 大模型如何助力AIOps以保證高可靠的服務?
大模型如何助力AIOps以保證高可靠的服務?
十多年來,微軟提供了世界上最流行的超大規模生產力套件之一,Office 365,它現在是Microsoft 365的一部分。微軟365包括數百種不同的服務,在全球數十個數據中心的數十萬臺服務器上每秒運行數十億次事務。它為數以億計的企業、教育和消費者用戶提供日常云服務。
這些服務永遠不會停止。我們的服務被醫院和創傷中心、電網提供商、國家、州和地方政府、主要銀行和金融服務提供商、航空公司、航運和物流提供商以及從最大到最小的企業所使用。為了滿足他們的需求,我們必須持續可用,這意味著在很長一段時間內100%可用。我們的服務應該在災難中無縫運行,因為災難往往是我們的服務最重要的時候;協調應急工作。
這是一個巨大的挑戰。我們的極端規模意味著,在我們的服務中,“十億分之一”的事件并不罕見,而是司空見慣。同時,我們不能允許那些“十億分之一”的事件損害我們服務的可用性。這種幾乎令人難以置信的大規模和極端臨界的組合要求我們不斷地重新思考和改進服務架構、設計、開發和運營的各個方面。實現持續可用性和高可靠性服務的一個重要方面是全面理解事件并減輕它們對客戶的影響。
除了使用人工智能(AI)和機器學習(ML)來開發新的生產特性和功能,以取悅我們的用戶,我們還利用人工智能和機器學習的力量來提高服務的可用性和可靠性,這對我們的超大規模服務至關重要。本文展示了將AI應用于管理生產事件生命周期的一個示例。我們計劃在以后的文章中分享更多示例。
——Jim Kleewein, Microsoft 365技術科學家
1. 介紹
微軟365(“M365”)是世界上最大的生產力云。成千上萬的各種規模的組織都在使用它。無論您是在召開團隊會議,在Outlook中編寫電子郵件還是與同事協作處理Word文檔,您都可以依靠M365來支持這些生產力工具和應用程序。M365由網絡規模和大規模分布式云服務提供支持,由全球幾十個數據中心、每個中心數十萬臺服務器處理艾字節(exabytes)量級的數據。
