") 使用LIME解釋CNN
使用LIME解釋CNN
作者:Mehul Gupta
來源:DeepHub IMBA
我們已經(jīng)介紹過很多解析機(jī)器學(xué)習(xí)模型的方法,例如如pdp、LIME和SHAP,但是這些方法都是用在表格數(shù)據(jù)的,他們能不能用在神經(jīng)網(wǎng)絡(luò)模型呢?今天我們來LIME解釋CNN。
圖像與表格數(shù)據(jù)集有很大不同(顯然)。如果你還記得,在之前我們討論過的任何解釋方法中,我們都是根據(jù)特征重要性,度量或可視化來解釋模型的。比如特征“A”在預(yù)測(cè)中比特征“B”有更大的影響力。但在圖像中沒有任何可以命名的特定特征,那么怎么進(jìn)行解釋呢?
一般情況下我們都是用突出顯示圖像中模型預(yù)測(cè)的重要區(qū)域的方法觀察可解釋性,這就要求了解如何調(diào)整LIME方法來合并圖像,我們先簡單了解一下LIME是怎么工作的。

LIME在處理表格數(shù)據(jù)時(shí)為訓(xùn)練數(shù)據(jù)集生成摘要統(tǒng)計(jì):
使用匯總統(tǒng)計(jì)生成一個(gè)新的人造數(shù)據(jù)集
從原始數(shù)據(jù)集中隨機(jī)提取樣本
根據(jù)與隨機(jī)樣本的接近程度為生成人造數(shù)據(jù)集中的樣本分配權(quán)重
用這些加權(quán)樣本訓(xùn)練一個(gè)白盒模型
解釋白盒模型
就圖像而言,上述方法的主要障礙是如何生成隨機(jī)樣本,因?yàn)樵谶@種情況下匯總統(tǒng)計(jì)將沒有任何用處。
如何生成人造數(shù)據(jù)集?最簡單的方法是,從數(shù)據(jù)集中提取一個(gè)隨機(jī)樣本,隨機(jī)打開(1)和關(guān)閉(0)一些像素來生成新的數(shù)據(jù)集但是通常在圖像中,出現(xiàn)的對(duì)象(如狗vs貓的分類中的:狗&貓)導(dǎo)致模型的預(yù)測(cè)會(huì)跨越多個(gè)像素,而不是一個(gè)像素。所以即使你關(guān)掉一兩個(gè)像素,它們看起來仍然和我們選擇樣本非常相似。所以這里需要做的是設(shè)置一個(gè)相鄰像素池的ON和OFF,這樣才能保證創(chuàng)造的人工數(shù)據(jù)集的隨機(jī)性。所以將圖像分割成多個(gè)稱為超像素的片段,然后打開和關(guān)閉這些超像素來生成隨機(jī)樣本。讓我們使用LIME進(jìn)行二進(jìn)制分類來解釋CNN的代碼。例如我們有以下的兩類數(shù)據(jù)。類別0: 帶有任意大小的白色矩形的隨機(jī)圖像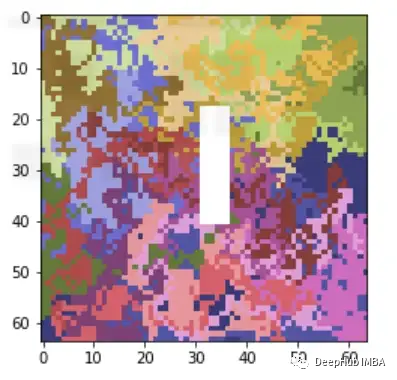
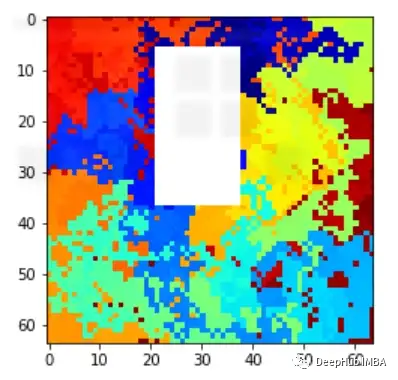 類別1:隨機(jī)生成的圖像(沒有白色矩形)
類別1:隨機(jī)生成的圖像(沒有白色矩形)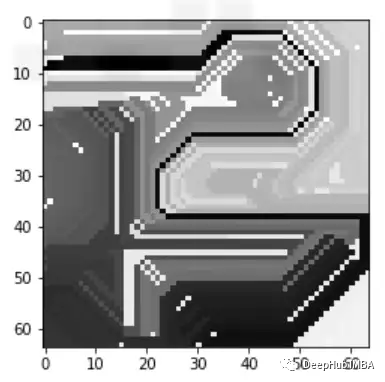
然后創(chuàng)建一個(gè)簡單的CNN模型
LIME示例
%matplotlib inline
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from keras.layers import Input, Dense, Embedding, Flatten
from keras.layers import SpatialDropout1D
from keras.layers.convolutional import Conv2D, MaxPooling2D
