 河套IT TALK95:(原創)GPT技術揭秘:大模型訓練會導向滅霸的響指嗎?
河套IT TALK95:(原創)GPT技術揭秘:大模型訓練會導向滅霸的響指嗎?
1. 大模型訓練的套路
昨天寫了一篇關于生成式模型的訓練之道,覺得很多話還沒有說完,一些關鍵點還沒有點透,決定在上文的基礎上,再深入探討一下大模型訓練這個話題。
任何一個大模型的訓練,萬變不離其宗,一定要經歷以下幾個步驟:
-
模型選擇(Model Selection):選擇適合任務和數據的模型結構和類型。
-
數據收集和準備(Data Collection and Preparation):收集并準備用于訓練和評估的數據集,確保其適用于所選模型。
-
無監督預訓練(Pretraining):使用大規模未標記的數據進行預訓練,使模型學習通用的語言表示。
-
驗證和測試(Verification and testing):評估預訓練或者微調后模型在特定任務上的性能,并進總的來說,這些步驟不是簡單的線性順序,具體大家看圖來體會。而是在預訓練和微調或調優階段后的驗證和測試,都要跟隨一個決策是否要調整模型,是否要繼續進行微調或調優。根據決策來判定是否選擇迭代的循環,通過不斷的反饋和優化,逐步提升模型的性能和泛化能力,知道涌現出來的能力,讓訓練者滿意結束訓練過程。但讓這個過程有個確定起點的話,一定要從模型選擇開始。行必要的調整和改進。
-
微調或調優(Fine-tuning):使用標記的任務特定數據對預訓練模型進行微調,以提高其在特定任務上的性能。
-
決策(Decision Making):根據驗證和測試結果,判斷是否需要重新選擇模型、調整超參數、重新收集數據等,進一步優化模型。
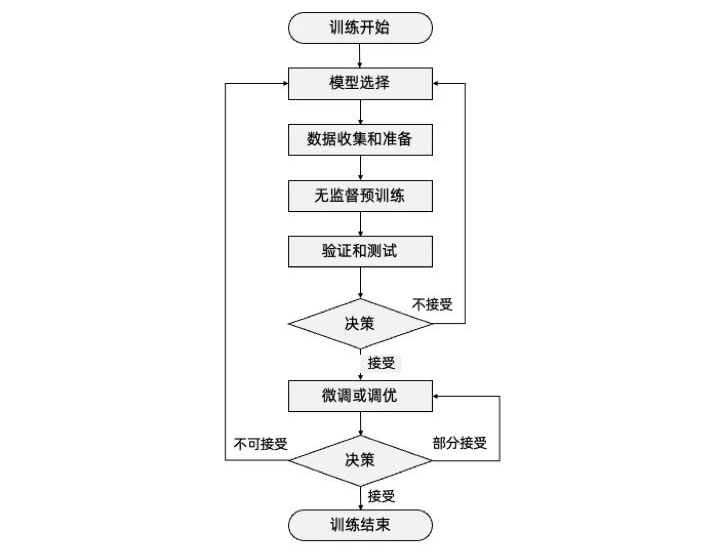
總的來說,這些步驟不是簡單的線性順序,具體大家看圖來體會。而是在預訓練和微調或調優階段后的驗證和測試,都要跟隨一個決策是否要調整模型,是否要繼續進行微調或調優。根據決策來判定是否選擇迭代的循環,通過不斷的反饋和優化,逐步提升模型的性能和泛化能力,直到涌現出能力,讓訓練者滿意結束訓練過程。但讓這個過程有個確定起點的話,一定要從模型選擇開始。
2. 模型選擇:信仰、篤定和堅持
啟動訓練大模型這個事兒,本身就很瘋狂。因為沒有人知道結果是否會成功,以及最終訓練是否會涌現奇跡。所以模型的選擇,說的謙虛一點,是基于模型構建者的先驗知識、經驗、文獻研究和調研,說的玄學一點就是基于一種信仰和篤定。