為了確保一流的生產力體驗,我們的工程基礎設施在高效的同時高度可靠是至關重要的。 在M365系統創新研究小組,我們利用人工智能(AI)的力量,將云智能和AIOps集成到我們的服務和產品中。我們正在使用創新的AI/ML技術和算法來幫助設計、構建和運營復雜的云基礎設施和服務,并在運營效率和可靠性方面提供逐步改進的功能,使我們能夠提供一流的生產力體驗。我們正在將AIOps應用于以下幾個領域:
系統AI使智能成為一種內置能力,在較少人為干預的情況下實現高質量、高效率、自我控制和自適應。
客戶利用AI/ML創造無與倫比的用戶體驗,并通過云服務實現卓越的用戶滿意度。
AI for DevOps將AI/ML注入到整個軟件開發生命周期中,以實現高開發人員生產力。
幫助構建高度可靠的云服務一直是我們關注的重點領域之一。其中一個挑戰是快速識別、分析和緩解事件。我們的研究從生產事件的基礎開始:我們分析事件的生命周期,了解常見的根本原因、緩解措施和解決方案的工程效益。
2. 了解生產事故
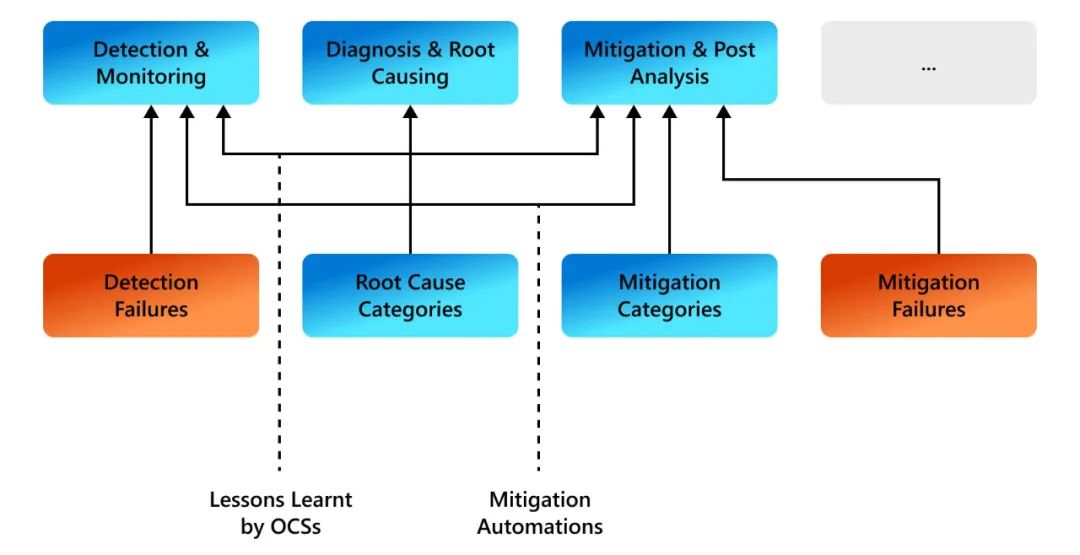
圖1 大規模云服務中服務可靠性問題概述 我們的獲獎論文[1]對Microsoft Teams使用的大規模M365云上的生產事件進行了全面的多維實證研究。由于Microsoft-Teams支持實時通信,因此可靠性至關重要。從檢測、根因和緩解的角度理解生產事件,是構建更好的監控和自動化工具的第一步。圖1顯示了大規模云服務的服務可靠性問題概述,來源于我們研究論文[1]的總結。
1) 事件背后的常見根本原因和緩解措施
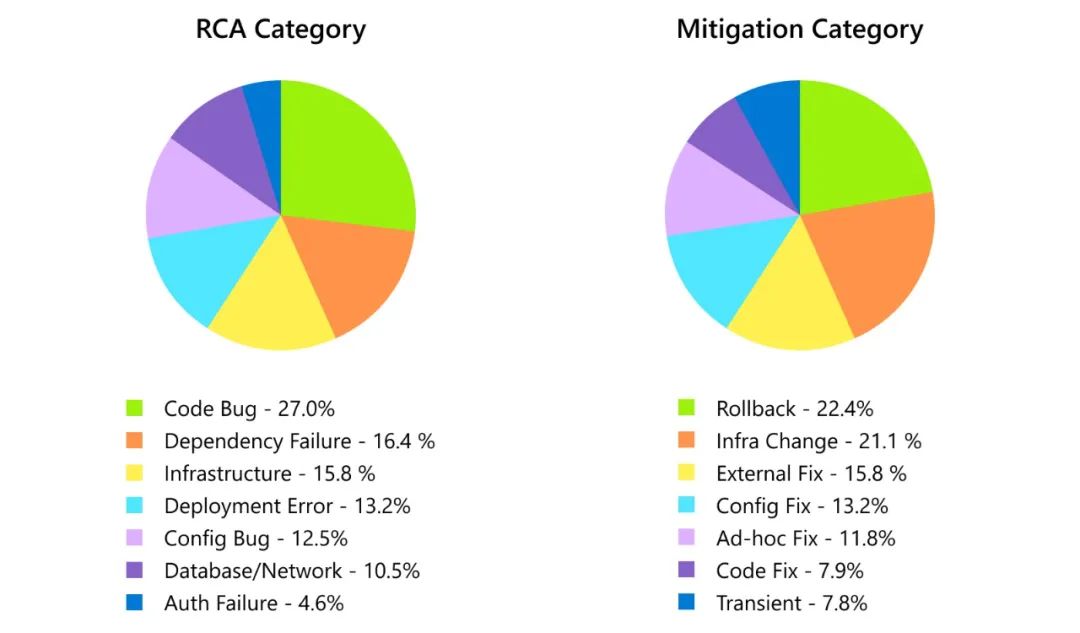
圖2 根本原因分析(RCA)和風險緩解類別的細分 雖然代碼錯誤是最常見的事件原因,但大多數事件(約60%)是由基礎設施、部署和服務依賴關系中的非代碼/非配置相關問題引起的。我們還觀察到,在由代碼/配置錯誤引起的40%的事件中,近80%的事件在沒有代碼或配置修復的情況下得到了緩解。
2)TTD和TTM的根本原因和緩解措施
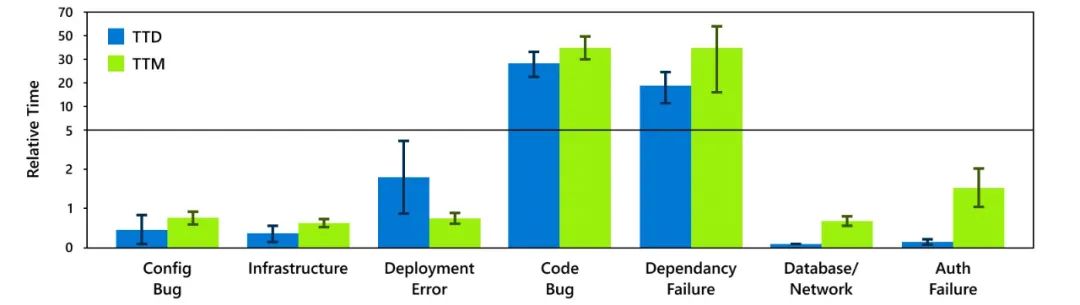
