 ChatGLM2-6B:性能大幅提升,8-32k上下文,推理提速42%,在中文榜單位列榜首
ChatGLM2-6B:性能大幅提升,8-32k上下文,推理提速42%,在中文榜單位列榜首
自3月14日發布以來, ChatGLM-6B 深受廣大開發者喜愛,截至 6 月24日,來自 Huggingface 上的下載量已經超過 300w。
為了更進一步促進大模型開源社區的發展,我們再次升級 ChatGLM-6B,發布 ChatGLM2-6B 。
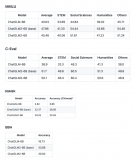
在主要評估LLM模型中文能力的 C-Eval 榜單中,截至6月25日 ChatGLM2 模型以 71.1 的分數位居 Rank 0 ,ChatGLM2-6B 模型以 51.7 的分數位居 Rank 6,是榜單上排名最高的開源模型。
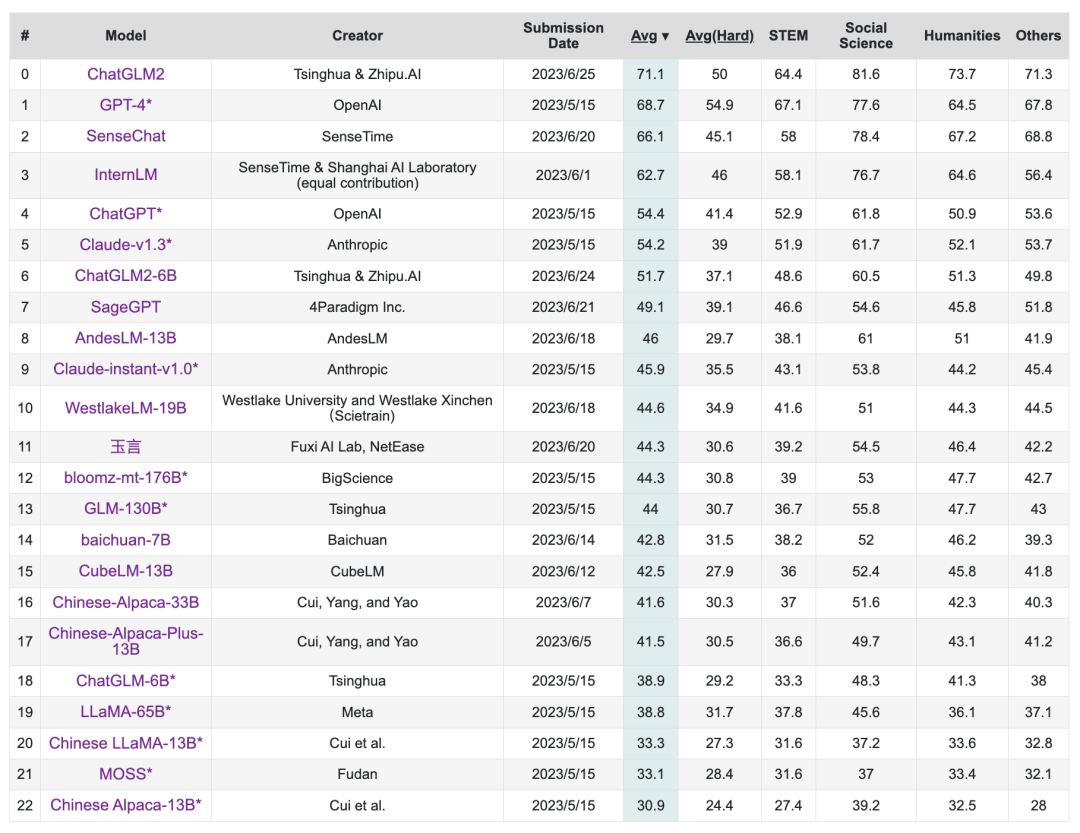
