 設計大規模并行哈希圖時的幾個重要考慮事項
設計大規模并行哈希圖時的幾個重要考慮事項
數十年的計算機科學史致力于設計有效存儲和檢索信息的解決方案。哈希圖(或哈希表)是一種流行的信息存儲數據結構,因為它對元素的插入和檢索具有攤銷、恒定的時間保證。
然而,盡管哈希圖很流行,但很少在 GPU 加速計算的上下文中討論哈希圖。雖然 GPU 以其大量線程和計算能力而聞名,但其極高的內存帶寬使許多數據結構(如哈希圖)得以加速。
這篇文章介紹了哈希圖的基本原理,以及它們的內存訪問模式如何使其非常適合 GPU 加速。我們將介紹 cuCollections ,這是一個用于并發數據結構(包括哈希圖)的新的開源 CUDA C ++庫。
最后,如果您對在應用程序中使用 GPU 加速哈希映射感興趣,我們將提供多列關系連接算法的示例實現。 RAPIDS cuDF 集成了 GPU 哈希圖,這有助于實現 數據科學工作負載的驚人加速。要了解更多信息,請參閱 GitHub 上的 rapidsai/cudf 和 使用 Dask 和 RAPIDS 為自然語言處理加速 TF-IDF。
您還可以將 cuCollections 用于表格數據處理之外的許多用例,例如推薦系統、流壓縮、圖形算法、基因組學和稀疏線性代數操作。
哈希圖基礎知識
哈希映射是 associative 容器,這意味著它們存儲 key – value 對,其中 key 映射到關聯的 value ,從而通過查找其鍵來檢索值。例如,您可以使用哈希圖來實現電話簿,方法是使用個人的姓名作為密鑰,將其電話號碼作為關聯值。
哈希映射與其他關聯容器的不同之處在于,插入或檢索等操作的平均成本是恒定的。 std::map 在 C ++標準模板庫中不是哈希表,但通常實現為二進制搜索樹。 std::unordered_map 更類似于與此討論相關的哈希表類型。在本文中,哈希表和哈希圖之間沒有區別。這兩個術語將在整個過程中互換使用。
單值與多值比較
討論哈希表時的一個重要區別是是否允許重復鍵。單值哈希表或哈希映射要求鍵是唯一的(例如,std::unordered_map),而多值哈希表和哈希多映射允許重復鍵(例如,std::unordered_multimap)。
使用電話簿類比,后者指的是一個人可以擁有多個電話號碼的情況。例如,電話簿可以具有 (k=Alice, v=408-555-0148) 和具有另一個值 (k=Alice, v=408-555-3847) 的重復密鑰。
存儲和檢索
從概念上講,哈希映射由一個桶數組組成,其中每個桶可以包含一個或多個鍵值對。要在映射中插入新的對,將向鍵應用哈希函數以生成哈希值。然后使用該哈希值選擇其中一個桶。如果存儲桶可用,則該對存儲在該存儲桶中。
例如,要插入對 (Alice, 408-555-0148) ,您對鍵 hash(Alice)=4, 進行散列以獲取其散列值,并選擇位置 4 處的存儲桶來存儲對。稍后,要檢索與 Alice 關聯的值,可以使用相同的哈希函數 hash(Alice), 再次選擇位置 4 處的存儲桶并檢索先前存儲的值。
哈希沖突
如果表中桶的數量等于可能的鍵的數量,則可以使用哈希桶和鍵之間的一對一關系,其中每個鍵正好映射到表中的一個桶。
然而,這在大多數情況下是不切實際的,因為潛在密鑰的數量事先不知道,或者為每個密鑰保留存儲桶所需的存儲將超過可用的存儲容量。想象一下,如果你的電話簿必須為宇宙中每個可能的名字保留一個條目!
