 淺談存算一體技術的發展路線
淺談存算一體技術的發展路線
后摩智能發布了首款存算一體芯片——鴻途 H30,最高物理算力 256TOPS,功耗僅為 35W,碾壓國內一眾智駕芯片。
存儲一體?還首款?
不僅是后摩智能,包括英特爾、SK 海力士、IBM、美光、三星、臺積電、阿里、九天睿芯、恒爍股份、億鑄科技、千芯科技、蘋芯科技、知存科技、智芯科技等在內,無論是國際大廠還是初創企業都紛紛扎堆涌入這個領域。
不禁要問,讓各大芯片廠商打雞血的存儲一體是個什么東西,下面我們存算一體技術是什么,為什么這么火爆。
01存算一體是什么
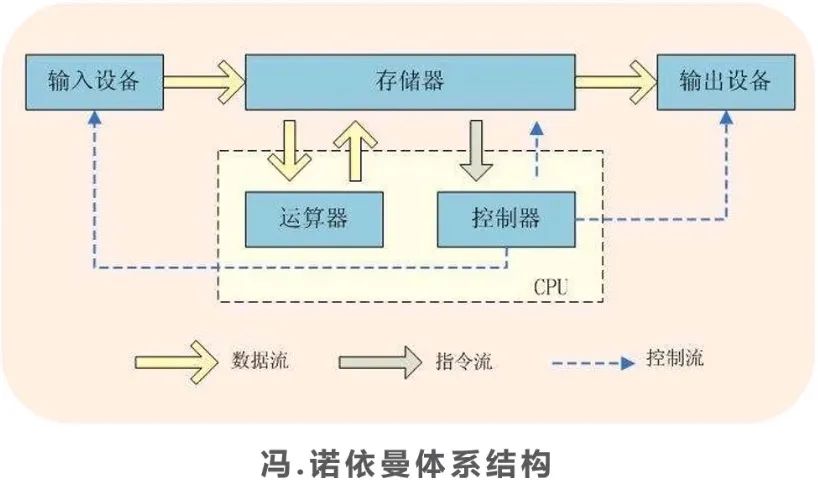
目前市面上的芯片都是基于馮諾依曼架構,其特點是處理單元和存儲單元分離,各不相干,需要運算的時候,計算單元再從存儲單元讀取數據進行處理,處理完再還回去。
而存算一體則是把存儲單元和處理單元合二為一,把數據和計算融合在同一片區中,這樣處理的好處在于可以直接利用存儲器進行數據處理,從根本上消除馮諾依曼架構計算存儲分離的問題,尤其特別適用于現代大數據大規模并行的應用場景。
實際上存儲一體并不是近年來被提出的新概念,最早可追溯至上個世紀 70 年代,只是受限于當時的芯片制造技術和算力需求,存算一體僅僅停留在理論研究上,一直到了大數據、人工智能時代,巨大的算力需求才為存算一體提供了新的發展動力。
比如中國國防科大、中科曙光和國家并行計算機工程技術研究中心計劃推出首臺 E 級超算,但想要研制這種級別的超算,科學家首先面臨的巨大挑戰就是功耗過高問題,以現有的技術研制 E 級超算功率高達千兆瓦,需要一個專門的核電站才能滿足耗電量,而其中 50% 以上的電量都要被用來消耗進行數據搬運。
本質上就是馮諾依曼架構的處理和存儲分離的缺陷所致,因此存算一體被當作全村的希望。
02存算一體的優勢
由于把存儲計算合二為一,去掉了中間傳輸路徑,所以可以大幅減少數據搬運,消過程中不必要的延遲和功耗,能耗可降至 1/10-1/100,能效可提升 10-100TOPS/W
因為存儲一體是以存儲器為介質,在里面加入計算單元,所以可以直接利用存儲單元進行邏輯計算提升算力。(等效于在面積不變的情況下規模化增加計算核心數),在特定區域可提供 1000TOPS 以上的算力
不依賴制程工藝,因為存儲一體基于全新架構開發,可以打破摩爾定律的限制,所以不受先進制程工藝限制。比如鴻途 H30 就是基于 12nm 制程工藝打造,在 Int8 數據精度下實現高達 256TOPS 的物理算力,功耗不超過 35W。
如果在傳統的馮·諾依曼架構下采用相同工藝,能效比多在 2TOPS/W,某國際巨頭芯片基于 8nm 工藝,如果二者用同一工藝,存算一體架構的芯片處理效率優勢將會更加明顯。