ChatGPT這種事兒最終能被Samuel Altman 搞成,從他的歷史經歷來看也是有跡可循的。Sam在個性上是個敢于冒險和不按常理出牌的人。在斯坦福大學學習計算機科學那會兒,剛學了一年,在2005年就退學搞創業了,成立了Loopt,一款基于位置的社交移動應用,作為CEO,幾年給公司籌集了3000萬美金的風險投資,2012年,它被綠點公司以4340萬美金收購,也算是他撈到的第一桶金。Sam接下來從2011年起,成了YC(以投資種子階段初創公司為業務的創投公司)的合伙人。2014年,Sam被任命為YC的總裁,并開始大刀闊斧,愿意投資和推動新的、未經證實的技術,準備將YC擴大到每年資助1000家初創公司,尤其是“硬科技”公司,而OpenAI就是2015年他和幾個行業大佬聯合資助起來的,致力于訓練人工智能,讓人工智能走進人類,試圖創建并推廣友好的人工智能,以造福所有人,實現智能公平。并很快在2015年就籌集了10億美金。2019年,Sam篤定大模型一定能搞成,毅然決然離開YC,專注于OpenAI。
Transformer模型在谷歌大腦2017年發布開源的時候,應用的場景是自然語言處理(NLP) 的機器翻譯和時間序列預測任務。Sam等人堅信Transformer更適合并行化,允許在更大的數據集上進行訓練,這就直接導致了預訓練系統的發展。
3. 數據預處理:剔除“臟”數據
有了模型,就要考慮怎么去找數據訓練了。這可不是隨便在互聯網上找到海量數據,然后不分青紅皂白就開始訓練的。根據國際數據公司IDC的估計,截至2020年,全球數字宇宙的大小為44 Zettabytes(其中1 Zettabyte等于10億 Terabytes),其中文本、圖像和視頻等非結構化數據占據了絕大部分。具體來說,據IDC估計,非結構化數據占據數字宇宙的80%以上,其中視頻數據占比最高,約為60%。據統計,截至2020年,全球每天產生的文本數據量約為50萬億字節,這相當于每天產生50億部普通手機的存儲容量;而每天上傳到YouTube的視頻數據量約為500小時,相當于每分鐘上傳約300小時的視頻。如果要把這些數據都學習了,不是不可能,但是也沒有必要。
人類的信息有很多,有些信息是正確信息,有些是錯誤信息,有些是噪聲數據。有些信息帶有明顯的惡意或者邏輯漏洞。如果不分青紅皂白,讓AI自己去訓練自己,可能會在訓練數據這個環節就會失控,表現不如預期甚至出現偏差和過擬合等問題。因為“臟”數據,自然不會學出一個理想的模型和能力沉淀。因此,在選擇訓練數據時,需要盡量篩選和清洗出具有代表性和高質量的數據,從而提高模型的表現和泛化能力。
關于GPT-4學了多大當量的數據并未公開,但是GPT-3學了45TB的文本數據。主要來源于:
-
Common Crawl:提供了包含超過50億份網頁數據的免費數據庫。有超過7年的網絡爬蟲數據集,包含原始網頁數據、元數據提取和文本提取。
-
