第一個向它發(fā)送投票請求的哨兵回復(fù)贊成票Y。
在 t5時刻,哨兵A2收到A1 的Leader投票請求,因?yàn)樯诒鳤2之前已經(jīng)投過贊成票給A3了,所以它只能給A1投反對票N。
最后t6時刻,哨兵A1只收到自己的一票Y贊成票,而哨兵A3得到兩張贊成票(A2和A3投的),因此哨兵A3成為了Leader 。
假設(shè)網(wǎng)絡(luò)故障等原因,哨兵A3也沒有收到兩張票 ,那么這輪投票就不會產(chǎn)生Leader。哨兵集群會等待一段時間(一般是哨兵故障轉(zhuǎn)移超時時間的2倍),再進(jìn)行重新選舉。
2.7 故障轉(zhuǎn)移
假設(shè)哨兵模式架構(gòu)如下,有三個哨兵,一個主庫M,兩個從庫S1和S2。
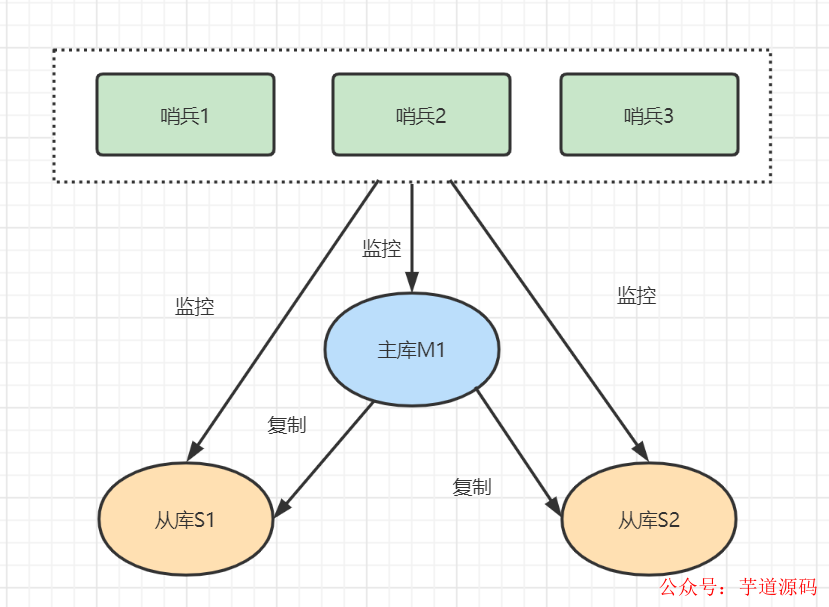
當(dāng)哨兵檢測到Redis主庫M1出現(xiàn)故障,那么哨兵需要對集群進(jìn)行故障轉(zhuǎn)移。假設(shè)選出了哨兵3 作為Leader。故障轉(zhuǎn)移流程如下:
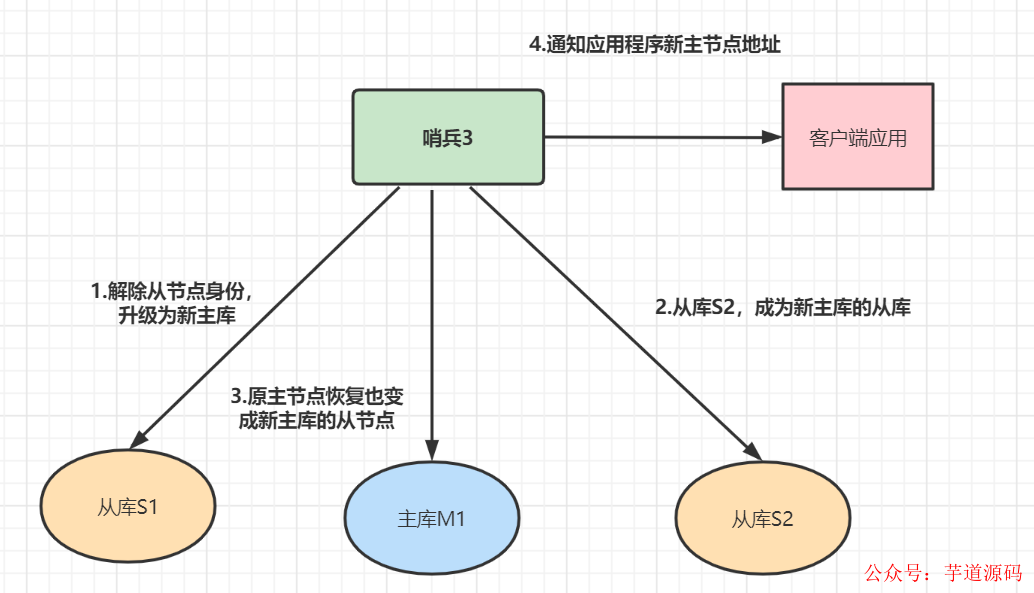
從庫S1解除從節(jié)點(diǎn)身份,升級為新主庫
從庫S2成為新主庫的從庫
原主節(jié)點(diǎn)恢復(fù)也變成新主庫的從節(jié)點(diǎn)
通知客戶端應(yīng)用程序新主節(jié)點(diǎn)的地址。
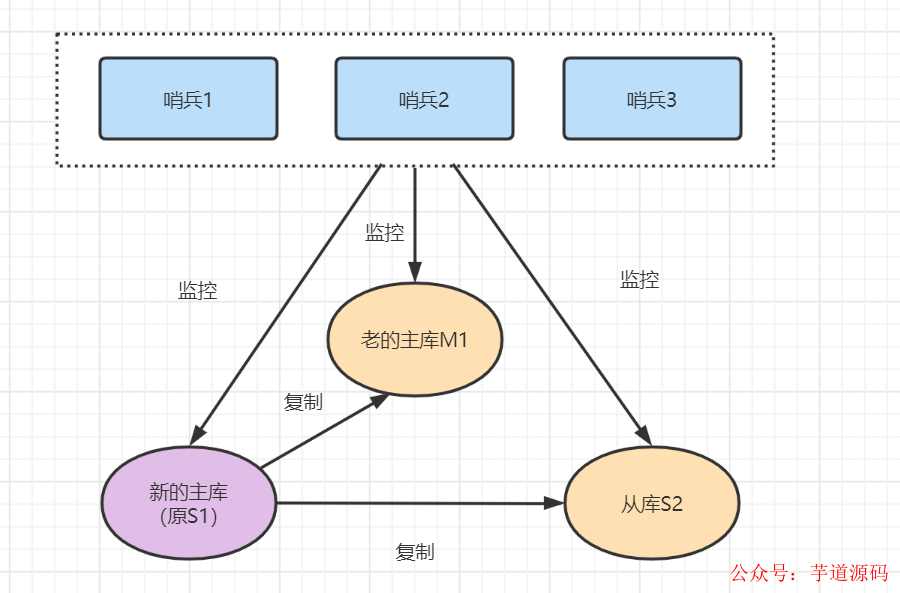
故障轉(zhuǎn)移后:
3.Redis Cluster集群
哨兵模式基于主從模式,實(shí)現(xiàn)讀寫分離,它還可以自動切換,系統(tǒng)可用性更高。但是它每個節(jié)點(diǎn)存儲的數(shù)據(jù)是一樣的,浪費(fèi)內(nèi)存,并且不好在線擴(kuò)容 。