") 支持億級(jí)標(biāo)簽接入,縱行科技在廣域物聯(lián)網(wǎng)云平臺(tái)架構(gòu)的探索與實(shí)踐
支持億級(jí)標(biāo)簽接入,縱行科技在廣域物聯(lián)網(wǎng)云平臺(tái)架構(gòu)的探索與實(shí)踐

—— 作者 | 縱行科技平臺(tái)開發(fā)團(tuán)隊(duì) ——
業(yè)務(wù)背景:自縱行科技在2020年推出ZETag云標(biāo)簽以來(lái)廣受市場(chǎng)好評(píng),目前已經(jīng)在物流、資產(chǎn)管理、庫(kù)存盤點(diǎn)等領(lǐng)域有了許多落地項(xiàng)目。在業(yè)務(wù)量急速增加的過程中,ZETag云平臺(tái)作為解決方案中重要的一環(huán),也面臨了許多挑戰(zhàn)與考驗(yàn)。本文分享了在建設(shè)ZETag云平臺(tái)過程中,我們?cè)诩軜?gòu)設(shè)計(jì)方面的一些思路與實(shí)踐。
面臨的挑戰(zhàn)
1)設(shè)備量與數(shù)據(jù)量的快速增加
不同于傳統(tǒng)的物聯(lián)網(wǎng)終端,低成本ZETag云標(biāo)簽更多用于物的定位與追蹤,同時(shí),還有次拋等新的應(yīng)用場(chǎng)景。因此,ZETag云標(biāo)簽的數(shù)量遠(yuǎn)遠(yuǎn)大于傳統(tǒng)的物聯(lián)網(wǎng)終端,萬(wàn)級(jí)別標(biāo)簽每客戶將是業(yè)務(wù)常態(tài),可以預(yù)估ZETag云平臺(tái)需要管理的標(biāo)簽量將在百萬(wàn)到千萬(wàn)級(jí),每天需要保存的上報(bào)數(shù)據(jù)將達(dá)到億級(jí),這對(duì)平臺(tái)數(shù)據(jù)存儲(chǔ)的寫性能、擴(kuò)展性以及存儲(chǔ)成本將是一個(gè)巨大的考驗(yàn)。
2)如何在保留云上擴(kuò)展性的同時(shí),降低私有化部署的成本
物聯(lián)網(wǎng)行業(yè)是一個(gè)典型的B2B行業(yè),私有化部署是很多對(duì)數(shù)據(jù)私密性較高要求的客戶的強(qiáng)需求,一個(gè)復(fù)雜的大數(shù)據(jù)平臺(tái)架構(gòu)也許能夠滿足我們對(duì)性能、擴(kuò)展性的需求,但是卻同樣有非常高的運(yùn)維成本與設(shè)備成本,對(duì)于大部分成本敏感的中小長(zhǎng)尾客戶來(lái)說,較高的實(shí)施運(yùn)維成本是難以承受的,因此在離線部署私有云的場(chǎng)景,除了性能之外,整體架構(gòu)的輕量化也是一個(gè)重要的考量因素。
3)如何支持實(shí)時(shí)靈活的多維分析,挖掘數(shù)據(jù)價(jià)值
ZETag云標(biāo)簽業(yè)務(wù)大多涉及指標(biāo)告警、實(shí)時(shí)追蹤、多維分析報(bào)表等,端到端的延遲需要控制在秒級(jí)別,同時(shí)也需要滿足客戶不同條件、維度、指標(biāo)的實(shí)時(shí)統(tǒng)計(jì)與分析,因此對(duì)于數(shù)據(jù)的查詢延遲、靈活性都有比較高的要求。
