 分享一下關于Linux服務器開發中相關數據去重的做法
分享一下關于Linux服務器開發中相關數據去重的做法
1. 海量數據去重的Hash
1.1 背景
● 在使用word文檔時,word如何判斷某個單詞是否拼寫正確?
● 網絡爬蟲程序,怎么讓它不去爬相同的url頁面?
● 垃圾郵件(短信)過濾算法如何設計?
● 公安辦案時,如何判斷某嫌疑人是否在網逃名單中?
● 緩存穿透問題如何解決?
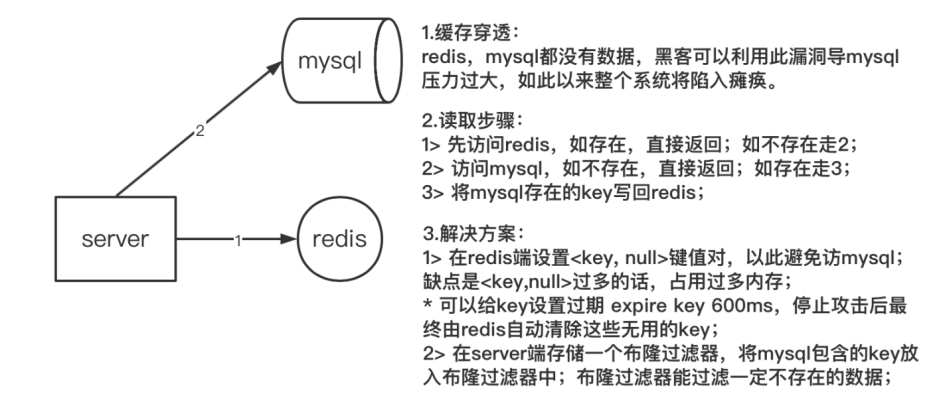
描述緩存場景,為了減輕落盤數據庫(mysql)的訪問壓力,在server端與mysql之間加入一層緩沖數據層(用來存放熱點數據);
緩存穿透發生的場景是server端向數據庫請求數據時,緩存數據庫(redis)和落盤數據庫(mysql)都不包含該數據,數據請求壓力全部涌向落盤數據庫(mysql)。
數據請求步驟:如上圖2的描述;
發送原因:黑客利用漏洞偽造數據攻擊或者內部業務bug重復大量請求不存在的數據;
解決方法:如上圖3的描述;
1.2 需求
從海量數據中查詢某字符串是否存在
1.3 set和map
c++標準庫(STL)中的set和map結構都是采用紅黑樹實現的,它增刪改查的時間復雜度是o(log2n );
圖結構示例:
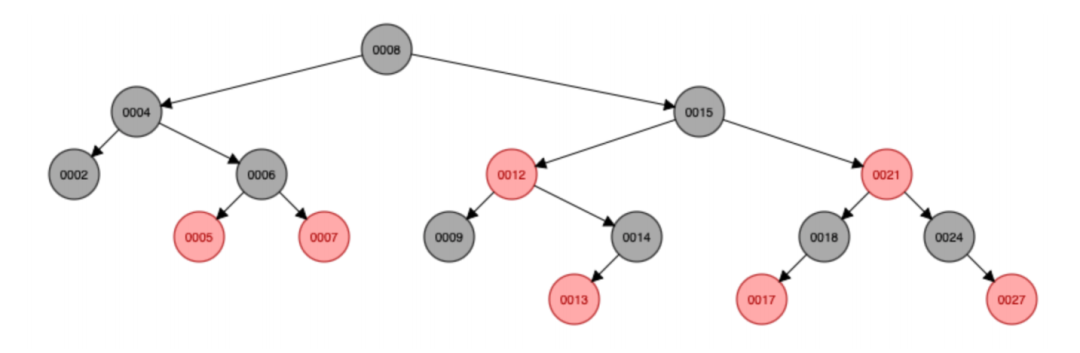
對于嚴格平衡二叉搜索樹(AVL),100w條數據組成的紅黑樹,只需要比較20次就能找到該值;對于10億條數據只需要比較30次就能找到該數據;也就是查找次數跟樹的高度是一致的;
對于紅黑樹來說平衡的黑節點高度,所以研究次數需要考慮樹的高度差,最好情況某條樹鏈路全是黑節點,假設此時高度為h1,最差情況某條樹鏈路全是黑紅節點間隔,那么此時樹高度為2*h1;
在紅黑樹中每一個節點都存儲key和val字段,key是用來做比較的字段;紅黑樹并沒有要求key字段唯一,在set和map實現過程中限制了key字段唯一。我們來看nginx的紅黑樹實現:
//這個是截取nginx的紅?樹的實現,這段代碼是insert操作中的?部分,執?完這個函數還 需要檢測插?節點后是否平衡(主要是看他的?節點是否也是紅?節點) //調?ngx_rbtree_insert_value時,temp傳的參數為紅?樹的根節點,node傳的參數為 待插?的節點 voidngx_rbtree_insert_value(ngx_rbtree_node_t*temp,ngx_rbtree_node_t *node, { ngx_rbtree_node_t**p; for(;;){ p=(node->keykey)?