存算一體超越馮諾依曼架構,該架構可徹底消除數據搬運過程中的延遲和功耗,是一種真正意義上的處理存儲相融合,所以二者完全耦合,可以開發更細粒度的并行性,從而獲得更高的性能和能效,明顯超越現有的 ASIC 芯片。
存算一體架構無論是制程、功耗、成本還是算力,相比傳統架構都有明顯優勢,可以說完全就是為人工智能時代而生,但前途有多光明,道路就有多曲折,存算一體技術研發的困難也是相當巨大。
03存算一體的挑戰
傳統架構是計算和存儲相分離,現在兩者要合二為一,這就對存儲器本身和存算一體的設計提出更高的要求,是需要技術人員從頭探索的新領域。
隨著以后數據量不斷增大,在全新架構下,計算、功耗、通信三方面都要重新變革,對制造工藝都提出更高要求。
為了保持梯度計算的保真性和權重更新,現在市面上的AI芯片大都在 16bit 精度以上,而作為首款存算一體芯片的鴻途 H30 只有 8bit,還難以和傳統芯片媲美,即便是在 PCM 存儲器上有十多年的 IBM,也只是發布了 8bit 精度的模擬芯片,而其他大廠如微軟、英特爾、美光等則是投資創業公司。
由于存算一體是把計算和數據高度耦合,因此一旦其中一方出問題,另一方幾乎也會遭到極大影響,這都是需要處理的難題。
總而言之,存算一體是一條全新的、沒有現成方法可以參考的、還需要解決傳統架構遺留問題的艱難道路。
可即便優勢明顯,但存算一體難度這么大,為什么各路大廠還要紛紛打雞血參戰,傳統芯片架構技術成熟、產品可靠,創業公司也就算了,但為什么傳統廠商也來趟這趟回水,傳統芯片架構沒路可走了嗎,下面就要說說傳統架構的問題了。
04傳統芯片架構的「原罪」
文章開頭提到過,傳統芯片都是基于馮諾依曼架構開發,這種架構的特點是處理和存儲兩部分是分開的,通過數據總線進行數據連接傳輸,而且是以處理為主,存儲主要起到輔助作用,處理器先要把存儲器里的數據搬運出來才能處理,處理完再丟回去。
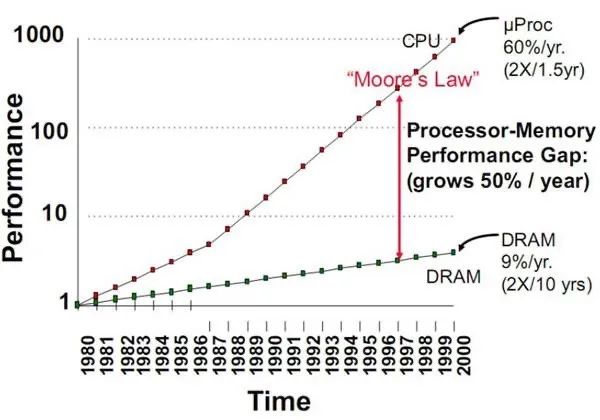
但隨著芯片技術的飛速發展,處理器的性能不斷飆升,而存儲器的性能卻在龜速前進,兩者的性能差距越來越大,存儲器的讀寫速度遠遠跟不上處理器的處理速度,導致芯片在運行的時候,大部分算力都被搬運數據的過程消耗掉了,只有小部分算力被有效利用。
就相當于一個極度口渴的人拿著一瓶水,瓶子的瓶體直徑有 1 米,但瓶口直徑只有 1 厘米,那種感覺各位感受下,所以逐漸就形成了業界普遍流傳的存儲墻,嚴重制約芯片綜合性能的提升。
有算力的地方就有功耗,正如上文所說,基于馮諾依曼架構開發的芯片在處理數據的過程中,處理器先要通過數據總線把存儲器中的數據搬運出來,處理完成后在搬運回去,整個搬運過程所消耗的功耗是浮點運算的 4-1000 倍左右。
雖然半導體工藝一直在進步,芯片的總體功耗在下降,但馮諾依曼架構天然的缺陷難以改變,數據搬運的功耗比只會越來越大,整個過程的無用能耗能占到 60%-90%,能效之低,令人發指,因此又形成了功耗墻,兩面墻就這樣死死壓制著芯片性能的提升。
