 用RAPIDS生成用于加速短期價格預測的限價訂單簿數據集
用RAPIDS生成用于加速短期價格預測的限價訂單簿數據集
做市商是賣方的主要參與者,為市場提供流動性。投機者站在買方一邊,進行實驗和研究,希望從中獲利。最終用戶是向零售經紀人咨詢建議和交易的散戶投資者。總體而言,金融公司有興趣評估金融機器學習( ML )算法,以發現哪些算法最有利可圖。
研究人員最近發表了許多版本的這種類型的算法。我們試圖利用高頻數據和隨機森林( RF )模型的可解釋性,并選擇了本文中提出的 RF 方法研究短期價格預測的限價訂單簿特征:一種機器學習方法.
我們的研究發現,使用 GPU 的硬件加速減少了金融 ML 研究人員獲得預測結果所需的時間。由于大部分運行時間都可以用于分類器訓練,因此人們當然對更有效的訓練方法感興趣。
本文介紹了我們的研究,包括生成的數據集,使用限價訂單簿( LOB )數據進行價格預測,以及 ML 訓練的推薦步驟。我們解釋了所研究的 GPU 配置如何顯著加快 ML 訓練時間,從而實現更高效和更廣泛的模型開發
數據集
本研究使用顯示實時股價的時間序列數據集來更好地理解 LOB 結構和方向預測。市場數據公司提供Intrinio,本研究的數據集包含紐約證券交易所和納斯達克股票代碼的實際市場價格樣本,以 1 秒為基礎,來自道瓊斯 30 指數股票。
1 秒的報價被用作 ABIDES (基于代理的交互式離散事件模擬)的輸入,以生成看起來像市場 LOB 的 LOB 數據。每條記錄上的時間戳都在第二個標記處;例如: 2019 年 1 月 2 日的 2019-01-02T14 : 09 : 18Z ,即 2019 年的第一個交易日
輸入到 ABIDES 的 CSV 文件由這一列作為第一列,后面是 30 列 DOW 30 的美元價格(到兩位數)。本文將 AAPL 股票行情作為一個測試案例。
使用 ABIDES 生成合成數據
ABIDES 是一種模擬金融市場運作的方法。在最近的論文中進行了解釋,ABIDES: Towards High-Fidelity Multi-Agent Market Simulation,由佐治亞理工學院、佐治亞大學和摩根大通銀行的研究人員撰寫
ABIDES 模擬了許多通過交易所代理買賣資產的個人交易代理。模擬中的每一筆交易和其他事件都會被記錄下來,并與執行交易的代理人聯系在一起。這使市場研究人員能夠詳細分析不同的代理人策略和事件如何影響模擬市場。重要的是,給定交換的 LOB 可以在模擬之后重建
ABIDES 模擬中的一些代理基于時間序列來評估資產,該時間序列表示代理在某個頻率下觀察到的資產的真實價值,并添加一些噪聲。這個時間序列被稱為基本價值股票的價格。為了在宏觀尺度上模擬一個更現實的市場,我們使用真實的歷史數據作為基本值。
