") 2023 DPU廠商大盤點(先鋒版)
2023 DPU廠商大盤點(先鋒版)
去年SDNLAB推出的《史上最全DPU廠商大盤點》系列文章受到了很多的討論與關(guān)注,春風(fēng)吹過,又是一年。國內(nèi)自研DPU芯片發(fā)展突飛猛進,DPU應(yīng)用也開始逐漸落地。根據(jù)賽迪顧問發(fā)布的數(shù)據(jù),預(yù)計到2025年全球DPU產(chǎn)業(yè)市場規(guī)模將超過245.3億美元(約1771億人民幣),DPU市場有望實現(xiàn)跳躍式增長,迎來黃金發(fā)展期。
在DPU全球千億市場面前,廠商們今年又整出了什么花活?
以下排名不分先后,按公司簡稱拼音排序:
阿里云:CIPU
2017年10月阿里云推出了神龍架構(gòu),2022年又發(fā)布了一款全新的云數(shù)據(jù)中心專用處理器——CIPU,不同于傳統(tǒng)的以CPU為中心的架構(gòu)設(shè)計,CIPU被定義為云計算的控制和核心性能加速中心。
CIPU向下云化管理數(shù)據(jù)中心硬件,加速計算、存儲和網(wǎng)絡(luò)資源;向上接入飛天云操作系統(tǒng),將全球上百萬臺服務(wù)器變成一臺“超級計算機”。目前,CIPU已經(jīng)在阿里云內(nèi)部有較大規(guī)模的應(yīng)用,為雙11、阿里集團業(yè)務(wù)等內(nèi)部客戶和最新實例提供支撐。
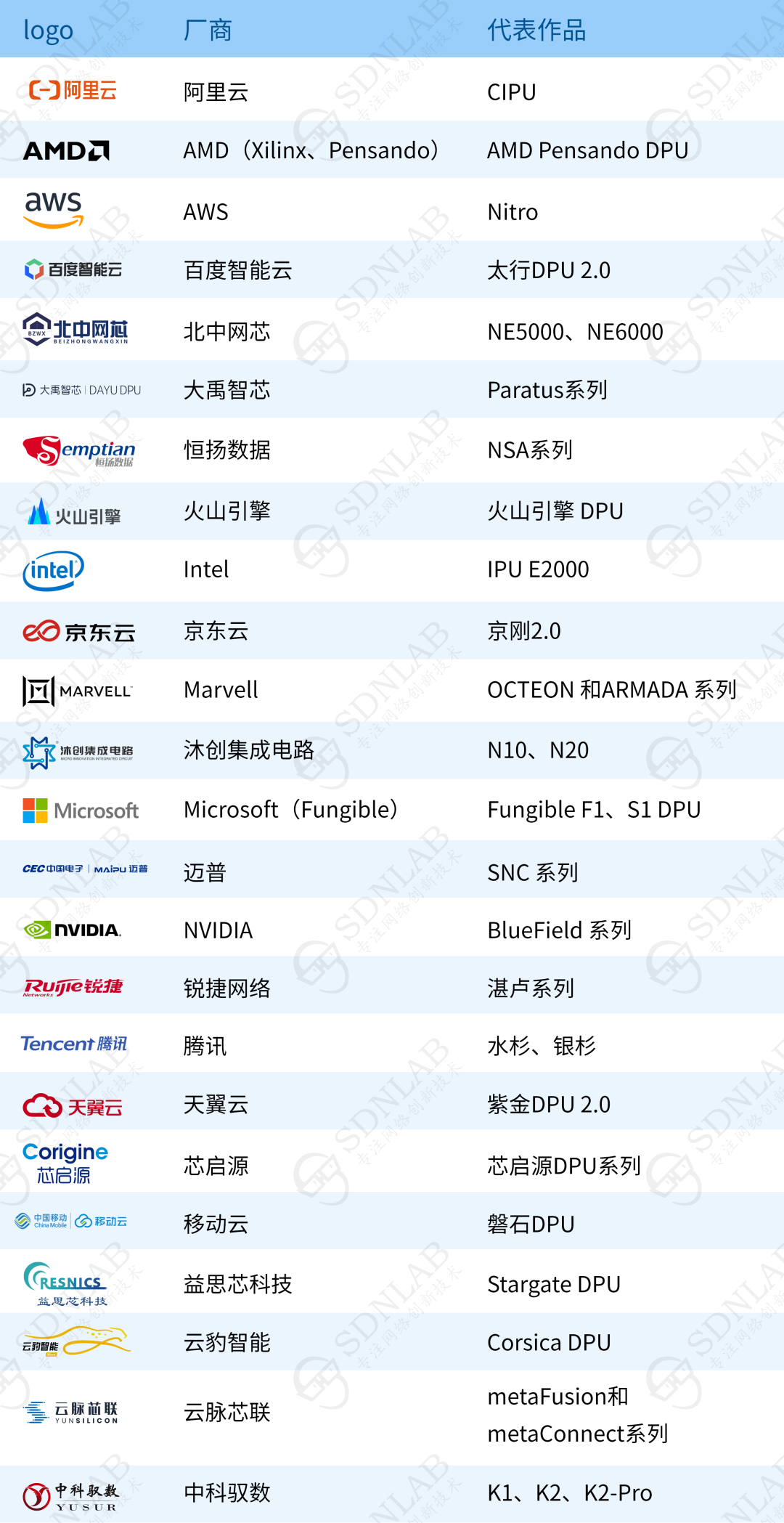
總體來說,CIPU有兩大功能:一是具備對底層基礎(chǔ)設(shè)施資源的虛擬化管理能力,二是能承載飛天對這些資源的編排和調(diào)度需求,并具備存儲、網(wǎng)絡(luò)、計算、安全等硬件加速能力。
存儲方面,其對存算分離架構(gòu)的塊存儲接入進行硬件加速,提供超高性能的云盤。
網(wǎng)絡(luò)方面,其對高帶寬物理網(wǎng)絡(luò)進行硬件加速,通過建設(shè)大規(guī)模的彈性RDMA分布式高性能網(wǎng)絡(luò),實現(xiàn)RDMA技術(shù)的普惠化,客戶無需修改代碼,即可享受CIPU的加速紅利。
計算方面,CIPU快速接入不同類型資源的神龍服務(wù)器,帶來算力的“0”損耗,以及硬件級安全的加固隔離能力(可信根、數(shù)據(jù)加解密等)。
AMD:AMD Pensando DPU
2022 年,AMD以19億美元收購了Pensando,進入DPU賽道。AMD Pensando 平臺的核心是完全可編程 P4 數(shù)據(jù)處理單元 (DPU),采用與超大規(guī)模服務(wù)系統(tǒng)相同的底層技術(shù)。經(jīng)過專門優(yōu)化,通過軟件堆棧實現(xiàn)以云級別提供云服務(wù)、計算、網(wǎng)絡(luò)、存儲和安全服務(wù),并盡可能地降低延遲、抖動和能源需求。
AMD Pensando DPU 將強大的軟件堆棧與“零信任安全”和領(lǐng)先的可編程數(shù)據(jù)包處理器相結(jié)合,打造出更為智能、性能更強的 DPU。AMD Pensando DPU 現(xiàn)已在 IBM 云、微軟Azure 和甲骨文云等云合作伙伴中大規(guī)模部署。在企業(yè)中,它被部署在 HPE Aruba CX 10000 智能交換機中,與領(lǐng)先的 IT 服務(wù)公司 DXC 等客戶合作,作為 VMware vSphere Distributed Services Engine 的一部分,為客戶加速應(yīng)用程序性能。
AMD還公布了代號為“Giglio”的下一代 DPU 路線圖,與當(dāng)前一代產(chǎn)品相比,該路線圖旨在為客戶帶來更高的性能和能效,預(yù)計將于 2023 年底上市。
AWS :Nitro
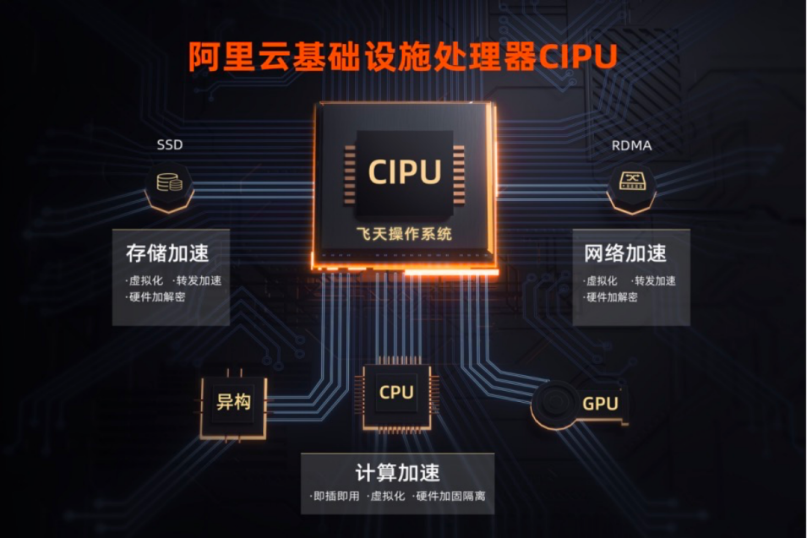
AWS 是早期自研DPU的云廠商之一。2015年,AWS收購了芯片廠商Annapurna Labs,2017年正式推出Nitro芯片。AWS Nitro DPU 系統(tǒng)目前已經(jīng)成為了AWS 云服務(wù)的技術(shù)基石。AWS 借助 Nitro DPU 系統(tǒng)把網(wǎng)絡(luò)、存儲、安全和監(jiān)控等功能分解并轉(zhuǎn)移到專用的硬件和軟件上,將服務(wù)器上幾乎所有資源都提供給服務(wù)實例,極大地降低了成本。
Nitro DPU 系統(tǒng)主要分為以下幾個部分:
Nitro Hypervisor是一個輕量級虛擬機監(jiān)控程序只負責(zé)管理 CPU 和 Memory 的分配,幾乎不占用 Host 資源,所有的服務(wù)器資源都可用來執(zhí)行客戶的工作負載。
Nitro Cards是一系列用于卸載和加速的協(xié)處理外設(shè)卡,承載網(wǎng)絡(luò)、存儲、安全及管理功能,使得網(wǎng)絡(luò)和存儲性能得到了極大提升,并且從硬件層提供天然的安全保障。
Nitro Security Chip提供了面向?qū)S糜布O(shè)備及其固件的安全防護能力,包括限制云平臺維護人員對設(shè)備的訪問權(quán)限,消除人為的錯誤操作和惡意篡改。
Nitro Enclaves基于 Nitro Hypervisor 進一步提供了創(chuàng)建 CPU 和 Memory 完全隔離的計算環(huán)境的能力,以保護和安全地處理高度敏感的數(shù)據(jù)。
Nitro TPM(可信平臺模塊)支持 TPM 2.0 標準,Nitro TPM 允許 EC2 實例生成、存儲和使用密鑰,繼而支持通過 TPM 2.0 認證機制提供實例完整性的加密驗證。
百度智能云:太行DPU 2.0
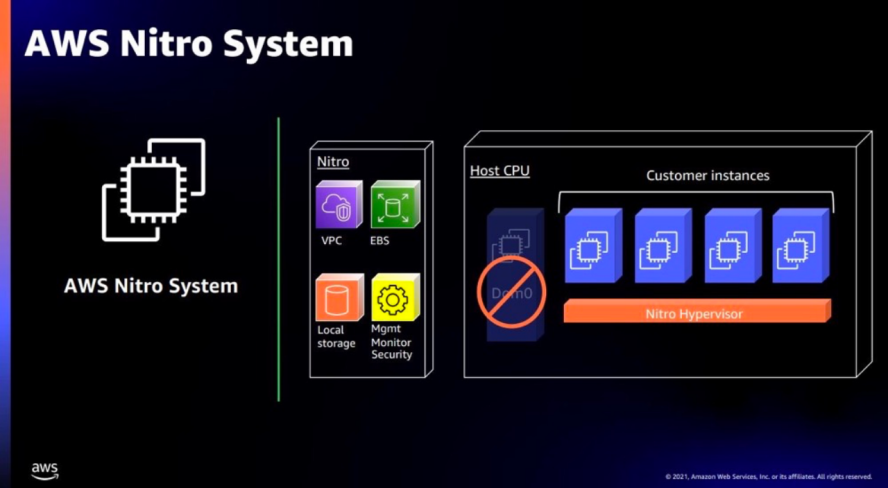
在第五屆Create AI開發(fā)者大會上,百度重磅發(fā)布了新一代計算架構(gòu)——百度太行DPU2.0,全新太行DPU2.0具備多平臺、多場景、多協(xié)議、多業(yè)務(wù)四大核心能力,支持Intel、AMD、ARM平臺,同時支持計算、存儲、網(wǎng)絡(luò)、虛擬化等功能。
百度智能云對 DPU2.0的核心定位是“Cloud Native IO Engine”。云架構(gòu)下的核心問題就在于數(shù)據(jù)中心東西向流量大增,IO 的負擔(dān)太大。因此重點需要解決在多租戶、細粒度算力形態(tài)、后端解耦的硬件資源池架構(gòu)下,海量的 IO 數(shù)據(jù)搬移、通信、處理、安全等等問題。重新定義軟硬件邊界。
百度太行 DPU2.0主要包含5大關(guān)鍵技術(shù):
軟件定義虛擬化,支持萬級虛擬設(shè)備;
網(wǎng)絡(luò)硬件加速,由軟件轉(zhuǎn)發(fā)變成硬件轉(zhuǎn)發(fā);
高性能的 RDMA 網(wǎng)絡(luò),用自研協(xié)議解決流控留空、擁塞等問題;
存算分離硬件加速,通過超大資源池打平本地和遠程的區(qū)別;
云管控硬件通道,保證各形態(tài)計算實例共池,實現(xiàn)熱遷移、熱升級、熱插拔等特性,支持千億級模型訓(xùn)練。
百度太行DPU發(fā)展路徑如下所示:
北中網(wǎng)芯:NE5000、NE6000
成都北中網(wǎng)芯科技有限公司于2020年4月成立,專注于網(wǎng)絡(luò)通信和安全領(lǐng)域的芯片設(shè)計和開發(fā)。經(jīng)過研發(fā)團隊長期的技術(shù)攻堅,公司率先推出基于SOC-NP可編程架構(gòu)NE6000 DPU芯片、NE5000 DPU芯片,并基于自研芯片推出2*100GbE智能網(wǎng)卡、2*25GbE智能網(wǎng)卡、VPN和DPI等一系列技術(shù)研發(fā)成果。
北中網(wǎng)芯鯖鯊系列首款網(wǎng)絡(luò)數(shù)據(jù)處理DPU芯片NE6000于2022年11月13日流片成功,這款芯片基于專用的NP可編程芯片架構(gòu),采用28nm工藝制程,兼具高性能、可編程、低延時、低功耗等特點,具有雙向200Gbps的處理能力。
NE6000專注于網(wǎng)絡(luò)數(shù)據(jù)處理和安全防護功能,可實現(xiàn)網(wǎng)絡(luò)協(xié)議處理、交換路由、安全檢測等高性能和高效率的任務(wù),具備25GE和100GE網(wǎng)絡(luò)接入能力。NE6000通過微碼編程升級,可根據(jù)最終用戶需求靈活進行網(wǎng)絡(luò)報文協(xié)議解析和編輯,適應(yīng)任何網(wǎng)絡(luò)協(xié)議的變化。
NE6000芯片所特有的級聯(lián)特性可實現(xiàn)表項擴展和性能擴展,進一步增強系統(tǒng)的靈活性和可擴展性。級聯(lián)接口傳輸帶寬可達100Gbps,傳輸延時小于1us。NE6000在靈活性、可編程性、性能、功耗、流片條件等多個維度取得了很好的平衡。
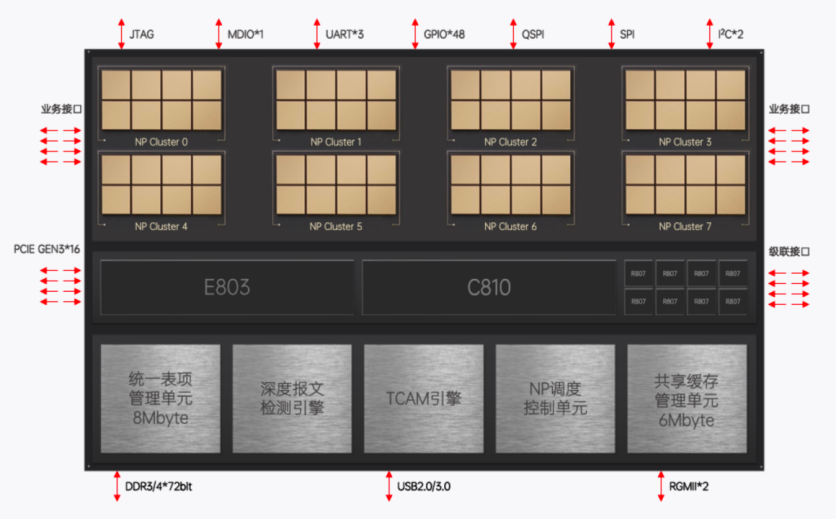
NE6000芯片的應(yīng)用范圍廣泛,可以滿足云計算、數(shù)據(jù)通信、網(wǎng)絡(luò)安全、5G、邊緣計算、人工智能等領(lǐng)域的需求,適應(yīng)數(shù)據(jù)中心、物聯(lián)網(wǎng)、車聯(lián)網(wǎng)等不同業(yè)務(wù)場景,以及滿足負載均衡、VPN網(wǎng)關(guān)、下一代防火墻、智能網(wǎng)卡等不同產(chǎn)品形態(tài)的要求。
大禹智芯:Paratus系列
大禹智芯是一家專注于提供DPU產(chǎn)品設(shè)計、研發(fā)與服務(wù)的國家高新科技企業(yè)。為滿足不同客戶及不同場景的DPU使用需求,大禹智芯堅持從貼近用戶需求的場景出發(fā),遵循明確的產(chǎn)品規(guī)劃路線,提供Paratus系列DPU產(chǎn)品,目前已推出2個產(chǎn)品序列:

1.0序列產(chǎn)品——Paratus 1.0、Paratus 1.5
Paratus 1.0和Paratus 1.5是大禹智芯的第一款DPU產(chǎn)品。通過運行在ARM SoC上的Linux操作系統(tǒng)及DPDK、SPDK開發(fā)套件,用戶可將原先運行在主機側(cè)的功能方便的下沉到DPU上運行,實現(xiàn)主機側(cè)算力資源的釋放。基于相同的DPU開發(fā)運行環(huán)境,大禹智芯也提供了虛擬化網(wǎng)絡(luò)組件,存儲客戶端組件以及與開源云管平臺Openstack和Kubernetes集成所必要的相關(guān)組件。用戶通過Paratus1.0構(gòu)建高性能的裸金屬云、虛擬機云及容器云等服務(wù)。Paratus 1.0可廣泛應(yīng)用于公有云,邊緣云,企事業(yè)內(nèi)部私有云及其他復(fù)雜網(wǎng)絡(luò)流量處理等場景。
2.0序列產(chǎn)品——Paratus 2.0
Paratus 2.0是大禹智芯在1.0序列產(chǎn)品基礎(chǔ)上,通過增加FPGA組件而打造的全新DPU產(chǎn)品。采用ARM SoC + FPGA的硬件架構(gòu),在保持了與第一款DPU產(chǎn)品相同的軟件開發(fā)運行環(huán)境的同時,提供了基于FPGA的網(wǎng)絡(luò)數(shù)據(jù)處理通路,大幅提升了網(wǎng)絡(luò)流量處理能力。在此基礎(chǔ)上,Paratus 2.0還具有一些獨特的功能:大禹智芯自研高性能網(wǎng)絡(luò)協(xié)議HPRT的實現(xiàn)可充分釋放RDMA應(yīng)用的潛力;無感知端到端網(wǎng)絡(luò)數(shù)據(jù)加密功能可最大化保證數(shù)據(jù)網(wǎng)絡(luò)傳輸可靠性,其功能及性能均為業(yè)界領(lǐng)先水平;網(wǎng)絡(luò)上層應(yīng)用行為分析功能可為網(wǎng)絡(luò)入侵行為判斷提供實時可靠的數(shù)據(jù)支撐。
恒揚數(shù)據(jù):NSA系列
深圳市恒揚數(shù)據(jù)股份有限公司成立于2003年,通過靈活多變的客制化定制方式,為客戶提供個性化DPU加速產(chǎn)品及異構(gòu)計算加速方案的設(shè)計、研發(fā)及生產(chǎn),滿足用戶在機器學(xué)習(xí)、視頻轉(zhuǎn)碼、圖像識別、語音識別、自然語言處理、基因組測序分析等多種應(yīng)用場景的加速需求,實現(xiàn)高性能、高帶寬、低延遲、低功耗的智能化計算加速。
恒揚數(shù)據(jù)DPU產(chǎn)品面向數(shù)據(jù)中心設(shè)計,為服務(wù)器提供高帶寬IO,為數(shù)據(jù)中心算力提供高性能卸載,產(chǎn)品在網(wǎng)絡(luò)、存儲、安全、計算領(lǐng)域得到廣泛批量應(yīng)用。基于FPGA的設(shè)計方式,可極大地利用FPGA自身豐富的邏輯單元,實現(xiàn)對數(shù)據(jù)的快速并行處理,通過較小的能耗開銷,實現(xiàn)數(shù)據(jù)中心性能的大幅躍遷。
恒揚數(shù)據(jù)NSA系列DPU產(chǎn)品及解決方案依托FPGA、FPGA+CX、FPGA+CPU等多種架構(gòu)設(shè)計,其中FPGA單元主要基于Xilinx Zynq系列、KU系列、VU系列、VP系列,CX系列(包括CX5、CX6)芯片研制開發(fā),產(chǎn)品可廣泛應(yīng)用于互聯(lián)網(wǎng)數(shù)據(jù)中心的網(wǎng)絡(luò)、存儲、安全、計算等加速場景,是集高速IO帶寬和高性能計算處理為一體的異構(gòu)數(shù)據(jù)處理加速單元。
產(chǎn)品方案可廣泛應(yīng)用于云數(shù)據(jù)中心網(wǎng)絡(luò)、存儲加速,網(wǎng)絡(luò)虛擬化卸載、RDMA網(wǎng)絡(luò)加速及資源池化等多種場景,助力客戶在云數(shù)據(jù)中心的算力加速,包括圖片/視頻的處理分析、目標識別與追蹤、基因測序、版權(quán)保護、傳播影響力監(jiān)測、素材管理等領(lǐng)域的算法加速。
火山引擎:火山引擎 DPU
火山引擎是字節(jié)跳動于2021年6月推出的云服務(wù)業(yè)務(wù)板塊,至今逐漸完善了IaaS+PaaS+SaaS云服務(wù)體系。在2023火山引擎原動力大會上,火山引擎全棧自研核心組件——火山引擎DPU重磅登場。
火山引擎基于自研DPU推出了新一代服務(wù)器實例,整體性能大幅提升。在Intel全新一代SPR CPU平臺上,通過引入火山引擎DPU,整機性能最高提升93%,單核性能最高提升13%。≤16c小規(guī)格實例性能最高提升6倍以上。