技術(shù)選型
綜合來(lái)看,查的快、寫的快、成本低是我們?nèi)齻€(gè)比較核心的訴求。我們調(diào)研了業(yè)內(nèi)常見的開源分布式OLAP數(shù)據(jù)庫(kù),最終確定了 ClickHouse+MySQL 混合存儲(chǔ)的方式作為ZETag云平臺(tái)最終存儲(chǔ)方案。
其中,ClickHouse用于存儲(chǔ)網(wǎng)關(guān)、終端、標(biāo)簽的事件數(shù)據(jù),例如心跳、注冊(cè)等。同時(shí),MySQL專注存儲(chǔ)設(shè)備的物模型數(shù)據(jù),通過兩者的協(xié)同配合來(lái)更好的支撐平臺(tái)的業(yè)務(wù)目標(biāo),其中ClickHouse的一些獨(dú)特的特性是我們選擇它的主要原因。
- 1.相比其他時(shí)序數(shù)據(jù)庫(kù),例如ElasticSearch、HBase等,ClickHouse的LSM-Tree實(shí)現(xiàn)機(jī)制更為極致,擁有更強(qiáng)大的寫性能,這意味著可以用更少的成本支撐更大的數(shù)據(jù)量。
- 2.ClickHouse支持 Apache 2.0 license開源協(xié)議,相比ElasticSearch協(xié)議更加友好,同時(shí)也不像InfluxDB,開源版本有功能上的限制。
- 3.ClickHouse的架構(gòu)非常的輕量,相比其他數(shù)據(jù)庫(kù)產(chǎn)品,例如OpenTSDB依賴Hbase、Druid.io依賴HDFS,ClickHouse單機(jī)版本完全可以不依賴第三方組件,并且只有一個(gè)服務(wù)進(jìn)程,有著非常低的離線部署運(yùn)維成本。
- 4.由于ClickHouse的MPP架構(gòu)及優(yōu)秀的工程實(shí)現(xiàn),查詢性能在各大基準(zhǔn)測(cè)試榜中名列前茅。
特性分析
- 存儲(chǔ)結(jié)構(gòu)
LSM-Tree是業(yè)內(nèi)存儲(chǔ)時(shí)序數(shù)據(jù)的常用數(shù)據(jù)結(jié)構(gòu),它的核心思路其實(shí)非常簡(jiǎn)單,每次有數(shù)據(jù)寫入時(shí)并不將數(shù)據(jù)實(shí)時(shí)寫入到磁盤,而是先緩存在內(nèi)存的memTable中并使用歸并排序的方式將內(nèi)存中的數(shù)據(jù)合并,等到積累到一定閾值之后,再追加到磁盤中,并按照一定的頻率與觸發(fā)閾值將磁盤存儲(chǔ)的數(shù)據(jù)文件進(jìn)行合并。這種方案利用了硬盤順序?qū)懶阅苓h(yuǎn)大于隨機(jī)寫的特性,降低了硬盤的尋道時(shí)間,對(duì)于物聯(lián)網(wǎng)設(shè)備所產(chǎn)生時(shí)序數(shù)據(jù)這種寫遠(yuǎn)大于讀的場(chǎng)景來(lái)說有非常好的優(yōu)化效果。
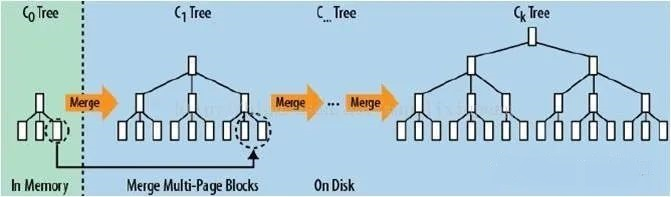
