 為Spark ML算法提供GPU加速度
為Spark ML算法提供GPU加速度
Spark MLlib是Apache Spark用于大規模machine learning并且提供了許多流行的機器學習算法的內置實現。這些實現創建于十年前,但沒有利用現代計算加速器,如 NVIDIA GPU 。
為了解決這一差距,我們最近開源了 Spark RAPIDS ML(NVIDIA/spark-rapids-ml) ,一個 Python 包,為 Py Spark ML 應用程序提供 GPU 加速。通過這樣做,我們實現了以下關鍵目標:
應用程序編程接口:完全保留 Py Spark MLlib 基于 DataFrames 的 APISpark ML algorithms,保持與 Spark 的 Pipeline API 、 CrossValidation 等的兼容性。允許在基線 Spark ML 實現和 GPU 加速實現之間切換,只需最少的代碼更改(即最多更改 Python 包導入語句)。
加快速度并節省成本:為 Spark ML 算法展示 GPU 加速帶來的顯著性能提升和成本節約。
體系結構:利用 NVIDIA 已經完成的大量工作來加速傳統的 ML 算法。
您可以從NVIDIA/spark-rapids-mlApache v2 許可證下的 GitHub 存儲庫。初始版本為以下 Spark ML 算法提供了 GPU 加速度:
主成分分析
K- 均值聚類
帶脊和彈性網正則化的線性回歸
隨機森林分類和回歸
該版本還包括以下內容的 Spark ML API 兼容版本:
K 最近鄰
我們之所以最初選擇算法,是因為我們的第三個目標:盡可能使用現有的 NVIDIA 加速 ML 庫。
具體而言,我們選擇在OSS RAPIDS cuML library并為 Spark ML 中也提供的算法的現有 cuML 分布式實現提供 Py Spark API 包裝器。
RAPIDS cuML 還對 Spark ML 中沒有的一些流行算法進行了 GPU 加速的分布式實現,我們已經包括了 k 個最近鄰居,作為為這些算法提供 Spark ML API 兼容性的概念證明。
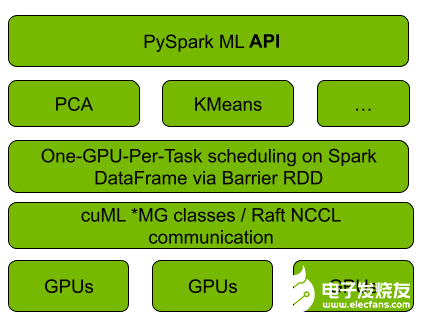
圖 1 。 Spark RAPIDS ML 和 cuML 集成
圖 1 顯示, GPU cuML ML 與 cuML 的集成使用 Spark 的 Barrier RDD 同步和通信機制,在正在運行的 Spark cluster 上引導 cuML s 的分布式算法實現,每個 RAPIDS 工作者映射到每個 Spark 一個 Spark ]任務上。算法計算和工作人員之間的通信被推遲到 cuML 。對于后者, cuML 依賴于 NCCL 和 UCX 庫來加速 GPU 之間的通信, Spark RAPIDS ML 也使用這些通信。
易于采用的 API
作為核心設計目標, Spark RAPIDS ML API 旨在將代碼更改降至最低,以方便 Spark ML 開發人員采用,并促進現有 Spark ML 應用程序的遷移。
以下代碼示例用于 KMean 的基線 Spark ML 和 Spark RAPIDS ML ,其中只有 Python 導入語句被更改.