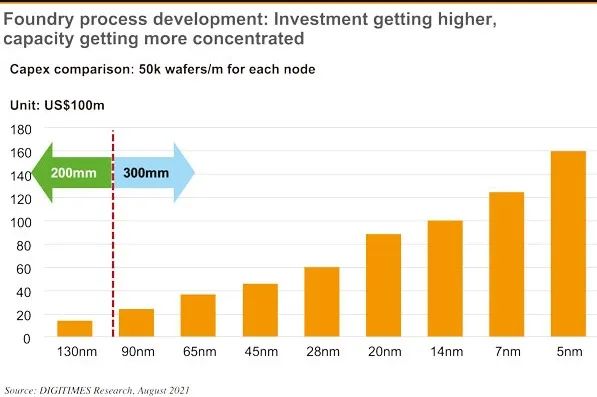
另外,根據咨詢公司評估,晶圓廠每一代工藝的建設資金都在急劇增加,還不說技術專利和人才問題,只是建造一個 5nm 晶圓廠,就需要 160 億美元,光是資金就嚇退所有人。
為了打破馮諾依曼架構的瓶頸,降低處理和存儲二者搬運過程帶來的高損耗,學術界和產業界嘗試了各種方法,大體可分為兩類:
近存儲計算
核心思想就是設計芯片的時候,把處理單元和存儲單元兩塊區域盡可能的拉近距離,縮短路徑,從而降低數據搬運過程中的算力損耗和功耗,目前市面上的主要技術路徑是多級緩存和高密度片上存儲。
光互連、2D/3D堆疊和高速帶寬數據通信
2D/3D堆疊技術是將多個芯片堆疊在一起,通過增大處理單元和存儲單元之間的并行寬度提高傳輸速度。
高速帶寬數據通信主要就是通過提高通信帶寬降低數據搬運過程的損耗。
因為馮諾依曼架構的天然缺陷依舊存在,所以上面兩種方案并沒有從根本上解決數據存儲和處理的搬運損耗問題,到了大數據、人工智能時代,海量的數據處理讓這些問題暴露的更加徹底,產業界和學術界都迫切希望找到一種能徹底解決該問題的方案,就是存算一體。
綜上所述,就是傳統的馮諾依曼架構缺陷導致自我消耗、限制太大,無法滿足算力需求,再加上摩爾定律逼近極限、晶圓廠建設又是個吞金獸,成本巨大,幾乎死路一條,各大廠商只能押注存算一體。
簡單來說,從馮諾依曼架構到存算一體架構,指導思想就是停止內耗,一致對外。
05存算一體技術發展路線
雖然存儲一體已經成為目前業界發展共識,但由于各個技術廠商的技術、發展方向、商業模式等條件不同,因此發展出了四種路徑。
查存計算
目前 GPU 芯片中對復雜函數的處理就是用了這種方法,主要通過在存儲單元內部查表完成處理任務,技術成熟穩定。
近存計算
國外的典型代表便是 AMD 的 ZEN 系列 CPU,國內阿里巴巴基于 DRAM 的 3D 堆疊技術芯片也是這個路線,主要通過在存儲區域外部的獨立處理單元完成操作,這種架構的代際升級成本較低,特別適合傳統芯片廠商過渡。
存內計算
主要在存儲單元內部加入獨立計算單元完成數據處理操作,計算方式可以是數字也可以是模擬,一般用于固定場景的算法計算,上文提到的鴻途 H30 便屬于這種。
存內邏輯
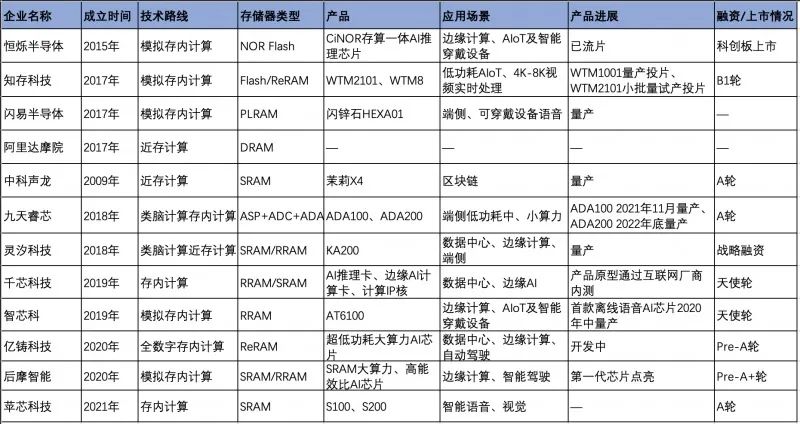
這是目前存算一體的最新架構,主要在存儲區域加入計算邏輯,直接進行數據計算,這種架構數據傳輸路徑最短,真正做到存算一體,能滿足大模型的計算需求,代表廠商有 TSMC 和千芯科技。
由于存算一體芯片都是基于存儲器介質開發,而存儲器可分為易失性和非易失性兩種,所以又有數字計算和模擬計算兩種方向。
