 GLoRA:一種廣義參數高效的微調方法
GLoRA:一種廣義參數高效的微調方法
近年來,大規模深度神經網絡的顯著成就徹底改變了人工智能領域,在各種任務和領域展示了前所未有的性能。這些高度復雜的模型,通常具有數百萬甚至數十億個參數,在計算機視覺、自然語言理解和語音識別等領域表現出了卓越的能力。
本文提出了廣義LoRA(GLoRA),一種通用參數高效微調任務的先進方法。增強低秩適應(LoRA),GLoRA采用廣義提示模塊優化預訓練模型權重并調整中間層激活函數,為不同的任務和數據集提供更大的靈活性和能力。
GLoRA源于統一的數學公式,具有較強的transfer learning、few-shot learning和domain generalization能力,其通過權值和激活的附加維度調整到新任務。
實驗表明,GLoRA在自然、專業和結構化基準測試中優于所有以前的方法,在各種數據集上以更少的參數和計算實現了更高的準確性。此外,結構重新參數化設計確保GLoRA不需要額外的推理成本,使其成為資源有限應用程序的實用解決方案。
GLoRA
簡介
本文首先對現有最先進的PEFT方法進行數學概述,分析了它們的優缺點。然后,引入了一個整合所有現有SOTA PEFT方法的統一公式,并根據統一公式的觀點詳細闡述了所提出的廣義LoRA。然后,提出了一種結構重新參數化設計,以在不增加額外成本的情況下顯示推理效率。為了實現廣義LoRA的目標,還引入了最優分層配置的進化搜索,進一步對所提出的方法的更高性能進行了理論分析和討論。
已有方法及其局限性
Visual Prompt Tuning(VPT) :VPT將少量特定于任務的可學習參數引入輸入空間,同時在下游微調期間凍結整個預先訓練的Transformer主干。VPT提出了兩種策略:VPT-Shallow和VPT-Deep。
VPT-Shallow策略如下:其中P是可訓練的提示。x是[CLS]token,E是圖像paches。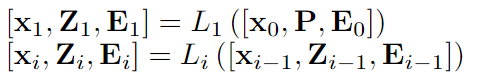 VPT-Deep策略如下:VTP-Deep在大多數視覺任務上都優于完全微調,在低數據狀態下也有更好的準確性。
VPT-Deep策略如下:VTP-Deep在大多數視覺任務上都優于完全微調,在低數據狀態下也有更好的準確性。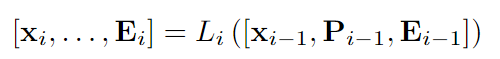
AdaptFormer:AdaptFormer在MLP塊上引入了兩個線性層的并行可學習分支和ReLU,并在暫停其他部分的同時僅學習該路徑。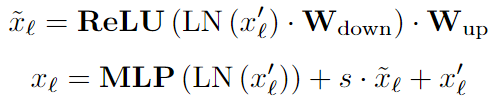
LoRa:LoRA方法凍結預訓練模型權重并將可訓練的低秩分解矩陣注入每一層。只從預訓練的權重中學習殘差。在GPT-2模型家族上與prompt learning、adapters等相比,實現了SOTA性能。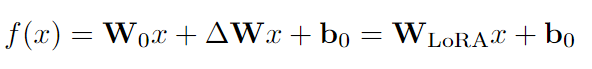
Scaling & Shifting Features (SSF) :SSF模塊在訓練過程中對所有的MLP、MHSA、Layernorm模塊進行特征縮放和移位,并在推理過程中進行重新參數化,其是一個線性結構。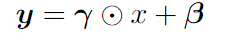
