 手把手用Verilog實現FIR濾波器
手把手用Verilog實現FIR濾波器
設計思想
首先需要把FIR最基本的結構實現,也就是每個FIR抽頭的數據與其抽頭系數相乘這個操作。由頂層文件對這個基本模塊進行多次調用。
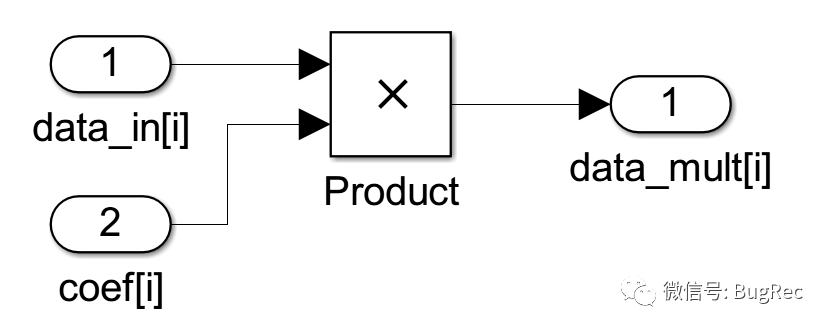
由于FIR抽頭系數是中心對稱的,為了減少乘法在FPGA內的出現,每個基本結構同時會輸入兩個信號,也是關于中心對稱的。
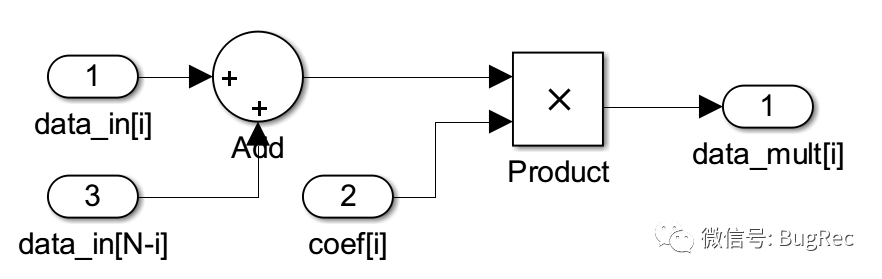
此外,為了防止后續相加的過程引起符號位溢出,FIR基本模塊需要對乘法結果進行符號位擴展。
擴展完成后,如果同時對這些(71個)加權結果相加,肯定會使得系統運行速率上不去,而且設計的比較死板。這里需要引入流水線操作;何為流水線操作,簡單地說,本來你一個人承擔一桌菜,你需要洗菜,切菜,炒菜,裝盤,上桌,不僅十分麻煩而且很耽誤時間;這個時候有人過來幫你,一個人洗菜,一個人切菜,一個人炒菜,一個人裝盤,你負責上桌,雖然費了些人,但是每個人的任務都比較輕松所以做事速度也很快,這就是流水線操作,把一件很復雜的事情劃分成N個小事,雖然犧牲了面積但換取了系統運行時鐘的提升。
前期準備
除了Verilog模塊,我們還有幾樣東西需要準備。首先,需要將FIR抽頭系數定點化,上一文使用的FIR抽頭系數都是很小的浮點數,為此,我們直接對每個系數乘以2的15次冪,然后取整數,舍去小數位,設定FIR抽頭系數位寬為16bit;因為系數本身比較小,不擔心會溢出。注意,這里抽頭系數的位寬盡量不超過信號位寬,否則可能會有問題。
為了方便多個模塊同時調用FIR系數,這里使用Python直接將定點化的系數生成為function,輸入為index,需要第N階的FIR系數,就調用function,輸入參數為N,輸出為定點化的系數。
所謂定點化,這里使用的方法十分粗暴,直接對所有浮點數,乘以一個2的n次冪。然后對參數向下取整,舍棄小數位。
FIR浮點系數轉化為定點數并生成function的代碼如下:
def coef2function(filename, exp, gain):
# :param filename: FIR抽頭系數文件名
# :param exp: 浮點數轉定點數的位寬
# :param gain: 浮點數整體的增益,增益為power(2, gain)
# :return:
coef = set_coef(filename)
with open('fir_coef.v', 'w') as f:
f.write('function [{}:0] get_coef;\\n'.format(exp-1))
f.write('input [7:0] index;\\n')
f.write('case (index)\\n')
for i in range(len(coef)):
f.write('{}: get_coef = {};\\n'.format(i,int(np.floor(coef[i] * np.power(2,gain)))))
f.write('default: get_coef = 0;\\n')
f.write('endcase\\nendfunction')
轉換生成的function示例如下:
function [15:0] get_coef;
input [7:0] index;
case (index)
0: get_coef = 0;
1: get_coef = 0;
2: get_coef = 2;
3: get_coef = 10;
...