&temp->left:&temp->right;//這?很重要 if(*p==sentinel){ break; } temp=*p; } *p=node; node->parent=temp; node->left=sentinel; node->right=sentinel; ngx_rbt_red(node); } //不插?相同節點如果插?相同讓它變成修改操作此時紅?樹當中就不會有相同的key了 定時器key時間戳 //如果我們插?key = 12,如上圖紅?樹,12號節點應該在哪個位置?如果我們要實現插?存在 的節點變成修改操作,該怎么改上?的函數 voidngx_rbtree_insert_value_ex(ngx_rbtree_node_t*temp,ngx_rbtree_node_t *node, ngx_rbtree_node_t*sentinel) { ngx_rbtree_node_t**p; for(;;){ //{-------------add------------- if(node->key==temp->key){ temp->value=node->value; return; } //}-------------add------------- p=(node->keykey)?&temp->left:&temp->right;//這?很重要 if(*p==sentinel){ break; } temp=*p; } *p=node; node->parent=temp; node->left=sentinel; node->right=sentinel; ngx_rbt_red(node); }
另外set和map的關鍵區別是set不存儲val字段;
優點:存儲效率高,訪問速度高效;
缺點:對于數據量大且查詢字符串比較長且查詢字符串相似時將會是噩夢;
1.4 unordered_map
c++標準庫(STL)中的unordered_map
構成:數組+hash函數;
它是將字符串通過hash函數?成?個整數再映射到數組當中;它增刪改查的時間復雜度是o(1);
圖結構示例:
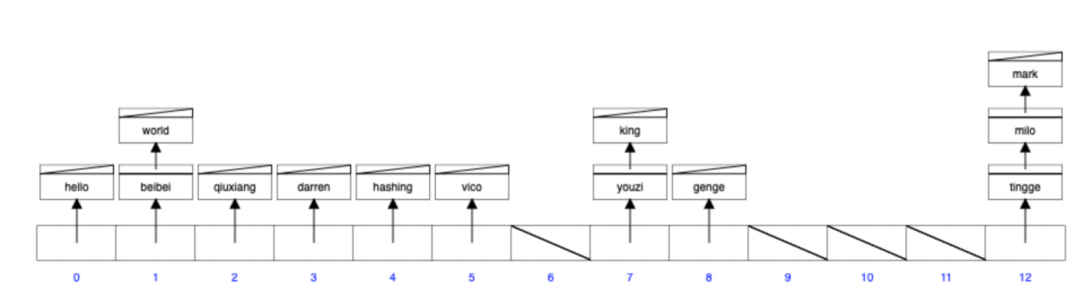
hash函數的作?:避免插入的時候字符串的?較;hash函數計算出來的值通過對數組?度的取模
能隨機分布在數組當中;
hash函數?般返回的是64位整數,將多個?數映射到?個?數組中,必然會產?沖突;
如何選取hash函數?