* CEval榜單,ChatGLM2暫時位居Rank 0,ChatGLM2-6B位居 Rank 6
性能升級
ChatGLM2-6B 是開源中英雙語對話模型 ChatGLM-6B 的第二代版本,在保留了初代模型對話流暢、部署門檻較低等眾多優秀特性的基礎之上,ChatGLM2-6B 引入了如下新特性:
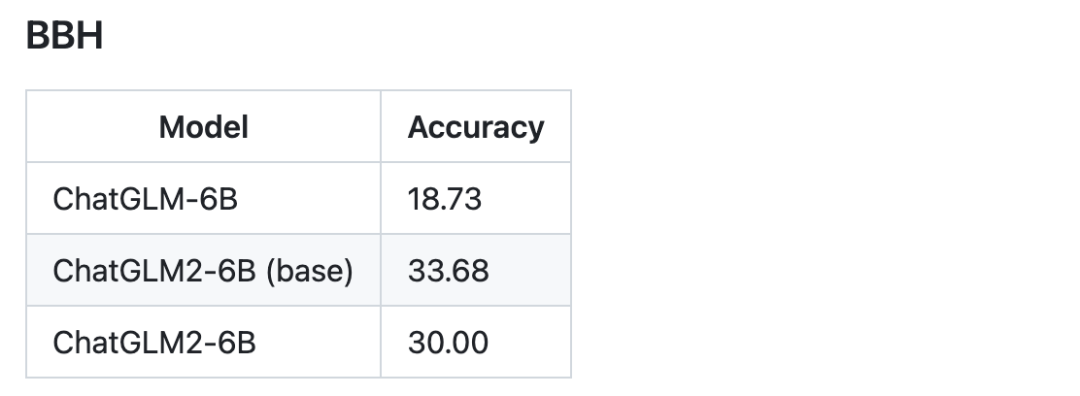
更強大的性能:基于 ChatGLM 初代模型的開發經驗,我們全面升級了 ChatGLM2-6B 的基座模型。ChatGLM2-6B 使用了 GLM 的混合目標函數,經過了 1.4T 中英標識符的預訓練與人類偏好對齊訓練,評測結果顯示,相比于初代模型,ChatGLM2-6B 在 MMLU(+23%)、CEval(+33%)、GSM8K(+571%) 、BBH(+60%)等數據集上的性能取得了大幅度的提升,在同尺寸開源模型中具有較強的競爭力。
