 CVPR 2023 | 清華大學提出LiVT,用視覺Transformer學習長尾數據
CVPR 2023 | 清華大學提出LiVT,用視覺Transformer學習長尾數據
 ?背景
?背景
在機器學習領域中,學習不平衡的標注數據一直是一個常見而具有挑戰性的任務。近年來,視覺 Transformer 作為一種強大的模型,在多個視覺任務上展現出令人滿意的效果。然而,視覺 Transformer 處理長尾分布數據的能力和特性,還有待進一步挖掘。
目前,已有的長尾識別模型很少直接利用長尾數據對視覺 Transformer(ViT)進行訓練。基于現成的預訓練權重進行研究可能會導致不公平的比較結果,因此有必要對視覺 Transformer 在長尾數據下的表現進行系統性的分析和總結。

論文鏈接:
https://arxiv.org/abs/2212.02015代碼鏈接:
https://github.com/XuZhengzhuo/LiVT 本文旨在填補這一研究空白,詳細探討了視覺 Transformer 在處理長尾數據時的優勢和不足之處。本文將重點關注如何有效利用長尾數據來提升視覺 Transformer 的性能,并探索解決數據不平衡問題的新方法。通過本文的研究和總結,研究團隊有望為進一步改進視覺 Transformer 模型在長尾數據任務中的表現提供有益的指導和啟示。這將為解決現實世界中存在的數據不平衡問題提供新的思路和解決方案。 文章通過一系列實驗發現,在有監督范式下,視覺 Transformer 在處理不平衡數據時會出現嚴重的性能衰退,而使用平衡分布的標注數據訓練出的視覺 Transformer 呈現出明顯的性能優勢。相比于卷積網絡,這一特點在視覺 Transformer 上體現的更為明顯。另一方面,無監督的預訓練方法無需標簽分布,因此在相同的訓練數據量下,視覺 Transformer 可以展現出類似的特征提取和重建能力。 基于以上觀察和發現,研究提出了一種新的學習不平衡數據的范式,旨在讓視覺 Transformer 模型更好地適應長尾數據。通過這種范式的引入,研究團隊希望能夠充分利用長尾數據的信息,提高視覺 Transformer 模型在處理不平衡標注數據時的性能和泛化能力。 ?文章貢獻
本文是第一個系統性的研究用長尾數據訓練視覺 Transformer 的工作,在此過程中,做出了以下主要貢獻:
首先,本文深入分析了傳統有監督訓練方式對視覺 Transformer 學習不均衡數據的限制因素,并基于此提出了雙階段訓練流程,將視覺 Transformer 模型內在的歸納偏置和標簽分布的統計偏置分階段學習,以降低學習長尾數據的難度。其中第一階段采用了流行的掩碼重建預訓練,第二階段采用了平衡的損失進行微調監督。