圖3 不同根本原因類別的平均TTD和TTM
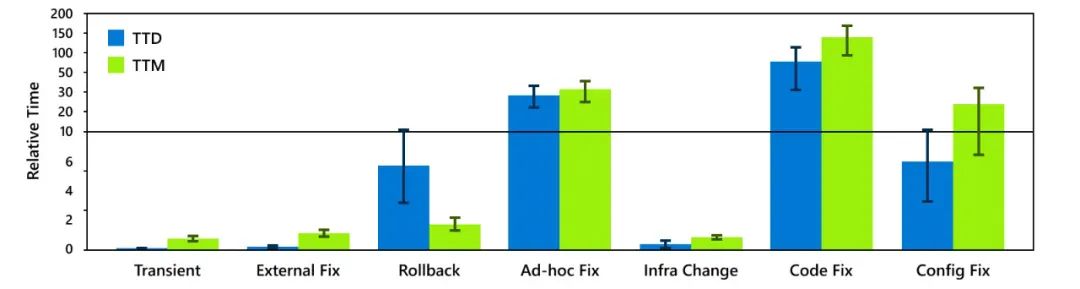
圖4 不同緩解步驟的平均TTD和TTM 由代碼錯誤和依賴失敗引起的事件的TTD和TTM明顯高于其他事件。此外,30%的緩解延遲是由手動緩解步驟造成的。 3)小結
由于監控不力,軟件bug和外部依賴導致的事件檢測時間較長。這凸顯了對實用工具的需求,以實現細粒度、原位系統可觀測性。
某些根本原因類別導致的事件在確定其根本原因類別后會迅速緩解。這表明,使用能夠快速識別其根本原因類別的工具,可以縮短由這些類別引起的事件的總體緩解時間。
由某些根本原因引起的事件本身就難以自動監控(例如,需要監控全局狀態)。這表明開發人員應該在測試中投入更多,以便在生產前發現這些根本原因類別,從而避免此類事件。
我們還設想,自動化將在未來用于進行事件診斷并確定根本原因和緩解步驟,以幫助快速解決事件并最大限度地減少客戶影響。此外,我們應該利用過去的經驗教訓,建立應對未來事件的韌性。我們假設采用AIOps和使用最先進的ML模型,如大型語言模型(LLM)可以幫助實現這兩個目標。
3. 使用LLM進行自動事件管理
最近人工智能的突破使大語言模型(LLM)對自然語言有了豐富的理解。他們已經變得善于從大量數據中理解和推理。它們還可以泛化各種任務和領域,如代碼生成、翻譯、問答等。考慮到事件管理的復雜性,我們有動力評估這些LLM在幫助分析根本原因和減輕生產事件方面的有效性。
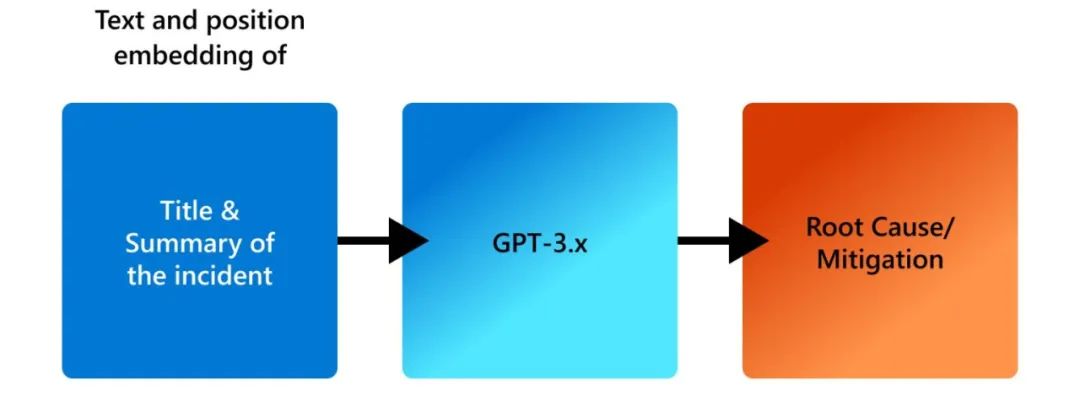
圖5 根因分析和風險緩解中充分利用GPT-3.X的能力 在最近的工作中,我們在ICSE 2023會議上首次展示了LLM對生產事故診斷的有用性。當創建一個事件時,作者將為事件指定一個標題,并描述任何相關細節,如任何錯誤消息、異常行為和其他可能有助于解決的細節。我們使用給定事件的標題和摘要作為LLM的輸入,并生成根本原因和緩解步驟。
