") 37年歷史的PostgreSQL數(shù)據庫將進行重大架構變更
37年歷史的PostgreSQL數(shù)據庫將進行重大架構變更
在瞬息萬變的開源世界中,軟件項目來得快、去得也快。如今獲得廣泛追捧的工具,很可能在短時間后就被更好的成果取代,再也無人問津。但即使在這樣殘酷的環(huán)境下,也有不少項目能夠長期保持生命力。
PostgreSQL 數(shù)據庫系統(tǒng)就是其中的典型,其歷史可以追溯到 1986 年的伯克利 POSTGRES 項目。經過幾十年的發(fā)展,作為一款跨平臺、免費和開源的數(shù)據庫軟件,PostgreSQL 應用已經相當廣泛:根據 Stack Overflow 2023 開發(fā)者調查數(shù)據顯示,PostgreSQL 甚至超越了 MySQL,成為開發(fā)人員首選。
對擁有如此悠久歷史的大型代碼庫做根本性變更絕非易事,但項目開發(fā)團隊正在認真考慮這種可能性,希望讓 PostgreSQL 脫離長久以來的面向進程模型。
任何 PostgreSQL 實例都是以大量協(xié)作進程的形式保持運行,其中包含一個用于所有接入客戶端的進程。這些進程使用精心設計的庫通過多個共享內存區(qū)域進行彼此通信,而這個庫的作用就是在內存設置各異、映射地址不同的所有進程之間建立起復雜的數(shù)據結構。
多年以來,這套模型一直兢兢業(yè)業(yè)地支撐整個項目。但隨著項目發(fā)展,現(xiàn)實世界正在發(fā)生巨大變化。因此,PostgreSQL 開發(fā)團隊意識到必須盡快調整、順應現(xiàn)實的潮流。
一份提案
今年 6 月初,Heikki Linnakangas 在經過一系列線下討論之后,發(fā)布了將 PostgreSQL 轉為線程模型的提案。

我覺得現(xiàn)在大家已經達成了強烈共識,比以往任何時候都更支持這項重大調整。實現(xiàn)這個目標需要投入大量精力、討論很多細節(jié),但團隊高層對這個基本思路沒有異議。 這封電子郵件的發(fā)布,就是想把這種沉默的共識變成明確的發(fā)展路線。
其中簡要概括了這項遷移所涉及的種種挑戰(zhàn),并低調地承認轉化過程“肯定無法通過單一版本徹底完成”。但郵件中沒有提到推動這項重大變更的原因,好在隨著討論的進行,相關信息很快得到了補充。正如 Andres Freund(PostgreSQL Developer & Committer,EnterpriseDB 高級數(shù)據庫架構師)指出的那樣:
我認為原有流程模型開始產生諸多限制,這個問題在大型設備上體現(xiàn)得尤其明顯。跨進程上下文切換所帶來的開銷,原本就比在同一進程內的不同線程間切換要更高——我估計這種開銷還將持續(xù)提升。面對大量連接,整個體系最終一定會因 TLB 未命中而浪費大量時間。這是進程模型無法跨進程共享 TLB 的天然屬性造成的必然結果。
他還提到,進程模型也增加了開發(fā)成本,迫使項目不得不維護大量重復代碼,包括在同一地址空間內保留本不必要的多種內存管理機制。在隨后的消息中,他還補充稱由于線程全部運行在同一地址空間之內,因此可以更高效地實現(xiàn)狀態(tài)共享。