基于易失性的數字計算存儲器,主要有 SRAM 和 DRAM。
SRAM 和 DRAM 技術工藝成熟,是目前存儲器的主流,因此很多廠商都基于兩者展開存算一體技術研究,具有高性能和高精度優點,也有很好的抗噪聲能力和可靠性。
基于非易失性的模擬計算存儲器,主要有閃存 Flash、相變存儲器 PCM、阻變存儲器 RRAM/憶阻器 ReRAM。
這些新型存儲器在近年來取得了較快的發展,具有存儲密度大、并行度高優點、對存儲和計算具備天然的融合性,但對環境噪聲和溫度比較敏感,但由于工藝尚不成熟,距離真正落地還有一段距離。
數字存算一體適合大算力高能效的應用場景,模擬存算一體適合小算力、不需要非常強的可靠性的民用場景。
一句話概括,未來很長一段時間內,SRAM 和 DRAM 都是存算一體芯片的主流選擇。
寫在最后
存算一體已經被業界普遍確定為下一代人工智能芯片技術發展方向,由于是全新的技術方向,目前國內外廠商都處于剛起步階段,沒有成熟方法可以借用,而且該技術依賴于存儲器的不斷流片積累經驗,需要技術團隊有充分的量產經驗和技術認知,還需要大量資金,行業壁壘很高。
目前各大廠商根據自身情況,主要有兩種發展思路:
從小算力入手,比如從 1TOPS 開始,先解決音頻類、健康類這些低功耗的應用場景,掌握芯片商業化后的性能和功耗問題,然后在進入大算力領域。
直接發展大算力,提供大于 100TOPS 的高性價比產品,應用于智能駕駛、云計算、機器人等領域。
隨著現在各種大模型、自動駕駛、云計算等 AI 技術的加速落地,對大算力需求迫切增加,即使技術有很多困難,但巨大的市場需求一定會倒逼技術突破,成為繼 CPU、GPU 架構之后的另一主流架構。
審核編輯:湯梓紅
-
處理器
+關注
關注
68文章
19178瀏覽量
229200 -
存儲器
+關注
關注
38文章
7455瀏覽量
163622 -
sram
+關注
關注
6文章
764瀏覽量
114638 -
美光
+關注
關注
5文章
708瀏覽量
51405 -
存算一體
+關注
關注
0文章
100瀏覽量
4288
原文標題:存算一體技術發展路線
文章出處:【微信號:nev360,微信公眾號:焉知新能源汽車】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
存算一體大算力AI芯片將逐漸走向落地應用
比存算一體更進一步,“感存算一體化”前景如何?
2PFLOPS,存算一體迎來新的卷王
探索存內計算—基于 SRAM 的存內計算與基于 MRAM 的存算一體的探究

ReRAM存算一體AI大算力芯片的獨特優勢

2023年存算一體是芯片設計的技術趨勢
關于存算一體,我們和ChatGPT聊了聊
特斯拉的下一代AI芯片:存算一體

如何選擇存儲器類型 存算一體芯片發展趨勢








 工商網監
工商網監
評論