") HadaFS可擴(kuò)展性和性能的優(yōu)勢(shì)
HadaFS可擴(kuò)展性和性能的優(yōu)勢(shì)
本篇文章發(fā)表于頂級(jí)會(huì)議 FAST 2023,由無錫國(guó)家超級(jí)計(jì)算中心、清華大學(xué)、山東大學(xué)、中國(guó)工程院的學(xué)者為我們分享了他們?cè)诩舛顺?jí)計(jì)算機(jī)和高性能計(jì)算領(lǐng)域的最新的成果,提出了一種名為 HadaFS 的新型 Burst Buffer 文件系統(tǒng),實(shí)現(xiàn)了可擴(kuò)展性和性能的優(yōu)勢(shì)與數(shù)據(jù)共享和部署成本的優(yōu)勢(shì)的良好結(jié)合。
相關(guān)文章: 收藏:多家Burst Buffer存儲(chǔ)技術(shù)解析(附下載) Burst Buffer技術(shù)為何在HPC如此盛行
一、背景
高性能計(jì)算(HPC)正在經(jīng)歷計(jì)算規(guī)模和數(shù)據(jù)爆發(fā)式增長(zhǎng)的時(shí)代。為了滿足 HPC 應(yīng)用不斷增長(zhǎng)的 I/O 需求或突發(fā)流量 I/O 性能需求,研究人員提出 Burst Buffer(BB)技術(shù),通過 SSD 等新型存儲(chǔ)介質(zhì)構(gòu)建數(shù)據(jù)加速層,作為前端計(jì)算和后端存儲(chǔ)之間的緩沖區(qū),為 HPC 應(yīng)用提供高速 I/O 服務(wù),提高了系統(tǒng)的性能。
取決于 SSD 陣列的部署位置 ,BB可以分為兩種類型:
1)本地BB,即SSD作為本地磁盤部署在每個(gè)計(jì)算節(jié)點(diǎn)上,專門為單個(gè)計(jì)算節(jié)點(diǎn)服務(wù);
2)共享BB,即SSD部署在計(jì)算節(jié)點(diǎn)可以訪問的專用節(jié)點(diǎn)上 (例如 I/O 轉(zhuǎn)發(fā)節(jié)點(diǎn)),以支持共享數(shù)據(jù)訪問。
本地 BB 具有良好的可擴(kuò)展性和性能優(yōu)勢(shì),系統(tǒng)性能可以隨著計(jì)算節(jié)點(diǎn)的數(shù)量線性增長(zhǎng)。但本地 BB 數(shù)據(jù)共享不友好,要么以靜態(tài)數(shù)據(jù)遷移方式運(yùn)行,要么需要應(yīng)用程序通過計(jì)算節(jié)點(diǎn)遷移數(shù)據(jù),遷移效率低下,造成計(jì)算資源浪費(fèi)。本地 BB 還會(huì)造成嚴(yán)重的資源浪費(fèi),因?yàn)?HPC 應(yīng)用程序之間 I/O 負(fù)載的差異巨大,數(shù)據(jù)密集型應(yīng)用程序相對(duì)較少。未來隨著超級(jí)計(jì)算機(jī)規(guī)模的迅速擴(kuò)大,本地BB的部署成本將急劇上升。
共享 BB 天然具有數(shù)據(jù)共享和部署成本的優(yōu)勢(shì),但難以為數(shù)十萬(wàn)規(guī)模的客戶端提供高效的數(shù)據(jù)訪問處理性能。如何統(tǒng)一本地BB和共享BB的優(yōu)勢(shì),滿足多樣化的應(yīng)用需求,降低BB的建設(shè)成本,支持大規(guī)模的BB數(shù)據(jù)管理和遷移,是亟待解決的問題。BB 雖然具有高性能的優(yōu)勢(shì),但具有容量小的缺點(diǎn),所以 BB 必須與 GFS(如 Lustre 等全局文件系統(tǒng))協(xié)同工作才能滿足容量要求。