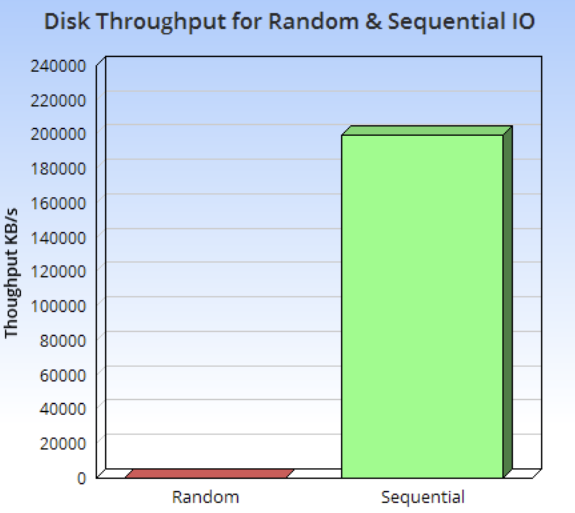
由下圖可以看到,硬盤的順序IO性能與隨機(jī)IO性能有著巨大的差距。
傳統(tǒng)的LSM-Tree雖在寫性能上很優(yōu)秀,但隨之帶來(lái)的讀放大與寫放大依然是業(yè)內(nèi)難以解決的問題,目前最優(yōu)秀的LSM-Tree結(jié)構(gòu)數(shù)據(jù)庫(kù)讀寫放大倍數(shù)也在20倍以上,讀寫放大主要來(lái)自于幾個(gè)方面:
- 1.由于數(shù)據(jù)需要buffer在內(nèi)存之中,為了保證瞬時(shí)停機(jī)例如斷電時(shí)數(shù)據(jù)不丟失,因此所有內(nèi)存里的數(shù)據(jù)都需要記錄一份WAL(Write Ahead Log),用于在極端時(shí)刻進(jìn)行數(shù)據(jù)恢復(fù)。
- 2.后臺(tái)進(jìn)行數(shù)據(jù)文件合并時(shí)是一個(gè)先讀取再寫入的過程,這個(gè)行為同樣會(huì)造成寫放大。
- 3.當(dāng)數(shù)據(jù)庫(kù)發(fā)生數(shù)據(jù)查詢操作時(shí),由于LSM-Tree寫數(shù)據(jù)的方式會(huì)生成較多的小文件,讀請(qǐng)求往往需要跨越內(nèi)存與硬盤的多個(gè)memTable與數(shù)據(jù)文件才能獲取到正確的結(jié)果。
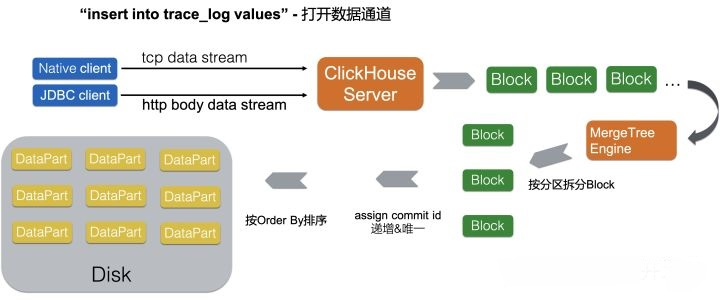
相比其他使用LSM-Tree的數(shù)據(jù)庫(kù),ClickHouse在設(shè)計(jì)上直接取消了memTable的內(nèi)存聚合階段,只對(duì)同一寫入批次的數(shù)據(jù)做排序并直接落盤。因此,完全不需要傳統(tǒng)的寫WAL的過程,減少了數(shù)據(jù)的重復(fù)寫入。同時(shí),ClickHouse也限制了數(shù)據(jù)的實(shí)時(shí)修改,這樣就減少了合并時(shí)產(chǎn)生的讀寫放大,這個(gè)思路相當(dāng)于限縮了數(shù)據(jù)庫(kù)的使用場(chǎng)景,但卻換取了更強(qiáng)大的讀寫性能。對(duì)于物聯(lián)網(wǎng)設(shè)備產(chǎn)生的數(shù)據(jù)來(lái)說,寫入時(shí)本來(lái)就是一定間隔的批量寫入,同時(shí)極少有數(shù)據(jù)修改的場(chǎng)景,與ClickHouse的優(yōu)化方向正好一致。
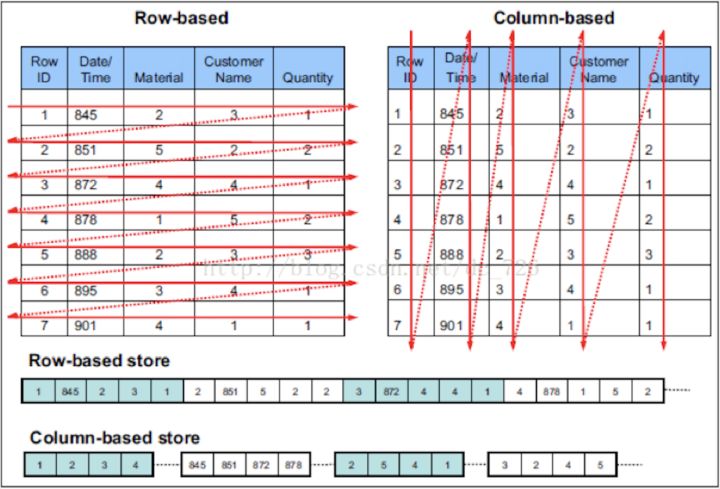
列式存儲(chǔ)帶來(lái)的極高壓縮比
相比于傳統(tǒng)的行存儲(chǔ)數(shù)據(jù)庫(kù)(例如MySQL),ClickHouse采用列式存儲(chǔ)的方式存儲(chǔ)數(shù)據(jù),
而列式存儲(chǔ),能夠帶來(lái)更極致的壓縮比。
壓縮的本質(zhì)是按照一定步長(zhǎng)對(duì)數(shù)據(jù)進(jìn)行匹配掃描,當(dāng)發(fā)現(xiàn)重復(fù)部分的時(shí)候就進(jìn)行編碼轉(zhuǎn)換。