為了創建合理的 LOB 數據來訓練我們的 RF 模型,我們使用 Intrinio 提供的 1 秒報價作為 ABIDES 模擬的歷史基本值。圖 1 將輸出 LOB 數據的中間價與用作 AAPL 歷史基本面的 1 秒報價進行了比較。
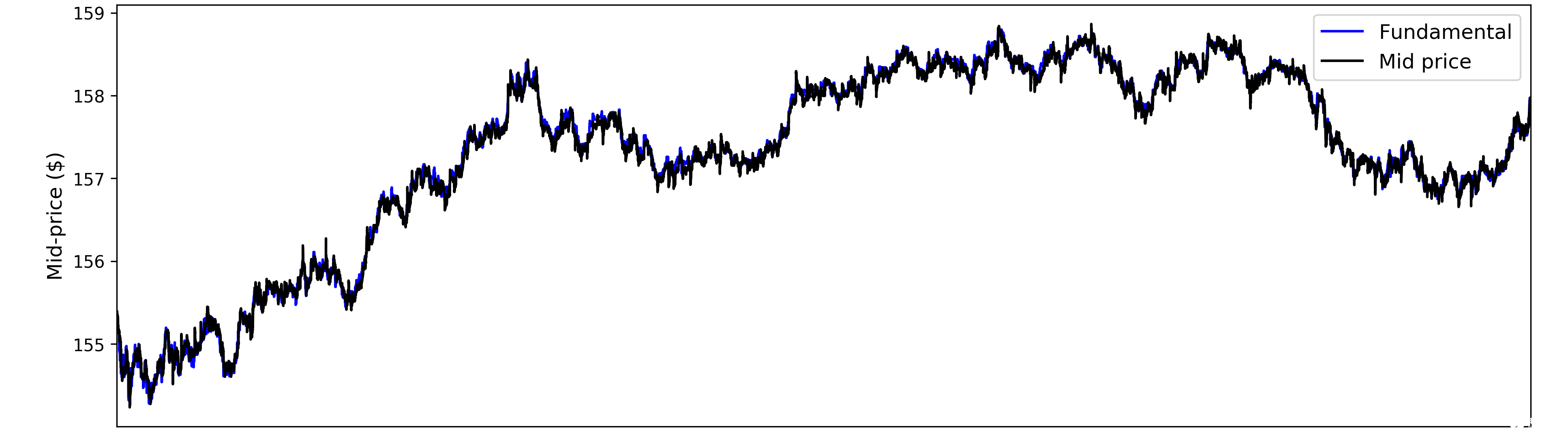 圖 1 。將 Intrinio 的 1 秒輸入 AAPL 報價數據(藍線)與單個交易日輸出 ABIDES 模擬的中間價(黑線)進行比較的圖表
圖 1 。將 Intrinio 的 1 秒輸入 AAPL 報價數據(藍線)與單個交易日輸出 ABIDES 模擬的中間價(黑線)進行比較的圖表
LOB 作為短期價格變動的預測指標
在貿易交易的投標方,買方希望盡可能少地支付購買給定證券的費用。在要求方,賣方希望以盡可能高的價格出售證券。限價單是在買賣雙方設定這些限制的一種方式。
給定證券的 LOB 是一個訂單大小列表, x 軸為證券價格, y 軸為該價格下買賣雙方的總交易量。例如,買家愿意以每股 580 美元的價格購買 100 股谷歌證券,因此出售者必須有足夠的股份來完成這 100 股。請參見圖 2 以獲取 LOB 示例。
LOB 分為出價部分(圖 2 中紅線左側)和要價部分(圖 2 紅線右側),前者的價格低于中間市場,后者的價格較高。
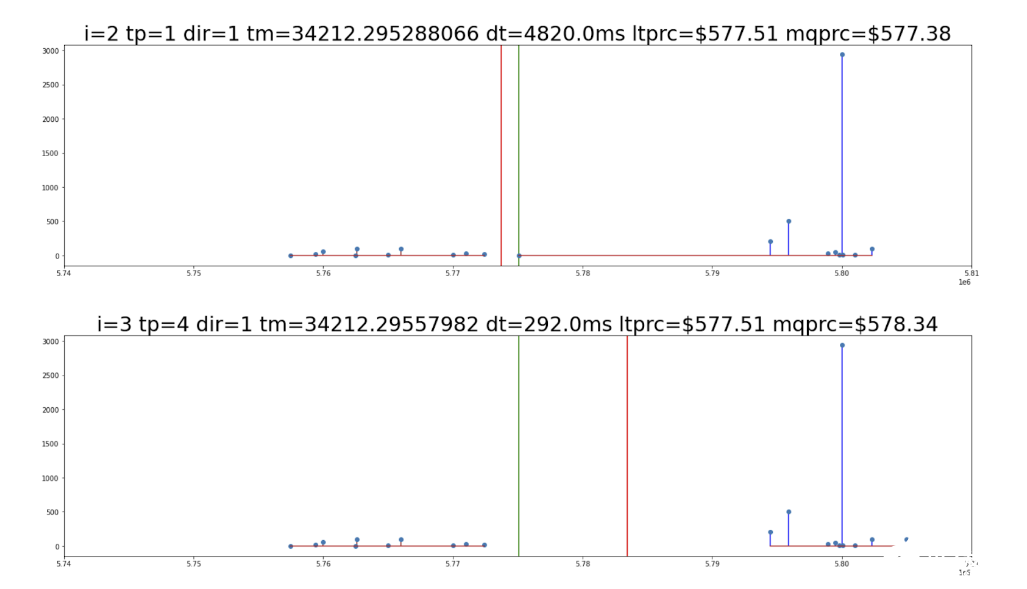 圖 2 :將 GOOG 安全的訂單簿快照限制在相隔 292 微秒的兩個時間點。訂單量顯示在 y 軸上,價格顯示在 x 軸上。中間報價由買賣盤之間的紅線標記。
圖 2 :將 GOOG 安全的訂單簿快照限制在相隔 292 微秒的兩個時間點。訂單量顯示在 y 軸上,價格顯示在 x 軸上。中間報價由買賣盤之間的紅線標記。
簡單地說,買方希望在市場上支付更低的價格,而賣方希望獲得更高的價格。時間點在小數點后有九位數,這反映了現代證券交易所的納秒精度
兩個框架中的第一個框架(位于圖 2 頂部)的一個顯著特征是,從高點(高于標記為 5 . 80 的點)可以看出,以 580 美元的價格出售的需求量很大。觀察這是如何主導 LOB 的,預示著中間報價向右移動,美元價值更高。
圖 3 顯示,當向分類器提供更多的 LOB 深度時,預測價格走勢即時方向的準確性會提高。這是直觀的,因為分類器在訓練過程中有更多關于市場兩側的可用信息(出價水平和要價水平)。
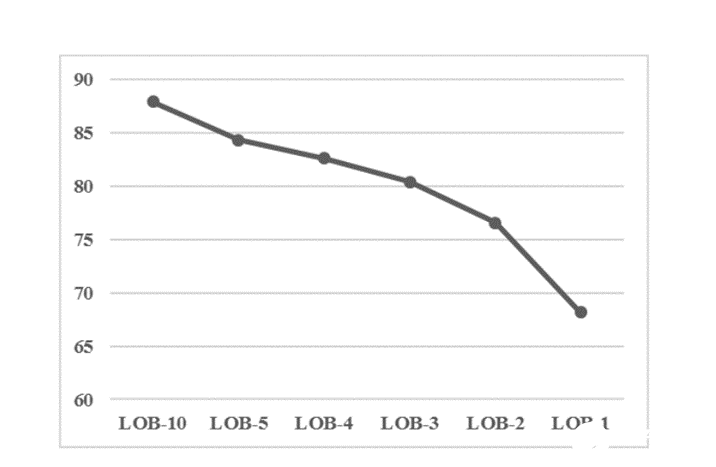 圖 3 。限制訂單簿深度可能會有所不同。 ML 中間價格方向預測的準確性在書中有更多級別時更加穩健