FacT:FacT提出使用張量分解方法來存儲額外的權重,將模型的權重張量化為單個3D張量,然后將其相加分解為輕量級因子。在微調中,只有因子會被更新和存儲。FacT有兩種方式: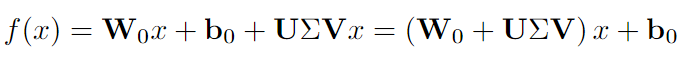 其中LoRA中的ΔW被分解為U、V和Σ。
其中LoRA中的ΔW被分解為U、V和Σ。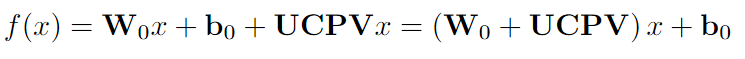 其中LoRA中的ΔW被分解為U、C、P和V。
其中LoRA中的ΔW被分解為U、C、P和V。
RepAdapter:RepAdapter將輕量級網絡插入到預先訓練的模型中,并且在訓練后,額外的參數將被重新參數化為附近的投影權重。將順序適配器添加到MHA和MLP中,適配器是線性的,因此可以重新參數化,并且有兩層:下采樣密集FC層以下采樣輸入;對劃分為組的下采樣特征進行上采樣,并且每個組都具有上采樣層。上采樣層組可以合并為單個稀疏上采樣層,并且可以直接重新參數化為原始MLP或MHSA。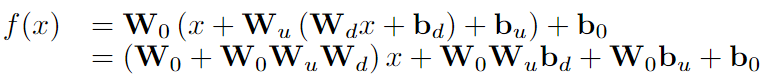
局限性:許多現有的PETL方法,例如(VPT, Adapter)會增加推理時間,因其提出的結構無法重新參數化。直接提示調優也很難設計,帶來了計算負擔,并且需要超參數調整,即如何以及在哪里放置提示。LoRA在推理時可以重新參數化,但它不能擴展到更大的矩陣,并且適應能力受到權重空間的限制。SSF/RepAdaptor無法學習到權重的變化,即權重空間中的ΔW,而LoRA/FacT不能有效地學習特征變化的縮放和移動,即特征空間中的ΔH。在從大型模型執行遷移學習時,特征空間和權重空間都需要靈活性。因此本文在這項工作中提出的的改進想法為:ΔW調整、ΔH調整以及W和H縮放和移位學習。
One-for-All unified formulation
對于模型微調,本文提出了一個統一的公式,包含所有可調維度,包括但不限于權重空間和特征空間。此外,們采用重新參數化策略在推理階段將輔助參數合并到相鄰投影權重中。從廣義上講,本文提出的方法是所有先前解決方案的超集,即一次性機制。通過將不同的支持張量設置為零,GLoRA可以簡化為這些先前方法中的任何一種。GLoRA體系結構可以簡潔地表述為統一的數學方程。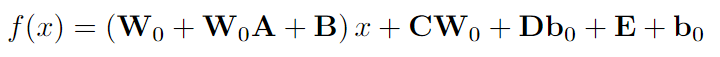 其中 A、B、C、D、E 是GLoRA中下游任務的可訓練張量,W0和b0在整個微調過程中被凍結。A用于縮放權重,B的作用是縮放輸入并移動權重,C服務于VPT-Deep、D和E表示逐層提示,分別用于縮放和移動偏差。具體流程如下圖所示:
其中 A、B、C、D、E 是GLoRA中下游任務的可訓練張量,W0和b0在整個微調過程中被凍結。A用于縮放權重,B的作用是縮放輸入并移動權重,C服務于VPT-Deep、D和E表示逐層提示,分別用于縮放和移動偏差。具體流程如下圖所示: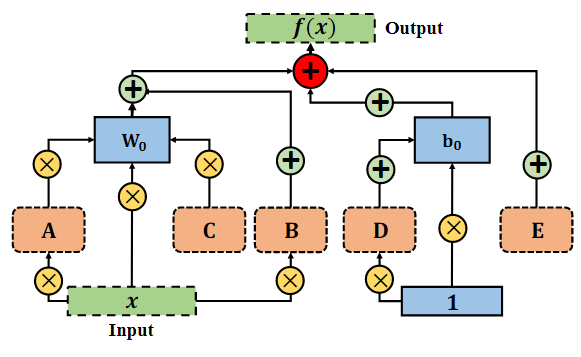
Prompt Modules-提示模塊
prompt modules描述了為 A、B、C、D、E 設計分層適配器或提示模塊的方法。從某種意義上說,這些可以采用scalars, vectors,low-rank decompositions, or none形式。基于這些可訓練支持張量的作用,可分為以下幾類: 這種權重糾纏策略有助于在不增加參數數量的情況下增加搜索空間,并且由于不同子網中的權重共享,也顯示出更快的收斂
