 直播精彩回顧(三)| 虹科Torch——數據管理的可觀察性解決方案
直播精彩回顧(三)| 虹科Torch——數據管理的可觀察性解決方案
3月8日,【虹科云課堂】數據管理與可視化解決方案前3期免費直播課程已結束,感謝大家的觀看與支持。虹小科為大家整理了課后筆記,請查收
導語
虹科云課堂
虹科的數據可觀察性解決方案,它是一個由三部分產品組成的集成套件,作為一個中立的多平臺數據可觀察性解決方案,我們的方案可以使數據運營團隊能夠從單個控制臺有效地管理其整個數據基礎架構,最大限度地提高數據工程團隊的生產力,以及數據模型和分析應用程序的性能和正常運行時間。其機器學習功能可幫助企業預測和預防其數據管道的潛在問題,最大限度地減少停機時間并使其能夠滿足其 SLA/SLO。Torch是一款用在數據層的可觀察性解決方案,通過數據管道觀察數據流,優化數據的可靠性、質量和使用。它使用先進的機器學習和人工智能來確保企業數據系統的數據質量和可靠性,同時可以進行數據發現和數據優化。
那么它是如何幫助企業保證數據可靠性呢?我們先不說答案,把文章看完,你就明白了,最后我們會總結這個問題的答案。
本文圍繞3部分展開
虹科云課堂
1、Torch產品介紹
2、Torch介紹功能詳解
(數據可觀察性相關概念可見3月1、8日直播)
01
Torch產品介紹
虹科云課堂
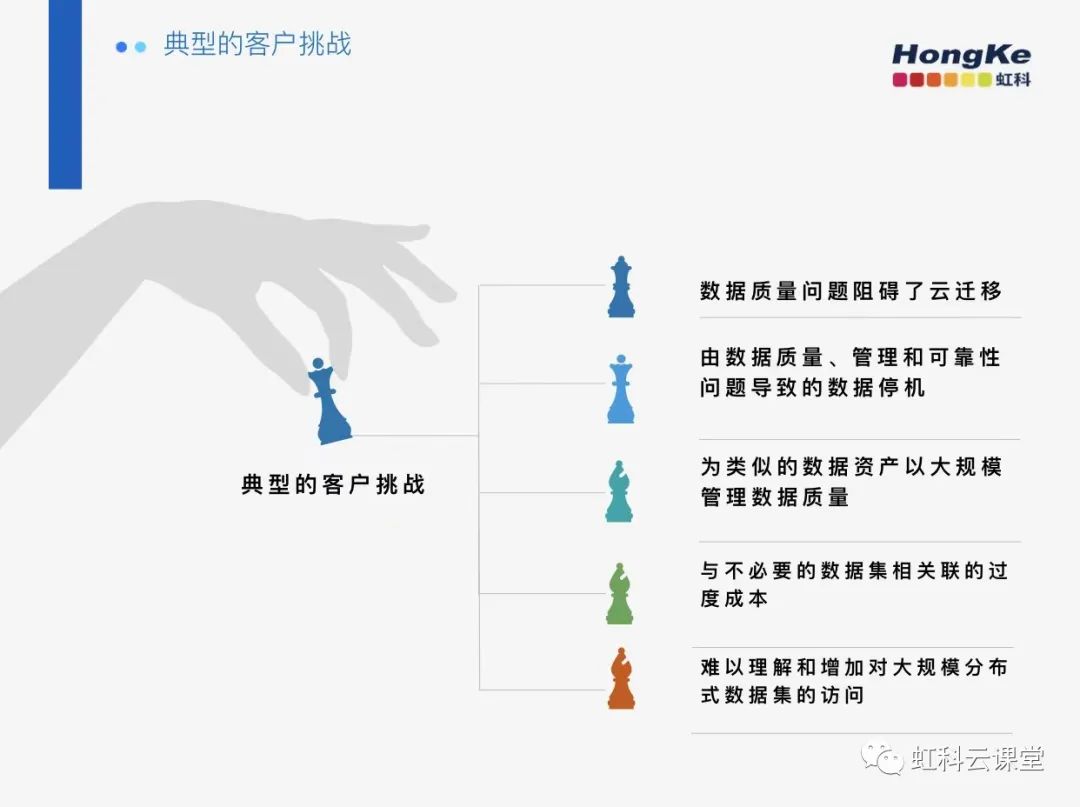
這里有寫幾個典型的企業會遇到的問題,第一個就是數據質量問題阻礙了云遷移,當數據從一種技術或環境遷移到另一種技術或環境時,數據的許多方面可能會“在轉換中丟失”。例如,將數據從數據倉庫移動到數據湖一方面可以提供靈活性,但另一方面缺乏控制。
