") LeCun世界模型首項研究來了:自監(jiān)督視覺,已開源
LeCun世界模型首項研究來了:自監(jiān)督視覺,已開源
讓 AI 像人類一樣學習和推理,這是人工智能邁向人類智能的重要一步。圖靈獎得主 Yann LeCun 曾提出自監(jiān)督 + 世界模型的解決方案,如今終于有了第一個實實在在的視覺模型。
去年初,Meta 首席 AI 科學家 Yann LeCun 針對「如何才能打造出接近人類水平的 AI」提出了全新的思路。他勾勒出了構建人類水平 AI 的另一種愿景,指出學習世界模型(即世界如何運作的內(nèi)部模型)的能力或許是關鍵。這種學到世界運作方式內(nèi)部模型的機器可以更快地學習、規(guī)劃完成復雜的任務,并輕松適應不熟悉的情況。
LeCun 認為,構造自主 AI 需要預測世界模型,而世界模型必須能夠執(zhí)行多模態(tài)預測,對應的解決方案是一種叫做分層 JEPA(聯(lián)合嵌入預測架構)的架構。該架構可以通過堆疊的方式進行更抽象、更長期的預測。
6 月 9 日,在 2023 北京智源大會開幕式的 keynote 演講中,LeCun 又再次講解了世界模型的概念,他認為基于自監(jiān)督的語言模型無法獲得關于真實世界的知識,這些模型在本質(zhì)上是不可控的。

今日,Meta 推出了首個基于 LeCun 世界模型概念的 AI 模型。該模型名為圖像聯(lián)合嵌入預測架構(Image Joint Embedding Predictive Architecture, I-JEPA),它通過創(chuàng)建外部世界的內(nèi)部模型來學習, 比較圖像的抽象表示(而不是比較像素本身)。
I-JEPA 在多項計算機視覺任務上取得非常不錯的效果,并且計算效率遠高于其他廣泛使用的計算機視覺模型。此外 I-JEPA 學得的表示也可以用于很多不同的應用,無需進行大量微調(diào)。
舉個例子,Meta 在 72 小時內(nèi)使用 16 塊 A100 GPU 訓練了一個 632M 參數(shù)的視覺 transformer 模型,還在 ImageNet 上實現(xiàn)了 low-shot 分類的 SOTA 性能,其中每個類只有 12 個標簽樣本。其他方法通常需要 2 到 10 倍的 GPU 小時數(shù),并在使用相同數(shù)據(jù)量訓練時誤差率更高。
相關的論文《Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture》已被 CVPR 2023 接收。當然,所有的訓練代碼和模型檢查點都將開源。