這種權重糾纏策略有助于在不增加參數數量的情況下增加搜索空間,并且由于不同子網中的權重共享,也顯示出更快的收斂
結構重新參數化設計與推理效率分析
實現重新參數化的基本方面是消除相鄰變換中的非線性,從而允許將補充參數吸收到前面的參數中。去除這種非線性層不會對網絡的性能產生不利影響。GLoRA重新參數化策略如下: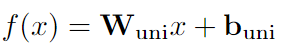 在GLoRA中最終統一訓練的權重和偏差。根據等式對它們進行重新參數化:
在GLoRA中最終統一訓練的權重和偏差。根據等式對它們進行重新參數化: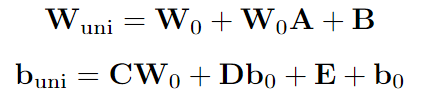 因此,重新參數化策略將可學習參數集成到相鄰投影權重中,其可能是有利的,因為在推理階段不會產生額外的計算成本。
因此,重新參數化策略將可學習參數集成到相鄰投影權重中,其可能是有利的,因為在推理階段不會產生額外的計算成本。
最優分層配置的進化搜索
對統一適配器的設計是在每層的基礎上實現的,其允許跨不同層的異構性。為了確定每一層的最佳配置,采用了進化搜索方法,它提供了效率和有效性的平衡。盡管這種搜索過程會導致訓練時間的增加,但值得注意的是,現有工作需要進行廣泛的超參數搜索。此外,本文使用權重共享策略,其中為每個支持張量定義單個矩陣,并且根據分量,對子矩陣進行索引并應用于當前訓練迭代,這允許更好的參數效率,因為最大的權重共享是在子網中完成的。
具有更高容量的GLoRA
模型能力是指模型近似各種函數的能力。調節學習算法的能力的方法包括選擇一個適當的假設空間,本質上是一組函數,學習算法被允許考慮作為潛在的解決方案。本文使用Vapnik-Chervonenkis維數(VC維數)進行統計算法的容量和復雜性的度量。其定義如下所示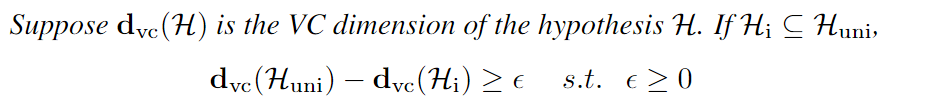
實驗
本文在VTAB-1K基準上對不同參數計數的GLoRA進行了全面評估。VTAB-1K包括19個圖像分類任務。任務分為三個領域:自然圖像;由遙感和醫學數據集組成的專門任務;以及專注于場景結構理解的結構化任務,如深度預測和方向預測等。為了測試少鏡頭微調性能,在五個細粒度視覺識別少鏡頭數據集上評估了GLoRA:Food101、OxfordFlowers102、StandfordCars、OxfordPets和FGVCAircraft。根據之前的工作,本文評估了shot為1、2、4、8和16下的結果。最后,為了展示GLoRA的領域泛化能力,在ImageNet上在shot為16設置下訓練GLoRA,并在ImageNetV2、ImageNet Sketch、ImageNet-a和ImageNet-R上進行測試。
VTAB-1K Dataset
