 基于交互環境的生成式預訓練和指令微調方法
基于交互環境的生成式預訓練和指令微調方法
引言
距離上次的長篇大論,已經過去了半年有余。這段時間,對于AI業界甚至整個世界,都是驚心動魄的。在這段時間里,最令人印象深刻的大事莫過于ChatGPT和GPT-4的發布。毫無疑問,GPT-4是有史以來最為強大的AI程序。在隨后發表的一篇論文[1]中,學者們將GPT-4稱為通用人工智能(AGI)誕生的火花。誠然,每個人對于AGI的定義不盡相同,現階段的GPT也尚未真正解決AI領域的所有難題;然而,基于大模型的技術,確實已經接近完成NLP領域的大一統,甚至讓人隱約看到了AGI的曙光。或許,在3-5年內,我們就能夠看到馮諾伊曼架構基礎之上的AGI計算架構;倘若如此,大模型將在其中占據核心位置。
除了GPT系列外,計算機視覺領域也好不熱鬧,幾個前沿方向都出現了令人驚嘆的進展。對于公眾來說,感受最深的莫過于AI繪畫了。Stable Diffusion[2]和ControlNet[3]等技術的出現,大幅降低了訓練和應用擴散模型的門檻。在Midjourney等社區中,AI繪畫的發展速度可謂一日千里,許多技術困難(如AI不會畫手、不會數數等)也得到了初步改善。如今,只要有一塊入門級GPU或者交一點訂閱費用,每個人都可以創作出自己的AI作品來。就連一段時間以來頗為平淡的視覺感知領域,也被一個叫做SAM[4]的方法攪動起來:雖然SAM還存在諸多缺陷(如語義識別能力有限),但它讓人看到了視覺基礎模型的更多可能性。根據Google scholar的統計,僅僅兩個月的時間里,SAM就得到了超過200次引用,足見關注程度之高、研究之內卷。
面對如此沖擊,包括我在內的許多研究者都會感到迷茫。很顯然,在NLP的引領下,發展大一統的任務和體系,將成為未來3-5年整個CV領域的核心課題。然而,CV是否已經做好實現這個宏偉目標的準備?當前的視覺基礎模型(包括最近的SAM)究竟做到了什么、沒有做到什么?這篇斷斷續續寫了兩個月的文章,就是我對于這些問題的思考。
文章的部分內容,也被我整理成一篇微型survey,并與VALSE上報告的PPT一起,放在以下地址:
在這篇文章中,我將從AGI的定義說起。隨后,我將簡要回顧NLP領域所經歷的變革。基于大語言模型的GPT系列,為自然語言處理帶來了劃時代的改變,點燃了AGI的火花。接著,我將進入CV領域的討論。作為AGI的下一個重要戰場,CV領域正在走向大一統模型,但是面臨的困難還很大。我將回顧現有工作,分析本質困難,并且在GPT的啟發下提出一種新的研究范式。最后,我還將分享一些個人觀點。
人工智能和通用人工智能
今天的人們,對于人工智能(AI)一詞并不陌生。現代意義上的AI誕生于1956年的達特茅斯會議,隨后經歷了幾十年的發展,幾經興衰。AI的根本目標,在于使用數學方法復現人類智能。近年來,在深度學習的帶動下,AI領域取得了長足進步,也深刻地改變了人們的生產生活方式。
通用人工智能(AGI),是AI發展的最高目標。關于AGI的定義有很多,其中最通俗的一種,即AGI是能夠具有任何人類和動物所具有能力的算法。從早期的圖靈測試(早于達特茅斯會議)開始,關于AGI的追求和爭論從未停止。深度學習的出現,大大加快了AGI的進程;而近期的GPT系列,則被學者們認為是點燃了AGI的火花[1]。深度學習本身提供了一種通用的方法論,使得人們可以在確定輸入和輸出形式的情況下,使用統計學習方法,構建神經網絡(一種層次化的數學函數)來近似輸入和輸出之間的關系。只要有足夠多的數據,深度學習就能夠應用于CV、NLP、強化學習等諸多AI子領域。

GPT:點燃NLP領域的AGI火花
發布以來,GPT系列刷新了無數紀錄,其中就包括2個月內達到1億用戶的神跡。這個紀錄的重要性在于,它表明了AI算法已經具備面向普通用戶(to consumers,即2C)的能力,這在歷史上還是第一次。為了做到2C,AI算法必須具備極強的通用能力,能夠滿足用戶的絕大部分要求。令人吃驚的是,GPT做到了這一點。GPT基本上解決了NLP領域的常見問題。在許多問題(如編寫代碼)上,GPT的能力甚至超越了專門設計的算法。也就是說,GPT實現了NLP領域的大一統:原先看似孤立的各個任務,都可以在多輪對話任務下統一起來。誠然,GPT還不完美,也會在許多問題上犯錯或者胡言亂語,但是在可預見的范圍內,NLP的研究范式不會再發生大的變革了。這場曠日持久(從達特茅斯會議算起,已有近70年)的NLP戰爭已經分出勝負,接下來就是些打掃戰場的工作,比如解決垂直領域問題、邏輯推理、提高用戶體驗,等等。
關于GPT的能力展示,此處不再贅述,大家可以參考互聯網上浩如煙海的資料,或者“AGI火花”一文里系統詳盡的分析[1]。我只想引述GPT-4官方新聞的一句話:
As a result, our GPT-4 training run was (for us at least!) unprecedentedly stable, becoming our first large model whose training performance we were able to accurately predict ahead of time.