因此,Reids Cluster集群(切片集群的實(shí)現(xiàn)方案) 應(yīng)運(yùn)而生,它在Redis3.0加入的,實(shí)現(xiàn)了Redis的分布式存儲 。對數(shù)據(jù)進(jìn)行分片,也就是說每臺Redis節(jié)點(diǎn)上存儲不同的內(nèi)容,來解決在線擴(kuò)容的問題。并且,它可以保存大量數(shù)據(jù) ,即分散數(shù)據(jù)到各個Redis實(shí)例,還提供復(fù)制和故障轉(zhuǎn)移的功能。
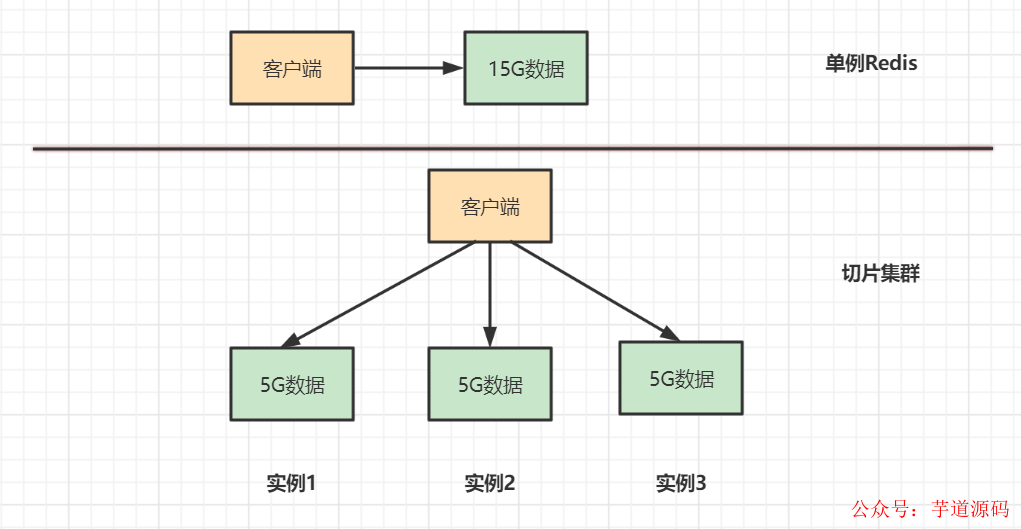
比如你一個Redis實(shí)例保存15G甚至更大的數(shù)據(jù),響應(yīng)就會很慢,這是因?yàn)镽edis RDB 持久化機(jī)制導(dǎo)致的,Redis會fork子進(jìn)程完成 RDB 持久化操作,fork執(zhí)行的耗時與 Redis 數(shù)據(jù)量成正相關(guān)。
這時候你很容易想到,把15G數(shù)據(jù)分散來存儲就好了嘛。這就是Redis切片集群 的初衷。切片集群是啥呢?來看個例子,如果你要用Redis保存15G的數(shù)據(jù),可以用單實(shí)例Redis,或者3臺Redis實(shí)例組成切片集群 ,對比如下:
切片集群和Redis Cluster 的區(qū)別:Redis Cluster是從Redis3.0版本開始,官方提供的一種實(shí)現(xiàn)切片集群 的方案。
既然數(shù)據(jù)是分片分布到不同Redis實(shí)例的,那客戶端到底是怎么確定想要訪問的數(shù)據(jù)在哪個實(shí)例上呢?我們一起來看下Reids Cluster 是怎么做的哈。
3.1 哈希槽(Hash Slot)
Redis Cluster方案采用哈希槽(Hash Slot),來處理數(shù)據(jù)和實(shí)例之間的映射關(guān)系。