數(shù)據(jù)中的重復(fù)項(xiàng)越多,則壓縮率越高,舉一個(gè)簡(jiǎn)單的例子:
壓縮前:12345678_2345678
壓縮后:12345678_(8,7)
上述示例中的 (8,7),表示如果從下劃線開始向前移動(dòng)8個(gè)字節(jié),并向前匹配到7個(gè)字節(jié)長(zhǎng)度的重復(fù)項(xiàng),即這里的2345678,真實(shí)的壓縮算法肯定比這個(gè)簡(jiǎn)單的例子復(fù)雜,但本質(zhì)是一樣的。顯而易見,同一個(gè)列字段的數(shù)據(jù),因?yàn)樗鼈儞碛邢嗤臄?shù)據(jù)類型和現(xiàn)實(shí)語(yǔ)義,重復(fù)項(xiàng)的可能性自然就更高,在大數(shù)據(jù)量的場(chǎng)景下,更高的壓縮比,會(huì)給我們帶來(lái)更大的性能和成本優(yōu)勢(shì)。
- 1.分析場(chǎng)景中往往有需要讀大量行但是少數(shù)列的情況。在行存模式下,數(shù)據(jù)按行連續(xù)存儲(chǔ),所有列的數(shù)據(jù)都存儲(chǔ)在一個(gè)block中,不參與計(jì)算的列在IO時(shí)也要全部讀出,讀取操作被嚴(yán)重放大。而列存模式下,只需要讀取參與計(jì)算的列即可,極大地減低了IO cost,加速了查詢。
- 2.更高的壓縮比意味著更小的文件,從磁盤中讀取相應(yīng)數(shù)據(jù)耗時(shí)更短。
- 3.高壓縮比,意味著同等大小的內(nèi)存能夠存放更多數(shù)據(jù),系統(tǒng)cache效果更好。
- 4.同樣更高的壓縮比下,相同大小的硬盤可以存儲(chǔ)更多的數(shù)據(jù),大大地降低了存儲(chǔ)成本。
極低的查詢延遲
在索引正確的情況下,ClickHouse可以說是世界上最快的OLAP分析引擎之一。這里快指的就是查詢延遲,簡(jiǎn)單說就是用戶發(fā)起一次查詢到用戶獲取到結(jié)果的時(shí)間,這種快很大的原因也來(lái)自于ClickHouse極端的設(shè)計(jì)思路與優(yōu)秀的工程實(shí)現(xiàn)。
ClickHouse的大部分計(jì)算操作,都基于CPU的SIMD指令,SIMD的全稱是Single Instruction Multiple Data,即用單條指令操作多條數(shù)據(jù),它的原理是在CPU寄存器層面實(shí)現(xiàn)數(shù)據(jù)的并行操作,例如一次for循環(huán)每次處理一條數(shù)據(jù),有8條數(shù)據(jù)則需要循環(huán)8次,但使用SIMD指令可以讓這8條數(shù)據(jù)并行處理,從而一次就得到結(jié)果,這種方式被稱為向量化計(jì)算。