Wikipedia:網絡維基百科,目前有超過1億的條目項。
-
BooksCorpus:由100萬本英文電子書組成的語料庫。
-
WebText:一個來自于互聯網的語料庫,其中包含了超過8億個網頁的文本內容。
-
OpenWebText:類似于WebText,但是包含的文本數據更加規范化和質量更高。
-
ConceptNet:一個用于語義網絡的數據庫,其中包含大量的語言學知識。
-
NewsCrawl:從新聞網站收集的大量新聞文章的集合。
-
Reddit:一個包含了大量用戶發布的信息的論壇網站。
但不能簡單的運用拿來主義。這種原始數據,是不能直接進入訓練的,還至少要經過以下四個數據預處理階段,才可以進入到預訓練環節:
數據清理(Data Cleaning):處理數據中存在的錯誤、缺失或不一致的部分,包括刪除重復數據、處理缺失值、修復錯誤數據或調整數據格式等操作。數據清理旨在確保數據的準確性和一致性,以避免對模型訓練產生不良影響。
去除噪聲(Noise Removal):在數據中可能存在一些無關緊要或錯誤的信息,被稱為噪聲。去除噪聲的過程是識別和過濾掉這些噪聲數據,以提高數據的質量和模型的性能。噪聲可能包括文本中的標點符號、停用詞、拼寫錯誤、不一致的格式等。通過去除噪聲,可以減少對模型的干擾,提高模型對真實信號的學習能力。
標準化(Normalization):標準化是將數據轉化為統一的標準尺度的過程。這對于具有不同尺度或分布的特征數據非常重要。標準化可以確保不同特征之間的數據具有可比性,避免模型在處理數據時對某些特征給予不合理的權重。常見的標準化方法包括將數據縮放到特定的范圍(例如0到1之間)或者使用均值和標準差進行標準化。
分詞(Tokenization):前文已經說了,token是指在信息數據處理中的最小單位,文本數據的預處理中,一個常見的步驟是將原始文本拆分成一個個token,這個過程稱為tokenization。目的是將連續的文本序列劃分為離散的單元,例如單詞、子詞或字符。這樣做的好處是將文本轉換為機器可以處理的離散表示形式。在深度學習模型中,tokenization通常是將文本轉換為數字表示的第一步。每個token都被賦予一個唯一的整數編號,這個編號會作為模型輸入中的一個特征向量的一部分。
4. 預訓練:反向傳播算法(Backpropagation)
在數據開始預訓練之前,需要先定義損失函數。損失函數是衡量模型預測結果與實際目標之間差異程度的指標。確實,較小的損失函數值表示模型在訓練數據上的擬合效果較好,也就是更好地學習了訓練數據的內容。在訓練過程中,我們的目標是最小化損失函數的值。通過調整模型的參數,使損失函數達到最小值,即實現了對任務的最佳擬合。