from keras.models import Sequential
from randimage import get_random_image, show_array
import random
import pandas as pd
import numpy as np
import lime
from lime import lime_image
from skimage.segmentation import mark_boundaries
#preparing above dataset artificially
training_dataset = []
training_label = []
for x in range(200):
img_size = (64,64)
img = get_random_image(img_size)
a,b = random.randrange(0,img_size[0]/2),random.randrange(0,img_size[0]/2)
c,d = random.randrange(img_size[0]/2,img_size[0]),random.randrange(img_size[0]/2,img_size[0])
value = random.sample([True,False],1)[0]
if value==False:
img[a:c,b:d,0] = 100
img[a:c,b:d,1] = 100
img[a:c,b:d,2] = 100
training_dataset.append(img)
training_label.append(value)
#training baseline CNN model
training_label = [1-x for x in training_label]
X_train, X_val, Y_train, Y_val = train_test_split(np.array(training_dataset).reshape(-1,64,64,3),np.array(training_label).reshape(-1,1), test_size=0.1, random_state=42)
epochs = 10
batch_size = 32
model = Sequential()
model.add(Conv2D(32, kernel_size=3, padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=2))
model.add(Flatten())
# Output layer
model.add(Dense(32,activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(X_train, Y_train, validation_data=(X_val, Y_val), epochs=epochs, batch_size=batch_size, verbose=1)
讓我們引入LIME
x=10
explainer = lime_image.LimeImageExplainer(random_state=42)
explanation = explainer.explain_instance(
X_val[x],
model.predict,top_labels=2)
)
image, mask = explanation.get_image_and_mask(0, positives_only=True,
hide_rest=True)