py Spark 毫升
from pyspark.ml.clustering import KMeans kmeans_estm = KMeans() .setK(100) .setFeaturesCol("features") .setMaxIter(30) kmeans_model = kmeans_estm.fit(pyspark_data_frame) kmeans_model.write().save("saved-model") transformed = kmeans_model.transform(pyspark_data_frame)
Spark _ RAPIDS _ ml
從 Spark _ RAPIDS _ ml 導入 KMeans
kmeans_estm = KMeans()
.setK(100)
.setFeaturesCol("features")
.setMaxIter(30)
kmeans_model = kmeans_estm.fit(pyspark_data_frame)
kmeans_model.write().save("saved-model")
transformed = kmeans_model.transform(pyspark_data_frame)
更一般地說,支持算法的 Spark RAPIDS ML 加速版本實現了 Spark ML 對應的估計器模型 API 。它們具有匹配的(在名稱和數據類型上)構造函數參數、 getter 和 setter 以及模型屬性和方法,在各種算法的底層 cuML 實現所支持的范圍內。
相應的擬合和變換方法接受帶有 VectorUDT 的 Spark 數據幀、 Spark SQL 數組或標量特征列(帶有Float或Double元素類型)。目前,僅支持密集向量。
加快速度并節省成本
在本節中,我們提供了初步的基準測試結果,比較了支持算法的 GPU 加速 Spark RAPIDS ML 版本和基于 CPU 的 Spark ML 版本。
基準測試在 Databricks 的 AWS 托管 Spark 服務上的三個節點 Spark cluster (一個驅動程序,兩個執行器)中運行,具有以下硬件配置:
在 CPU 集群中,m5.2xlarge執行器和驅動程序節點各有八個CPU內核和32 GB RAM。