一個切片集群被分為16384個slot(槽),每個進(jìn)入Redis的鍵值對,根據(jù)key進(jìn)行散列,分配到這16384插槽中的一個。使用的哈希映射也比較簡單,用CRC16算法計(jì)算出一個16bit的值,再對16384取模。數(shù)據(jù)庫中的每個鍵都屬于這16384個槽的其中一個,集群中的每個節(jié)點(diǎn)都可以處理這16384個槽。
集群中的每個節(jié)點(diǎn)負(fù)責(zé)一部分的哈希槽,假設(shè)當(dāng)前集群有A、B、C3個節(jié)點(diǎn),每個節(jié)點(diǎn)上負(fù)責(zé)的哈希槽數(shù) =16384/3,那么可能存在的一種分配:
節(jié)點(diǎn)A負(fù)責(zé)0~5460號哈希槽
節(jié)點(diǎn)B負(fù)責(zé)5461~10922號哈希槽
節(jié)點(diǎn)C負(fù)責(zé)10923~16383號哈希槽
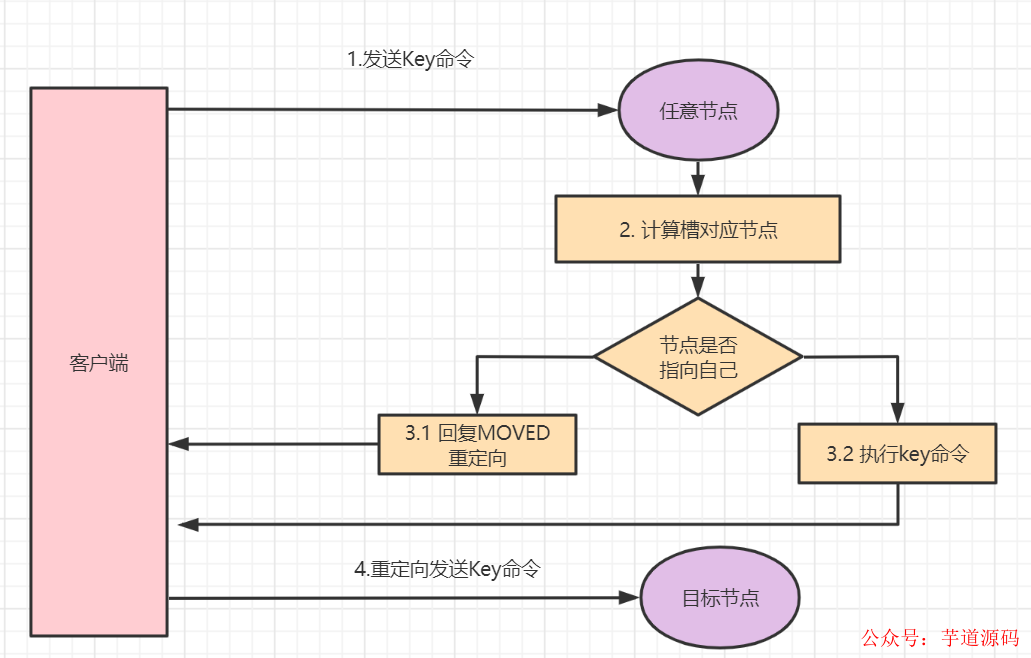
客戶端給一個Redis實(shí)例發(fā)送數(shù)據(jù)讀寫操作時,如果這個實(shí)例上并沒有相應(yīng)的數(shù)據(jù),會怎么樣呢?MOVED重定向和ASK重定向了解一下哈
3.2 MOVED重定向和ASK重定向
在Redis cluster模式下,節(jié)點(diǎn)對請求的處理過程如下:
通過哈希槽映射,檢查當(dāng)前Redis key是否存在當(dāng)前節(jié)點(diǎn)
若哈希槽不是由自身節(jié)點(diǎn)負(fù)責(zé),就返回MOVED重定向
若哈希槽確實(shí)由自身負(fù)責(zé),且key在slot中,則返回該key對應(yīng)結(jié)果
若Redis key不存在此哈希槽中,檢查該哈希槽是否正在遷出(MIGRATING)?