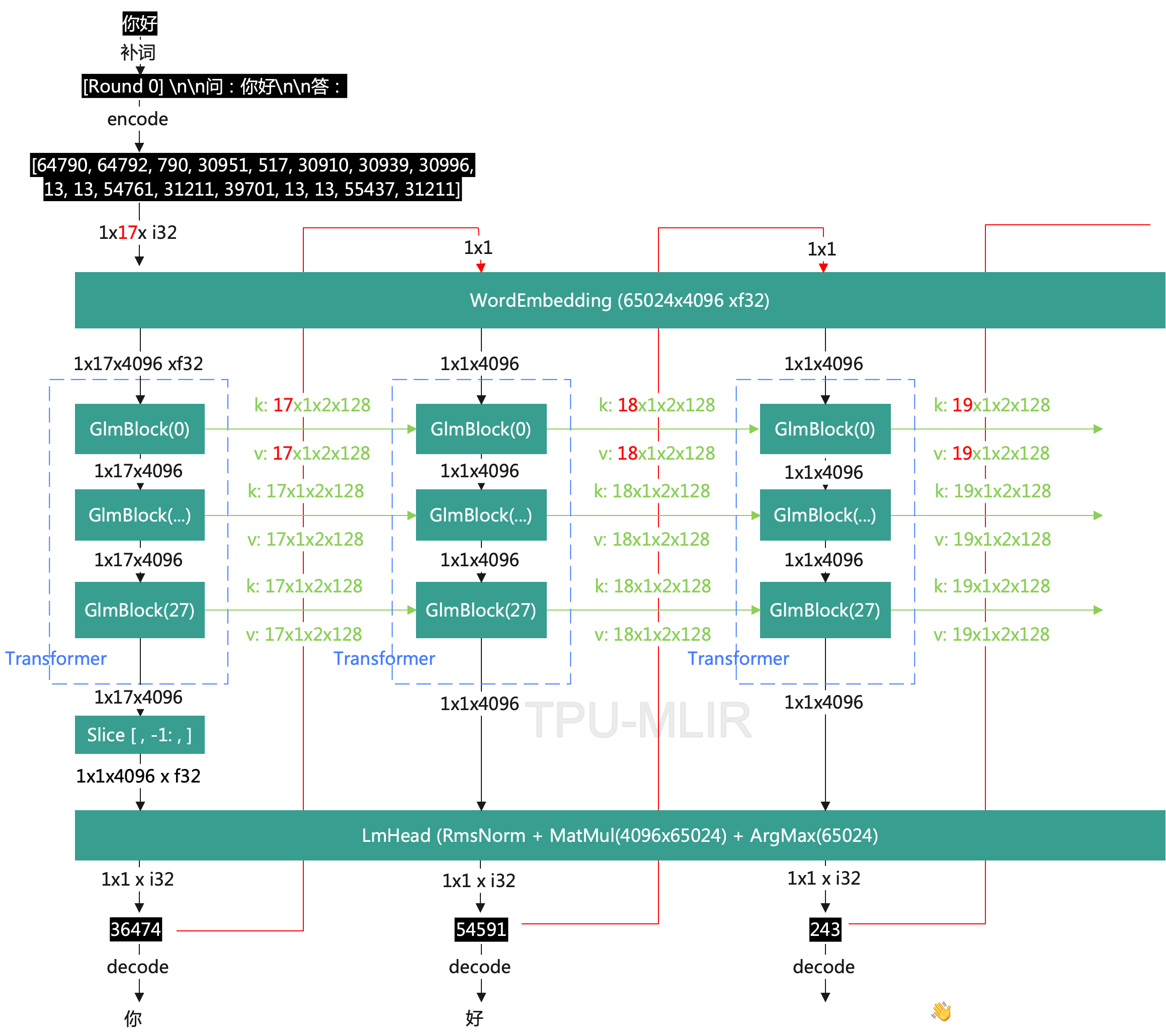
更長的上下文:基于 FlashAttention 技術,我們將基座模型的上下文長度(Context Length)由 ChatGLM-6B 的 2K 擴展到了 32K,并在對話階段使用 8K 的上下文長度訓練,允許更多輪次的對話。但當前版本的 ChatGLM2-6B 對單輪超長文檔的理解能力有限,我們會在后續迭代升級中著重進行優化。
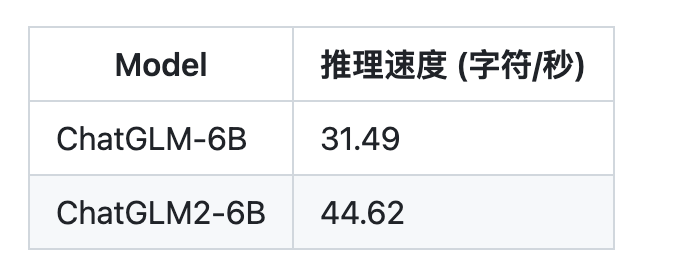
更高效的推理:基于 Multi-Query Attention 技術,ChatGLM2-6B 有更高效的推理速度和更低的顯存占用:在官方的模型實現下,推理速度相比初代提升了 42%,INT4 量化下,6G 顯存支持的對話長度由 1K 提升到了 8K。