但有部分開發(fā)人員反映,Linnakangas 所說的“強烈共識”可能并沒有那么強烈。Postgres 的主要貢獻者 Tom Lane 表示,“我認為這將是一場災難,大量原有代碼將受到影響。”他隨后補充稱,此次調整將帶來“巨大”成本,產生“不止一個安全級 bug”,也無法證明其收益超過成本投入。有人提出,目前還有其他一些高優(yōu)先級工作值得早做打算。也有人擔心隨著進程模型被淘汰,原本基于各獨立進程的隔離性將被打破,導致系統(tǒng)的整體健壯性受到破壞。
盡管如此,大部分 PostgreSQL 開發(fā)者還是以謹慎樂觀的態(tài)度支持、至少愿意嘗試這一改動。EnterpriseDB 副總裁、首席數(shù)據庫科學家,PostgreSQL 主要貢獻者 Robert Haas 表示,PostgreSQL 在大型系統(tǒng)上的擴展性確實不佳,主要就是因為所有進程都在消耗資源。“其他很多數(shù)據庫并不存在這個問題。如果不進行某種重大的架構變更,PostgreSQL 將無法克服這個難題。”
也許單純轉向線程模型可能還不夠,但他認為這將為其他后續(xù)改進開個好頭。
從提案到現(xiàn)實
將 PostgreSQL 服務器的核心轉移至單一地址空間,幾乎必然帶來諸多挑戰(zhàn)。正如 Haas 等研究人員所指出,其中最大的問題就是服務器“目前正頻繁使用全局變量”。具體來講,當每個服務器進程都擁有自己的集合時,全局變量就能良好運作;而在用線程加以替代時則會引發(fā)問題。根據 Konstantin Knizhnik 的說法,PostgreSQL 服務器目前使用約 2000 個全局變量。
開發(fā)團隊隨后討論了該問題的幾種解決思路。首先是將所有全局變量拉入統(tǒng)一的“會話狀態(tài)”結構,而這套結構具備線程本地化屬性。但考慮到需要創(chuàng)建并維護的是需要容納 2000 個變量成員的復雜結構時,這個提議因為可行性太低而很快失去了吸引力。另一種方法是直接把所有全局變量放入線程本地存儲內,這種方法倒是簡單可行,但大量使用線程本地存儲會導致性能損失,損耗轉為線程模型帶來的收益。Haas 指出,對全局變量做明確標記(包括將其放入線程本地存儲)本身也有積極的意義,可說為減少全局變量的使用開了個好頭。Freund 贊同這個觀點,并表示即使后續(xù)沒有全面轉向線程模型,這項調整也將有所回報。
但 Freund 也警告稱,將全局變量轉移至線程本地存儲只是這項工作中最簡單的部分:
在此之后,重新設計 postmaster、定義如何處理擴展庫、擴展兼容性、開發(fā)工具以實現(xiàn)線程化 postgres、在會話生命周期內建立新的內存分配和釋放機制(以往是通過退出進程實現(xiàn)內存釋放)、保證變更的可審查性和可移植性等等,全都是更加困難的工作。
這里還有一個討論熱度不高、但卻非常有趣的觀點,即 Knizhnik 已經完成了 PostgreSQL 的線程端口。他說全局變量的問題并不是那么難以解決。他在配置數(shù)據、錯誤處理、信號等方面遇到的麻煩還更多。另外,支持由外部維護的擴展也是個重大挑戰(zhàn)。可盡管如此,他還是認可轉向線程模型所帶來的一系列顯著回報,只是提醒項目決策層在采取任何行動之前,務必要認真做好研究分析。
PostgreSQL 開發(fā)團隊還想到了另一個復雜問題,即是否可能同時支持基于進程和基于線程兩種模式。在繼續(xù)支持進程模式的同時引入線程架構不僅極為困難,而且會顯著增加項目的總體維護負擔。但 Haas 堅持認為,PostgreSQL 絕對不可能徹底放棄對進程模式的支持。畢竟線程在一部分用例中的性能反而更差,也有不少重要擴展無法在線程模式下正常運行。他強調稱,只有在確認線程架構運行良好之后,才可能認真討論要不要徹底放棄進程支持。
