 Multi-CLS BERT:傳統集成的有效替代方案
Multi-CLS BERT:傳統集成的有效替代方案
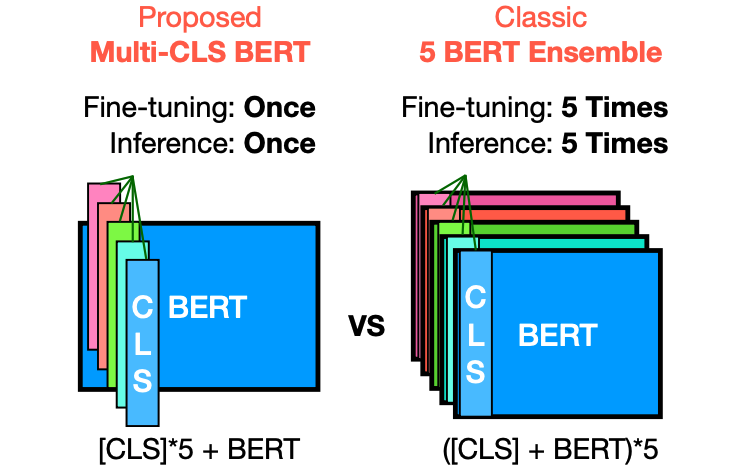
在本文中,介紹了Multi-CLS BERT,這是傳統集成方法的有效替代方案。
這種基于 CLS 的預測任務的新穎方法旨在提高準確性,同時最大限度地減少計算和內存需求。
通過利用具有不同參數化和目標的多個 CLS token,提出的方法無需微調集成中的每個 BERT 模型,從而實現更加簡化和高效的流程。
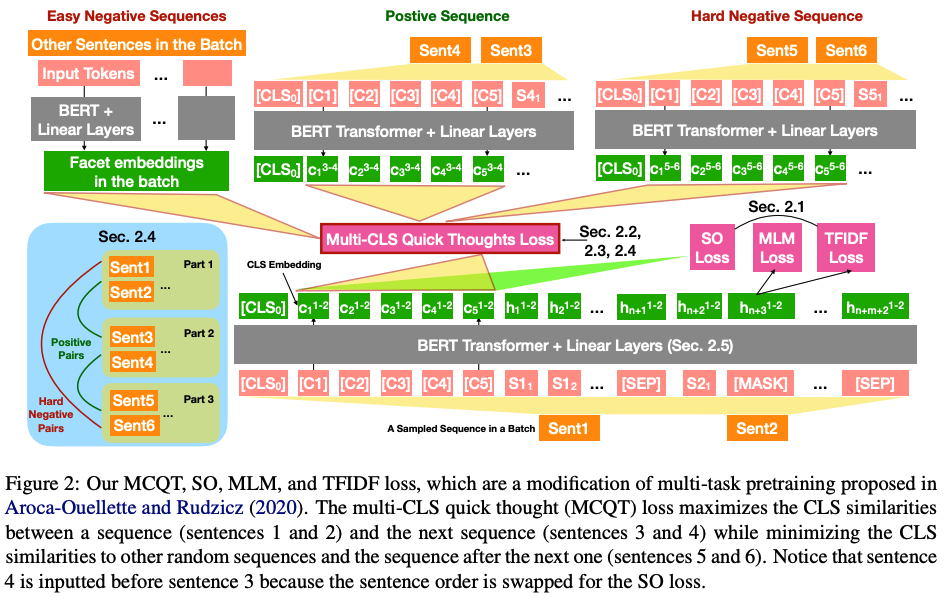
在 GLUE 和 SuperGLUE 數據集上進行了實驗,證明了 Multi-CLS BERT 在提高整體準確性和置信度估計方面的可靠性。它甚至能夠在訓練樣本有限的情況下超越更大的 BERT 模型。最后還提供了 Multi-CLS BERT 的行為和特征的分析。
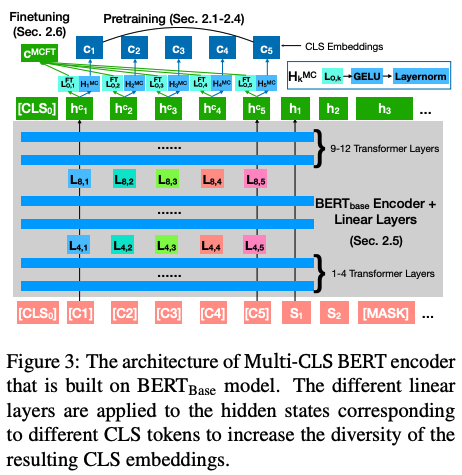
Multi-CLS BERT和傳統集成方法不同點是?
