繼開源 LLaMA 之后,Meta 在生成式 AI 方向又公布一項重大研究。
我們知道,GPT、DALL-E 等大規模生成模型徹底改變了自然語言處理和計算機視覺研究。這些模型可以生成高保真文本或圖像,而且它們有個重要特點就是「通才」,可以解決沒訓過的任務。相比之下,語音生成模型在規模和任務泛化方面一直沒有「突破性」成果。
今日,Meta 介紹了一種「突破性」的生成式語音系統,它可以合成六種語言的語音,執行噪聲消除、內容編輯、轉換音頻風格等。Meta 稱之為最通用的語音生成 AI。
相關研究論文也已公布。接下來我們具體看下這下項研究。

論文:https://research.facebook.com/publications/voicebox-text-guided-multilingual-universal-speech-generation-at-scale/
Meta 表示,Voicebox 是第一個沒有經過專門針對語音生成的訓練,卻可以泛化到語音生成任務的模型。
與圖像和文本的生成一樣,Voicebox 可以創建多種樣式的語音輸出,包括從頭開始創建輸出和修改給定的樣本。Voicebox 可以合成六種語言的語音,以及執行噪聲去除、內容編輯、風格轉換和多樣化樣本生成。
在 Voicebox 出現之前,生成語音的 AI 需要使用精心準備的訓練數據對每項任務進行特定訓練。而 Voicebox 僅需要從原始音頻和隨附的轉錄文本中學習,并且 Voicebox 可以修改給定樣本的任何部分。
Voicebox 基于一種稱為流匹配(Flow Matching)的方法,該方法已被證明可以改進擴散模型。
在生成效果方面,Voicebox 的可懂度(詞錯率:1.9% VS 5.9%)和音頻相似度(0.681 VS 0.580)優于當前英文語音生成 SOTA 模型 VALL-E,并且速度快了 20 倍。在跨語言風格遷移任務上,Voicebox 優于 YourTTS,將平均詞錯率從 10.9% 降低到 5.2%,將音頻相似度從 0.335 提高到 0.481。
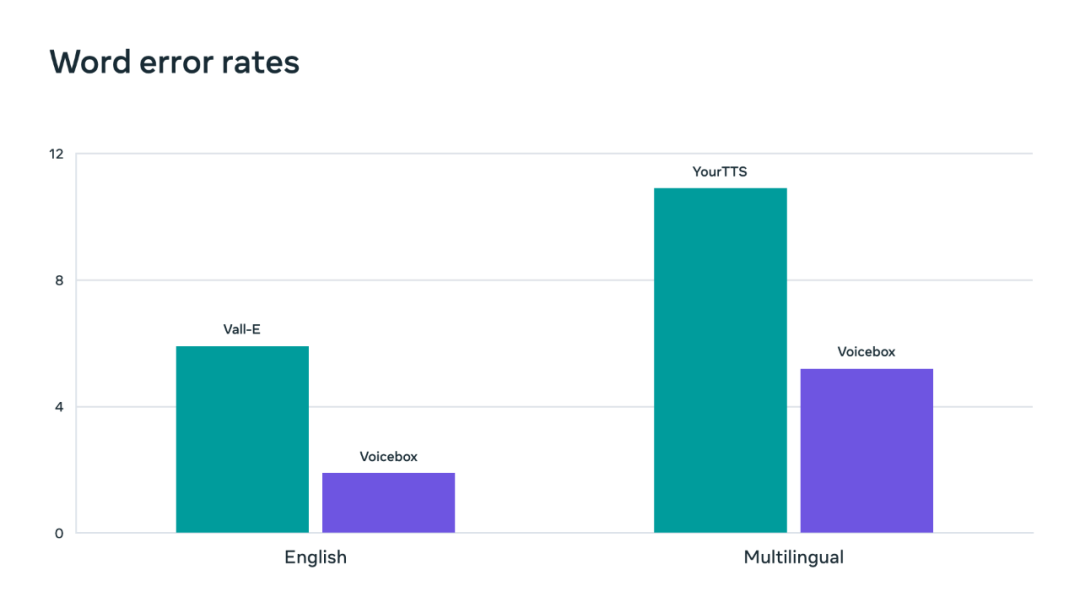
Voicebox 在詞錯率指標上的表現優于 Vall-E 和 YourTTS,實現新的 SOTA。
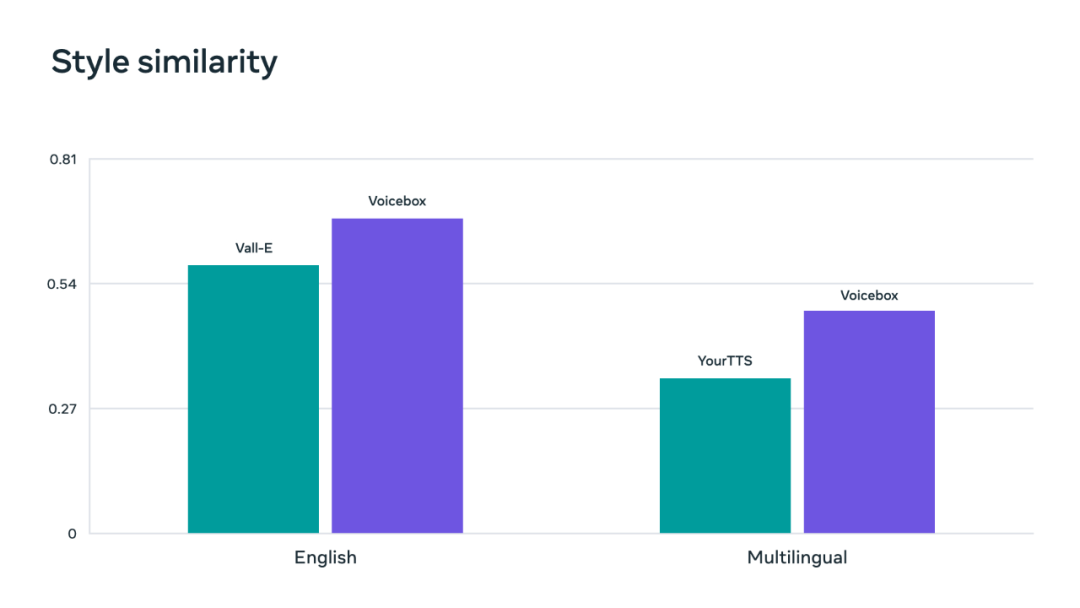
在英語和多語言基準的音頻風格相似度指標上,Voicebox 都取得了新的最佳結果。
語音生成新方法
現有語音合成器的一大主要局限是它們的訓練數據都是針對目標任務準備的。這些輸入基本都要求是單調的干凈數據,也因此難以獲取,數據量很有限,并且用這些數據訓練出的模型也只能輸出單調的聲音。
Voicebox 基于流匹配(Flow Matching)模型,這是 Meta 在非自回歸生成模型方面的最新進展,其可以學習到文本和語音之間高度非確定性的映射關系。非確定性映射很有用,因為這能讓 Voicebox 學習不同的語音數據而無需仔細標注這些變體。也就是說,Voicebox 可以在更多樣化的數據上訓練,因此可使用數據的范圍也大得多。
Meta 訓練 Voicebox 時使用的數據來自英語、法語、德語、西班牙語、波蘭語、葡萄牙語這六種語言,包含 50000 小時的錄音和轉錄文本以及公共領域的有聲書。Voicebox 的訓練目標是根據周圍語音和某片段的轉錄文本來預測該片段的語音。學習過基于上下文填充語音之后,該模型就能讓其用于各種語音生成任務,包括生成音頻錄音中的缺失片段(無需重建整個輸入)。