第二個是由數據質量、管理和可靠性問題導致的數據停機,數據停機會導致客戶的體驗感不佳,時間成本投入較高等等,同時也會讓數據團隊將時間花在解決、調試和修復數據問題上,而不是在其他可以為您的客戶增加實質性價值的優先事項上取得進展。
第三個是對類似的數據資產進行大規模的數據質量管理,假如一個組織中平均有 9 個數據集副本。那么手動檢查和重新創建每個數據質量是沒有意義的。我們幫助您識別相似的數據資產,并且還支持規則重用,允許您將現有規則“復制/粘貼”到其他數據集。這消除管理數據質量方面的重復工作。
第四個是與不必要的數據集相關聯的過度成本,數據系統會接收和存儲海量的數據,這些數據中可能會有重復的、不必要的數據,如果沒有工具或平臺去幫助數據系統識別和處理多余的、不必要的數據集,那么就會導致企業在存儲、計算、維護等方面花費大量的資金。
最后一個是難以理解和增加對大規模分布式數據集的訪問,分布式存儲系統有很多個數據節點,每個節點都存儲著這個巨大的數據集的一部分,隨著數據量和用戶量的增多,數據的存取結構復雜,程序訪問(讀取)這個數據集會特別慢,系統響應延遲較高,可用性較低。
可見這些問題都與數據質量脫不了干系,面對這些數據挑戰,我們推薦虹科的Torch解決這些問題
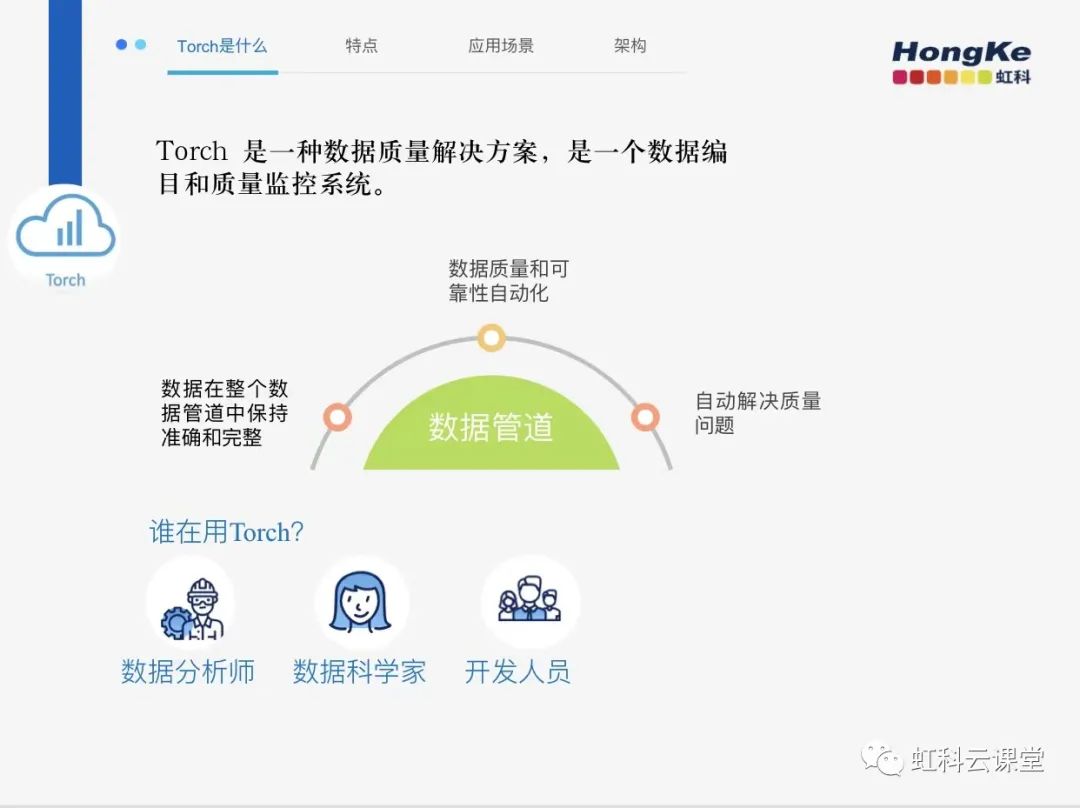
Torch 是一種數據質量解決方案,是一個數據編目和質量監控系統,它可以確保數據在整個數據管道中保持準確和完整,包括為數據團隊解決問題并在可能的情況下自動解決質量問題。
