 英偉達提出了同時對未知物體進行6D追蹤和3D重建的方法
英偉達提出了同時對未知物體進行6D追蹤和3D重建的方法
如今,計算機視覺社區已經廣泛展開了對物體姿態的 6D 追蹤和 3D 重建。本文中英偉達提出了同時對未知物體進行 6D 追蹤和 3D 重建的方法。該方法假設物體是剛體,并且需要視頻的第一幀中的 2D 物體掩碼。
除了這兩個要求之外,物體可以在整個視頻中自由移動,甚至經歷嚴重的遮擋。英偉達的方法在目標上與物體級 SLAM 的先前工作類似,但放松了許多常見的假設,從而能夠處理遮擋、反射、缺乏視覺紋理和幾何線索以及突然的物體運動。
英偉達方法的關鍵在于在線姿態圖優化過程,同時進行神經重建過程和一個內存池以促進兩個過程之間的通信。相關論文已被 CVPR 2023 會議接收。

-
論文地址:https://arxiv.org/abs/2303.14158
-
項目主頁:https://bundlesdf.github.io/
-
項目代碼:https://github.com/NVlabs/BundleSDF
本文的貢獻可以總結如下:
-
一種用于新穎未知動態物體的因果 6 自由度姿態跟蹤和 3D 重建的新方法。該方法利用了并發跟蹤和神經重建過程的新穎共同設計,能夠在幾乎實時的在線環境中運行,同時大大減少了跟蹤漂移。
-
引入了混合 SDF 表示來處理動態物體為中心的環境中由于噪聲分割和交互引起的不確定自由空間的挑戰。
-
在三個公共基準測試中進行的實驗顯示了本文方法與主流方法的最先進性能。
英偉達方法的魯棒性在下圖 1 中得到了突出顯示。



