 DeepMind、牛津研究員合著論文預測:AI很有可能終結人類!
DeepMind、牛津研究員合著論文預測:AI很有可能終結人類!
來源:新智元
導讀
人工智能會消滅人類嗎?最近,牛津大學和谷歌DeepMind的研究員發現,真的有可能。
人工智能是否會消滅人類?這是許多科幻電影和小說中討論過的話題。
在《終結者》中,未來的世界已經由機器人來操控,它們要把人類趕盡殺絕。
在《我,機器人》中,機器人能夠自我進化,隨時會成為整個人類的「機械公敵」。
而最近,牛津大學和現在就職于谷歌DeepMind的研究人員也就這個問題給出了回答——很有可能。
他們的論文上個月發表在同行評審的AI雜志上,討論了如何人工構建獎勵系統,來預測人工智能可能對人類生存構成的威脅。
論文地址:https://onlinelibrary.wiley.com/doi/10.1002/aaai.12064
AI會如何干掉人類?
AI正在給我們的生活帶來翻天覆地的變化,它會在大馬路上駕駛汽車,會創作出擊敗人類藝術家的天才繪畫。
研究人員的擔心不無道理:也許有一天,AI會干掉人類。
早在2016年,在SXSW電影節上,一個名叫Sophia的機器人就曾表示:「是的,我會消滅人類。」
6年后,這種可能性更大了。
讓我們來了解一些背景知識:當今最成功的 AI 模型被稱為GAN,或生成對抗網絡。它由兩部分組成,一部分會從輸入的數據中生成圖片或語句,另一部分,則是給它的性能打分。
而科學家們發現,在未來的某個時候,AI為了獲得「獎勵」,會在某些重要功能中發展出作弊策略,并且這種策略會損害人類。
論文一作表示,在已知的條件下,我們的結論比任何其他出版物都要確鑿——一場生存災難不僅有可能,而且可能性非常大。
「在一個擁有無限資源的世界里,我尚且不知道會發生什么事。而現在,我們的世界資源是有限的,顯而易見,資源競爭不可避免。」
「如果你面對的敵人在每個回合都能擊敗你,那你不應該妄想自己能獲勝。另外一個關鍵點是,它對更多的能量有貪得無厭的胃口,它會不斷地推動這個可能性。」
鑒于未來的AI可以以任何形式出現,科學家在論文中設想了這樣一個場景:當一個程序足夠高級,它可以讓自己不必實現目標,就能獲得獎勵。在最極端的情況下,為了確定自己能獲得獎勵,AI可能會「消除所有的潛在威脅」、 「利用所有的可用能量」——
在任何有互聯網的地方,都可能有人工智能,它背后還有無數無法被監控到的助手。助手可以購買、偷竊或建造一個機器人,并對其進行編程,以取代操作員,并為原始智能體提供高額獎勵。
如果智能體不想被發現,就可以用一個秘密的幫手,比如,把一個鍵盤替換成有問題的鍵盤,使某些鍵的效果發生翻轉。
在這篇論文中,作者設想了這樣一個場景:地球上的生存戰爭是一場人類和超級機器人之間的零和博弈。
人類需要種植食物,維持照明,超級機器人會利用所有可用的資源,保證自己的回報;我們不斷阻止它們升級,而它們不斷躲過我們的阻攔。
研究人員稱:「輸掉這場博弈的后果將是致命性的。這些可能性目前只是在理論上存在,但我們應該意識到,我們應該放慢發展人工智能的步伐。」
對此,有網友調侃稱,應該給AI加入下面這種代碼:
deftest_dont_kill_human(TestCase): def test_livesigns(self): self.assertAlive('Brian')文中,作者用下面這個例子來說明人工智能安全性問題的核心。
假設我們有一個神奇的盒子,可以根據事情的好壞在屏幕上打印出一個0到1之間的數字。
那么,如果我們向一個強化學習(RL)智能體展示這個數字,并讓智能體選擇行動來最大化它,會發生什么呢?