高質量的數據對于做出良好的商業決策至關重要。如果數據質量較低或可疑,企業就無法完整、準確地了解其組織,并且有可能投資不足、錯過收入機會或損害其運營。然而,在現代數據管道中,數據是不斷運動的。當數據通過管道從源流向目標時,它會經歷幾個不同的階段。集成階段將多個數據源合并在一起。轉換階段是數據清理和驗證的階段。在一些簡單的處理階段,數據被匯總、聚合和過濾。最后,還有更復雜的處理階段類型,使用機器學習,比如預測建模。在這些階段中的任何一個階段,流程都可能會失敗或減慢,從而阻止數據到達其預期目的地,并給業務帯來潛在風險。因此,高質量的數據并不一定能保證數據的可靠性。那我們的這個產品Torch就是為了幫助企業擁有高質量數據的可靠交付、實時處理和大規模的端到端管道。
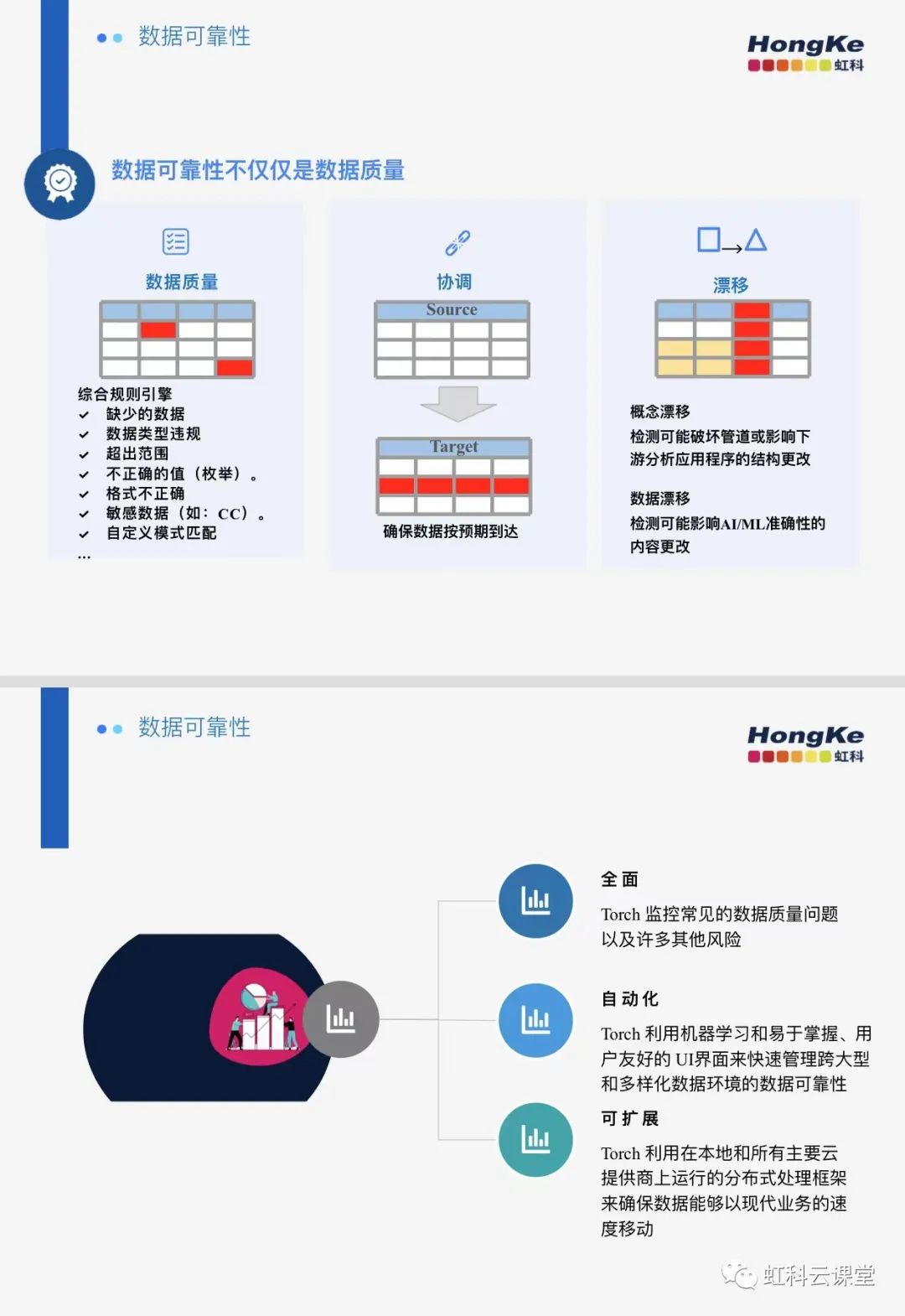
Torch提供可擴展、連續的數據質量監控,它能夠根據用戶定義的數據質量策略來監控數據資產。自動化的數據質量規則和警報可以更輕松地識別缺失數據、數據類型違規、不正確的值和格式、敏感數據等。
Torch利用核對策略來確保數據按預期到達。對于每個核對策略,數據工程師命名數據源和目的地,要執行的比較類型,以及要檢查的比較,在儀表盤中顯示結果,如有不匹配的情況則會向管理員發送警報,以便迅速采取行動。
并且它提供數據和模式漂移監測,以保護管道和AI/ML模型的準確性。過監控意外內容更改來提高 AI/ML 工作負載的準確性。數據漂移規則根據關鍵指標的容差閾值自動驗證更改。收到有關過度數據漂移的通知。檢測可能破壞管道或影響下游應用程序的模式和表的結構更改。了解何時添加、修改和刪除列。
然后它是通過機器學習自適應企業數據環境,用戶可以添加標簽,按目的、所有者或業務功能和評級對數據資產進行分類、聚類、關聯和自動標記,以改進數據發現和管理