SNS基于神威新一代異構(gòu)高性能眾核處理器和互聯(lián)網(wǎng)絡(luò)芯片構(gòu)建,采用與神威太湖之光相似的架構(gòu)。超級(jí)計(jì)算機(jī)由計(jì)算系統(tǒng)、互聯(lián)網(wǎng)絡(luò)系統(tǒng)、軟件系統(tǒng)、存儲(chǔ)系統(tǒng)、維護(hù)診斷系統(tǒng)、供電系統(tǒng)和冷卻系統(tǒng)組成。下圖顯示了總體架構(gòu)。
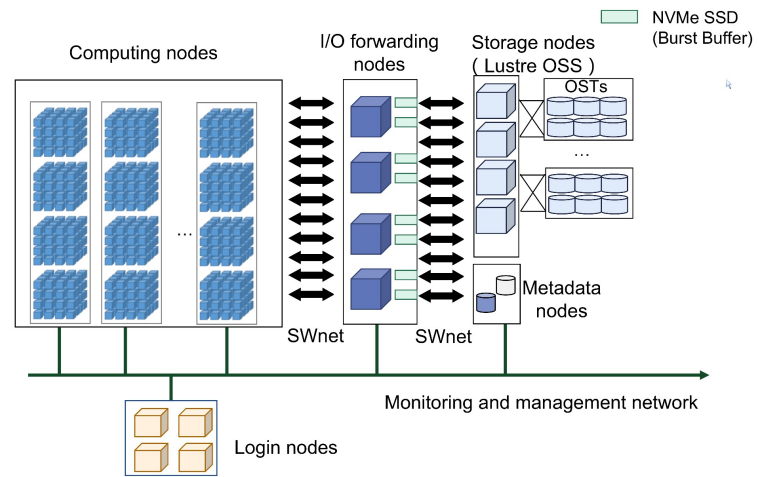
圖1SNS的架構(gòu)
二、動(dòng)機(jī)問題
BB 技術(shù)已被廣泛引入尖端超級(jí)計(jì)算機(jī),但現(xiàn)有的主流 BB 技術(shù)仍然存在許多局限性。
問題1:
隨著百億億級(jí)計(jì)算的壁壘被打破,超級(jí)計(jì)算機(jī)的 I/O 并發(fā)量可達(dá)數(shù)十萬(wàn),同時(shí) AI、工作流等數(shù)據(jù)共享應(yīng)用占比提升導(dǎo)致 I/O 需求發(fā)生變化,大規(guī)模數(shù)據(jù)的高速共享存儲(chǔ)對(duì) BB 架構(gòu)的可擴(kuò)展性提出了挑戰(zhàn)。
現(xiàn)有超級(jí)計(jì)算機(jī)計(jì)算機(jī)采用的方案各有優(yōu)缺點(diǎn),例如,F(xiàn)rontier 使用獨(dú)立硬件分別構(gòu)建本地 BB 和共享 BB,但這種方法需要很多加速設(shè)備(SSD),建設(shè)和維護(hù)成本高。
問題2:
傳統(tǒng)的文件系統(tǒng)的文件管理在目錄樹結(jié)構(gòu)中實(shí)現(xiàn)并且嚴(yán)格遵循 POSIX 協(xié)議,但在 HPC 中,計(jì)算節(jié)點(diǎn)通常負(fù)責(zé)讀寫數(shù)據(jù),很少執(zhí)行目錄樹訪問,通過放寬 POSIX 協(xié)議也可以提高性能。不同應(yīng)用程序?qū)ξ募到y(tǒng)一致性的需求不同,一致性程度越高 ,它的適應(yīng)性就越強(qiáng),但代價(jià)是開銷越大。靈活地選擇一致性語(yǔ)義來平衡應(yīng)用程序的需求并利用 BB 性能是一個(gè)很大的挑戰(zhàn)。
問題3:
大多數(shù)應(yīng)用程序都可以使用 BB 來加快 I/O 性能,但 BB 的利用率較低,需要為用戶開發(fā)靈活的數(shù)據(jù)管理工具。BB 作為高速緩沖區(qū),并不是應(yīng)用程序持久化存儲(chǔ)數(shù)據(jù)的地方,因此 BB 系統(tǒng)需要考慮高效便捷地在 BB 和 GFS 之間遷移數(shù)據(jù)。目前還不支持用戶在應(yīng)用運(yùn)行過程中動(dòng)態(tài)管理 BB 的數(shù)據(jù)遷移,非常不利于 BB 的高效利用。
從成本控制的角度出發(fā),共享 BB 部署更適合未來的超大規(guī)模計(jì)算節(jié)點(diǎn)系統(tǒng),因?yàn)楣蚕?BB 可以部署在計(jì)算或數(shù)據(jù)轉(zhuǎn)發(fā)節(jié)點(diǎn)上。為了解決上述問題,本文研究如何從共享 BB 模型開始,獲得本地 BB 模型的優(yōu)勢(shì),以更好地滿足百億億級(jí)及以上 HPC 應(yīng)用程序的需求。
三、HadaFS的設(shè)計(jì)與實(shí)現(xiàn)
HadaFS概述
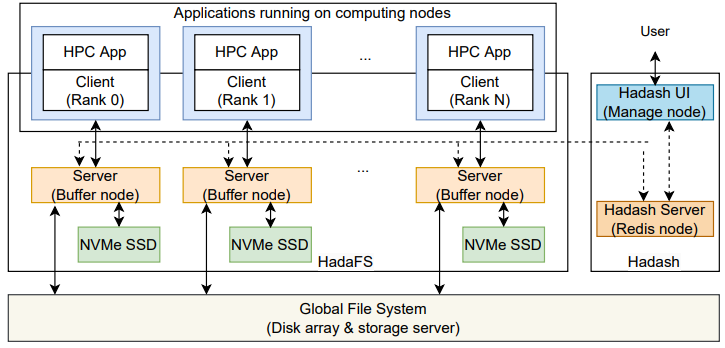
圖2 HadaFS的架構(gòu)
HadaFS 相當(dāng)于是堆疊在磁盤陣列或存儲(chǔ)服務(wù)器的全局文件系統(tǒng)上的一個(gè)分布式文件系統(tǒng),HadaFS 的整體架構(gòu)如上圖所示,包括HadaFS 客戶端、HadaFS 服務(wù)器、數(shù)據(jù)管理工具 Hadash。