論文地址:https://arxiv.org/pdf/2301.08243.pdfGitHub
地址:https://t.co/DgS9XiwnMz
通過自監(jiān)督學習獲取常識型知識
I-JEPA 基于一個事實,即人類僅通過被動觀察就可以了解關于世界的大量背景知識,這些常識信息被認為是實現(xiàn)智能行為的關鍵。
通常,AI 研究人員會設計學習算法來捕獲現(xiàn)實世界的常識,并將其編碼為算法可訪問的數(shù)字表征。為了高效,這些表征需要以自監(jiān)督的方式來學習,即直接從圖像或聲音等未標記的數(shù)據(jù)中學習,而不是從手動標記的數(shù)據(jù)集中學習。
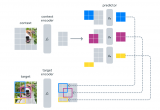
在高層級上,JEPA 的一個輸入中某個部分的表征是根據(jù)其他部分的表征來預測的。同時,通過在高抽象層次上預測表征而不是直接預測像素值,JEPA 能夠直接學習有用的表征,同時避免了生成模型的局限性。
相比之下,生成模型會通過刪除或扭曲模型輸入的部分內(nèi)容來學習。然而,生成模型的一個顯著缺點是模型試圖填補每一點缺失的信息,即使現(xiàn)實世界本質(zhì)上是不可預測的。因此,生成模型過于關注不相關的細節(jié),而不是捕捉高級可預測的概念。
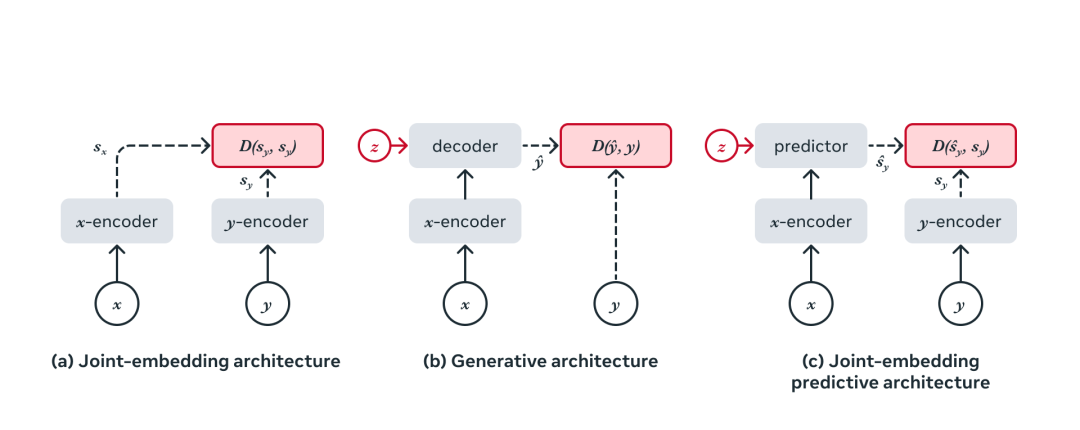
自監(jiān)督學習的通用架構,其中系統(tǒng)學習捕獲其輸入之間的關系。
邁向能力廣泛的 JEPA 的第一步
I-JEPA 的核心思路是以更類似于人類理解的抽象表征來預測缺失信息。與在像素 /token 空間中進行預測的生成方法相比,I-JEPA 使用抽象的預測目標,潛在地消除了不必要的像素級細節(jié),從而使模型學習更多語義特征。
另一個引導 I-JEPA 產(chǎn)生語義表征的核心設計是多塊掩碼策略。該研究使用信息豐富的上下文來預測包含語義信息的塊,并表明這是非常必要的。
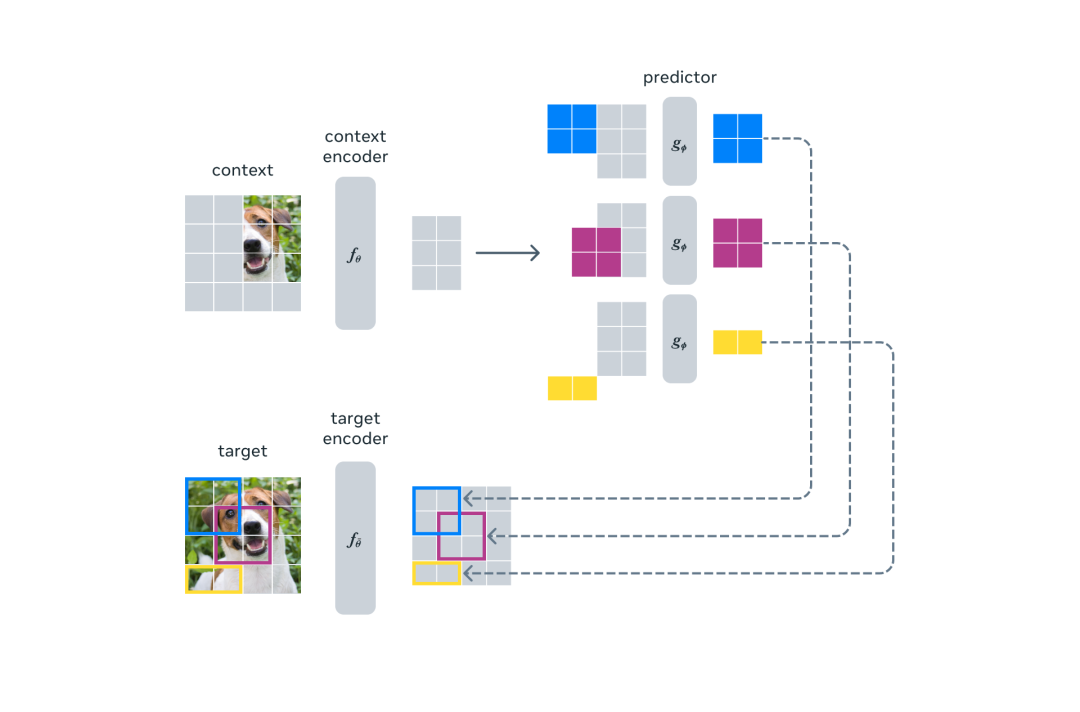
I-JEPA 使用單個上下文塊來預測源自同一圖像的各種目標塊的表征。
I-JEPA 中的預測器可以看作是一個原始的(和受限的)世界模型,它能夠從部分可觀察的上下文中模擬靜態(tài)圖像中的空間不確定性。更重要的是,這個世界模型是語義級的,因為它預測圖像中不可見區(qū)域的高級信息,而不是像素級細節(jié)。