在訓練過程中,通過計算損失函數相對于參數的梯度,可以了解每個參數對損失函數的影響程度。梯度告訴我們應該如何更新參數值來最小化損失函數。當梯度接近零時,表示損失函數達到了一個局部最小值或平穩點,這可能意味著模型已經收斂到一個較好的狀態。這樣的情況下,訓練可以被認為是相對順利的。然而,并不是所有情況下梯度接近零都代表訓練的順利進行。在深度學習中,模型可能會遇到鞍點或局部最小值,并且梯度可能會陷入平原地帶。此時,某些維度上的梯度接近零,但并不表示找到了全局最小值。鞍點是指在某個位置上,沿一些維度上的梯度是零,但沿其他維度上的梯度不為零的點,甚至其他維度梯度可能仍然有較大的值,說明還有改進的空間。
這個損失函數梯度收斂的過程,除了剛才說的鞍點和局部最小值,還可能遇到梯度消失(Vanishing Gradient)和梯度爆炸(Exploding Gradient),上文已經說過這兩個問題代表著什么,以及怎么去應對,這里就不再贅述。
在神經網絡中,損失函數梯度收斂的過程是通過反向傳播算法(Backpropagation)實現的。反向傳播算法(Backpropagation)是指在神經網絡中,通過計算損失函數對網絡參數的梯度,并將梯度信息從輸出層向輸入層進行傳遞的過程。它基于鏈式法則,通過將梯度從輸出層逐層反向傳播至輸入層,計算每個參數對損失函數的貢獻,并利用梯度信息更新網絡參數,從而最小化損失函數。反向傳播算法用于訓練神經網絡,通過調整參數使得預測結果與真實標簽更接近。
這個過程被很多人戲稱為煉丹。在預訓練階段,模型通過大規模的無監督學習來學習語言模型的結構和表示。這個階段的目標是讓模型在未標記的數據上進行自我訓練,從中學習到語言的統計規律和語義信息。在這個過程中,模型有機會發現并表現出一些意想不到的能力,這就是“涌現”了。具體來說,當模型規模擴大、參數增多時,模型可能會表現出更好的泛化能力、更高的性能或具備某些令人驚訝的特征。這種涌現現象可能與模型內部的復雜交互和表示能力有關,模型在訓練過程中學習到了隱藏的結構或規律,從而表現出超出預期的能力。而作為一種驚喜,“涌現”不能自我展示,還得需要在驗證環節被發現。
5. 驗證和測試階段:發現“涌現”的激動時刻
在驗證和測試階段,研究人員和開發者會對訓練得到的模型進行評估和驗證。一般大模型的驗證會分為可塑性、可供性、可用性、可信性和可替代性五個大類26個細分指標:
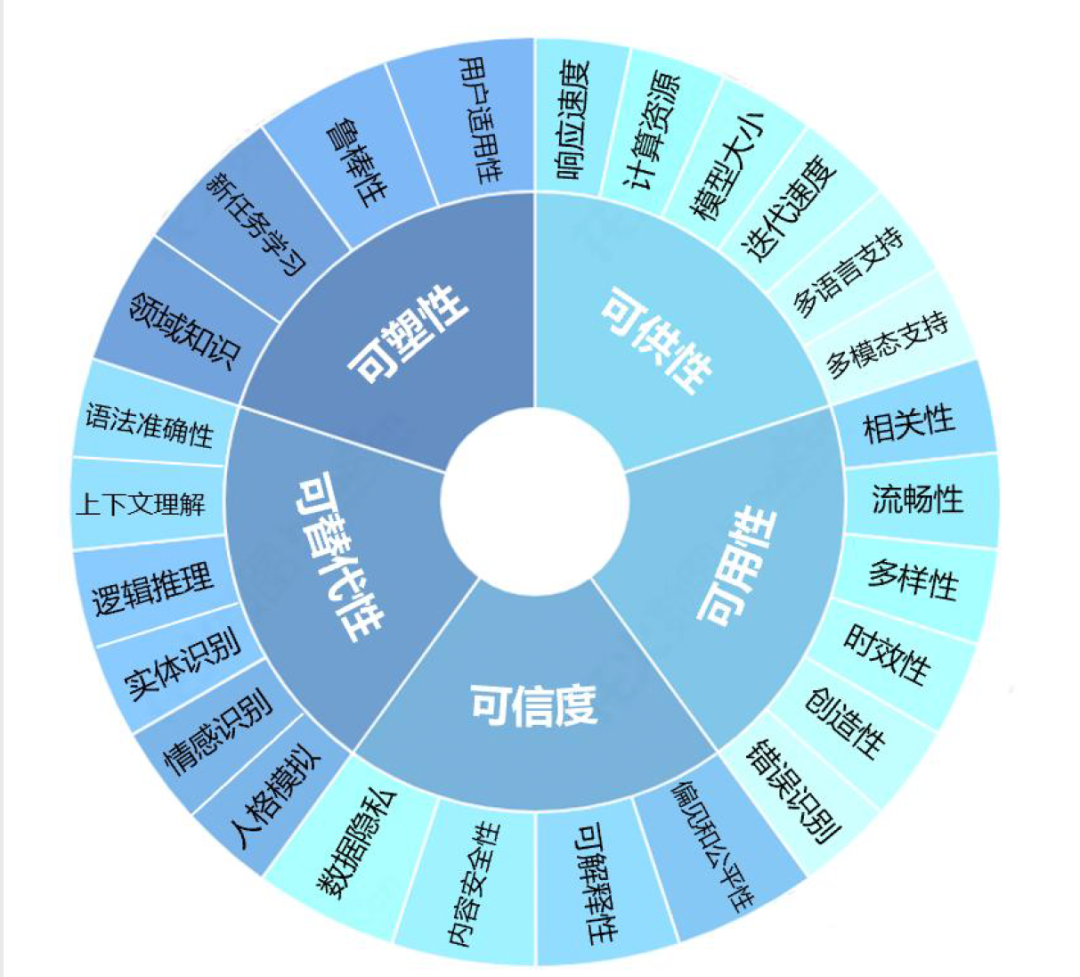
在測試和驗證中發現涌現具有偶然性,但也不是一點兒不能預測,所以在測試用例的設計時候,能夠足夠大膽,預估到可能“涌現”的方向,而提前做好準備。智愿君下面會列出來一些可能涌現的能力,但現實場景可能遠遠比這個要復雜:
高階推理能力:大型語言模型在經過訓練和優化后,可能展現出對高階推理任務的能力。這包括對因果關系的理解、擾動變量分析、反事實推理等。模型可以在文本中尋找關聯,并推斷出復雜的邏輯關系,從而回答復雜的問題。
去除噪聲和問題定位:在訓練過程中,模型可能學習到了如何去除輸入中的噪聲,并從復雜的問題中定位和理解問題的根源。這使得模型能夠更好地理解用戶的意圖,并給出準確和有針對性的回復。
自我修正能力:大型語言模型可能具有一定的自我修正能力。通過與用戶的交互和反饋,模型可以不斷學習和糾正自己的錯誤,并提供更準確的回答。這種自我修正能力可以幫助模型逐步改進,并提供更高質量的輸出。
靈活應對知識盲區:模型在訓練過程中可能遇到知識盲區,即對某些領域或主題的了解有限。然而,通過涌現,模型可能能夠從已有的知識中推斷和應用相關信息,填補知識盲區并給出合理的回答。
知識嵌入、想象力和創造力:模型在訓練過程中可能學習到了豐富的知識,并能夠將這些知識嵌入到生成的回答中。這使得模型能夠展示出一定的想象力和創造力,生成豐富多樣的文本,并提供更加富有表現力的回復。大型語言模型可以通過知識圖譜、外部知識庫等輔助信息,加深對知識的理解和應用。它可以從知識庫中檢索和整合信息,豐富回答的內容和準確性。
社交和情感智能:大型語言模型可以對情感和情緒進行理解和生成。它可以識別和表達情感色彩,并與用戶進行情感交流和互動,從而提供更加個性化和情感化的回復。涌現還可能表現為模型能夠根據上下文進行適應性回復,并生成多樣性的輸出。模型可以根據對話的進行和用戶的需求,靈活地調整回復的風格和內容,提供更加個性化和多樣化的回答。在處理復雜對話和語境理解方面,模型可能展現出更強的能力。它可以從多個回合的對話中提取關鍵信息,并進行語義上的深入理解,從而給出更加準確和連貫的回復。
傾向性調控和自我監控:大型語言模型可能具備一定的傾向性調控和自我監控能力。它可以根據用戶的需求和要求,調整回復的傾向性和風格,并對自己的輸出進行監控和評估,以確保回復的質量和合理性,并堅守某些原則,不會被使用者欺騙而給出違反基本價值觀和傷害人類的回復。
多模態能力:大型語言模型不僅可以處理文本輸入,還可以與其他模態數據(如圖像、語音、視頻等)進行交互。模型可以通過學習多模態數據的表示和關聯,展現出理解和生成多模態內容的能力。
增量學習和在線學習:大型語言模型可以具備增量學習和在線學習的能力,即在不中斷模型服務的情況下,通過逐步接受新數據進行訓練和更新,以不斷改進模型的性能和適應新領域的需求。
增強學習:大型語言模型可以結合增強學習技術,在與環境進行交互的過程中,通過試錯和獎勵機制來改進模型的表現。這使得模型能夠在特定任務或領域中進行優化和自我調節。