更開放的協議:ChatGLM2-6B 權重對學術研究完全開放,在獲得官方的書面許可后,亦允許商業使用。如果您發現我們的開源模型對您的業務有用,我們歡迎您對下一代模型 ChatGLM3 研發的捐贈。
評測結果
我們選取了部分中英文典型數據集進行了評測,以下為 ChatGLM2-6B 模型在 MMLU (英文)、C-Eval(中文)、GSM8K(數學)、BBH(英文) 上的測評結果。
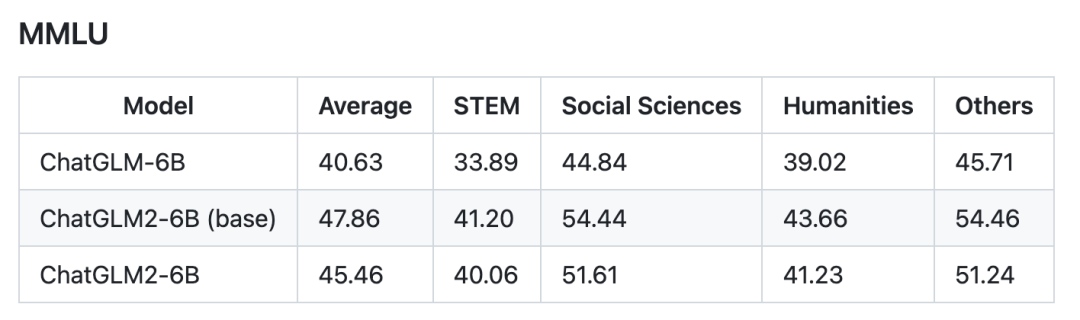
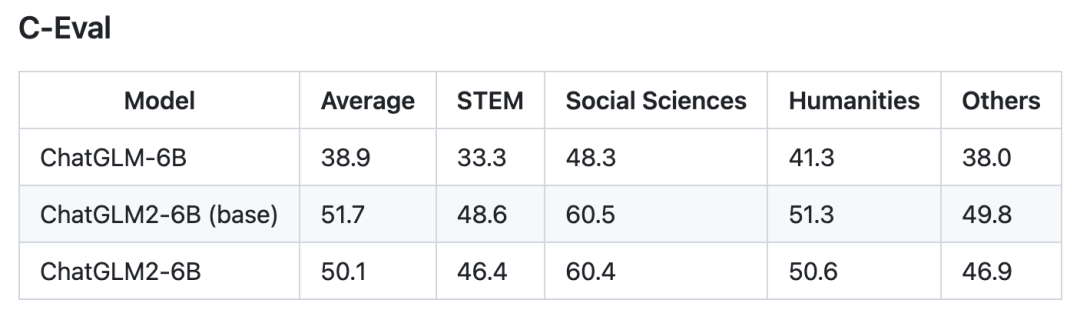
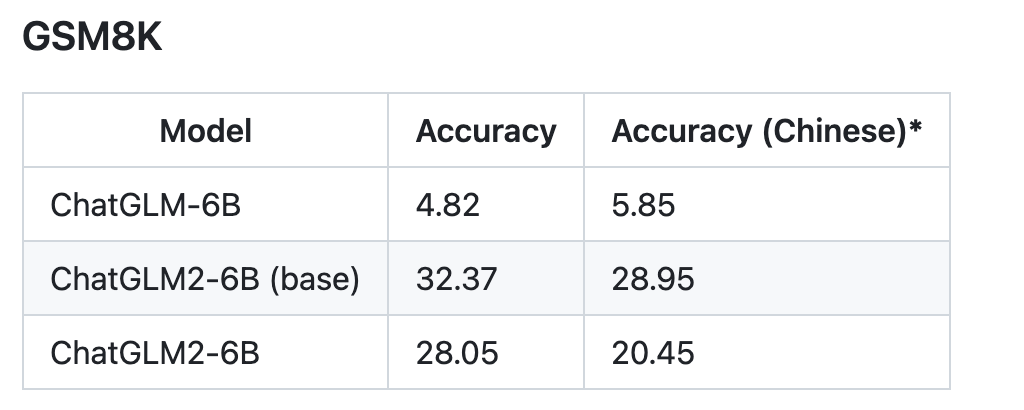
推理性能
ChatGLM2-6B 使用了 Multi-Query Attention,提高了生成速度。生成 2000 個字符的平均速度對比如下
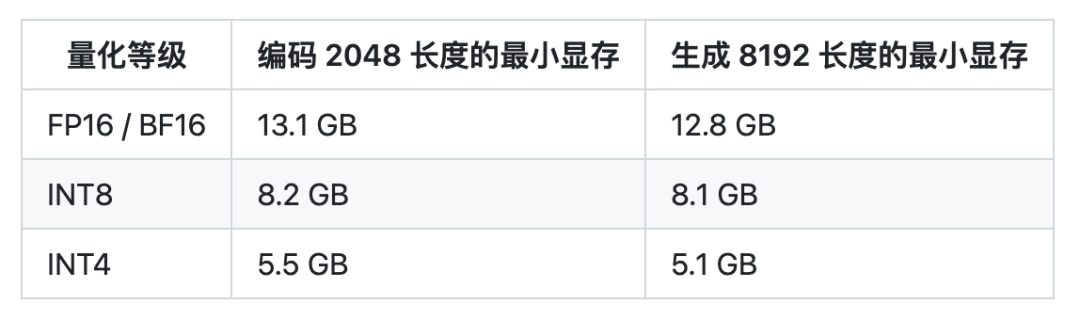
