 數字信號處理:實時I/O的編程注意事項
數字信號處理:實時I/O的編程注意事項
David Skolnick 和 Noam Levine
現在,我們更仔細地關注實時系統特有的DSP編程問題。本文重點介紹如何為具有各種I/O接口的DSP系統開發算法。
“實時”是什么意思?在模擬系統中,每項任務都是通過連續的信號和處理“實時”執行的。在數字信號處理(DSP)系統中,信號用一組樣本表示,即離散時間點的值。因此,根據采樣率,在DSP系統中處理給定數量的樣本的時間可以“實時”進行任意解釋。本系列的第一篇文章介紹了采樣的概念和奈奎斯特準則,即在實時應用中,采樣頻率必須至少是(模擬)信號中感興趣的最高頻率分量(奈奎斯特速率)頻率的兩倍。樣本之間的時間稱為采樣間隔。要將系統視為“實時”運行,必須在新數據到達之前完成對給定數據集(一個或多個樣本,取決于算法)的所有處理。
實時的這種定義意味著,對于以給定時鐘速率運行的處理器,輸入數據的速度和數量決定了可以在不落后于數據流的情況下對數據進行多少處理。對于模擬設計人員來說,處理數據的時間有限的想法可能看起來很奇怪,因為這個概念在模擬系統中沒有并行。在模擬系統中,信號被連續處理。慢速系統中唯一的懲罰是有限的頻率響應。相比之下,數字系統處理部分信號,足以進行非常精確的近似,但只能在有限的時間內。圖 1 顯示了一個比較。實時DSP可以受到在算法時間預算內可以完成的數據量或處理類型的限制。例如,處理以 48 kHz(音頻信號)采樣的數據值的給定 DSP 處理器處理這些數據值的時間比一個采樣 8 kHz 語音頻段數據的時間更少。
在本系列前面描述的濾波器示例中,輸入采樣率為8 kHz。為了使示例中的DSP跟上實時數據,所有處理都必須在1/(8 kHz)或125 μs的時間預算內完成。在 33MHz 數字信號處理器(每周期 30ens)上,時間預算提供 125 μs/30 ns 或 4166 個指令周期,以完成處理和任何其他必需的任務。
由于執行任何給定算法可以預算的時間有限,因此管理時間是DSP系統軟件設計的核心部分。時間管理策略確定處理器如何獲得有關事件的通知、影響數據處理以及塑造處理器通信。
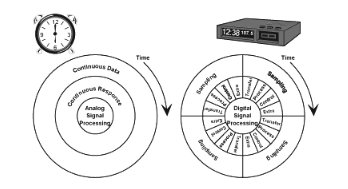
圖1.模擬和數字信號處理的比較。a. 模擬:響應值對應于所有時刻的每個數據值。b. 數字:對于每個樣品,必須傳輸和處理數據,事件標志著處理(控制)的結束,并且在指定過程發生后,周期內的其他任務可能需要額外的時間。
事件通知: 中斷:人們可以對DSP進行編程,以使用處理“事件”(數據到達)的幾種策略之一來處理數據。可以定期讀取狀態位或標志引腳,以確定新數據是否可用。但是,“輪詢”會浪費處理器周期。數據可能會在上次民意調查后到達,但直到下一次民意調查才能知道它的存在。這使得開發實時系統變得困難。
第二種策略是讓數據在到達時中斷處理器。使用中斷通知處理器是有效的,盡管編程不那么容易;在等待中斷期間可能會浪費時鐘周期。然而,事件驅動的中斷編程非常適合快速處理真實世界的信號,大多數DSP都旨在有效地處理它們。事實上,它們旨在非常快速地響應中斷。ADSP-2181對中斷的響應時間約為三個處理器周期;即,在75 ns內,DSP已停止執行其正在執行的操作,并正在處理中斷事件(矢量)。
在許多基于DSP的系統中,基于輸入數據采樣速率的中斷速率通常與DSP的時鐘速率完全無關。在本系列前面的 FIR 示例中,處理器以 125 μs 的間隔中斷以接收新數據。
中斷處理和中斷向量:由于中斷處理是DSP系統中至關重要的元素,因此處理器通常具有內置的硬件機制來有效地處理中斷。硬連線機制比單獨的軟件更有效,因為 DSP 的中斷服務例程 (ISR) 可能必須滿足以下所有需求:
快速上下文切換 – 從一個任務及其數據(上下文)切換到另一個上下文,而不會因編寫程序以保存寄存器內容和芯片狀態信息而浪費時間和復雜性。
嵌套中斷處理 – “同時”處理不同優先級的多個中斷。DSP 一次處理一個中斷,但優先級較高的中斷可能優先于優先級較低的中斷的處理。
繼續接受數據/記錄狀態 - 當 DSP 服務中斷時,現實世界中不斷發生事件,數據不斷到達。為了跟上“現實世界”的步伐,DSP必須記錄這些事件并接受數據,然后在完成中斷服務后處理它們。
在ADI公司的DSP上,使用兩組數據寄存器實現快速上下文切換。一次只有一個集處于活動狀態,其中包含該上下文期間處理的所有數據。處理中斷時,計算機可以從活動集切換到備用集,而無需將數據臨時保存在內存中。這有助于在任務之間快速切換。