若Redis key正在遷出,返回ASK錯誤重定向客戶端到遷移的目的服務(wù)器上
若哈希槽未遷出,檢查哈希槽是否導(dǎo)入中?
若哈希槽導(dǎo)入中且有ASKING標(biāo)記,則直接操作,否則返回MOVED重定向
3.2.1 Moved 重定向
客戶端給一個Redis實(shí)例發(fā)送數(shù)據(jù)讀寫操作時,如果計(jì)算出來的槽不是在該節(jié)點(diǎn)上,這時候它會返回MOVED重定向錯誤,MOVED重定向錯誤中,會將哈希槽所在的新實(shí)例的IP和port端口帶回去。這就是Redis Cluster的MOVED重定向機(jī)制。流程圖如下:
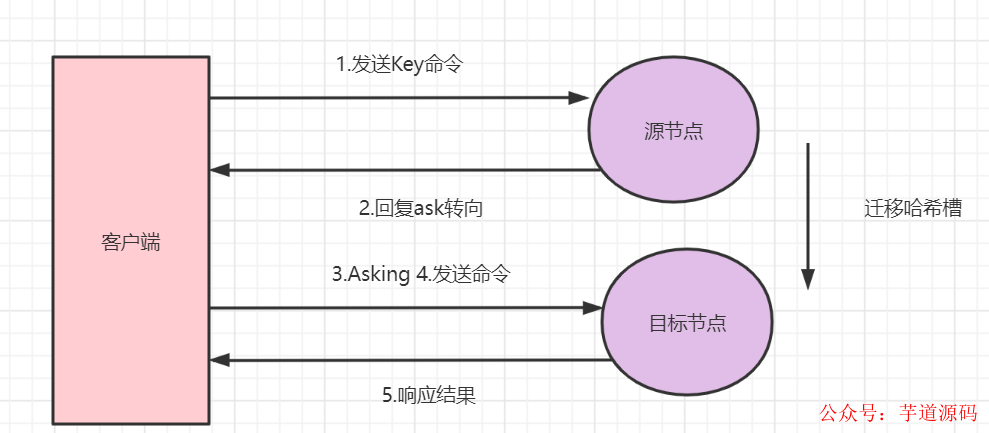
3.2.2 ASK 重定向
Ask重定向一般發(fā)生于集群伸縮的時候。集群伸縮會導(dǎo)致槽遷移,當(dāng)我們?nèi)ピ垂?jié)點(diǎn)訪問時,此時數(shù)據(jù)已經(jīng)可能已經(jīng)遷移到了目標(biāo)節(jié)點(diǎn),使用Ask重定向 可以解決此種情況。
3.3 Cluster集群節(jié)點(diǎn)的通訊協(xié)議:Gossip
一個Redis集群由多個節(jié)點(diǎn)組成,各個節(jié)點(diǎn)之間是怎么通信的呢?通過Gossip協(xié)議 !Gossip是一種謠言傳播協(xié)議,每個節(jié)點(diǎn)周期性地從節(jié)點(diǎn)列表中選擇 k 個節(jié)點(diǎn),將本節(jié)點(diǎn)存儲的信息傳播出去,直到所有節(jié)點(diǎn)信息一致,即算法收斂了。
Gossip協(xié)議基本思想:一個節(jié)點(diǎn)想要分享一些信息給網(wǎng)絡(luò)中的其他的一些節(jié)點(diǎn)。于是,它周期性的隨機(jī)選擇一些節(jié)點(diǎn),并把信息傳遞給這些節(jié)點(diǎn)。這些收到信息的節(jié)點(diǎn)接下來會做同樣的事情,即把這些信息傳遞給其他一些隨機(jī)選擇的節(jié)點(diǎn)。一般而言,信息會周期性的傳遞給N個目標(biāo)節(jié)點(diǎn),而不只是一個。這個N被稱為fanout
