 什么是非均勻數據重采樣?哪種非均勻數據重采樣方法更適合你?
什么是非均勻數據重采樣?哪種非均勻數據重采樣方法更適合你?
在數據分析和機器學習領域,我們常常需要處理非均勻數據。非均勻數據是指具有不平衡分布或樣本數量不均等的數據集。為了準確建模和預測,我們需要對這些非均勻數據進行重采樣。本文將詳細介紹什么是非均勻數據重采樣以及如何應用不同的方法來解決這一問題。
一、什么是非均勻數據重采樣?
非均勻數據重采樣是一種數據處理技術,用于解決數據集中存在的類別不平衡或樣本數量不均等的問題。在非均勻數據中,某些類別的樣本數量很少,而其他類別的樣本數量很多。這種不平衡會導致建模和預測過程中的偏差,影響結果的準確性。
非均勻數據重采樣的目標是通過增加少數類別的樣本數量或減少多數類別的樣本數量,使得數據集更加平衡。通過重采樣,我們可以在保持數據分布特征的前提下,增加較少樣本的可用性,從而提高模型的性能。
二、常見的非均勻數據重采樣方法和Python示例
(1)過采樣(Oversampling):過采樣方法通過增加少數類別的樣本數量來平衡數據集。其中一種常見的方法是復制少數類別的樣本,使其在數據集中出現多次。然而,簡單復制樣本可能會導致過擬合問題。因此,一些改進的過采樣方法被提出,如SMOTE(合成少數類過采樣技術)和ADASYN(自適應合成)等,它們根據少數類別樣本之間的距離關系合成新的樣本。
使用imbalanced-learn庫中的RandomOverSampler方法進行過采樣:
from imblearn.over_sampling import RandomOverSampler
X_resampled, y_resampled = RandomOverSampler().fit_resample(X, y)
使用imbalanced-learn庫中的SMOTE方法進行合成少數類過采樣:
from imblearn.over_sampling import SMOTE
X_resampled, y_resampled = SMOTE().fit_resample(X, y)
完整示例:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from imblearn.over_sampling import RandomOverSampler
from sklearn.metrics import classification_report
# 加載數據集
data = pd.read_csv('your_dataset.csv')
# 分割特征和目標變量
X = data.drop('target', axis=1)
y = data['target']
# 將數據集拆分為訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 方法1.創建RandomOverSampler對象
ros = RandomOverSampler(random_state=42)
# 對訓練集進行過采樣
X_train_resampled, y_train_resampled = ros.fit_resample(X_train, y_train)
# 方法2創建SMOTE對象
# smote = SMOTE(random_state=42)
# 對訓練集進行過采樣
# X_train_resampled, y_train_resampled = smote.fit_resample(X_train, y_train)
# 使用過采樣后的數據訓練模型
model = LogisticRegression()
model.fit(X_train_resampled, y_train_resampled)
# 在測試集上進行預測
y_pred = model.predict(X_test)
# 輸出分類報告
print(classification_report(y_test, y_pred))
(2)欠采樣(Undersampling):欠采樣方法通過減少多數類別的樣本數量來平衡數據集。最簡單的欠采樣方法是隨機地刪除多數類別的樣本。然而,這種方法可能會丟失一些重要的信息。因此,一些更高級的欠采樣方法被提出,如NearMiss和ClusterCentroids等,它們通過保留具有代表性的多數類別樣本來減少樣本數量。
使用imbalanced-learn庫中的RandomUnderSampler方法進行欠采樣:
from imblearn.under_sampling import RandomUnderSampler
X_resampled, y_resampled = RandomUnderSampler().fit_resample(X, y)
使用imbalanced-learn庫中的NearMiss方法進行近鄰欠采樣:
from imblearn.under_sampling import NearMiss
X_resampled, y_resampled = NearMiss().fit_resample(X, y)
(3)混合采樣(Combination Sampling):混合采樣方法是過采樣和欠采樣的結合。它同時對多數和少數類別進行處理,以達到數據集平衡的效果。其中一種常見的混合
混采樣方法是SMOTEENN(SMOTE + Edited Nearest Neighbors)方法。它首先使用SMOTE方法對少數類別進行過采樣,生成一些合成樣本。然后,使用Edited Nearest Neighbors(ENN)方法對多數類別進行欠采樣,刪除一些樣本。通過這種方式,混合采樣方法能夠克服簡單過采樣和欠采樣方法的一些問題,同時平衡數據集。
使用imbalanced-learn庫中的SMOTEENN方法進行SMOTE + Edited Nearest Neighbors采樣:
from imblearn.combine import SMOTEENN
X_resampled, y_resampled = SMOTEENN().fit_resample(X, y)
(4)加權重采樣(Weighted Resampling):加權重采樣方法通過為不同類別的樣本賦予不同的權重來平衡數據集。它可以用于訓練模型時調整樣本的重要性。常見的加權重采樣方法包括基于頻率的加權和基于錯誤率的加權。基于頻率的加權根據每個類別的樣本數量設置權重,使得樣本數量少的類別具有更高的權重。基于錯誤率的加權根據每個類別的錯誤率來調整權重,使得錯誤率高的類別具有更高的權重。
import torch
from torch.utils.data import DataLoader, WeightedRandomSampler
# 假設有一個不均衡的數據集,包含10個樣本和對應的類別標簽
data = [
([1, 2, 3], 0),
([4, 5, 6], 1),
([7, 8, 9], 1),
([10, 11, 12], 0),
([13, 14, 15], 1),
([16, 17, 18], 0),
([19, 20, 21], 1),
([22, 23, 24], 0),
([25, 26, 27], 1),
([28, 29, 30], 1)
]
# 分割特征和目標變量
X = [sample[0] for sample in data]
y = [sample[1] for sample in data]
# 創建權重列表,根據類別進行加權
class_counts = torch.tensor([y.count(0), y.count(1)])
weights = 1.0 / class_counts.float()
# 創建WeightedRandomSampler對象
sampler = WeightedRandomSampler(weights, len(weights))
# 創建數據加載器,使用加權重采樣
dataset = list(zip(X, y))
dataloader = DataLoader(dataset, batch_size=2, sampler=sampler)
# 遍歷數據加載器獲取批次數據
for batch_X, batch_y in dataloader:
print("Batch X:", batch_X)
print("Batch y:", batch_y)
三、選擇適當的重采樣方法
選擇適當的重采樣方法需要考慮數據集的特點和具體問題的需求。以下是一些建議:
(1)數據分析:在重采樣之前,首先對數據集進行分析,了解每個類別的樣本分布情況和特征。這有助于確定哪些類別是少數類別,哪些類別是多數類別,以及是否存在其他特殊情況(如噪聲數據)。
(2)重采樣策略:根據數據分析的結果選擇合適的重采樣策略。如果少數類別的樣本數量很少,可以考慮過采樣方法;如果多數類別的樣本數量較多,可以考慮欠采樣方法;如果兩者都存在問題,可以考慮混合采樣方法或加權重采樣方法。
(3)驗證效果:在應用重采樣方法后,需要評估重采樣對模型性能的影響。可以使用交叉驗證或保持獨立測試集的方法來評估模型的準確性、召回率、精確度等指標,并與未經過重采樣的結果進行對比。
四、總結
非均勻數據重采樣是解決非均勻數據集問題的重要步驟。通過過采樣、欠采樣、混合采樣和加權重采樣等方法,我們可以調整數據集的分布,提高模型的性能和準確性。選擇適當的重采樣方法需要基于數據分析的結果,并進行有效的評估。
-
模擬濾波器
+關注
關注
0文章
30瀏覽量
13400 -
機器學習
+關注
關注
66文章
8377瀏覽量
132409
發布評論請先 登錄
相關推薦
以遠場模型(平面波)為例,講解時空采樣定理!
請問PSpice仿真瞬態分析Transient如何設置輸出的Excel文件的采樣時刻為均勻采樣時刻?
關于labview中xy圖中波形重采樣的問題