為了處理多個中斷,ADI公司的DSP記錄每個中斷的狀態。處理器狀態信息保存在位于 DSP 程序序列器中的一組狀態“堆棧”上。“堆棧”由一組硬件寄存器組成。事件發生時,當前狀態信息被“推送”到堆棧上。這種堆棧機制還允許嵌套中斷;優先級較高的一個可以中斷優先級較低的一個。
中斷鎖存器和自動I/O兩種硬件特性使ADI公司的DSP在處理中斷時能夠及時了解“現實世界”。鎖存器可防止 DSP 在處理中斷時錯過重要事件。另一個功能包括各種形式的自動I/O(包括串行端口、DMA、自動緩沖等),允許外部設備將數據泵入DSP的存儲器,而無需DSP的干預。因此,當DSP“繁忙”時,不會丟失任何數據。
當外部源或內部資源生成中斷請求時,DSP 處理器會自動存儲其當前操作狀態,并準備執行中斷例程。中斷例程是從中斷向量表調度的。中斷向量表是程序存儲器中的一個區域,其中的指令地址分配給特定的DSP中斷功能。例如,在下表中,ADSP-1處理器串行端口1(SPORT2181)上的發送(Tx)中斷將導致下一條指令在程序存儲器(PM)位置0x0020執行,然后通過0x0023(中斷例程)執行接下來三個位置的內容。如表中的12項所示,ADSP-2181可以處理來自11個位置(外部硬件、DMA端口和串行端口)和處理器復位的中斷。該表列出了分配給存儲器位置中每個中斷向量源的編程指令,0x0000 FIR濾波器程序0x002F。
Jump start; nop; nop; nop; /* PM(0x0000-03): Reset vector */
rti; nop; nop; nop; /* PM(0x0004-07): IRQ2 vector */
rti; nop; nop; nop; /* PM(0x0008-0B): IRQL1 vector */
rti; nop; nop; nop; /* PM(0x000C-0F): IRQL0 vector */
ar = dm(stat_flag); ar = pass ar; if eq_rti; jump next_cmd;
/* PM(0x0010-13): SPORT0 Tx vector */
jump input_samples; nop; nop; nop;
/* PM(0x0014-17): SPORT0 Rx vector */
jump irqe; nop; nop; nop; /* PM(0x0018-1B): IRQE vector */
rti; nop; nop; nop; /* PM(0x001C-1F): BDMA vector */
rti; nop; nop; nop; /* PM(0x0020-23): SPORT1 Tx vector */
rti; nop; nop; nop; /* PM(0x0024-27): SPORT1 Rx vector */
rti; nop; nop; nop; /* PM(0x0028-2B): Timer vector */
rti; nop; nop; nop; /* PM(0x002C-2F): Powerdown vector */
每個中斷向量有四個指令位置。通常,這些指令將導致處理器跳轉到另一個內存區域以處理數據,如重置(0x0000時)、SPORT0 Rx (0x0014) 和 IRQE (0x0018) 中斷向量所示。如果只有幾個步驟(例如讀取值、檢查狀態或加載內存)可以在四個可用指令位置內完成,則直接對其進行編程,如 SPORT0 Tx 矢量 (0x0010-13) 所示。任何未使用的中斷向量都要求從中斷返回 (rti),并帶有三個 nop(無操作)指令。
nop 指令用作占位符 – 指令空間,用于確保正確的中斷操作與硬件指定的中斷向量對齊。每個未使用的矢量位置開頭的 rti 指令既是占位符又是安全閥。如果未使用的中斷被錯誤地取消屏蔽或無意中觸發,“rti”會導致恢復正常執行。
數據 I/O
在DSP系統中,中斷通常是由數據的到達或提供新輸出數據的要求產生的。每個樣本都可能發生中斷,也可能在收集一幀數據后發生中斷。這些差異極大地影響了DSP算法處理數據的方式。
對于逐個樣本運行的算法,可能需要DSP軟件來處理每個傳入和傳出的數據值。每個 DSP 串行端口包含兩個數據 I/O 寄存器,一個接收寄存器 (Rx) 和一個發送寄存器 (Tx)。收到串行字時,端口通常會生成接收中斷。處理器停止它正在執行的操作,開始在中斷向量位置執行代碼,將來自 Rx 寄存器的傳入值讀取到處理器數據寄存器中,然后對該數據值進行操作或返回到其后臺任務。在上表中,計算機跳轉到程序段“input_samples”,執行在該段中編程的任何指令,并直接從中斷或通過返回中斷向量返回。
