 如何使用NVIDIA Triton 推理服務器來運行推理管道
如何使用NVIDIA Triton 推理服務器來運行推理管道
在許多生產級機器學習( ML )應用程序中,推理并不局限于在單個 ML 模型上運行前向傳遞。相反,通常需要執行 ML 模型的管道。例如,一個由三個模塊組成的對話式人工智能管道:一個將輸入音頻波形轉換為文本的自動語音識別( ASR )模塊,一個理解輸入并提供相關響應的大型語言模型( LLM )模塊,以及一個從 LLM 輸出產生語音的文本到語音( TTS )模塊。
或者,考慮一個文本到圖像的應用程序,其中管道由 LLM 和擴散模型組成,它們分別用于對輸入文本進行編碼和從編碼的文本合成圖像。此外,許多應用程序在將輸入數據饋送到 ML 模型之前需要對其進行一些預處理步驟,或者對這些模型的輸出進行后處理步驟。例如,輸入圖像在被饋送到計算機視覺模型之前可能需要被調整大小、裁剪和解碼,或者文本輸入在被饋送給 LLM 之前需要被標記化。
近年來, ML 模型中的參數數量激增,它們越來越多地被要求為龐大的消費者群體提供服務;因此,優化推理管道變得比以往任何時候都更加重要。 NVIDIA TensorRT 和 FasterTransformer 等工具在 GPU s 上執行推理時,優化單個深度學習模型,以獲得更低的延遲和更高的吞吐量。
然而,我們的首要目標不是加快單個 ML 模型的推理,而是加快整個推理管道。例如,當在 GPU 上服務模型時,在 CPU 上具有預處理和后處理步驟會降低整個管道的性能,即使模型執行步驟很快。推理管道最有效的解決方案是使預處理、模型執行和后處理步驟都在 GPU s 上運行。這種端到端推理流水線在 GPU 上的效率來自以下兩個關鍵因素。
在流水線步驟之間,數據不需要在 CPU (主機)和 GPU (設備)之間來回復制。
GPU 強大的計算能力被用于整個推理管道。
NVIDIA Triton Inference Server 是一款開源推理服務軟件,用于在 CPU 和 GPU 上大規模部署和運行模型。在許多功能中, NVIDIA Triton 支持 ensemble models ,使您能夠將推理管道定義為有向非循環圖( DAG )形式的模型集合。 NVIDIA Triton 將處理整個管道的執行。集成模型定義了如何將一個模型的輸出張量作為輸入饋送到另一個模型。
使用 NVIDIA Triton 集成模型,您可以在 GPU 或 CPU 上運行整個推理管道,也可以在兩者的混合上運行。當涉及預處理和后處理步驟時,或者當管道中有多個 ML 模型,其中一個模型的輸出饋送到另一個模型時,這是有用的。對于管道包含循環、條件或其他自定義邏輯的用例, NVIDIA Triton 支持 Business Logic Scripting (BLS) 。
這篇文章只關注整體模型。它將引導您完成使用不同框架后端創建具有多個模型的端到端推理管道的步驟。 NVIDIA Triton 提供了使用多個框架后端構建模型管道的靈活性,并在 GPU 或 CPU 上運行它們,或兩者混合運行。我們將探索以下三種管道運行方式。
整個管道在 CPU 上執行。
預處理和后處理步驟在 CPU 上運行,模型執行在 GPU 上運行。
整個管道在 GPU 上執行。
我們還將強調使用 NVIDIA Triton 推理服務器在 GPU 上運行整個推理管道的優勢。我們專注于 CommonLit Readability Kaggle challenge ,用于預測 3-12 年級文學段落的復雜度,使用 NVIDIA Triton 進行整個推理。請注意, NVIDIA Triton 222.11 用于本博客文章的目的。您也可以使用 NVIDIA Triton 的更高版本,前提是您在后端使用匹配的版本(表示為),以避免可能的兼容性錯誤。
模型創建
對于這項任務,訓練兩個獨立的模型:使用 PyTorch 訓練的 BERT-Large 和使用 cuML 訓練的隨機森林回歸器。將這些型號命名為bert-large和cuml。這兩個模型都會將經過預處理的摘錄作為輸入,并輸出分數或復雜度。
作為第一個模型,從預訓練的 Hugging Face 模型中微調基于 transformer 的bert-large模型 bert-large-uncased 其具有 340M 個參數。通過添加一個線性層來微調任務的模型,該線性層將 BERT 的最后一個隱藏層映射到單個輸出值。