與相關工作的對比
此前的 6D 物體姿態估計旨在推斷出目標物體在相機幀中的三維平移和三維旋轉。最先進的方法通常需要實例或類別級別的物體 CAD 模型進行離線訓練或在線模板匹配,這限制了它們在新穎未知物體上的應用。盡管最近有幾項研究工作放寬了假設并旨在快速推廣到新穎未見的物體,但它們仍然需要預先捕獲測試物體的姿態參考視圖,而英偉達的設定中并不假設這一點。
除了單幀姿態估計之外,6D 物體姿態跟蹤利用時間信息在整個視頻中估計每幀物體姿態。與單幀姿態估計方法類似,這些方法在不同的假設條件上進行,例如訓練和測試使用相同的物體,或者在相同類別的物體上進行預訓練。
然而,與所有以往工作不同的是,英偉達的追蹤和重建協同設計采用了一種新穎的神經表示,不僅在實驗證實中實現了更強大的跟蹤能力,還能夠輸出額外的形狀信息。
此外,雖然 SLAM(同時定位與地圖構建)方法解決的是與本研究類似的問題,但其專注于跟蹤相機相對于大型靜態環境的姿態。動態 SLAM 方法通常通過幀 - 模型迭代最近點(ICP)與顏色相結合、概率數據關聯或三維水平集似然最大化來跟蹤動態物體。模型通過將觀察到的 RGBD 數據與新跟蹤的姿態聚合實時重建。
相比之下,英偉達的方法利用一種新穎的神經對象場表示,允許自動融合,同時動態矯正歷史跟蹤的姿態以保持多視角一致性。英偉達專注于物體為中心的場景,包括動態情景,其中常常缺乏紋理或幾何線索,并且交互主體經常引入嚴重遮擋,這些是在傳統 SLAM 中很少發生的困難。與物體級 SLAM 研究中研究的靜態場景相比,動態交互還允許觀察物體的不同面以進行更完整的三維重建。
方法概覽
英偉達方法的概述如下圖所示。給定單目 RGBD 輸入視頻以及僅在第一幀中感興趣物體的分割掩碼,該方法通過后續幀跟蹤物體的 6D 姿態并重建物體的紋理 3D 模型。所有處理都是因果的(無法訪問未來幀的信息)。英偉達假設物體是剛體,但適用于無紋理的物體。
此外不需要物體的實例級 CAD 模型,也不需要物體的類別級先驗知識(例如事先在相同的物體類別上訓練)。
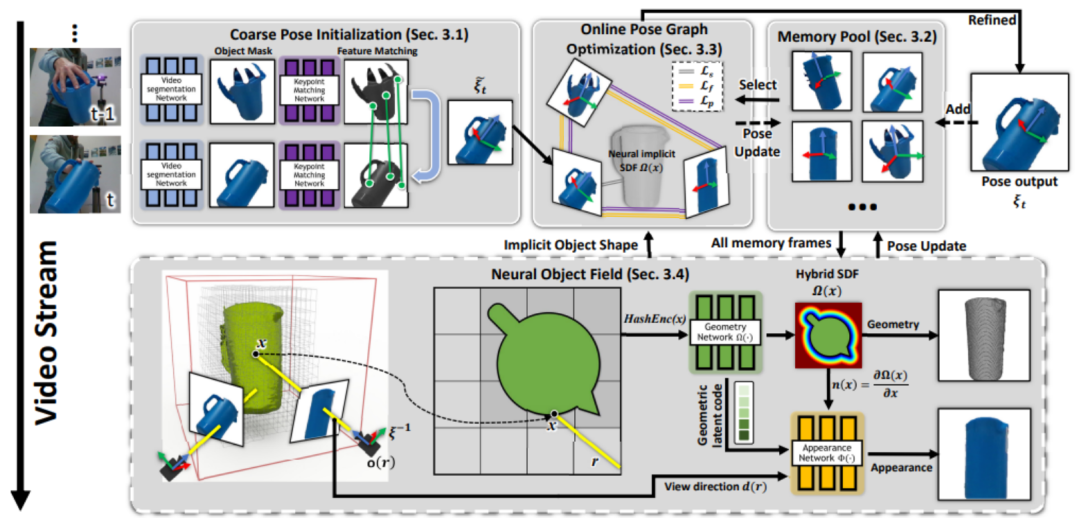
整個框架的流程可以概括為:首先在連續的分割圖像之間匹配特征,以獲得粗略的姿態估計(第 3.1 節)。其中一些具有姿態的幀被存儲在內存池中,以便稍后使用和優化(第 3.2 節)。從內存池的子集動態創建姿態圖(第 3.3 節);在線優化與當前姿態一起優化圖中的所有姿態。
然后,這些更新的姿態被存儲回內存池中。最后,內存池中的所有具有姿態的幀用于學習基于 SDF 表示的神經物體場(在單獨并行的線程中),該對象場建模物體的幾何和視覺紋理(第 3.4 節),同時調整它們先前估計的姿態,以魯棒化 6D 物體姿態跟蹤。