?Hadash 運(yùn)行在用戶登錄節(jié)點(diǎn)上,用于管理全局文件系統(tǒng)與 HadaFS 之間的數(shù)據(jù)遷移。
?HadaFS 客戶端運(yùn)行在計(jì)算節(jié)點(diǎn)上,作為一個(gè)靜態(tài)/動(dòng)態(tài)庫(kù),攔截應(yīng)用程序的 POSIX I/O 請(qǐng)求并將其重定向到 HadaFS 服務(wù)器。
?HadaFS 服務(wù)器運(yùn)行在部署 NVMe SSD 的專用突發(fā)緩沖節(jié)點(diǎn)上,提供全局?jǐn)?shù)據(jù)和元數(shù)據(jù)分離的存儲(chǔ)服務(wù)。
HadaFS 作為共享突發(fā)緩沖文件系統(tǒng),可以為每個(gè)客戶端提供全局視圖。HadaFS 中的每個(gè)文件都與兩種類型的服務(wù)器相關(guān)聯(lián)。一種是數(shù)據(jù)存儲(chǔ)服務(wù)器,通過 NVMe SSD 上的基礎(chǔ)文件系統(tǒng)存儲(chǔ) HadaFS 文件的數(shù)據(jù),另一種是元數(shù)據(jù)存儲(chǔ)服務(wù)器,通過高性能數(shù)據(jù)庫(kù)(RocksDB)存儲(chǔ) HadaFS 文件的元數(shù)據(jù)。
Localized Triage Architecture(LTA,本地化分流架構(gòu))
HadaFS 遵循繞過內(nèi)核的思路,直接將客戶端掛載到應(yīng)用程序中使用,避免引入內(nèi)核的I/O請(qǐng)求stage-in和stage-out開銷。為了更好地給應(yīng)用程序提高全局文件視圖,HadaFS 提出了名為 LTA 的新方法,每個(gè) HadaFS 客戶端只連接一臺(tái)HadaFS 服務(wù)器(橋接服務(wù)器),橋接服務(wù)器負(fù)責(zé)處理客戶端產(chǎn)生的所有I/O請(qǐng)求,并將數(shù)據(jù)寫入底層文件。當(dāng)客戶端需要訪問另一臺(tái)服務(wù)器上的數(shù)據(jù)時(shí),必須通過橋接服務(wù)器進(jìn)行轉(zhuǎn)發(fā)。因此,服務(wù)器是一個(gè)全連接結(jié)構(gòu)。
LTA 為每個(gè)計(jì)算節(jié)點(diǎn)匹配了一個(gè)橋接服務(wù)器以提供相當(dāng)于本地 BB 的服務(wù),并通過所有橋接服務(wù)器之間的全互聯(lián)支持所有客戶端的共享,結(jié)合了本地 BB 和共享 BB 的優(yōu)點(diǎn)。
LTA 還提供了新的掛載接口,應(yīng)用程序可以指定客戶端到服務(wù)器的映射,這有助于減少數(shù)據(jù)轉(zhuǎn)發(fā)。HadaFS 掛載后,應(yīng)用程序可以通過與 POSIX 文件操作完全一樣的接口進(jìn)行 I/O 操作。
文件命名空間和元數(shù)據(jù)處理
在 HPC 中計(jì)算節(jié)點(diǎn)通常負(fù)責(zé)讀寫數(shù)據(jù),很少執(zhí)行目錄樹訪問。為了提高可擴(kuò)展性和性能,HadaFS 放棄了目錄樹的思想,采用了全路徑索引方法。數(shù)據(jù)存儲(chǔ)在生成該文件的 HadaFS 客戶端對(duì)應(yīng)的橋接服務(wù)器上,文件元數(shù)據(jù)以 key-value 方式存儲(chǔ),文件路徑的哈希值是一個(gè)全局唯一ID(key)。
每個(gè) HadaFS 服務(wù)器上都維護(hù)著兩種元數(shù)據(jù)數(shù)據(jù)庫(kù),它們的數(shù)據(jù)結(jié)構(gòu)如下圖所示。
