 LSPTM在軍事C2領域的潛在應用
LSPTM在軍事C2領域的潛在應用
超大預訓練模型(large scale pre-trained model, LSPTM) 的發展在人工智能領域產生了意想不到的效果, 尤其是在自然語言處理(natural language processing, NLP)上 ChatGPT 的突破, 似乎打通了 “人工智能” 的任督二脈, 在短短的幾個月內, 其智能實現了從人類可以理解的智能到無法理解的智能跨越。以 ChatGPT 為代表的 LSPTM 即將開啟一個全新的硅基智能時代,指揮與控制(command and control, C2) 作為人類社會引以為豪的體現智慧的關鍵要素,會面臨什么樣的機遇和挑戰?以 C2 過程的基本范式和運行基本模式框架為指導, 全面分析 LSPTM 在 C2 活動的物理域、信息域、認知域以及社會域各方向潛在的應用, 闡述硅基智能時代,人工智能從輔助工具角色向伙伴和替代角色的跨越,C2 領域發展的機遇. 軍事領域對抗性 C2 的競爭不再局限于技術, 而是培育 LSPTM 的文化底蘊, 東西方文化與價值觀的差異將決定兩種不同 LSPTM 的智慧與智能。
自1943年美國神經科學家麥卡洛克(Warren McCulloch)和邏輯學家皮茨(Water Pitts)建立神經元的數學模型以來,人工智能的發展可謂是“過山車”,既有符號主義、聯結主義(神經網絡)學派掀起的高潮,也有專家系統帶來的困境和徘徊,總而言之,人工智能的孕育過程跌宕起伏。2018年,一種全新的學習訓練方法——預訓練為深度學習打開了一扇智慧之門。預訓練成功激活了深度神經網絡對大規模無標注數據的自監督學習能力,在圖形處理器(graphics processing unit,GPU)算力和海量無標注文本數據的雙重加持下,實現深度學習模型規模與性能齊飛,成為人工智能領域的革命性突破。
圍繞LSPTM在海量數據、并行計算和模型學習能力方面等展開的“軍備競賽”日益白熱化。2023年,OpenAI發布的預訓練多模態模型GPT-4已經達到了萬億級參數量的驚人訓練規模,其智能在各種職業和學術考試上的表現與人類水平相當。
馬克思認為科學技術是軍事發展中最活躍、最具革命性的因素,每一次重大科技進步都深刻影響著世界軍事發展走向,引發戰爭形態和作戰方式的重大變革[1]。超大規模預訓練模型帶來的人工智能的技術突破將導致什么樣的軍事變革?本文深度剖析LSPTM的發展歷程、科學原理、關鍵技術及涌現功能,以軍事體系的關鍵要素——指揮與控制為對象,以C2過程的基本范式和運行模式框架為指導,從物理域、信息域、認知域和社會域,全維LSPTM的應用場景,闡述LSPTM實現人工智能突破給C2領域發展帶來的機遇和挑戰。
1LSPTM
1.1 LSPTM發展歷程
LSPTM一般指在大規模未標注數據集上進行預訓練的深度神經網絡(deep neural network)。預訓練后的深度神經網絡可以通過微調(fine-tune)、上下文學習(in-context learning)等方式適配各種下游任務,并達到最佳性能(state of the art,SOTA)。LSPTM已經成為人工智能領域中最具潛力的方向之一。
LSPTM的發展歷程可以追溯到2017年Vaswani等發表的論文《Attention Is All You Need》[2],文中提出了Transformer新型神經網絡。Transformer的優勢在于設計自注意力機制(self-attention mechanism),在機器翻譯、文本分類、問答系統等NLP問題中,超越循環神經網絡(recurrent neural network,RNN)和卷積神經網絡(convolutional neural network,CNN)取得了SOTA。隨后Transformer被拓展至計算機視覺(computer vision,CV)、多模態數據等其他任務中,并同樣取得了優異的成績。