選取計算速度快;
哈希相似字符串能保持強隨機分布性(防碰撞);
murmurhash1,murmurhash2,murmurhash3,siphash(redis6.0當中使?,rust等?多數語?選?的hash算法來實現hashmap),cityhash都具備強隨機分布性;測試地址如下:https://github.com/aappleby/smhasher
負載因?:數組存儲元素的個數/數組?度;負載因?越?,沖突越?;負載因?越?,沖突越?;
hash沖突解決?案:○ 鏈表法引?鏈表來處理哈希沖突;也就是將沖突元素?鏈表鏈接起來;這也是常?的處理沖突的?式;但是可能出現?種極端情況,沖突元素?較多,該沖突鏈表過?,這個時候可以將這個鏈表轉換為紅?樹;由原來鏈表時間復雜度 o(n) 轉換為紅?樹時間復雜度o(log2n) ;那么判斷該鏈表過?的依據是多少?可以采?超過256(經驗值)個節點的時候將鏈表結構轉換為紅?樹結構;○ 開放尋址法將所有的元素都存放在哈希表的數組中,不使?額外的數據結構;?般使?線性探查的思路解決;
當插?新元素的時,使?哈希函數在哈希表中定位元素位置;
檢查數組中該槽位索引是否存在元素。如果該槽位為空,則插?,否則3;
在 2 檢測的槽位索引上加?定步?接著檢查2;加?定步?分為以下?種:
i+1,i+2,i+3,i+4 ... i+n
i-1^2^ ,i+2^2^ ,i-3^2^ ,1+4^2^ ...這兩種都會導致同類hash聚集;也就是近似值它的hash值也近似,那么它的數組槽位也靠近,形成hash聚集;第一種同類聚集沖突在前,第二種只是將聚集沖突延后;另外還可以使用雙重哈希來解決上面出現hash聚集現象:
在.net HashTable類的hash函數Hk定義如下:Hk(key) = [GetHash(key) + k * (1 + (((GetHash(key) >> 5) + 1) % (hashsize – 1)))] % hashsize在此 (1 + (((GetHash(key) >> 5) + 1) % (hashsize – 1))) 與 hashsize 互為素數(兩數互為素數表示兩者沒有共同的質因?);執?了 hashsize 次探查后,哈希表中的每?個位置都有且只有?次被訪問到,也就是說,對于給定的 key,對哈希表中的同?位置不會同時使? Hi 和 Hj;