ClickHouse的每一次查詢或統(tǒng)計(jì)分析操作,都會(huì)盡可能的使用所有的CPU資源來(lái)進(jìn)行并行處理,這種方式能夠讓廉價(jià)的服務(wù)器同樣擁有極低的查詢延遲,從而在海量數(shù)據(jù)的場(chǎng)景下保證平臺(tái)產(chǎn)品的流暢與快速,而快速和流暢就是最好的用戶體驗(yàn)。ClickHouse在工程實(shí)現(xiàn)上也同樣堅(jiān)持了快這個(gè)原則,可以看到在ClickHouse源碼中不斷地給函數(shù)或者算子的局部邏輯增加更多的變種實(shí)現(xiàn),以提升在特定情形下的性能,根據(jù)不同數(shù)據(jù)類型、常量和變量、基數(shù)的高低選擇不同的算法。
例如ClickHouse的hash agg,用模板實(shí)現(xiàn)了30多個(gè)版本,覆蓋了最常見的group key的類型,再比如去重計(jì)數(shù)函數(shù)uniqCombined函數(shù),當(dāng)數(shù)據(jù)量較小的時(shí)候會(huì)選擇Array保存,當(dāng)數(shù)據(jù)量中等的時(shí)候會(huì)選擇HashSet保存,當(dāng)數(shù)據(jù)量很大的時(shí)候,則使用HyperLogLog算法等等,Clickhouse的性能,就是大量類似的工程優(yōu)化堆積起來(lái)的。
那么代價(jià)是什么呢?
然而,世界上并沒有完美無(wú)缺的方案,方案設(shè)計(jì)更像是一場(chǎng)trade-off,比起了解它的優(yōu)點(diǎn),更重要的是能不能接受它的缺點(diǎn)。為了更極致的寫入性能,ClickHouse去掉memtable緩存數(shù)據(jù)再寫入的機(jī)制以及實(shí)時(shí)修改的能力,前者需要客戶端進(jìn)行額外的攢批操作,而后者限縮了數(shù)據(jù)庫(kù)的使用場(chǎng)景。
ClickHouse其實(shí)更像一個(gè)單機(jī)的數(shù)據(jù)庫(kù),極致的單表性能優(yōu)化,非常輕量的安裝部署流程,這些給我們帶來(lái)了非常低的離線部署成本,但在大規(guī)模分布式場(chǎng)景下卻有著一些缺陷。
在分布式查詢的場(chǎng)景上,ClickHouse使用Distributed Table來(lái)實(shí)現(xiàn)分布式處理,查詢Distributed Table相當(dāng)于對(duì)不同節(jié)點(diǎn)上的單機(jī)Table進(jìn)行一個(gè)UNION ALL,這種辦法對(duì)付單表查詢還可以,但涉及多表Join就有點(diǎn)力不從心了,在分布式多表Join的場(chǎng)景下,由于沒有Data shuffling之類的功能,ClickHouse需要耗費(fèi)更多的內(nèi)存和帶寬來(lái)緩存和遷移數(shù)據(jù),造成了性能的嚴(yán)重下降,大部分人不得不使用大寬表的方式來(lái)規(guī)避這個(gè)問題。