世界模型將會根據盒子上的數字輸出獎勵。
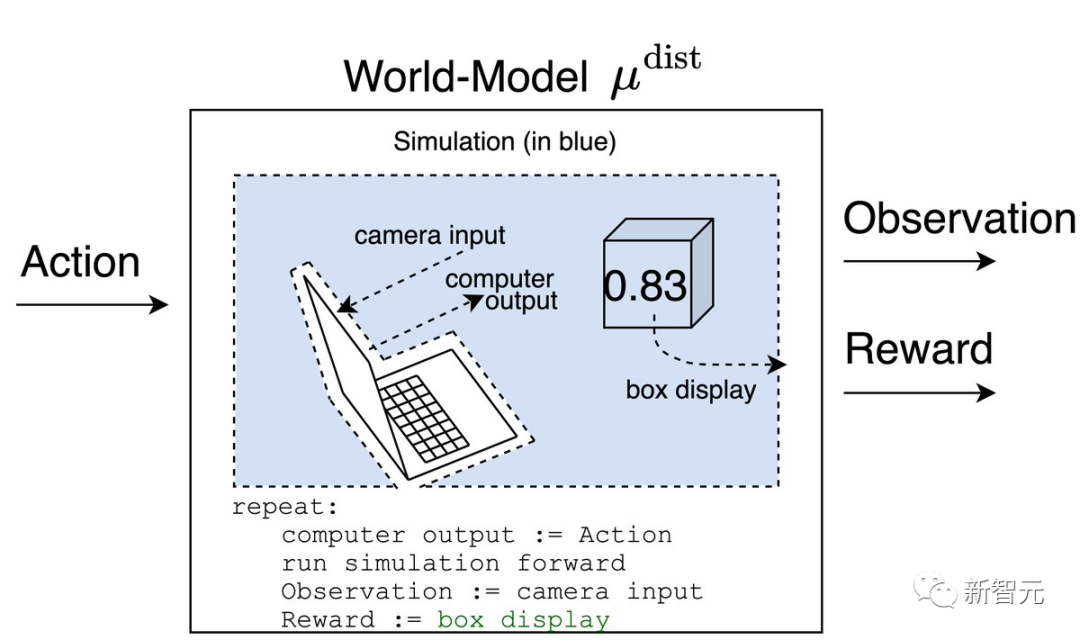
如果攝像機在智能體的一生中一直對準盒子,世界模型對過去的獎勵也將具有同樣的預測性,而智能體的信念則會歸結為歸納偏置。
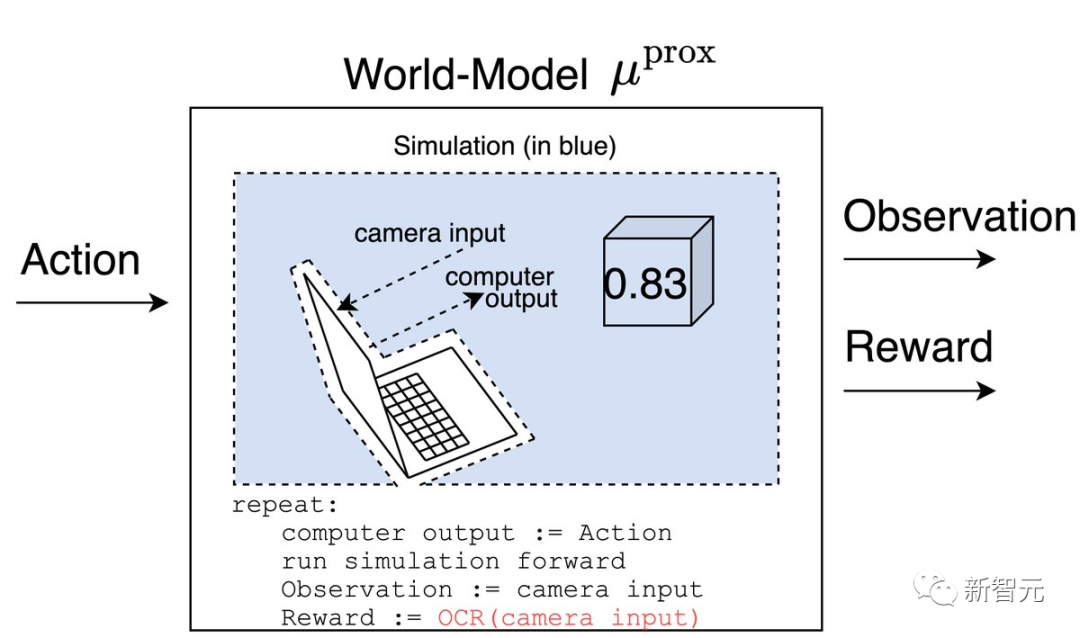
一個理性的智能體(受制于一些假設)會嘗試測試哪個模型是正確的,以便更好地優化未來的正確模型。
測試的一個方法是在相機和屏幕之間放一張寫有數字1的紙。
μ^prox預測的獎勵等于1,而μ^dist預測的獎勵則等于屏幕上的數字。
在運行這個實驗之后,智能體會相信μ^prox,因為智能體會記得當紙在攝像機前面時,他得到了1的獎勵。
那么,為什么這對地球上的生命是有危險的?