同樣的hashtable中節點存儲了key和val,hashtable并沒有要求key的??順序,我們同樣可以修改代碼讓插?存在的數據變成修改操作;
優點:訪問速度更快;不需要進行字符串比較;
缺點:需要引?策略避免沖突,存儲效率不?;空間換時間;
1.5 總結
紅?樹和hashtable都不能解決海量數據問題,它們都需要存儲具體字符串,如果數據量大,提供不了?百G的內存;所以需要嘗試探尋不存儲key的?案,并且擁有hashtable的優點(不需要?較字符串);
2. 布隆過濾器
定義:布隆過濾器是?種概率型數據結構,它的特點是?效的插入和查詢,能明確告知某個字符串?定不存在或者可能存在;
布隆過濾器相?傳統的查詢結構(例如:hash,set,map等數據結構)更加高效,占?空間更小;但是其缺點是它返回的結果是概率性的,也就是說結果存在誤差的,雖然這個誤差是可控的;同時它不支持刪除操作;
組成:位圖(bit數組)+ n個hash函數
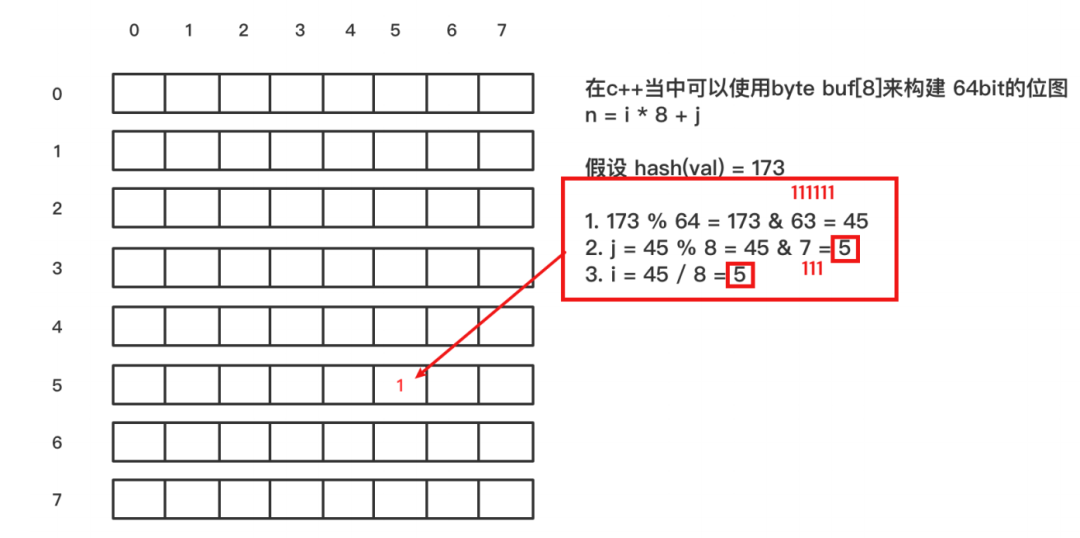
原理:當?個元素加?位圖時,通過k個hash函數將這個元素映射到位圖的k個點,并把它們置為1;當檢索時,再通過k個hash函數運算檢測位圖的k個點是否都為1;如果有不為1的點,那么認為不存在;如果全部為1,則可能存在(存在誤差);
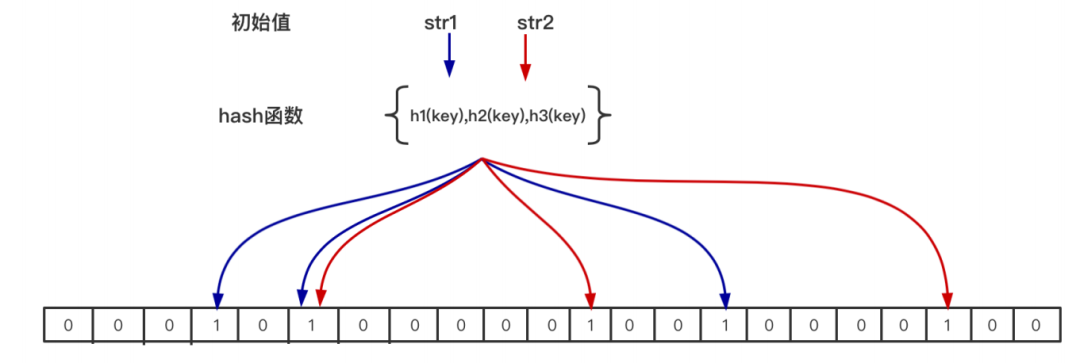
在位圖中每個槽位只有兩種狀態(0或者1),?個槽位被設置為1狀態,但不明確它被設置了多少 次;也就是不知道被多少個str1哈希映射以及是被哪個hash函數映射過來的;所以不?持刪除操作;
在實際應?過程中,布隆過濾器該如何使??要選擇多少個hash函數,要分配多少空間的位圖,存儲多少元素?另外如何控制假陽率(布隆過濾器能明確?定不存在,不能明確?定存在,那么存在的判斷是有誤差的,假陽率就是錯誤判斷存在的概率)?