69: get_coef = 10;
70: get_coef = 2;
71: get_coef = 0;
72: get_coef = 0;
default: get_coef = 0;
endcase
endfunction
這樣,當多個基本模塊并行運行時,每個模塊的系數可以通過調用function獲取對應的參數。
仿真需要有信號源供FIR濾波,所以直接將仿真用的信號源定點化;因為Testbench中使用readmemh或者readmemb讀取txt文檔數據,只能讀取二進制或16進制數據,所以需要對數據進行二進制或16進制轉換。
信號源選取上一文的信號源,由于該信號源最大值為3,設定信號源的位寬為16位,為防止數據溢出,信號源整體乘以2的12次冪,然后取整舍去小數位。為了方便后續轉二進制,這里需要將數據由16bit有符號轉為16bit無符號;轉換的過程為,如果data[i]小于0,直接設定data[i] = 2^16 + data[i]。然后使用“{{:0>16b}}”.format(data[i])轉換為16bit二進制,存入cos.txt。
浮點數轉換定點數并轉換二進制數據存入txt轉換代碼如下:
def float2fix_point(data, exp, gain, size):
# '''
# :param data: 信號源數據
# :param exp: 浮點數轉定點數的位寬
# :param gain: 浮點數整體乘以增益,增益為power(2,15)
# :param size: 轉換多少點數
# :return:
# '''
if size > len(data):
print("error, size > len(data)")
return
data = [int(np.floor(data[i] * np.power(2, gain) )) for i in range(size)]
fmt = '{{:0 >{}b}}'.format(exp)
n = np.power(2, exp)
for i in range(size):
if data[i] > (n //2 - 1):
print("error")
if data[i] < 0:
d = n + data[i]
else:
d = data[i]
data[i] = fmt.format(d)
# data = [bin(data[i]) for i in range(4096)]
np.savetxt('cos.txt', data, fmt='%s')
實現方法
為了方便看示例代碼,這里假定信號位寬DATA_BITS為16,系數位寬為COEF_BITS為16,擴展符號位寬EXTEND_BITS為5, 階數FIR_ORDER為72。
設計思路還是從底層開始設計,首先需要實現FIR的基本模塊。前面提到,為了節省乘法器,每個模塊輸入兩個信號和一個FIR抽頭系數,兩個參數相加,相加結果直接乘以系數,最后做符號位擴展,防止后續操作導致符號位溢出。
fir_base.v 主要代碼:
reg signed [DATA_BITS + COEF_BITS - 1:0] data_mult;
// 因為FIR系數是中心對稱的,所以直接把中心對稱的數據相加乘以系數
// 相加符號位擴展一位
wire signed [DATA_BITS:0] data_in ;
assign data_in = {data_in_A[DATA_BITS-1], data_in_A} + {data_in_B[DATA_BITS-1], data_in_B};
// 為了防止后續操作導致符號位溢出,這里擴展符號位,設計位操作知識
assign data_out = {{EXTEND_BITS{data_mult[DATA_BITS + COEF_BITS - 1]}},data_mult };
always @(posedge clk or posedge rst) begin
if (rst) begin
// reset
fir_busy <= 1'b0;
data_mult <= 0 ;
output_vld <= 1'b0;
end
else if (en) begin
//如果coef為0,不需要計算直接得0
data_mult <= coef != 0 ? data_in * coef : 0;
output_vld <= 1'b1;
end
else begin
data_mult <= 'd0;
output_vld <= 1'b0;
end
end
完成了基本模塊后,頂層模塊就是調用基本模塊,然后對運算結果進行相加操作。但這里需要注意,頂層首先需要73個16bit的寄存器,用來保存傳入的信號并實現每時鐘周期上升沿,73個數據整體前移;學過數據結構的同學可以把這個想象成隊列結構,每次信號上升沿時,隊首信號出隊,隊尾補進新的信號。