通過訓練三種不同的GLoRA超網配置,以改變可訓練參數的數量。它們之間的區別僅在于搜索空間中的LoRA維度,該維度在最大模型中為8和4,在中間模型中為4和2,在最小模型中為2。本文方法中增加的參數靈活性允許在最終模型中進行用戶定義的可訓練參數計數。VTAB-1k基準測試的結果如下表所示。將最先進的參數有效遷移學習提高了2.9%,即使是最小的模型也大大優于所有現有方法。值得注意的是,在與至少一個數據集上失敗的所有現有工作相比,GLoRA在數據集上表現有競爭力,證明了GLoRA的高泛化能力。GLoRA在VTAB-1k基準測試中的19個數據集中的14個數據集中顯現出了最優的性能,同時在其余數據集上也表現得很有競爭力。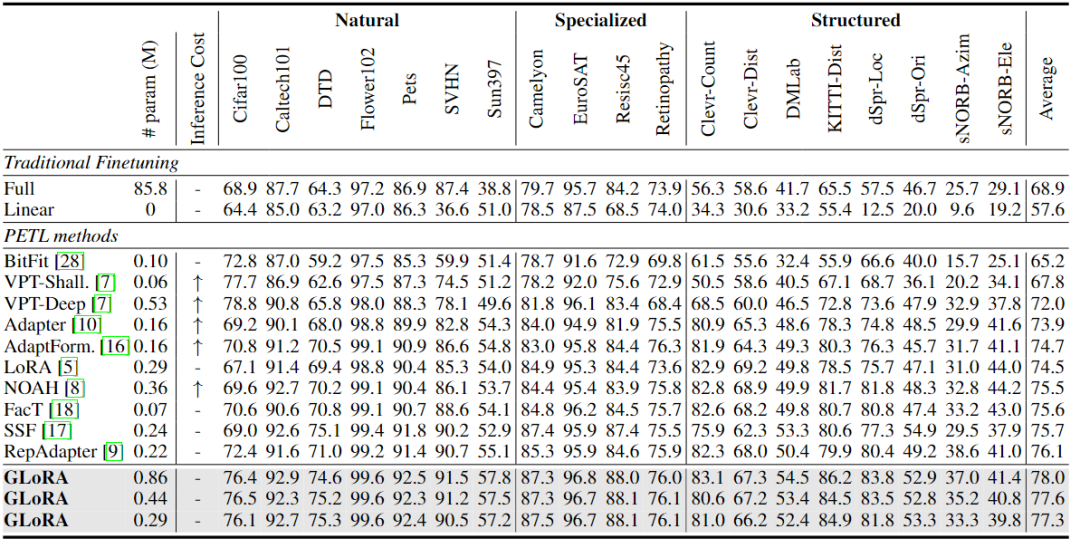
Few-shot Learning
為了在數據可用性有限的情況下擴展GLoRA的評估,將GLoRA在細粒度視覺識別數據集上的性能作為few-shot Learning,并將其與LoRA、Adapter、VPT和NOAH進行比較。1、2、4、8和16的shot結果如下圖所示。GLoRA在大多數few-shot learning數據集中表現出卓越的功效,在參數計數相似的情況下,其性能始終大大優于現有方法。有趣的是,在Flowers102數據集上,由于已經非常出色的整體性能,所有方法都產生了相似的準確度水平。在Food101數據集上,GLoRA的平均準確度與NOAH相當。可以觀察到的第一個子假設來看,在較高的shot場景下,平均性能提升變得更加明顯,然而,即使在較低的shot設置下,效果仍然顯著。
Domain Generalization
域外泛化能力對于大規模神經網絡具有重要的價值。通過PETL方法微調的模型應該表現出增強的域泛化能力,從而使它們更適用于現實場景。下表展示了GLoRA的域外泛化能力,其中單個ImageNet-1K微調的GLoRA模型經過域外數據集的測試。與以前的研究對齊,與現有方法相比,域外性能顯著提高。與LoRA相比,GLoRA提高了100% (ImageNet-A)和50%(ImageNet-Sketch)的域外性能。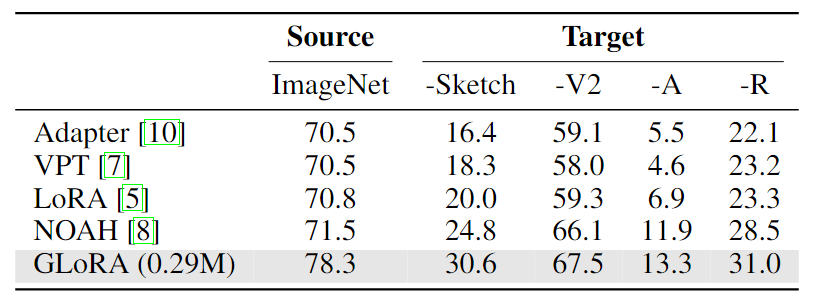
總結
本文提出了GLoRA,這是一種廣義參數高效的微調方法,它成功地證明了增強大規模預訓練模型的微調和遷移學習能力的有效性。通過采用廣義低秩自適應和重新參數化框架,GLoRA減少了微調所需的參數數量和計算量,使其成為實際應用的資源高效和實用的方法。在各種任務和數據集上進行的實驗證實了GLoRA優于現有的PEFT技術,展示了其可擴展性和適應性。這項工作不僅有助于改進大規模預訓練模型的微調過程,而且還為未來的工作開辟了新的途徑,包括進一步探索廣義低秩適應技術、混合方法的開發以及搜索和優化算法的改進。這些領域的研究可能會繼續擴大遷移學習在更廣泛的應用中的可訪問性和效率。
-
神經網絡
+關注
關注
42文章
4762瀏覽量
100535 -
數據集
+關注
關注
4文章
1205瀏覽量
24641 -
自然語言
+關注
關注
1文章
287瀏覽量
13330
原文標題:GLoRA—高效微調模型參數!
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
一種修正的近場聲源定位時延估計方法
有沒有一種方法可以在電機工作臺中微調電機參數呢?
一種改進的LPCC參數提取方法
一種廣義運動模糊模型
一種新的基于電穿孔的皮膚高效核酸遞送方法

四種微調大模型的方法介紹
一種簡單高效配置FPGA的方法
一種信息引導的量化后LLM微調新算法IR-QLoRA






 工商網監
工商網監
評論