") NVIDIA拿下CVPR 2023 3D Occupancy預測第一名!
NVIDIA拿下CVPR 2023 3D Occupancy預測第一名!
自動駕駛中的三維占用預測難題,一場比賽給出了解決方案。
道路錯綜復雜、交通工具形態(tài)各異、行人密集,這是當前城市道路交通的現(xiàn)狀,也是自動駕駛領(lǐng)域面臨的現(xiàn)實挑戰(zhàn)。為了應對這一挑戰(zhàn),感知和理解三維環(huán)境至關(guān)重要。
在傳統(tǒng)的三維物體檢測任務中,前景物體通常由三維邊界框表示。然而,這種方法存在一些弊端,一方面,現(xiàn)實世界的物體幾何形狀非常復雜,無法用簡單的三維框表示;另一方面,這種方法容易忽略背景元素的感知。對于實現(xiàn)全面的 L4/L5 自動駕駛,傳統(tǒng)的三維感知方法是遠遠不夠的。
最近,端到端自動駕駛研討會 (End-to-End Autonomous Driving Workshop) 聯(lián)合視覺中心自動駕駛研討會 (Vision-Centric Autonomous Driving Workshop) 在 CVPR 2023 上舉辦了自動駕駛挑戰(zhàn)賽,其中就包括三維占用預測(3D occupancy prediction)賽道。

圖 1 CVPR2023 自動駕駛挑戰(zhàn)賽
三維占用預測是自動駕駛領(lǐng)域的新興任務,要求對車輛行駛場景進行細粒度建模,對于實現(xiàn)自動駕駛的通用感知能力有著重要意義。比賽提供基于 nuScenes 數(shù)據(jù)集的大規(guī)模占用預測評估基準,對三維空間進行體素化表示,并在三維占用任務的基礎(chǔ)上結(jié)合兩項新任務:估計三維空間中體素的占據(jù)狀態(tài)和語義信息。整個任務旨在在給定多視角圖像的情況下對三維空間進行密集預測。
本次比賽是三維占用感知領(lǐng)域的首個國際頂尖權(quán)威賽事,吸引了業(yè)界和學界的廣泛關(guān)注。比賽共有 149 個團隊參與角逐,其中包括來自小米汽車,華為,42dot,海康威視的業(yè)界團隊,也有來自北京大學,浙江大學,中國科學院等科研院所的學術(shù)界團隊。
最終,來自英偉達 (NVIDIA) 和南京大學的團隊在激烈的競爭中脫穎而出,同時贏得了三維占用預測任務的冠軍和最佳創(chuàng)新獎兩個重磅獎項。下面我們來看一下冠軍團隊的獲獎方案。
冠軍方案
不同于以往比賽對于數(shù)據(jù)利用方面的限制,本次自動駕駛比賽允許參賽者使用額外的開源數(shù)據(jù)或者模型進行數(shù)據(jù)驅(qū)動算法的探索。因此在本次比賽中,英偉達和南大的研究人員在設(shè)計高效的模型結(jié)構(gòu)的基礎(chǔ)上,也在大模型的訓練方面進行了探索,將模型參數(shù)擴展到 10 億量級,達到過去常用 3D 感知模型的 10 倍以上。
