 高性能服務器網絡模型詳解
高性能服務器網絡模型詳解
作者簡介:謝友鵬,目前在螞蟻金服-支付寶-網絡技術部任職技術專家,先后在華為和支付寶從事網絡和云相關開發。涉及領域vpn、sdwan、全球網絡加速、區塊鏈網絡加速、cdn靜態緩存等。長期研究nginx、apache traffic server、frp等代理項目和基于k8s的云原生項目。不定期更新個人微信公眾號--網絡技術修煉。關注領域:網絡、云、linux高性能服務端。
1999年Dan Kegel在發表的論文中提出了The C10K problem,這篇論文對傳統服務器架構處理大規模并發連接時的挑戰進行了詳細描述,并提出了一些解決方案和優化技術。這里的C指的是Concurrent(并發)的縮寫,C10K問題是指怎么在單臺服務器上并發一萬個請求。如果你分析過性能問題一定會注意到,性能極限通常受到一個或多個資源的限制,比如內存、文件句柄個數、網絡帶寬、CPU等。這里討論的前提是機器的物理資源和系統配置能夠滿足一萬個請求。在這個前提下,網絡并發主要關注兩個方面:一是應用程序和操作系統內核之間如何進行IO事件通知,二是應用程序進程或線程的分配方式。
I/O模型
阻塞vs非阻塞、同步vs異步
你可能經常看到某某項目用的同步非阻塞模型、某某項目用的異步非阻塞模型,所以在正式討論I/O模型前,還是先對齊一下關于阻塞、非阻塞以及同步、異步的概念吧。
阻塞、非阻塞指的是系統調用時“等待數據準備好”這個動作。比如read時候,如果內核判定數據還沒準備好:
內核讓應用進程一直等待,直到數據準備好才通知應用進程就是阻塞;
內核立即通知應用程序說數據沒準備好,你先干別的吧,就是非阻塞。
同步、異步指的是“內核空間與用戶空間復制數據”這個動作。比如read時候,如果內核判定數據還沒準備,過一段時間數據來了:
內核通知應用進程你來讀取數據吧,應用程序再次系統調用將數據讀走就是同步;
內核將數據拷貝到用戶空間后再通知應用進程,數據已經拷貝好了直接用吧,就是異步。
I/O模型詳解
Stevens在《UNIX 網絡編程 卷1》一書的6.2章節介紹了五種 I/O 模型。以下模型以UDP接收報文為例來說明這五種I/O 的工作方式。