在AMD全新一代Genoa CPU平臺上,通過引入火山引擎DPU,整機性能最高提升138%,單核性能最高提升39%。≤16c小規(guī)格實例性能最高提升10倍以上。而在Nvidia A800 裸金屬上,擁有火山引擎DPU的加持,跨節(jié)點提供800Gbps RDMA網(wǎng)絡(luò)帶寬,更加適用于大規(guī)模集群分布式訓(xùn)練場景,提高集群并行效率,相較于上一代實例集群性能最高提升3倍以上。
據(jù)悉,火山引擎 DPU 整體網(wǎng)絡(luò)性能升級到 5000 萬 pps 轉(zhuǎn)發(fā)能力,20us 延遲。目前,字節(jié)內(nèi)部已經(jīng)實現(xiàn)上萬臺 DPU 的部署,并且將持續(xù)提升滲透率。基于自研 DPU 的各類計算實例性能也有顯著提升,例如適用于大模型分布式并行訓(xùn)練場景的 GPU 實例,相較上一代實例集群性能最高提升 3 倍以上。
Intel:IPU E2000
Intel在 2021 年 6 月正式提出了IPU,目的是改善資料中心效率與管理簡便度,并強調(diào)這是唯一與超大型云端客戶合作構(gòu)建的加速與卸載解決方案。
E2000是Intel和谷歌共同設(shè)計的新型定制IPU芯片,代號為“Mount Evans”,以降低數(shù)據(jù)中心主 CPU 負載,并更有效和安全地處理數(shù)據(jù)密集型云工作負載。特性如下:
2 個 100 GbE 或 1 個 200 GbE 連接
多達 16 個 Arm Neoverse N1 核心
PCIe 4.0 x16
支持高達 48 GB DRAM