在Transformer提出不久后,研究人員開始探索基于Transformer的LSPTM,首先應用于NLP任務,隨后拓展至CV和多模態任務。由于超大的參數量和強大的性能,這類LSPTM也被稱之為基石模型(foundation model)、大模型(large/big model)[3]。
1.2典型LSPTM
國內外多家高校、研究機構和公司已開展了LSPTM的研究,并取得了豐碩的成果,本節簡要介紹相關LSPTM,更多關于LSPTM的介紹和發展討論可以參考文獻[4]。
1)生成式預訓練Transformer(generative pre-trained transformer,GPT)
2018年,OpenAI提出了GPT。GPT采用自監督學習(self-supervised learning)訓練模型,其首先使用大量文本數據進行預訓練,然后針對各種NLP任務進行微調[5]。GPT采用了Transformer結構,使用了12層解碼器和768個隱藏單元,共有1.17億個參數。GPT使用的文本數據包括維基百科、新聞、書籍等。GPT在英文的文本生成任務中取得了當時的SOTA。GPT-2在GPT的基礎上提升了網絡規模,約有15億個參數和48層Transformer結構,訓練集為約40 GB的文本數據[6]。GPT-3沿著該思路進一步升級,網絡約有1750億個參數[7]。今年3月份,OpenAI發布了約有1.6萬億個參數的GPT-4。GPT-4除了可以完成更加復雜的NLP任務,還可處理多模態數據,能夠描述不尋常圖像中的幽默、總結截屏文本以及回答包含圖表的試題。在GPT-4發布前,OpenAI發布了第一款面向大眾的LSPTM產品——ChatGPT,提供了堪比真人的交流體驗,引起了全球轟動。
2)基于Transfomer的雙向編碼器表征(bidirectional encoder representations from Transformers,BERT)
2018年,Google提出了NLP模型BERT[8]。相比與其他NLP模型,BERT的不同之處在于采用了雙向的Transformer結構,可以同時利用左右兩個方向的上下文信息,從而更好地理解文本。在預訓練任務中,BERT設計了遮蔽語言模型(masked language model)和下句預測(next sentence prediction)兩種任務。在遮蔽語言模型任務中,BERT會隨機遮蔽文本中的一些詞匯,然后讓模型預測這些被遮蔽的詞匯。在下句預測任務中,BERT會隨機選擇兩個句子,并讓模型判斷這兩個句子是否為相鄰的兩個句子。標準版的BERT約有3.4億個參數,基本結構為Transformer。BERT在11種NLP任務上都取得了當時的SOTA,是LSPTM的代表之一。
3)對比語言圖像預訓練(contrastive language-image pre-training,CLIP)
在多模態任務中,OpenAI于2021年提出了CLIP,用于實現圖像和文本之間的交互理解[9]。CLIP同樣采用了Transformer結構,其目標是通過預訓練模型,在大規模的圖像和文本數據上學習一個通用的視覺和語言表示,從而使得模型能夠同時理解圖像和文本的含義。CLIP的預訓練任務是通過對圖像和文本之間的對比學習來實現的。具體來說,CLIP會將一張圖像和一段文本作為輸入,然后讓模型判斷這個圖像和文本是否相關。通過這種方式,CLIP能夠學習到圖像和文本之間的關聯性,從而建立起視覺和語言之間的聯系。CLIP可以應用于各種NLP和CV任務,例如:圖像分類、圖像生成、視覺問答、圖像檢索、文本分類等。與一般的單模態的NLP和CV模型相比,CLIP的優點在于它能夠同時處理
文本和圖像數據,完成更復雜的任務。
4)文心一言