阻塞式I/O
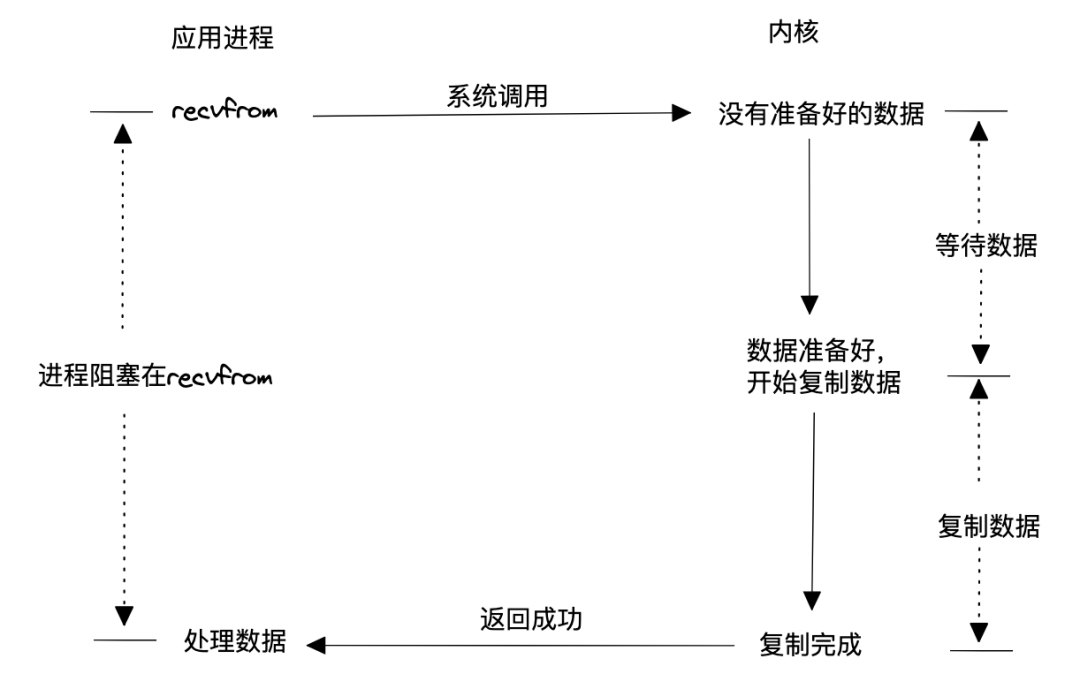
該模型使用最簡,用戶進程調用讀取數據系統后就一直等待,直到內核數據準備好,并將數據從內核空間拷貝到用戶空間后,調用結束。這種模型效率顯然的低下,因為這種模型會導致兩種可能結果:
為每個請求分配一個進程或線程,那么高并發意味著內核要調度的進程或線程數量很龐大,調度、上下文切換等開銷會使系統性能降低。
固定數量的進程或線程處理請求,那么這些進程或線程全被被占用后,新請求就只能等了。
該模型低效的根本原因在于阻塞,內核數據沒有準備好的時候,用戶態進程明明可以干其他活的,現在只能白白等待。
非阻塞式 I/O
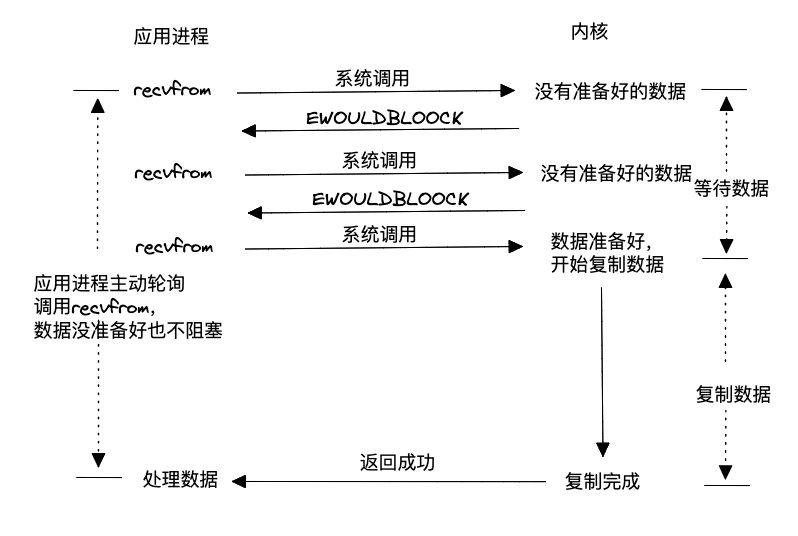
這種模型通過非阻塞的方式與內核打交道,如果內核中數據還未準備好,就立刻返回給用戶進程,用戶進程就可以先干別的事情,過一段再進行讀數據的系統調用,直到內核數據準備好,并將數據拷貝到用戶空間。相比于阻塞的模型,這種非阻塞+主動輪詢的模型避免了用戶進程白白等待內核準備數據的時間,所以效率有所提升,但是因為每次輪詢都是系統調用,所以上下文切換變多了,因此性能也不高。
I/O 復用
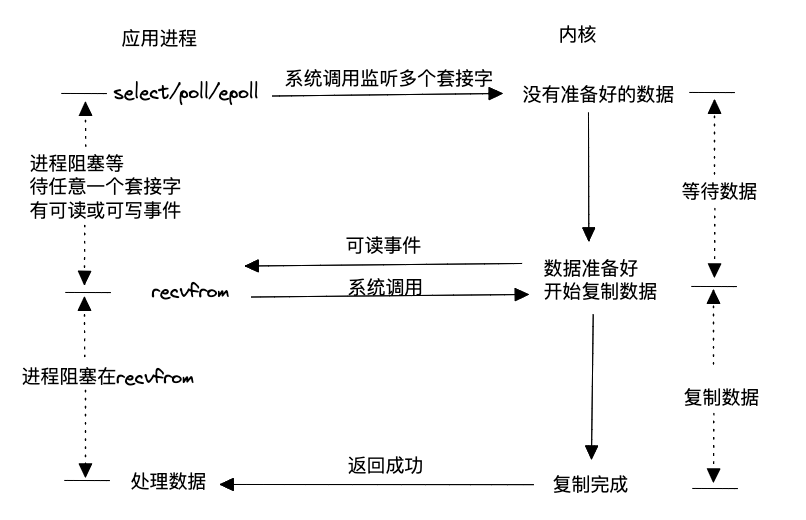
既然不停主動查詢內核數據是否準備好這件事會引起系統性能下降,那能不能通過注冊+通知的方式呢?這就是大名鼎鼎的I/O復用模型。該模型允許用戶態通過一個進程將所有相關的讀寫事件(使用select、poll或epoll)注冊到內核,然后內核會主動通知用戶態進程,一旦任意一個或多個請求的讀寫數據準備好。這種方式在單個進程或線程中同時處理多個I/O通道的就緒狀態被稱為I/O多路復用。使用I/O多路復用既不會阻塞處理請求的進程,也不會因為輪詢內核數據是否準備好而導致過多的系統調用,因此具有高效的特點。然而,需要注意的是,一旦內核通知應用進程數據準備就緒,仍然需要通過系統調用觸發數據的讀取過程。
