 Sonicverse:用于訓練同時能夠看和聽的家居智能體的多感官仿真平臺
Sonicverse:用于訓練同時能夠看和聽的家居智能體的多感官仿真平臺
本文介紹了SONICVERSE,這是一個多感官模擬平臺,用于訓練既能看又能聽的家用代理人。該平臺在實時的3D環境中實現了逼真的連續音頻渲染,并通過新的音頻-視覺虛擬現實界面實現與代理人的交互。此外,針對語義音頻-視覺導航任務,作者提出了一種新的多任務學習模型,并展示了SONICVERSE通過模擬到真實環境的遷移所達到的真實感。
1 前言
本文介紹了SONICVERSE,一個新的具備多感官功能的模擬平臺,用于訓練音頻-視覺具身代理。該平臺實現了實時的3D環境中連續音頻渲染,通過使用完整的場景幾何和材料屬性達到了高保真度的空間音頻渲染。同時,還引入了一個多任務學習框架,用于語義音頻-視覺導航和占據地圖預測,取得了最先進的結果。此外,本文還首次展示了在模擬中訓練的音頻-視覺導航代理可以成功部署到現實環境中。
作者的貢獻有三個方面。
介紹了SONICVERSE,這是一個新的多感官模擬平臺,實時模擬了3D環境中的連續音頻渲染,為許多需要音頻-視覺感知的具身化人工智能和人機交互任務提供了一個新的測試平臺。
介紹了一個多任務學習框架,用于語義音頻-視覺導航和占據地圖預測,取得了最先進的結果。
首次展示了在模擬中訓練的音頻-視覺導航代理可以成功部署到現實環境中。
2 相關工作
本文介紹了具身AI模擬器和視聽學習的相關研究。作者提出了SONICVERSE模擬器,它能夠提供連續的3D空間音頻渲染,并結合完整的場景幾何和表面材料特性實現高度逼真性。作者的工作填補了現有視覺導航研究中缺乏音頻的重要空白,并提供了一個新的測試平臺來支持需要音視知覺的具身AI任務。通過音視導航任務的案例研究,作者展示了我們模擬器的有用性和逼真性。此外,作者的工作還提供了一個新的視覺和聽覺學習的框架,可以應用于各種具身AI任務,包括音視導航、平面圖重建、探索驅動好奇心等。
3 SONICVERSE模擬平臺
本節介紹了SONICVERSE模擬平臺,它是一個具備音視感知功能的具身AI模擬平臺。該平臺構建在iGibson 2.0之上,并使用開源的Resonance Audio SDK實現對音頻的模擬。平臺提供了音頻模擬、3D環境和其他關鍵功能,為研究者開展音視知覺方面的具身AI研究提供了強大的工具和環境。
3.1. 聲學模擬
聲學模擬中的主要組成部分包括直接聲音、動態遮擋、早期反射和晚期混響以及頭部相關傳遞函數(HRTFs)。直接聲音表示從源頭到聽者的未受環境阻礙或反射影響的聲音,并隨著距離的增加而衰減。動態遮擋通過遮擋節點衰減源頭到聽者的聲音,并模擬現實世界的遮擋效果。早期反射和晚期混響是通過預模擬混響烘焙過程計算得到的,早期反射還考慮了聽者與探測器位置的關系,并使用箱形近似房間的方法呈現。頭部相關傳遞函數(HRTFs)用于模擬人類通過感知聲音的時間和級別差異來定位聲源。整個聲學模擬過程可以實現逼真的空間音頻渲染和實時性能。