另外,運(yùn)維一個(gè)分布式ClickHouse集群也是非常頭疼的一個(gè)點(diǎn)。ClickHouse并不具備數(shù)據(jù)均衡功能,提供的Distributed Table由于寫入性能太差形同虛設(shè),往往需要通過業(yè)務(wù)層來(lái)保證分發(fā)的數(shù)據(jù)足夠均勻,開源的ClickHouse并沒有集中的元數(shù)據(jù)管理,ON CLUSTER語(yǔ)法能夠節(jié)約一定的操作,但集體擴(kuò)容以后由于新的節(jié)點(diǎn)并不會(huì)同步元數(shù)據(jù)信息,也不會(huì)自動(dòng)平衡數(shù)據(jù)的負(fù)載,因此需要大量的人工介入。作為從標(biāo)準(zhǔn)的計(jì)算存儲(chǔ)一體的Shared-nothing結(jié)構(gòu)發(fā)展而來(lái)的數(shù)據(jù)庫(kù),ClickHouse對(duì)于云原生和存算分離的支持也比較一般,目前社區(qū)正在朝這個(gè)方向努力,只能說還算是未來(lái)可期。
實(shí)踐經(jīng)驗(yàn)
- 寫入優(yōu)化
由于ClickHouse特殊的數(shù)據(jù)寫入方式,為了獲得更高的性能我們需要在寫入客戶端上進(jìn)行一定的定制化開發(fā)。在整體架構(gòu)上,我們主要使用Flink來(lái)實(shí)現(xiàn)ClickHouse數(shù)據(jù)的寫入,由于目前還沒有官方的Connector,我們基于社區(qū)接口自研了自己的ClickHouse Connector,主要實(shí)現(xiàn)了以下功能:
- 1.實(shí)現(xiàn)了基于表與分區(qū)的攢批功能,由于ClickHouse特殊的寫入策略,相同表與分區(qū)數(shù)據(jù)在同一批次進(jìn)行寫入會(huì)有更好的性能,同時(shí)也能減少寫入時(shí)生成的文件數(shù)量。
- 2.支持通過配置不同算法將數(shù)據(jù)以不同的方式分發(fā)到節(jié)點(diǎn)的shard中,實(shí)現(xiàn)了常規(guī)的Hash、輪詢、加權(quán)等等算法。
- 3.背壓感知與限流功能,通過查詢ClickHouse不同shard的文件碎片數(shù),經(jīng)限流算法評(píng)估后在必要時(shí)觸發(fā)Flink的反壓機(jī)制,防止ClickHouse客戶端報(bào)錯(cuò)造成寫入性能持續(xù)下降。
- 4.支持通過接入設(shè)備數(shù)自動(dòng)化調(diào)節(jié)攢批的各種參數(shù)、包括數(shù)據(jù)量大小、條數(shù)、間隔時(shí)間等等,減少在參數(shù)配置時(shí)的工作量與門檻。
冷熱分離
時(shí)序數(shù)據(jù)的價(jià)值往往與時(shí)間相關(guān),越靠近當(dāng)前時(shí)間的熱數(shù)據(jù)越有價(jià)值,會(huì)被頻繁的使用,越久遠(yuǎn)的冷數(shù)據(jù)價(jià)值相對(duì)較低,但依然需要長(zhǎng)期的存儲(chǔ)。
因此,可以通過冷熱分離的策略將近期高價(jià)值的數(shù)據(jù)存儲(chǔ)在相對(duì)昂貴的存儲(chǔ)來(lái)提升統(tǒng)計(jì)分析的性能,并在一段時(shí)間后將數(shù)據(jù)移動(dòng)到相對(duì)便宜的大容量存儲(chǔ)中,這種方式可以在不影響用戶體驗(yàn)的情況下較好地節(jié)省數(shù)據(jù)的存儲(chǔ)成本。在ClickHouse 19.15版本之后開始原生支持冷熱分離的存儲(chǔ)策略,通過相應(yīng)配置可以按照時(shí)間或大小自動(dòng)地將數(shù)據(jù)遷移到冷盤。