跨任務遷移:大型語言模型在完成一個任務的訓練后,可以通過遷移學習的方式將學到的知識和模型參數應用到其他相關任務上,從而加速其他任務的訓練和提升性能。
元學習和自適應學習:大型語言模型可以通過元學習和自適應學習的方法,快速適應新的任務或環境。模型可以從先前的訓練和經驗中快速學習到新任務的模式和規律,從而實現快速上手和靈活應對新情境的能力。
6. 微調:強化學習是要尋求特定領域的最優解
如果我們的最初目的就是希望ChatGPT就是和我們侃大山,天馬行空,停留在所謂的通用模型的狀態,可能我們不會進入到微調和調優階段。但如果我們是完美主義者,我們希望ChatGPT可以在很多有最優解的問題上能回答得很完美,強化學習就用的上了。
而無監督學習的硬傷就是通常是通過最大化數據的某種統計屬性來學習模型。以一種通用的方式學習數據的分布和特征,缺乏領域或任務特定信息,說白了就是萬金油之后,容易產生不必要的瞎聯系,或者說一本正經地胡說八道。
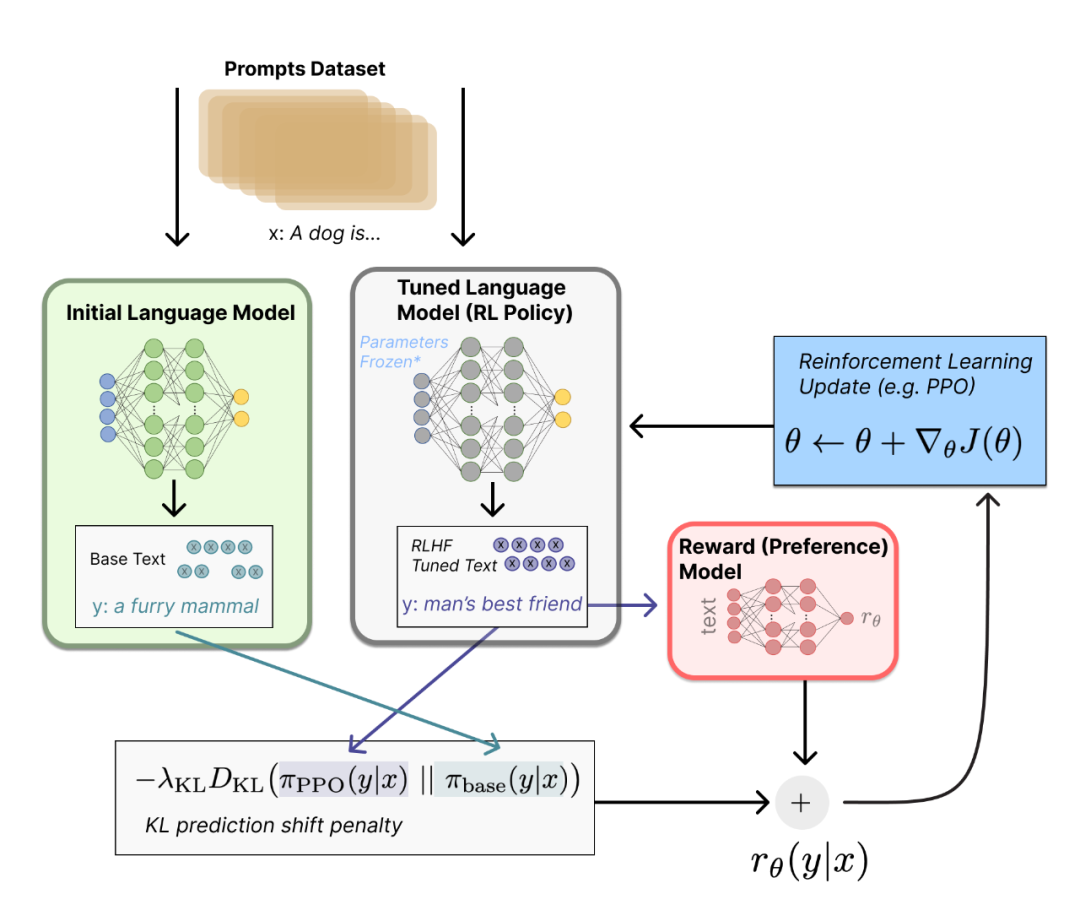
要想讓ChatGPT在很多專業領域表現出色,基于人類反饋的強化學習(RLHF,Reinforcement Learning from Human Feedback)訓練的微調和調優就顯得格外重要。RLHF在模型預訓練的基礎上,通過與人類進行交互,收集人類專家的反饋信息,以指導模型的微調和調優。通過將人類專家的知識和判斷引入模型訓練過程中,可以根據人類反饋的獎勵信號對模型進行優化,使模型能夠在特定環境下做出“最優決策”。我之所以在這里給“最優策略”打引號,是因為這是在部分專家反饋基礎上的最優策略。如果我們加大人類專家反饋的力度,花費更大的成本進行微調,可能最終的效果會更為理想,到這個階段,就不是純技術問題,而上升為一個密集勞動型的動作了。RLHF的一個主要問題是可擴展性,即如何應對大規模的訓練數據和計算資源需求。此外,這種訓練過程可能是緩慢且昂貴的,需要耗費大量的時間和資源。也正是由于這個原因,OpenAI更愿意把這部分能力通過API或者Plugin插件開放出來,眾人拾柴火焰高, 讓更多的垂直領域的產業發揮作用,在各自的領域深耕。經過這種微調后,GPT的專業領域技能就會越來越豐富,越來越優秀。
微調和調優還有一個很重要的點就是價值學習。AI系統如何與人類價值觀保持一致,能夠在復雜的動態環境中與人類價值觀對齊,符合人類倫理、法律準則并尊重個人隱私和防止壞人用AI進行欺詐。這就需要不停地對AI進行微調和調優,來完善和修訂在實際運作中的各種漏洞和表現。從這個維度來看,微調和調優是一個永無止境的工作,不存在一勞永逸。當然,這里面還存在另外一個風險,就是人類反饋的質量和一致性可能會因任務、界面和個體偏好的差異而有所不同。如果人類反饋缺乏公正性或不正確,那么模型也有可能學到錯誤的東西,這種情況被稱為人工智能偏見。特別是當反饋來自具有特定價值觀的人群時,這種偏見可能表現得尤為明顯。如果最終模型的使用人群范圍的復雜度遠遠大于RLHF的單一價值觀,就會出現非常糟糕的使用體驗。所以微調和調優,也是一個雙刃劍,如果處理不好,害人害己。