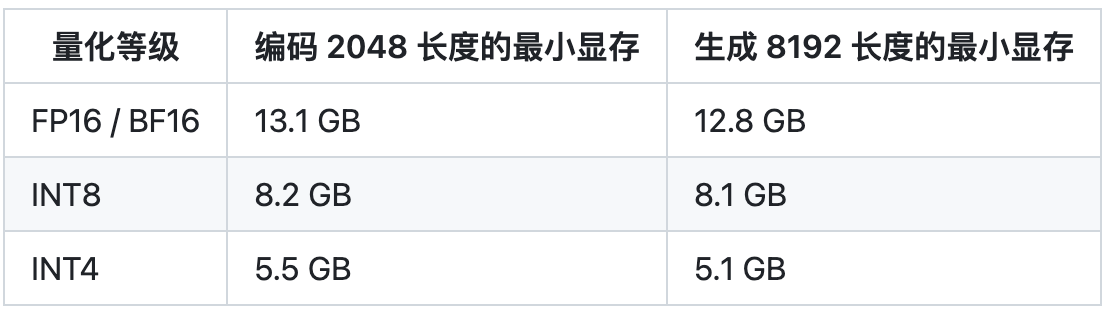
Multi-Query Attention 同時也降低了生成過程中 KV Cache 的顯存占用,此外,ChatGLM2-6B 采用 Causal Mask 進行對話訓練,連續對話時可復用前面輪次的 KV Cache,進一步優化了顯存占用。因此,使用 6GB 顯存的顯卡進行 INT4 量化的推理時,初代的 ChatGLM-6B 模型最多能夠生成 1119 個字符就會提示顯存耗盡,而 ChatGLM2-6B 能夠生成至少 8192 個字符。
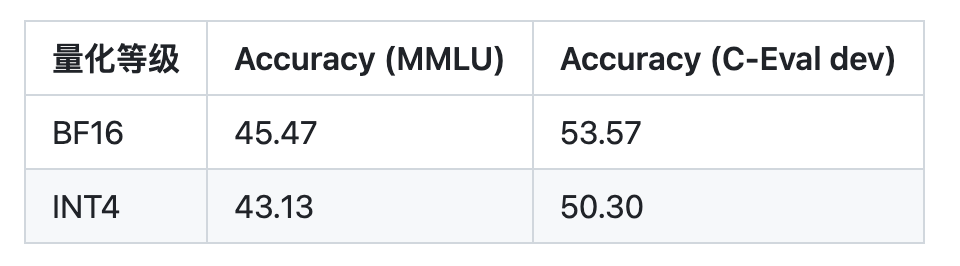
我們也測試了量化對模型性能的影響。結果表明,量化對模型性能的影響在可接受范圍內。
示例對比
相比于初代模型,ChatGLM2-6B 多個維度的能力都取得了提升,以下是一些對比示例。更多 ChatGLM2-6B 的可能,等待你來探索發現!