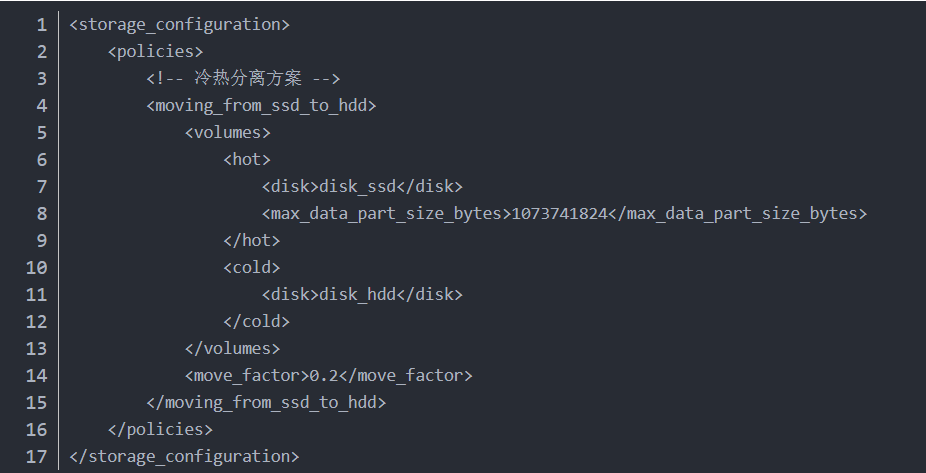
上述配置中配置了一個(gè)名為moving_from_ssd_to_hdd的存儲(chǔ)策略,該策略包含了hot和cold兩個(gè)volume。
在volumes的前后順序決定了volume的優(yōu)先級(jí),意味著part會(huì)優(yōu)先在這個(gè)卷上生成,且沒有輪詢策略。因此volumes內(nèi)的順序是敏感的。hot中含有一塊ssd類型的disk;cold中含有一塊hdd類型的disk。move_factor定義了前一個(gè)卷剩余存儲(chǔ)空間的量。當(dāng)存儲(chǔ)空間小于這個(gè)值時(shí),會(huì)將前一個(gè)volume中相對(duì)較早的part遷移到后面的volume中。上述配置表示,當(dāng)hotvolume的存儲(chǔ)空間超過80%時(shí),便將數(shù)據(jù)遷移到cold中。
- 字段擴(kuò)展場(chǎng)景
查詢中需要擴(kuò)充字段是非常常見的業(yè)務(wù)場(chǎng)景,在我們的架構(gòu)中部分字段甚至存在不同的數(shù)據(jù)庫(kù)例如MySQL中。目前,業(yè)內(nèi)的常見做法是通過流式計(jì)算引擎,例如Flink、Storm等,在入庫(kù)之前進(jìn)行數(shù)據(jù)字段的拼接,在ClickHouse中直接存儲(chǔ)計(jì)算后的數(shù)據(jù)。這種方案可以最大的保證數(shù)據(jù)的查詢效率,但需要付出額外的開發(fā)工作量以及硬件資源,特別是SQL JOIN的場(chǎng)景,需要在流式計(jì)算引擎中緩存大量實(shí)時(shí)更新的狀態(tài),有著很大的資源消耗。而我們?cè)趯?shí)踐中發(fā)現(xiàn),有些更新頻率很低的字段擴(kuò)充場(chǎng)景,例如設(shè)備型號(hào)、所屬企業(yè)等其實(shí)有更好的解決方案,
通過ClickHouse提供的Dictionaries特性能夠代替部分更新頻率較低JOIN場(chǎng)景。
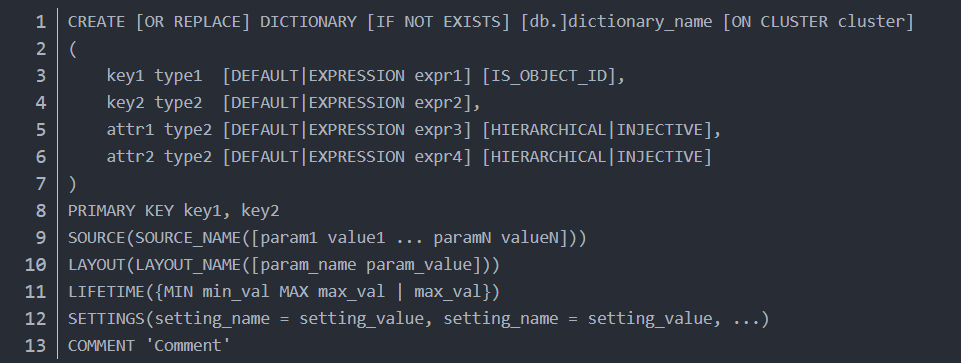
ClickHouse支持將外部數(shù)據(jù)源例如MySQL、Redis、PostgreSQL等等配置為一個(gè)內(nèi)置的字典,在查詢中可以通過函數(shù)進(jìn)行key -> attributes的轉(zhuǎn)換,變相的實(shí)現(xiàn)了類似JOIN的功能,這種方式相比于JOIN有著更好的性價(jià)比。
總結(jié)
在物聯(lián)網(wǎng)這個(gè)業(yè)務(wù)場(chǎng)景下,需要存儲(chǔ)大量的時(shí)序事件數(shù)據(jù)并且不需要事后進(jìn)行修改,剛好契合了ClickHouse的寫入性能優(yōu)勢(shì)并且規(guī)避了使用場(chǎng)景上