Redis Cluster集群通過Gossip協(xié)議進(jìn)行通信,節(jié)點(diǎn)之前不斷交換信息,交換的信息內(nèi)容包括節(jié)點(diǎn)出現(xiàn)故障、新節(jié)點(diǎn)加入、主從節(jié)點(diǎn)變更信息、slot信息 等等。gossip協(xié)議包含多種消息類型,包括ping,pong,meet,fail,等等
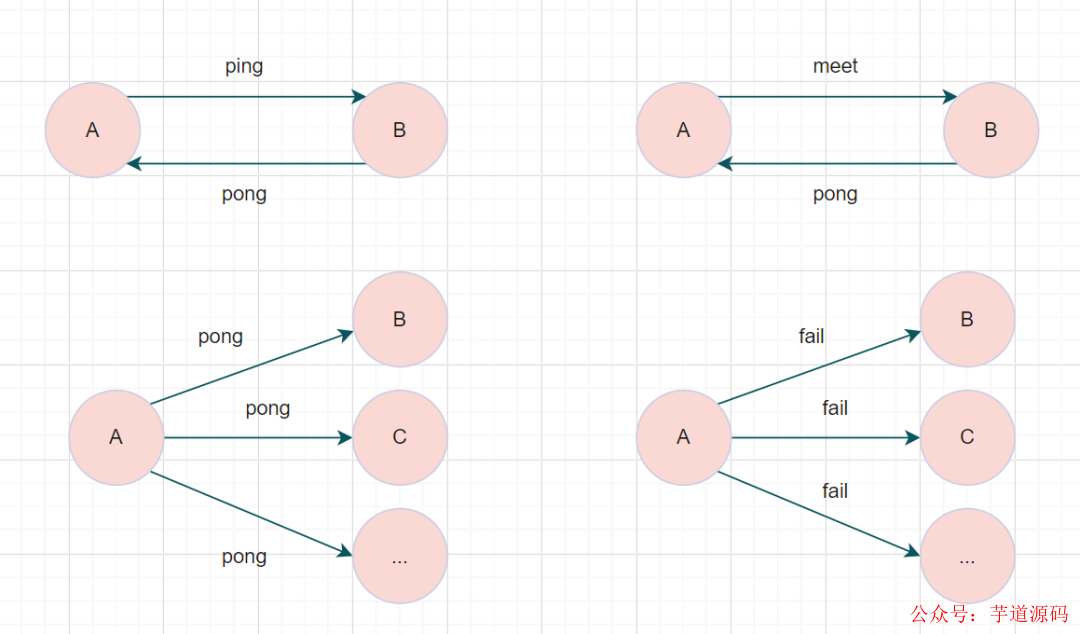
meet消息:通知新節(jié)點(diǎn)加入。消息發(fā)送者通知接收者加入到當(dāng)前集群,meet消息通信正常完成后,接收節(jié)點(diǎn)會加入到集群中并進(jìn)行周期性的ping、pong消息交換。
ping消息:節(jié)點(diǎn)每秒會向集群中其他節(jié)點(diǎn)發(fā)送 ping 消息,消息中帶有自己已知的兩個節(jié)點(diǎn)的地址、槽、狀態(tài)信息、最后一次通信時間等
pong消息:當(dāng)接收到ping、meet消息時,作為響應(yīng)消息回復(fù)給發(fā)送方確認(rèn)消息正常通信。消息中同樣帶有自己已知的兩個節(jié)點(diǎn)信息。
fail消息:當(dāng)節(jié)點(diǎn)判定集群內(nèi)另一個節(jié)點(diǎn)下線時,會向集群內(nèi)廣播一個fail消息,其他節(jié)點(diǎn)接收到fail消息之后把對應(yīng)節(jié)點(diǎn)更新為下線狀態(tài)。
特別的,每個節(jié)點(diǎn)是通過集群總線(cluster bus) 與其他的節(jié)點(diǎn)進(jìn)行通信的。通訊時,使用特殊的端口號,即對外服務(wù)端口號加10000。例如如果某個node的端口號是6379,那么它與其它nodes通信的端口號是 16379。nodes 之間的通信采用特殊的二進(jìn)制協(xié)議。
3.4 故障轉(zhuǎn)移
Redis集群實(shí)現(xiàn)了高可用,當(dāng)集群內(nèi)節(jié)點(diǎn)出現(xiàn)故障時,通過故障轉(zhuǎn)移 ,以保證集群正常對外提供服務(wù)。
redis集群通過ping/pong消息,實(shí)現(xiàn)故障發(fā)現(xiàn)。這個環(huán)境包括主觀下線和客觀下線 。