目前無論是從郵件討論還是從社交媒體平臺投票結果來看,大多數(shù) PostgreSQL 開發(fā)者認同架構轉換的理論收益。
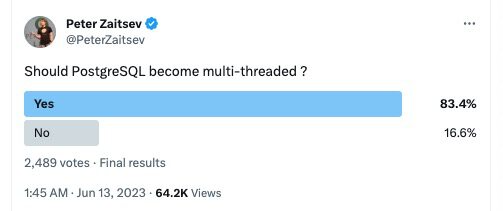
并且,數(shù)據庫管理系統(tǒng) Peloton 早在 2015 年就已經嘗試讓 PostgreSQL 多線程化了。至于 PostgreSQL 本身,從討論到具體實施落地還有很長的路要走,更重要的是,需要有人主動請纓、表示愿意投入時間來推進這項工作。
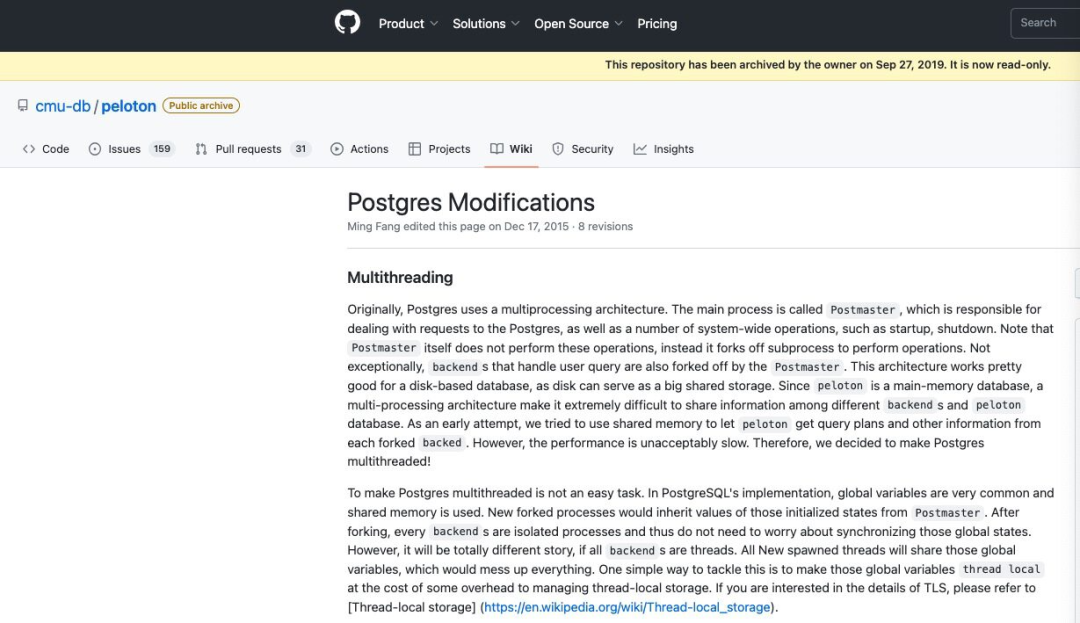
Peloton 的《Postgres 架構變更公告》:
最初,Postgres 采用的是多進程架構。其中主進程名為 Postmaster,負責處理 Postgres 接收到的請求,以及啟動、關閉等系統(tǒng)層面的操作。請注意,Postmaster 本身并不執(zhí)行這些操作,而會派生出子進程來執(zhí)行操作。再有,處理用戶查詢的 backend 也是由 Postmaster 分叉而來。這種架構非常適合基于磁盤的數(shù)據庫,因為磁盤可以作為大容量共享存儲。由于 peloton 充當主內存數(shù)據庫,多進程架構導致不同后端和 peloton 數(shù)據庫間的信息共享變得極其困難。在早期的嘗試中,我們曾考慮用共享內存讓 peloton 從每個分叉的 backend 處獲取查詢計劃和其他信息。但結果證明其性能慢得令人無法接受,因此我們最終決定將 Postgres 轉為多線程架構!
-
數(shù)據庫
+關注
關注
7文章
3766瀏覽量
64277 -
架構
+關注
關注
1文章
510瀏覽量
25447 -
MySQL
+關注
關注
1文章
802瀏覽量
26445
原文標題:這將是一場災難?37年歷史的PostgreSQL數(shù)據庫將進行重大架構變更
文章出處:【微信號:AI前線,微信公眾號:AI前線】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
數(shù)據庫數(shù)據恢復—通過拼接數(shù)據庫碎片恢復SQLserver數(shù)據庫

數(shù)據庫數(shù)據恢復—SQL Server數(shù)據庫出現(xiàn)823錯誤的數(shù)據恢復案例

恒訊科技分析:跨境電商網站有哪些數(shù)據庫系統(tǒng)是推薦使用的?
恒訊科技分析:sql數(shù)據庫怎么用?
華為云多模數(shù)據庫 GeminiDB 架構與應用實踐直播問答實錄
PostgreSQL數(shù)據庫連接報錯故障分析
GSMA最新資訊:IMEI數(shù)據庫平臺品牌更新與鏈接地址變更告知

【數(shù)據庫數(shù)據恢復】Oracle數(shù)據庫ASM實例無法掛載的數(shù)據恢復案例
2024年,國產數(shù)據庫正醞釀新變局!
數(shù)據庫數(shù)據恢復—未開啟binlog的Mysql數(shù)據庫數(shù)據恢復案例

常見的存儲Idea數(shù)據庫的地方
關于JSON數(shù)據庫

oracle數(shù)據庫的基本操作
什么是JSON數(shù)據庫






 工商網監(jiān)
工商網監(jiān)
評論