預測器如何學習建模世界的語義。對于每張圖像,藍框外的部分被編碼并作為上下文提供給預測器。然后預測器輸出它期望在藍框內(nèi)區(qū)域的表示。為了可視化預測,Meta 訓練了一個生成模型, 它生成了由預測輸出表示的內(nèi)容草圖,并在藍框內(nèi)顯示樣本輸出。很明顯,預測器識別出了應該填充哪些部分的語義(如狗的頭部、鳥的腿、狼的前肢、建筑物的另一側)。
為了理解模型捕獲的內(nèi)容,Meta 訓練了一個隨機解碼器,將 I-JEPA 預測的表示映射回像素空間,這展示出了探針操作后在藍框中進行預測時的模型輸出。這種定性評估表明,I-JEPA 正確捕獲了位置不確定性,并生成了具有正確姿態(tài)的高級對象部分(如狗的頭部、狼的前肢)。
簡而言之,I-JEPA 能夠?qū)W習對象部分的高級表示,而不會丟棄它們在圖像中的局部位置信息。
高效率、強性能
I-JEPA 預訓練在計算上也很高效,在使用更多計算密集型數(shù)據(jù)增強來生成多個視圖時不會產(chǎn)生任何開銷。目標編碼器只需要處理圖像的一個視圖,上下文編碼器只需要處理上下文塊。
實驗發(fā)現(xiàn),I-JEPA 在不使用手動視圖增強的情況下學習了強大的現(xiàn)成語義表示,具體可見下圖。此外 I-JEPA 還在 ImageNet-1K 線性探針和半監(jiān)督評估上優(yōu)于像素和 token 重建方法。
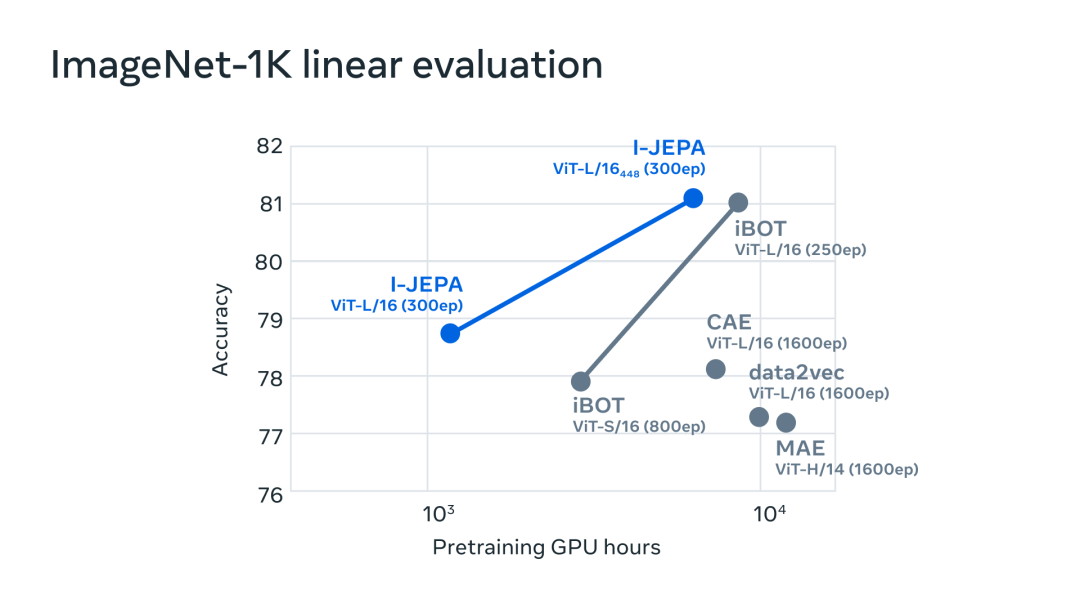
ImageNet-1k 數(shù)據(jù)集上的線性評估。
I-JEPA 還能與以往在語義任務上依賴手動數(shù)據(jù)增強的方法競爭。相比之下,I-JEPA 在對象計數(shù)和深度預測等低級視覺任務上取得了更好的性能。通過使用較小剛性歸納偏置的更簡單模型,I-JEPA 適用于更廣泛的任務集合。
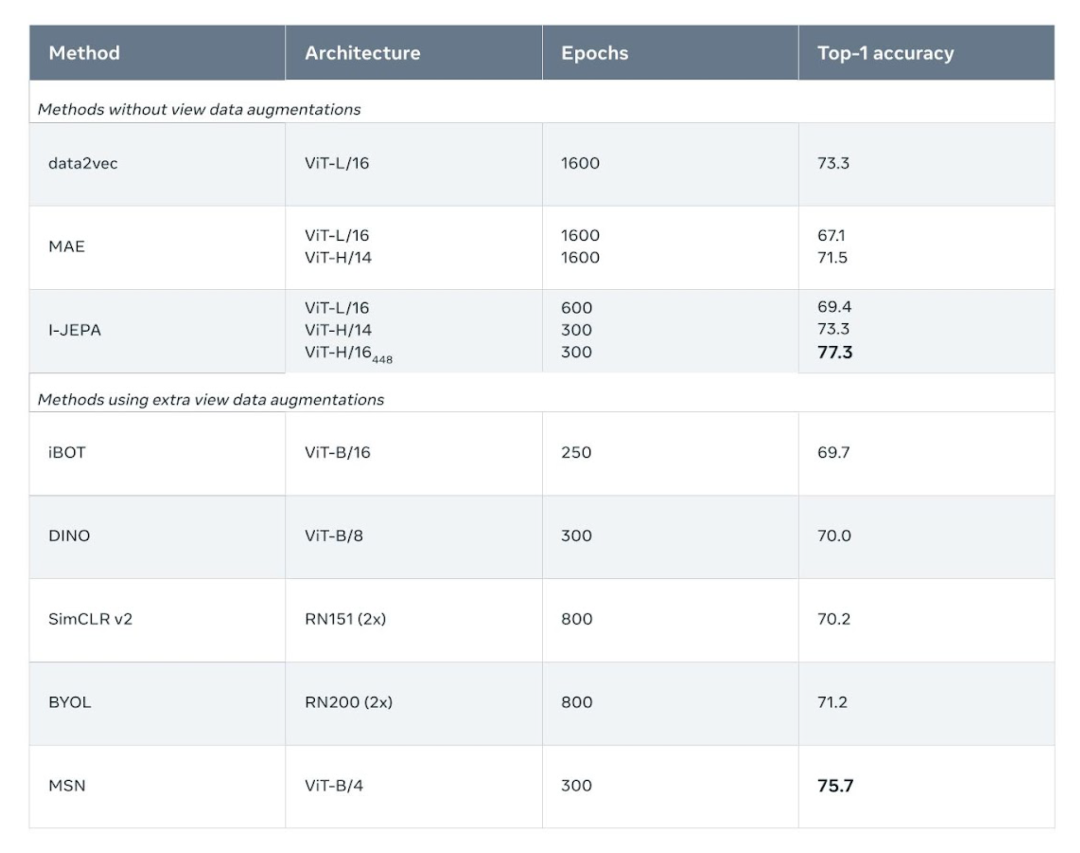
low shot 分類準確性:使用 1% 標簽時 ImageNet-1k 上的半監(jiān)督評估結果(每類只有 12 張標簽圖像)。
AI 智能向人類水平更近了一步