Voicebox 的這種多功能性使其可以很好地執行多種不同任務,包括:
基于語境的文本轉語音合成:僅需使用長度 2 秒的輸入音頻樣本,Voicebox 就能匹配樣本的音頻風格并將其用于文本轉語音生成。這一能力具有重要的應用前景,比如可以為難以說話的人帶來語音表達能力,還能讓用戶為 NPC 角色和虛擬助手定制聲音。
跨語言風格遷移:給定一段語音樣本和對應的文本片段,不管是英語、法語、德語,還是西班牙語、波蘭語、葡萄牙語,Voicebox 都能以該語言讀出該文本。這是一種激動人心的能力,因為這能幫助人們自然而真實地交流 —— 即便他們不說同一種語言。
語音降噪和編輯:Voicebox 的上下文學習能力讓它可以在音頻錄音中生成無縫銜接的片段。要是音頻中出現了被噪聲污染的片段,它也可以為其重新合成,甚至無需重新錄音就能替換原音頻中說錯的詞句。用戶可以辨別原始音頻中被噪聲(比如犬吠聲)污染的片段,然后將其裁剪下來,再指示 Voicebox 重新生成該片段。這項能力有望讓音頻編輯變得非常簡單,就像現在流行的圖像編輯工具調整圖像一樣。
多樣化的語音采樣:Voicebox 學習了多樣化的野外數據,所以可以生成就像在現實世界中說話的聲音,并且支持上述六種語言。未來,這種能力可用于合成數據,然后用于訓練語音助理模型等。Meta 的實驗結果表明,基于 Voicebox 合成語音訓練的語音識別模型的表現幾乎不遜于使用真實語音訓練的模型 —— 錯誤率僅高了 1%;而要是使用之前的文本轉語音模型合成的數據訓練,錯誤率會提升 45%-70%。
Meta 表示,Voicebox 作為首個能成功執行任務泛化的高效的多功能模型,將開創一個語音生成式 AI 的新時代。
但 Meta 也沒有否認這項技術可能被誤用乃至被惡意使用。為了應對這種可能性,降低潛在的風險,Meta 還構建了一種分類器,其宣稱可有效分辨真實語音和 VoiceBox 生成的音頻。
Voicebox 是生成式 AI 研究的重要一步。具備任務泛化能力的生成式 AI 模型正在催生出涉及文本、圖像和視頻生成的實際應用,這將讓生成式 AI 更上一層樓。
參考內容:https://www.engadget.com/metas-open-source-speech-ai-recognizes-over-4000-spoken-languages-161508200.htmlhttps://ai.facebook.com/blog/voicebox-generative-ai-model-speech/
原文標題:語音領域的GPT時刻:Meta 發布「突破性」生成式語音系統,一個通用模型解決多項任務
文章出處:【微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
原文標題:語音領域的GPT時刻:Meta 發布「突破性」生成式語音系統,一個通用模型解決多項任務
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
相關推薦
本帖最后由 jf_40317719 于 2024-9-29 17:13 編輯
智能硬件的語音交互接入大模型后可以直接理解自然語言內容,但大模型作為一