Oak Springs Canyon是Intel第二代基于 FPGA 的 IPU 平臺,該平臺采用Intel Xeon-D和Agilex FPGA 構(gòu)建。
在 2022 年的 Vision 全球用戶大會期間,公布了其最新的IPU路線圖,展示了從2022年至2026年IPU的整體規(guī)劃。英特爾將繼續(xù) ASIC + FPGA IPU 設(shè)計,其IPU路線圖如下:
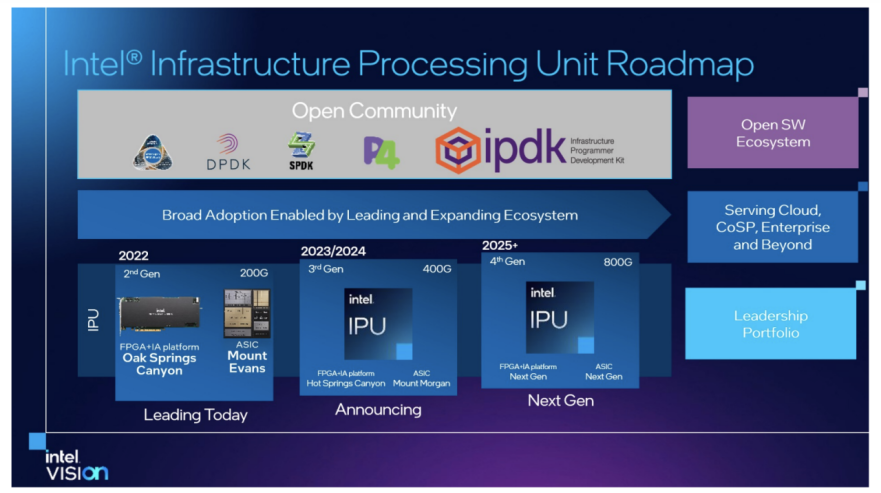
2022年:推出了200 Gbps IPU,代號為Mount Evans和Oak Springs Canyon。
2023/2024年:推出 400 Gbps IPU,代號為Mount Morgan和Hot Springs Canyon。
2025/2026 : 推出800 Gbps IPU。
京東云:京剛2.0
京剛是京東云自主研發(fā)的行業(yè)領(lǐng)先的全業(yè)務(wù)軟硬一體虛擬化引擎,包括京剛智能網(wǎng)卡和完整的計算、存儲、網(wǎng)絡(luò)虛擬化協(xié)議棧和管理軟件。在2022京東云峰會上,京東云正式發(fā)布了京剛2.0。
作為數(shù)據(jù)中心級DPU引擎,京剛2.0存儲IOPS、網(wǎng)絡(luò)轉(zhuǎn)發(fā)性能均提升50%,效能提升立竿見影。基于存算分離技術(shù)自主研發(fā)的統(tǒng)一存儲平臺云海,打破了存算一體限制,使計算資源利用率提升30%。京剛2.0+云海軟硬融合,存儲性能提升10倍,極大提升了資源利用率,目前已經(jīng)全面應(yīng)用于京東618、京東11.11等大規(guī)模復(fù)雜場景。
京剛智能網(wǎng)卡的核心為基于FPGA的京剛DPU芯片,使用硬件替代軟件完成虛擬化工作,極大提升了資源利用率。京剛智能芯片卸載網(wǎng)絡(luò)轉(zhuǎn)發(fā)和存儲IO功能,讓硬件性能不受損,支持了業(yè)界標準的SRIOV虛擬化技術(shù),保證設(shè)備虛擬化無開銷;同時,芯片級的硬件隔離技術(shù),實現(xiàn)了用戶負載和云管理負載的完全隔離,大幅提升了云計算平臺的安全級別。
此外,京剛2.0還做到了更廣泛的適配,同時支持x86架構(gòu)下Intel、AMD處理器,及ARM架構(gòu)下安培、飛騰等處理器,應(yīng)用場景進一步擴大。
Marvell:OCTEON 和 ARMADA 系列
Marvell 的 OCTEON 和 ARMADA 系列設(shè)備用于 5G 無線基礎(chǔ)設(shè)施和網(wǎng)絡(luò)設(shè)備,包括交換機、路由器、安全網(wǎng)關(guān)、防火墻、網(wǎng)絡(luò)監(jiān)控和 SmartNIC(智能網(wǎng)絡(luò)接口卡)。
OCTEON 10 DPU 針對具有挑戰(zhàn)性的超大規(guī)模云工作負載、5G 傳輸處理、5G RAN 智能控制器 (RIC) 和邊緣推理、運營商和企業(yè)數(shù)據(jù)中心應(yīng)用以及無風(fēng)扇網(wǎng)絡(luò)邊緣盒進行了優(yōu)化。OCTEON 10 DPU采用 Arm Neoverse N2 內(nèi)核,5nm 工藝,與前幾代 OCTEON 相比計算性能提高 3 倍,功耗降低 50%。
OCTEON TX2 是 64 位 ARM SoC 處理器,將多達 36 個內(nèi)核與可配置和可編程硬件加速器模塊相結(jié)合,支持高達 200G 的數(shù)據(jù)路徑。
OCTEON MIPS64 多核DPU是唯一采用定制設(shè)計的 64 位 cnMIPS 內(nèi)核并可擴展至 48 個內(nèi)核的 DPU 系列。它結(jié)合了網(wǎng)絡(luò) I/O 以及先進的安全性、存儲和應(yīng)用程序硬件加速,提供高吞吐量和可編程性。
ARMADA DPU經(jīng)過定制設(shè)計,可提供最佳性能、低功耗和高集成度。ARMADA DPU 系列針對計算、網(wǎng)絡(luò)和存儲平臺中的成本優(yōu)化應(yīng)用進行了優(yōu)化。
Marvell 為所有 OCTEON 和 ARMADA 系列提供統(tǒng)一軟件開發(fā)套件 (SDK)。DPU系列設(shè)備的功能通過開源數(shù)據(jù)包和安全應(yīng)用加速 API 得到增強。Marvell還提供行業(yè)標準控制、管理和數(shù)據(jù)平面軟件堆棧,針對最新一代基于 ARM 的 OCTEON 處理器進行了優(yōu)化。
沐創(chuàng)集成電路:N10、N20
無錫沐創(chuàng)集成電路設(shè)計有限公司成立于2018年12月,專注于可重構(gòu)可編程系統(tǒng)芯片的研發(fā)和銷售,主要產(chǎn)品包括密碼安全芯片和智能網(wǎng)絡(luò)控制器芯片。
2021年,沐創(chuàng)首款純國產(chǎn)化智能網(wǎng)絡(luò)控制器芯片N10順利推出。N10系列智能網(wǎng)絡(luò)控制器芯片是基于清華大學(xué)可重構(gòu)技術(shù)開發(fā)出來的網(wǎng)卡芯片,擁有完全自主知識產(chǎn)權(quán);支持八口10G,雙口25G,雙口40G 以太網(wǎng)接口,內(nèi)置可重構(gòu)處理器內(nèi)核,支持網(wǎng)絡(luò)協(xié)議卸載處理,同時還支持高效的密碼算法加速,通過可重構(gòu)實現(xiàn)40Gbps 的密碼算法處理,支持國際密碼(AES/SHA/RSA)和國內(nèi)商用密碼(SM2/3/4)等數(shù)十種算法,實現(xiàn)高效的IPSec/TLS 加速。RNP N10智能網(wǎng)絡(luò)控制器芯片具有高安全、高性能、可編程等特點。截至當(dāng)前,N10系列芯片已與百余家客戶完成適配,并在眾多客戶的不同應(yīng)用場景中落地生根。
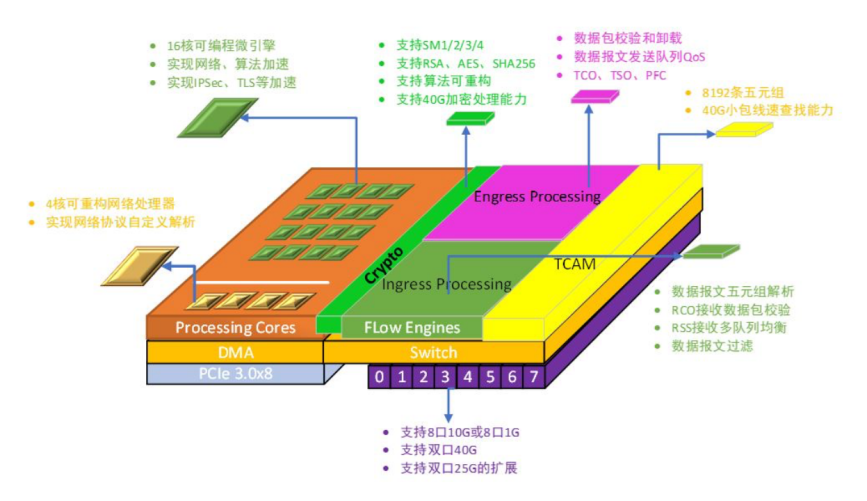
N10架構(gòu)圖
N20是沐創(chuàng)在研的第二代智能網(wǎng)絡(luò)控制器芯片,是一款25G/100G的智能網(wǎng)卡芯片,具備高速網(wǎng)絡(luò)協(xié)議卸載,RDMA,網(wǎng)絡(luò)可編程,虛擬化等能力。主要面向國產(chǎn)服務(wù)器、網(wǎng)絡(luò)安全設(shè)備、云廠等廠家,為其提供100G網(wǎng)卡芯片產(chǎn)品。
沐創(chuàng)公司的產(chǎn)品路線圖如下:
N10:2021年,第一代智能網(wǎng)絡(luò)控制器,10G/40G,支持基礎(chǔ)的網(wǎng)絡(luò)協(xié)議卸載能、安全卸載和可編程能力;
N20:2023年,第二代智能網(wǎng)絡(luò)控制器,25G/100G,支持RDMA、OVS,更高性能的網(wǎng)絡(luò)協(xié)議卸載、安全卸載、可編程能力;
N30:2025年,第三代智能網(wǎng)絡(luò)控制器,100G,多核ARM架構(gòu),數(shù)據(jù)平面和控制平面的全面卸載。
Microsoft(Fungible):
F1、S1
2023 年1 月,微軟宣布收購 DPU 技術(shù)提供商 Fungible。Fungible 曾經(jīng)是最熱門的半導(dǎo)體初創(chuàng)公司之一,自 2015 年以來已籌集了超過 3.7 億美元的資金。Fungible 是第一家針對云級 DPU 的商業(yè)芯片公司,先于Intel、Nvidia、Pensando (AMD) 和 Marvell。
Fungible DPU 平臺包括硬件和軟件,按需拆分或組合計算和存儲資源。它包括兩個核心部分:一是可編程數(shù)據(jù)路徑引擎,它可以高速執(zhí)行以數(shù)據(jù)為中心的計算,并提供比通用 CPU 更大的靈活性。二是實現(xiàn) Fungible 專有 TrueFabric 端點的網(wǎng)絡(luò)引擎。可提供確定性的低延遲、高帶寬、擁塞和錯誤控制以及從數(shù)百到數(shù)十萬個節(jié)點的高安全性。
Fungible 有兩款DPU芯片。Fungible F1 DPU 是一款 800 Gb/s 芯片,專為高性能存儲、分析和安全平臺而設(shè)計。Fungible S1 DPU 是一款 200 Gb/s 芯片,針對主機端用例進行了優(yōu)化,包括裸機虛擬化、存儲啟動器、NFV 基礎(chǔ)設(shè)施/虛擬網(wǎng)絡(luò)功能 (VNF) 應(yīng)用程序和分布式節(jié)點安全性。
Fungible S1 DPU 經(jīng)過優(yōu)化,可在服務(wù)器節(jié)點內(nèi)組合以數(shù)據(jù)為中心的計算并在節(jié)點間高效移動數(shù)據(jù)。以數(shù)據(jù)為中心的計算的特點是高速數(shù)據(jù)流的有狀態(tài)處理,通常是通過網(wǎng)絡(luò)、安全和存儲堆棧。S1 DPU 通過其 TrueFabric技術(shù)促進服務(wù)器節(jié)點之間的數(shù)據(jù)交換。
邁普:SNC 系列
邁普通信 SNC 系列智能網(wǎng)卡是邁普公司面向新一代云數(shù)據(jù)中心推出的智能化網(wǎng)絡(luò)接口控制器。該系列智能網(wǎng)卡為公有云/專為云、高性能計算、人工智能和超大規(guī)模計算等應(yīng)用而設(shè)計,提供強大的網(wǎng)絡(luò)和應(yīng)用平臺能力,用于應(yīng)對現(xiàn)代云和數(shù)據(jù)中心在網(wǎng)絡(luò)性能、軟件定義網(wǎng)絡(luò)(SDN)、業(yè)務(wù)卸載、計算加速以及定制化解決方案等方面的挑戰(zhàn)。
該產(chǎn)品型號為 SNC4000-2S,該系列產(chǎn)品在滿足傳統(tǒng)的彈性裸金屬及虛擬化場景下,追求高性價比以及提供強大的場景化定制能力,可靈活適應(yīng)于客戶特定的應(yīng)用場景和服務(wù)器類型,可按需打造滿足客戶特定要求的高價值解決方案。
該產(chǎn)品型號為 SNC5000-2S,該系列產(chǎn)品技術(shù)架構(gòu)先進,根據(jù)不同的業(yè)務(wù)應(yīng)用場景,提供基于 CPU+FPGA 芯片的智能網(wǎng)卡解決方案,國內(nèi)技術(shù)領(lǐng)先。可針對數(shù)據(jù)中心計算/網(wǎng)絡(luò)/存儲等基礎(chǔ)設(shè)施,提供區(qū)別于傳統(tǒng)網(wǎng)卡的強大優(yōu)化能力,如網(wǎng)絡(luò)加速、OVS 卸載、存儲標準化、加解密、安全卸載、裸金屬管理、可編程能力等。從芯片到硬件到軟件的全方位提供安全可控、穩(wěn)定、可靠、開放的高性能智能網(wǎng)卡軟硬件平臺。
該產(chǎn)品型號為 SNC5000-2H,具備 100G 的接口能力以及標準的 BMC 管理能力,致力于 打造高吞吐轉(zhuǎn)發(fā)性能以及高 IOPS 存儲性能的產(chǎn)品。除傳統(tǒng)裸金屬和虛擬化場景智能網(wǎng)卡的 能力外,還提供適用于容器等場景對 SRIOV 有極致虛擬化要求的能力,以及提供硬件國密加解密算法能力。
NVIDIA:BlueField 系列
NVIDIA是一家以設(shè)計顯示芯片和主板芯片組為主的半導(dǎo)體公司,總部位于美國加利福尼亞州圣克拉拉市。2020 年 4 月,Nvidia 以 69 億美元的價格收購了網(wǎng)絡(luò)芯片和設(shè)備公司 Mellanox,隨后陸續(xù)推出 BlueField 系列 DPU。
NVIDIA BlueField-3 DPU 延續(xù)了 BlueField-2 DPU 的特性,是首款為 AI 和加速計算而設(shè)計的 DPU。BlueField-3 DPU 提供了最高 400Gbps 網(wǎng)絡(luò)連接,可以卸載、加速和隔離軟件定義網(wǎng)絡(luò)、存儲、安全和管控功能,從而提高數(shù)據(jù)中心性能、效率和安全性。
BlueField-3 DPU 能夠滿足苛刻的應(yīng)用基礎(chǔ)設(shè)施需求,在I/O路徑中提供強大的計算能力和廣泛的可編程加速引擎,同時通過NVIDIA DOCA軟件框架提供完整的軟件向后兼容性。
BlueField-3 DPU 將傳統(tǒng)的計算環(huán)境轉(zhuǎn)變?yōu)楦咝阅堋⒏咝Ш涂沙掷m(xù)的數(shù)據(jù)中心,使組織能夠在安全的多租戶環(huán)境中運行應(yīng)用程序工作負載。BlueField-3 DPU 將數(shù)據(jù)中心基礎(chǔ)設(shè)施與業(yè)務(wù)應(yīng)用分離,增強了數(shù)據(jù)中心的安全性,簡化了操作并降低了總擁有成本。
銳捷網(wǎng)絡(luò):湛盧系列
銳捷網(wǎng)絡(luò)結(jié)合對云數(shù)據(jù)中心方案和運營商數(shù)據(jù)中心業(yè)務(wù)的理解,推出了智能網(wǎng)卡產(chǎn)品,面向裸金屬、虛擬化和存儲卸載三大場景,整合運營商大云方案開發(fā)智能網(wǎng)卡解決方案,在提升服務(wù)器內(nèi)網(wǎng)絡(luò)性能同時,實現(xiàn)網(wǎng)絡(luò)Overlay、混合Overlay過渡到統(tǒng)一的主機Overlay架構(gòu),簡化了運營商云數(shù)據(jù)中心的邏輯組網(wǎng)模式,支持裸金屬、虛擬化環(huán)境,實現(xiàn)統(tǒng)一的網(wǎng)絡(luò)架構(gòu),并且具有更強的轉(zhuǎn)發(fā)性能和可編程特性,可靈活擴展有狀態(tài)安全組、QoS流控和SDN網(wǎng)絡(luò)功能,同時Underlay層面的物理交換機不再與SDN方案綁定,增加了運營商云數(shù)據(jù)中心網(wǎng)絡(luò)設(shè)備選擇的靈活性。
銳捷網(wǎng)絡(luò)支持 2x100G和2x25G智能網(wǎng)卡:

RG-SMARTNIC-2000 雙口100G智能網(wǎng)卡(左)、RG-SMARTNIC-1810雙口25G智能網(wǎng)卡(右)
銳捷網(wǎng)絡(luò)湛盧系列智能網(wǎng)卡基于FPGA+SOC增強架構(gòu),支持裸金屬和虛擬化兩種模式,通過FPGA實現(xiàn)OVS快路徑的轉(zhuǎn)發(fā)功能卸載,通過SOC實現(xiàn)OVS DPDK慢路徑轉(zhuǎn)發(fā)和存儲SPDK控制功能卸載,因此支持轉(zhuǎn)發(fā)和控制功能的網(wǎng)絡(luò)全卸載。
銳捷智能網(wǎng)卡基于FPGA+SOC架構(gòu),可以根據(jù)用戶將來需求不斷迭代新功能。支持裸金屬、虛擬化和存儲卸載三大場景功能,支持OVS 轉(zhuǎn)發(fā)和控制功能全卸載。銳捷智能網(wǎng)卡方案可以實現(xiàn)與運營商云平臺全面對接,可在 SOC 上部署裸金屬插件、存儲插件、虛擬火墻等應(yīng)用。
騰訊:水杉、銀杉
2020年9月,騰訊第一代基于FPGA的自研智能網(wǎng)卡正式上線,命名為“水杉”。水杉投入應(yīng)用后,“銀杉”的研發(fā)工作也緊鑼密鼓地啟動,并于2021年10月正式上線。