Linux內核對這種模型的支持非常完善,因此許多高性能服務器在Linux環境中廣泛采用這種模式。
信號驅動式 I/O
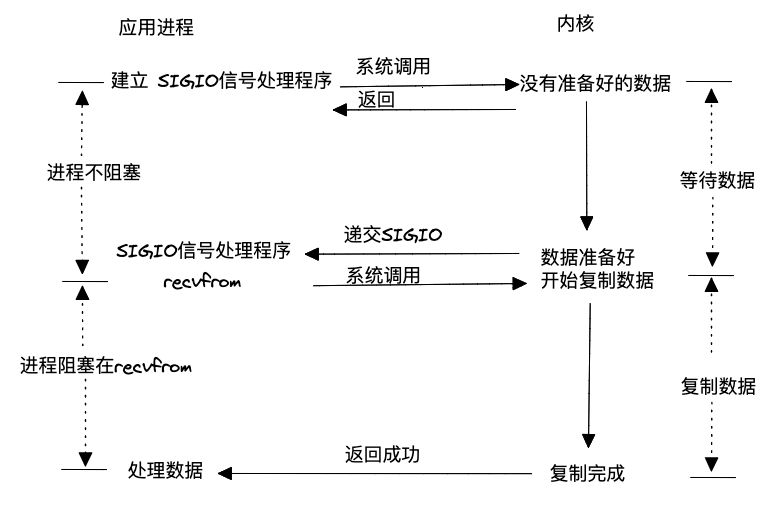
I/O復用模型中是用一個進程(select、poll或epoll)阻塞或輪詢所有請求的數據是否準備好,從而讓所有請求進程的處理都不會阻塞。信號驅動式則沒有這個復用的I/O進程,每個請求進程自己去內核注冊,然后等數據準備好內核通知應用進程去處理。這種模型應用套接字處理的實踐場景為基于UDP的NTP服務,幾乎沒有在TCP上的應用,因為對于TCP來說信號產生過于頻繁,而且并沒有告訴應用程序發生了什么事件,比如下面條件均會導致TCP套接字產生SIGIO信號:
監聽套接字某個連接請求已經完成;
某個斷鏈請求已經發起;
某個斷鏈請求已經完成;
某個半連接已經關閉;
數據到達套接字;
數據已經從套接字發出;
發生某個異步錯誤。
異步 I/O
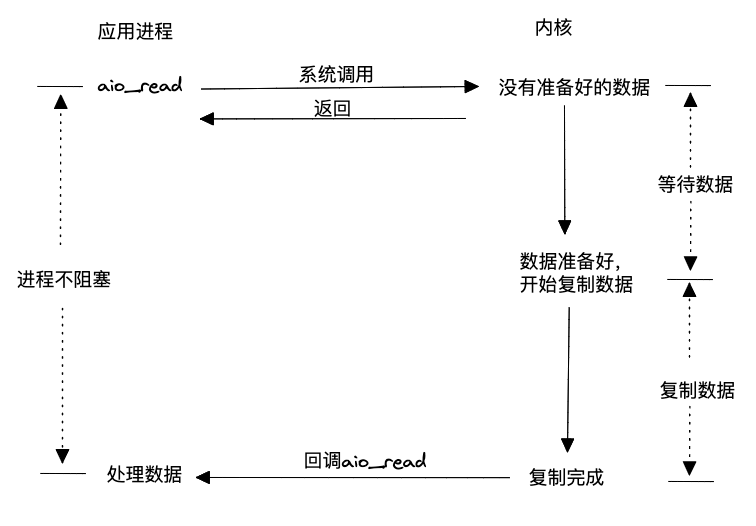
前面幾種方式,無論是阻塞還是非阻塞,從內核空間到用戶空間復制數據的動作都是在內核通知用戶進程后,用戶進程再通過系統調用觸發完成的,因此都屬于同步操作。而異步I/O模型則不同,它允許用戶態進程通過系統調用讀取數據后,即使內核數據未準備好,也會立即返回給用戶進程,告知數據未準備好,讓用戶進程可以執行其他操作。當數據準備好后,內核會將數據從內核空間拷貝到用戶態,并直接回調用戶進程,將數據送到用戶進程手中。這種模型不僅具備非阻塞特性,還能進一步減少系統調用的次數,因此在理論上相對于其他模型更加高效。需要注意的是,這種模型需要操作系統內核的支持。
在《UNIX網絡編程卷1》一書中,截至書稿時,支持POSIX異步I/O的系統相對較少。由于早期Linux內核對網絡異步I/O的支持不夠成熟,在Linux環境下,大多數高性能網絡服務器選擇采用I/O復用的方式,如epoll。然而,從Linux內核5.0版本開始,引入了io_uring異步操作,隨著該技術的成熟,越來越多的高性能網絡服務器(例如nginx)開始支持使用這種異步I/O方式。
如何簡單理解5種I/O?