文心一言(ERNIE Bot)是今年3月百度發布的一款知識增強大語言模型產品,能夠與人對話互動、回答問題、商業文案創作、數理邏輯推理、多模態生成(協助用戶創作和繪圖),高效地幫助用戶們獲取信息、知識和靈感。文心一言在中文的NLP任務中具有一定的優勢,其基礎LSPTM是ERNIE5。根據文獻[10],ERNIE中ERNIE 3.0 Titan約有2600億個參數。ERNIE Titan采用了自監督對抗損失(self-supervised adversarial loss)和一個可控語言建模損失(controllable language modeling loss),使ERNIE 3.0 Titan產生可控且具有可信度的文本,ERNIE 3.0 Titan在68個NLP任務中取得了當時的SOTA。
5)盤古
盤古(PanGu)是華為推出的一系列人工智能LSPTM產品,包括NLP大模型、CV大模型、科學計算大模型。盤古系列大模型于2021年預先發布了NLP大模型和CV大模型,沉寂兩年后,今年4月8號將正式發布相關產品,首次將Transformer的編碼器和解碼器同時用于LSPTM,保證模型生成能力和理解能力。文獻[11]介紹了華為自然語言LSPTM盤古-α(PanGu-α),展示了盤古NLP大模型的技術。PanGu-α網絡參數量為2 000億。PanGu-α是在MindSpore2下開發的,并在2 048個Ascend 910人工智能處理器的集群上進行訓練。訓練的并行策略是基于MindSpore Auto-parallel實現的。此外,華為為增強模型的泛化能力,收集了1.1TB的中文NLP數據訓練模型。
6)M6
M6是阿里巴巴推出的多模態大模型產品,目前模型參數達10萬億以上。M6通過將不同模態的信息經過統一加工處理,沉淀成知識表征,為各個行業場景提供語言理解、圖像處理、知識表征等智能服務,其M6指多模態到多模態多任務巨型轉化器(multi-modality to multimodality multitask mega-transformer)。根據文獻[12],M6的工作包括構建了當時最大的中文多模態預訓練數據集,其中包括超過1.9 TB的圖像和292 GB的文本,并在一系列下游任務取得了良好的表現,例如電商圖文商品檢索、推薦;智能制造中設計圖片生成、汽車3D圖片展示;金融行業摘要和文本生成、數字感知、點評等等。
2ChatGPT的技術原理與功能分析
ChatGPT是OpenAI發布的第一款面向大眾的LSPTM產品,也是GPT系列的代表作之一,發布即取得了全世界范圍內的廣泛關注,具有里程碑式的意義。本章以ChatGPT為例介紹其相關原理和方法。由于GPT-2以后GPT模型不再開源,且ChatGPT并無論文,所以主要參考InstructGPT[13]和ChatGPT的博客。
2.1 ChatGPT的技術原理
與RNN和CNN不同,Transformer在處理數據(尤其是時序數據)時無需按時間順序來處理信息。Transformer利用自注意力機制,能夠同時考慮輸入序列中所有位置的信息,從而能夠更好地捕捉長距離依賴關系。另外,Transformer還引入位置編碼(position encoding)來保留輸入序列中的位置信息。Transformer結構由編碼器和解碼器兩部分組成。編碼器負責將輸入序列編碼為特征表示,而解碼器則將這些特征表示轉化為輸出序列。Transfomer更詳細的介紹可參考論文[14]。
與其他深度神級網絡不同,增加Transformer的網絡參數可以提升其性能,這使得提升網絡參數以突破網絡性能瓶頸成為了可能,因而引領了LSTPM的人工智能潮流。ChatGPT基于Ttransformer框架,基礎模型為GPT-3.5,并采用人類反饋強化學習(reinforcement learning from human feedback,RLHF)對模型輸出進行優化,實現了真人的交流體驗。
ChatGPT的訓練流程如圖1所示,其訓練流程大致可分為3步:
Step 1 基于真人回復示例監督訓練GPT-3.5;
Step 2 基于真人排序訓練獎勵模型;