實現方法如下:
// FIR輸入數據暫存寄存器組
reg signed [DATA_BITS-1:0] data_tmp [FIR_ORDER:0] ;
always @(posedge clk or posedge rst) begin
if (rst) begin
// reset
data_tmp[0] <= 0;
end
else if (data_in_vld) begin
data_tmp[0] <= data_in;
end
end
generate
genvar j;
for (j = 1; j <= FIR_ORDER; j = j + 1)
begin: fir_base
//這里無法兼顧0,FIR_HALF_ORDER
always @(posedge clk or posedge rst) begin
if (rst) begin
// reset
data_tmp[j] <= 0;
end
else if (data_in_vld) begin
data_tmp[j] <= data_tmp[j-1];
end
end
endgenerate
這里實現了從0-72共73個寄存器,使用了Verilog的類似二維數組的寄存器定義用法。可以從代碼看到,0號data_tmp過于特殊,需要保存輸入的信號,而其他data_tmp直接使用generate for語法實現前面提到的“隊列”功能。generate for語法是可以綜合的, 其中for循環的參數必須是常數 ,其作用就是直接在電路上復制循環體的內容。對于像這樣需要規律性地賦值操作很方便,下面還會出現generate for語法。
寄存器組的問題解決后,需要與FIR參數進行乘加,這里同樣適用generate for語句簡化設計:
localparam FIR_HALF_ORDER = FIR_ORDER / 2; //36
wire signed [OUT_BITS-1:0] data_out_tmp [FIR_HALF_ORDER:0] ;
// FIR輸出數據后流水線相加的中間變量,多出部分變量,防止下一級相加過程中index越界
reg signed [OUT_BITS-1:0] dat_out_reg [FIR_HALF_ORDER+4:0] ; //40-0
always @(posedge clk or posedge rst) begin
if (rst) begin
// reset
dat_out_reg[FIR_HALF_ORDER] <= 0;
end
else if (output_vld_tmp[FIR_HALF_ORDER]) begin
dat_out_reg[FIR_HALF_ORDER] <= data_out_tmp[FIR_HALF_ORDER];
end
end
fir_base
#(
.DATA_BITS(DATA_BITS),
.COEF_BITS(COEF_BITS),
.EXTEND_BITS(EXTEND_BITS)
)
fir_inst_FIR_HALF_ORDER(
.clk (clk),
.rst (rst),
.en (data_in_vld),
.data_in_A (data_tmp[FIR_HALF_ORDER]),
.data_in_B (12'd0),
.coef (get_coef(FIR_HALF_ORDER)),
.fir_busy (),
.data_out (data_out_tmp[FIR_HALF_ORDER]),
.output_vld (output_vld_tmp[FIR_HALF_ORDER])
);
generate
genvar j;
for (j = 1; j < FIR_HALF_ORDER; j = j + 1)
begin: fir_base
fir_base
#(
.DATA_BITS(DATA_BITS),
.COEF_BITS(COEF_BITS),
.EXTEND_BITS(EXTEND_BITS)
)
fir_inst_NORMAL
(
.clk (clk),
.rst (rst),
.en (data_in_vld),
.data_in_A (data_tmp[j]),
.data_in_B (data_tmp[FIR_ORDER-j]),
.coef (get_coef(j)),
.fir_busy (),
.data_out (data_out_tmp[j]),
.output_vld (output_vld_tmp[j])
);
always @(posedge clk or posedge rst) begin
if (rst) begin
// reset
dat_out_reg[j] <= 0;
end
else if (output_vld_tmp[j]) begin