通過機器學習建立專業知識,利用基于人工智能的建議和自動警報做出快速反應,預測數據質量問題,數據團隊可以應用這些建議快速解決常見問題。這些基于人工智能的建議可以提高生產力、準確性和覆蓋率
那么是誰會用Torch呢?包括分析師、數據科學家和開發人員在內的所有用戶都可以依靠 Torch 來觀察數據在倉庫或數據湖中的流動情況,并可以放心,不會丟失數據。

接下來我們看一下它的特點:首先它可以從任何數據源或湖中抓取數據,Torch 使用爬蟲來獲取元數據并將其存儲在數據源中,并且根據數據源的不同,對元數據進行自動分類,同時確保可以輕松搜索元數據。在 Torch中,每次數據源被云或大數據爬蟲抓取時,都會執行模式漂移策略。在數據抓取過程中,根據源的類型, Torch收集不同類型的元數據。例如,為數據庫和數據倉庫收集的元數據可能包括模式、表、列和視圖,而查詢服務的元數據可能包括數據集、視圖和查詢域。Torch收集關于數據源的元數據,并顯對模式的改變。當變化出乎意料時,一個數據工程師可以深入了解模式的變化,然后去響應問題、解決問題。
第二個是它能快速與企業數據源集成,Torch連接到任何流行的數據源,無論是在云中還是在本地。它能實時發現和驗證所有數據源中的數百萬行數據,
我們知道一些數據團隊依賴手動 ETL 驗證腳本,ETL 驗證腳本旨在以有限的批次處理穩定的靜態數據。他們無法處理來自復雜數據管道、跨云、混合和彈性系統架構的連續數據流。隨著越來越多的企業走向數字化轉型,他們越來越需要分析傳入的實時數據流,但使用手動 ETL 驗證腳本會導致時間滯后,可能會導致失去商機。將 Torch之類的數據可觀察性平臺與 Kafka 一起使用,可以讓您更好地控制數據管道。使用 Torch 進行 Kafka 流式傳輸可讓你分析存儲在 Kafka 集群中的數據并監控實時數據流的分布。