Step 3 反饋優化監督訓練后的GPT-3.5。
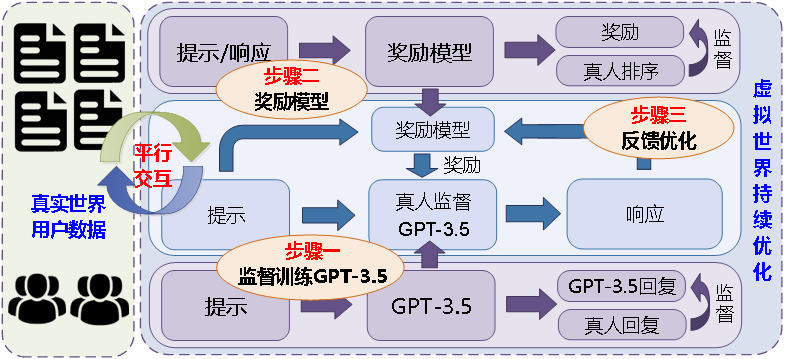
圖1 ChatGPT訓練流程
Fig.1The training process of ChatGPT
1)基于真人回復示例監督訓練GPT-3.5
針對同一提示,該步基于GPT-3.5的回復以及人類給出的回復示例,再采用監督學習的方式訓練GPT-3.5,使其初步產生與人類對話類似的回復。該步過后的GPT并不完美,但可初步提供具有人類對話感覺的體驗。
2)基于真人排序訓練獎勵模型
該步是RLHF的核心步驟之一,其目的是通過神經網絡去學習真人的價值偏好。針對所有的提示,如果都可以用真人去評價,自然也可以訓練得ChatGPT,但這樣無法實現自動化的訓練方式,客觀上實現也并不可能。因而需要有個符合真人價值偏好的獎勵模型來評價監督訓練后GPT-3.5的回復,以糾正其輸出。該步通過對比學習的方式實現,即真人在多個回復中,任意對比其中兩個,選出更為偏好的一個,為獎勵模型提供標注信息實現監督學習。該步也是RLHF中引入人類反饋的關鍵步驟。
3)反饋優化監督訓練后的GPT-3.5
一旦獲得獎勵模型后,監督訓練后GPT-3.5根據獎勵模型給出的獎勵自動反饋優化模型,最終形成ChatGPT。該步是采用了近端策略優化(proximal policy optimization,PPO)強化學習算法,是實現ChatGPT的核心,也是與其他LSPTM不同的地方。
ChatGPT是一個典型基于平行智能Hanoi(integrated human, artificial, natural, and organizational intelligence)的LSPTM[4, 15-16],構成了人在回路的社會化大閉環(the grand socialization closed-loop of human in the loop)[4]。ChaGPT中各種要素在實際物理空間和虛擬空間基于中心化自主組織及全中心化自主運行(decentralized autonomous organizations and decentralized autonomous operations,DAO)通訊、組織和協調[15],形成了人類、人工、自然和組織智能的有機結合體,是語言智能范式的代表之一[16]。
2.2 ChatGPT的功能
ChatGPT是一款能夠以文字方式進行自然對話的人工智能模型,其基本功能如圖2所示[8]。可以從事各種復雜的語言工作,如自然對話、自動摘要、文本生成、自動問答等。在自動文本生成方面,ChatGPT能夠根據用戶要求生成論文、代碼、劇本、企劃等內容。在自動問答方面,它能夠理解用戶提出的問題,并給出相應答案。此外,ChatGPT的知識范圍廣泛,涵蓋自然科學、人文社科、社會科學、文體娛樂、奇聞趣事等等領域,同時它還能夠掌握用戶的語氣,正確分析文本情感。ChatGPT出色的自動摘要、文本生成能力在C2中會有出色的表現,例如:作戰方案生成、敵方意圖分析等等。該部分會在后面詳細介紹。
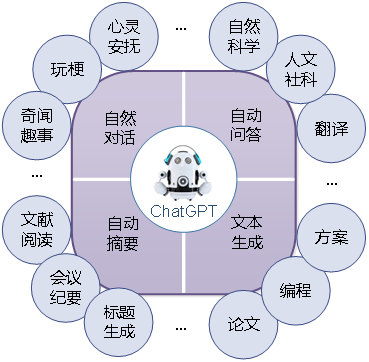
圖2ChatGPT的基本功能
Fig.2 Basic functions of ChatGPT
ChatGPT能出色完成上述任務的能力可能源自復雜系統涌現現象。復雜系統涌現現象是指在一個復雜系統中出現的新的特征或行為,這些特征或行為是由系統中各個組成部分相互作用和協同作用產生的,不能被簡單地從單個組成部分的行為中預測或解釋。復雜系統涌現現象在自然界和人工系統中都廣泛存在,例如自然界中的蜂群、蟻群和鳥群等,人工系統中的交通流、股市和互聯網等[17]。
在以LSPTM為代表的人工神經網絡領域,涌現現象同樣存在。總體來說,LSPTM的涌現能力可總結為如下兩種表現:1)上下文學習;2)思維鏈(Chain-of-Thought,CoT),在較小的模型中,上述兩種能力是不具備的。
