 基于LRU-K模型如何實現高效的元數據緩存?
基于LRU-K模型如何實現高效的元數據緩存?
對于存儲來說,性能是繞不開的話題。當提到性能,可靠、高效的緩存策略是極其重要的。在計算機領域,緩存技術一般是指,用一個更快的存儲設備存儲一些經常用到的數據,供用戶快速訪問。用戶不需要每次都與慢設備去做交互,因此可以提高訪問效率。凡是位于速度相差較大的兩種硬件之間,用于協調兩者數據傳輸速度差異的結構,均可稱之為緩存。緩存是提升訪問性能的一個重要技術。緩存通過減少系統對數據庫的訪問量來提高系統性能。
存儲層使用緩存的優勢
目前緩存分為兩種模式,一種是文件緩存,一種是內存緩存,文件緩存即緩存數據存放在服務器的硬盤空間中,內存緩存即緩存數據存放在服務器的內存空間中。在分布式文件存儲中,客戶端就能提供文件緩存,那為什么存儲層還需要緩存呢?以下是存儲層使用緩存的優勢因素:
- 客戶端資源有限,無法緩存海量的文件,而后端存儲則可以線性擴展,可以緩存更多的數據。
- 后端存儲可以根據整個存儲情況提供更全面的緩存,比如說多個客戶端同時訪問熱點。
- 分布式文件存儲中,客戶端散布各個終端節點,存儲層的緩存可以保證一致性,更加安全可靠。
- 存儲層可以根據我們數據在物理機上的分布特點,靈活調配緩存大小和策略。
存儲層的緩存能力是提升分布式存儲性能非常重要的部分,今天我們主要討論利用 LRU-K 模型如何實現高效的元數據緩存?
LRU-K 模型的優勢及運作模式
內存中的讀寫速度很快,基于此很多緩存技術都喜歡將數據存在內存中,但是內存空間是有限的,當到達一定量后需要將一些不常用的緩存數據刪除或者落盤。緩存淘汰算法順應而生,其中 LRU、LRU-K 就是比較常見的,目的都是為了高效地維護緩存數據。
LRU 的基本思想是如果數據最近被訪問過,那么將來被訪問的幾率更高。我們實現 LRU 時,要維護一個隊列,第一次訪問的數據直接入隊,重復訪問的緩存,將該數據移至隊尾,需要刪除時刪除隊頭的數據,這樣就能保持隊列越往后,數據再次被訪問的可能性就越大。LRU 緩存變換之快這是它的優點也是它的缺點,因為只需要一次訪問就能成為最新鮮的數據,當出現很多偶發數據時,這些偶發的數據也會被當作最新鮮的,從而成為緩存。但其實這些偶發數據以后并不會被經常訪問到。在文件系統里,這個現象會更加明顯,絕大部分文件/目錄只在業務過程中單次去查詢,而熱點往往集中在少量文件。
LRU-K 的主要目的是為了解決 LRU 算法"緩存污染"的問題,其核心思想是將"最近使用過 1 次"的判斷標準擴展為"最近使用過 K 次"。LRU-K 提供兩個 LRU 隊列,一個是訪問計數隊列,一個是標準的 LRU 隊列,兩個隊列都按照 LRU 規則淘汰數據。當訪問一個數據時,數據先進入訪問計數隊列,當數據訪問次數超過 K 次后,才會進入標準 LRU 隊列。標準的 LRU 算法相當于 LRU-1;LRU-K 具有 LRU 的優點,同時能夠避免 LRU 的缺點,實際應用中 LRU-2 是綜合各種因素后最優的選擇,LRU-3 或者更大的 K 值命中率會高,但適應性差,需要大量的數據訪問才能將歷史訪問記錄清除掉。
目錄的結構是樹形的,這就決定了我們不能平等地去看待每一個目錄,越接近樹頂的目錄,它的訪問概率越高,訪問頻次越高,這些是最值得保存的數據。所以 LRU-K 更適合海量目錄場景下的緩存淘汰。
采用 LRU-K 模型實現目錄的緩存:
- 數據第一次被訪問,加入到訪問歷史列表;
- 如果數據在訪問歷史列表里后沒有達到 K 次訪問,則按照一定規則(LRU)淘汰;
- 當訪問歷史隊列中的數據訪問次數達到 K 次后,將數據索引從歷史隊列刪除,將數據移到緩存隊列中,并緩存此數據,緩存隊列重新按照時間排序;
- 緩存數據隊列中被再次訪問后,重新排序;
- 需要淘汰數據時,淘汰緩存隊列中排在末尾的數據,即:淘汰“倒數第 K 次訪問離現在最久”的數據。

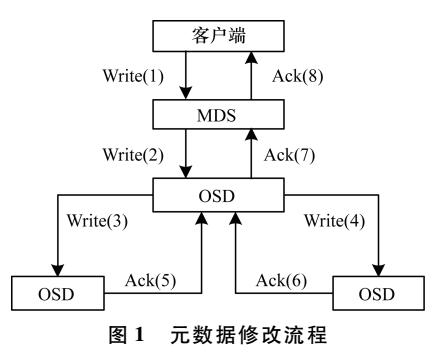
存儲層使用緩存加速元數據性能是一種有效的方法,它可以提高分布式文件存儲的訪問效率和一致性,同時減少對數據庫的壓力。LRU-K 模型是一種適合海量目錄場景下的緩存淘汰算法,它可以避免緩存污染的問題,保證緩存數據的熱度和新鮮度。焱融分布式文件存儲 YRCloudFile 提供元數據服務的組件是 MDS,在海量目錄百億級文件規模場景下實現了高效的存儲層的元數據緩存,能夠提供卓越的性能和可靠性,滿足用戶對文件存儲的各種需求,實測性能成倍提升,為用戶提供了高性能、高可靠、高擴展的存儲服務。
-
存儲器
+關注
關注
38文章
7452瀏覽量
163605 -
緩存器
+關注
關注
0文章
63瀏覽量
11652 -
MDS
+關注
關注
0文章
5瀏覽量
8042
發布評論請先 登錄
相關推薦
LRU緩存模塊最佳實踐
Redis的LRU實現和應用
【原創】Android開發—Lru核心數據結構實現突破緩存框架
高速數據采集系統中高速緩存與海量緩存的實現
基于PC的多通道自帶緩存數據采集系統的設計與實現
基于OpenFlow分組緩存管理模型

適用于命名數據網絡的緩存內容分類模型
設計并實現一個滿足LRU約束的數據結構
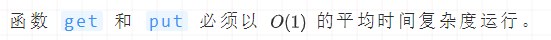
Redis的LRU與LFU算法實現
redis的lru原理
關于LRU(Least Recently Used)的邏輯實現






 工商網監
工商網監
評論