結果表明,GPT-4的訓練過程(至少對我們來說)前所未有地穩定,它也成為我們訓練過的第一個能夠提前準確預測效果的大模型。
換句話說,GPT-4的本質是個神經網絡,是個概率模型;但是它表現出來的行為(不論是訓練還是測試),已經穩定得不像個概率模型了。這著實是一次了不起的技術突破!
關于GPT系列的實現原理,許多優秀的文章已經做過分析,此處我不再贅述。簡單地說,GPT訓練分為兩個階段。第一階段被稱為生成式預訓練,主要在無標注的通用語料庫中進行。大規模語言模型通過預測下一單詞,擬合通用文本的數據分布,并獲得in-context learning能力,能夠通過少量示例來適應新任務。第二階段被稱為指令微調,主要在有標注的對話數據庫中進行。在此過程中,大規模語言模型將通用文本分布對齊到問答數據中,顯著提升了針對性解決問題的能力。同時,模型還可以從人類用戶的反饋中學習獎勵函數,從而進一步增強其滿足用戶偏好的能力。如果對更具體的分析感興趣,可以自行搜索ChatGPT的實現原理。
CV:AGI的下一個戰場
由于人類通過多種模態來理解世界,因此真正的AGI必須結合CV和NLP來實現。然而,在CV中實現AGI,比在NLP中實現AGI的難度大很多。根據前面的定義,真正的AGI應該具有即解決通用問題、與環境互動的能力,而不僅僅是完成萬物識別和多模態對話等初級任務。然而如圖2所示(示例圖源:UberNet[6]),相比于利用統一對話系統來解決所有問題的GPT,當前CV的常用方法論還比較初步,大多局限于使用獨立的模型甚至算法來解決不同的問題,包括圖像分類、物體檢測、實例分割、注意力檢測、圖像描述、以文生圖等。
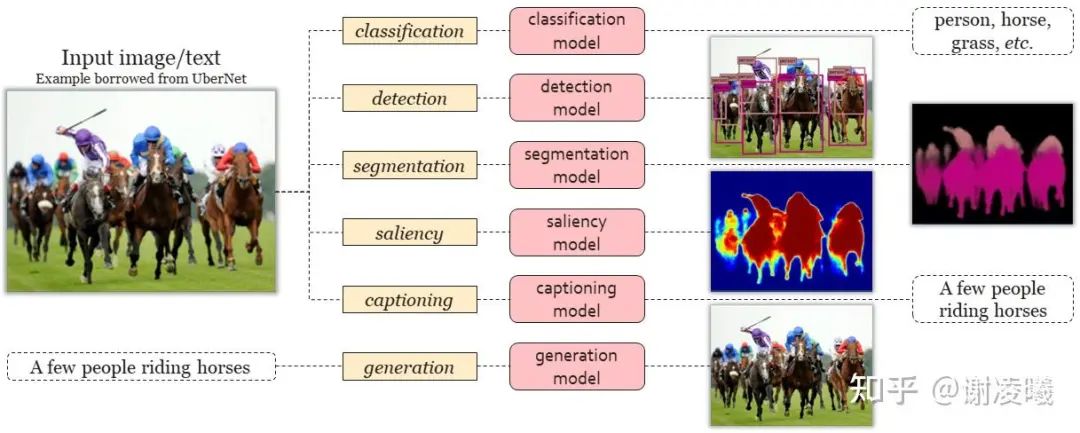
圖2:當前CV主要使用獨立的算法解決問題。
艱難的CV大一統之路
為了接近GPT的水平,CV必須走向大一統,也就是使用一套系統,解決各種視覺問題。近來,業界出現了不少此類嘗試,我們將其分為五個主要方向。其中前三個方向主要解決任務形式的統一、第四個方向主要解決視覺任務邏輯的統一、最后一個方向主要解決視覺和語言交互的統一。以下我們簡要綜述每個方向的代表性工作,并且分析它們的優缺點。
開放域視覺識別:即要求算法不僅能夠識別訓練集中出現過的概念,還能夠通過自然語言等方式識別訓練集中未出現過的概念。當前,開放域識別的主要奠基性工作為CLIP[7],它提供了文本和圖像間的跨模態特征對齊方法,使得人們能夠統一使用自然語言來指代目標語義,從而完成了分類、檢測、分割、定位、按需識別等各類任務。雖然自然語言提供了足夠的靈活性,使得開放域識別成為可能,但自然語言難以指代視覺信號中的細粒度信息,從而在一定程度上限制了識別能力。
Segment Anything任務:通過設計統一的prompt系統并且在標注層面完成數據閉環,SAM[4]能夠分割出圖像中的所有基礎單元,并且在相當廣泛的視覺域中展現出了泛化能力。無需重新訓練,SAM就能提供基礎語義單元,并應用于分割3D物體、物體消除和填充、分割醫療影像或者隱藏物體,等。SAM傳遞出的重要思路是:通過降低視覺任務的難度(此處主要指無語義標簽的分割),來統一視覺任務形式定義,增強模型的域間遷移能力。從形式看看,SAM很像通用的視覺識別流程中的一個部分,但如何構建合理的上下游模塊來配合它(以構建完整流程),依然是個開放問題。