?文章貢獻
本文是第一個系統性的研究用長尾數據訓練視覺 Transformer 的工作,在此過程中,做出了以下主要貢獻:
首先,本文深入分析了傳統有監督訓練方式對視覺 Transformer 學習不均衡數據的限制因素,并基于此提出了雙階段訓練流程,將視覺 Transformer 模型內在的歸納偏置和標簽分布的統計偏置分階段學習,以降低學習長尾數據的難度。其中第一階段采用了流行的掩碼重建預訓練,第二階段采用了平衡的損失進行微調監督。
 ?
?其次,本文提出了平衡的二進制交叉熵損失函數,并給出了嚴格的理論推導。平衡的二進制交叉熵損失的形式如下:
?
?其次,本文提出了平衡的二進制交叉熵損失函數,并給出了嚴格的理論推導。平衡的二進制交叉熵損失的形式如下:
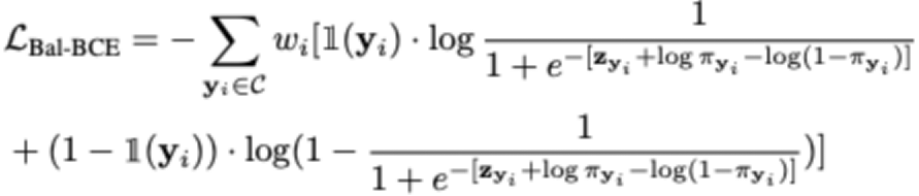 ?
?與之前的平衡交叉熵損失相比,本文的損失函數在視覺 Transformer 模型上展現出更好的性能,并且具有更快的收斂速度。研究中的理論推導為損失函數的合理性提供了嚴密的解釋,進一步加強了我們方法的可靠性和有效性。
?
?與之前的平衡交叉熵損失相比,本文的損失函數在視覺 Transformer 模型上展現出更好的性能,并且具有更快的收斂速度。研究中的理論推導為損失函數的合理性提供了嚴密的解釋,進一步加強了我們方法的可靠性和有效性。
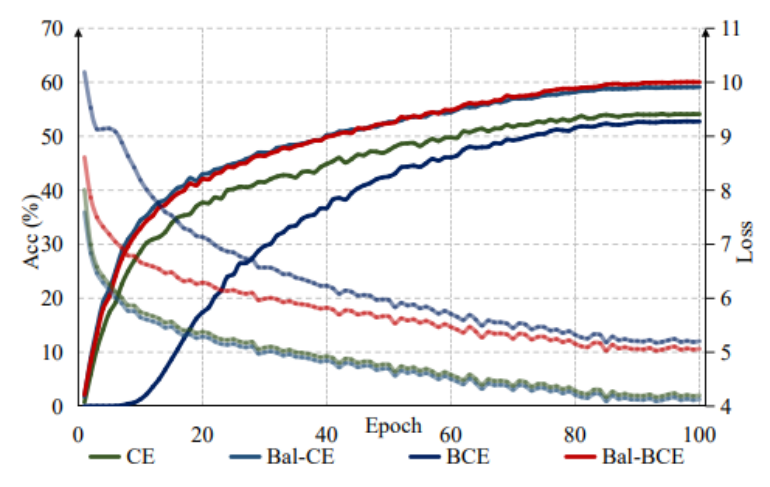 ▲不同損失函數的收斂速度的比較
基于以上貢獻,文章提出了一個全新的學習范式 LiVT,充分發揮視覺 Transformer 模型在長尾數據上的學習能力,顯著提升模型在多個數據集上的性能。該方案在多個數據集上取得了遠好于視覺 Transformer 基線的性能表現。
▲不同損失函數的收斂速度的比較
基于以上貢獻,文章提出了一個全新的學習范式 LiVT,充分發揮視覺 Transformer 模型在長尾數據上的學習能力,顯著提升模型在多個數據集上的性能。該方案在多個數據集上取得了遠好于視覺 Transformer 基線的性能表現。
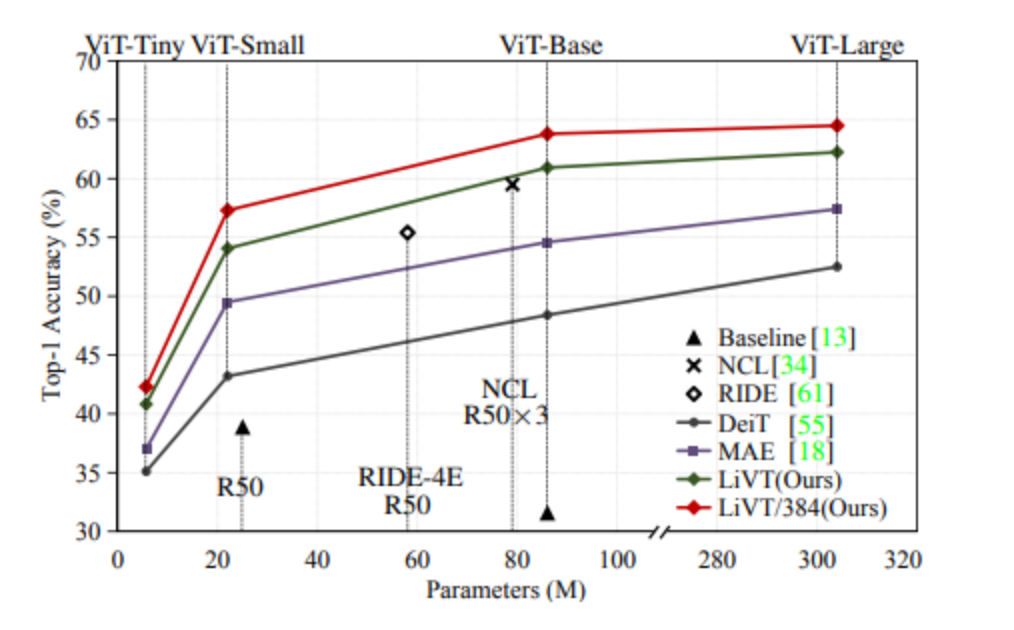 ▲不同參數量下在ImageNet-LT上的準確性
▲不同參數量下在ImageNet-LT上的準確性
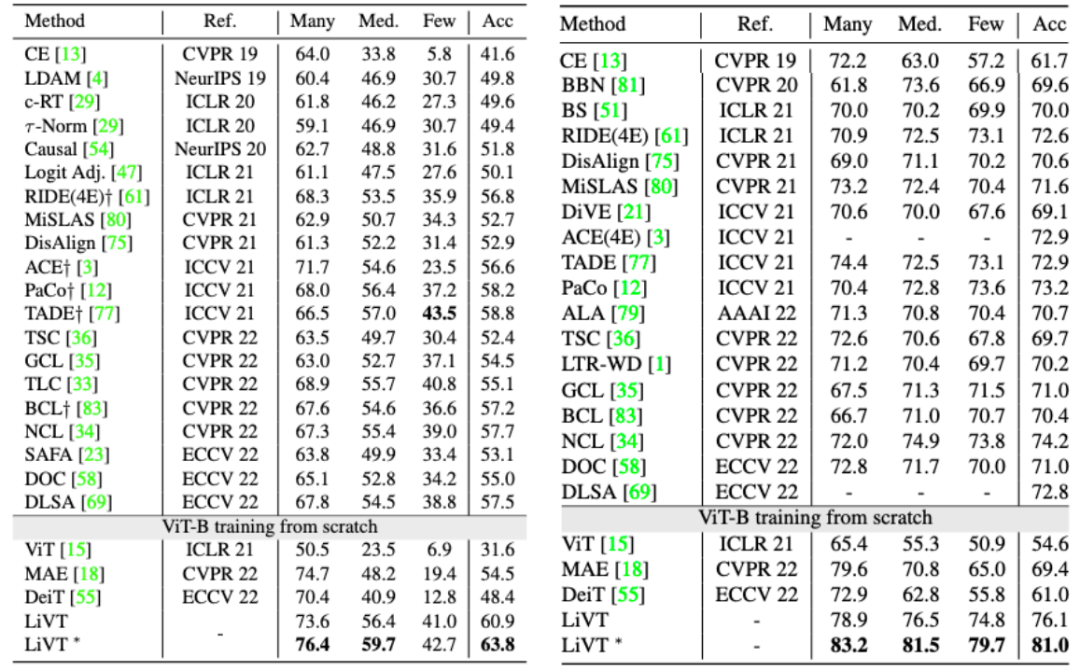 ▲在ImagNet-LT(左)和iNaturalist18(右)數據集上的性能表現
