 Linux管道符不是你想用就能亂用的!
Linux管道符不是你想用就能亂用的!
一、什么是管道符?
管道符號,是unix一個很強大的功能,符號為一條豎線:"|"。
用法:命令 1 | 命令 2
功能是把第一個命令,即命令 1執行的結果作為命令 2的輸入傳給命令 2
例如命令:
cat test.txt | wc -l
命令功能拆解:
cat test.txt命令功能是打印test.txt文件內容(行數)。
wc -l命令完成行數統計。
整個命令功能就是將cat test.txt的執行結果,通過管道符|,傳給后一個命令wc -l,作為wc -l命令的執行對象。
即上述兩個命令結合管道符完成對test.txt文件的行數統計。
二、使用管道符的便捷之處
通過上述簡單例子,我們應該可以看出使用管道符確實有它便捷的地方。以下羅列幾個,讓大家加深對于管道符使用的便捷之處。
例子1:通過shell分析,查看2023年4月1日14時這一個小時內有多少IP訪問網站;
awk '{print $4,$1}' log_file | grep 01/Apr/2023:14 | awk '{print $2}'| sort | uniq | wc -l
例子2:通過shell分析網站日志,查看有多少個IP訪問?
awk '{print $1}' log_file|sort|uniq|wc -l
三、為什么要少用管道符?
這個才是我們本文講解的重點,也是作為一個高級linux運維人員所要知道的,為什么要少用管道符?并不是說方便就可以大量使用,我們需要考慮到其執行的速度及效率,下面一起通過實例看看管道符要少用的原因!
實例:通過多種統計字符串長度命令的執行效率進行對比,得出管道符要少用的具體原因!
(一)統計字符串長度的命令有哪些?以下舉例4個方法。
方法1:通過echo ${#str1}命令進行統計,其中str1為自定義字符串變量。
方法2:通過expr length "${str1}"命令進行統計,其中str1為自定義字符串變量。
方法3:通過echo命令,結合管道符,以及awk命令實現,如下命令:
echo"${str1}"|awk'{printlength($0)}'
其中str1為自定義字符串變量。
方法4:通過echo命令,結合管道符,以及wc命令實現,如下命令:
echo ${#str1} |wc -L
其中str1為自定義字符串變量。
(二)以上4種統計字符串長度的方法命令,哪一種效率最高,即速度最快?
以下先通過seq相關命令來生成相關的字符串長度。然后通過for循環執行來控制字符串生成次數的情況下,最后再通過time命令統計整個命令的執行時間,通過同等循環條件下,不同命令,結合直觀的運行時間進行比較,得出效率最高的方法。
執行結果1:方法1中,通過echo ${#str1}命令進行統計,具體命令如下:
time for i in {1..10000};do str1=`seq -s "haodao" 100`;echo ${#str1} &> /dev/null;done
命令執行結果,所耗時間如下:
[root@haodaolinux1 ~]# time for i in {1..10000};do str1=`seq -s "haodao" 100`;echo ${#str1} &> /dev/null;done
real 0m19.519s
user 0m8.606s
sys 0m11.374s
通過上述命令執行結果看出,該方法1耗時為19.519秒左右;
執行結果2:方法2中,通過expr length "${str1}"命令進行統計,具體命令如下:
time for i in {1..10000};do str1=`seq -s "haodao" 100`;expr length "${str1}" &> /dev/null;done
命令執行結果,所耗時間如下:
[root@haodaolinux1 ~]# time for i in {1..10000};do str1=`seq -s "haodao" 100`;expr length "${str1}" &> /dev/null;done
real 0m36.041s
user 0m15.888s
sys 0m21.697s
通過上述命令執行結果看出,該方法1耗時為36.041秒左右;
執行結果3:方法3中,通過echo命令,結合管道符,以及awk命令實現進行統計,具體命令如下:
time for i in {1..10000};do str1=`seq -s "haodao" 100`;echo "${str1}" | awk '{print length($0)}' &> /dev/null;done
命令執行結果,所耗時間如下:
time for i in {1..10000};do str1=`seq -s "haodao" 100`;echo "${str1}" | awk '{print length($0)}' &> /dev/null;done
real 0m45.241s
user 0m21.136s
sys 0m35.092s
通過上述命令執行結果看出,該方法1耗時為45.241秒左右;
執行結果4:方法4中,通過echo命令,結合管道符,以及wc命令實現進行統計,具體命令如下:
time for i in {1..10000};do str1=`seq -s "haodao" 100`;echo ${#str1} |wc -L &> /dev/null;done
命令執行結果,所耗時間如下:
[root@haodaolinux1 ~]# time for i in {1..10000};do str1=`seq -s "haodao" 100`;echo ${#str1} |wc -L &> /dev/null;done
real 0m43.024s
user 0m20.671s
sys 0m34.042s
通過上述命令執行結果看出,該方法1耗時為43.024秒左右;
結語:通過以上4種方法執行結果,我們很清楚得出方法1所耗時最少,效率最高。方法2次之;方法3和方法4中都結合了管道符的使用,耗時最多,效率最低。這里面有什么門道呢?我們都知道linux中的shell是由C語言開發的,因此它底層命令效率是最高的,而方法1中用的是linux內置命令,內置的操作;方法2中使用linux內置函數,效率高也就自然而然了。而方法3和方法4通過管道符,這涉及到類似二次加工,效率肯定也就低了。這下,我們知道了吧,管道符雖然在某些使用場景下很便捷,但是其也有其效率低的缺點,因此不能多用!
審核編輯:劉清
-
Linux
+關注
關注
87文章
11123瀏覽量
207912 -
C語言
+關注
關注
180文章
7575瀏覽量
134090
原文標題:切記!Linux管道符不是你想用就能亂用的!
文章出處:【微信號:浩道linux,微信公眾號:浩道linux】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Linux匿名管道和命名管道的區別


Linux系統管道和有名管道的通信機制解析
Linux中的管道和命名管道介紹
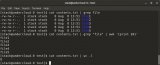
管道數據流"實時性" 和使用小提示
Linux進程間通信方式——管道
Linux進程間通信方法之管道
Linux系統用戶與用戶組管理
linux知識中常用到的管道符號有哪些
linux管道概述





 工商網監
工商網監
評論