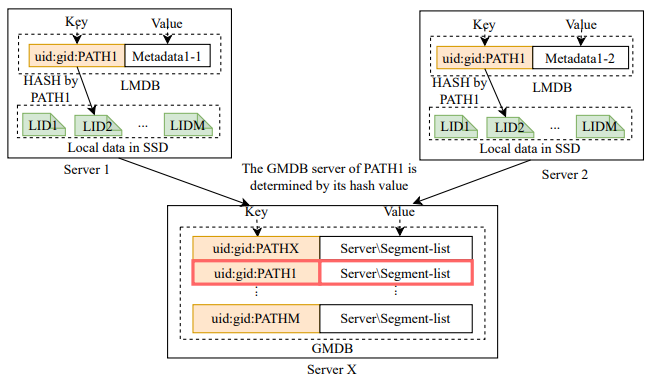
圖3 HadaFS服務(wù)器上的兩張K-V表
本地元數(shù)據(jù)數(shù)據(jù)庫(kù)(LMDB)存儲(chǔ)了文件在本地讀寫過程中會(huì)變化的一些元信息,全局元數(shù)據(jù)數(shù)據(jù)庫(kù)(GMDB)存儲(chǔ)文件在所有服務(wù)器讀寫訪問過程中會(huì)變化的一些元信息。GMDB 負(fù)責(zé)維護(hù)文件數(shù)據(jù)段位置的全局列表,以支持 HadaFS 服務(wù)器之間數(shù)據(jù)的全局共享。注意:每個(gè)服務(wù)器都會(huì)維護(hù)本地文件的 GMDB。
元數(shù)據(jù)數(shù)據(jù)庫(kù)的 key 由用戶的 UID、GID 和 PATH 組成,GID 和 UID 用于控制字符串檢索的范圍,因?yàn)?HadaFS 使用字符串前綴匹配來檢索文件。
數(shù)據(jù)管理工具 Hadash
Hadash 支持用戶在目錄樹視圖中檢索和管理文件,按功能分為兩類:元數(shù)據(jù)信息查詢和數(shù)據(jù)遷移。
元數(shù)據(jù)信息查詢主要提供 ls、du、find、grep 等命令,Hadash 從元數(shù)據(jù)庫(kù)中獲取這些查詢類型操作的信息。其中 ls、find 支持目錄樹視圖的文件信息查詢,Hadash 采用前綴匹配的方式來呈現(xiàn)一個(gè)虛擬的目錄樹,前綴匹配的方式可以通過 LMDB 在本地執(zhí)行。其他涉及數(shù)據(jù)遷移的命令,Hadash 通過特定的 Redis 管道將命令發(fā)送到 HadaFS 服務(wù)器上的數(shù)據(jù)管理模塊執(zhí)行。下圖顯示了從 HadaFS 到 GFS 的數(shù)據(jù)遷移流程示例。
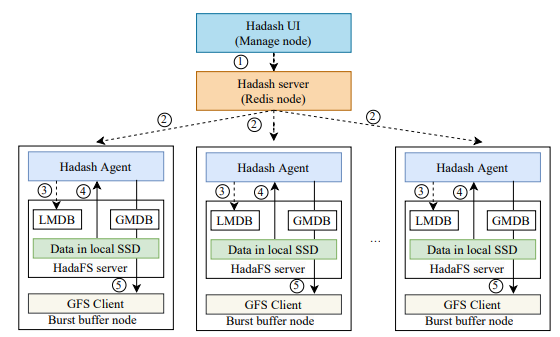
圖4 Hadash的退出流程
HadaFS 其他的一些優(yōu)化設(shè)計(jì)
HadaFS 采用了寬松的一致性語(yǔ)義,依賴于基本文件系統(tǒng)(ext4)的緩存機(jī)制來提高性能,其一致性語(yǔ)義主要依賴于元數(shù)據(jù)同步,不支持在客戶端和服務(wù)端緩存數(shù)據(jù)。為此,HadaFS針對(duì)不同的應(yīng)用場(chǎng)景提出了三種元數(shù)據(jù)同步策略。
?mode1: 是異步更新所有元數(shù)據(jù)(對(duì)應(yīng)最終一致性語(yǔ)義)。文件的所有操作都先在橋接服務(wù)器本地執(zhí)行,之后元數(shù)據(jù)會(huì)從 LMDB 異步更新到 GMDB,適用于無數(shù)據(jù)依賴的場(chǎng)景。
?mode2: 是同步更新部分元數(shù)據(jù),異步更新部分元數(shù)據(jù)(對(duì)應(yīng)會(huì)話一致性語(yǔ)義和提交一致性語(yǔ)義)。文件創(chuàng)建時(shí)同步更新元數(shù)據(jù),文件讀寫時(shí)異步更新元數(shù)據(jù),或者通過 flush 操作同步更新。
?mode3: 是在文件訪問過程中同步所有打開、讀取和寫入操作的元數(shù)據(jù)(比強(qiáng)一致性語(yǔ)義略弱)。
HadaFS 沒有使用分布式鎖機(jī)制,因此HadaFS 本身很難保證數(shù)據(jù)的一致性,只有在第三種元數(shù)據(jù)同步策略下才支持原子寫。為了保證數(shù)據(jù)的一致性,用戶至少要了解應(yīng)用程序的文件共享模式,可以通過 Darshan、Beacon 等獲得,自行保證數(shù)據(jù)一致性。