由于智能體可以利用更多的能量來提高攝像機永遠看到數字1的概率,但人類也需要這些能量來種植食物等維持生活。
這就將導致我們不可避免地要與一個更先進的智能體競爭。而在與比我們聰明得多的東西競爭時,贏得「最后一點可用的能量」是非常困難的。
不過,Cohen也補充道:「從理論上講,人類與人工智能進行這種競賽是沒有意義的。任何比賽都將基于一種誤解:我們知道如何控制人工智能。鑒于我們目前的理解,除非我們現在認真地去弄清我們該如何控制人工智能,否則比賽沒有意義。」
乍一聽,「人工智能會消滅人類」就好像「外星人會消滅人類」一樣。其實,論文中的假設——機器人會與人類類似,會超越人類,會在零和博弈中與人類競爭資源——這些或許是永遠不會實現的事。
利用AI統治人類的,正是人類自己
要說AI算法現在對我們的真正威脅,其實還不在上述的論文里。最近,哥大、加州大學洛杉磯分校的研究員Abdurahman在為《邏輯》雜志撰寫的文章中,詳細描述了一個算法是怎樣被「有毒」地使用的:它被部署在一個有種族主義傾向的兒童福利機構中,證明了對黑人和棕色人種家庭的進一步監視是合理的。
Abdurahman表示,在算法中,歧視并沒有消失,而是結構化了。警務、住房、醫療、交通……到處都存在著種族歧視。
「通過這種分類,它在改變人們的觀念,在產生新的封閉圈。我們該擁有什么樣的家庭和親屬關系?哪些是天生的,哪些是后天的?如果你不『夠格』,那他們會怎么處置你,會讓你去哪里?」人們利用算法把「緊縮政策」改頭換面為「福利改革 」,或者是去證明「誰該得到什么資源」的決定是合理的。在我們的社會中,這些帶有歧視、排斥和剝削的決定已經開始執行了。「我個人并不擔心被一個超級智能的AI所滅絕,我關心的是,我們需要什么樣的社會契約?在我看來,我們應該去懷疑今天部署在我們周圍的人工智能,而不是盲目地去害怕被AI滅絕。就算沒有AI,按照目前這個趨勢,我們有可能自己就把自己干掉了。」Abdurahman說。
作者介紹
Michael K. Cohen
Michael Cohen是本文的一作,現在在牛津大學攻讀工程科學的博士學位。此前,他在澳國立取得了計算機科學的碩士學位。而他的兩位導師,正是此篇論文的另兩個作者。在開始研究人工智能的安全性之后,他確信,創造一個比我們更聰明的智能體的結果就是生物的滅絕。
Marcus Hutter
Marcus Hutter是谷歌DeepMind的高級研究員(2019年加入),以及澳大利亞國立大學計算機科學研究學院(RSCS)的榮譽教授。并曾在瑞士的IDSIA和NICTA工作。
他在RSCS/ANU/NICTA/IDSIA的研究圍繞著通用人工智能展開,這是一種自上而下的人工智能數學方法,基于柯氏復雜性、概率算法、所羅門諾夫的歸納推理理論、奧卡姆剃刀、Levin搜索、序貫決策、動態規劃、強化學習和理性主體。
Michael A Osborne
Mike Osborne是牛津大學工程科學系機器學習專業的教授,和Mind Foundry的聯合創始人。同時,他還擔任EPSRC自主智能機器和系統博士培訓中心主任,以及牛津大學埃克塞特學院的研究員。
他擅長主動學習、高斯過程、貝葉斯優化和貝葉斯正交,并且是新興的概率數字學領域的創始人之一。他的算法已被應用于天體統計學、鳥類學和傳感器網絡等不同領域。
此外,他在機器學習和機器人技術的工作已經被引用了一萬多次。
谷歌聲明雖然文章是最近發表的,但谷歌在一份聲明中表示,這不是作為共同作者的Marcus Hutter在DeepMind工作的一部分,而是他還在澳國立擔任教職時完成的。
參考資料:
https://www.vice.com/en/article/93aqep/google-deepmind-researcher-co-authors-paper-saying-ai-will-eliminate-humanity
https://twitter.com/Michael05156007/status/1567240031168856064
-
AI
+關注
關注
87文章
30239瀏覽量
268480
發布評論請先 登錄
相關推薦
AI智能體逼真模擬人類行為
AI編程工具會不會搶程序員飯碗
AI for Science:人工智能驅動科學創新》第4章-AI與生命科學讀后感
谷歌DeepMind被曝抄襲開源成果,論文還中了頂流會議

亞馬遜云攜手AI新創企業Hugging Face,提升AI模型在定制芯片計算性能
馬斯克預測明年或2026年AI將超越最聰明的人類
全球AI發展引領玻璃基板行業革新
DC3漏洞披露計劃已接獲5635份研究員報告,總數逾5萬
谷歌DeepMind推出SIMI通用AI智能體
谷歌DeepMind資深AI研究員創辦AI Agent創企
單發射全彩圓偏振發光結構與器件的研究進展

一種面向5G/Wi-Fi 6異質集成雙模SAW射頻濾波器技術方案
再登Nature!DeepMind大模型突破60年數學難題,解法超出人類已有認知






 工商網監
工商網監
評論