我們對4萬多起事件進行了認真的研究,并比較了幾家LLM在零樣本(zero-shot)、微調(fine-tuning)和多任務設置下的表現。我們發現,對GPT-3和GPT-3.5模型進行微調后,可以顯著提高LLM 處理事件數據的有效性。
1)在根因分析中GPT-3.x模型的有效性
表1 不同LLM的詞匯和語義性能
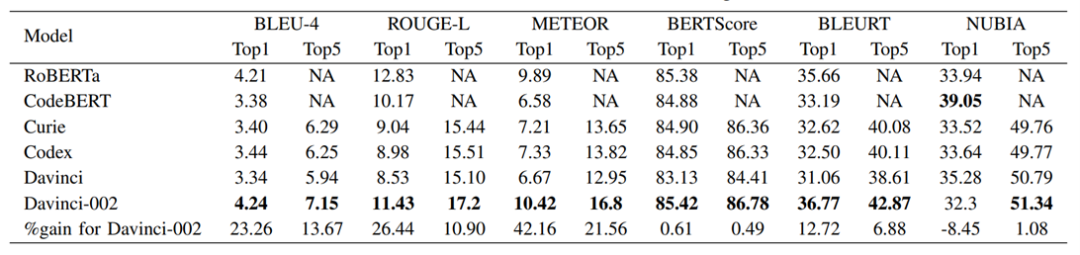
在離線評估中,我們通過計算生成的建議與事件管理(IcM)系統中提到的根本原因或緩解步驟的基本事實之間的3個詞匯相似性進行度量,將GPT-3.5與三個GPT-3模型的性能進行了比較。不同任務的GPT-3.5指標的平均增益如下:
對于根本原因和緩解建議任務,davincici-002 (GPT-3.5)比所有GPT-3模型分別提供至少15.38%和11.9%的增益,如表1所示。
當我們通過將根本原因作為輸入添加到模型中來生成緩解計劃時,GPT-3.5模型比3個GPT-3模型至少高出11.16%。
我們觀察到,由于MRI(Machine Reported Incidents,機器報告的事件)的重復性,LLM模型在MRI上比客戶報告的事件(Customer Reported Incidents,CRIs)上表現更好。
使用事件數據對LLM進行微調可以顯著提高性能。優化后的GPT-3.5模型在根本原因生成任務中提高了45.5%,在風險緩解生成任務中提高了131.3%(即直接在預訓練的GPT-3或GPT-3.5模型上進行推理)。
2)從事件所有者的角度看問題
除了使用語義和詞匯度量進行分析分析外,我們還采訪了事件所有者,以評估生成的建議的有效性。總體而言,GPT-3.5在大多數指標上都優于GPT-3。在實時生產環境中,超過70%的OCEs給出了3分或以上的評分(滿分5分)。
4. 展望
雖然我們正處于使用LLM來幫助自動化事件解決的初始階段,但我們設想在這個領域有許多開放的研究問題,這些問題將大大提高LLM的有效性和準確性。例如,我們如何結合關于事件的其他上下文,如討論條目、日志、服務度量,甚至受影響服務的依賴關系圖,以改進診斷。
另一個挑戰是數據過時(staleness),因為模型需要經常使用最新的事件數據進行重新訓練。