因此,哈希函數通常是不完美的,并可能導致哈希沖突,其中兩個不同的鍵映射到相同的哈希值(圖 1 )。好的哈希函數尋求最小化沖突的可能性,但在大多數情況下它們是不可避免的。
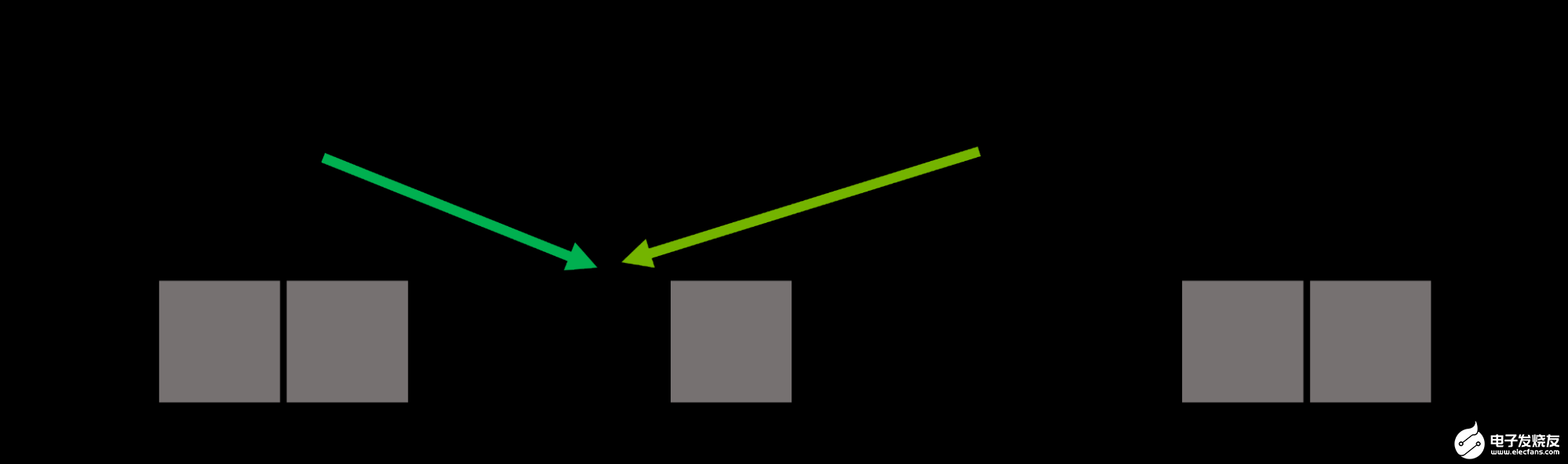 圖 1 。兩個不同的鍵, Alice 和 Bob ,具有相同的哈希值,導致桶 4 處的哈希沖突
圖 1 。兩個不同的鍵, Alice 和 Bob ,具有相同的哈希值,導致桶 4 處的哈希沖突
打開尋址
在文獻中可以找到許多解決哈希沖突的策略,但本文重點介紹了一種名為 open addressing with linear probing 的策略。
開放尋址哈希表使用內存中的連續存儲桶數組。使用線性探測,如果在位置 i, 處遇到已占用的鏟斗,則移動到下一個相鄰位置 i+1 。如果這個桶也被占用了,你就轉到 i+2, ,依此類推。當你到達最后一個桶時,你就繞回到開頭。這個所謂的 probing scheme 對于每個密鑰都是確定性的(圖 2 )。
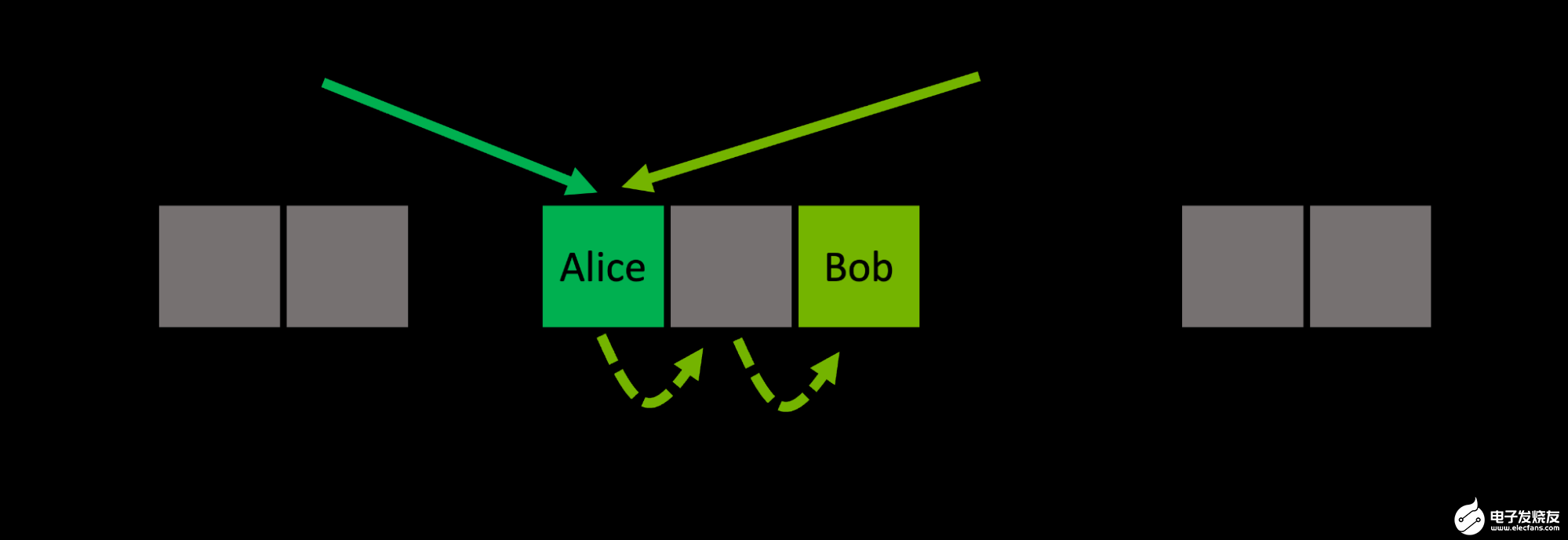 圖 2 :開放尋址通過探測方案在不同位置存儲沖突條目,探測方案以確定性順序遍歷一系列備選存儲桶
圖 2 :開放尋址通過探測方案在不同位置存儲沖突條目,探測方案以確定性順序遍歷一系列備選存儲桶
這種方法具有緩存效率,因為它訪問內存中的連續位置。如果 負載因子(已填充的存儲桶與總存儲桶的比率)較高,則可能會導致性能下降,因為這會導致額外的內存讀取。
從地圖中檢索關鍵字 Bob 的工作方式相同:從位置 hash(Bob)=4 開始遵循關鍵字的探測順序,直到在位置 6 找到所需的桶。如果在給定鍵的探測序列中的任何一點上遇到空桶,則知道所查詢的鍵不在映射中。
隨機存儲器訪問
精心設計的哈希函數通過最大化哈希任意兩個鍵將導致不同哈希值的可能性來最小化沖突次數。這意味著對于任何給定的兩個鍵,它們對應的桶可能位于不同的內存位置。
因此,大多數哈希表操作的內存訪問模式實際上是隨機的。為了理解哈希表的性能,了解隨機內存訪問的性能非常重要。
表 1 比較了理論峰值帶寬與在現代 GPU s 和 GPU s 上通過 GUPS benchmark 測量的隨機 64 位讀取的實現帶寬。
| Chip (memory) | Theoretical peak bandwidth (GB/s) | Measured random 64-bit read bandwidth (GB/s) |
| Intel Xeon Platinum 8360Y (DDR4-3200, 8 channels) | 204 | 15 |