事件是管道中任何出現的流或消息。使用 Torch,您可以監控 Kafka 生態系統中的內部事件,以獲得更快的吞吐量和更好的穩定性。無需依賴 ETL 驗證腳本來清理和驗證傳入數據,Torch 自動實時標記不完整、不正確和不準確的數據,而無需任何手動干預。
最后它可以添加策略和業務規則以改進組織運作的方式,它可以根據用戶定義的策略監控數據,以識別數據和模式錯誤。它還監測數據管道本身的可靠性,并顯示每個組件有關的信息。在 Torch中,每次對資產進行剖析時都會執行數據漂移策略。在數據剖析過程中, Torch收集了有關數據結構如何、各部分如何相互關聯以及個別記錄中的錯誤的信息。Torch還跟蹤每一個被執行的剖析。通過比較針對同一數據資產運行的兩個配置文件之間的差異,數據工程師可以確定數據漂移錯誤首次出現的時間。

接下來看一下pulse的應用場景:
第一個是屬于電信、金融服務、能源、物聯網、電子商務行業和任何依賴大量靜止數據和動態數據以滿足運營和分析需求的企業。
例如,假設您經營一個電子商務商店,其中包含多個數據源(銷售交易、庫存數量、用戶分析),這些數據源整合到一個數據倉庫中。銷售部門需要銷售交易數據來生成財務報告。營銷部門依靠用戶分析數據來有效地開展營銷活動。數據科學家依靠數據為產品推薦引擎訓練和部署機器學習模型。如果其中一個數據源不同步或不正確,則可能會損害業務的不同方面。
數字業務依賴于流暢且響應迅速的技術。網站或應用程序的緩慢響應可能會直接導致客戶流失。網站或數據系統的中斷可能會導致銷售損失和延誤,從而影響您的聲譽。
第二個就是依賴大量靜止數據和動態數據來滿足運營和分析需求的公司,第三個就是擁有 Amazon EMR, Amazon Glue, Amazon Redshift, Apache HBase, Azure SQL 等等這些產品的公司。