I-JEPA 展示了無需通過手動圖像變換來編碼額外知識時,學習有競爭力的現(xiàn)成圖像表示的潛力。繼續(xù)推進 JEPA 以從更豐富模態(tài)中學習更通用世界模型將變得特別有趣,比如人們從一個短上下文中對視頻中的將來事件做出長期空間和時間預測,并利用音頻或文本 prompt 對這些預測進行調(diào)整。
Meta 希望將 JEPA 方法擴展到其他領域,比如圖像 - 文本配對數(shù)據(jù)和視頻數(shù)據(jù)。未來,JEPA 模型可以在視頻理解等任務中得到應用。這是應用和擴展自監(jiān)督方法來學習更通用世界模型的重要一步。
-
gpu
+關注
關注
28文章
4701瀏覽量
128708 -
AI
+關注
關注
87文章
30154瀏覽量
268423 -
模型
+關注
關注
1文章
3173瀏覽量
48715
原文標題:LeCun世界模型首項研究來了:自監(jiān)督視覺,像人一樣學習和推理,已開源
文章出處:【微信號:AI智勝未來,微信公眾號:AI智勝未來】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
“悟道3.0”系列大模型全面開源,有助于AI應用普及!

為什么生成模型值得研究
TextTopicNet模型:以自監(jiān)督學習方式學習區(qū)別視覺特征
自監(jiān)督學習與Transformer相關論文
基于人工智能的自監(jiān)督學習詳解
人的大腦和自監(jiān)督學習模型的相似度有多高?
基于視覺Transformer的監(jiān)督視頻異常檢測架構進行腸息肉檢測的研究
LeCun新作:全面綜述下一代「增強語言模型」
LeCun世界模型首個研究!自監(jiān)督視覺像人一樣學習和推理!
Meta開源I-JEPA,“類人”AI模型
「悟道·視界」視覺大模型系列,6項領先成果技術詳解
基礎模型自監(jiān)督預訓練的數(shù)據(jù)之謎:大量數(shù)據(jù)究竟是福還是禍?

NeurIPS 2023 | 全新的自監(jiān)督視覺預訓練代理任務:DropPos

視覺模型weak-to-strong的實現(xiàn)
機器人基于開源的多模態(tài)語言視覺大模型






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論