| NVIDIA A100-80GB-SXM (HBM2e) | 2039 | 141 |
| NVIDIA H100-80GB-SXM (HBM3) | 3352 | 256 |
表 1 . 帶寬計算為訪問大小乘以訪問次數除以時間
如果您有興趣在系統上運行 GUPS GPU 基準測試,請參閱 NVIDIA developer blog code samples GitHub 存儲庫。您可以訪問 ParRes/Kernels GitHub 存儲庫中的 CPU 代碼。
如您所見,隨機內存訪問大約比理論峰值帶寬慢 10 倍。這是因為內存子系統針對順序訪問進行了優化。更重要的是, NVIDIA GPU s 的隨機訪問吞吐量比現代 CPU s 的高一個數量級。這些結果表明,性能最好的 CPU 哈希表可能比性能最好的 GPU 哈希表慢一個數量級。
GPU 哈希圖實現
隨機內存訪問在哈希表實現中是不可避免的, GPU 在隨機訪問方面優于 CPU 。這很有希望,因為它暗示 GPU 應該擅長哈希表操作。為了測試這一理論,本節討論 GPU 哈希表的實現和優化,并將性能與 CPU 實現進行比較。
目標不是開發一個標準 C ++容器(如std::unordered_map)的替代品,而是專注于實現一個哈希表,該哈希表適用于 GPU 加速應用程序中出現的大規模并行、高吞吐量問題。
本示例使用以下簡化假設:
表的容量是固定的,不能添加超出初始容量的其他鍵值對
需要將其中一個可能的鍵值設置為哨兵值,以指示空桶
鍵和值類型的大小之和必須小于或等于 8 個字節
插入后不能刪除鍵值對
請注意,這些不是基本的限制,可以通過 cuCollections 庫中提供的更高級的實現來克服。
首先,示例哈希表使用開放尋址,由一組桶組成。每個存儲桶可以保存一個鍵 – 值對,并使用鍵/值標記進行初始化,以表示當前為空。對于沖突解決,使用線性探測 。
GPU 加速哈希表需要支持來自多個線程的并發更新,例如,如果兩個線程試圖在同一位置插入,則需要采取步驟避免數據競爭。為了避免昂貴的鎖定,示例哈希表通過 cuda::std::atomic 其中每個鏟斗定義為cuda::std::atomic>。
為了插入新的密鑰,實現根據其哈希值計算第一個存儲桶,并執行原子比較和交換操作,期望存儲桶中的密鑰等于empty_sentinel。如果是,則插槽為空,插入成功。否則,它前進到下一個桶,直到最終找到一個空桶。
下面的代碼顯示了哈希表插入函數的簡化版本。
__device__ bool insert(Key k, Value v) {
// get initial probing position from the hash value of the key