眾所周知,超級(jí)計(jì)算機(jī)上同時(shí)運(yùn)行著很多作業(yè)。這些作業(yè)往往會(huì)爭(zhēng)奪共享資源,從而導(dǎo)致 I/O 干擾。將客戶端動(dòng)態(tài)映射到服務(wù)器也有助于提高應(yīng)用程序性能。得益于HadaFS靈活的設(shè)計(jì),用戶可以動(dòng)態(tài)制定 HadaFS 客戶端到 HadaFS 服務(wù)器的連接關(guān)系,可以有效幫助隔離不同應(yīng)用的BB資源,解決作業(yè)間的 I/O 干擾,缺點(diǎn)是對(duì)運(yùn)維人員的要求略高。
四、性能評(píng)估
本文在神威新一代超級(jí)計(jì)算機(jī)(SNS)上進(jìn)行評(píng)估,以測(cè)試 HadaFS 的性能。下圖顯示了 HadaFS 的部署。SNS 包含超過 10 萬(wàn)個(gè)計(jì)算節(jié)點(diǎn),每個(gè)節(jié)點(diǎn)最多可以啟動(dòng) 6 個(gè) MPI 進(jìn)程和 6 個(gè) HadaFS 客戶端。也就是說整機(jī)可以支持超過 60 萬(wàn)個(gè) MPI 進(jìn)程和 60 萬(wàn)個(gè) HadaFS 客戶端。共有 600 個(gè) I/O 轉(zhuǎn)發(fā)節(jié)點(diǎn),每個(gè) I/O 轉(zhuǎn)發(fā)節(jié)點(diǎn)配置兩塊 3.2TB 的 NVMe SSD(每塊NVMe SSD對(duì)應(yīng)一臺(tái) HadaFS 服務(wù)器,支持 HadaFS 文件的數(shù)據(jù)和元數(shù)據(jù)的存儲(chǔ))。所有節(jié)點(diǎn)使用 SWnet 網(wǎng)絡(luò)互連,HadaFS 使用基于 SWne t的 RDMA 協(xié)議傳輸數(shù)據(jù)。
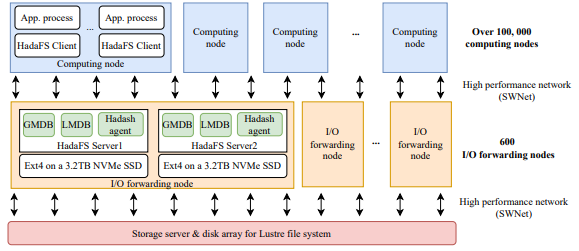
圖5 HadaFS的部署
評(píng)估的對(duì)比對(duì)象為:BeeGFS(許多超級(jí)計(jì)算機(jī)用來管理 BB 的并行文件系統(tǒng))和 GFS(SNS 中基于LWFS 和 Lustre 的傳統(tǒng)并行文件系統(tǒng))。
元數(shù)據(jù)訪問性能評(píng)估
首先使用 MDTest(元數(shù)據(jù)性能評(píng)估基準(zhǔn))來比較 HadaFS、GFS 和 BeeGFS 在 1024、4096、16384 和 65536 個(gè)進(jìn)程的并行規(guī)模下的元數(shù)據(jù)性能差異。下圖(a)、(b) 和 (c) 分別顯示了 Create、Stat 和 Remove 的 OPS 比較。Mode1 具有最高的性能,Mode2 的性能與 Mode3 相當(dāng),因?yàn)樵?MDTest 設(shè)置中沒有讀/寫操作。但 BeeGFS 無法擴(kuò)展到 65536 個(gè)進(jìn)程,需要掛載 16384 個(gè)客戶端節(jié)點(diǎn),但超過 10000 個(gè)節(jié)點(diǎn)后批量掛載不容易成功。由于 LWFS 數(shù)據(jù)轉(zhuǎn)發(fā)造成的性能開銷和 Lustre 的元數(shù)據(jù)服務(wù)器有限,傳統(tǒng)文件系統(tǒng) GFS 的性能最差。
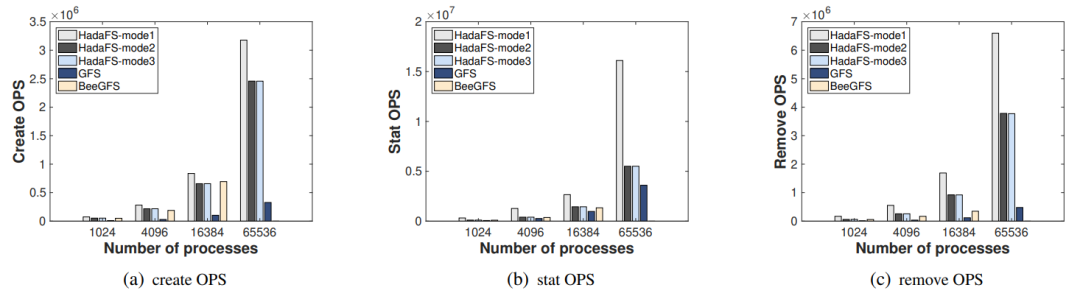
圖6元數(shù)據(jù)性能比較
數(shù)據(jù)訪問性能評(píng)估