發表于 09-29 17:12
未來2-3年內,機器人基礎模型的研究將迎來重大突破,這一時刻被形象地比喻為機器人領域的“GPT-3時刻
![的頭像]() 發表于
發表于 09-20 17:05
?761次閱讀
英偉達科學家9月19日,科技媒體The Decoder發布了一則引人關注的報道,英偉達高級科學家Jim Fan在近期預測,機器人技術將在未來兩到三年內迎來類似GPT-3在語言處理領域的
![的頭像]() 發表于
發表于 09-19 15:13
?538次閱讀
Meta公司近日在人工智能領域邁出了重要一步,隆重推出了其創新之作——“Imagine Yourself”AI模型,這一
![的頭像]() 發表于
發表于 08-26 10:59
?463次閱讀
科技巨頭Meta近期震撼發布了其最新的開源人工智能(AI)模型——Llama 3.1,這一舉措標志著Meta在AI
![的頭像]() 發表于
發表于 07-24 18:25
?1400次閱讀
在人工智能領域的激烈競爭中,Meta公司再次擲出重磅炸彈,宣布將于7月23日正式發布其最新力作——Llama 3-405B,一個擁有驚人40
![的頭像]() 發表于
發表于 07-18 09:58
?953次閱讀
自然語言處理、語音識別、語音生成等多個領域展現出強大的潛力和廣泛的應用前景。本文將從Transformer模型的基本原理出發,深入探討其在
![的頭像]() 發表于
發表于 07-03 18:24
?979次閱讀
大模型語音問答、拍照識圖、大模型繪圖等豐富供能示例,支持語音喚醒、多輪語音交互。
2智能對話除了大模型
發表于 06-18 17:33
中國電信人工智能研究院(TeleAI)近日發布了一項引領業界的語音識別技術——星辰超多方言語音識別大模型。這
![的頭像]() 發表于
發表于 05-28 09:14
?544次閱讀
學習能力。這些模型以生成能力強和靈活性強為特點,逐漸演變成一種通用計算平臺。其參數多樣性、生成能
發表于 05-04 23:55
OpenAI近日宣布推出其全新的文本到視頻生成模型——Sora。這一突破性的技術將視頻創作帶入了一個
![的頭像]() 發表于
發表于 02-18 10:07
?1011次閱讀
Meta發布CodeLlama70B開源大模型 Meta發布了開源大模型CodeLlama70B
![的頭像]() 發表于
發表于 01-31 10:30
?1369次閱讀
Meta近日宣布了其最新版本的AI代碼生成模型Code Llama70B,并稱其為“目前最大、最優秀的模型”。這一更新標志著
![的頭像]() 發表于
發表于 01-30 18:21
?1398次閱讀
一、引言 在人工智能領域,語音技術被譽為“未來人機交互的入口”,而語音數據集則是AI語音技術的靈魂。本文將深入探討
![的頭像]() 發表于
發表于 12-14 14:33
?982次閱讀
的發展趨勢。 二、語音數據集的重要性 提高語音識別和生成能力:語音數據集包含大量的語音樣本,可以
![的頭像]() 發表于
發表于 12-12 11:32
?677次閱讀
 語音領域的GPT時刻:Meta 發布「突破性」生成式語音系統,一個通用模型解決多項任務
語音領域的GPT時刻:Meta 發布「突破性」生成式語音系統,一個通用模型解決多項任務





 工商網監
工商網監
評論