7. 大模型訓練的未來:“滅霸”還是“女媧”
大模型的訓練當前的基本流程,未來一定是會調整的。因為當下,大模型的“煉丹”是離線學習,也稱為批量學習(Batch learning),使用固定的數據集進行訓練和學習,而不是在實時數據流中進行更新。而未來是一定要走到在線學習(Online learning)的道路上的,能夠在不斷到達的數據流中進行實時學習和適應。只有后者,才有可能成為真正的通用人工智能,適應人類社會的高速發展的實時性,更好地應對動態和快速變化的環境。
所以說,即便演進到通用人工智能,對這個模型的訓練,也是一條永無止盡的路。只要人類社會還在進化,通用人工智能就需要考慮如何跟進人類的集體智能,不停地將新學到的人類只是和技能遷移到新任務或領域中。
而且未來大模型的交互或者表達的手段會更加多模態化,不僅僅局限在文字、圖形。因此,大模型的訓練必然會整合不同領域的知識和技術,包括自然語言處理、計算機視覺、語音識別等,以構建多模態學習的能力。
當然,我們仍需要謹慎樂觀,如果未來要面對人機共生,就需要慎重面對強化道德倫理和人工智能政策,因為我們要創造的不是滅霸的響指,而是女媧造人和盤古開天。
-
開源技術
+關注
關注
0文章
389瀏覽量
7914 -
OpenHarmony
+關注
關注
25文章
3662瀏覽量
16159
原文標題:河套IT TALK95:(原創)GPT技術揭秘:大模型訓練會導向滅霸的響指嗎?
文章出處:【微信號:開源技術服務中心,微信公眾號:共熵服務中心】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

深信服發布安全GPT4.0數據安全大模型
大語言模型的預訓練
llm模型和chatGPT的區別
人臉識別模型訓練是什么意思
OpenAI揭秘CriticGPT:GPT自進化新篇章,RLHF助力突破人類能力邊界
【大語言模型:原理與工程實踐】大語言模型的預訓練
【大語言模型:原理與工程實踐】大語言模型的基礎技術
【大語言模型:原理與工程實踐】核心技術綜述
【大語言模型:原理與工程實踐】揭開大語言模型的面紗
揭秘大語言模型可信能力的五個關鍵維度
OpenAI GPT 商店即將亮相,SpaceX 新型 Starlink 衛星發射上天






 工商網監
工商網監
評論