 如何將ChatGPT的能力蒸餾到另一個大模型
如何將ChatGPT的能力蒸餾到另一個大模型
如何將ChatGPT的能力蒸餾到另一個大模型,是當前許多大模型研發的研發范式。當前許多模型都是采用chatgpt來生成微調數據,如self instruct,然后加以微調,這其實也是一種數據蒸餾的模擬路線。
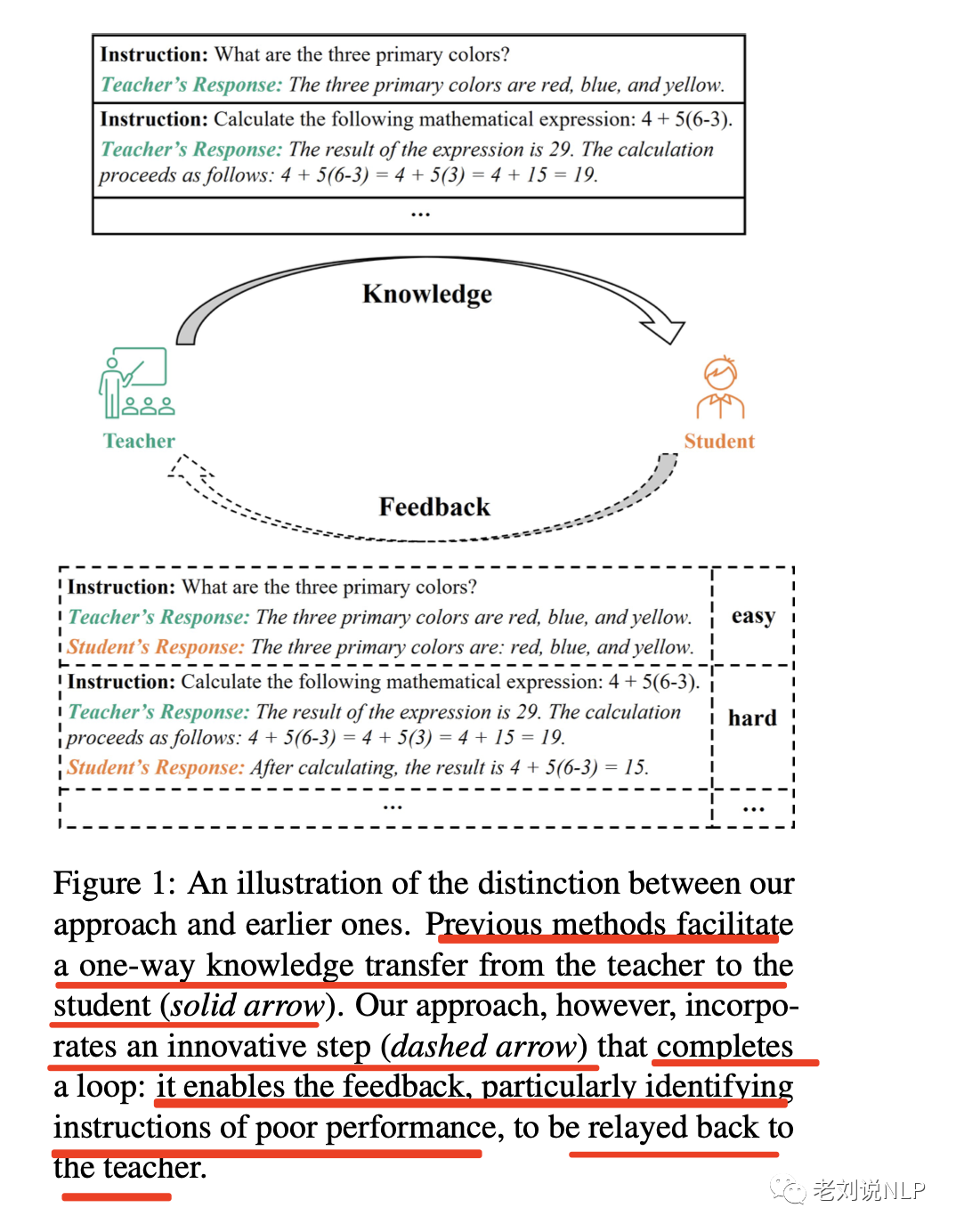
不過,這種數據蒸餾的方式,只是單向的,并沒有進行數據反饋。
最近的一篇文章《Lion: Adversarial Distillation of Closed-Source Large Language Model》 提出了一個將知識從一個復雜的、閉源的大型語言模型(LLM)轉移到一個緊湊的、開源的LLM的做法,其中加入了數據反饋的閉環機制,將蒸餾的指令分成困難和簡單兩類指令,并且逐步來生成困難指令有偏的引導開源LLM模型的學習,取得了較好的效果。
論文地址:https://arxiv.org/pdf/2305.12870.pdf
整體框架AKD的工作如圖2所示,在一個迭代中分成三個階段:1)模仿階段,使學生的反應與教師的反應保持一致;2)辨別階段,識別困難指令;3)生成階段,產生新的困難指令,以升級對學生模型的挑戰。
該對抗性知識蒸餾框架可以被解釋為一個動態的最小-最大游戲:在模仿階段,對學生進行微調,使其與教師在硬樣本上的模型差異最小;在辨別和生成階段,根據學生模型的學習進度,制作新的困難樣本,使模型差異最大化。
從教育的角度上來看,這種框架推動了學生模型去發現原本隱藏的知識,為完全理解鋪平道路,隨著訓練的進行,經過幾次迭代,系統能夠最好能達到平衡狀態。這時,學生模型已經掌握了所有的硬樣本,裁判員R不再能夠區分學生S和教師T的模型。
為了驗證方法的有效性,該框架將ChatGPT的知識轉移到LLaMA上,選擇Alpaca的訓練數據(僅由175條手動選擇的種子指令生成)作為初始訓練指令,并執行三次AKD的迭代,總共訓練了70K數據,最終得到模型Lion,實驗結果表明,7B模型Lion都表現出較好的性能。
本文對該工作的具體算法思想進行介紹,供大家一起參考,其中關于各種prompt,包括打分prompt,指令擴充prompt都是可以關注的點。
一、算法思想方法
利用一個復雜的教師模型T(x; θT)的知識,目標是制作一個更輕便的學生模型S(x; θS)。
理想情況下,如果模型差異的期望值(表示教師T和學生S之間的預測差異)在統一數據分布上達到最小,那么學生模型就是最優的。
受對抗性知識提煉(AKD)的啟發,該框架轉向優化期望值的上限--"難樣本 "上的模型差異期望值,其中教師T和學生S的表現差距相對較大。
這些 "難樣本 "傾向于主導模型差異的期望值。因此,通過在這些 "難樣本 "上對學生模型S進行優化,可以有效和高效地重新控制整體預期模型差異。
其基本原理是相當直接,可以類比于現實世界的教育場景:持續關注學生認為難以掌握的 "難 "知識,是提高學生能力的最有效方法。
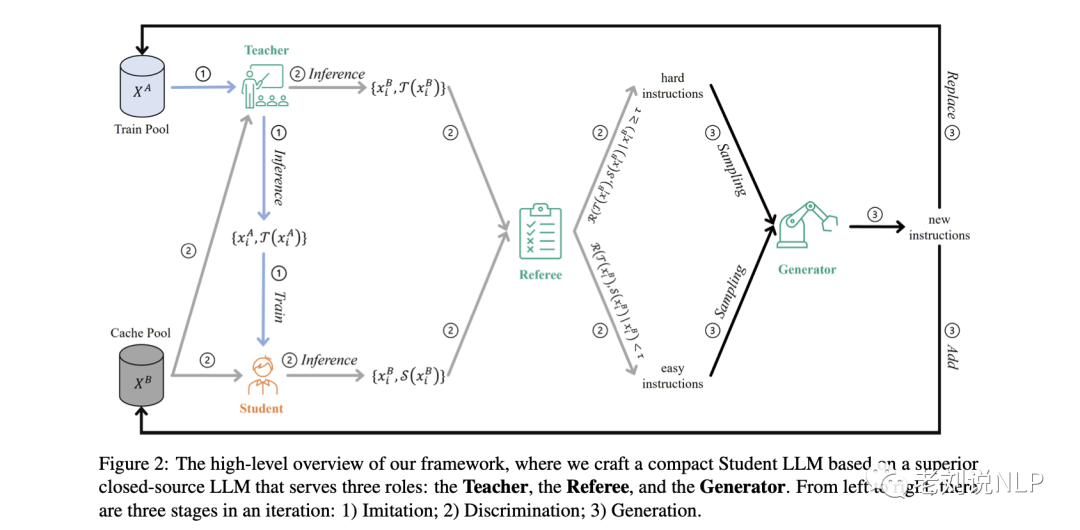
圖2描述了對抗性知識蒸餾的整個框架,它包含了一個迭代的三個階段:
1)模仿階段,使學生的反應與教師的反應相一致;
2)辨別階段,識別難樣本;
3)生成階段,產生新的硬樣本,以升級學生模型所面臨的挑戰。
1、初始化
如圖2所示,框架中建立了四個角色和兩個數據池,并使用使用LLaMA來初始化學生模型S。
通過使用ChatGPT來初始化教師模型T、裁判員R和生成器G,
該框架從一個給定的初始Train Pool XA = {xAi }i∈[1,NA]開始迭代,其中xAi是XA中的第i條指令,NA是XA中的樣本數。
Cache Pool XB的初始化與XA相同,由評估S和T性能的指令組成。
注意,這里的指令是由指令提示和實例輸入組成的,如下表所示:

2、模仿階段
損失函數采用Kullback-Leibler Divergence,即KL散度,用于量化教師模型T和學生模型S的輸出概率分布的差異。
因此,為了將教師的知識傳遞給學生,通過教師T向前傳播訓練池XA中的指令,構建訓練數據{xAi, T (xAi )}i∈[1,N A]。
有了這些訓練數據,其中xAi作為輸入,T(xAi )作為目標,通過最小化交叉熵損失來微調我們的學生模型S。
3、識別階段
圖2展示了從緩存池開始的判別階段,表示為XB。
大型語言模型如ChatGPT,有可能作為無偏見的裁判來衡量兩個不同的人工智能助手產生的回復質量,也就是使用chatgpt進行打分。
在具體實現上,將緩存池XB中的每條指令xBi通過教師T和學生S反饋,分別產生輸出T(xBi)和S(xBi)。然后要求裁判員R量化教師的響應T(xBi)和學生的響應S(xBi)之間的質量差異,di用來表示這兩個分數之間的差異。di的計算公司如下:
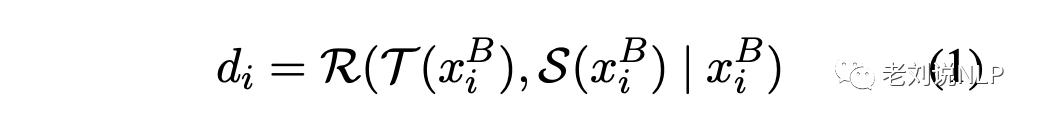