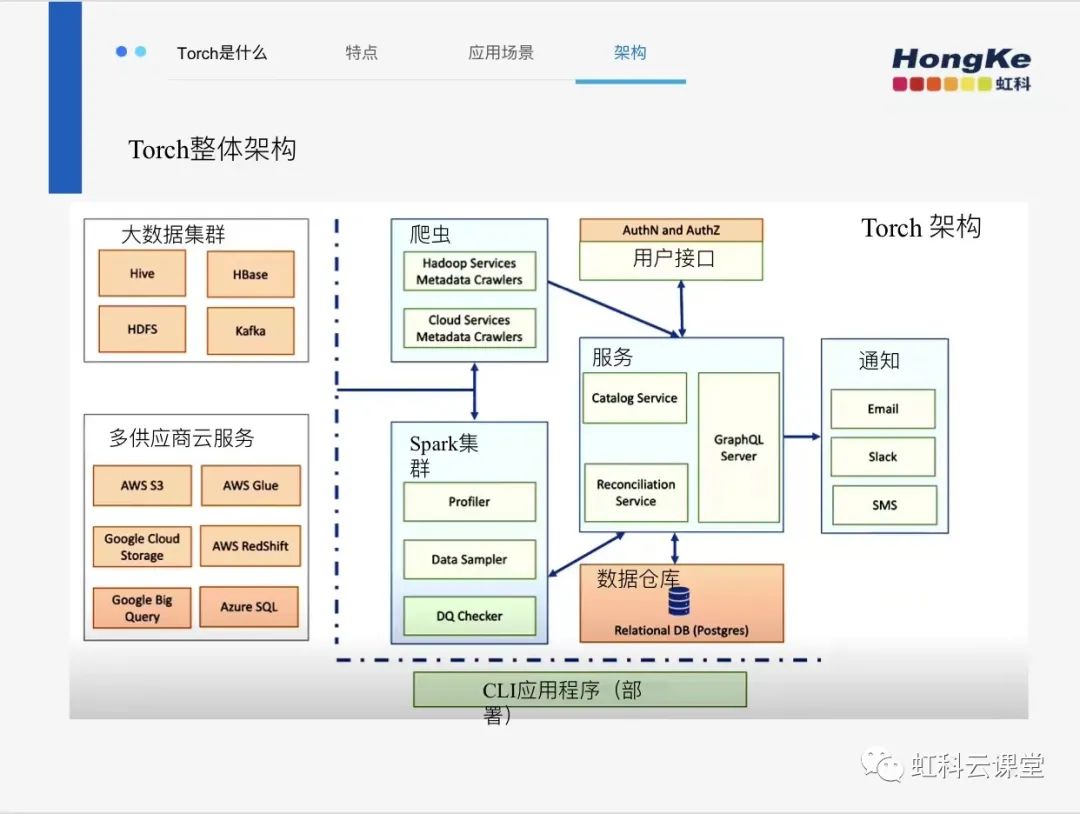
看一下Torch的架構,Torch將強大的數據質量管理平臺與功能豐富的資產目錄、分析器、業務詞匯表等結合在一起。Torch 從底層數據源讀取和處理原始數據以及元信息,以收集各種指標并驗證系統內定義的數據質量策略。Torch 被設計為一系列微服務,它們協同工作以協調各種業務成果。此外,它使用 Apache spark 來運行卸載數據處理需求的作業。
首先建立數據源鏈接,然后由爬蟲遍歷數據源并提取元數據,再將元數據信息發送到目錄服務器,通過其余的表示狀態傳輸調用目錄服務器正確索引它們,并將它們存儲在數據庫中,然后,您可以設置執行以下操作的規則:分析數據。驗證數據源中的數據。使用 ETL(提取、轉換和加載)工具協調從另一個源系統加載到數據源的數據。用戶界面用于查看元數據并檢索有關其數據源中數據的有用信息,質量規則可以設置自動運行或在執行規則時的計劃 ,它會創建系統執行。執行結果決定了該時間段內該規則是通過還是失敗,這將顯示在用戶界面中,你將通過電子郵件或slack收到通知。
Torch功能詳解
虹科云課堂
02
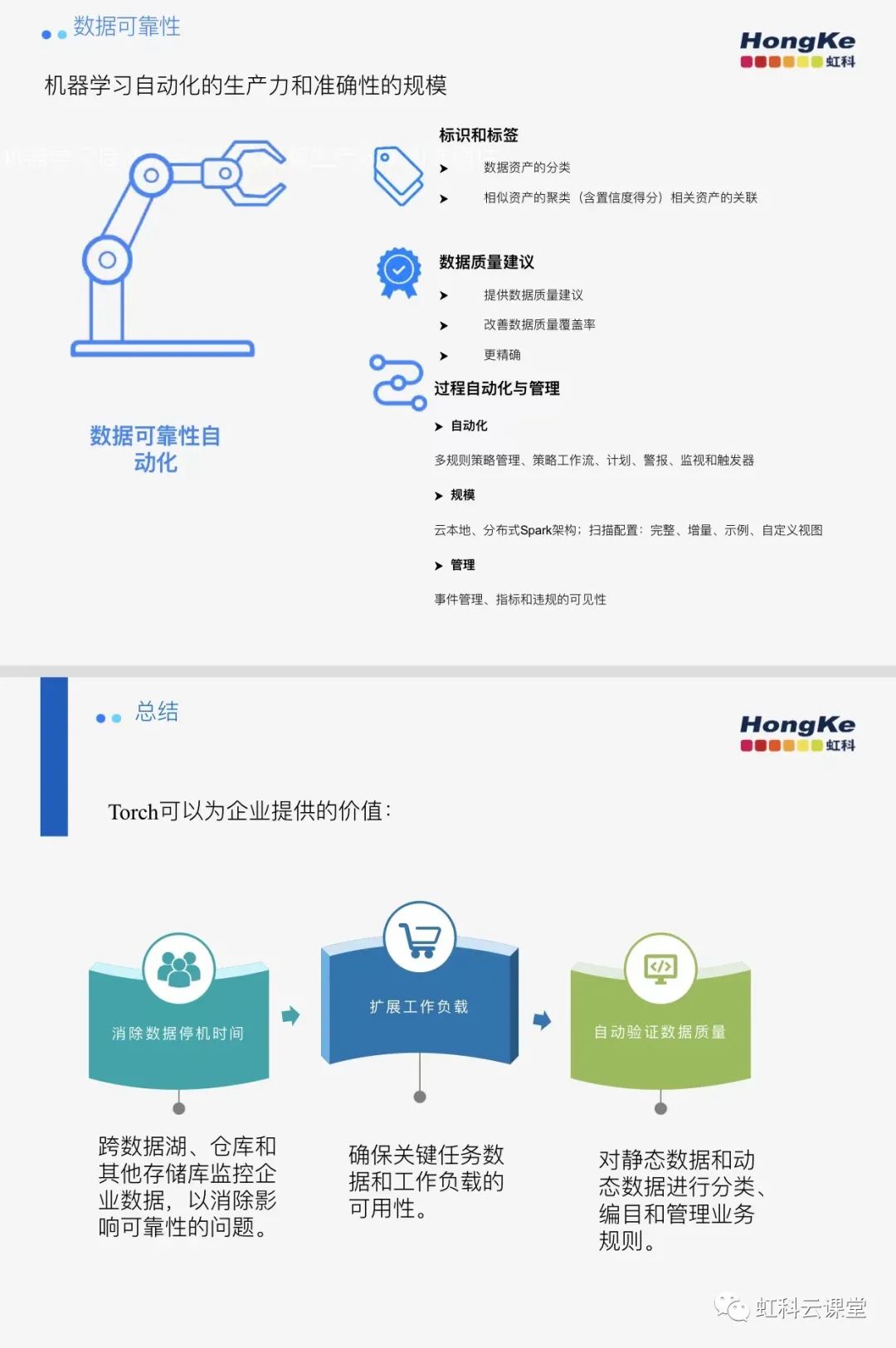
總結一下:我們的自動化機器學習會自動對您的數據資產進行分類,甚至理解大量的非結構化數據集,包括敏感、相似和相關的數據資產,并在幾分鐘內進行自動分析、協調和分類。將相似的資產聚集在一起,并為相關資產賦予相同的標簽。我們還會自動掃描您的數據資產以了解數據質量,并提供準確的一鍵式建議來解決多達 80% 的問題。