為了傳輸數據,串行端口可以產生傳輸中斷,表示可以將新數據寫入SPORT Tx寄存器。然后,DSP 可以在 SPORT Tx 中斷向量處開始執行代碼,并且通常將值從數據寄存器傳輸到 SPORT Tx 寄存器。如果數據輸入和輸出由同一采樣時鐘控制,則只需要一個中斷。例如,如果程序段由接收中斷計時啟動,則會在中斷例程期間讀取新數據;然后,要么傳輸先前計算的結果(保存在寄存器中),要么計算新結果并立即傳輸 - 作為中斷例程的最后一步。
所有這些機制都有助于DSP能夠模擬模擬系統的自然功能——實時連續處理數據——但具有數字精度和靈活性。此外,在高效編程的數字系統中,處理數據集之間剩余的備用處理器周期可用于處理其他任務。
編程注意事項
在“實時”系統中,處理速度至關重要。通過使用 SPORT 自動緩沖,數據 I/O 不會浪費任何時間。相反,數據管理目標是確保所選地址指向新數據。
在FIR濾波器示例中(模擬對話31-3,第15頁),當輸入自動緩沖器已滿時,會生成SPORT接收中斷請求,這意味著DSP已收到三個數據字:狀態、左通道數據和右通道數據。由于此簡化應用程序使用單通道數據,因此算法僅使用駐留在位置 rx_buf+1 的數據值。
過濾器算法擴展在其他應用程序中,數據處理可能更加復雜。例如,如果將示例的FIR濾波器擴展到雙通道實現,則無需更改核心DSP算法代碼。但是,必須修改與數據處理相關的代碼,以考慮第二個數據流和第二組系數。
在篩選器代碼中,內存中需要兩個新緩沖區來處理額外的數據流和額外的系數集。核心濾波器環路可以作為單獨的“可調用”函數進行隔離。無論輸入數據值如何,此技術都允許使用相同的代碼。這種編程風格的優點包括可讀代碼、可重用算法和減小代碼大小。如果不采用模塊化方法,則必須使用額外的DSP存儲器空間重復濾波器環路。
然后,SPORT 接收中斷例程將包括指針設置和調用過濾器。修訂后的篩選器例程顯示在以下清單中:
Filter: cntr = taps - 1;
mr = 0, mx0 = dm(i2,m1), my0 = pm(i5,m5);
/* clear accumulator, get first data
and coefficient value */
do filt_loop until ce; /* set-up zero-overhead loop */
filt_loop: mr = mr + mx0*my0(ss), mx0 = dm(i2,m1),
my0 = pm(i5,m5); /* MAC and two data fetches */
mr = mr + mx0 * my0 (rnd); /* final multiply, round to 16-bit
result */
if mv sat mr; / * check for overflow*/
rts; /* return */
需要注意的是,對核心過濾器循環的唯一修改是在例程的開頭添加了一個標簽“Filter:”,并在最后添加了“rts”(從子例程返回)指令。這些新增功能將篩選器代碼從獨立例程更改為可從其他例程調用的子例程。它不再是一個單一用途的例程,而是一個可重用、可調用的子例程。
通過將核心過濾器設置為可調用的子例程,現在可以滿足雙通道數據處理要求。為了簡化一些編程問題,此示例假定左通道和右通道使用相同的濾波器系數。
在本系列的第三部分中,顯示了整個篩選器應用程序程序集代碼。在代碼清單的頂部,聲明了所有必需的內存緩沖區。若要擴展篩選器應用程序以處理兩個數據通道,需要聲明所需的新變量和緩沖區。對于傳入的數據,緩沖區聲明,
.var/dm/circ_filt_data[taps];/* 輸入數據緩沖區 */
需要替換為兩個緩沖區,聲明為
.var/dm/circ_filt1_data[taps];/* 左通道輸入數據緩沖區 */ .var/dm/
circ_filt2_data[taps];/* 右通道輸入數據緩沖器 */
由于兩個通道將應用相同的濾波器系數,因此數據緩沖區的長度相等。
過濾器循環子例程期望使用特定的地址寄存器訪問某些數據和系數值。具體而言,地址寄存器 I2 必須指向最早的數據樣本,I5 必須指向調用篩選器例程之前的正確系數值。
由于左通道和右通道的過濾器將共享相同的內存指針,因此必須有一種機制來區分兩個數據流。對于數據指針,I2,需要定義兩個新變量,“filter1_ptr”和“filter2_ptr”。