一種新的非均勻采樣信號的離散傅里葉變換方法
如何使用概率模型進行非均勻數據聚類算法的設計介紹
空間曲線基于內在幾何量的均勻采樣方法

一種空間曲線基于內在幾何量的均勻采樣方法


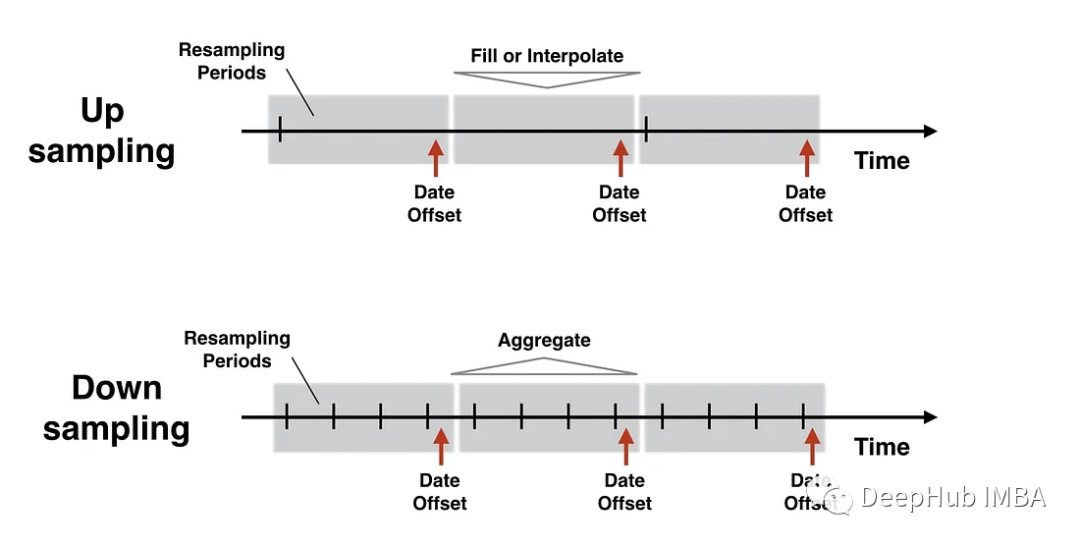
為什么重采樣很重要?Pandas中重新采樣的關鍵問題解析





 工商網監
工商網監
評論