auto i = hash(k) % capacity;
while (true) {
// load the content of the bucket at the current probe position
auto [old_k, old_v] = buckets[i].load(memory_order_relaxed);
// if the bucket is empty we can attempt to insert the pair
if (old_k == empty_sentinel) {
// try to atomically replace the current content of the bucket with the input pair
bool success = buckets[i].compare_exchange_strong(
{old_k, old_v}, {k,v}, memory_order_relaxed);
if (success) {
// store was successful
return true;
}
} else if (old_k == k) {
// input key is already present in the map
return false;
}
// if the bucket was already occupied move to the next (linear) probing position
// using the modulo operator to wrap back around to the beginning if we
// go beyond the capacity
i = ++i % capacity;
}
}
在映射中查找特定鍵的關聯值的方式類似。沿鑰匙探測順序檢查每個位置,直到找到包含所需鑰匙的存儲桶或空存儲桶,表明鑰匙無法駐留在表中。
合作團體
最初,為每個輸入元素分配一個工作線程似乎是一個合理的比率。但是,請考慮以下事項:
輸入中的相鄰鍵與其在存儲器中的相關探測位置之間沒有關系。這意味著扭曲中的每個線程都可能訪問哈希圖的完全不同的區域。在最壞的情況下,每個探測步驟需要從全局內存中的 32 個不同位置加載每個扭曲。(回想隨機內存訪問。)
利用線性探測,每個線程可以從其初始探測位置開始訪問多個相鄰桶。這種本地訪問模式將允許使用單個聯合負載預取多個探測位置,不幸的是,這無法通過單個線程實現。