上面的代碼片段需要一些解釋我們初始化了LimeImageExplainer對(duì)象,該對(duì)象使用explain_instance解釋特定示例的輸出。這里我們從驗(yàn)證集中選取了第10個(gè)樣本,Get_image_and_mask()返回模型與原始圖像一起預(yù)測(cè)的高亮區(qū)域。讓我們看看一些樣本,它們實(shí)際上是1(隨機(jī)圖像),但檢測(cè)到為0(帶白框的隨機(jī)圖像)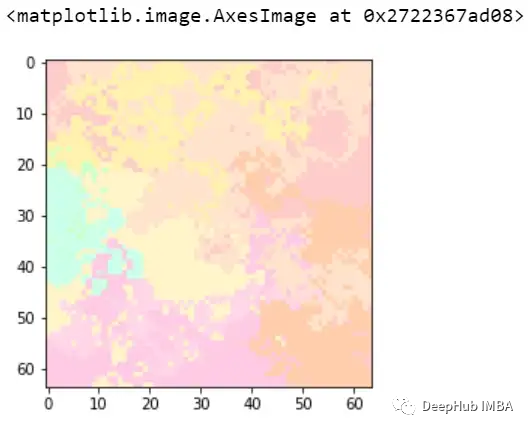
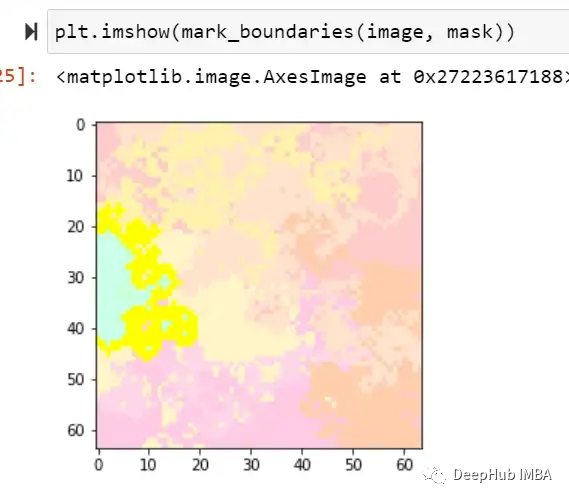 可以看到下圖有黃色的突出顯示區(qū)域,這張圖片的標(biāo)簽為1,但被標(biāo)記為0,這是因?yàn)楦吡溜@示的區(qū)域看起來像一個(gè)矩形,因此讓模型感到困惑,也就是說模型錯(cuò)吧黃色標(biāo)記的部分當(dāng)成了我們需要判斷的白色矩形遮蔽。
可以看到下圖有黃色的突出顯示區(qū)域,這張圖片的標(biāo)簽為1,但被標(biāo)記為0,這是因?yàn)楦吡溜@示的區(qū)域看起來像一個(gè)矩形,因此讓模型感到困惑,也就是說模型錯(cuò)吧黃色標(biāo)記的部分當(dāng)成了我們需要判斷的白色矩形遮蔽。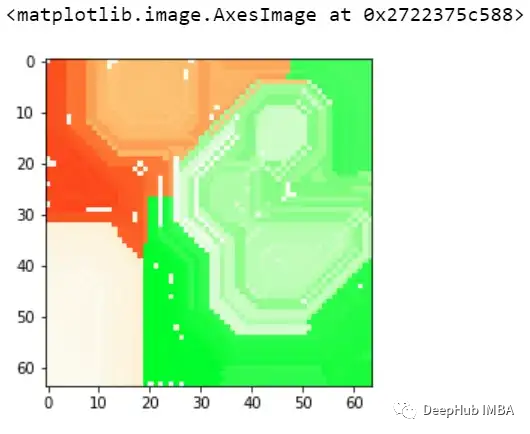
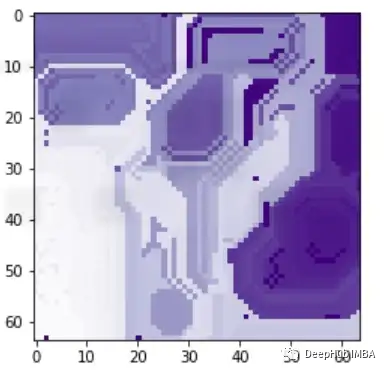
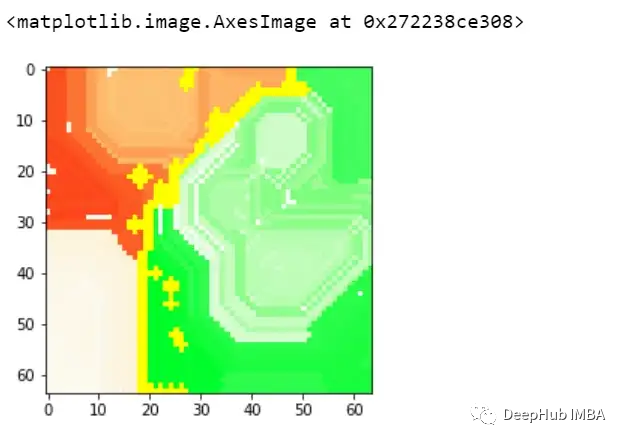 再看看上面兩個(gè)圖,與前面的例子類似,模型也預(yù)測(cè)了class=0。通過黃色區(qū)域可以判斷,某種形狀可能被模型曲解為白色方框了。
再看看上面兩個(gè)圖,與前面的例子類似,模型也預(yù)測(cè)了class=0。通過黃色區(qū)域可以判斷,某種形狀可能被模型曲解為白色方框了。
這樣我們就可以理解模型導(dǎo)致錯(cuò)誤分類的實(shí)際問題是什么,這就是為什么可解釋和可解釋的人工智能如此重要。
-
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8377瀏覽量
132409 -
cnn
+關(guān)注
關(guān)注
3文章
351瀏覽量
22169
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
cnn常用的幾個(gè)模型有哪些
圖像分割與語義分割中的CNN模型綜述
CNN與RNN的關(guān)系?
CNN在多個(gè)領(lǐng)域中的應(yīng)用
CNN的定義和優(yōu)勢(shì)
基于CNN的網(wǎng)絡(luò)入侵檢測(cè)系統(tǒng)設(shè)計(jì)
如何在TensorFlow中構(gòu)建并訓(xùn)練CNN模型
如何利用CNN實(shí)現(xiàn)圖像識(shí)別
NLP模型中RNN與CNN的選擇
cnn卷積神經(jīng)網(wǎng)絡(luò)分類有哪些
cnn卷積神經(jīng)網(wǎng)絡(luò)三大特點(diǎn)是什么
CNN模型的基本原理、結(jié)構(gòu)、訓(xùn)練過程及應(yīng)用領(lǐng)域
卷積神經(jīng)網(wǎng)絡(luò)cnn模型有哪些
深度神經(jīng)網(wǎng)絡(luò)模型cnn的基本概念、結(jié)構(gòu)及原理
基于Python和深度學(xué)習(xí)的CNN原理詳解





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論