使用均方根損失、帶有權重衰減的 Adam 優化器和 5 倍交叉驗證進行微調。通過在模型中傳遞示例輸入并使用以下命令跟蹤模型,將模型序列化為 TorchScript 文件(名為model.pt):
traced_script_module = torch.jit.trace(bert_pytorch_model, (example_input_ids, example_attention_mask)) traced_script_module.save("model.pt")
作為第二個模型,使用 cuML 隨機森林回歸器,其中有 100 棵樹,每棵樹的最大深度為 16 。為基于樹的模型生成以下特征:每個摘錄的單詞數、每個摘錄的不同單詞數、標點符號數、每個節選的句子數、每個句子的平均單詞數、每次摘錄的停止單詞數、每句子的平均停止單詞數, N 最常出現的單詞在語料庫中的頻率分布,以及 N 最不頻繁單詞在語料庫中的頻率分布。
使用 N=100 ,這樣隨機森林總共包含 207 個特征。通過使用以下命令轉換 cuML 模型實例,將經過訓練的 cuML 模型序列化為 Treeite 檢查點(名為checkpoint.tl):
cuml_model.convert_to_treelite_model().to_treelite_checkpoint('checkpoint.tl')
請注意,與模型關聯的 Treelite 版本需要與用于推斷的 NVIDIA Triton 容器中的 Treeliet 版本相匹配。
在 NVIDIA Triton 上運行 ML 模型
要在 NVIDIA Triton 中部署的每個模型都必須包括一個模型配置。默認情況下,當模型元數據可用時, NVIDIA Triton 將嘗試使用模型元數據自動創建配置。在模型元數據不足的情況下,可以手動提供模型配置文件,也可以覆蓋推斷的設置。有關更多詳細信息,請參閱 GitHub 上的 triton-inference-server/server 。
要在 NVIDIA Triton 上運行 PyTorch 格式的 BERT Large ,請使用 PyTorch (LibTorch) backend 。將以下行添加到模型配置文件中以指定此后端:
backend: "pytorch"
要在 NVIDIA Triton 上運行基于樹的隨機林模型,請使用 FIL (Forest Inference Library) backend ,在模型配置文件中添加以下內容:
backend: "fil"
此外,在模型配置文件中添加以下行,以指定所提供的模型為 Treeite 二進制格式:
parameters { key: "model_type" value: { string_value: "treelite_checkpoint" } }
最后,在每個模型配置文件中,包括instance_group[{kind:KIND_GPU}]或instance_group[{kind:KIND_CPU}],這取決于模型是在 GPU 還是 CPU 上提供服務。
到目前為止,生成的模型存儲庫目錄結構如下:
.
├── bert-large
│ ├── 1
│ │ └── model.pt
│ └── config.pbtxt
└── cuml
├── 1
│ └── checkpoint.tl
└── config.pbtxt
預處理和后處理
預處理和后處理可以在 NVIDIA Triton 服務器之外執行,也可以作為 NVIDIA Triton 中模型集合的一部分進行合并。對于本例,預處理和后處理由 Python 中執行的操作組成。使用 Python backend 作為集成的一部分來運行這些操作。
如果 NVIDIA Triton 服務器容器中提供的默認 Python 版本可以運行 Python model ,則可以忽略以下部分,直接跳到下面標題為“比較推理管道”的部分否則,您將需要創建一個自定義 Python 后端存根和一個自定義執行環境,如下所述。
自定義 Python 后端存根
Python 后端使用存根進程將model.py文件連接到 NVIDIA Triton C++核心。 Python 后端可以使用安裝在當前[ZGK8環境(虛擬環境或Conda環境)或全局 Python 環境中的庫。