我們能做得更好嗎?對 CUDA cooperative groups 模型可以輕松地重新配置工作分配的粒度。每個輸入元素不使用單個 CUDA 線程,而是將一個元素分配給同一經線內的一組連續線程。
對于給定的輸入鍵,不是按順序遍歷其關聯的探測序列,而是用單個合并負載預取多個相鄰桶的窗口。然后,該組使用有效的ballot和shuffle內部函數協同確定窗口內的候選桶。
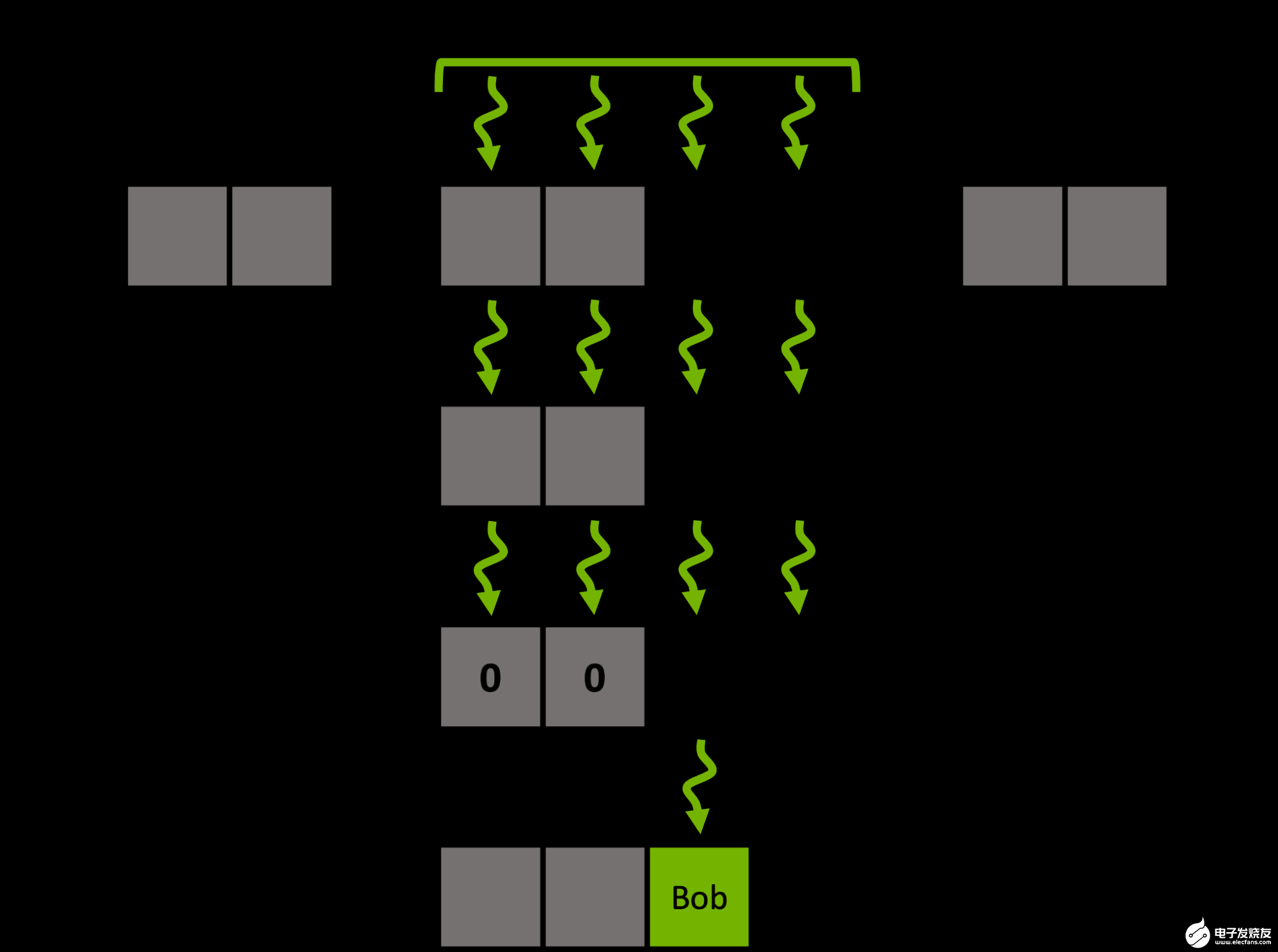 圖 3 。密鑰 Bob 的組協作探測步驟及其中間步驟
圖 3 。密鑰 Bob 的組協作探測步驟及其中間步驟
下面的代碼擴展了之前引入的 insert 函數,以使用扭曲中的四個連續線程協同插入一個鍵。cg::thread_block_tile<4>表示子 rp 中的四個線程。
enum class probing_state { SUCCESS, DUPLICATE, CONTINUE };
__device__ bool insert(cg::thread_block_tile<4> group, Key k, Value v) {
// get initial probing position from the hash value of the key
auto i = (hash(k) + group.thread_rank()) % capacity;
auto state = probing_state::CONTINUE;
while (true) {
// load the contents of the bucket at the current probe position of each rank in a coalesced manner
auto [old_k, old_v] = buckets[i].load(memory_order_relaxed);
// input key is already present in the map
if(group.any(old_k == k)) return false;
// each rank checks if its current bucket is empty, i.e., a candidate bucket for insertion
auto const empty_mask = group.ballot(old_k == empty_sentinel);
// it there is an empty buckets in the group's current probing window
if(empty_mask) {