通用視覺編碼:即一系列通過統一編碼形式,來整合多種任務的嘗試。它們雖然形式不同,但是都指向同一個目標,即通過把不同模態、不同任務的數據編碼為統一形態,使得單個神經網絡模型能夠完成盡可能多的任務。其中代表性的方法分為三類:首先是Gato[8],它驗證了單個transformer模型能夠完成CV、NLP、強化學習等任務;其次是pix2seq[9]和OFA[10],驗證了不同視覺任務(如檢測、分割、描述)在自然語言形態下得到統一,從而送入單個模型進行訓練;最后是Painter[11]和SegGPT[12],借鑒了NLP中in-context learning的方式,將一系列視覺任務編碼為不同形式的圖像密集預測任務,并訓練單個純視覺模型來解決問題。相比于傳統視覺識別框架,這些方法更接近大一統的目標,也論證了當前的神經網絡模型特別是transformer能夠適應一大類跨模態任務。然而,這些僅僅追求形式上的統一,與多任務學習的邊界并不清晰,也并未充分展現出統一帶來的好處。
大語言模型引導的視覺理解:在語言模型的協助下,將復雜視覺問題拆解為統一的邏輯鏈,并分步解決問題。其實這類方法并非最近才出現:至少在2017年,就出現了使用LSTM拆分問題并調用視覺模塊的嘗試[13]。只是大語言模型的出現,使得這一方法論的通用性大大增強。最近出現的一系列工作,其共同特點是使用GPT將文本問題轉化為可分步執行的邏輯。這種邏輯可以是代碼,可以對接搜索引擎,也可以表現為流程圖或者自然語言。必要時,程序將調用視覺模塊,以提供檢測、計數、OCR、描述等基礎能力。這類方法充實了視覺問答的邏輯,也提升了答案的可解釋性,但它強烈地依賴于大語言模型和基礎視覺模塊。很多情況下,以檢測為代表的視覺任務本身也需要復雜邏輯來完成。很顯然,當前的方法很難下探到這一深度。
多模態對話:在對話任務中引入圖像或視頻作為參考,從而允許通過對話任務來完成統一形式的視覺理解。在視覺、語言、跨模態預訓練模型的基礎上,只需要微調很少部分的參數,就能完成問答任務[14]。受到GPT系列的啟發,研究者們將視覺標注送入語言模型,在簡單的提示下,生成了問答數據[15]。多模態對話模型在這些問答數據上微調之后,就具備了回答復雜問題的能力。目前,以此種方式產生的問答結果,已經可以媲美GPT-4技術報告中提到的例子[16]。然而,當前多模態對話系統的能力,大部分來自大語言模型。這也就意味著,與開放域識別一樣,多模態對話對于細粒度視覺信息的指代能力比較有限。在使用復雜圖像作為參考時,算法很難針對其中某個特定的人或物進行提問,從而也限制了解決具體問題的能力。
以上幾個方向的研究,將CV領域帶到了新的高度。以當前進展看,CV算法能夠在一定條件下完成視覺識別,也能夠進行初步的多模態對話,但是距離大一統模型、距離通用的任務解決還有很遠。而后者正是AGI所需要的能力。