憑借先進的模型結(jié)構(gòu)設(shè)計和大模型強大的表征能力,該團隊提出的方案 FB-OCC 實現(xiàn)了單模型 50+% mIoU 的出色性能,并最終取得了 54.19% mIoU 的最佳成績。
網(wǎng)絡架構(gòu)
FB-OCC 的主要創(chuàng)新在于使用了前向和后向投影相結(jié)合的三維空間建模方式。
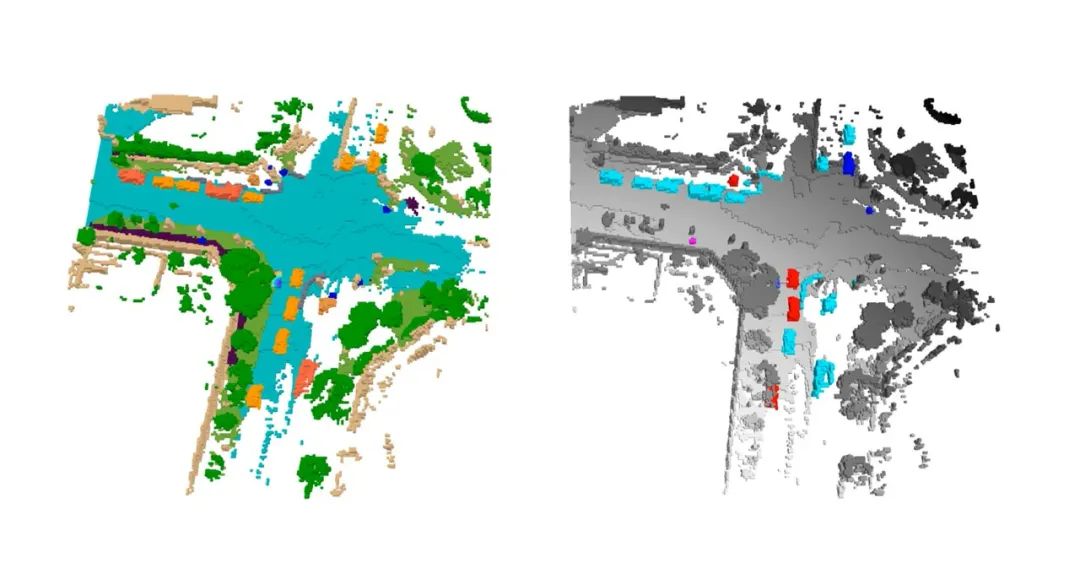
如圖 2 所示,在前向投影過程中,參考 LSS 投影范式,F(xiàn)B-OCC 會根據(jù)每個像素的深度分布生成場景對應的三維體素 (3D voxel) 表征。同時,由于 LSS 范式生產(chǎn)的特征傾向于稀疏且不均勻,F(xiàn)B-OCC 引入反向投影機制來優(yōu)化稀疏的場景特征。
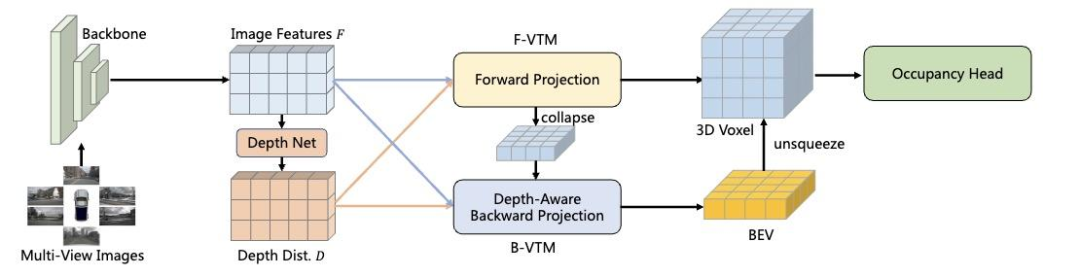
圖 2 網(wǎng)絡架構(gòu)圖
此外,考慮到計算負擔,F(xiàn)B-OCC 在方向投影的過程中會將場景特征壓縮為鳥瞰圖 (BEV) 表征,最后將三維體素表征和鳥瞰圖表征相結(jié)合。結(jié)合后得到的三維體素特征在后續(xù)還會經(jīng)過額外的體素編碼器 (Voxel encoder) 來增強特征感受野。
大規(guī)模模型探索
增加模型參數(shù)量是提升模型精度的最便捷的方式,但在三維視覺感知領(lǐng)域,研究人員發(fā)現(xiàn)更大規(guī)模的模型更容易產(chǎn)生過擬合現(xiàn)象,而現(xiàn)有主流感知模型的參數(shù)仍在 100M 量級。
在本次比賽中,F(xiàn)B-OCC 模型嘗試使用 10 億參數(shù)量級的 InternImage 主干網(wǎng)絡,模型總體參數(shù)量是現(xiàn)有常用模型的十倍以上。大模型訓練通常需要大數(shù)據(jù)與之匹配,但受限于自動駕駛數(shù)據(jù)采集標注的高昂成本,開源的三維感知數(shù)據(jù)集并不足以支撐 10 億參數(shù)規(guī)模的模型。
針對這個痛點,F(xiàn)B-OCC 使用了多輪預訓練機制。由于可獲取的二維感知數(shù)據(jù)集遠遠豐富于三維感知數(shù)據(jù),F(xiàn)B-OCC 首先在大規(guī)模開源數(shù)據(jù)集 Objects365 上進行通用目標檢測預訓練。然后,如圖 3 所示,F(xiàn)B-OCC 引入深度和語義聯(lián)合預訓練來建立二維感知和三維感知的橋梁。
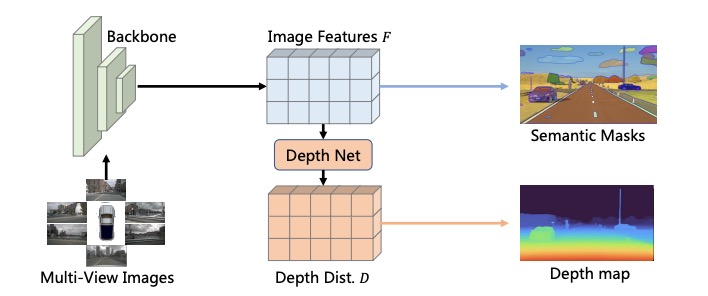
圖 3 深度和語義聯(lián)合預訓練
為了生成語義分割標簽,F(xiàn)B-OCC 還使用 Meta 的 SAM 模型來進行自動標注,分別使用框提示和點提示來生成不同類別的語義。經(jīng)過多輪預訓練后,大規(guī)模模型在占用感知任務上可以避免嚴重的過擬合問題。