Multi-CLS BERT與傳統的集成方法不同之處在于它使用多個CLS token,并通過參數化和目標函數來鼓勵它們的多樣性。這樣一來,就不需要對集成中的每個BERT模型進行微調,從而使整個過程更加簡化和高效。相比之下,傳統的集成方法需要對集成中的每個模型進行微調,并在測試時同時運行它們。Multi-CLS BERT在行為和特性上與典型的BERT 5-way集成模型非常相似,但計算和內存消耗幾乎減少了4倍。
在所提出的方法中使用多個 CLS tokens有哪些優點?
在所提出的方法中,使用多個CLS token的優點在于可以鼓勵它們的多樣性,從而提高模型的準確性和置信度估計。相比于傳統的單個CLS token,使用多個CLS token可以更好地捕捉輸入文本的不同方面和特征。
此外,Multi-CLS BERT的使用還可以減少計算和內存消耗,因為它不需要對集成中的每個BERT模型進行微調,而是只需要微調單個Multi-CLS BERT模型并在測試時運行它。
GLUE 和 SuperGLUE 數據集上的實驗結果
GLUE和SuperGLUE是兩個廣泛使用的自然語言理解基準測試數據集。
在所提出的方法中,作者使用GLUE和SuperGLUE數據集來評估Multi-CLS BERT的性能。在GLUE數據集上,作者使用100個、1,000個和完整數據集進行了實驗,并在SuperGLUE數據集上使用了相同的設置。
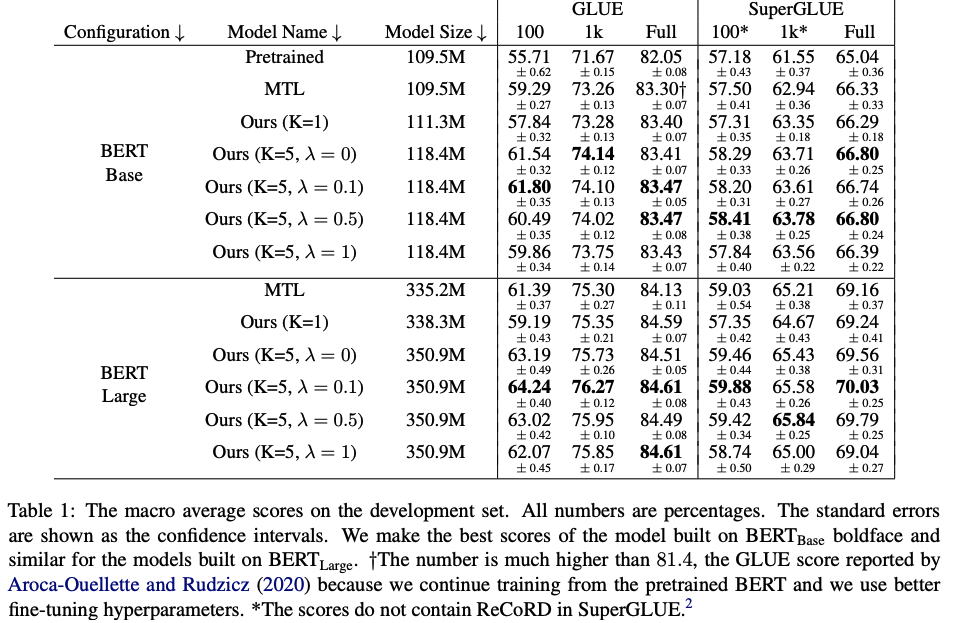
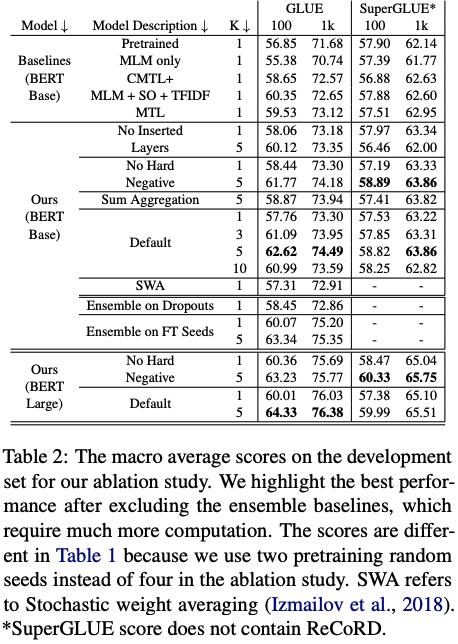
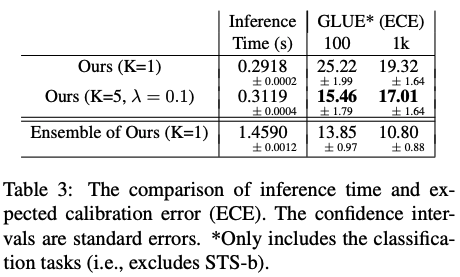
實驗結果表明,Multi-CLS BERT在GLUE和SuperGLUE數據集上都能夠可靠地提高整體準確性和置信度估計。在GLUE數據集中,當只有100個訓練樣本時,Multi-CLS BERT Base模型甚至可以勝過相應的BERT Large模型。在SuperGLUE數據集上,Multi-CLS BERT也取得了很好的表現。