在網(wǎng)絡(luò)方面,銀杉提供2*100G網(wǎng)絡(luò)帶寬、高達5000萬PPS的超高網(wǎng)絡(luò)性能;存儲方面,提供高達100萬IOPS,存儲延遲低于40微秒;同時,銀杉具備彈性RMDA支持,可為業(yè)務(wù)提供Bypass kernel和零拷貝的網(wǎng)絡(luò)傳輸能力,網(wǎng)絡(luò)延遲低于5微秒,滿足企業(yè)高性能計算和集群訓(xùn)練場景的高性能需求。
目前,騰訊自研DPU已經(jīng)支撐公有云外部客戶,以及微信、QQ、騰訊會議等自研業(yè)務(wù)上云。
2021 年 11 月,騰訊發(fā)布了玄靈智能網(wǎng)卡芯片,騰訊表示其定位于云主機的性能加速,結(jié)合CVM/BM/容器等場景優(yōu)化芯片架構(gòu),將原來運行在主CPU上的虛擬化、網(wǎng)絡(luò)/存儲IO等功能下移到芯片,實現(xiàn)了主CPU的零占用,相比業(yè)界產(chǎn)品性能提升了4倍。這一芯片的目標或許和云計算有關(guān),更進一步或許和云游戲相關(guān),游戲業(yè)務(wù)對騰訊至關(guān)重要,而云游戲則面向未來,通過玄靈智能網(wǎng)卡芯片,騰訊或?qū)⑦M一步完成其在云游戲領(lǐng)域的深入布局。
天翼云:紫金DPU 2.0
天翼云紫金DPU 2.0采用FPGA+SoC架構(gòu),依托于FPGA超高的性能和靈活的可編程特性,將數(shù)據(jù)面全卸載到FPGA,實現(xiàn)業(yè)務(wù)的直接硬件卸載加速,支持網(wǎng)絡(luò)虛擬化、存儲虛擬化、IO虛擬化、RDMA、高可用等關(guān)鍵技術(shù)。相較于傳統(tǒng)數(shù)據(jù)中心,搭配紫金DPU的新一代數(shù)據(jù)中心,具有多個方面的領(lǐng)先優(yōu)勢。
軟硬協(xié)同卸載加速。充分發(fā)揮軟件“功能全”,硬件“速度快”的優(yōu)勢。讓硬件專注解決主要矛盾,發(fā)揮極致性能;軟件則提供完整功能,負責(zé)整個系統(tǒng)的兜底。整個系統(tǒng)軟硬協(xié)同,通力合作,從而達到1+1>2的協(xié)同效果。網(wǎng)絡(luò)轉(zhuǎn)發(fā)性能超過5000萬PPS,存儲讀寫性能超過200萬IOPS。
SF-STACK超融合協(xié)議棧。打造內(nèi)核態(tài)TCP/用戶態(tài)TCP/RDMA三棧合一的傳輸層。內(nèi)核態(tài)TCP主打高可用,用于故障切換。用戶態(tài)TCP和RDMA主打高性能,分別用于跨AZ和AZ內(nèi)的數(shù)據(jù)傳輸。傳輸層對上提供統(tǒng)一接口,動態(tài)選擇傳輸協(xié)議,真正做到簡單易用,高可靠,高性能,可大規(guī)模部署。
一云多芯、即插即用。紫金DPU實現(xiàn)了主機CPU環(huán)境與虛擬化環(huán)境的物理隔離,主機不同CPU芯片架構(gòu)的服務(wù)器實現(xiàn)了“即插即用”。紫金架構(gòu)更加開放、靈活、兼容,提升了算力資源使用效率和國產(chǎn)化平臺性能,架構(gòu)適配上做到了又快又穩(wěn)。
天翼云紫金DPU主要為天翼云自身產(chǎn)品提供底層和技術(shù)支撐,通過彈性裸金屬、云主機、容器等產(chǎn)品進行整體售賣。紫金DPU支持彈性裸金屬、云主機、容器等場景,目前已經(jīng)在天翼云部分資源池推廣部署2000+臺服務(wù)器,后續(xù)將在整個云數(shù)據(jù)中心全面推廣部署。
天翼云將堅持DPU核心技術(shù)自主研發(fā),持續(xù)演進,產(chǎn)品路線圖如下:
2022年:DPU1.0。
2023年:DPU2.0,支持25G網(wǎng)絡(luò),支持SF-STACK超融合協(xié)議棧等核心技術(shù)。
2024年:DPU3.0,支持100G網(wǎng)絡(luò),并適配更多的業(yè)務(wù)場景。
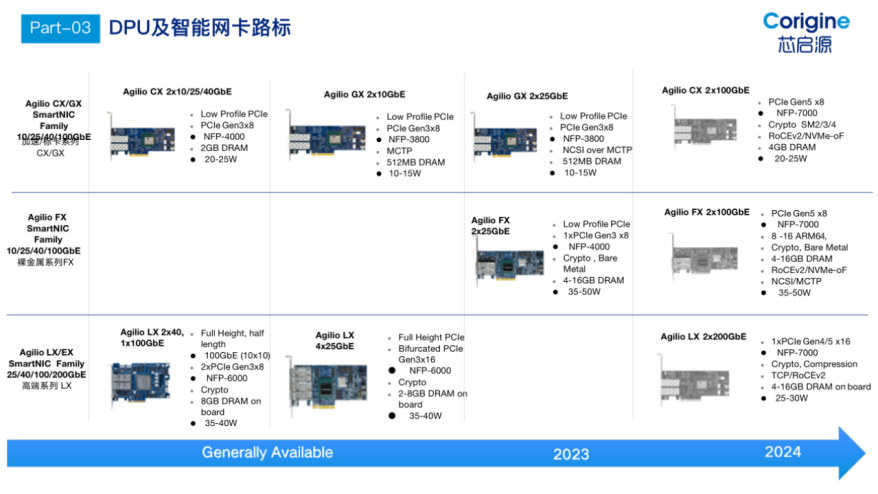
芯啟源:芯啟源DPU系列
芯啟源智能網(wǎng)卡是基于SoC架構(gòu)的成熟DPU解決方案,具備完全的自主知識產(chǎn)權(quán)并已成熟量產(chǎn),可以提供從芯片、板卡、驅(qū)動軟件和全套云網(wǎng)解決方案產(chǎn)品,同時具有可編程、高性能、低功耗、低成本、節(jié)能減排等獨特優(yōu)勢,可以為5G通訊、云數(shù)據(jù)中心、大數(shù)據(jù)、人工智能等應(yīng)用提供極有競爭力的解決方案,滿足當(dāng)前快速迭代的新技術(shù)、新應(yīng)用不斷對基礎(chǔ)設(shè)施提出的新需求。
芯啟源下一代DPU架構(gòu)基于Chiplet技術(shù),極大地提升了自有網(wǎng)卡產(chǎn)品的性能;同時通過支持與第三方芯片的Die-To-Die互聯(lián),還可以集成更多的特定專業(yè)領(lǐng)域芯片。除了在性能和功能豐富度有飛躍式提升外,基于下一代DPU芯片的網(wǎng)卡產(chǎn)品將為客戶提供更多業(yè)務(wù)場景的支持能力。
芯啟源下一代DPU智能網(wǎng)卡是基于DPU芯片的新一代智能網(wǎng)卡,采用NP-SoC模式進行芯片設(shè)計、多線程的處理模式,使其可以達到ASIC固化芯片的數(shù)據(jù)處理能力。在高性能數(shù)據(jù)處理的同時,芯啟源DPU智能網(wǎng)卡還具備靈活高效的可編程能力,支持P4/C語言等高級編程語言的混合編程能力,支持基于XDP的eBPF卸載,幫助客戶實現(xiàn)貼合自身業(yè)務(wù)的定制化功能。兼具了FPGA高效、靈活可編程和專用處理器芯片(ASIC)低成本、低功耗的優(yōu)勢,致力于為客戶提供高性能、低成本、產(chǎn)業(yè)化、生態(tài)化的解決方案。
芯啟源DPU產(chǎn)品路線圖如下:
移動云:磐石DPU
磐石DPU由移動云計算團隊自主設(shè)計和研發(fā),是中國移動強化芯片自主可控、布局算力網(wǎng)絡(luò)的重要載體。基于移動云算力迭代需求,結(jié)合業(yè)界首推的COCA(Compute on Chip Architecture)開放生態(tài),實現(xiàn)“算力+連接”的高性能、高效率、集群化算力架構(gòu)。

