 單張圖像超分辨率和立體圖像超分辨率的相關工作
單張圖像超分辨率和立體圖像超分辨率的相關工作
多階段策略在圖像修復任務中被廣泛應用,雖然基于Transformer的方法在單圖像超分辨率任務中表現出高效率,但在立體超分辨率任務中尚未展現出CNN-based方法的顯著優勢。這可以歸因于兩個關鍵因素:首先,當前單圖像超分辨率Transformer在該過程中無法利用互補的立體信息;其次,Transformer的性能通常依賴于足夠的數據,在常見的立體圖像超分辨率算法中缺乏這些數據。為了解決這些問題,作者提出了一種混合Transformer和CNN注意力網絡(HTCAN),它利用基于Transformer的網絡進行單圖像增強和基于CNN的網絡進行立體信息融合。此外,作者采用了多塊訓練策略和更大的窗口尺寸,以激活更多的輸入像素進行超分辨率。作者還重新審視了其他高級技術,如數據增強、數據集成和模型集成,以減少過擬合和數據偏差。最后,作者的方法在NTIRE 2023立體圖像超分辨率挑戰的Track 1中獲得了23.90dB的分數,并成為優勝者。
1 前言
立體圖像超分辨的最終性能取決于每個視圖的特征提取能力和立體信息交換能力。相比于卷積神經網絡,變換器擁有更大的感受野和自我關注機制,可以更好地模擬長期依賴。但是,其內存和計算成本通常要高得多。因此,作者提出了一種混合架構,利用了變換器的強大長期依賴建模能力和卷積神經網絡的信息交換的有效性。在作者的方法中,作者首先使用變換器來保留重要特征,然后使用CNN方法進行信息交換。實驗結果表明,該混合架構具有較好的性能。
本文有以下三個貢獻:
一種混合立體圖像超分辨網絡。作者提出了一個統一的立體圖像超分辨算法,它集成了變換器和CNN架構,其中變換器用于提取單視圖圖像的特征,而CNN模塊用于交換來自兩個視圖的信息并生成最終的超分辨圖像。
全面的數據增強。作者對多補丁訓練策略和其他技術進行了全面研究,并將它們應用于立體圖像超分辨。
新的最先進性能。作者提出的方法實現了新的最先進性能,并在立體圖像超分辨挑戰賽的第一軌中獲得了第一名。
2 相關背景
本文這一節介紹了單張圖像超分辨率和立體圖像超分辨率的相關工作。針對單張圖像超分辨率,研究人員一開始使用外部圖像或樣本數據庫來生成超分辨圖像,手工制作的特征依賴于先驗知識/假設,并存在很多局限性。后來引入了基于CNN的方法,CNN網絡通過學習局部結構模式降低了計算成本。最近,基于Transformer的方法也受到越來越多的關注,因為它刪除了先前卷積模塊使用的局部性先知,并允許更大的接收場。對于立體圖像超分辨率,在以前的工作中,大多是從單張圖像超分辨率骨干出發的,并提出了通信分支來允許左右視圖之間的信息交換。然而,左右視圖之間的視差通常沿著基線而大于傳統卷積核的接收場。近年來,采用了與單張超分辨率類似的方法,引入了基于CNN和Transformer的方法,以修復立體圖像的超分辨率。
3 方法
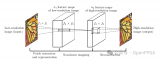
本節中,作者詳細介紹所提出的混合Transformer和CNN Attention網絡(HTCAN)。所提出的HTCAN是一個多階段的恢復網絡。具體而言,給定低分辨率的立體圖像Llr和Rlr,作者首先使用基于Transformer的單圖像超分辨率網絡將其超分辨到Ls1和Rs1。在第二階段,作者采用基于CNN的網絡來增強Ls1和Rs1的立體效果,并得到增強的圖像Lsr和Rsr。在第三階段,作者使用與第2階段相同的基于CNN的網絡進行進一步的立體增強和模型集成。
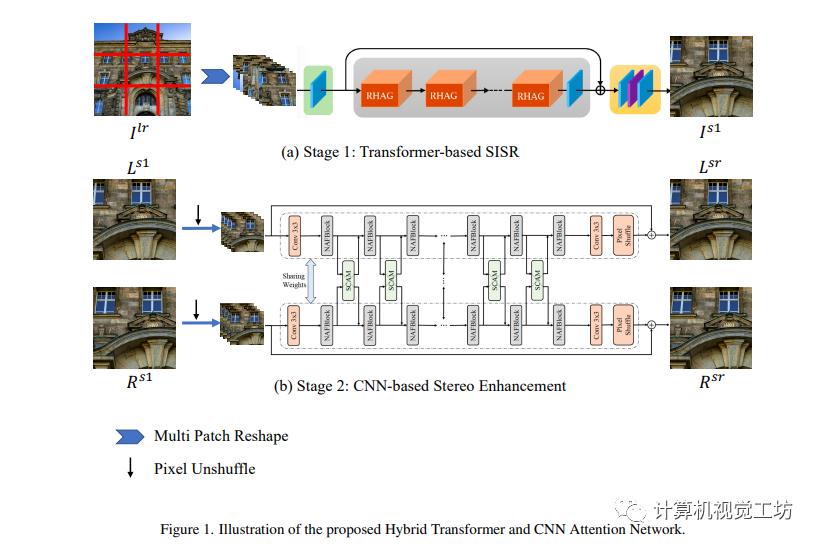
3.1 階段1: 基于Transformer的單圖像超分辨率網絡結構