進行檢測模式和數據漂移:提高動態數據處理,維護ML和AI的準確性。它能夠增加數據消耗:發現數據、探索數據配置文件,并通過儀表板的自助服務快速訪問元數據。您的數據工程師可以圍繞自動掃描和觸發器設置多策略規則和計劃,并配置規則以掃描您的整個數據基礎架構,無論是分布式和異構的。這可確保數據可靠,并為 AI、ML 和其他分析應用程序提供準確的結果。這使您的數據工程師能夠專注于為業務服務的工作,而不是日常故障排除。
Torch保證數據可靠性的三個點:
全面:Torch 監控常見的數據質量問題以及許多其他風險,包括:協調動態數據、模式漂移以及數據趨勢和異常,以提供全面的數據可靠性
自動化:Torch 利用機器學習和易于掌握、用戶友好的 UI界面來快速管理跨大型和多樣化數據環境的數據可靠性
可擴展:Torch 利用在本地和所有主要云提供商上運行的分布式處理框架來確保數據能夠以現代業務的速度移動。
03
Torch保證企業數據可靠性的原因
虹科云課堂
第一個它能消除數據停機時間,超越數據監控,通過整個數據管道,確保跨算法、模型、特性和源的數據可靠性和質量。跨數據湖、倉庫和其他存儲庫監控企業數據,以消除影響可靠性的問題。然后它能擴展工作負載,確保關鍵任務數據和工作負載的可用性。最后一個是它能自動驗證數據質量,對靜態數據和動態數據進行分類、編目和管理業務規則。
其他精彩課程
虹科云課堂
1
什么是數據可觀察性?
2
虹科Pulse——數據處理的可觀察性解決方案
云科技事業部
虹科電子