3.2. 三維環境
SONICVERSE支持Matterport3D和iGibson兩個3D場景數據集,其中Matterport3D包含85個大型的現實世界室內環境場景,而iGibson包含15個具有家具和可動物體的現實世界家庭場景。對于Matterport3D場景,作者使用整個場景進行混響烘焙,并通過將語義網格類別映射到Resonance Audio的材料類型來確定房間表面的聲學特性。對于iGibson場景,由于物體可移動,作者只使用場景的靜態骨架進行混響烘焙,并對墻壁、天花板、窗戶和地板進行相應的映射。
3.3. 主要特點
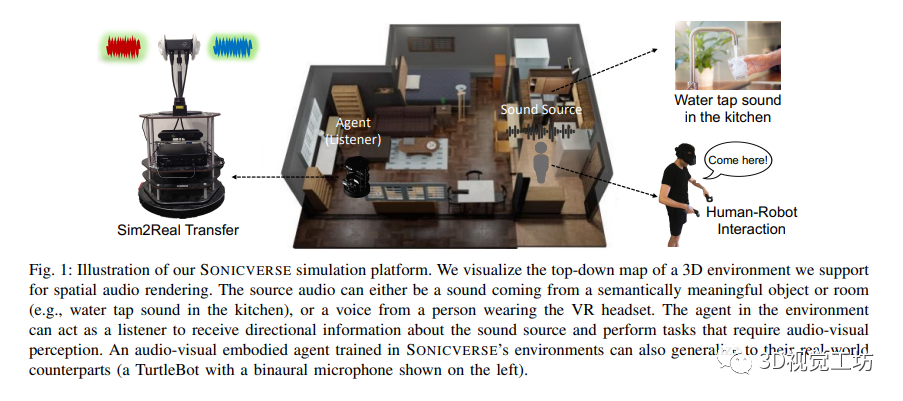
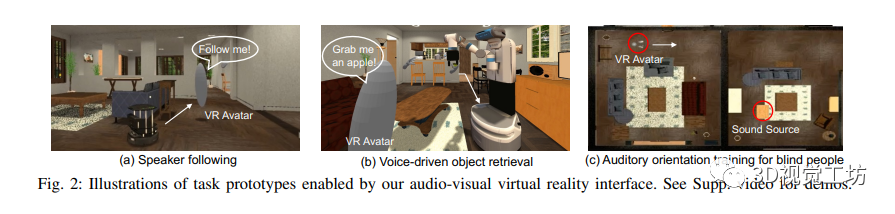
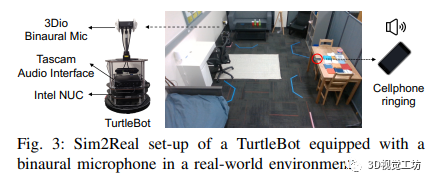
SONICVERSE是一個具備音頻-視覺虛擬現實界面和Sim2Real轉換能力的模擬器。其音頻-視覺虛擬現實界面基于iGibson 2.0和OpenVR,能夠將戴著VR頭顯的人作為音頻-視覺化身,并實現人與代理之間的音頻-視覺交互任務。具體的任務原型包括說話人跟隨、語音驅動的物體檢索和盲人聽覺定位訓練。同時,SONICVERSE使用TurtleBot作為具體化代理,通過3Dio FS雙耳麥克風和Tascam音頻接口實現音頻模擬,并借助Asus XTION PRO RGBD相機和Intel NUC進行視頻捕獲和處理。相比于SoundSpaces和ThreeDWorld,SONICVERSE的模擬器通過將聲音附加到場景中的動態物體實現音頻和視覺模擬的整合,并支持動態遮擋和連續空間的音頻渲染。此外,SONICVERSE利用完整的場景幾何和自動映射的材質進行混音烘焙,實現了更高的逼真度。雖然與ThreeDWorld不同,SONICVERSE不直接模擬物體碰撞聲音,但支持將現有的多感官物體資源與預計算的音頻模擬相結合使用。通過上述優勢和功能,SONICVERSE為音頻-視覺模擬和實際環境的轉換提供了有效的解決方案。
4 在SonicVerse中訓練音視化具象導航智能體
SonicVerse支持許多需要音視感知的具象人工智能任務。作者以具有挑戰性的語義音視導航任務作為案例研究,以展示作者模擬器的實用性。這是音頻目標導航的更具挑戰性的版本,其中智能體必須定位一個持續發出聲音的來源。在語義音視導航中,物體會發出與其現實世界對應物相符的聲音(例如,門會發出咯吱的聲音),而這些聲音只會持續很短的一段時間。因此,智能體必須能夠在聲音停止發出后更好地定位聲源,可能通過利用已學習的關于哪些物體可以發出某些聲音的知識。