于是我們不禁要問:為什么在CV中完成大一統如此困難?這個問題的答案,還要從NLP中去找。
NLP給CV帶來的啟發
我們嘗試從另一個視角來理解GPT所完成的事情。我們不妨想象自己像GPT一樣,生活在一個純文本的世界里。在這樣的世界里,多輪對話任務是充分且必要的:一方面,我們只能通過文字與其他智能體交流;另一方面,我們可以通過多輪對話去完成所有任務。也就是說,在NLP領域,學習環境是完備的:我們通過多輪對話來訓練算法,而算法也只需要掌握多輪對話,就是一個能夠完成所有任務的AGI。我將這個性質成為“所訓即所需”——這個詞是模仿“所見即所得”造出來的。
這樣看來,GPT所定義的對話任務,比起GPT的實現方法更加重要!這種定義使得AI算法能夠通過與環境互動來學習,恰好符合AGI的定義:與環境互動,并且最大化獎勵。相較而言,CV就沒有形成清晰的路線:既沒有環境用于預訓練,各種算法也并不能在實際環境中解決問題。顯然,這背離了CV和AGI的基本原則。事實上,早在1970年代,計算機視覺的先驅大衛·馬爾就提出:視覺算法必須構建真實世界的模型,并且從交互中學習[17];隨后也不乏其他學者指出交互的重要性。然而如今,大部分視覺算法并非研究如何與環境交互,而是研究如何在各種任務上提升精度。
這是為什么呢?當然是環境構建的難度太大!
代理任務:理想向現實的妥協
要想構建場景用于CV任務,主要有兩種方法:
構建真實環境:在真實世界中放置大量智能體,使其通過與包括人類在內的其他智能體互動學習。這種方式的缺點在于成本太高且難以確保安全。
構建虛擬環境:通過視覺算法模擬或者重建3D環境,在虛擬世界中訓練智能體。這種方式的缺點在于真實性不足,包括場景建模的真實性和智能體行為的真實性,從而訓練的智能體難以有效遷移至真實世界中。
除此之外,對環境中其他智能體行為的模擬也很重要,這決定了CV算法在真實應用場景中的適應能力。如果希望環境與智能體互動(例如在現實世界中放置一個真實的機器人),則收集數據的成本還會顯著上升。另一方面,環境中的智能體的行動模式往往比較單一,難以模擬真實世界中豐富而開放(open-domain)的行為。
總的來說,目前所構建的場景,還不足以滿足大規模訓練CV算法的需要。在無法模擬環境情況下,人們只能退而求其次,不直接與環境互動,而從真實環境中采樣大量的數據,并且將與環境互動可能需要的能力定義為一系列代理任務(即通過完成任務,接近最終的目標),如物體識別、追蹤等。人們假設,通過提升這些代理任務的精度,就能夠讓CV算法更接近AGI。
可問題是,這個假設對嗎?
圖3表達了我們的觀點。在深度學習出現之前,CV的算法還比較弱,代理任務的精度也不高。當時,對于代理任務的追求,很大程度上推進了AGI的發展。然而過去十年,隨著深度學習的發展,各項代理任務都已經高度飽和。在ImageNet-1K數據集上,top-1分類精度已經從前深度學習時代的50%以下提升到了90%以上。此時,繼續提升代理任務的精度,有可能無法逼近AGI,甚至與之背道而馳。GPT的出現,進一步印證了這個觀點:在接近AGI的模型出現后,原本孤立的NLP代理任務,如翻譯和命名實體抽取,就變得不再重要了。
代理將死!