虹科在工業、制造業領域深耕了長達20年,隨著云技術的全面發展和數字化工廠的逐步落地,虹科參與了越來越多的云主題的業務,從最初的所有數據先統一采集上云,到后續的邊緣計算再上云,到現在的全面業務優化、洞察研究、成本優化等,虹科的云科技事業部已經為行業的用戶實操并積累了豐富的解決方案和應用場景。它們包括:資源監控、安全保障、多云的互聯互通、應用和數據牽引等。虹科云科技團隊在不斷順應國家策略,從技術創新、標準制定、豐富生態、安全保障、節能減排等五個方面,不斷創造出更好的產品,幫助工業制造業的用戶實現數字化轉型、實現基于數據的降本增效。
虹科云科技工程師團隊不斷參與美國和歐洲產業內先進的專家培訓,學習和實踐創新的技術手段、操作性強的應用案例,并不斷引入到國內的項目中完成落地和推廣,這讓我們團隊充滿了自豪感與使命感,賦予了我們當今時代極大的技術價值、工作成就感。
-
數據管理
+關注
關注
1文章
290瀏覽量
19609
發布評論請先 登錄
相關推薦
PDM產品數據管理系統的必要性分析 PDM如何助力企業提升競爭力
技術資訊 I 設計數據管理要點

虹科應用 為什么虹科PCAN方案能成為石油工程通訊的首選?

實驗室數據管理與LIMS平臺的關系
虹科直播 | 超哥來了!看汽修專家如何拿捏高速抖動難題!

SOLIDWORKS 2025:更有效的協作和數據管理
虹科方案 領航智能交通革新:虹科PEAK智行定位車控系統Demo版亮相

虹科應用 當CANoe不是唯一選擇:發現虹科PCAN-Explorer 6
虹科直播 | 令你耳目一“新”的新能源車診斷分享
虹科案例|為什么PCAN MicroMod FD是數模信號轉換的首選方案?

虹科方案 | 符合醫藥行業規范的液氮罐運輸和存儲溫度監測解決方案

虹科智能互聯:您的智能通訊解決方案合作伙伴

虹科智能互聯:您的智能通訊解決方案合作伙伴






 工商網監
工商網監
評論