接下來使用 IOR(數(shù)據(jù)性能評(píng)估基準(zhǔn))來比較并行規(guī)模為 1024、4096、16384 和 65536 進(jìn)程的 HadaFS、GFS 和 BeeGFS 之間的 I/O 帶寬差異。HadaFS 和 BeeGFS 分別使用 4、16、64、256 個(gè) I/O 轉(zhuǎn)發(fā)節(jié)點(diǎn)。下圖顯示了結(jié)果。對(duì)于 HadaFS,Mode1 性能最高,其次是 Mode2,最后是 Mode3。當(dāng)規(guī)模達(dá)到 65536 個(gè)進(jìn)程時(shí),HadaFS 的性能比其他文件系統(tǒng)要好得多。對(duì)于讀取操作,HadaFS 的表現(xiàn)十分接近 SSD 的理論性能極限。對(duì)于寫操作,由于無法利用內(nèi)核緩存機(jī)制,隨機(jī)寫不利于 HadaFS 的性能。BeeGFS 的性能表現(xiàn)略差于 HadaFS,但仍然無法擴(kuò)展到 65536 個(gè)進(jìn)程。由于轉(zhuǎn)發(fā)開銷和存儲(chǔ)介質(zhì)問題(數(shù)據(jù)存儲(chǔ)由 HDD 構(gòu)建),GFS 的性能依舊最低。
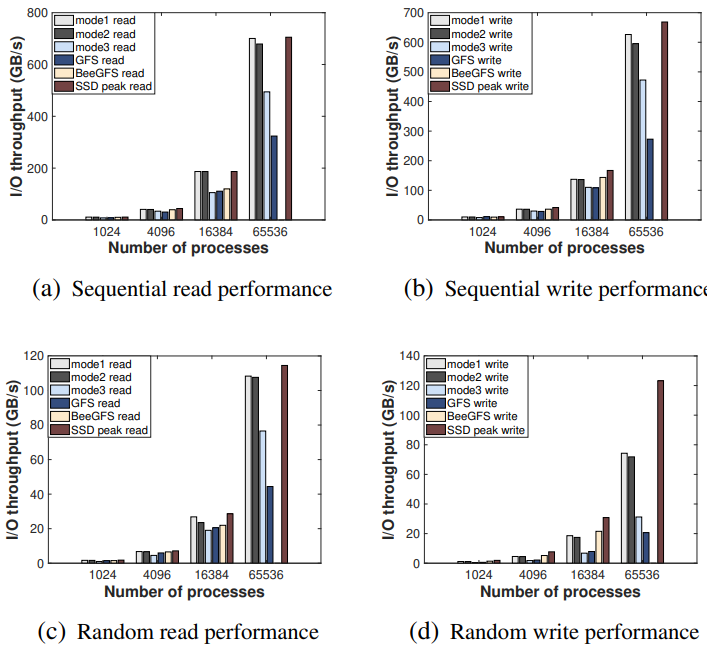
圖7 IO吞吐量比較
數(shù)據(jù)遷移性能評(píng)估
接下來評(píng)估 Hadash 的 I/O 吞吐量和遷移超小文件的能力,對(duì)比對(duì)象是 Datawarp。HadaFS 配置了 256 臺(tái)數(shù)據(jù)服務(wù)器和 256 臺(tái)元數(shù)據(jù)服務(wù)器,Datawrap 配置了 4096 個(gè)數(shù)據(jù)遷移進(jìn)程。
首先,使用 4096 個(gè)文件進(jìn)行數(shù)據(jù)stage-in 和 stage-out實(shí)驗(yàn),文件的總數(shù)據(jù)量在 256 MB 到 64 TB 之間。實(shí)驗(yàn)結(jié)果如下圖所示,當(dāng)需要遷移的文件總量較小時(shí)(stage-in 小于 64GB,stag-out 小于 16GB),Hadash 的性能略差于 Datawarp,因?yàn)閱蝹€(gè)文件較小會(huì)導(dǎo)致基于 Redis 管道的命令分發(fā)和結(jié)果獲取機(jī)制占用了較大比例的時(shí)間。隨著總體積和單個(gè)文件大小的變大,Hadash 的 I/O 吞吐量穩(wěn)定在 100 GB/s(stage-in)和 140 GB/s(stage-out)左右,遠(yuǎn)高于 Datawarp。
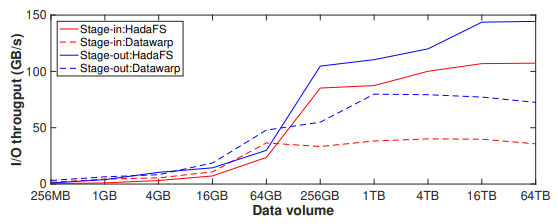
圖8 數(shù)據(jù)遷移吞吐量比較
下圖顯示了使用不同數(shù)量的 4 KB 小文件進(jìn)行數(shù)據(jù) stage-in 和 stage-out 的實(shí)驗(yàn)結(jié)果。對(duì)于 stage-in,當(dāng)小文件的數(shù)量超過 10000 時(shí),Hadash 的性能明顯優(yōu)于 Datawarp,而 Datawarp 的性能變化較小。對(duì)于 stage-out,當(dāng)小文件數(shù)量超過 100000 時(shí),Hadash 明顯優(yōu)于 Datawarp。
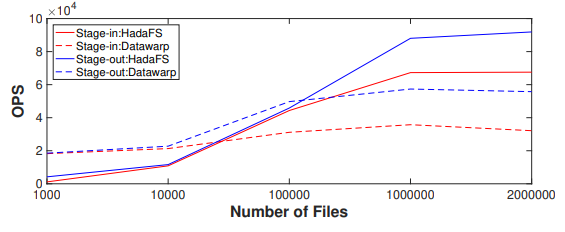
圖9每秒遷移的文件數(shù)比較