上下文學習是指采用零樣本學習(研究人員或用戶給出幾個示例)就可以使LSPTM在不調整深度神經網絡參數的情況下很好地處理研究人員給出的任務。這與根據下游任務微調模型的方式有明顯的不同。在上下文學習中,模型參數不變,說明LSPTM在預訓練階段根據基本的自然語言任務已經習得了特定任務的特征,僅需一些示例就可將該能力激發出來。
CoT可視為少樣本提示(few shot prompt)推理,即對于某個復雜的問題,研究人員或用戶分步給LSPTM展示出具體的分析/推導過程,LSPTM根據展示就可完成一些類似的復雜推理任務。CoT在數學、物理等自然科學等問題中表現良好。
3LSPTM在指揮控制領域的應用場景分析構設計
3.1 C2過程的基本范式及C2過程產品與技術分析
C2是軍事體系的關鍵要素,直接決定戰爭的勝負。指揮控制活動過程機理存在尺度的關聯性[18],戰術C2、戰役與戰略C2有各自的活動過程機理。戰術C2以經典理論觀察-判斷-決策-行動 (observe, orient, decide, act, OODA)環[19]為指導,在宏觀戰役與戰略尺度上,其C2活動以籌劃-準備-執行-評估 (planning, readiness, execution, assessment, PREA)環為指導,多尺度C2是軍事體系的指揮控制過程的一般機理[20-21]。
多尺度C2過程可描述為多PREA環與OODA環的結合,PREA環負責軍事體系C2活動的宏觀指導,其C2活動過程從作戰籌劃、部署準備、執行監控到作戰評估與轉換活動4個主要環節構成3個反饋閉環,從態勢角度,是對態勢的謀劃設計、部署和評估;OODA環負責軍事體系的戰術執行的C2活動指導,從態勢角度上,是對態勢演化的控制,其C2活動從觀察、判斷、決策到行動4個環節構成一個閉環。
PREA&OODA構成了軍事體系各級指揮與控制活動的基本指導,如圖3所示。
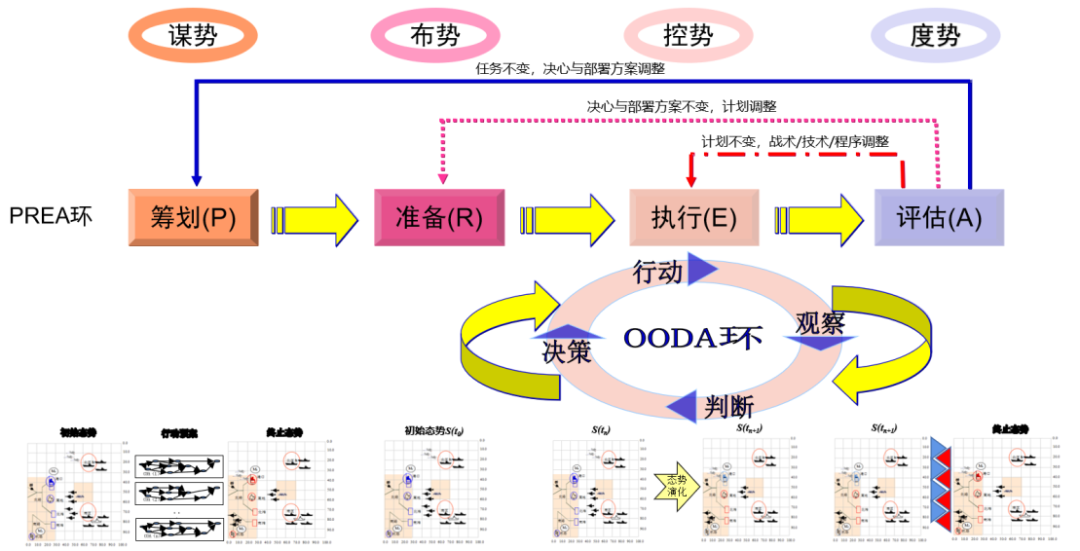
圖3 軍事體系C2過程的基本范式:PREA&OODA
Fig. 3 The basic paradigm of the C2 process of the military system: PREA & OODA
軍事體系C2過程的基本范式涵蓋各域的活動,并伴隨相關產品。在物理域,體現為真實戰場的各種形態,包括基于歷史→未來設計的戰場、構建引導的戰場、實際的戰場以及評估所需要的描述戰場;在信息域,主要體現為演繹態勢、直前態勢、實時態勢和復盤態勢4種態勢所需要的信息產品以及相關技術;在認知域,主要體現為基于意圖的周密決策、基于預案的審慎決策、基于規則的快速決策和基于評估效果的轉換決策;在社會域,主要體現為政治、經濟、文化以及組織形態的相關活動,包括政治、經濟、文化策略設計,組織結構關系設計,政治、經濟、文化引導及軍事組織關系構建,政治、經濟、文化及軍事組織協同,政治、經濟、文化影響評估及組織結構關系效能評估,等等。軍事體系C2過程的關鍵活動、技術與產品如圖4所示。
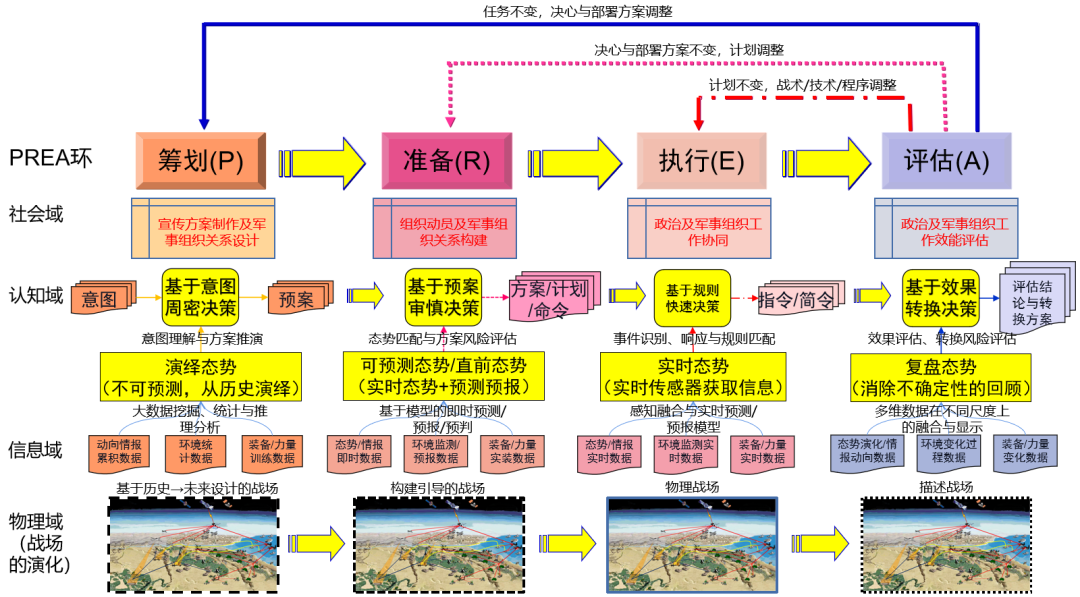
圖4 軍事體系C2過程的關鍵活動、技術與產品
Fig. 4Key activities, technologies and products of the C2 process of the military system
3.2 指揮控制領域LSPTM的應用場景分析
在上一節中,C2過程的基本范式描述了C2在物理域、信息域、認知域和社會域的具體活動、技術需求及產品,從ChatGPT-4.0公布的功能看,LSPTM的潛在應用體現在C2活動的全過程和各域。
3.2.1 LSPTM在物理域的應用
在物理域,C2活動與LSPTM一樣,需要有物理域的憑借和依托,包括真實的戰場環境和支撐C2活動的算力所需要的計算與存儲設備。