dat_out_reg[j] <= data_out_tmp[j];
end
end
endgenerate
首先由于中心點(第36階)的系數是只乘中心點,并不像其他系數可以傳入關于中心對稱的兩個信號。所以FIR_HALF_ORDER需要單獨例化。同樣,dat_out_reg也需要單獨復制;其他的信號在generate for循環體完成操作,由于0號系數在階數為偶數的情況下為0,這里跳過0號系數直接從1號系數開始,所以for循環是從1 - FIR_HALF_ORDER。
加權結果出來后,需要對結果相加,為了提升系統運行速率,這里采用三級流水線操作。每次進行4位數據相加傳遞給下一級流水線,所以示例代碼里FIR最高階數為4 * 4 * 4 * 2 = 128。
流水線操作過程如下:
// 流水線第一級相加,計算公式ceil(N/4)
localparam FIR_ADD_ORDER_ONE = (FIR_HALF_ORDER + 3) / 4; //
// 流水線第二級相加,計算公式ceil(N/4)
localparam FIR_ADD_ORDER_TWO = (FIR_ADD_ORDER_ONE + 3) / 4; //3
reg signed [OUT_BITS-1:0] dat_out_A [FIR_ADD_ORDER_ONE+3:0] ; //12-0
reg signed [OUT_BITS-1:0] dat_out_B [FIR_ADD_ORDER_TWO+3:0] ; //6-0
// 這些多余的reg直接設為0就可以了
always @ (posedge clk) begin
dat_out_reg[FIR_HALF_ORDER+1] = 0;
dat_out_reg[FIR_HALF_ORDER+2] = 0;
dat_out_reg[FIR_HALF_ORDER+3] = 0;
dat_out_reg[FIR_HALF_ORDER+4] = 0;
dat_out_A[FIR_ADD_ORDER_ONE] = 0;
dat_out_A[FIR_ADD_ORDER_ONE+1] = 0;
dat_out_A[FIR_ADD_ORDER_ONE+2] = 0;
dat_out_A[FIR_ADD_ORDER_ONE+3] = 0;
dat_out_B[FIR_ADD_ORDER_TWO] = 0;
dat_out_B[FIR_ADD_ORDER_TWO + 1] = 0;
dat_out_B[FIR_ADD_ORDER_TWO + 2] = 0;
dat_out_B[FIR_ADD_ORDER_TWO + 3] = 0;
end
// 判定所有FIR_BASE模塊完成轉換
assign data_out_vld = (&output_vld_tmp[FIR_HALF_ORDER:1] == 1'b1) ? 1'b1 : 1'b0;
//最后一級流水線
always @(posedge clk or posedge rst) begin
if (rst) begin
// reset
data_out <= 0;
end
else if (data_out_vld) begin
data_out <= dat_out_B[0] + dat_out_B[1] + dat_out_B[2] + dat_out_B[3];
end
end
generate
genvar j;
for (j = 1; j < FIR_HALF_ORDER; j = j + 1)
if (j <= FIR_ADD_ORDER_ONE)
begin
//流水線相加 第一級
//注意j 的范圍是[1,FIR_HALF_ORDER]
//所以dat_out_A[j-1]
always @(posedge clk or posedge rst) begin
if (rst) begin
// reset
dat_out_A[j-1] <= 0;
end
else begin
dat_out_A[j-1] <= dat_out_reg[4*j-3] + dat_out_reg[4*j-2] + dat_out_reg[4*j-1] + dat_out_reg[4*j];
end
end
end
if (j <= FIR_ADD_ORDER_TWO)
begin
// 流水線相加 第二級
always @(posedge clk or posedge rst) begin
if (rst) begin
// reset
dat_out_B[j-1] <= 0;
end
else begin
dat_out_B[j-1] <= dat_out_A[4*j - 4] + dat_out_A[4*j- 3] + dat_out_A[4*j - 2] + dat_out_A[4*j - 1];
end
end
end
end
endgenerate