磐石DPU
磐石DPU聚焦算力服務(wù),以100%自研安全、穩(wěn)定、可靠、高性能硬件為措施,力圖在算力、連接、效率等關(guān)鍵領(lǐng)域取得核心突破,主要創(chuàng)新點包括:
基于磐石DPU “PCIe Switch+PF/VF”動態(tài)封裝算力服務(wù)接口,實現(xiàn)一套硬件滿足移動云裸金屬、云主機、容器等多種算力載體的業(yè)務(wù)需求,突破性能瓶頸,降低算力損耗的同時提升算力編排效率。
自研彈性裸金屬虛擬化技術(shù)棧,以自主設(shè)計的可編程芯片磐石DPU和全新打造的輕量級Hypervisor為核心,突破傳統(tǒng)技術(shù)架構(gòu)極限,實現(xiàn)真正意義上的I/O虛擬化零損耗。
提出硬件多級流控QoS引擎,實現(xiàn)整機QoS、隊列QoS、流級QoS的雙向三級QoS精細調(diào)度,在高優(yōu)先級業(yè)務(wù)帶寬保證的同時具備更低時延、更小抖動。
自研RNIC算法,將RDMA路徑管控邏輯全面開放,實現(xiàn)網(wǎng)絡(luò)數(shù)據(jù)路徑透明、智能、實時管控,場景化降低RDMA網(wǎng)絡(luò)通信時延,減少連接路徑上的網(wǎng)絡(luò)抖動,以實現(xiàn)大規(guī)模場景下高效率、大容量吞吐和時延低至5微秒的網(wǎng)絡(luò)數(shù)據(jù)傳輸。
存儲卸載引擎通過全方位深度開發(fā)的虛擬化卸載技術(shù)NVMe-oF、RDMA等,結(jié)合用戶態(tài)存儲后端轉(zhuǎn)發(fā)能力,實現(xiàn)云存儲IO全鏈路零拷貝。
當(dāng)前,磐石DPU已應(yīng)用到移動云全系列計算產(chǎn)品中,并支持以容器為接口實現(xiàn)硬件級云原生的能力拓展,滿足HPC、AI等高性能業(yè)務(wù)上云訴求。下一階段,磐石DPU將通過COCA聯(lián)動GPU、RDMA等技術(shù)體系,面向AI/HPC場景構(gòu)建以AI大模型應(yīng)用場景為代表的端到端技術(shù)能力支撐體系,構(gòu)建AI抽象、AI池化、AI加速三大模塊和自主可控的高性能算力連接核心技術(shù),解決國產(chǎn)GPU生態(tài)“碎片化”和算力集群大規(guī)模擴展瓶頸問題。
益思芯科技:Stargate DPU
益思芯科技(上海)有限公司成立于2020年7月,團隊由國內(nèi)外網(wǎng)絡(luò)、交換、存儲領(lǐng)域的核心專業(yè)人員組成,在網(wǎng)絡(luò)、交換、存儲及高性能CPU等領(lǐng)域具有深厚的技術(shù)實力。公司致力于為通信、互聯(lián)網(wǎng)行業(yè)提供領(lǐng)先的存儲與網(wǎng)絡(luò)芯片解決方案。
Stargate DPU智能網(wǎng)卡是一款具有自主知識產(chǎn)權(quán)的P4可編程云原生智能網(wǎng)卡。益思芯科技的P4網(wǎng)絡(luò)加速引擎是針對vSwitch加速而設(shè)計的VLIW ISA P4可編程處理器,不依賴于FPGA的可編程性,支持千萬級流表的同時性能可以做到數(shù)據(jù)包線速轉(zhuǎn)發(fā)。NVMe-oF引擎基于全硬件邏輯實現(xiàn),具有高性能、低延遲等特點,是對高速共享存儲有較高要求的云計算、HPC、數(shù)據(jù)庫等應(yīng)用領(lǐng)域的最佳選擇。
益思芯科技DPU智能網(wǎng)卡技術(shù)與產(chǎn)品創(chuàng)新點如下:
1.P4網(wǎng)絡(luò)可編程:具有自主知識產(chǎn)權(quán)的DSA P4引擎,滿足靈活的定制需求;具有高性能、低延遲、高靈活性、低功耗等特點。
2.NVMe-oF高速共享存儲:NVMe-oF把NVMe協(xié)議在單系統(tǒng)中的高性能、低延遲和低協(xié)議負擔(dān)的優(yōu)勢發(fā)揮到了基于高速網(wǎng)絡(luò)的NVMe共享存儲架構(gòu)中。益思芯NVMe-oF技術(shù)采用全硬件加速的端到端解決方案,是數(shù)據(jù)中心下一代共享存儲的最佳解決方案。
3.豐富的安全特性:支持完善的網(wǎng)絡(luò)安全、存儲數(shù)據(jù)安全處理;支持國密SM2/SM3/SM4加解密算法。
4.云原生軟件開發(fā)平臺:支持使用Host側(cè)的云原生驅(qū)動。與開源DPDK、SPDK庫無縫對接。
益思芯科技后續(xù)產(chǎn)品規(guī)劃如下:
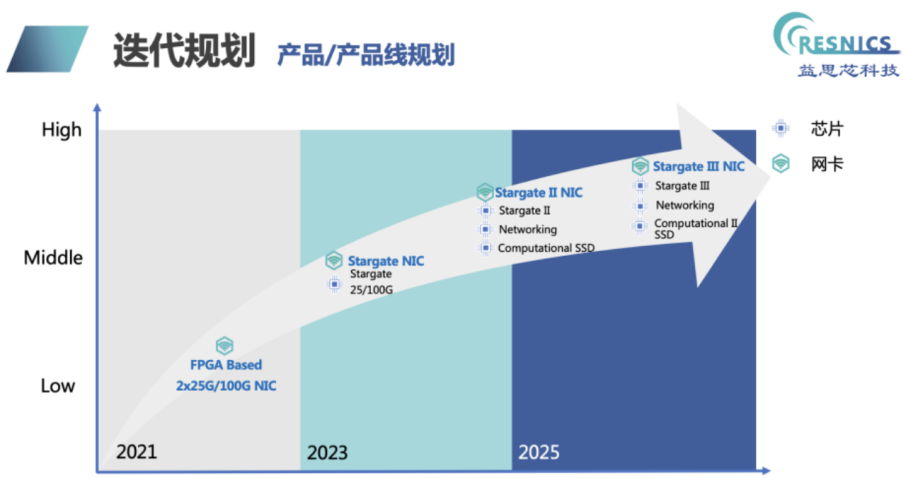
云豹智能:Corsica DPU
云豹智能是一家專注于云計算和數(shù)據(jù)中心DPU和解決方案的領(lǐng)先半導(dǎo)體公司。云豹智能自主設(shè)計研發(fā)的Corsica DPU芯片是云計算數(shù)據(jù)中心高性能軟件定義數(shù)據(jù)處理器芯片,具備豐富的可編程性和完備的DPU功能,支持不同云計算場景和資源統(tǒng)一管理,優(yōu)化數(shù)據(jù)中心計算資源利用率。
云豹Corsica DPU具有性能強大的“CPU+可編程硬件”,不僅能夠保證硬件計算的高能效,還能提供靈活的軟件定義的可編程能力,助力數(shù)據(jù)中心提供租戶自定義高能效云計算基礎(chǔ)設(shè)施服務(wù)。
云豹Corsica DPU具備層級化可編程、低時延網(wǎng)絡(luò)、統(tǒng)一運維管控和適應(yīng)云計算業(yè)務(wù)持續(xù)發(fā)展的加速卸載等特性,主要聚焦解決當(dāng)前數(shù)據(jù)中心應(yīng)用中消耗CPU、GPU算力資源的網(wǎng)絡(luò)、存儲、安全以及應(yīng)用相關(guān)問題,諸如AI、數(shù)據(jù)庫等性能要求敏感的數(shù)據(jù)處理任務(wù)。
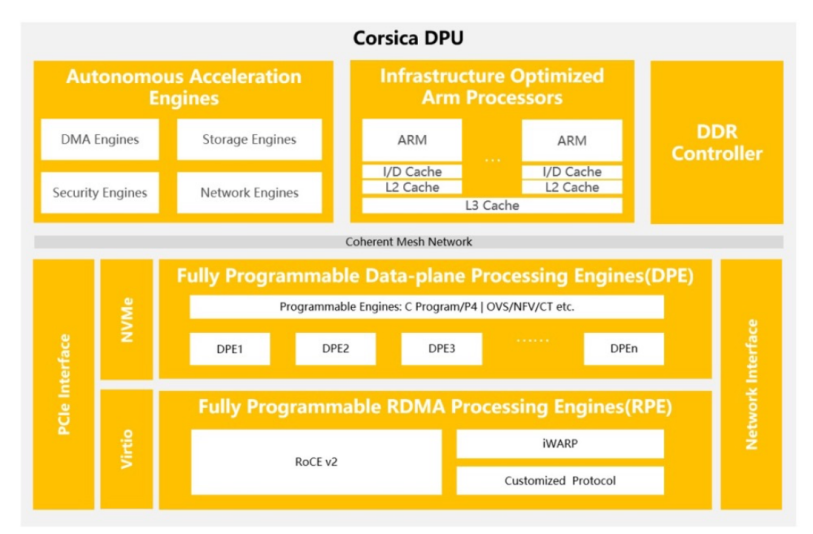
云豹Corsica DPU提供最高2*200G網(wǎng)絡(luò)連接,搭載性能強勁ARMv9架構(gòu)的通用處理單元,滿足數(shù)據(jù)中心云計算基礎(chǔ)設(shè)施層業(yè)務(wù)的卸載需求。云豹智能Corsica DPU還配備眾多自主研發(fā)設(shè)計的可編程硬件加速處理引擎,實現(xiàn)網(wǎng)絡(luò)、存儲和安全的全面加速,具體情況如下:
數(shù)據(jù)面處理引擎提供高性能數(shù)據(jù)處理,具備靈活的軟硬件多層級可編程能力。
RDMA處理引擎支持RoCE和iWARP等主流協(xié)議和可編程擁塞控制算法。
安全處理引擎提供SM2/SM3/SM4等國密和其他主流加密算法。
支持安全啟動、機密計算、加解密的零信任安全解決方案,保護系統(tǒng)、數(shù)據(jù)、應(yīng)用的安全。
支持DDP(Data Direct Path)數(shù)據(jù)直通技術(shù),加速數(shù)據(jù)處理,提高 AI 訓(xùn)練效率。
云脈芯聯(lián):metaFusion和metaConnect系列
云脈芯聯(lián)自2021年成立以來已經(jīng)先后發(fā)布了面向云計算場景的metaFusion系列DPU產(chǎn)品和主打RDMA高性能網(wǎng)絡(luò)的metaConnect系列智能網(wǎng)卡產(chǎn)品,能夠提升用戶計算集群整體的運算效率,釋放更多CPU資源支持上層應(yīng)用,滿足數(shù)據(jù)中心云計算、智能計算、云存儲等核心場景集群高性能互聯(lián)和算力擴展的業(yè)務(wù)訴求。
云脈芯聯(lián)第一款高性能DPU產(chǎn)品metaFusion-50基于自主知識產(chǎn)權(quán)硬核業(yè)務(wù)邏輯研發(fā)設(shè)計,重點針對當(dāng)前云計算數(shù)據(jù)中心發(fā)展的新需求,解決云計算產(chǎn)品形態(tài)支持能力的問題,實現(xiàn)統(tǒng)一計算、網(wǎng)絡(luò)、存儲的管理方式,簡化云計算平臺的管理運維成本,提升新基建的綜合業(yè)務(wù)能力。metaFusion-200高性能DPU為云計算基礎(chǔ)設(shè)施提供了豐富的虛擬化能力、高性能的開放網(wǎng)絡(luò)、靈活的存儲解決方案,同時在RoCEv2網(wǎng)絡(luò)還提供了自主創(chuàng)新的HyperDirect能力和可編程擁塞控制算法平臺,實現(xiàn)高性能網(wǎng)絡(luò)能力。