內存中的這些位置將用于存儲適用于每個數據流的地址值。ADSP-2181的循環緩沖功能用于確保每當執行濾波器時,數據指針始終位于緩沖器中的正確位置。由于子例程現在處理兩個緩沖區,因此在完成每個通道的處理時需要保存指針位置。
要設置指針,需要在數據存儲器中聲明兩個變量,如下所示:
.var/dm filter1_ptr;/* 左通道數據的數據指針 */ .var/
dm filter2_ptr;/* 右通道數據的數據指針 */
然后需要用每個數據緩沖區的起始地址初始化這些變量;
.init filter1_ptr: ^filt1_data;/* 初始化起點,
左通道 */
.init filter2_ptr: ^filt2_data;/* 初始化起點,
右通道 */
DSP 匯編軟件將符號“^”識別為表示“地址”。DSP 鏈接器軟件填寫相應的地址值。這樣,可執行程序中的指針變量就使用相應內存緩沖區的起始地址進行初始化。
以下清單顯示了 FIR 過濾器中斷例程如何使用這些新的內存元素。第 3 部分中的原始 Filter 子例程已修改為提供兩個單獨的篩選通道。例程必須首先加載相應的數據指針,而不是直接啟動到篩選器計算中。然后調用篩選器例程,并將生成的輸出放置在正確的位置進行傳輸。
/*--------------------FIR Filter--------------------*/
input_samples:
ena sec_reg; /* use shadow register bank */
/* set up for filter 1 */
i2 = dm(filter1_ptr); /* set data pointer for filter 1 */
ax0 = dm(rx_buf + 1); /* read left channel data */
dm(i2,m1) = ax0; /* write new data into delay line,
pointer now pointing to oldest data */
call filter; /* perform the first filter for left
channel data */
dm(tx_buf+1) = mr1; /* write left-channel output data */
dm(filter1_ptr) = i2; /* save updated filter1 data pointer */
/* set up for filter 2 */
i2 = dm(filter2_ptr); /* set data pointer for filter 2 */
ax0 = dm(rx_buf + 2); /* read right channel data */
dm(i2,m1) = ax0; /* write new data into delay line,
pointer now pointing to oldest data */
call filter; /* perform the filter again for the
right channel data */
dm(tx_buf+2) = mr1; /* write right channel output data */
dm(filter2_ptr) = i2; /* save updated filter2 data pointer */
rti; /* return from interrupt */
由于核心過濾器算法不再處理數據 I/O,因此只需添加更多指針變量并聲明更多緩沖區空間(只要存在足夠的內存!同樣,通過設置包含系數緩沖區指針信息的變量,可以對兩個篩選器使用不同的系數。無論哪種情況,都不需要更改過濾器算法。通過使用這種模塊化編程風格,用戶可以構建一個可調用的DSP函數庫。因此,特定系統的差異可以簡化為數據處理問題,而不是新算法的開發。雖然這種編程風格不一定允許算法更快地執行其任務,但系統設計人員在確定數據如何流經系統方面具有更大的靈活性。
實時接口問題:到目前為止,我們已經研究了嵌入式系統中的實時編程如何依賴于快速中斷響應、高效的數據處理和快速的程序執行。此外,進出處理器的數據流也會影響系統在實時嵌入式環境中的工作情況。
流入和流出數字信號處理器的主數據可以是并行的,也可以是串行的。并行傳輸通常至少與處理器架構的本機數據字一樣寬(ADSP-16系列處理器為2100位,SHARC為32位)。并行傳輸通過處理器的外部內存總線或外部主機接口總線進行。串行數據傳輸需要的互連要少得多;它們經常用于與數據轉換器通信。?