圖3:CV的代理任務正在失去意義,甚至使我們遠離AGI。
未來范式:從環境中學習
我們設想的學習流程如圖4(圖源:Habitat[18]和ProcTHOR[19])所示,分為如下階段:
第0階段,環境構建。通過各種方式構建虛擬環境,盡可能地增強環境的豐富性、真實性,可交互性。
第1階段,生成式預訓練。讓智能體探索環境,結合自身行動,預測未來將會看到的畫面。這對應于GPT的預訓練階段,任務是預測下一個單詞。在這個過程中,CV算法記憶了現實世界的分布,并做好了通過少量樣本學習任務的能力。
第2階段:指令微調。訓練智能體完成具體任務,如尋找特定物體,甚至與其他智能體交互。這對應于GPT的指令微調任務,同樣建立在豐富的任務描述和人工指令數據基礎上。在這個過程中,CV算法為了完成任務,必須掌握各種視覺概念,并習得按需處理視覺信號的能力。
下游階段(可選)。可以用基于prompt的方式,將AGI模型用于傳統視覺任務。
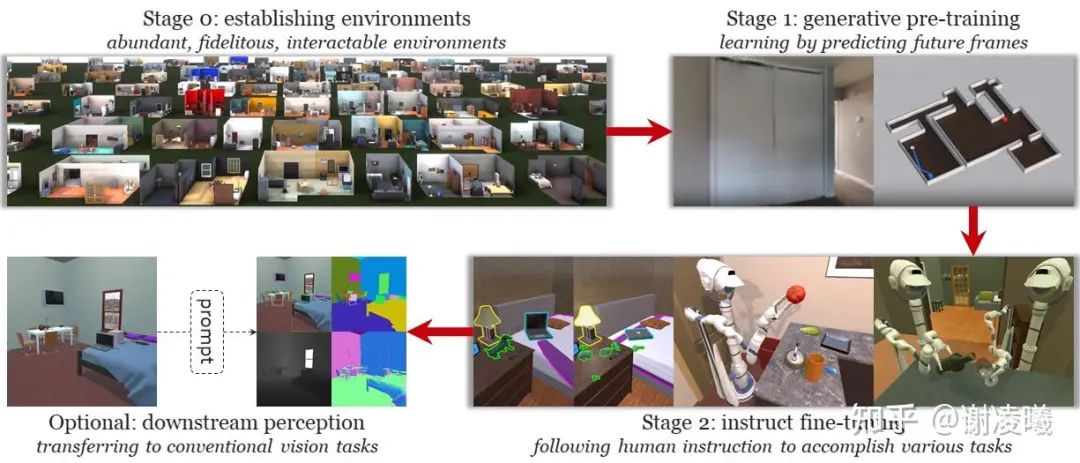
圖4:設想中的未來CV訓練流程,在環境探索、完成任務,并遷移到下游感知任務。
需要注意的是,在這樣一個流程中,代理任務只是算法在通用任務上訓練過后,“順手”習得的能力。而現在的大部分CV研究,卻將代理任務作為唯一的追求,屬實是本末倒置了。
要想實現上述流程,面臨的困難有很多。我們從三個階段來分析。
更復雜的虛擬環境。當前構建虛擬環境的方法主要有兩種。一是基于真實數據產生的虛擬環境:收集實際場景數據,并將其建模為點云、面片(mesh)、神經輻射場(NeRF)等數據結構,并支持高速、大規模的渲染。這種做法的成本還比較高,難以規模化生產環境。當前可用的3D數據集(如Habitat[18]),相比于2D數據集,規模要小好幾個數量級,且依然局限于某些特殊場景(如室內或者街景)。二是通過仿真學方法構建虛擬環境:通過3D建模、生成式算法(包括GAN和擴散模型)等方式,直接采樣虛擬數據并渲染3D環境。這種做法雖然能夠批量生成環境(如ProcTHOR[19]),但它不易還原真實世界的數據分布。一方面,圖像上通常包含影響算法學習的artifacts(即使肉眼難以觀察出來),從而難以保證在虛擬數據上訓練的模型的遷移能力。然而不論是哪種方法,虛擬環境的大小和真實度還不能滿足要求,且難以允許AI算法與環境中的其他智能體互動。
更復雜的數據結構。NLP的數據結構比較簡單,它天然具備“單詞”這樣基本、不可分的[20]語義單元,也自然地設計出了transformer這樣的架構來處理這些離散單元;在任務層面上,NLP將預訓練定義為上下文生成(俗稱完形填空),同時也將所有下游任務也建模為上下文生成。如此渾然一體的框架,使得NLP的預訓練任務和下游任務之間gap很小。然而CV的數據結構就要復雜得多:這種復雜不僅體現在圖像的維度更高,而且體現在圖像的基本語義單元難以定義。在這種情況下,一味地“抄作業”,強行把圖像切分為tokens以套用transformer架構,顯然不是最優方案。當前,我越來越傾向于認為,token只是一種假象、一種權宜之法,真正適合視覺表征的數學性質,還需要更多工作來揭示。
更復雜的實際任務。顯然,引入CV信號后,智能體通過與環境互動,能夠完成更多、更復雜的任務。與NLP的多輪對話相比,這些任務的形式更復雜、數據模態更豐富、多樣性也更顯著。可以預期,如果采用指令微調的方式,就需要收集更多的數據,甚至引入真實智能體的行為模式。這對于數據量、數據復雜度等方面,都有更高的要求。