主觀下線: 某個節(jié)點(diǎn)認(rèn)為另一個節(jié)點(diǎn)不可用,即下線狀態(tài),這個狀態(tài)并不是最終的故障判定,只能代表一個節(jié)點(diǎn)的意見,可能存在誤判情況。
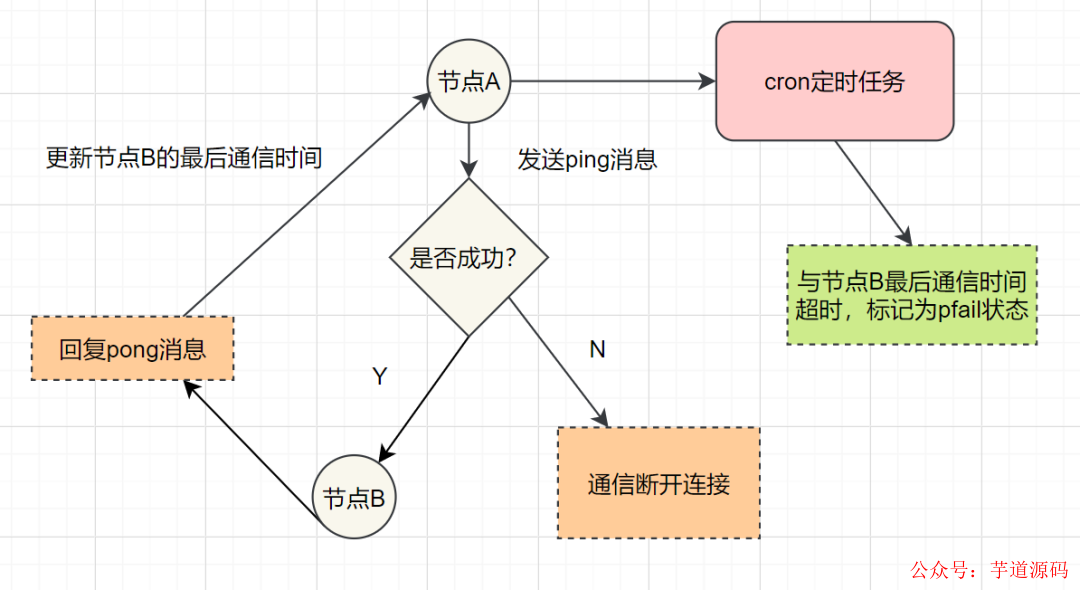 主觀下線
主觀下線
客觀下線: 指標(biāo)記一個節(jié)點(diǎn)真正的下線,集群內(nèi)多個節(jié)點(diǎn)都認(rèn)為該節(jié)點(diǎn)不可用,從而達(dá)成共識的結(jié)果。如果是持有槽的主節(jié)點(diǎn)故障,需要為該節(jié)點(diǎn)進(jìn)行故障轉(zhuǎn)移。
假如節(jié)點(diǎn)A標(biāo)記節(jié)點(diǎn)B為主觀下線,一段時間后,節(jié)點(diǎn)A通過消息把節(jié)點(diǎn)B的狀態(tài)發(fā)到其它節(jié)點(diǎn),當(dāng)節(jié)點(diǎn)C接受到消息并解析出消息體時,如果發(fā)現(xiàn)節(jié)點(diǎn)B的pfail狀態(tài)時,會觸發(fā)客觀下線流程;
當(dāng)下線為主節(jié)點(diǎn)時,此時Redis Cluster集群為統(tǒng)計(jì)持有槽的主節(jié)點(diǎn)投票,看投票數(shù)是否達(dá)到一半,當(dāng)下線報告統(tǒng)計(jì)數(shù)大于一半時,被標(biāo)記為客觀下線 狀態(tài)。
流程如下:
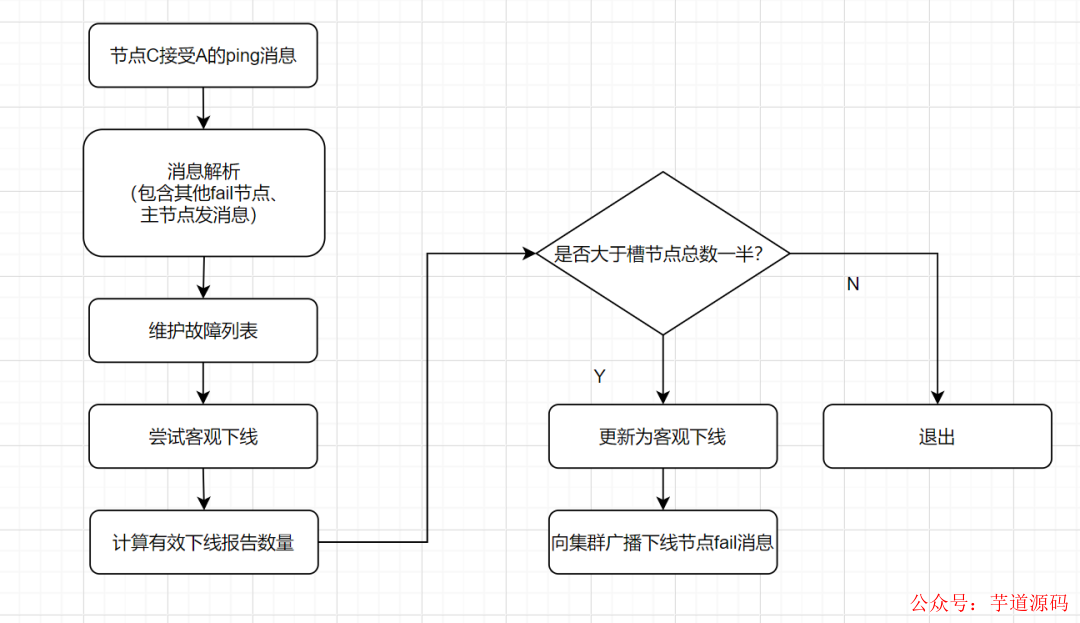 客觀下線
客觀下線
故障恢復(fù) :故障發(fā)現(xiàn)后,如果下線節(jié)點(diǎn)的是主節(jié)點(diǎn),則需要在它的從節(jié)點(diǎn)中選一個替換它,以保證集群的高可用。流程如下:
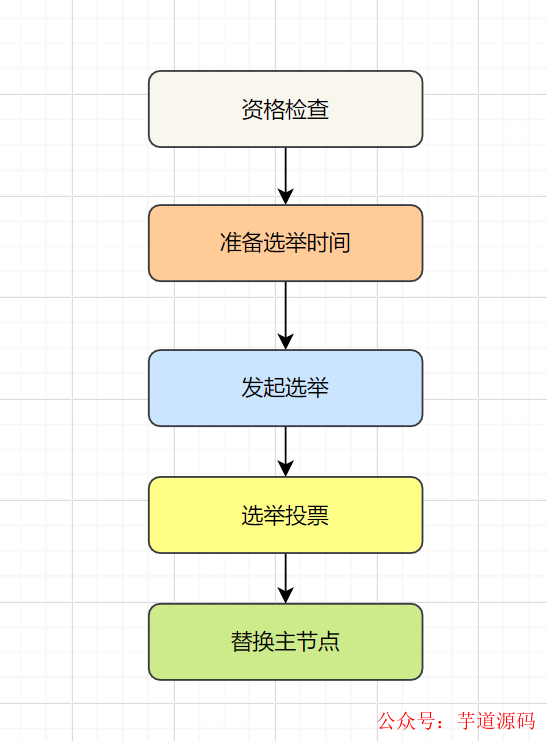
資格檢查:檢查從節(jié)點(diǎn)是否具備替換故障主節(jié)點(diǎn)的條件。
準(zhǔn)備選舉時間:資格檢查通過后,更新觸發(fā)故障選舉時間。
發(fā)起選舉:到了故障選舉時間,進(jìn)行選舉。
選舉投票:只有持有槽的主節(jié)點(diǎn) 才有票,從節(jié)點(diǎn)收集到足夠的選票(大于一半),觸發(fā)替換主節(jié)點(diǎn)操作