串行接口:硬件接口的便利性是高效實現DSP系統的重要因素。ADSP-2181 EZ-Kit Lite系統使用AD1847串行編解碼器(COder/DECoder)。串行編解碼器允許通過 DSP 上的串行端口 (SPORT) 進行數據傳輸。此串口不是RS-232 PC式異步串口;它是一個 5 線同步接口,可傳遞位時鐘、接收數據、發送數據和幀同步信號。串行接口的主要優點是引腳數少,易于硬件連接。AD1847僅需4個信號即可與DSP接口:串行時鐘、接收數據、發送數據和接收幀同步信號。串行數據流是時分復用(TDM),這意味著同一物理線路可以按串行順序傳輸多種類型的信息。在上一期啟動的EZ-Kit Lite上的AD1847應用中,串行線路同時包含左聲道和右聲道音頻信息,以及編解碼器控制和狀態信息。
如前所述,處理器具有處理此數據的各種方法。SPORT 中斷由串行端口硬件自動生成,用于接收或傳輸數據以及單個字或字塊(圖 2)。數字信號處理器和I/O設備之間的串行接口
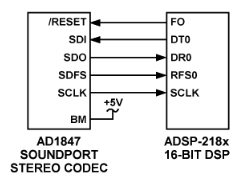
圖2.數字信號處理器和 I/O 設備之間的串行接口。
并行接口:即使串行位時鐘的運行速度與DSP處理器一樣快,串行接口也會犧牲數據傳輸速度以簡化布線,以DSP處理器速度的一小部分傳輸數據字。對于需要更高數據速率的系統性能,可以使用并行接口。并行接口時,DSP使用其外部數據和地址總線,以讀取或寫入外設的數據。在ADSP-2181上,總線最多可連接16位數據。
并行數據傳輸始終比串行傳輸更快。DSP可以在每個處理器周期執行外部訪問,但這需要能夠跟上它的非常快速的并行外設,例如快速SRAM芯片。與其他實體的并行數據傳輸通常在每個處理器周期不到一個的情況下發生。
串行接口和并行接口的中斷處理是不同的。由于DSP處理器的外部數據總線是處理各種數據的通用實體,因此它沒有用于中斷生成和控制的專用信號線;但是,其他 DSP 資源也可用。在ADSP-2181上,多個外部硬件中斷線(例如用于I/O存儲器選擇的中斷線)可用于由外部器件(如A/D轉換器或編解碼器)觸發。這種接口如圖3所示,涉及一個并行器件和ADSP-2181 DSP。用于 DSP 的并行 I/O 接口
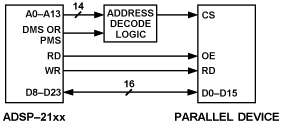
圖3.用于 DSP 的并行 I/O 接口。
當響應并行數據的中斷時,處理器讀取適當的源,并通常通過執行類似于此處所示的指令將該數據值放在內存中:
irq2_svc: ax0 = IO(ad_converter);dm(i2,m1) = ax0;RTI;
“ad_converter”是 I/O 空間中先前定義的地址。
本文旨在詳細介紹DSP開發人員在處理實時系統中的I/O和其他事件時面臨的編程問題。引入的問題包括實時數據(樣本和幀)、中斷和中斷處理、自動 I/O 以及通用化例程以創建可調用的子例程。這篇簡短的文章無法公正地描述與每個主題相關的許多細節層次。更多信息可在以下參考資料中找到。本系列中的后續主題將繼續基于此應用程序進行構建。下一篇文章將為我們不斷增長的示例程序添加更多功能,并描述軟件驗證(即調試)技術。
審核編輯:郭婷
-
處理器
+關注
關注
68文章
19167瀏覽量
229153 -
dsp
+關注
關注
552文章
7962瀏覽量
348280 -
濾波器
+關注
關注
160文章
7731瀏覽量
177693
發布評論請先 登錄
相關推薦
AT89S51單片機的I/O端口的特點及使用注意事項有哪些
設計AVR單片機通用I/O口有哪些注意事項呢
數字信號處理器(DSP)
基于雙數字信號處理器(DSP)的實時相關圖像處理系統的設計
TN:選擇數字信號處理器ADSP-21161與TMS360C6711/12的注意事項






 工商網監
工商網監
評論