下面通過一個例子對比一下5種模型,顧客是應用進程,餐飲人員為內核,餐桌為應用進程的數據buffer:
阻塞式I/O:交完錢也要在窗口排隊,等師傅做好,將飯端給你,你再端到自己餐桌。
非阻塞式I/O:交完錢你就可以離開窗口玩一會了,窗口有個屏幕,你過一會跑過來看一下自己的飯好了沒,直到飯做好,自己端到自己的餐桌。
I/O復用:好幾個同學都把飯卡交給你,你一個人跑到窗口排隊刷卡,誰的飯好了,你就打電話給誰,讓他自己將飯端到餐桌。
信號驅動式I/O:你去窗口手機刷卡后就可離開了,飯做好會通過手機通知你,然后自己過去將飯端到餐桌。
異步I/O:去窗口點餐后,告訴服務員你在哪個餐桌就可以離開了,飯做好,服務員會將飯幫你端到餐桌。
進程/線程分配
進程和線程的創建、調度都需要系統開銷。在高并發系統中,為每個請求分配一個進程或線程會對性能產生不利影響。為了克服這個問題,高性能的網絡模型通常采用進程池或線程池來管理進程或線程。進程/線程池的設計目的是降低創建和銷毀進程/線程的頻率,并限制系統中總進程/線程的數量,以減少內核調度的開銷。
常用高性能模式
reactor 模式
《The Design and Implementation of the Reactor》一文詳細介紹了reactor模式的工作方式,簡單來說,reactor模式=I/O復用 + 進程池/線程池。
proactor模式
《Proactor: An Object Behavioral Pattern for Demultiplexing and Dispatching Handlers for Asynchronous Events》一文詳細介紹了proactor模式的工作方式,簡單來說,proactor模式=異步I/O+ 進程池/線程池。
驚群效應
對于TCP請求來說,最理想的情況是每個事件每次從池中喚醒一個進程或線程去執行,這樣既不需要等待又不會引起競爭。用一個進程或線程專門負責處理accept事件,然后將接下來的事件繼續分發給其他worker處理是可行的。有一些模型(比如nginx)存在多個進程或線程監聽同一個端口的情況,如果不加處理會出現一個accept事件喚醒所有worker進程的情況,即驚群效應。為了應對驚群效應,早期nginx引入了accept_mutex的機制,競爭到鎖的worker才會執行accept操作,從而避免所有worker都被喚醒。Linux3.9 版本后提供了reuseport更好的解決了多個進程或線程監聽同一個端口引起的驚群問題,簡單說就是內核幫你輪詢,而不用在應用層面競爭了。
更快、更強大的網絡模型
欲望是永無止境的,有人提出The C10K problem問題,就有人提出The C10M problem,前文中的討論基本都是圍繞用戶態進程和內核的交互優化,既然和內核交互容易導致性能瓶頸,那為何不旁路掉內核協議棧呢?所以有了更快的網絡方案,比如DPDK、XDP、甚至硬件加速等。
審核編輯:湯梓紅
-
Linux
+關注
關注
87文章
11229瀏覽量
208927 -
服務器
+關注
關注
12文章
9021瀏覽量
85184 -
UDP
+關注
關注
0文章
323瀏覽量
33878 -
網絡模型
+關注
關注
0文章
44瀏覽量
8414
原文標題:高性能服務器網絡模型詳解
文章出處:【微信號:SDNLAB,微信公眾號:SDNLAB】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

解鎖高性能計算與區塊鏈應用,阿里云Kubernetes服務召喚神龍
高性能高并發服務器架構分享
基于OPNET實現跨層網絡服務器模型的構型
詳解Nginx高性能的HTTP和反向代理服務器
用高性能服務器優化大型HFSS模型
人工智能服務器高性能計算需求
GPU高性能服務器配置
GPU服務器AI網絡架構設計






 工商網監
工商網監
評論