實驗結(jié)果
研究團隊在實驗中證明了 FB-OCC 的出色性能。如表 1 所示,F(xiàn)B-OCC 在 ResNet-50 主干網(wǎng)絡以及 256x704 分辨率的輸入圖像下,借助時序融合、深度監(jiān)督等技術(shù),模型性能從最初的 23.12% mIoU 增長至 42.06% mIoU。
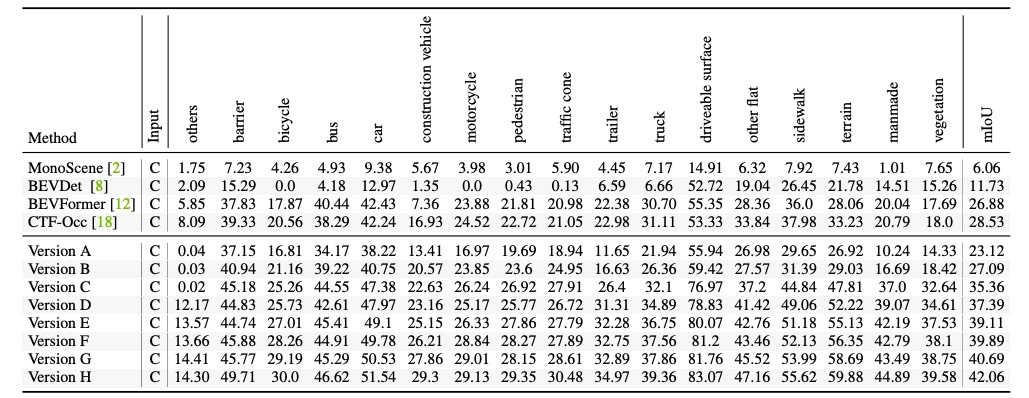
表 1 小規(guī)模模型的消融實驗結(jié)果
為了獲得更好的精度,F(xiàn)B-OCC 使用了更大參數(shù)量的模型。如表 2 所示,在 400M 的模型規(guī)模下,F(xiàn)B-OCC 獲得了單模型 50+% mIoU 的效果。借助 InternImage 主干網(wǎng)絡,10 億參數(shù)量級的模型進一步取得了 52.79% 的極佳效果。
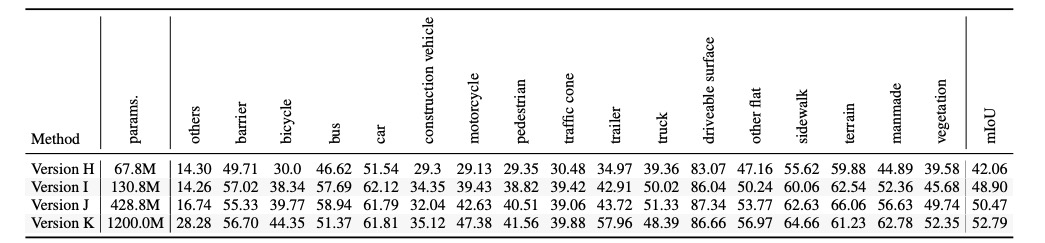
表 2 不同模型規(guī)模下的效果
最終,F(xiàn)B-OCC 多個模型的集成結(jié)果取得了目前測試集上最高的準確率 ——54.19%,贏得了比賽的冠軍并被授予最佳創(chuàng)新獎。FB-OCC 為自動駕駛中復雜的三維占用預測問題貢獻了新的思路。
-
NVIDIA
+關(guān)注
關(guān)注
14文章
4940瀏覽量
102815 -
三維
+關(guān)注
關(guān)注
1文章
496瀏覽量
28944 -
自動駕駛
+關(guān)注
關(guān)注
783文章
13684瀏覽量
166147
原文標題:NVIDIA拿下CVPR 2023 3D Occupancy預測第一名!
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
祝賀 | 鵬城實驗室開源 EDA 團隊勇奪 ICCAD 競賽第一名
口碑最好的國產(chǎn)手機,華為mate9排第五!第一名你認可嗎!
三星認為自家手機才是手機拍照的第一名
小米10Pro AI相機詳解 如何鑄就DxOMark排行榜第一名
iPhone 11依舊占據(jù)手機銷量的第一名
五菱宏光mini EV以2萬輛的銷量奪回國內(nèi)新能源汽車市場銷量第一名
小米電視2020年出貨量位列國內(nèi)第一名
京東618會議平板榜,新銳品牌會參謀(leaderhub)第一名
NVIDIA 3D MoMa:基于2D圖像創(chuàng)建3D物體
NVIDIA Research 在 CVPR 上贏得自動駕駛挑戰(zhàn)賽并獲得創(chuàng)新獎
華潤微電子以第一名的成績榮獲新吳區(qū)區(qū)長質(zhì)量獎






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論