最近,我們關注到一些令人欣喜的工作。其中一個工作是PaLM-E[21],它使用跨模態基礎模型來指導具身視覺算法,增強其能力。另一個不如PaLM-E有名,但卻更讓人振奮的工作則是ENTL[22],它將環境建模和指令學習都建模為序列預測的形式,實現了上述框架的雛形。這些工作照亮了在環境中學習的道路;在此基礎上,伴隨著系統設計和工程優化,我們將會看到CV大一統的光明未來。
小結
在達特茅斯會議的提議書中,AI的先驅者們寫下了一個看似平凡,卻無比困難的問題:如何讓計算機學會使用人類語言?經過幾十年的努力,研究者們終于在NLP領域看到了AGI的曙光,但是CV領域距離這個目標還有很遠。造成CV當前困境的本質原因,在于CV領域沒有構建起“從環境中學習”的范式,因而只能采樣環境、設計代理任務,無法形成系統層面的閉環。未來,為了實現CV的大一統,我們必須拋棄現有框架,設計全新的具身范式,讓CV算法在與環境的交互中增強能力,不斷進化。
一些感性的思考
最近一段時間,我看到了許多稍顯浮躁的論調。其中最為常見的,莫過于AI將要革新一切,甚至消滅大部分AI從業者,最終達到共同失業(劃掉最后一句)。作為理智的從業人員,我知道CV算法的能力還比較有限,硬骨頭還有很多。不過有一點是確定的:大規模語言模型(LLM)已經具備了強大的意圖理解和初步的邏輯推理能力,因而達到了成為AI與人類溝通的“中樞系統”的條件。一旦如此,這條技術路線就會固化下來,在未來3-5年甚至更長的時間內,業界要做的事情只有兩件:繼續強化中樞系統(增強LLM或者構建其多模態的變種、以模塊化的形式完善其各項能力),并且將這種范式復刻到CV領域里去。如今,再討論大模型是否是未來已經沒有意義,我們要做的,就是為CV真正用上大模型做好鋪墊和準備。
目前看來,大模型很可能會成為與深度學習本身相媲美的革命性技術,我們很可能正在經歷一場技術革命。在大模型定義的新時代里,我們每個人都是初學者。以代理任務為代表的舊時代遺存,將很快失去價值;而不能勇敢地擁抱新方法的人,也將隨著代理任務一并消亡。
附錄
以下文字,是對上述觀點的補充,也是一些暫時還沒有形成體系的思考。
再談CV的根本困難
在去年的那篇文章里,我闡述了CV的三大根本困難,即信息稀疏性、域間差異性、無限粒度性,并且指出它們正是采樣+代理任務的范式所帶來的副作用。文章鏈接如下:關于視覺識別領域發展的個人觀點
其中的關鍵段落摘抄如下:
從根本上說,自然語言是人類創造出來,用于存儲知識和交流信息的載體,所以必然具有高效和信息密度高的特性;而圖像則是人類通過各種傳感器捕捉的光學信號,它能夠客觀地反映真實情況,但相應地就不具有強語義,且信息密度可能很低。從另一個角度看,圖像空間比文本空間要大得多,空間的結構也要復雜得多。這就意味著,如果希望在空間中采樣大量樣本,并且用這些數據來表征整個空間的分布,采樣的圖像數據就要比采樣的文本數據大許多個數量級。順帶一提,這也是為什么自然語言預訓練模型比視覺預訓練模型用得更好的本質原因——我們在后面還會提到這一點。根據上述分析,我們已經通過CV和NLP的差別,引出了CV的第一個基本困難,即語義稀疏性。而另外兩個困難,域間差異性和無限粒度性,也多少與上述本質差別相關。正是由于圖像采樣時沒有考慮到語義,因而在采樣不同域(即不同分布,如白天和黑夜、晴天和雨天等場景)時,采樣結果(即圖像像素)與域特性強相關,導致了域間差異性。同時,由于圖像的基本語義單元很難定義(而文本很容易定義),且圖像所表達的信息豐富多樣,使得人類能夠從圖像中獲取近乎無限精細的語義信息,遠遠超出當前CV領域任何一種評價指標所定義的能力,這就是無限粒度性[23]。
進一步分析,我們就會得到一個有趣的結論:CV的本質困難在于人類對視覺信號的理解十分有限。人類從來就沒有真正掌握視覺信號的結構,乃至為其定義某種專用語言,而只能通過自然語言來指代和表示視覺信號。許多明顯的證據都能夠表達這一點:大部分人在沒有經過訓練的情況下,很難畫出具有真實感的圖像(這表明人類沒有掌握圖像的數據分布);同時,大部分人很難通過語言交流,向另外一個人準確地表達圖像上的意思——即使兩人在語音通話,且看著電腦上的同一張圖,要想通過純語言交流指代圖中的某些細節元素,也未必總是容易的。
