 生成式AI搭臺,Data+Analytics唱戲: Snowflake、Databricks 2023年度大會前瞻
生成式AI搭臺,Data+Analytics唱戲: Snowflake、Databricks 2023年度大會前瞻
編者按:
每年仲夏之際,全球兩大數據平臺巨頭 Snowflake、Databricks 均會召開各自的年度大會,成為數據圈的“超級碗”。隨著競爭的加劇,Snowflake、Databricks 把 2023 年度重磅市場大會放在相同日期(6.26-6.29),充滿著火藥味。大會召開在即,云器科技作為專注數據領域的創業公司,策劃一系列文章,從主題演講、重點發布、客戶案例等方面對比和解讀這兩個年度大會。本文是第一篇,對兩個大會做前瞻對比,并預測最值得聽的場。
發布會 Snowflake 搶到最重磅嘉賓, 但 Databricks 在生成式 AI 方向布局更早
Snowflake 和 Databricks 的 2023 年度市場大會都是在 6 月 26 日至 29 日舉行,但地點不同,前者在拉斯維加斯,后者在舊金山。為了緊扣熱點更吸引眼球,兩家公司的大會主題都與 AI 和大模型有關,并邀請了重量級的嘉賓,Snowflake 請到了英偉達 CEO 黃仁勛,Databricks 請到了微軟 CEO 薩蒂亞·納德拉。
布局方面,主打 Data+AI 口號的 Databricks 顯然更面向 AI,也布局更早。主推的 Lakehouse 湖倉一體架構天然更支持 AI 存儲和計算,之后收購了由前 Google LLC 和 Dropbox Inc. 工程師創立的 AI 存儲公司 Rubicon Inc. 近期推出自己的大語言開源模型 Dolly 和 Dolly 2.0。Databricks 將 Data+AI 的口號走的很徹底。而 Snowflake 去年年度大會的最重磅發布是收購 Streamlit 并面向數據應用構建生態,直到大語言模型火爆之后,才收購了 Neeva.ai(智能搜索公司),開始其在這個領域的布局。
展示各自的優勢和差異化: Snowflake 和 Databricks 在產品和技術上并不盡相同。
Snowflake 更專注于圍繞數據分析的數據倉庫和查詢處理,而 Databricks 更專注于數據科學和機器學習,本次大會兩方在努力突出他們在 Lakehouse 市場的優勢和差異化。據 Enterprise Technology Research 調研,36% 的 Snowflake 客戶同時也是 Databricks 的客戶,客戶也在同時使用獲得兩者最大化組合優勢(從 Snowflake 獲得分析的優勢,從 Databricks 獲得 AI 的優勢)。
從會議安排看,數據平臺是核心,AI 是噱頭
從會議的主題演講看,Snowflake 會繼續強調和推動DataCloud為核心的數據一體化和共享能力,基于Streamlit的一體化應用開發,以及生成式 AI 的可能性。特別值得一提的是,開源的Iceberg成為發布會介紹的關鍵字。在此,我們給出今年大會的一個合理猜測:Snowflake 會支持基于 iceberge 的開放數據架構,向湖倉一體邁進!

而反觀 Databricks 的主題演講,主線就非常明確且有持續性,重點強調三方面:LLM、Lakehouse Platform、OpenSource 軟件。LLM 是今年新增的熱點,也非常貼合 Data+AI 的定位。Lakehouse 經過 3 年持續推進,已經成為數據平臺的新標準。OpenSource 作為老牌領域,今年新增大量的生態話題,包括一度看作競對的 Presto/Trino 等。面對 Snowflake SaaS 化服務極致簡單的競爭壓力,Databricks 選擇聯合開源生態的力量。