在 GPU 集群中, g5.2x 大型執行器節點的 CPU 和 RAM 與 m5.2x 大型節點相同,還有 NVIDIA 24-GBA10GPU 。
基準測試是在適用于相應算法的 12-GB 合成數據集上運行的。它們是使用 sci-kit learn 的合成數據生成例程生成的,并以 Parquet 格式存儲在 Amazon S3 上。運行時用于從 Amazon S3 加擬合方法執行端到端數據加載。我們還使用了spark-rapids plugin以加速 GPU 運行的數據加載。
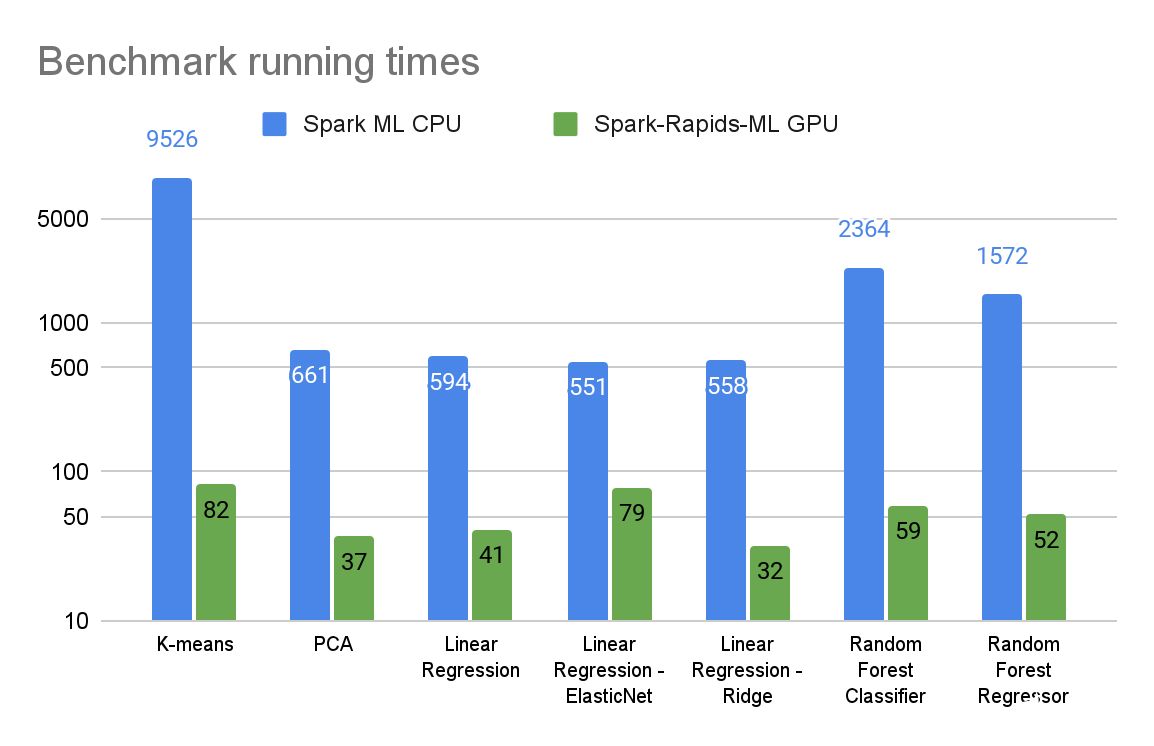 圖 2 : 基于 CPU 的 Spark ML 和 GPU 加速 Spark RAPIDS ML 算法擬合方法的運行時間(秒)(對數刻度)
圖 2 : 基于 CPU 的 Spark ML 和 GPU 加速 Spark RAPIDS ML 算法擬合方法的運行時間(秒)(對數刻度)
圖 2 和圖 3 總結了各種算法的基準測試結果。選擇數據集和算法參數來表示高度計算密集型的 ML 工作負載。
圖 3 中的成本效益圖顯示了由基準運行時間和 Databricks 的計算成本模型( DBU 加上 CPU EC2 實例成本)確定的 CPU 計算成本與 Amazon 計算成本的比率。雖然 GPU 集群每小時的成本更高,但對于這些基準測試來說,它的端到端成本效益要高得多,因為它不僅能補償更快的運行時間。
有關更多信息和重現這些結果的步驟,請參閱NVIDIA/spark-rapids-mlGitHub。
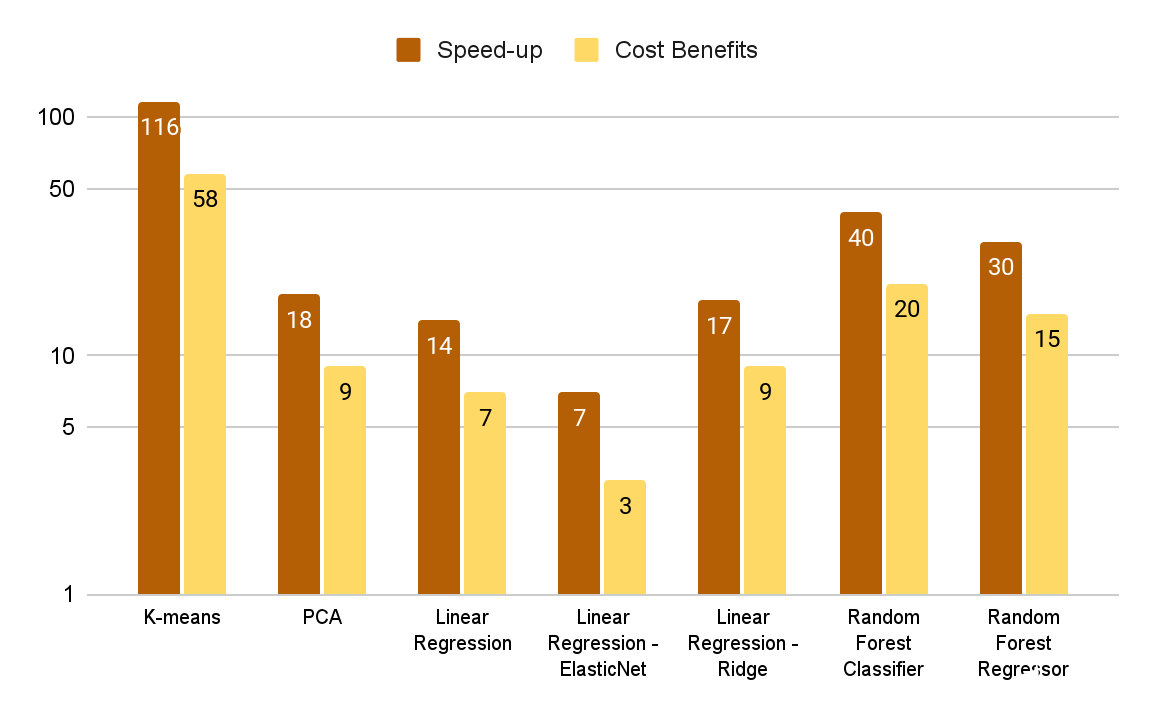 圖 3 。 GPU – CPU 加速系數和相應的成本效益
圖 3 。 GPU – CPU 加速系數和相應的成本效益
接下來的步驟
使用 Spark RAPIDS ML ,只需一行代碼更改即可顯著加快 Spark ML 應用程序的速度,并降低計算成本。
-
NVIDIA
+關注
關注
14文章
4940瀏覽量
102818 -
gpu
+關注
關注
28文章
4702瀏覽量
128708 -
人工智能
+關注
關注
1791文章
46872瀏覽量
237593
發布評論請先 登錄
相關推薦
ADI362如何得到線性加速度的值?






 工商網監
工商網監
評論