圖 3 。限制訂單簿深度可能會有所不同。 ML 中間價格方向預測的準確性在書中有更多級別時更加穩健
圖片來源:費薩爾·庫雷希
使用 RAPIDS 加速隨機森林訓練
我們訓練了一個隨機森林模型,以 LOB 數據作為輸入來預測短期價格走勢。我們訓練了一個分類器來預測給定的股價是向上、向下還是持平
具體來說,目標是預測未來 20 個中間價格( m下一個) 將小于或大于之前 20 個中間價格的平均值( m上一個) 以一定的幅度。我們將這一差額定義為 0 . 5 美分,這是我們數據集中任何兩個 LOB 幀之間中間價格的最小非零差異。
標簽為 2 表示價格上漲( m下一個–米上一個> 0 . 5 美分),標簽為 1 表示中性價格變動,標簽為 0 表示向下價格變動( m下一個–米上一個< -0 . 5 美分)
以下實驗是在一個NVIDIA A100用于 RAPIDS cuDF 和 RAPIDS cuML 的 80 GB SXM ,以及用于 scikit learn 和 pandas 的兩個 AMD EPYC 7742 64 核處理器。使用 RAPIDS cuDF 庫和 pandas 計算中間價、平均值和標簽
圖 4 顯示了運行時的比較。平均預處理時間是根據每種配置的 10 次運行和 10 次預熱計算得出的。這是在 ML 訓練運行之前的一個標記步驟,如圖 5 所示。
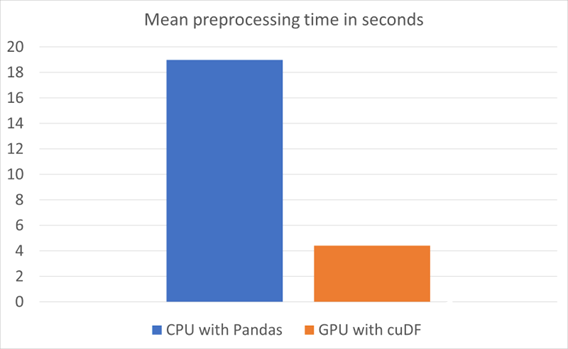 圖 4 。 CPU 與 pandas 以及 GPU 與 cuDF 的平均預處理時間的比較
圖 4 。 CPU 與 pandas 以及 GPU 與 cuDF 的平均預處理時間的比較
我們使用 scikit learn 和 RAPIDS cuML 訓練了一個由 100 棵樹組成的隨機森林分類器,并比較了兩者的訓練時間。 RAPIDS cuML 是 scikit learn 的免費替代品,它使許多流行的 ML 算法能夠在 GPU 上加速
圖 5 顯示了一個 NVIDIA A100 80 GB 與 RAPIDS cuML 以及兩個 AMD EPYC 7742 64 核處理器與 scikit learn 上訓練工作負載的運行時間的比較。 CPU 上的訓練是多線程的,有 128 個線程,使用 scikit learnn_jobs參數
五次熱身的平均時間是 50 分以上,而 scikit 的學習時間是五次熱身平均 10 分以上。使用 GPU 進行訓練的速度大約快 10 倍。這些結果與 2022 年 GPU 研究結果一致,詳見Accelerating Machine Learning Training Time for Limit Order Book Prediction.