兩會的主題演講都不約而同的強調生成式 AI,但如果看具體 session 組織,就會發現 AI 是噱頭,真正的主線依然在高速增長的數據平臺領域。(兩家今年均聲明 60% 的年化營收增長,在經濟整體下行的今天,數據平臺增長速度相當亮眼)。
Snowflake 年度發布會一共有 400 場 Session 之多,DataPlatform、DataApplication、DataAnalytics 是三個最大的主題,占據了一半的場次。ML/AI 相關的領域話題僅占 15%。考慮到 Snowflake 當前數據平臺“一哥”的位置,這種“守正 + 出奇”的會議安排就不讓人意外。
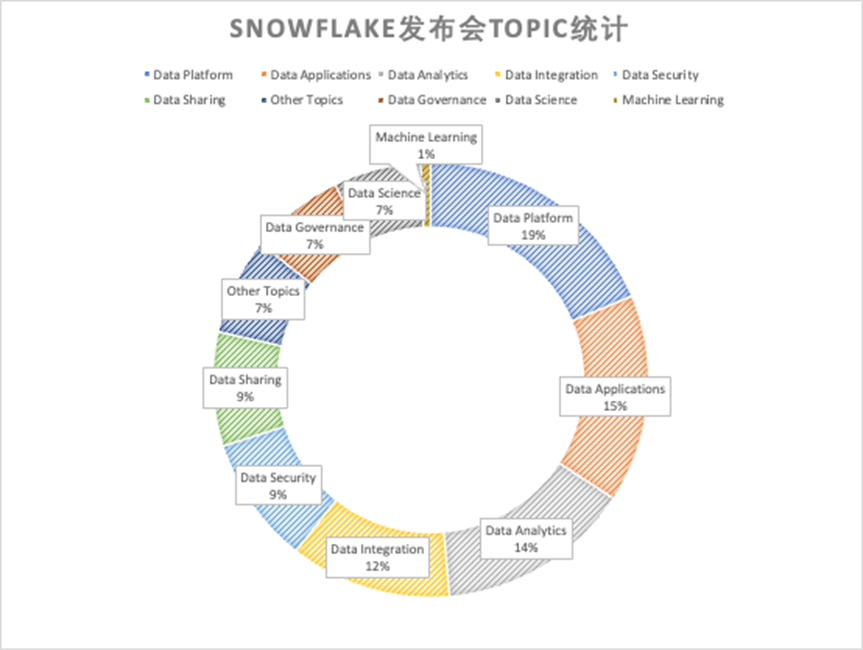
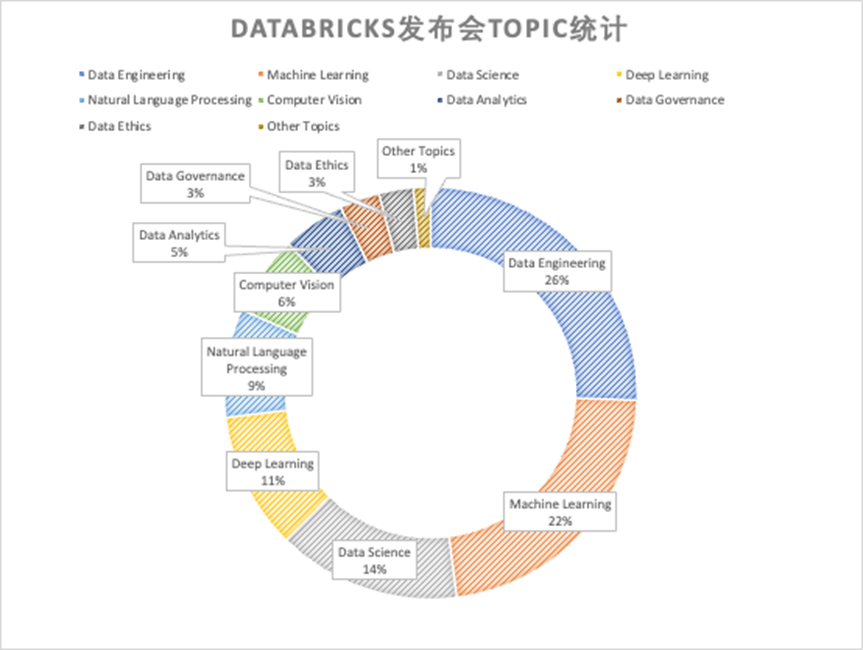
而 Databricks 的議題安排略顯不同。DataEngineering 作為主線占據 1/4 的議題,之后是 ML/DataScience 部分,要注意這里面的 ML/DataScience 并不僅僅是生成式 AI,而是包含了大量“傳統”的機器學習和算法部分(例如 SparkML)。特別的,在這些 session 的介紹中,Databricks 最重點強調的是 Lakehouse 架構對 AI 的支持,以及 Data+AI 的各種最佳實踐。Databricks 自己的大語言模型 dolly 并不是重點,真正宣傳 Dolly 的 session 僅有 3 個。
綜合起來看,盡管生成式 AI 是話題上的亮點,兩家不約而同的重點強調“自己的數據平臺能力本身和可擴展性,可以容易的集成生成式 AI 在內的多種計算模型”。
前瞻,兩個發布會最大看點在哪里?
結合筆者的經驗和發布會的內容,筆者大膽預測如下可能的方向演進和重磅發布:
Snowflake 的重點方向和重磅發布:
方向從數倉進一步轉型湖倉一體,改變封閉數倉的缺陷,發布支持基于 Iceberg 的開放數據格式。
發布內置的 AI 模型部署和推理能力,會更多的結合 LLM,通過 Snowflake 釋放 LLM 大型語言模型的力量。
Data + Application 一體化,推進 Operational Analytics。
Databricks 的重點方向和重磅發布:
借生成式 AI 的東風,繼續大力推進 Data+AI 的概念。同時借力對 AI 的支持,競爭 Snowflake(會有實際客戶案例比較 Databricks 和 Snowflake)
全鏈路實時化和增量化會成為重點方向(每天 40% 的 topic 與全鏈路實時增量化相關)
大幅增加企業級數據平臺能力的建設和宣傳(包括數據質量,數據加密這些 Databricks 的傳統弱項,這些 topic 占每天主題的 20%)
未來 AI 時代需要什么樣的數據平臺支撐?
看過上述對比和前瞻分析,讀者應該能感受到濃濃的火藥味,可見兩家的技術競爭已經是數據平臺全面或一體化綜合能力的競爭。