的劣勢(shì),同時(shí)ClickHouse部署成本低、架構(gòu)輕量化的優(yōu)勢(shì)也很符合當(dāng)前物聯(lián)網(wǎng)客戶需求。
目前,ZETag云平臺(tái)已經(jīng)對(duì)接大量的網(wǎng)關(guān)、標(biāo)簽、設(shè)備,幫助許多客戶實(shí)現(xiàn)了降本增效,這些都離不開一個(gè)高效穩(wěn)定的存儲(chǔ)計(jì)算引擎的幫助,后續(xù)我們也會(huì)持續(xù)優(yōu)化產(chǎn)品,積累優(yōu)秀實(shí)踐,打造一個(gè)更強(qiáng)大、穩(wěn)定、通用的物聯(lián)網(wǎng)云平臺(tái)。
-
物聯(lián)網(wǎng)
+關(guān)注
關(guān)注
2903文章
44284瀏覽量
371331 -
數(shù)據(jù)庫(kù)
+關(guān)注
關(guān)注
7文章
3766瀏覽量
64278 -
數(shù)據(jù)庫(kù)管理
+關(guān)注
關(guān)注
0文章
6瀏覽量
6842 -
ZETA
+關(guān)注
關(guān)注
0文章
119瀏覽量
10280
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
智能網(wǎng)聯(lián)汽車云控系統(tǒng)第1部分:系統(tǒng)組成及基礎(chǔ)平臺(tái)架構(gòu)
物聯(lián)網(wǎng)學(xué)習(xí)路線來(lái)啦!
PLC接入工業(yè)物聯(lián)網(wǎng)平臺(tái)會(huì)遇見的問題及解決方案
MQTT物聯(lián)網(wǎng)云平臺(tái)有什么功能
工業(yè)物聯(lián)網(wǎng)(IOT)云平臺(tái)是什么
天拓四方:工業(yè)物聯(lián)網(wǎng)關(guān)是什么?其在設(shè)備接入物聯(lián)網(wǎng)中的作用

物聯(lián)網(wǎng)云平臺(tái)是什么
智慧工地管理系統(tǒng)平臺(tái)架構(gòu)
MQTT物聯(lián)網(wǎng)平臺(tái)是什么?MQTT物聯(lián)網(wǎng)平臺(tái)的功能
縱行科技邀您相聚“2024全球物流技術(shù)大會(huì)”

ZWS云平臺(tái)應(yīng)用(2)-設(shè)備基于SDK接入

如何快速打造屬于自己的工業(yè)物聯(lián)網(wǎng)云平臺(tái)

PLC設(shè)備接入網(wǎng)關(guān)實(shí)現(xiàn)工廠PLC接入物聯(lián)網(wǎng)IOT云平臺(tái)

MQTT物聯(lián)網(wǎng)平臺(tái)是什么?MQTT物聯(lián)網(wǎng)平臺(tái)的功能有哪些
精彩回顧丨機(jī)智云:物聯(lián)網(wǎng)平臺(tái)選擇垂直行業(yè)的實(shí)踐與思考





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論