▲在ImagNet-LT(左)和iNaturalist18(右)數據集上的性能表現同時,本文還驗證了在相同的訓練數據規模的情況下,使用ImageNet的長尾分布子集(LT)和平衡分布子集(BAL)訓練的 ViT-B 模型展現出相近的重建能力。如 LT-Large-1600 列所示,在 ImageNet-LT 數據集中,可以通過更大的模型和 MGP epoch 獲得更好的重建結果。
 ?
?
?
? ?
?總結
本文提供了一種新的基于視覺 Transformer 處理不平衡數據的方法 LiVT。LiVT 利用掩碼建模和平衡微調兩個階段的訓練策略,使得視覺 Transformer 能夠更好地適應長尾數據分布并學習到更通用的特征表示。該方法不僅在實驗中取得了顯著的性能提升,而且無需額外的數據,具有實際應用的可行性。 論文的更多細節請參考論文原文和補充材料。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
物聯網
+關注
關注
2904文章
44306瀏覽量
371464
原文標題:CVPR 2023 | 清華大學提出LiVT,用視覺Transformer學習長尾數據
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
博世與清華大學續簽人工智能研究合作協議
近日,博世與清華大學宣布,雙方續簽人工智能領域的研究合作協議,為期五年。在此期間,博世將投入5000萬元人民幣。基于2020年成立的清華大學—博世機器學習聯合研究中心(以下簡稱“聯合研究中心”),博世和
京微齊力受邀參加2024年清華大學工程博士論壇
此前,2024年清華大學國家卓越工程師學院工程博士論壇在北京亦莊(北京經濟技術開發區)舉辦。本屆論壇以“清亦融創、新質引領”為主題,來自集成電路、生物醫藥、人工智能等戰略性新興領域500余位清華大學創新領軍工程博士生參加。
英諾達與清華大學攜手,共促國產EDA進步
10月30日,英諾達官方微信發布消息稱,英諾達與清華大學近期展開合作,共同深化產學研融合。此次合作聚焦于集成電路低功耗設計領域,英諾達團隊走進清華大學集成電路學院,為師生們帶來了專題授課及深入交流。
清華新力量,滬上芯征程!清華大學上海校友會半導體專委會2024思瑞浦迎新日
聚焦高性能模擬芯片2024年10月,清華大學上海校友會半導體專業委員會聯合思瑞浦共同舉辦2024年來滬清華校友迎新活動。金秋時節,新一批清華人離開清華園來到上海,希望借此活動助力他們更