筆者認為,AI 大火的今天,我們更應該關注的焦點,還是應該回歸到支撐 AI 的基礎數據平臺能力,回歸到“支點”上。從兩方大會的日程安排上,也可以得到充分印證。
Snowflake 大會的支點由數據倉庫 + 數據安全 + 數據應用三個方向共計 400 多個 session 組成。數據倉庫強相關的話題是 Snowflake 的基本盤,而數據應用主題延續了 Snowflake 在 2022 年秋季 Build 大會上通過 Streamlit 構建應用的熱點,并增強了數據科學和機器學習的主題方向。
Databricks 大會的支點由 300 多個 session 構成,涵蓋了數據工程,數據科學,機器學習,深度學習,自然語言處理,計算機視覺,數據分析,數據治理,數據倫理等和 ETL/ELT 數據處理、數據科學等數據湖上場景更為密切的支點型主題方向。很明顯,Databricks 在泛 AI 領域對主題做了更多細分,包括機器學習、數據科學、深度學習、自然語言處理、計算機視覺。特別的一點是 Databricks 在數據倫理方面開辟了新的主題。
站在國內視角,也會激發我們思考數據平臺演進的脈絡。這里推薦這篇文章《從 Hadoop 到 Snowflake,2023 年數據平臺路在何方?_InfoQ 精選文章》的梳理。
盡管兩方大會的共同主旋律“通過 Data + 生成式 AI 重塑企業”,但筆者這里可以大膽預先總結一下兩個峰會的內容套路:“生成式 AI 搭臺,Data+Analytics 唱戲”。
我們會持續關注會議的進展,并同步報道最新情況,看上述預測是否準確,請大家持續關注。
-
AI
+關注
關注
87文章
30122瀏覽量
268407 -
語言模型
+關注
關注
0文章
506瀏覽量
10245 -
機器學習
+關注
關注
66文章
8377瀏覽量
132406 -
生成式AI
+關注
關注
0文章
487瀏覽量
459
原文標題:生成式AI搭臺,Data+Analytics唱戲: Snowflake、Databricks 2023年度大會前瞻
文章出處:【微信號:AI前線,微信公眾號:AI前線】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Databricks利用NVIDIA全棧解決方案加速生成式AI應用
Snowflake洽談收購Reka AI,進軍生成式AI領域
利爾達榮膺“2023年度中國物聯網企業100強”!

廣東電信攜手華為斬獲“2023年度SDN、NFV、網絡AI最佳實踐案例”

廣東移動攜手華為斬獲“2023年度SDN、NFV、網絡AI最佳實踐案例”

中創新航榮獲“2023年度江蘇高質量發展標桿企業”稱號

迅鐳激光2023年度表彰暨2024年度誓師大會順利召開!
比創達元啟新程 共創新佳績:2023年度總結暨迎新年晚會圓滿收官!a
國芯科技獲2023年度“優秀密碼應用方案獎“
華秋2023年度大事記~~

新年驚喜!蓋樓有獎~一起來見證華秋2023年度高光時刻吧
2023年度十大科技名詞







 工商網監
工商網監
評論