LSPTM作為通用人工智能工具,在物理域上有大規模計算與存儲設備支撐其算力,同樣,C2活動在物理域也需要相關的系統與設備支撐,LSPTM對C2活動在物理域的應用主要體現在3個方面:1)通用人工智能進入C2系統,可大幅度減少C2系統對一般算力的設備需求,如LSPTM能提供的翻譯、自動對話、文本生成等通用智能都不需要C2系統再配置相應的計算與存儲設備,LSPTM的應用為小型無人作戰平臺、小規模無人集群等輕量級C2智能系統的物理配置提供了條件;2)LSPTM的算力與存儲設備的配置與應用,可為C2系統的設計提供借鑒和參考,尤其是跨域聯合的大型有人與無人結合的C2系統;3)在戰場環境方面,LSPTM可用于構建C2訓練環境,支持C2對抗的戰場環境從物理狀態向描述戰場、預測戰場和引導戰場的持續演化。
3.2.2 LSPTM在信息域的應用
在C2基本范式中,信息域的主要活動包括各類情報產品的獲取、處理,歷史數據的統計與分析處理,各類傳感器數據的獲取和融合處理,基于實時數據的預測與預報產品處理,以及行動過程的數據采集及態勢復盤信息處理,等等,針對信息域的這些活動及產品技術,LSPTM的潛在應用有正向應用和逆向應用,正向應用以支持C2在信息域的相關活動,主要體現在3個方面:1)信息不完備條件下的推理,如根據動向情報進行關聯分析,推理敵方的行動規律;2)信息在大規模條件下的挖掘,如對大數據的分析技術;3)信息在不確定條件下的分析,如情報信息的相互應證分析。相反,對確定的信息、完備的信息以及小規模數據的分析,LSPTM的應用與傳統C2系統的相關技術并存在特別的優勢,如小尺度的推算與推演、實時態勢數據的融合以及行動過程數據采集與復盤技術,等等,在這些方面,傳統C2系統仍然存在技術優勢。
LSPTM在信息域還有另外一種重要應用,即逆向應用。LSPTM的逆向應用場景包括生成不同模態的虛假內容,包括文本、語音、視頻等等,造成以假亂真的信息傳播,以欺騙對手,其生成虛擬內容可以是動向情報信息、歷史統計數據,也可以是虛擬的預測與預報數據,實時感知數據以及作戰行動過程數據,等等。所有這些生成的虛擬數據,可對敵方的認知活動造成干擾,從而影響其決策的正確性或延誤其決策時機。
3.2.3 LSPTM在認知域的應用
以ChatGPT為代表的LSPTM已經具備人類無法理解的推理能力。LSPTM在認知域的對抗是最具潛力的應用領域[23],認知戰是LSPTM未來的主戰場。LSPTM在認知域的潛在應用包括7個方面。
1)意圖理解/識別
LSPTM的語言與文本解析功能可用于無人作戰系統對有人指揮意圖的理解,包括對作戰構想的理解、作戰命令或作戰計劃的解析或者作戰指令的解碼,等等。
另一方面,LSPTM的圖形場景分析功能可用于對敵行動意圖的識別,如基于作戰情況圖或作戰經過圖,識別敵方行動的意圖,為指揮員的判斷提供支持。
2)基于演繹態勢的推理與周密決策技術
LSPTM具備事件關聯與邏輯推理能力,這一功能可用于動向情報分析和歷史統計數據分析,通過LSPTM的推理分析,從歷史構建未來的演繹態勢;同時,在構建演繹態勢過程中,提出相關的假設;基于假設,提出相應的解決問題方案,即作戰構想和作戰預案。
3)基于預案匹配的審慎決策技術
在意圖識別基礎上,LSPTM可進一步支持基于預案匹配的審慎決策。一方面,LSPTM強大的邏輯推理可對態勢進行預判,基于預判匹配各類預案,對匹配的預案進行風險和收益評估,為指揮員的決心提供支持。
4)基于實時態勢的威脅判斷技術
在計劃執行的實時對抗過程中,LSPTM的強大計算推理功能可用于支持目標的快速跟蹤識別和威脅判斷,為不同主體的OODA環提供運行支持。
5)基于規則的快速決策技術
在計劃執行的實時對抗過程中,LSPTM的強大算力可支持指揮主體的快速決策,如戰術規則的快速匹配,或者實施平行推演,快速組織規則的重建,為不同主體的OODA環提供決策和平行行動的支持。
6)事件的識別與響應技術