3.5 加餐:為什么Redis Cluster的Hash Slot 是16384?
對于客戶端請求過來的鍵值key,哈希槽=CRC16(key) % 16384,CRC16算法產(chǎn)生的哈希值是16bit的,按道理該算法是可以產(chǎn)生2^16=65536個值,為什么不用65536,用的是16384(2^14)呢?
大家可以看下作者的原始回答:
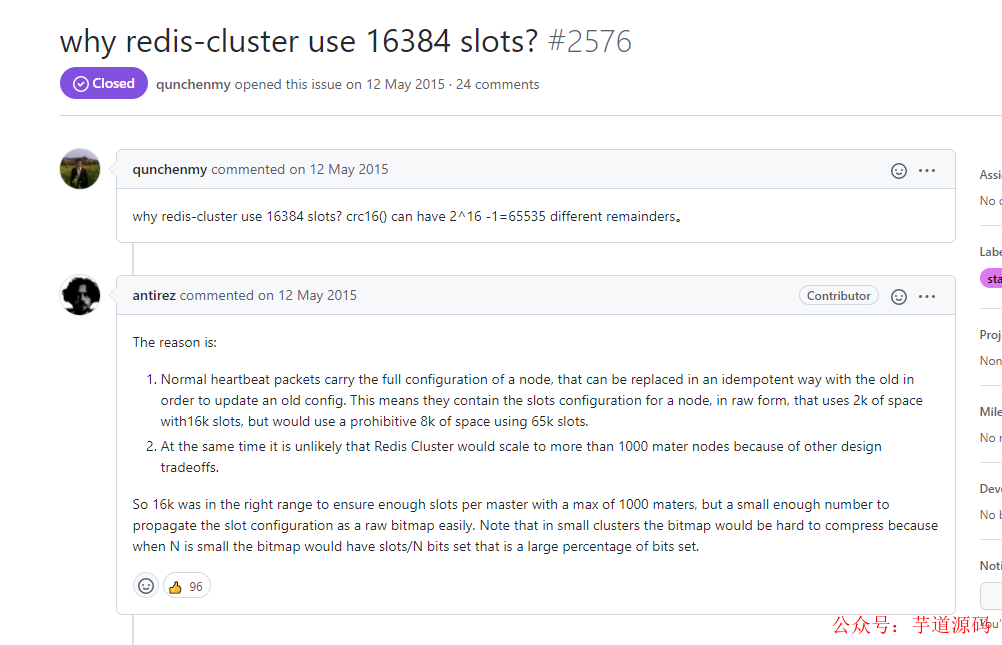
Redis 每個實(shí)例節(jié)點(diǎn)上都保存對應(yīng)有哪些slots,它是一個 unsigned char slots[REDIS_CLUSTER_SLOTS/8] 類型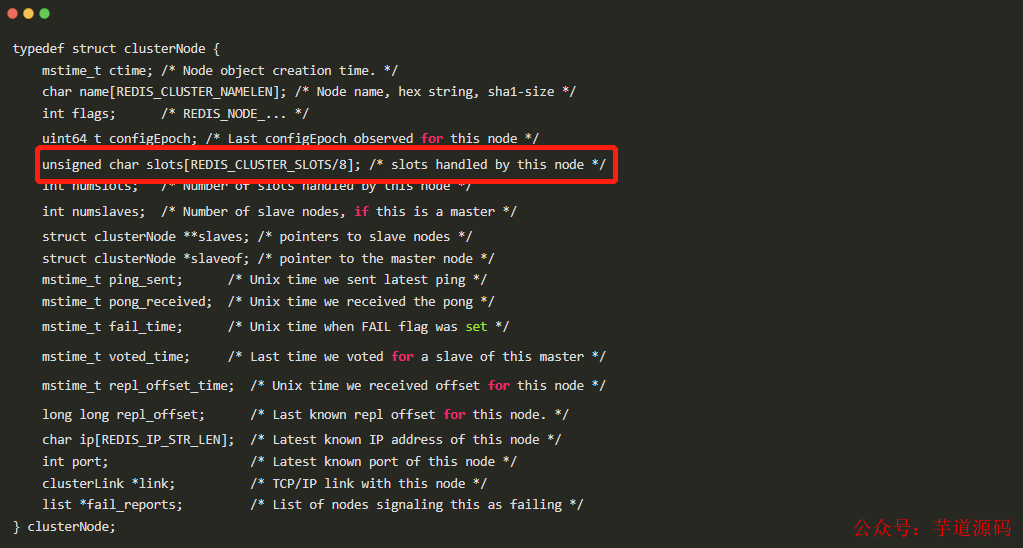
在redis節(jié)點(diǎn)發(fā)送心跳包時需要把所有的槽放到這個心跳包里,如果slots數(shù)量是 65536 ,占空間= 65536 / 8(一個字節(jié)8bit) / 1024(1024個字節(jié)1kB) =8kB ,如果使用slots數(shù)量是 16384 ,所占空間 = 16384 / 8(每個字節(jié)8bit) / 1024(1024個字節(jié)1kB) = 2kB ,可見16384個slots比 65536省 6kB內(nèi)存左右,假如一個集群有100個節(jié)點(diǎn),那每個實(shí)例里就省了600kB啦
一般情況下Redis cluster集群主節(jié)點(diǎn)數(shù)量基本不可能超過1000個,超過1000會導(dǎo)致網(wǎng)絡(luò)擁堵。對于節(jié)點(diǎn)數(shù)在1000以內(nèi)的Redis cluster集群,16384個槽位其實(shí)夠用了。
既然為了節(jié)省內(nèi)存網(wǎng)絡(luò)開銷,為什么 slots不選擇用8192(即16384/2) 呢?
8192 / 8(每個字節(jié)8bit) / 1024(1024個字節(jié)1kB) = 1kB ,只需要1KB!可以先看下Redis 把 Key 換算成所屬 slots 的方法
unsignedintkeyHashSlot(char*key,intkeylen){
