 聯合學習在傳統機器學習方法中的應用
聯合學習在傳統機器學習方法中的應用
在大數據和分布式計算時代,傳統的機器學習方法面臨著一個重大挑戰:當數據分散在多個設備或豎井中時,如何協同訓練模型。這就是聯合學習發揮作用的地方,它提供了一個很有前途的解決方案,將模型訓練與直接訪問原始訓練數據脫鉤。
聯合學習最初旨在實現去中心化數據上的協作深度學習,其關鍵優勢之一是其通信效率。這種相同的范式可以應用于傳統的 ML 方法,如線性回歸、 SVM 、 k-means 聚類,以及基于樹的方法,如隨機森林和 boosting 。
開發傳統 ML 方法的聯合學習變體需要在幾個層面上進行仔細考慮:
算法級別:您必須回答關鍵問題,例如客戶端應該與服務器共享哪些信息,服務器應該如何聚合收集的信息,以及客戶端應該如何處理從服務器接收的全局聚合模型更新。
實施級別:探索可用的 API 并利用它們來創建與算法公式一致的聯邦管道是至關重要的。
值得注意的是聯邦的和分布式的與深度學習相比,傳統方法的機器學習可能不那么獨特。對于某些算法和實現,這些術語可以是等效的。
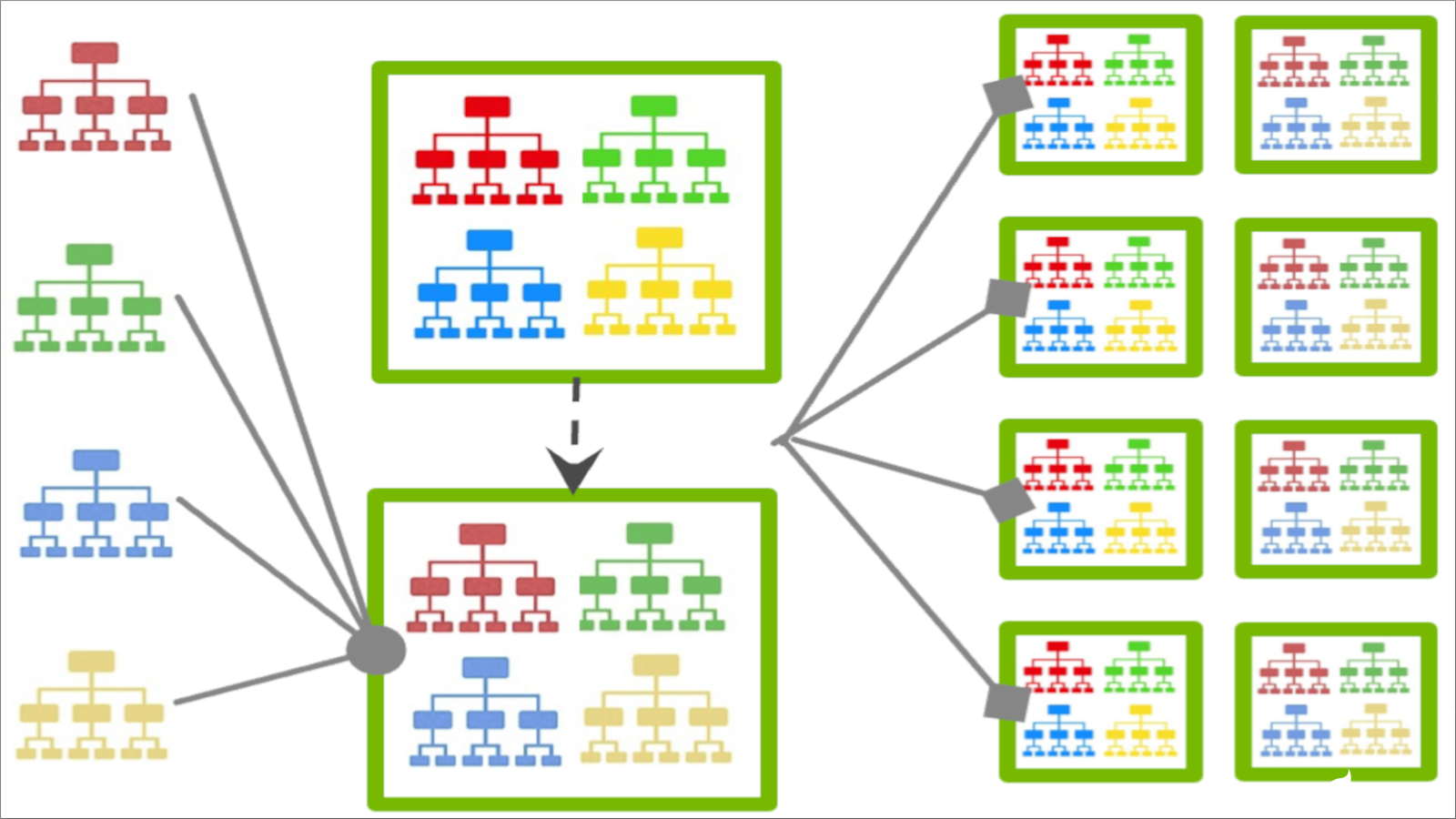
圖 1 。對基于聯邦樹的 XGBoost
在圖 1 中,每個客戶端構建一個唯一的增強樹,該樹由服務器聚合為樹的集合,然后重新分發給客戶端進行進一步的訓練。
要開始使用顯示此方法的特定示例,請考慮K-Means聚類示例。在這里,我們采用了Mini-Batch K-Means聚類中定義的方案,并將每一輪聯合學習公式化如下:
本地培訓:從全局中心開始,每個客戶端都用自己的數據訓練一個本地的 MiniBatchKMeans 模型。
全局聚合:服務器收集集群中心,統計來自所有客戶端的信息,通過將每個客戶端的結果視為小批量來聚合這些信息,并更新全局中心和每個中心的計數。
對于中心初始化,在第一輪中,每個客戶端使用 k-means ++方法生成其初始中心。然后,服務器收集所有初始中心,并執行一輪 k 均值以生成初始全局中心。
從制定到實施
將聯邦范式應用于傳統的機器學習方法雖然說起來容易,但做起來卻很困難。NVIDIA 新發布的白皮書 《聯合傳統機器學習算法》 提供了許多詳細的示例,以展示如何制定和實現這些算法。
我們展示了如何使用流行的庫,如scikit-learn和XGBoost,將聯邦線性模型、k-means聚類、非線性SVM、隨機森林和XGBoost應用于協作學習。
總之,聯合機器學習為在去中心化數據上協同訓練模型提供了一種令人信服的方法。雖然通信成本可能不再是傳統機器學習算法的主要約束,但要充分利用聯合學習的好處,仍然需要仔細制定和實施。
-
NVIDIA
+關注
關注
14文章
4936瀏覽量
102812 -
人工智能
+關注
關注
1791文章
46853瀏覽量
237544
發布評論請先 登錄
相關推薦
深度解析機器學習三類學習方法
如何學好機器學習?機器學習的學習方法4個關鍵點整理概述
機器學習入門寶典《統計學習方法》的介紹

隨著人工智能的落地 自動化機器學習方法AutoML應運而生
機器學習方法遷移學習的發展和研究資料說明

運用多種機器學習方法比較短文本分類處理過程與結果差別
水聲被動定位中的機器學習方法研究進展綜述






 工商網監
工商網監
評論