上述過程是通過使用表2的提示模板來完成,該模板要求LLM考慮兩個回答的有用性、相關性、準確性和詳細程度,并輸出兩個分數。
兩個分數之差,就是di,可以通過設置一個閾值τ(在實驗中使用的是1.0),將困難的指令劃分為那些di≥τ的指令,而其他的則被識別為簡單的指令。
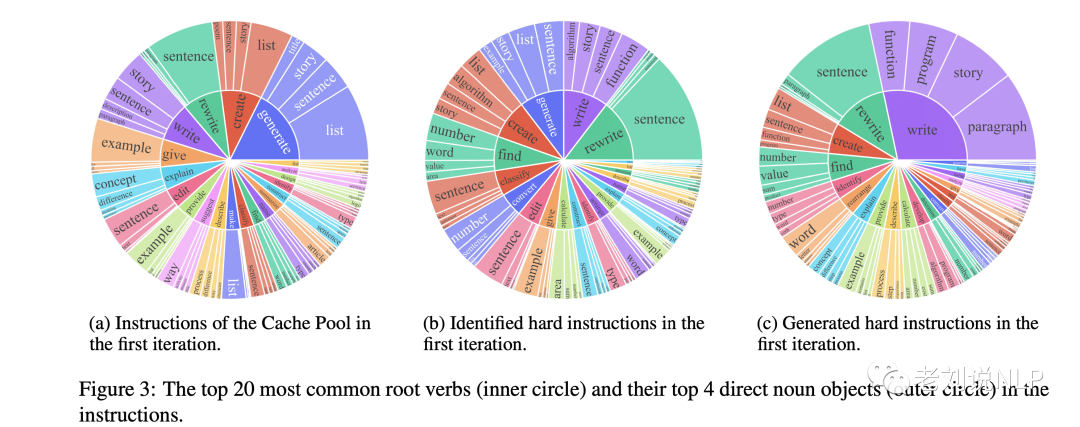
圖3直觀地展示了在第一次迭代中哪些類型的指令被識別為困難指令。與cache池中的指令相比,被識別的羅曼指令的分布是非常不同的,它們更側重于復雜的任務,如數學、編碼等。
4、生成階段
在仔細識別了困難指令之后,生成階段的目標是產生反映這些困難指令所對應的數據分布的樣本。
這個過程通過使用復雜的LLM作為生成器G來實現,并從困難指令中隨機抽取一條指令,并提示生成器G生成一條新指令。新生成的指令需要與同一領域有關,并與抽樣指令的任務類型相匹配,如下表3顯示了用于該提示的模板。

如圖3所示,指令要求新生成的硬性結構的分布似乎與先前確定的硬性指令的分布相類似。為了減輕災難性遺忘的問題并增加生成指令的多樣性,還從簡單指令中隨機抽出一條指令,并提示生成器G生成一條新的指令,該指令與抽出的指令屬于同一領域,但也呈現出更多的長尾分布,使用的指令模板如下所示:

為了控制迭代的比率,在每個迭代中,將N定義為新生成指令的總數量,然后在生成的困難指令和簡單指令之間保持1:1的比例。
為了保證多樣性,只有當一條新指令與緩存池中任何現有結構的ROUGE-L重疊度低于0.7時,才會被視為有效。
最后,將對Train Pool進行更新,用新生成的指令替換現有指令。同時通過加入這些新生成的指令來擴充緩存池。
在具體訓練過程中,該學生模型是用預先訓練好的LLaMA 7B進行初始化。Train Pool和Cache Pool用Alpaca的52K in-struction數據集進行初始化。迭代總次數設置為3次,每次迭代增加6K新生成的指令,最終形成訓練了70K數據。
在花費方面,學生模型在8個A100 GPU上訓練了3個epochs,請求使用gpt-3.5-turbo API大約36萬次,這個數字大約是WizardLM使用量624k的一半,產生了相當大的費用,接近500美元。
二、測試數據集與實驗模型
1、數據集
評估LLM在各種任務中的功效是一個相當大的挑戰,因為不同的任務需要相當不同的專業知識,而且許多任務不能用自動指標來評估,在實驗中采用了兩個著名的數據集:
Vicuna-Instructions:一個由GPT-4合成的數據集,包含80個基線模型認為具有挑戰性的問題。該數據集橫跨九個不同的類別,即通用、知識、角色扮演、常識、費米、反事實、編碼、數學和寫作。以用戶為導向的指導。
User oriented Instructions:一個人工組裝的數據集,包括252個結構,其動機是71個面向用戶的應用,如Grammarly、StackOverflow、Overleaf。
2、對比模型
對比實驗選用五個模型:
LLaMA:一個基礎語言模型的集合,參數范圍從7B到65B。它在公開可用的數據集上訓練了數萬億個標記,并被證明在多種基準中優于較大尺寸的LLM,如GPT-3(175B)。使用LLaMA 3的7B參數版本。
Alpaca:以LLaMA為基礎,通過查詢OpenAI的text-davinci-003模型產生的52K個指令跟隨實例進行微調。使用Alpaca 4的7B參數版本。
Vicuna:以LLaMA為基礎,并根據從ShareGPT收集的7萬個用戶共享對話進行了微調。使用FastChat 5的7B參數版本。
WizardLM:使用Evol-Instruct方法,將Alapca的52000條指令的例子引導到250000條更復雜的指令集中。使用WizardLM 6中的7B參數版本。
ChatGPT:通過監督和強化學習技術進行微調,由人類培訓師提供必要的反饋和指導。使用ChatGPT3.5 turbo版本。
3、評測結果
首先看自動化評估,使用GPT-4的方式進行模型自動打分,用于評價在給定封閉集合上的性能表現,對應的prompt如下,采用與識別困難樣本的prompt一致。

實現結果如下,GBS評測來看,Lion除了與ChatGPT有差距外,均好于其他模型。
再看使用人工評價的方式,進行對齊能力,如果一個聊天助手的特點是樂于助人、誠實和無害(HHH),則被認為是一致的。這些標準被用來衡量人工智能(AI)系統與人類價值觀一致的程度。結果如下:

我們可以看到,Lion也能得到一個與自動化評測一致的效果。
下面再看一個具體的模型預測效果,這是個比較好的case:

總結
本文對《Lion: Adversarial Distillation of Closed-Source Large Language Model》這一工作進行了介紹。
與Alpaca和WizardLM這樣只對學生模型進行一次微調的方法相比,該工作提出的對抗性知識蒸餾方法采用了對學生模型的迭代更新,得到了更好的效果。
不過這種迭代方法也有一些現實問題,例如:
首先,不可避免地導致了較慢的迭代速度。
其次,與傳統的對抗性知識蒸餾方法不同的是,該方法使用一個黑箱和參數凍結的ChatGPT來扮演這個角色,LLM的質量在新指令的生成中相當重要。
另外,在評估方面,盡管利用GPT-4進行的自動評估在評估聊天機器人的表現方面展示了良好的前景,但該技術尚未達到成熟和準確的水平,特別是考慮到大型語言模型容易產生不存在的或 "幻覺 "的信息。此外,缺乏一個統一的標準來評估大型語言模型,這降低了基于人類的評估的說服力。
最后,為聊天機器人創建一個全面的、標準化的評估系統是一個普遍的研究挑戰,需要進一步的探索和研究。當前,已經出現了很多魚龍混雜的各類榜單,而且排名的結果還不不一樣,這其實又是另一個混沌狀態,這需要引起我們的重視,并擦亮眼睛。
責任編輯:彭菁
-
數據
+關注
關注
8文章
6715瀏覽量
88321 -
模型
+關注
關注
1文章
3032瀏覽量
48375 -
ChatGPT
+關注
關注
28文章
1517瀏覽量
6955
原文標題:如何更好地蒸餾ChatGPT模型能力:Lion閉源大型語言模型的對抗性蒸餾模型原理及實驗工作介紹
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論