作者提出了一個基于Transformer和CNN Attention網絡的立體圖像增強網絡,可以提高圖像分辨率和立體效果。首先采用HAT-L作為單圖像超分辨率的骨干,使用多塊訓練策略和級聯殘差混合注意力組(RHAG)進行自注意和信息聚合,最終生成高分辨率圖像。同時,通過轉動和翻轉輸入圖像來實現自集成,使用SiLU激活函數替換GeLU激活函數進一步增強性能。
4.2 階段2:基于卷積神經網絡的立體增強網絡架構
作者介紹了基于卷積神經網絡的立體增強的第二階段流程。該流程使用了由NAFSSR-L作為骨干網絡,在提取淺層特征后,通過K2個NAF塊和SCAM模塊對左右圖像進行跨視圖信息聚合,最終輸出立體增強后的圖像。為了提高性能,通過自組合策略對模型進行了改進。
4.3 階段3: 基于卷積神經網絡的立體影像融合
作者介紹了一個基于卷積神經網絡的立體影像融合的三階段流程。在第三階段中,使用第二階段自組合的輸出作為輸入,提高了模型的整體性能。雖然第三階段模型表現與第二階段類似,但是作為一個集成模型,可以對第二階段模型進行進一步的改進。
5 實驗
5.1 實驗細節
本文的實驗部分訓練了一個 HTCAN 網絡,并對該網絡進行了三個階段的訓練。在第一階段的訓練中,使用了 Charbonnier 損失和 MSE 損失,同時還使用了各種數據增強技術。在第二階段中,我們采用 NAFSSR-L 的原始代碼在 Flickr1024 圖像上進行了訓練,并在第二階段訓練中使用 UnshuffleNAFSSR 模型的預訓練模型。最后,在第三階段的訓練中,采用與第二階段相同的設置,將網絡進行了微調。我們的方法在 Flickr1024 測試集上進行了評估,并通過與其他單幅圖像和立體圖像超分辨率方法的比較來證明其有效性。
5.2 實驗結果
本文的實驗結果顯示,與其他狀態-藝術單幅圖像超分辨率方法和立體圖像超分辨率方法相比,作者的方法在多數測試數據集上表現更好。此外,作者的方法在視覺效果上也表現出眾,能夠顯著地恢復圖像的細節和紋理。
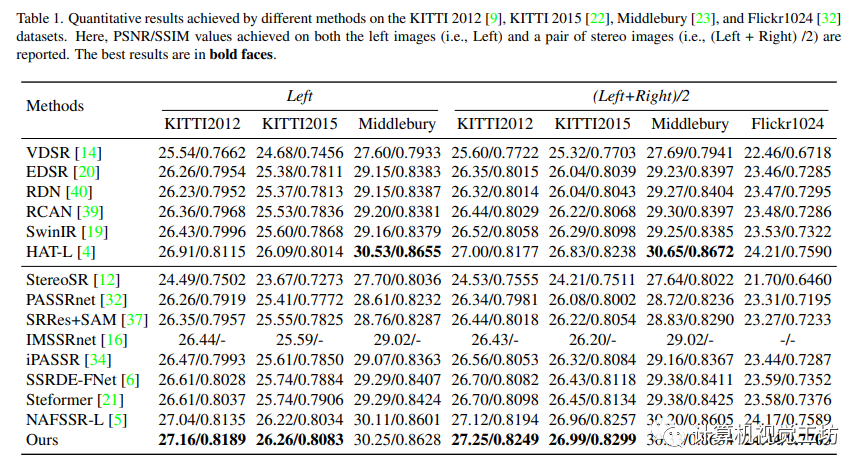
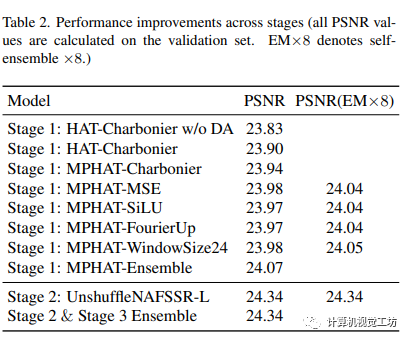
5.3 實驗分析
本文介紹了一種基于多塊訓練、數據增強和自我集成的立體圖像超分辨率方法,并引入了基于CNN的立體增強模塊來進一步提高性能。實驗表明這種方法可以有效地恢復圖像紋理和細節。其中,采用較大的接受域和窗口大小,以及自我集成策略可以進一步提高性能。本文提出的多階段方法將基于Transformer的SISR方法和基于CNN的立體增強方法相結合,進一步恢復了細節。


7 總結
本文介紹了混合Transformers和CNN注意力網絡(HTCAN),采用兩階段方法使用基于Transformers的SISR模塊和基于CNN的立體增強模塊來超分辨低分辨率立體圖像。作者提出的多補丁訓練策略和大窗口大小增加了SISR階段激活的輸入像素數量,使結果相較于原始的HAT-L架構有0.05dB的收益。此外,作者的方法采用先進的技術,包括數據增強,數據集成和模型集成,以在測試集上實現23.90dB的PSNR并贏得立體圖像超分辨率挑戰賽第一名。
-
數據
+關注
關注
8文章
6909瀏覽量
88849 -
變換器
+關注
關注
17文章
2087瀏覽量
109152 -
Transformer
+關注
關注
0文章
141瀏覽量
5982
原文標題:CVPR2023 I 混合Transformers和CNN的注意力網絡用于立體圖像超分辨率
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
新手關于圖像超分辨率的問題~
序列圖像超分辨率重建算法研究


序列圖像超分辨率重建
CVPR2020 | 即插即用!將雙邊超分辨率用于語義分割網絡,提升圖像分辨率的有效策略

基于目標檢測的海上艦船圖像超分辨率研究
基于CNN的圖像超分辨率示例





 工商網監
工商網監
評論