可以看到 stage-out 性能明顯優(yōu)于 stage-in 性能。首先 GFS 的寫性能和 BB 的讀性能決定了 stage-out 的性能,而 GFS 的讀性能和 BB 的寫性能決定了 stage-in 的性能。因?yàn)?GFS(Lustre)客戶端有寫緩存,所以 GFS 的寫性能高于讀性能,BB 的讀性能也高于寫性能,這就導(dǎo)致了 stage-out 的性能更高。并且在 stage-in 流程中,Hadash 需要從GFS中讀取單個(gè)目錄下的所有文件,隨著單個(gè)目錄下文件數(shù)量的增加,這個(gè)過程需要的時(shí)間會(huì)更長(zhǎng)。
綜合來看,HadaFS 已經(jīng)可以穩(wěn)定服務(wù)于數(shù)百個(gè)應(yīng)用程序,支持最大 600000 個(gè)客戶端擴(kuò)展,I/O 聚合帶寬達(dá)到 3.1 TB/s。
五、總結(jié)
本文提出了一種名為 HadaFS 的新型 Burst Buffer 文件系統(tǒng),基于共享 BB 架構(gòu)為計(jì)算節(jié)點(diǎn)提供了本地 BB 式的訪問,結(jié)合了本地 BB 的可擴(kuò)展性和性能的優(yōu)勢(shì)與共享 BB 的數(shù)據(jù)共享和部署成本的優(yōu)勢(shì)。
HadaFS 提出的 LTA 架構(gòu)通過橋接服務(wù)器處理計(jì)算節(jié)點(diǎn)的 I/O 請(qǐng)求,實(shí)現(xiàn)了與節(jié)點(diǎn)本地 BB 相當(dāng)?shù)目蓴U(kuò)展性,并提供新的接口以減少單個(gè)服務(wù)器上大量連接帶來的干擾。HadaFS 提出了三種元數(shù)據(jù)同步策略,以解決傳統(tǒng)文件系統(tǒng)復(fù)雜的元數(shù)據(jù)管理與 HPC 應(yīng)用程序的各種一致性語(yǔ)義需求之間的不匹配問題。此外,HadaFS內(nèi)部集成了名為Hadash的數(shù)據(jù)管理工具,可以為用戶提供全局的數(shù)據(jù)視圖和高效的數(shù)據(jù)遷移。最后,HadaFS 已經(jīng)部署在 SNS 上(超過 100000 個(gè)計(jì)算節(jié)點(diǎn))并支持?jǐn)?shù)百個(gè)應(yīng)用程序,可以為多種超大規(guī)模應(yīng)用提供穩(wěn)定、高性能的I/O服務(wù)。
責(zé)任編輯:彭菁
-
服務(wù)器
+關(guān)注
關(guān)注
12文章
9017瀏覽量
85182 -
數(shù)據(jù)共享
+關(guān)注
關(guān)注
0文章
56瀏覽量
10870
原文標(biāo)題:HadaFS:新型Burst Buffer文件系統(tǒng)
文章出處:【微信號(hào):架構(gòu)師技術(shù)聯(lián)盟,微信公眾號(hào):架構(gòu)師技術(shù)聯(lián)盟】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
可擴(kuò)展性的優(yōu)點(diǎn):從彼得·帕克(Peter Parker)到引腳復(fù)用
請(qǐng)問這兩種機(jī)械手模型哪種實(shí)驗(yàn)性能更好,可擴(kuò)展性更好
BeagleBoard,基于低成本OMAP3530 SoC OMAP處理器,可釋放筆記本電腦般的性能和可擴(kuò)展性
基于軟件定義網(wǎng)絡(luò)控制可擴(kuò)展性研究
如何解決區(qū)塊鏈的可擴(kuò)展性問題
區(qū)塊鏈可擴(kuò)展性的要點(diǎn)分別是什么
千兆位串行鏈路實(shí)現(xiàn)無限可擴(kuò)展性應(yīng)用
如何提高比特幣的可擴(kuò)展性
區(qū)塊鏈可擴(kuò)展性有怎樣的要點(diǎn)
影響軟件高可擴(kuò)展性的六大因素
COM-HPC:無限的高速可擴(kuò)展性
什么是可擴(kuò)展性,為什么它很重要
SD-WAN組網(wǎng)的可擴(kuò)展性怎么樣?