metaFusion-50(左)和metaFusion-200(右)
云脈芯聯(lián)推出的高性能智能網(wǎng)卡產(chǎn)品metaConnect-200,提供了高性能RDMA網(wǎng)絡(luò)能力,支持自主創(chuàng)新的HyperDirect技術(shù),可以有效加速GPU和AI芯片的計算效率,可編程擁塞控制算法平臺可以幫助用戶根據(jù)不同的業(yè)務(wù)類型設(shè)計和應(yīng)用適合的擁塞控制算法,提升端到端的網(wǎng)絡(luò)性能和可靠性,主要應(yīng)用于AI/ML、HPC和高性能存儲場景。
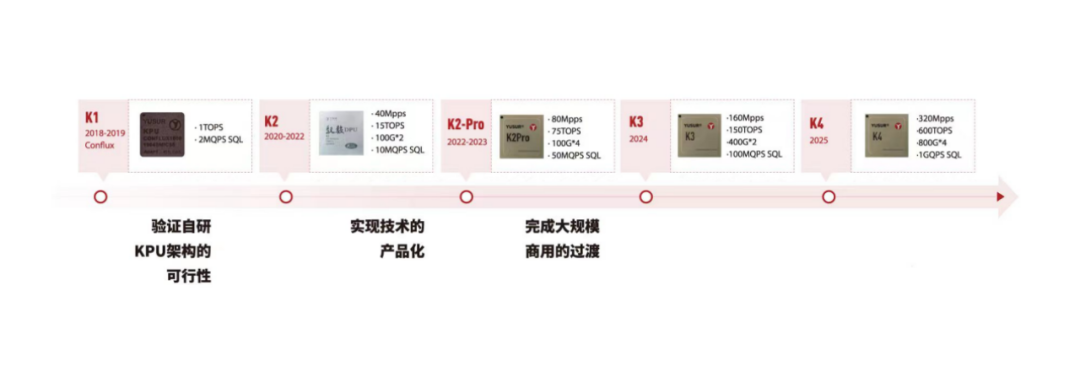
中科馭數(shù):K1、K2、K2-Pro
中科馭數(shù)在網(wǎng)絡(luò)、存儲、計算等領(lǐng)域積累了TOE、RDMA、NVMe-oF、大數(shù)據(jù)處理等功能核,已開展三代DPU系列芯片的研發(fā)迭代工作。其自主研發(fā)的DPU產(chǎn)品可應(yīng)用于超低延遲網(wǎng)絡(luò)、大數(shù)據(jù)處理、5G邊緣計算、高速存儲等場景,助力算力成為數(shù)字時代的新生產(chǎn)力。
中科馭數(shù)自研的第二代DPU芯片K2采用28nm成熟工藝制程,可以支持網(wǎng)絡(luò)、存儲、虛擬化等功能卸載,具有成本低、性能優(yōu)、功耗小等優(yōu)勢。尤其在性能上,其具有極其出色的時延性能,可以達到1.2微秒超低時延,支持最高200G網(wǎng)絡(luò)帶寬。在應(yīng)用場景上可以廣泛適用于金融計算、高性能計算、數(shù)據(jù)中心、云原生、5G邊緣計算等場景。

K1(左)和K2(右)
在核心技術(shù)上,公司提出了創(chuàng)新性的軟件定義加速器技術(shù)(Software Defined Accelerator),自主研發(fā)了面向領(lǐng)域?qū)S糜嬎?DSA)的芯片架構(gòu)KPU(Kernel Processing Unit)和敏捷異構(gòu)軟件棧(HADOS)。基于中科馭數(shù)DPU芯片底層,搭載敏捷異構(gòu)開發(fā)軟件HADOS,公司面向高吞吐、低時延場景,打造了三大體系“思威(SWIFT)系列、功夫(CONFLUX)系列、福來(FLEXFLOW)系列”,性能表現(xiàn)優(yōu)越。
此外,中科馭數(shù)還積極布局DPU產(chǎn)品矩陣,打造軟硬一體化的高吞吐、低時延的產(chǎn)品生態(tài),其中基于DPU研發(fā)的超低時延智能網(wǎng)卡、數(shù)據(jù)計算加速卡、以及面向金融計算領(lǐng)域的解決方案已經(jīng)實現(xiàn)成熟規(guī)模化商用。
中科馭數(shù)DPU發(fā)展路線圖如下:
2023 DPU廠商大盤點(先鋒版)就先到這里啦,目前SDNLAB正在籌備2023 DPU廠商大盤點(終極版),歡迎符合條件的廠商與我們聯(lián)系,一起將生態(tài)做大、做強!
-
處理器
+關(guān)注
關(guān)注
68文章
18929瀏覽量
227273 -
DPU
+關(guān)注
關(guān)注
0文章
343瀏覽量
24044 -
RDMA
+關(guān)注
關(guān)注
0文章
74瀏覽量
8896
原文標題:2023 DPU廠商大盤點(先鋒版)
文章出處:【微信號:SDNLAB,微信公眾號:SDNLAB】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
IaaS+on+DPU(IoD)+下一代高性能算力底座技術(shù)白皮書
國星光電成功斬獲“2023年度科技先鋒獎(科技進步獎)”

英飛凌零碳之路——2023年度盤點(1)

《數(shù)據(jù)處理器:DPU編程入門》DPU計算入門書籍測評
《數(shù)據(jù)處理器:DPU編程入門》讀書筆記
航順芯片一舉斬獲“2023年度MCU創(chuàng)新先鋒獎”

《數(shù)據(jù)處理器:DPU編程入門》+初步熟悉這本書的結(jié)構(gòu)和主要內(nèi)容
什么是DPU?
2023中國汽車產(chǎn)業(yè)ESG先鋒企業(yè)!德賽西威可持續(xù)發(fā)展成果再獲認可

集眾力、匯眾智,2023 中國計算機大會 DPU技術(shù)論壇成功舉辦

【書籍評測活動NO.23】數(shù)據(jù)處理器:DPU編程入門
NVIDIA 發(fā)布首部 DPU 和 DOCA 編程入門書籍

亮風(fēng)臺AR軌道交通數(shù)智化平臺入選國家五部委2023年度虛擬現(xiàn)實先鋒應(yīng)用案例






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論