當不確定事件發生時,LSPTM的意圖理解與識別功能可用于支持事件的響應與處置,包括事件的觀察、事件的識別、事件影響的評估,并提供事件處置的方案建議,輔助指揮員的臨機決策。
7)基于復盤態勢的行動效果評估技術
LSPTM在大(時間)尺度上的記錄分析可用于作戰過程的數據采集和復盤分析,其模式匹配與識別功能可進行初始態勢和當前態勢的一致性分析,從而支持指揮主體對作戰行動效果的評估分析。
3.2.4 LSPTM在社會域的應用
C2在社會域的活動以解決多主體在任務上的高效協同為目標,其主要活動包括團隊文化的宣傳與思政教育、C2組織結構的設計以及協同計劃的制定和實施等等。
1)組織文化的宣傳與思政教育
LSPTM的方案編寫、文本與視頻制作等功能可用于組織文化的宣傳與思政教育,指揮機構的政治工作在確定方案主旨的基礎上,可運用LSPTM,根據戰場實際情況快速編寫宣傳方案,并生成相應的文本或視頻,進行戰地宣傳教育。
2)基于任務的團隊設計構建以及敵方C2組織結構的識別
LSPTM強大的算力可替代傳統團隊設計技術,一方面用于己方團隊的設計構建,根據作戰任務的需求設計科學的團隊組織;另一方面,可進行逆向設計,對敵方戰場的C2組織進行結構的辨識,從而分析其關鍵的C2結構和力量。
3)多智能體的自適應編組、協同決策與協同控制技術
LSPTM的通用智能可用于支持群體智能技術,包括多智能體的自適應編組、協同決策與協同控制,如空中無人機群、海上無人集群以及陸上跨域無人作戰系統等等,這些無人作戰體系在完成復雜作戰任務的快速編組與協同,LSPTM可替代傳統的智能優化算法。
3.3 LSPTM在C2活動過程應用的潛力比較分析
在C2范式中,LSPTM對C2活動的支持并不均衡,在不同的閉環中有不同的應用潛力,如圖5所示。
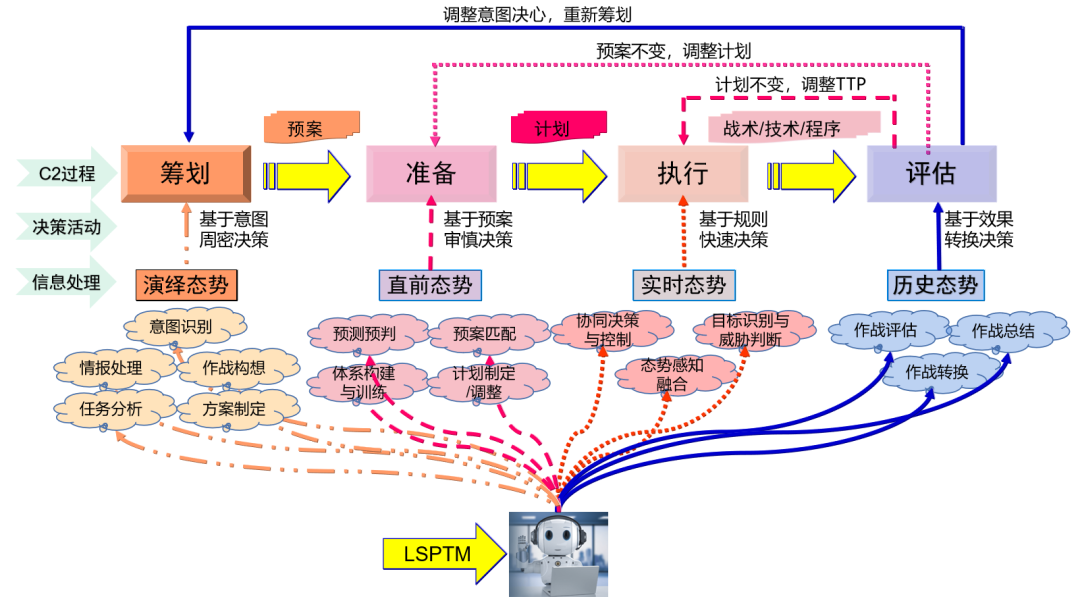
圖5 LSPTM在PREA環的4個階段運用的潛力比較
Fig. 5 Comparison of the potential applicationof LSPTM in the fourstages of the PREA loop
從圖中可以看出,LSPTM應用更多潛力并不在作戰計劃執行環節的OODA環,而是在PREA環的作戰籌劃和準備環節,在作戰籌劃準備環節,其應用包括作戰任務分析、作戰意圖的理解和識別、情報獲取和處理分析、態勢的預測與預判斷、作戰構想與作戰方案的生成等等,這些應用的背景是戰場具有太多的不確定性,存在各種假設,需要進行推演評估生成相應的方案預案,這些問題都是傳統智能算法表現不佳或者根本無法解決的問題,只有LSPTM在強大的算力與數據支撐條件下才有可能突破解決。
從3.2節LSPTM在物理域、信息域、認知域與社會域4個域應用分析看,LSPTM的強大功能表現并不在物理域、信息域,而是認知域和社會域,其中認知域對LSPTM的需求最為強烈,究其原因在于認知技術是智能的終極體現,C2在認知域的活動最為關鍵,同樣,對智能技術的支持也最為強烈,過去關于C2系統研發的關鍵和難點也在認知的輔助功能,包括態勢與意圖的理解、行動的規劃以及輔助決策技術等等。
4C2領域發展的機遇與挑戰
馬克思主義認為科學技術是軍事發展中最活躍、最具革命性的因素,每一次重大科技進步都深刻影響著世界軍事發展走向,引發戰爭形態和作戰樣式的重大變革。人工智能領域LSPTM的技術突破將帶來C2哪些方面的變革?
1)C2對抗形式:從真實戰場轉向虛擬戰場,不戰而屈人之兵成為未來戰爭的常態
LSPTM為虛擬戰場的構建與對抗推演提供了條件,沖突雙方可在虛擬戰場展開C2對抗,既可實現實力的較量,同時又避免現實沖突的損失與傷亡。
2)C2方式:集中籌劃與控制
未來戰場,中心C2的集中籌劃與集中控制將成為未來C2方式,LSPTM強大的算力與智力彌補了過去指揮主體——人的局限性,指揮員的參謀團隊逐漸被各種角色的LSPTM替代,戰場超強大腦可輔助指揮員實施集中籌劃和控制。
3)C2手段:戰術C2系統的無人化,中心C2系統實現有人與無人混合智能