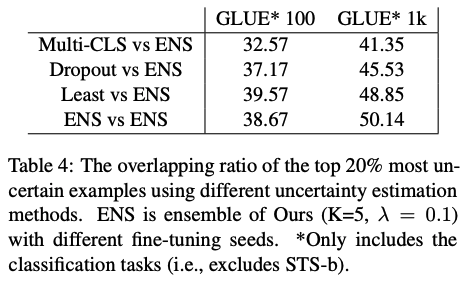
總結
在這項工作中,作者建議使用 K 個 CLS 嵌入來表示輸入文本,而不是在 BERT 中使用單個 CLS 嵌入。與 BERT 相比,Multi-CLS BERT 顯著提高了 GLUE 和 SuperGLUE 分數,并減少了 GLUE 中的預期校準誤差,而其唯一增加的成本是將最大文本長度減少了 K 并增加了一些額外的時間來計算插入的線性變換。因此,建議廣泛使用多個 CLS 嵌入,以獲得幾乎免費的性能增益。
為了解決 CLS 嵌入的崩潰問題,作者修改了預訓練損失、BERT 架構和微調損失。消融研究表明,所有這些修改都有助于 Multi-CLS BERT 性能的提高。在調查改進來源的分析中,發現 a) 集成原始 BERT 比集成 Multi-CLS BERT 帶來更大的改進,b) 不同 CLS 嵌入的不一致與 BERT 模型的不一致高度相關不同的微調種子。這兩項發現都支持作者的觀點,即 Multi-CLS BERT 是一種有效的集成方法。
-
模型
+關注
關注
1文章
3178瀏覽量
48731 -
數據集
+關注
關注
4文章
1205瀏覽量
24649 -
自然語言
+關注
關注
1文章
287瀏覽量
13335
原文標題:ACL2023 | Multi-CLS BERT:傳統集成的有效替代方案
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
WAN架構3個替代方案和挑戰
便于設備編程的12Gbps多通道BERT板設計包括BOM及層圖
如何將代碼集成到Multi IDE Project?
J-BERT N4903A高性能串行BERT手冊
BERT中的嵌入層組成以及實現方式介紹
BERT模型的PyTorch實現
從BERT得到最強句子Embedding的打開方式
自然語言處理BERT中CLS的效果如何?


什么是BERT?為何選擇BERT?
總結FasterTransformer Encoder(BERT)的cuda相關優化技巧





 工商網監
工商網監
評論