任務定義:在這個任務中,智能體需要通過聽到物體發出的聲音,在一個未知且未映射的環境中導航到一個特定的有語義意義的物體。聲音可以是非周期性的、不連續的,并且長度各異。為了到達目標物體,智能體必須推理出聲音物體的語義類別以及音頻感知中的雙耳空間線索。作者在實驗中使用一臺TurtleBot作為智能體。使用的15個有語義意義的聲音,包括水槽、靠墊、電視、淋浴等聲音。每個聲音都與特定的目標類別進行一對一映射。為了被認為是成功,智能體需要在聲音停止后仍能定位到目標位置,并導航到發出聲音的特定目標物體,而不是類別內的其他物體。
行動和觀測空間:與任務的現有規范相反,該規范使用固定步長的離散平移和旋轉,作者使用連續動作空間來表示機器人輪軸速度。這使得任務設定更加現實和具有挑戰性,并且更適用于真實世界的機器人環境。智能體的觀測包括RGB圖像、深度圖、兩只耳朵接收到的雙聲道音頻譜圖、碰撞傳感器輸入以及與起始位置相關的當前姿態。
回合規范與成功準則:每個回合由以下內容定義:場景、智能體的起始位置和方向、目標類別、類別內的一個目標物體以及離目標物體位置一米范圍內的八個位置,這些位置被視為定義物體邊界的附近位置。當智能體到達這九個終止位置之一時,被認為滿足成功準則:八個靠近目標物體的位置和原始目標物體位置。達到終點的距離容差為0.36m,這是真實TurtleBot的寬度。
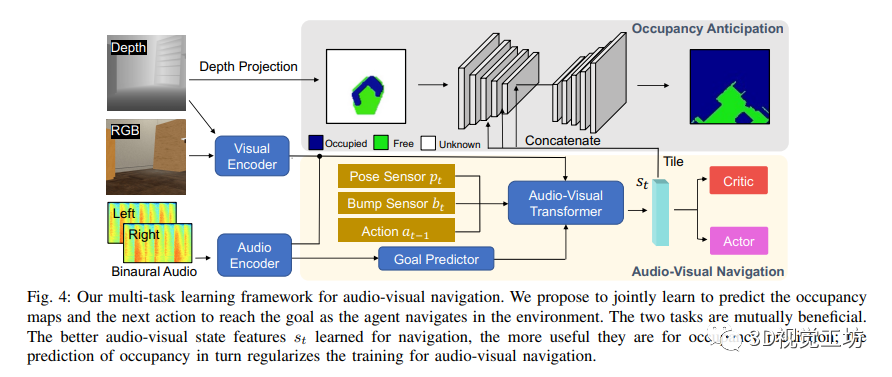
音視導航模型:作者提出了一個多任務學習框架,同時學習語義音視導航和占據地圖預測。在每個時間步t,智能體接收到中心視野的視覺觀測,包括RGB圖像和深度圖,以及代表智能體左右耳朵的雙聲道音頻,表示為雙聲道音頻譜圖。作者分別從視覺編碼器和音頻編碼器中提取視覺和音頻特征。
對于語義音視導航,作者采用了來自SAVi的基本架構,該架構改編自場景記憶變換網絡。它主要由兩個組件組成:1) Goal Predictor,它以音頻特征和智能體當前姿態作為輸入,預測一個包含有關聲源位置和聲音物體的對象類別信息的目標描述符;2) Audio-Visual Transformer,它使用一個記憶模塊對智能體的觀測進行編碼,并使用自注意機制來推理到目前為止看到的3D環境。變換器的解碼器使用目標預測器的輸出和內存中編碼的觀測,預測狀態特征,然后將其饋送給一個用于預測下一步動作的actor-critic網絡。使用中的分布式分散的鄰近策略優化兩階段訓練范式。
對于占據地圖預測,作者將其規定為逐像素分類任務。將自中心自我位置圖p ∈ V ×V表示為垂直俯視的地圖,該地圖由相機前方V×V個單元格的局部區域組成,該區域表示一個5m × 5m的區域。每個單元格中的值表示該單元格被占用的概率。通過使用對應室內環境的3D網格獲得地面實際局部占用。使用U-Net進行占據地圖預測。編碼器的輸入是從深度投影中獲得的局部占用地圖,通過在深度和相機內參的點云上設置高度閾值來獲得。然后,復制和平鋪狀態特征向量以匹配特征圖的空間維度,并在后3層編碼器的通道維度上進行連接。解碼器然后將融合的特征圖作為輸入,并通過一系列上卷積層輸出預測的局部占用地圖,包括可見和不可見的單元格。作者使用二元交叉熵損失訓練占據預測網絡。