// elect a candidate rank (here: thread with lowest rank in mask)
auto const candidate = __ffs(empty_mask) - 1;
if(group.thread_rank() == candidate) {
// attempt atomically swapping the input pair into the bucket
bool const success = buckets[i].compare_exchange_strong(
{old_k, old_v}, {k, v}, memory_order_relaxed);
if (success) {
// insertion went successful
state = probing_state::SUCCESS;
} else if (old_k == k) {
// else, re-check if a duplicate key has been inserted at the current probing position
state = probing_state::DUPLICATE;
}
}
// broadcast the insertion result from the candidate rank to all other ranks
auto const candidate_state = group.shfl(state, candidate);
if(candidate_state == probing_state::SUCCESS) return true;
if(candidate_state == probing_state::DUPLICATE) return false;
} else {
// else, move to the next (linear) probing window
i = (i + group.size()) % capacity;
}
}
}
哈希表插入函數的前面的代碼示例是 cuCollections cuco::static_map的實際實現的簡化版本。
圖 4 顯示了在 NVIDIA A100 80 GB GPU 上測量的不同組大小和表占用率的非協作和協作探測方法的性能,沒有具體化。
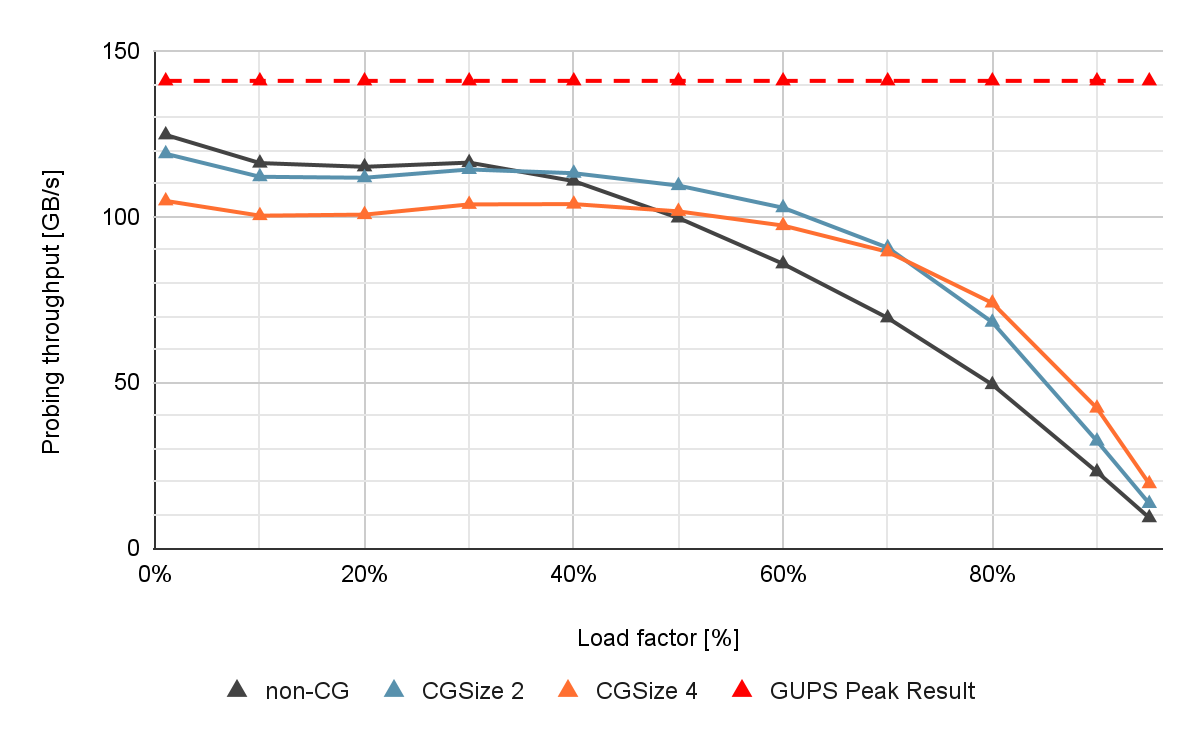 圖 4 。通過協作探測,吞吐量以 GB / s 為單位(越高越好)。紅色虛線顯示了峰值 GUPS 結果,它提供了在該系統上可以實現的吞吐量上限。