如果重新審視CV的三大根本困難,就會發現它們可以統一起來,體現為視覺信號的表征粒度具有主觀性和不確定性,或者追求客觀的視覺信號與追求簡潔的語義信號之間的矛盾。當表征粒度較大(即追求語義信號的簡潔性)時,人類可以用較為簡潔的方式表達視覺信息,于是認為視覺信號具有語義稀疏性;當表征粒度較小(即追求視覺信號的客觀性)時,人類又能夠識別出圖像中豐富的視覺信息,于是認為視覺信號具有無限粒度性;當表征粒度不確定時,人類很難將連續變化的視覺信號與離散的語義空間對應起來,于是在視覺信號改變而語義不變的范圍內,就產生了域間差異性[24]。
此外需要特別指出的是,信息稀疏性和無限粒度性之間的矛盾,主要體現在傳統的代理任務中。此時,如果追求表征的高效性(如使用信息壓縮作為指標),就難以保證識別的細粒度和準確率。為了規避這樣的矛盾,唯一的方案是構建真實的交互環境,允許智能體根據任務來調整視覺信號的粒度。
再次對比CV和NLP,就會發現,NLP很好地避免了粒度不確定的問題。由于NLP處理的文本信號是人為創造的,它的粒度就是文字本身的粒度。雖然這個粒度可變(例如用語言描述一個物體或者場景時,既可以描述得很精確,也可以描述得很粗略),但人類確定了這個粒度,并且保證它與實際需求相吻合。
既然NLP的粒度比較明確,是否可以幫助CV完成任務?我們發現,以往幾乎所有CV方法,都使用NLP的方式來定義粒度。其中典型的例子有兩個:基于分類的任務以及語言指代的任務。這兩種方式各自存在的缺陷,我在之前的文章中也分析過,摘錄如下。
基于分類的方法:這包括傳統意義上的分類、檢測、分割等方法,其基本特點是給圖像中的每個基本語義單元(圖像、box、mask、keypoint等)賦予一個類別標簽。這種方法的致命缺陷在于,當識別的粒度增加時,識別的確定性必然下降,也就是說,粒度和確定性是沖突的。舉例說,在ImageNet中,存在著“家具”和“電器”兩個大類;顯然“椅子”屬于“家具”,而“電視機”屬于“家電”,但是“按摩椅”屬于“家具”還是“家電”,就很難判斷——這就是語義粒度的增加引發的確定性的下降。如果照片里有一個分辨率很小的“人”,強行標注這個“人”的“頭部”甚至“眼睛”,那么不同標注者的判斷可能會不同;但是此時,即使是一兩個像素的偏差,也會大大影響IoU等指標——這就是空間粒度的增加引發的確定性的下降。語言驅動的方法:這包括CLIP帶動的視覺prompt類方法,以及存在更長時間的visual grounding問題等,其基本特點是利用語言來指代圖像中的語義信息并加以識別。語言的引入,確實增強了識別的靈活性,并帶來了天然的開放域性質。然而語言本身的指代能力有限(想象一下,在一個具有上百人的場景中指代某個特定個體),無法滿足無限細粒度視覺識別的需要。歸根結底,在視覺識別領域,語言應當起到輔助視覺的作用,而已有的視覺prompt方法多少有些喧賓奪主的感覺。
說了這么多,還是回到開始的那個根本癥結:視覺沒有定義好自己的語言。當前可見的方法,都是用NLP的方式來定義CV。這些方法可以解決CV的初級問題,但要深入探索下去,就要碰得頭破血流!
CV所處的發展階段
很顯然,GPT范式在NLP領域的大獲成功,讓CV研究者有些心癢難耐。遵循NLP的發展路徑看,NLP在GPT-1階段構建了大模型,在GPT-3階段觀察到了能力涌現,進而在ChatGPT階段采用了指令學習來解決具體任務。
于是一個很重要的問題是:當前的CV研究,到底發展到了什么階段?