作者的占據地圖預測模塊與機器人技術和具體視覺導航中建立世界的連續表示的前期方法相似。然而,作者聯合學習占據預測和音視導航,有新的見解表明準確預測占據地圖有助于學習更好的音視特征,從而有助于導航。
5 實驗
該研究展示了在音頻視覺導航領域的實驗結果,并將在SONICVERSE模擬器中訓練的代理轉移到真實世界中。通過與多個基準方法進行比較,作者證明了他們的模型在語義音頻視覺導航中的出色性能。作者還使用不同的評估指標對模型進行了評估,并比較了不同數據集上的性能。結果顯示,作者的多任務學習框架在所有指標上均優于現有的方法。此外,通過在俯視地圖上顯示導航軌跡,并與基準方法進行對比,作者進一步證明了他們的模型在感知障礙物和聲音、并高效導航到目標物體方面的能力。同時,該研究還展示了他們的模擬器的逼真性,通過將在模擬中訓練的導航代理成功轉移到真實世界環境中。三個關鍵步驟(記錄機器人噪音、隨機變化源聲音的增益、校準深度相機)被證明可以減少虛實差距,從而實現成功的策略轉移。總體而言,該研究為音頻視覺導航領域的研究提供了有價值的見解,并提供了促進虛實轉換的有效方法。
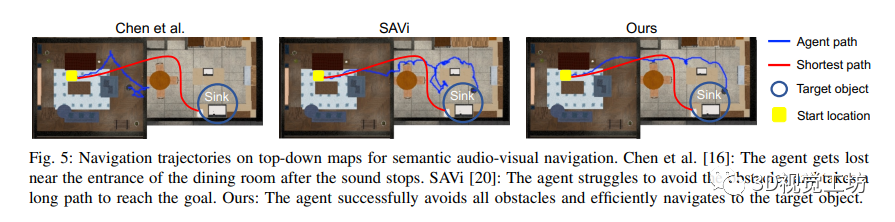
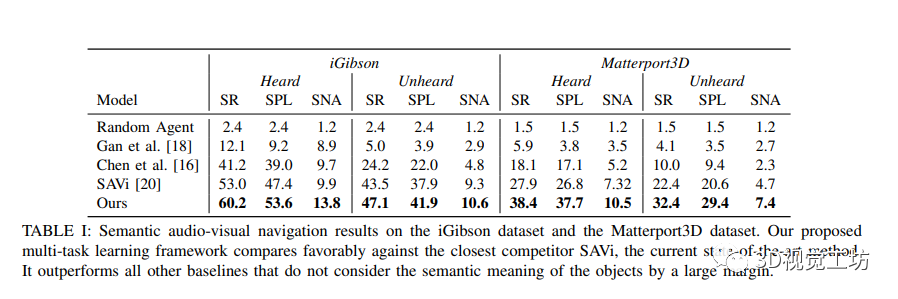
5 總結
本研究介紹了SONICVERSE,一個用于訓練同時能夠看和聽的家居智能體的多感官仿真平臺。該平臺能夠實時渲染3D環境中的連續音頻,并支持虛擬現實中的音頻流傳輸,為需要音頻視覺感知的體驗式人工智能任務提供了新的測試平臺。在音頻視覺導航任務上,研究者提出了一種新的語義音頻視覺導航模型,其性能優于以前的方法。此外,他們還成功地將在模擬中訓練的智能體應用到真實世界環境中。研究者對SONICVERSE帶來的體驗式多感官學習研究表示期待。
-
3D
+關注
關注
9文章
2864瀏覽量
107340 -
音頻
+關注
關注
29文章
2839瀏覽量
81373 -
仿真平臺
+關注
關注
0文章
25瀏覽量
9915
原文標題:ICRA2023 | Sonicverse:一個多感官模擬平臺,讓AI具體任務成為可能
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Veloce Apps硬件仿真平臺
電磁環境仿真平臺VREM EmXpert介紹
在LabVIEW圖形化編程環境下的智能車仿真平臺
基于STM32-XPC仿真平臺的構架 精選資料推薦

自動駕駛仿真平臺概述

多尺度材料設計與仿真平臺Device Studio介紹

Adams—系統級多體動力學仿真平臺

仿真平臺Device Studio應用實例





 工商網監
工商網監
評論