為了解決這些挑戰,我們正在利用最新的ChatGPT模型結合檢索增強方法,通過會話界面改進事件診斷。例如,ChatGPT可以通過提出假設,并通過反饋循環回答關鍵問題,幫助工程師有效地確定事件的根本原因。
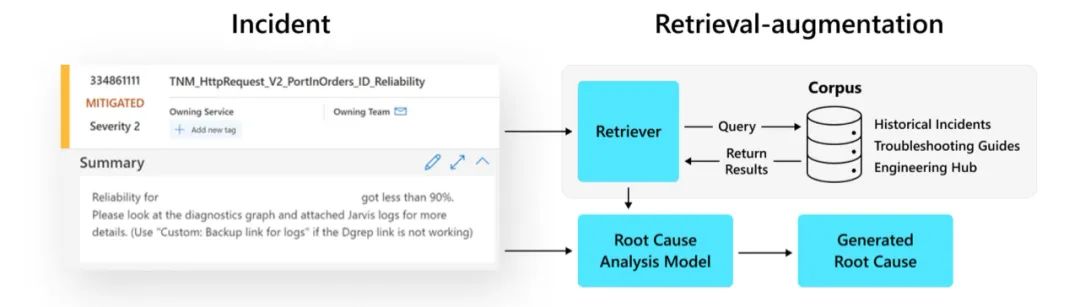
圖6 檢索增強RCA的工作流程
此外,ChatGPT可以積極地融入到事件診斷的“討論”中。通過從可用的文檔和日志中收集證據,該模型可以對查詢生成連貫的、上下文相關的、聽起來自然的響應,并提供相應的建議,從而促進討論,并加速事件解決過程。我們相信,通過上下文和有意義的根本原因分析和風險緩解,這有可能在整個事件管理過程中實現逐步功能改進,從而減少大量人力勞動,提高我們的可靠性和客戶滿意度。
審核編輯:劉清
-
人工智能
+關注
關注
1791文章
46879瀏覽量
237616 -
機器學習
+關注
關注
66文章
8381瀏覽量
132426 -
ChatGPT
+關注
關注
29文章
1548瀏覽量
7505
原文標題:大模型如何助力AIOps以保證高可靠的服務?
文章出處:【微信號:軟件質量報道,微信公眾號:軟件質量報道】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何保證備自投裝置可靠性和穩定性

云知聲山海大模型助力司法領域智慧化升級
NVIDIA助力提供多樣、靈活的模型選擇
軟通動力聯合華為助力永鋒臨港建設鋼鐵行業大模型
matlab預測模型怎么用
從人工到自動化到AIOps再到ChatOps:大模型在運維領域的應用
鴻蒙開發Ability Kit程序框架服務:FA模型訪問Stage模型DataShareExtensionAbility
高可靠繼電器的設計與制造
AI高算力服務器散熱,需要用到哪些導熱界面材料?


光纖布線如何保證數據可靠傳輸
全金屬更“抗造”,DH系列工業級連接器為企業級服務器提供可靠連接

保證負壓密封檢漏儀的精度和可靠性的方法






 工商網監
工商網監
評論