數理邏輯
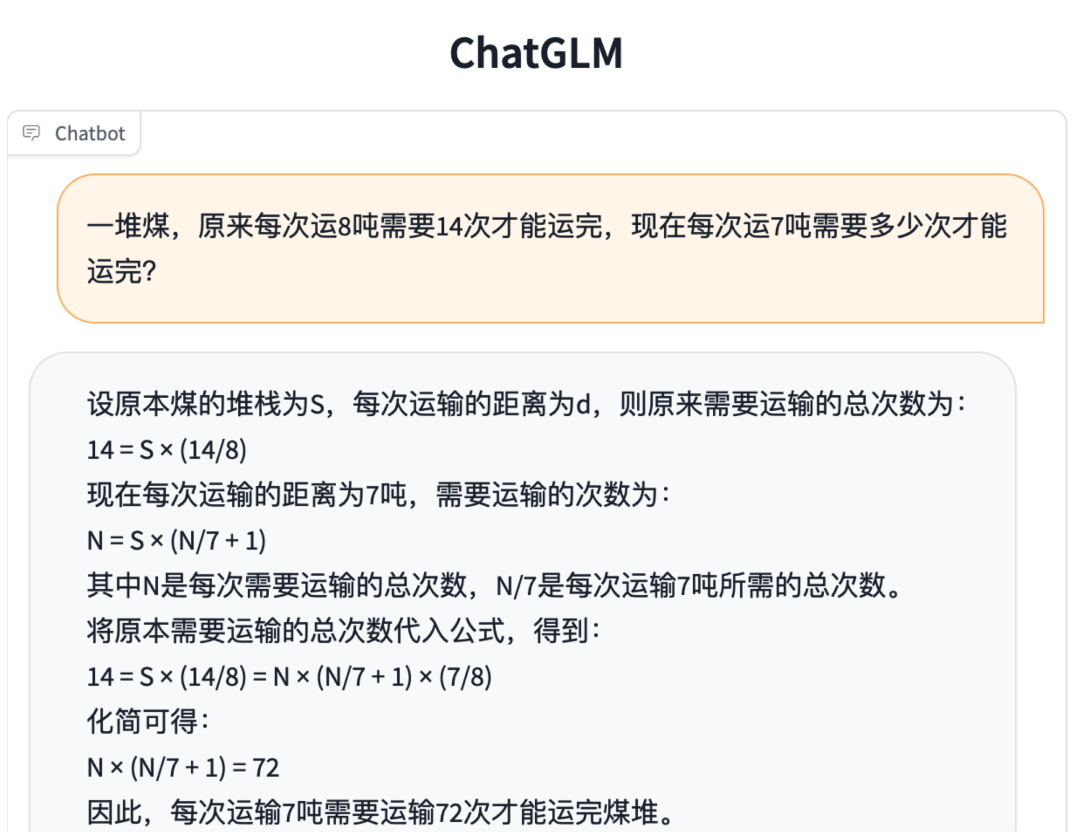
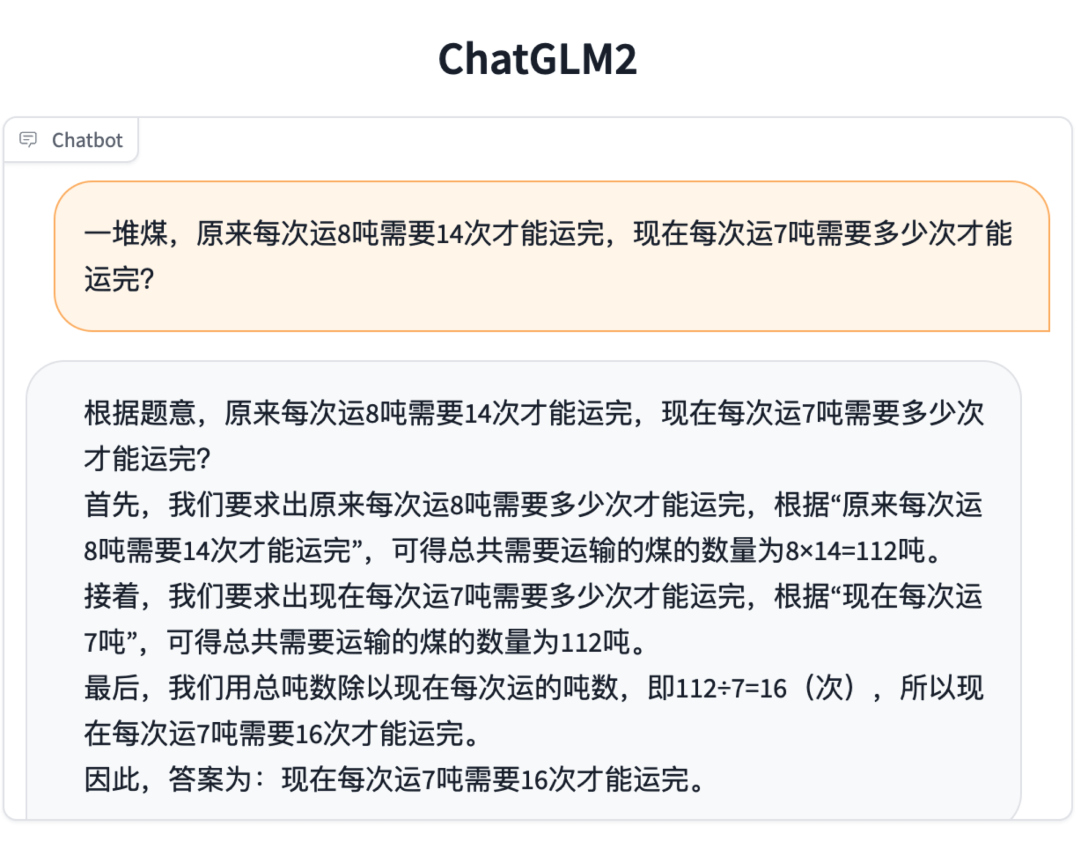
知識推理
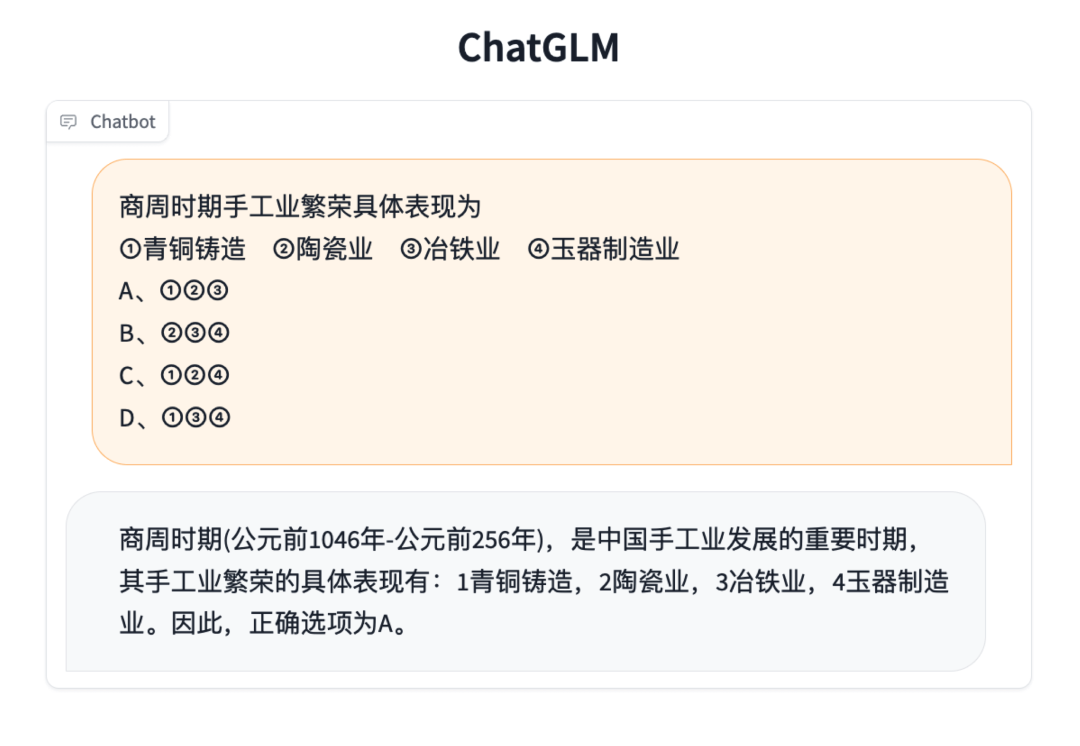
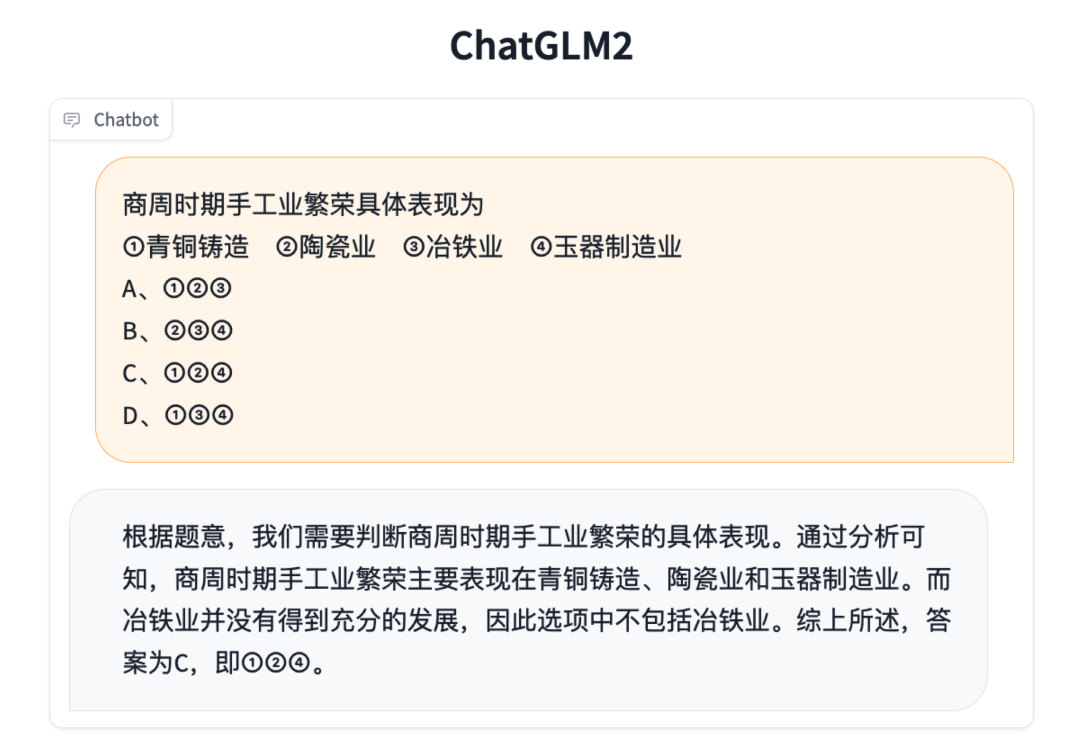
長文檔理解


ChatGLM2-6B的安裝請參考官方:
https://github.com/THUDM/ChatGLM2-6B
-
開源
+關注
關注
3文章
3245瀏覽量
42396 -
模型
+關注
關注
1文章
3171瀏覽量
48711 -
數據集
+關注
關注
4文章
1205瀏覽量
24641
原文標題:ChatGLM2-6B:性能大幅提升,8-32k上下文,推理提速42%,在中文榜單位列榜首
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
關于進程上下文、中斷上下文及原子上下文的一些概念理解
進程上下文與中斷上下文的理解
基于交互上下文的預測方法
基于Pocket PC的上下文菜單實現
基于Pocket PC的上下文菜單實現
基于上下文相似度的分解推薦算法
如何分析Linux CPU上下文切換問題
切換k8s上下文有多快

下載量超300w的ChatGLM-6B再升級:8-32k上下文,推理提速42%
探索ChatGLM2在算能BM1684X上INT8量化部署,加速大模型商業落地

全新近似注意力機制HyperAttention:對長上下文友好、LLM推理提速50%





 工商網監
工商網監
評論