ints,e;/*start-endindexesof{and}*/
for(s=0;s
Redis 將key換算成slots 的方法:其實(shí)就是是將crc16(key) 之后再和slots的數(shù)量進(jìn)行與計(jì)算
這里為什么用0x3FFF(16383) 來計(jì)算,而不是16384呢?因?yàn)樵诓划a(chǎn)生溢出的情況下 x % (2^n)等價于x & (2^n - 1)即 x % 16384 == x & 16383
那到底為什么不用8192呢?
crc16 出來結(jié)果,理論上出現(xiàn)重復(fù)的概率為 1?65536,但實(shí)際結(jié)果重復(fù)概率可能比這個大不少,就像crc32 結(jié)果 理論上 1/40億 分之一,但實(shí)際有人測下來10萬碰撞的概率就比較大了。假如 slots 設(shè)置成 8192, 200個實(shí)例的節(jié)點(diǎn)情況下,理論值是 每40個不同key請求,命中就會失效一次,假如節(jié)點(diǎn)數(shù)增加到400,那就是20個請求。并且1kb 并不會比 2k 省太多,性價比不是特別高,所以可能 選16384會更為通用一點(diǎn)
責(zé)任編輯:彭菁
-
管理系統(tǒng)
+關(guān)注
關(guān)注
1文章
2265瀏覽量
35562 -
小程序
+關(guān)注
關(guān)注
1文章
233瀏覽量
11990 -
Redis
+關(guān)注
關(guān)注
0文章
368瀏覽量
10780
原文標(biāo)題:Redis主從、哨兵、 Cluster集群一鍋端!
文章出處:【微信號:芋道源碼,微信公眾號:芋道源碼】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
Redis Cluster的基本原理及實(shí)現(xiàn)細(xì)節(jié)
Redis的四種模式復(fù)制、哨兵、Cluster以及集群模式
單機(jī)redis和redisCluster集群是如何獲取所有key的

什么是Redis主從復(fù)制
Cloud MemoryStore for Redis Cluster 正式發(fā)布






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論