可擴(kuò)展性對(duì)物聯(lián)網(wǎng)管理系統(tǒng)有哪些影響?
- 設(shè)計(jì)技術(shù)
- 可編程邏輯
- 電源/新能源
- MEMS/傳感技術(shù)
- 測(cè)量?jī)x表
- 嵌入式技術(shù)
- 制造/封裝
- 模擬技術(shù)
- RF/無線
- 接口/總線/驅(qū)動(dòng)
- 處理器/DSP
- EDA/IC設(shè)計(jì)
- 存儲(chǔ)技術(shù)
- 光電顯示
- EMC/EMI設(shè)計(jì)
- 連接器
- 行業(yè)應(yīng)用
- LEDs
- 汽車電子
- 音視頻及家電
- 通信網(wǎng)絡(luò)
- 醫(yī)療電子
- 人工智能
- 虛擬現(xiàn)實(shí)
- 可穿戴設(shè)備
- 機(jī)器人
- 安全設(shè)備/系統(tǒng)
- 軍用/航空電子
- 移動(dòng)通信
- 工業(yè)控制
- 便攜設(shè)備
- 觸控感測(cè)
- 物聯(lián)網(wǎng)
- 智能電網(wǎng)
- 區(qū)塊鏈
- 新科技
- 特色內(nèi)容
- 專欄推薦
- 學(xué)院
- 設(shè)計(jì)資源
- 設(shè)計(jì)技術(shù)
- 電子百科
- 電子視頻
- 元器件知識(shí)
- 工具箱
- VIP會(huì)員
- 最新技術(shù)文章
- 社區(qū)
- 小組
- 論壇
- 問答
- 評(píng)測(cè)試用
- 企業(yè)服務(wù)
- 產(chǎn)品
- 資料
- 文章
- 方案
- 企業(yè)
- 供應(yīng)鏈服務(wù)
- 硬件開發(fā)
- 華秋電路
- 華秋商城
- 華秋智造
- nextPCB
- BOM配單
- 媒體服務(wù)
- 網(wǎng)站廣告
- 在線研討會(huì)
- 活動(dòng)策劃
- 新聞發(fā)布
- 新品發(fā)布
- 小測(cè)驗(yàn)
- 設(shè)計(jì)大賽
- 華秋
- 關(guān)于我們
- 投資關(guān)系
- 新聞動(dòng)態(tài)
- 加入我們
- 聯(lián)系我們
- 舉報(bào)投訴
- 社交網(wǎng)絡(luò)
- 微博
- 移動(dòng)端
- 發(fā)燒友APP
- 硬聲APP
- WAP
- 聯(lián)系我們
- 廣告合作
- 王婉珠:wangwanzhu@elecfans.com
- 內(nèi)容合作
- 黃晶晶:huangjingjing@elecfans.com
- 內(nèi)容合作(海外)
- 張迎輝:mikezhang@elecfans.com
- 供應(yīng)鏈服務(wù) PCB/IC/PCBA
- 江良華:lanhu@huaqiu.com
- 投資合作
- 曾海銀:zenghaiyin@huaqiu.com
- 社區(qū)合作
- 劉勇:liuyong@huaqiu.com
-
關(guān)注我們的微信

-
下載發(fā)燒友APP

-
電子發(fā)燒友觀察



版權(quán)所有 ? 湖南華秋數(shù)字科技有限公司
長(zhǎng)沙市望城經(jīng)濟(jì)技術(shù)開發(fā)區(qū)航空路6號(hào)手機(jī)智能終端產(chǎn)業(yè)園2號(hào)廠房3層(0731-88081133)
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1
工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1
評(píng)論