4月底,我參加了一次VALSE線上研討會的panel環節,其中一個問題就是:SAM是否解決了計算機視覺問題,或者是否達到了GPT-3的水平(以致于可以在此基礎上構建強大的CV算法)。我給出的結論很悲觀:SAM沒有達到GPT-3的水平,甚至離GPT-1還很遠。其中最重要的原因,就是CV沒有構建合適的學習環境。前面說到,NLP構建了對話環境,并且針對對話任務,設計了完形填空配合指令微調的學習范式。如果CV要仿照這套流程,就應當也構建交互任務,并且設計相應的預訓練和微調任務。很顯然,當前的CV學習范式并沒有做到這一點,因此我們總感覺CV的上下游任務是脫節的:即使當前效果最好的MIM方法,似乎也和下游任務關系不大。要解決這個問題,很可能要從源頭下手,構建起真正的學習環境來。
接著我們討論能力涌現的問題。關于NLP的大模型為什么能夠觀察到能力涌現,業界似乎還存有疑問。我自己有一個大膽的假說:能力涌現的前提,是預訓練數據已經覆蓋了現實世界的一定比例。在這種情況下,預訓練模型不必擔心過擬合,因為它的任務就是記憶數據分布,某種意義上就是過擬合——這個假說也同時揭示了為什么NLP可以追求大模型:因為在不擔心過擬合的情況下,大模型的擬合能力要更強。在這里,NLP的特征空間小、數據形態簡單的優勢就體現出來,而CV要想達到這樣的狀態,還需要更多的數據和更大的算力。
我有一個不嚴格的類比:NLP好比國際象棋,CV好比圍棋。1996年,超級計算機深藍通過啟發式搜索的方式,在國際象棋中戰勝了人類世界冠軍,但是相似的方法無法在圍棋中復現,因為圍棋的狀態空間要遠遠超過國際象棋。后來,在深度學習的幫助下,圍棋的啟發式函數得到了非平凡的改進,終于能夠支撐起更復雜的狀態空間的探索。如果沒有深度學習,也許人類要再過幾十年,才能夠通過超大計算量的堆砌,達成同樣的成就。深度學習的出現極大地加速了這個過程。
回到CV的發展上來。誠然,按照當前數據收集和計算量提升的速度,或許再過足夠長的時間,CV也能夠跌跌撞撞地達到當前NLP的水平。不過我相信,在此之前,一定會有某項技術突破,加速CV趕超NLP的過程。而我們CV研究者的使命,就是找到這項技術,或者至少找對正確的方向。
對未來研究方向的展望
經過上面的討論,未來CV的pipeline已經有了雛形:基于交互環境的生成式預訓練和指令微調方法。這未必是唯一的路線,只是在NLP的啟發下催生出來的最有可能的路線。實現它的困難有很多,但只要認準了方向,當前的困難恰恰對應于最有前景的研究方向。
退一步說,如果上述pipeline在短期內難以實現,那么CV就應當盡可能吸收NLP的能力,以期提升通用能力。很顯然,純粹基于圖像信號的CV研究將越來越少,融合語言的跨模態研究將成為絕對主流:只要使用了CLIP或者類似的多模態基礎模型用于特征抽取,就相當于接受了跨模態的思想。在這條路線上,最重要的研究方向可以概括為“找到圖像與自然語言的交互方式”,或者更進一步地說,“找到圖像本身的語言”:這一點對于交互類任務也是至關重要的。
責任編輯:彭菁
-
數據
+關注
關注
8文章
6898瀏覽量
88838 -
計算機視覺
+關注
關注
8文章
1696瀏覽量
45928 -
GPT
+關注
關注
0文章
351瀏覽量
15315 -
nlp
+關注
關注
1文章
487瀏覽量
22012
原文標題:VALSE 2023 | 走向計算機視覺的通用人工智能:GPT和大語言模型帶來的啟發
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【大語言模型:原理與工程實踐】大語言模型的預訓練
為什么要使用預訓練模型?8種優秀預訓練模型大盤點
微軟在ICML 2019上提出了一個全新的通用預訓練方法MASS

新的預訓練方法——MASS!MASS預訓練幾大優勢!


微調前給預訓練模型參數增加噪音提高效果的方法
使用 NVIDIA TAO 工具套件和預訓練模型加快 AI 開發
基于多任務預訓練模塊化提示
基于一個完整的 LLM 訓練流程

基于生成模型的預訓練方法

基于雙級優化(BLO)的消除過擬合的微調方法






 工商網監
工商網監
評論