請注意,這假設用于編譯后端存根的 Python 版本與用于安裝依賴項的版本相同。寫入時使用的 NVIDIA Triton 容器中的默認 Python 版本為 3.8 。如果需要運行預處理和后處理的 Python 版本與 NVIDIA Triton 容器中的版本不匹配,則需要編譯 custom Python backend stub 。
要創建自定義 Python 后端存根,請在 NVIDIA conda容器內安裝conda、cmake、rapidjson和 Triton 。接下來,創建一個 Conda 虛擬環境(請參見 documentation ),并使用以下命令激活它:
conda create -n custom_env python= conda init bash bash conda activate custom_env
將替換為感興趣的版本,例如 3.9 。然后克隆 Python 后端回購,并使用以下代碼編譯 Python 后端存根:
git clone https://github.com/triton-inference-server/python_backend -b r cd python_backend mkdir build && cd build cmake -DTRITON_ENABLE_GPU=ON -DCMAKE_INSTALL_PREFIX:PATH=`pwd`/install .. make triton-python-backend-stub
請注意,必須替換為 NVIDIA Triton 容器版本。運行上面的命令將創建名為triton-python-backend-stub的存根文件。這個 Python 后端存根現在可以用來加載安裝有匹配版本[ZGK8的庫。
自定義執行環境
如果您想為不同的 Python 型號使用不同的 Python 環境,您需要創建一個 custom execution environment 。要為 Python 模型創建自定義執行環境,第一步是在已經激活的 Conda 環境中安裝任何必要的依賴項。然后運行conda-pack將我們的自定義執行環境打包為 tar 文件。這將創建一個名為custom_env.tar.gz的文件。
在撰寫本文時, NVIDIA Triton 僅支持conda-pack用于捕獲執行環境。請注意,當在 NVIDIA Triton Docker 容器中工作時,容器中包含的包也會在conda-pack創建的執行環境中捕獲。
使用 Python 后端存根和自定義執行環境
在創建 Python 后端存根和自定義執行環境后,將兩個生成的文件從容器復制到模型存儲庫所在的本地系統。在本地系統中,將存根文件復制到每個需要使用存根的 Python 模型(即預處理和后處理模型)的模型目錄中。對于這些模型,目錄結構如下:
model_repository
├── postprocess
│ ├── 1
│ │ └── model.py
│ ├── config.pbtxt
│ └── triton_python_backend_stub
└── preprocess
├── 1
│ └── model.py
├── config.pbtxt
└── triton_python_backend_stub
對于預處理和后處理模型,還需要在配置文件中提供自定義執行環境的 tar 文件的路徑。例如,預處理模型的配置文件將包括以下代碼:
name: "preprocess"
backend: "python"
...
parameters: {
key: "EXECUTION_ENV_PATH",
value: {string_value: "path/to/custom_env.tar.gz"}
}
要使此步驟生效,請將custom_env.tar.gz存儲在 NVIDIA Triton 推理服務器容器可以訪問的路徑中。
用于預處理和后處理的 model.py 文件的結構
每個 Python 模型都需要遵循 documentation 中描述的特定結構。在model.py文件中定義以下三個功能:
1. initialize(可選,在加載模型時運行):用于在推理之前加載必要的組件,以減少每個客戶端請求的開銷。特別是對于預處理,加載 cuDF tokenizer ,它將用于標記基于 BERT 的模型的摘錄。還加載用于隨機森林特征生成的停止詞列表,作為對基于樹的模型的輸入的一部分。
2 .execute(必需,請求推理時運行):接收推理請求,修改輸入,并返回推理響應。由于preprocess是推理的入口點,如果要對 GPU 執行推理,則需要將輸入移動到[Z1K1’。
通過創建cudf.Series的實例將摘錄輸入張量移動到 GPU ,然后利用initialize中加載的 cuDF 標記器在[Z1K1’上標記整批摘錄。
類似地,使用字符串操作生成基于樹的特征,然后使用在 GPU 上操作的CuPY數組對特征進行歸一化。要在 GPU 上輸出張量,請使用toDlpack和from_dlpack(參見 documentation )將張量封裝到推理響應中。
最后,為了保持張量在 GPU 上,并避免在集合中的步驟之間復制到 CPU ,請將以下內容添加到每個模型的配置文件中:
parameters: {
key: "FORCE_CPU_ONLY_INPUT_TENSORS"
value: {
string_value:"no"
}
}
postprocess的輸入分數已經在 GPU 上了,所以只需將分數與CuPY數組再次組合,并輸出最終的管道分數。對于在 CPU 上進行后處理的情況,在預處理步驟中將ML模型的輸出移動到[Z1K2’。
3. finalize(可選,在卸載模型時運行):使您能夠在從 NVIDIA Triton 服務器卸載模型之前完成任何必要的清理。
推理管道比較
本節介紹了不同的推理管道,并從延遲和吞吐量方面對它們進行了比較。
CPU 上的預處理和后處理, GPU 上的 ML 模型推理
此設置使用 NVIDIA Triton 對 ML 模型執行推理,同時在客戶端所在的本地機器上使用 CPU 執行預處理和后處理(圖 1 )。在預處理模型中,對于給定的一批文本摘錄,使用 BERT 標記器對摘錄進行標記,并為 cuML 模型生成基于樹的特征。
然后將預處理模型的輸出作為推理請求發送給 NVIDIA Triton 。 NVIDIA Triton 然后對 GPU 上的 ML 模型執行推理并返回響應。在 CPU 上本地對該響應進行后處理,以生成輸出分數。
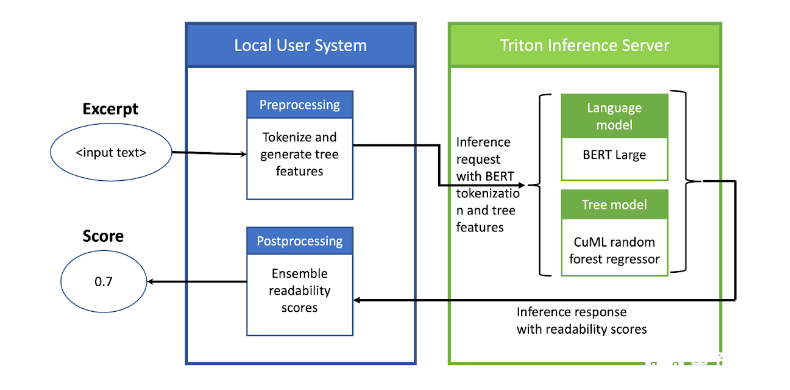 圖 1 。在 NVIDIA Triton 推理服務器上運行 ML 模型的管道設置,其中預處理和后處理步驟在 CPU 上本地執行
圖 1 。在 NVIDIA Triton 推理服務器上運行 ML 模型的管道設置,其中預處理和后處理步驟在 CPU 上本地執行
在 GPU 上執行 NVIDIA Triton 中的整個管道
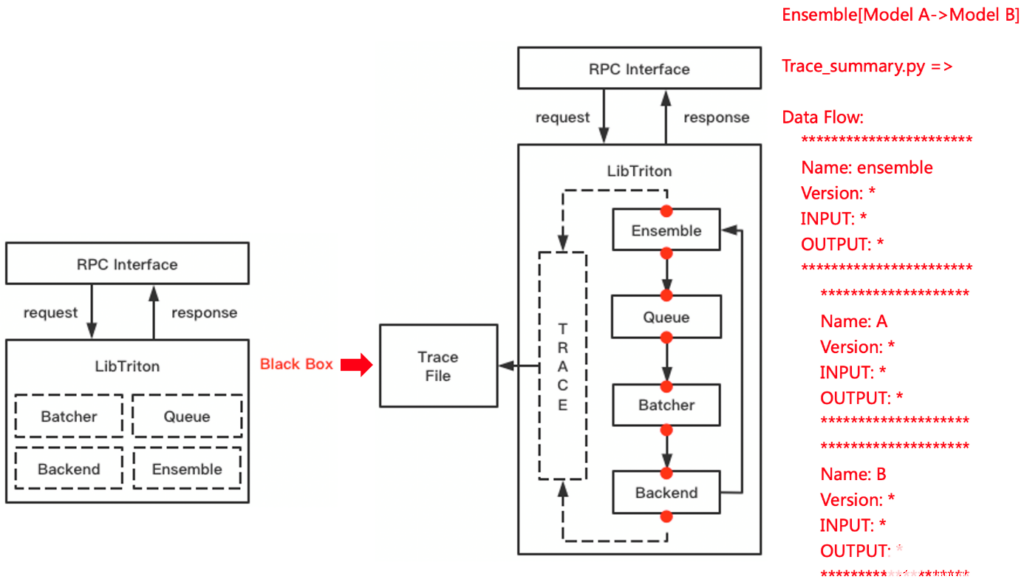
在此設置中,使用 NVIDIA Triton 在 GPU 上執行整個推理管道。對于這個例子, NVIDIA Triton 中的數據管道和流可以在圖 2 中看到。
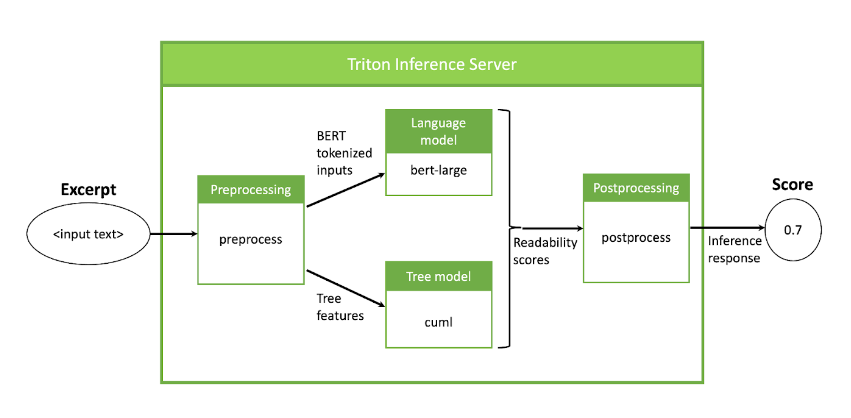 圖 2 :管道設置,包括預處理、模型執行和后處理,所有這些都作為 NVIDIA Triton 集成在 GPU 上執行
圖 2 :管道設置,包括預處理、模型執行和后處理,所有這些都作為 NVIDIA Triton 集成在 GPU 上執行
管道從一個預處理模型開始,該模型將文本摘錄作為輸入,為 BERT 標記摘錄,并為隨機森林模型提取特征。接下來,在預處理模型的輸出上同時運行兩個 ML 模型,每個模型生成指示輸入文本的復雜度的分數。最后,在后處理步驟中對得到的分數進行組合。
要讓 NVIDIA Triton 運行上面的執行管道,請創建一個名為ensemble_all的 ensemble model 。該模型與任何其他模型具有相同的模型目錄結構,只是它不存儲任何模型,并且只由一個配置文件組成。集成模型的目錄如下所示:
├── ensemble_all │ ├── 1 │ └── config.pbtxt
在配置文件中,首先使用以下腳本指定集成模型名稱和后端:
name: "ensemble_all" backend: "ensemble"
接下來,定義集合的端點,即集合模型的輸入和輸出:
input [
{
name: "excerpt"
data_type: TYPE_STRING
dims: [ -1 ]
},
{
name: "BERT_WEIGHT"
data_type: TYPE_FP32
dims: [ -1 ]
}
]
output {
name: "SCORE"
data_type: TYPE_FP32
dims: [ 1 ]
}
管道的輸入是可變長度的,因此使用 -1 作為尺寸參數。輸出是一個單浮點數。
要創建通過不同模型的管道和數據流,請包括ensemble_scheduling部分。第一個模型被稱為preprocess,它將摘錄作為輸入,并輸出 BERT 令牌標識符和注意力掩碼以及樹特征。調度的第一步顯示在模型配置的以下部分中:
ensemble_scheduling {
step [
{
model_name: "preprocess"
model_version: 1
input_map {
key: "INPUT0"
value: "excerpt"
}
output_map {
key: "BERT_IDS"
value: "bert_input_ids",
}
output_map {
key: "BERT_AM"
value: "bert_attention_masks",
}
output_map {
key: "TREE_FEATS"
value: "tree_feats",
}
},
step部分中的每個元素都指定了要使用的模型,以及如何將模型的輸入和輸出映射到集合調度器識別的張量名稱。然后使用這些張量名稱來識別各個輸入和輸出。
例如,step中的第一個元素指定應使用preprocess模型的版本一,其輸入"INPUT0"的內容由"excerpt"張量提供,其輸出"BERT_IDS"的內容將映射到"bert_input_ids"張量以供以后使用。類似的推理適用于preprocess的其他兩個輸出。
繼續在配置文件中添加步驟以指定整個管道,將preprocess的輸出傳遞到bert-large和cuml的輸入:
{
model_name: "bert-large"
model_version: 1
input_map {
key: "INPUT__0"
value: "bert_input_ids"
}
input_map {
key: "INPUT__1"
value: "bert_attention_masks"
}
output_map {
key: "OUTPUT__0"
value: "bert_large_score"
}
},
最后,通過在配置文件中添加以下行,將這些分數中的每一個傳遞到后處理模型,以計算分數的平均值并提供單個輸出分數,如下所示:
{
model_name: "postprocess"
model_version: 1
input_map {
key: "BERT_WEIGHT_INPUT"
value: "BERT_WEIGHT"
}
input_map {
key: "BERT_LARGE_SCORE"
value: "bert_large_score"
}
input_map {
key: "CUML_SCORE"
value: "cuml_score"
}
output_map {
key: "OUTPUT0"
value: "SCORE"
}
}
}
]
在集成模型的配置文件中調度整個管道的簡單性證明了使用 NVIDIA Triton 進行端到端推理的靈活性。要添加另一個模型或添加另一數據處理步驟,請編輯集成模型的配置文件并更新相應的模型目錄。
請注意,集成配置文件中定義的max_batch_size必須小于或等于每個模型中定義的max_batch_size。整個模型目錄,包括集成模型,如下所示:
├── bert-large
│ ├── 1
│ │ └── model.pt
│ └── config.pbtxt
├── cuml
│ ├── 1
│ │ └── checkpoint.tl
│ └── config.pbtxt
├── ensemble_all
│ ├── 1
│ │ └── empty
│ └── config.pbtxt
├── postprocess
│ ├── 1
│ │ ├── model.py