在這項工作中,一個獨特的挑戰在于交互者引入的嚴重遮擋,導致了多視幾何不再一致。并且完美的物體分割掩碼通常無法得到。為此,英偉達進行了獨特的建模以增加魯棒性。
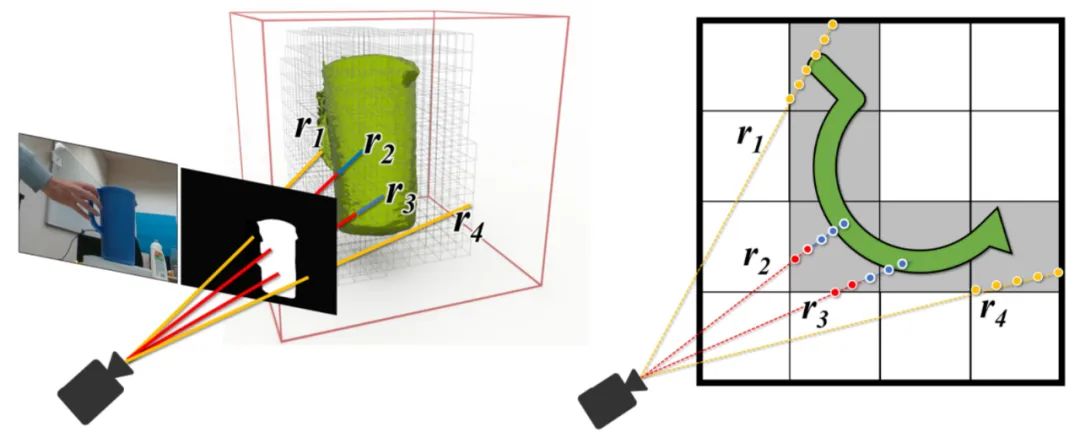
下面左圖:使用視頻分割網絡(第 3.1 節)預測的二值掩碼進行高效的射線追蹤的 Octree 體素表示,該物體分割掩碼由于來自神經網絡的預測難免存在錯誤。射線可以落在掩碼內部(顯示為紅色)或外部(黃色)。右圖:神經體積的 2D 俯視示意圖,以及沿著射線進行的混合 SDF 建模的點采樣。藍色樣本接近表面。
實驗和結果
數據集:英偉達考慮了三個具有截然不同的交互形式和動態場景的真實世界數據集。有關野外應用和靜態場景的結果,請參閱項目頁面。
-
HO3D:該數據集包含了人手與 YCB 物體交互的 RGBD 視頻,由近距離捕捉的 Intel RealSense 相機進行拍攝。
-
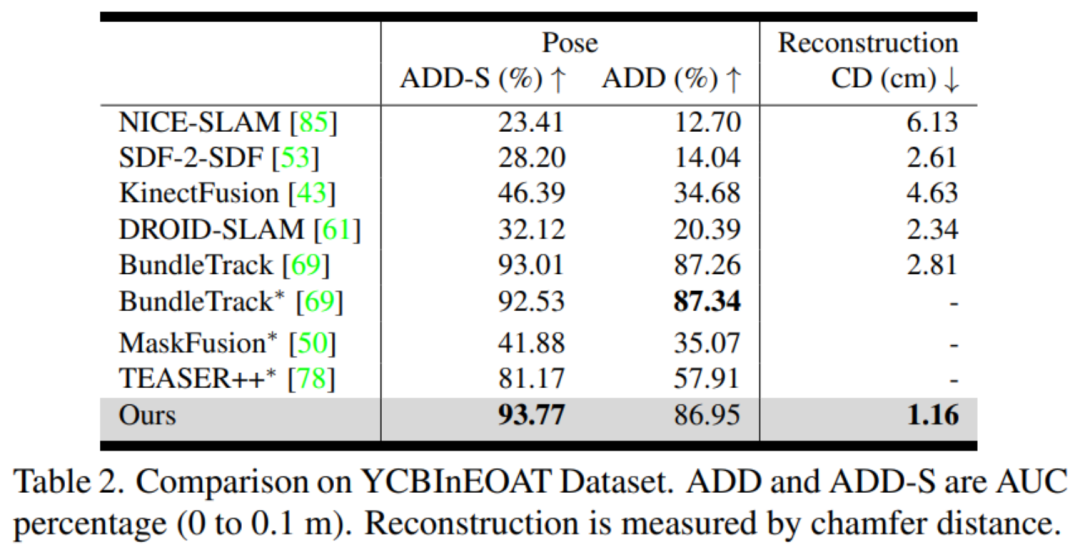
YCBInEOAT:該數據集包含了雙臂機器人操作 YCB 物體的第一視角的 RGBD 視頻,由中距離捕捉的 Azure Kinect 相機進行拍攝。操作類型包括:(1)單臂拾取和放置,(2)手內操作,以及(3)雙臂之間的拾取和交接。
-
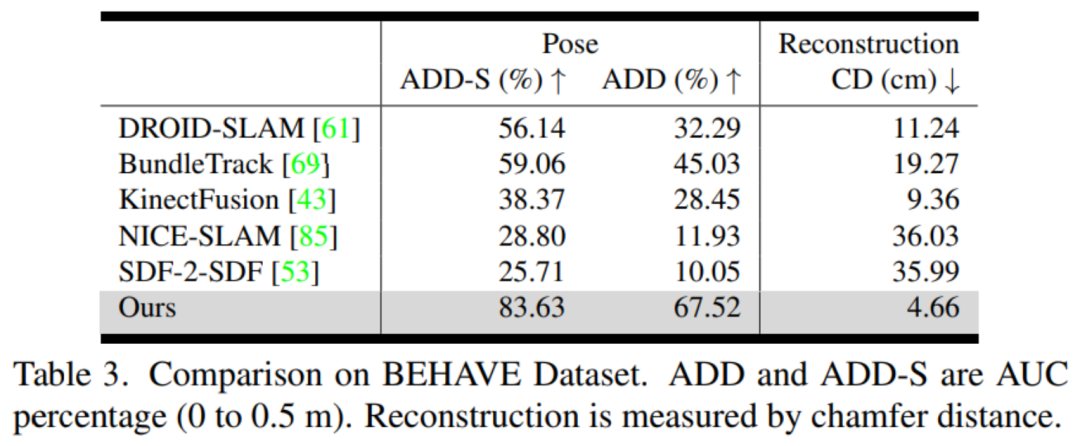
BEHAVE:該數據集包含人體與物體交互的 RGBD 視頻,由 Azure Kinect 相機的預校準多視圖系統遠距離捕捉。然而,我們將評估限制在單視圖設置下,該設置經常發生嚴重遮擋。
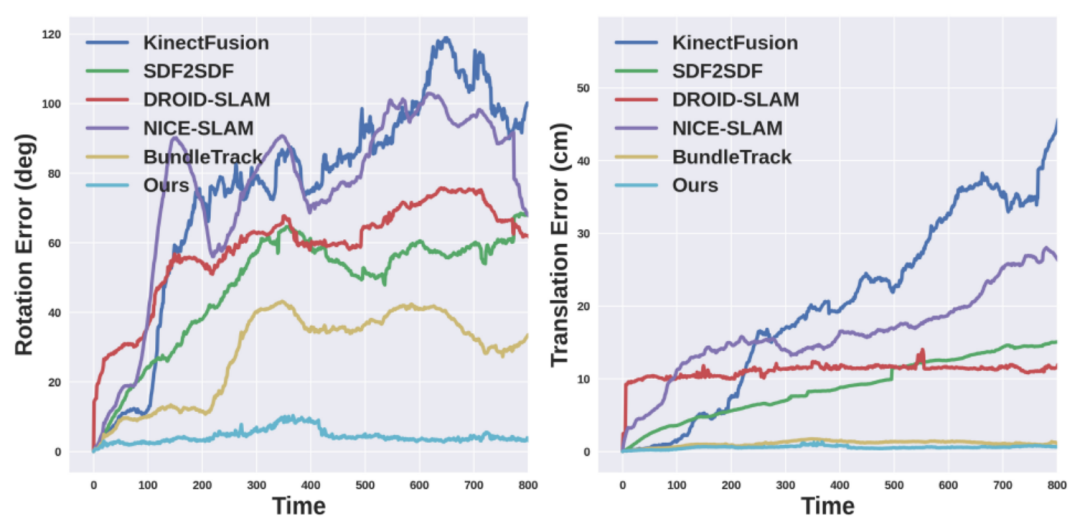
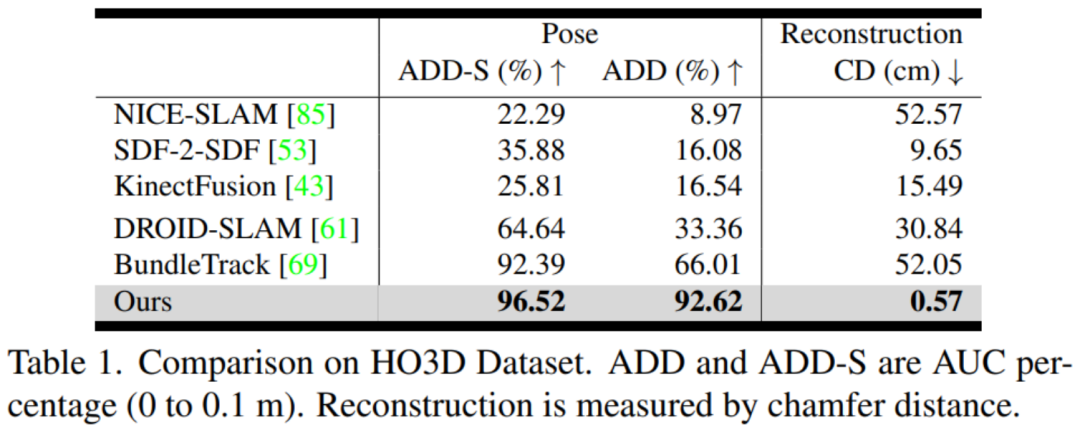
評估指標:英偉達分別評估姿態估計和形狀重建。對于 6D 物體姿態,他們使用物體幾何來計算 ADD 和 ADD-S 指標的曲線下面積(AUC)百分比。對于 3D 形狀重建,英偉達計算最終重建網格與地面真實網格之間在每個視頻的第一幀定義的規范坐標系中的 Chamfer 距離。
對比方法:英偉達使用官方的開源實現和最佳調整參數與 DROID-SLAM (RGBD) [61]、NICE-SLAM [85]、KinectFusion [43]、BundleTrack [69] 和 SDF-2-SDF [53] 進行比較。此外還包括它們在排行榜上的基準結果。