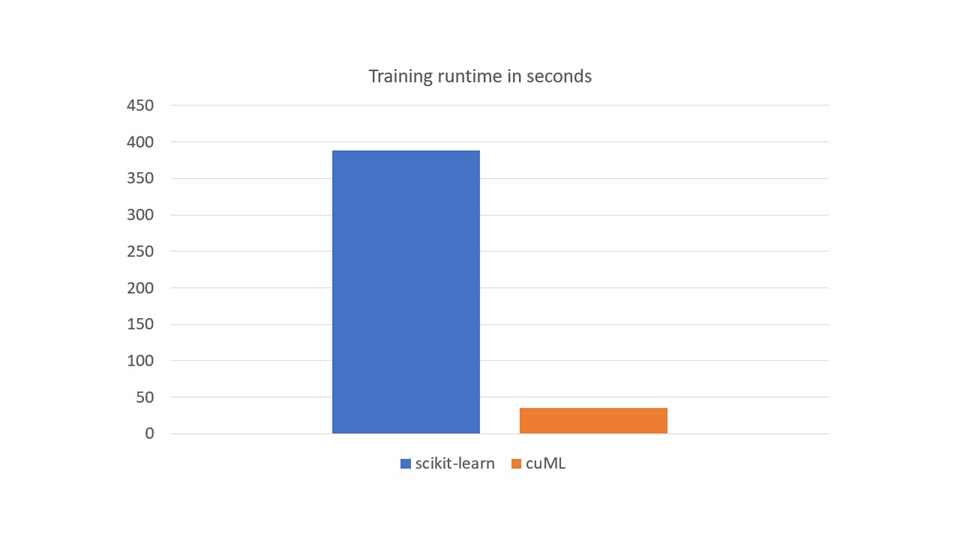 圖 5 。 scikit 在 CPU 上學習和在 GPU 上學習的訓練運行時間(秒)
圖 5 。 scikit 在 CPU 上學習和在 GPU 上學習的訓練運行時間(秒)
GPU 上的培訓可為這一工作量提供 10 倍以上的加速。 ML 分類器開發的迭代性質使其時間密集,特別是考慮到金融市場中使用的大量時間序列數據。簡而言之, GPU 是 ML 算法研究的游戲規則改變者。
金融數據集日益增長的計算需求
雖然前面的例子使用了一個股票行情器,但這些高頻交易和限價訂單的用例需要多個 AI 系統運行相當于多個的算法NVIDIA DGX SuperPODs通常,專門研究此類用例的組織需要多個資產類和跟蹤器
因此,這種算法的分析和應用可以很容易地并行化,案例可以擴展到需要加速時間和大量計算的多個人工智能系統。例如,定量金融、機器學習(如 RAPIDS cuML )和深度學習應用(如 LOB 數據集之上的神經網絡)。
為了在開發金融 ML 算法時加快培訓速度,您可以使用 RAPIDS 庫套件來利用 GPU 加速:
RAPIDS cuDF 取代 pandas Python 庫
RAPIDS cuML 取代 scikit 學習 Python 庫
下載并安裝 RAPIDS開始為您的數據科學工作負載啟用 GPU 。記得事先安裝 NVIDIA 驅動程序和 CUDA 工具包。
-
NVIDIA
+關注
關注
14文章
4940瀏覽量
102815 -
人工智能
+關注
關注
1791文章
46859瀏覽量
237567 -
機器學習
+關注
關注
66文章
8377瀏覽量
132409
發布評論請先 登錄
相關推薦
TF之CNN:CNN實現mnist數據集預測
高效簡潔的用labview讀取excel工作簿信息
長期價格高價回收西門子輸入輸出模塊
開發和設計實現LSTM模型用于家庭用電的多步時間序列預測相關資料分享
基于卡爾曼濾波的電力系統短期負荷預測
LSSVM短期負荷預測模型
華為開發者大會2021 OpenHarmony中短期價值

具有RAPIDS cuML的GPU加速分層DBSCAN
如何使用RAPIDS和CuPy時加速Gauss 秩變換

NVIDIA RAPIDS加速器v21.08的功能應用
通過RAPIDS加速單細胞DNA和RNA基因組分析





 工商網監
工商網監
評論