│ └── config.pbtxt
└── preprocess
├── 1
│ ├── model.py
└── config.pbtxt
要告訴 NVIDIA Triton 執行 GPU 上的所有模型,請在每個模型的配置文件中包括以下行(集成模型的配置文檔中除外):
instance_group[{kind:KIND_GPU}]
在 CPU 上執行 NVIDIA Triton 中的整個管道若要讓 NVIDIA Triton 在 CPU 上執行整個管道,請重復在 GPU 上運行管道的所有步驟。在每個配置文件中將instance_group[{kind:KIND_GPU}]替換為以下行:
instance_group[{kind:KIND_CPU}]
后果
我們使用 GCP a2 高 GPU -1g VM 在延遲和吞吐量方面比較了以下三個推理管道:
由 NVIDIA Triton 在英特爾至強 CPU 上以 2.20 GHz 執行的完整管道
NVIDIA Triton 在 NVIDIA A100 40 GB GPU 上執行 ML 模型,在英特爾至強 CPU 上以 2.20 GHz 本地執行預處理和后處理
由 NVIDIA Triton 在 NVIDIA A100 40 GB GPU 上執行的完整管道
從表 1 中的結果可以明顯看出,使用 NVIDIA Triton 在 GPU 上運行整個管道的優勢。對于較大的批處理大小和張量大小,吞吐量的提高更為明顯。 NVIDIA A100 40 GB 型號的執行管道比在 2.20 GHz 下在 Intel Xeon CPU 上運行的整個管道效率高得多。當將預處理和后處理從 CPU 移動到 GPU 時,有進一步的改進。
| Full pipeline on CPU | Pre/postprocess on CPU; ML models on GPU | Full pipeline on GPU | |
| Latency (ms) | 523 | 192 | 31 |
| Throughput (samples/second) for batch size 512 | 242 | 7707 | 8308 |
表 1 。不同管道的延遲和吞吐量
如圖 3 所示, CPU 在非常適中的批量下受到瓶頸限制,在 GPU 上運行整個管道可以顯著提高吞吐量。
 圖 3 。隨著批處理大小從 1 到 512 的變化,不同推理管道的吞吐量
圖 3 。隨著批處理大小從 1 到 512 的變化,不同推理管道的吞吐量
結論
這篇文章解釋了如何使用 NVIDIA Triton 推理服務器來運行由預處理和后處理組成的推理管道,以及基于 transformer 的語言模型和基于樹的模型來解決 Kaggle 挑戰。 NVIDIA Triton 為同一管道的模型以及預處理和后處理邏輯提供了使用多個框架/后端的靈活性。這些管道可以在 CPU s 和/或 GPU s 上運行。
我們表明,與在 CPU 上運行預處理和后處理步驟以及在 GPU 上執行模型相比,在模型執行的同時利用 GPU s 進行預處理和后期處理,將端到端延遲減少了 6 倍。我們還表明,使用 NVIDIA Triton 使我們能夠同時對多個 ML 模型執行推理,并且從一種部署類型(所有 CPU )到另一種(所有 GPU )只需要在配置文件中更改一行即可。
-
NVIDIA
+關注
關注
14文章
4793瀏覽量
102429 -
服務器
+關注
關注
12文章
8701瀏覽量
84549 -
AI
+關注
關注
87文章
28877瀏覽量
266230
發布評論請先 登錄
相關推薦
NVIDIA宣布其AI推理平臺的重大更新
NVIDIA Triton 推理服務器助力西門子提升工業效率
NVIDIA Triton開源推理服務軟件三大功能推動效率提升
NVIDIA Triton推理服務器幫助Teams使用認知服務優化語音識別模型
使用MIG和Kubernetes部署Triton推理服務器
NVIDIA推理平臺和全棧方法提供最佳性能

NVIDIA Triton推理服務器簡化人工智能推理
使用NVIDIA Triton推理服務器簡化邊緣AI模型部署
利用NVIDIA Triton推理服務器加速語音識別的速度
NVIDIA Triton助力騰訊PCG加速在線推理





 工商網監
工商網監
評論