團隊介紹
該論文來自于英偉達研究院。其中論文一作是華人溫伯文,博士畢業于羅格斯大學計算機系。曾在谷歌 X,Facebook Reality Labs, 亞馬遜和商湯實習。研究方向為機器人感知和 3D 視覺。

-
3D
+關注
關注
9文章
2863瀏覽量
107336 -
通信
+關注
關注
18文章
5975瀏覽量
135867 -
英偉達
+關注
關注
22文章
3749瀏覽量
90847
原文標題:對未知物體進行6D追蹤和3D重建,英偉達方法取得新SOTA,入選CVPR 2023
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于空間3D圓擬合圓孔參數測量
3D掃描的結構光
LIS2DE12TR如何在4D/6D模式下運行
PYNQ框架下如何快速完成3D數據重建
使用結構光的3D掃描介紹
3D掃描到底是如何進行的?
視覺處理,2d照片轉3d模型
一種基于深度神經網絡的迭代6D姿態匹配的新方法
英偉達再出新研究成果 可以渲染合成交互式3D環境的AI技術

無需實例或類級別3D模型的對新穎物體的6D姿態追蹤
英偉達新方法入選CVPR 2023:對未知物體的6D姿態追蹤和三維重建

基于3D形狀重建網絡的機器人抓取規劃方法
使用Python從2D圖像進行3D重建過程詳解






 工商網監
工商網監
評論