LSPTM可替代戰術指揮員,戰術C2系統將逐漸退出人在回路的閉環,實現OODA環的智能閉環,邊緣戰術C2實現中心C2指導下的自主行為;同時,傳統的中心C2根據角色和內容訓練LSPTM,實現機構精簡和業務活動的智能轉型,實現有人與無人的混合智能。
4)C2技術:從領域細分轉向融合通用智能
C2技術領域分布廣,從物理域的計算設備,到社會域的網絡分析,學科交叉與跨域是C2手段建設的難點所在。LSPTM通用智能可實現跨域技術的融合,未來C2技術將逐步統一至LSPTM的算力與數據。
人工智能時代,C2從對抗形式到技術的變革是未來軍事制高點,搶占這一制高點需要加速LSPTM的建設與應用,LSPTM盡管不存在技術上障礙,然而,LSPTM所依賴的其他條件是C2領域未來發展的挑戰。
挑戰1:LSPTM通用智能發展的挑戰。在LSPTM建設應用上,ChatGPT獨占鰲頭,盡管國內有百度的文心一言、華為的盤古及阿里巴巴的M6等產品,與ChatGPT的智能相比較,還存在較大的差距。
挑戰2:LSPTM在C2領域發展的挑戰。LSPTM在通用智能上的縱向突破是橫向發展基礎。軍事C2領域的LSPTM需要通用智能的突破,這是基礎和前提,國內LSPTM建設在通用智能產品上存在差距,其人機交互體驗不盡友好。
挑戰3:LSPTM的算力與數據支持。算力與數據是LSPTM發展的基礎,在算力上,硬件芯片發展與C2系統的輕量化發展是矛盾對立面,在數據上,LSPTM需要大量的訓練標注樣本,軍事領域的數據與互聯網數據不同,存在孤立性、保密性,如何圍繞LSPTM建設的需求展開軍事領域的數據建設與訓練實施,這是挑戰之一。
挑戰4:LSPTM的應用的倫理與安全。從測試看,ChatGPT已具備一定程度上的自我意識,與ChatGPT的溝通需要掌握對話技藝。LSPTM成熟產品一旦應用于軍事C2領域,不可避免帶來倫理安全問題。如何應用LSPTM獲取未來C2對抗的優勢,同時,減小LSPTM應用可能帶來的安全風險,LSPTM在軍事C2領域的挑戰。
5結論與展望
本文以C2活動過程的基本范式為指導,分析了LSPTM在軍事C2領域的潛在應用,包括物理域、信息域、認知域和社會域C2活動的主要應用,指揮與控制作為軍事力量的關鍵要素,對人工智能建設的需求最為強烈,因此,LSPTM在指揮與控制領域的潛在應用是廣泛的,涵蓋了從PREA到OODA的全過程、多尺度。從應用場景分析看,LSPTM的關鍵作用突顯在基本范式的“籌劃準備”環節,大量的態勢認知、研判、意圖理解與任務規劃等活動都是LSPTM應用的典型場景,從C2 4個域的維度分析看,最具潛力的運用在認知域,LSPTM可以成為C2主體認知活動理想的工具和手段。
C2領域LSPTM的建設既是機遇,同樣也面臨挑戰。在機遇上,可以通過LSPTM的建設,彌補常規武器裝備建設上的差距,以智能優勢彌補裝備技術劣勢;在挑戰上,需要解決LSPTM在C2領域的算力支持、領域數據與訓練支持以及LSPTM運用帶來的倫理安全等問題。這些問題是本課題研究的未來方向。
-
神經網絡
+關注
關注
42文章
4762瀏覽量
100541 -
人工智能
+關注
關注
1791文章
46859瀏覽量
237582 -
數學模型
+關注
關注
0文章
83瀏覽量
11928
原文標題:超大預訓練模型在指揮控制領域的應用與挑戰
文章出處:【微信號:AI智勝未來,微信公眾號:AI智勝未來】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
RFID技術給軍事物流領域帶來什么?
為什么PTN36241 C1/C2下的斷線問題都是open狀態?
帕拉帕C2號衛星參數表
vr在軍事領域的應用案例分析
TicWatch C2智能手表評測
晶振電路如何選擇C1和C2電容

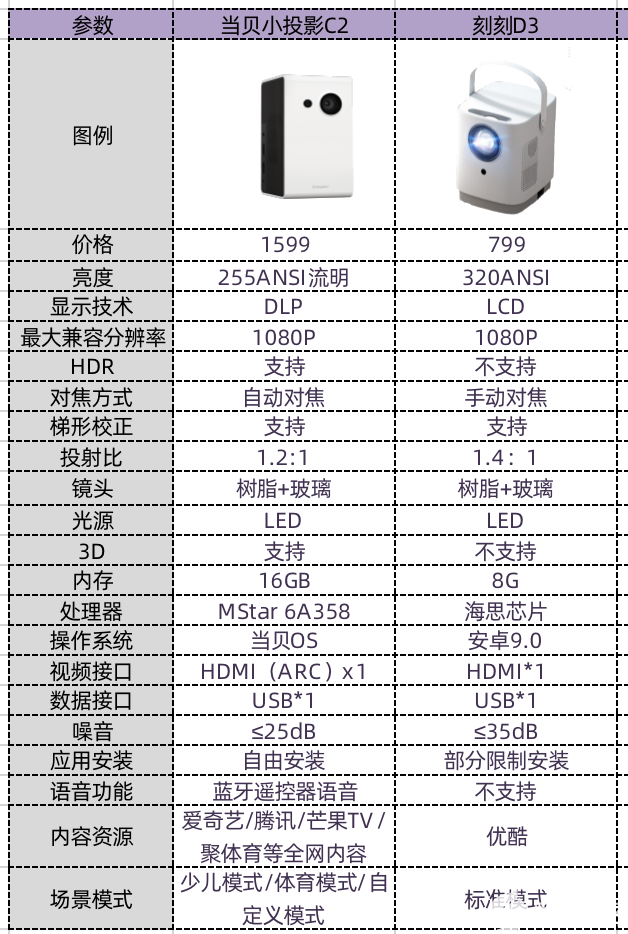
刻刻D3怎么樣,和當貝C2比哪款性價比更高





 工商網監
工商網監
評論