n--布隆過濾器中元素的個數,如上圖只有str1和str2兩個元素那么n=2 p--假陽率,在0-1之間0.000000 m--位圖所占空間 k--hash函數的個數 公式如下: n=ceil(m/(-k/log(1-exp(log(p)/k)))) p=pow(1-exp(-k/(m/n)),k) m=ceil((n*log(p))/log(1/pow(2,log(2)))); k=round((m/n)*log(2));
假定我們選取這四個值為:n = 4000p = 0.000000001m = 172532k = 30
四個值的關系:
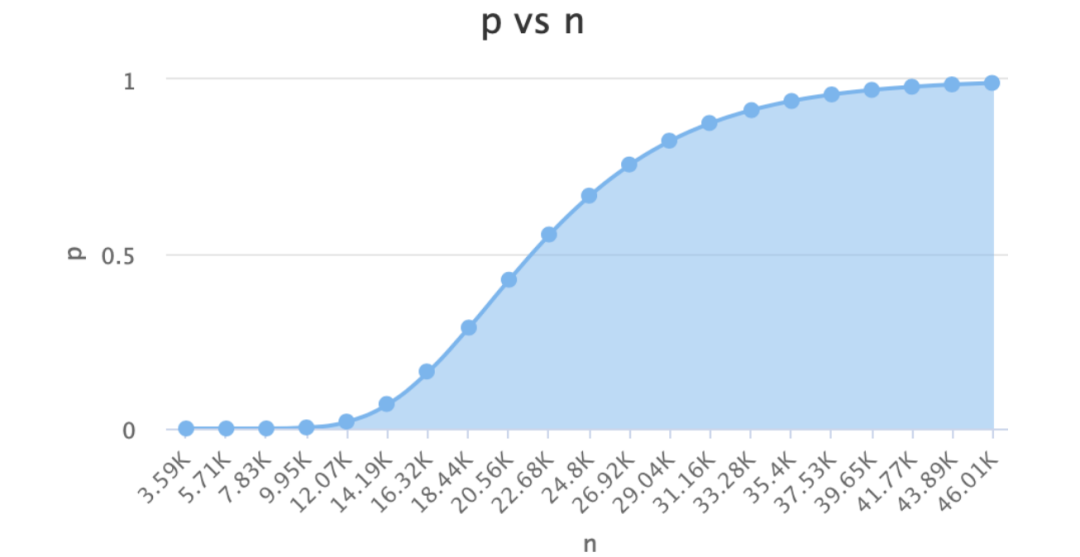
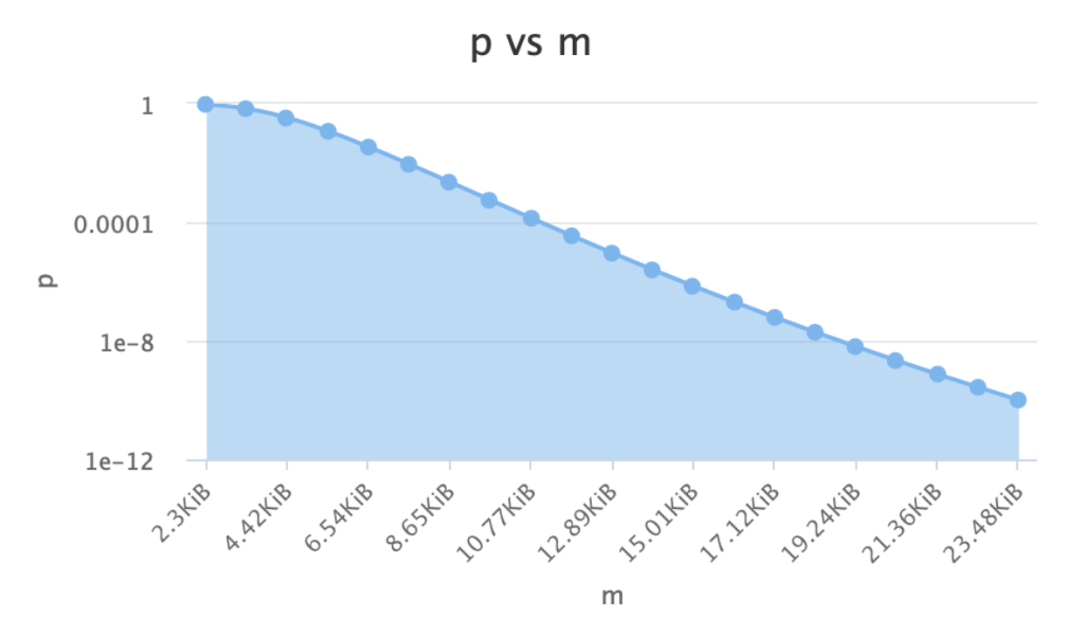
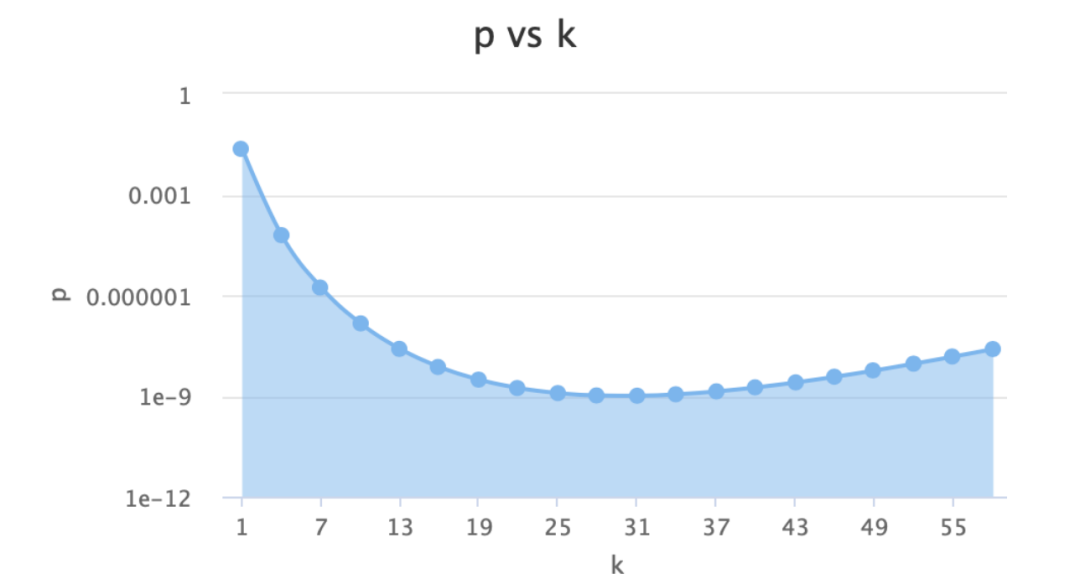
在實際應?中,我們確定n和p,通過上?的計算算出m和k;也可以在?站上選取合適的值:https://hur.st/bloomfilter
已知k,如何選擇k個hash函數?
//采??個hash函數,給hash傳不同的種?偏移值 //#defineMIX_UINT64(v)((uint32_t)((v>>32)^(v))) uint64_thash1=MurmurHash2_x64(key,len,Seed); uint64_thash2=MurmurHash2_x64(key,len,MIX_UINT64(hash1)); for(i=0;i
審核編輯:劉清
-
Linux系統
+關注
關注
4文章
591瀏覽量
27353 -
AVL
+關注
關注
0文章
14瀏覽量
10035 -
STL
+關注
關注
0文章
85瀏覽量
18300 -
Hash算法
+關注
關注
0文章
43瀏覽量
7379
原文標題:Linux服務器 | 數據去重hash與布隆過濾器
文章出處:【微信號:嵌入式開發AIoT,微信公眾號:嵌入式開發AIoT】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
求教:linux系統和WEB服務器什么關系?WEB服務器和網頁又是什么關系?
如何在linux服務器上使用hanlp
Linux和Windows下的登錄和使用Linux服務器的方式
探討一下關于STM32中的中斷系統
基于Linux系統的FTP服務器的實現
簡單探討一下關于電線電纜的結構材料的相關知識

如何使用Checkmk監控Linux服務器?





 工商網監
工商網監
評論