熱烈歡迎清華大學電子工程系學子來武漢六博光電交流實踐!
近日,武漢六博光電技術有限責任公司接到清華大學函件,正式成為清華大學電子工程系武漢實踐基地之一。2024年8月1日上午,清華大學電子工程系實踐團隊一行共計13名學子前往武漢六博光電有限責任公司交流

易華錄無錫數據湖與清華大學蘇州汽車研究院(吳江)合作挖掘智能駕駛數據新價值
6月15日,易華錄無錫數據湖與清華大學蘇州汽車研究院(吳江)數字工業中心就“聚焦汽車智能駕駛領域,共同挖掘智駕數據新價值”舉行了簽約儀式。清華大學蘇州汽車研究院顧問、數字工業中心主任王
清華大學研發新型仿生三維電子皮膚系統
在科技日新月異的今天,清華大學再次引領了科研的潮流。6月5日,從清華大學傳來喜訊,該校航天航空學院與柔性電子技術實驗室的張一慧教授團隊,成功研制出了一款具有仿生三維架構的新型電子皮膚系統。這一突破性的科研成果不僅代表了電子皮膚領域的新高度,更在人機交互、物理量測量等多個領
世界首款!又是清華:類腦互補視覺芯片“天眸芯”
近日,清華大學在類腦視覺感知芯片領域取得重要突破:清華大學依托精密儀器系的類腦計算研究中心施路平教授團隊,提出一種基于視覺原語的互補雙通路類

清華大學創新領軍工程博士團訪問摩爾線程
5月19日,“清華大學創新領軍工程博士代表團走進摩爾線程”活動順利舉辦。近五十位來自集成電路、能源、航天、通信等重要領域的清華大學工程博士參加了本次活動。
清華大學創新領軍工程博士代表團到訪摩爾線程,深化產學合作
5月19日,“清華大學創新領軍工程博士代表團走進摩爾線程”活動成功舉行。此次活動聚集了五十多位來自集成電路、能源、航天、通信等重要行業的清華大學創新領軍工程博士。

清華大學聯合中交興路發布《中國公路貨運大數據碳排放報告》
為踐行并推動實現“雙碳”目標,清華大學聯合中交興路發布《中國公路貨運大數據碳排放報告》(以下簡稱:《報告》)。

直線電機生產廠家談清華大學獲芯片領域重要突破
設備制造商、醫學設備制造商、科研機構以及各大高校。 像大家熟知的清華大學、北京航空航天大學、西安交通大學、哈爾濱工業大學、浙江大學、南京

清華大學研發成功大規模干涉-衍射異構集成芯片——太極
4月12日公布,清華大學研發出太極芯片,實現了每瓦160TOPS的高性能通用智能計算,這是該校電子工程系與自動化系共同攻克的難題。
DEKRA Stan Zurkiewicz拜訪清華大學蘇州汽車研究院,探討汽車行業安全發展
3月12日,DEKRA德凱集團董事會主席兼首席執行官Stan Zurkiewicz先生一行拜訪清華大學蘇州汽車研究院,探討汽車行業安全發展。
清華大學突破性成果!全球首個無串擾量子網絡節點誕生
清華大學交叉信息研究院的段路明教授課題組長期以來進行了創新性的研究,并提出使用同種離子的雙類型量子比特來實現量子網絡節點的方案。





 工商網監
工商網監
評論