圖 4 。通過協作探測,吞吐量以 GB / s 為單位(越高越好)。紅色虛線顯示了峰值 GUPS 結果,它提供了在該系統上可以實現的吞吐量上限。
如果負載系數較低,則非合作(非 CG )表現出接近最佳性能。然而,如果負載因子增加,則吞吐量會由于沖突次數增加和探測序列較長而急劇下降。這是有問題的,因為較高的表加載系數對應于更好的內存利用率。
協作探測提高了此類高負載因數場景的性能。與非合作方法相比,當負載系數較高時,如果組大小為 4 ,可以觀察到插入吞吐量高出 13% ,查找吞吐量高出 40% 。
長探測序列也出現在具有高密鑰乘數的多值場景中,因為相同的密鑰遍歷相同的桶序列。合作探測也有助于加快這些場景。
有關組協作哈希表探測的更多信息,請參見 Parallel Hashing on Multi-GPU Nodes 和 WarpCore: A Library for Fast Hash Tables on GPUs 。
現有 CPU 和 GPU 哈希圖比較
多年來,已經提出了多種 C ++哈希圖實現。其中最流行的是libstdc++/libc++ std::unordered_ map 和 Abseil absl::flat_hash_map。這些是順序實現,從多個線程使用它們需要額外的同步。
TBB 中的tbb::concurrent_hash_map和 Folly 中的folly::AtomicHashMap是并發多線程 CPU 數據結構的示例。 GPU s 中可用的少數實現之一是 Kokkos 庫中的kokkos::UnorderedMap。
將上面提供的映射實現的性能與 cuCollection cuco::static_map進行比較。基準設置如下。
首先,插入 227( 1GB )唯一的 4 字節密鑰/ 4 字節值對,然后查詢同一組密鑰以檢索它們的相關值。每次運行的目標工作臺負載系數為 50% 。性能以內存吞吐量衡量(每秒 GB ;越高越好)。
結果如圖 5 所示。cuco::static_map在單個 NVIDIA H100-80GB-SXM 上實現了 87.5 GB / s 的插入吞吐量和 134.6 GB / s 的查找吞吐量,這意味著與最快的 CPU 單線程和多線程實現相比,速度提高了超過數量級。此外, cuCollections 在本測試中的性能優于其他 GPU 實現kokkos::UnorderedMap,插入的性能為 3.8 倍,查找的性能為 2.6 倍。
請注意,在這個基準設置中,對于 CPU 側的實現,每個操作的 I / O 向量都駐留在 CPU memory 中,而對于 GPU 側的實施,則駐留在 GPU memory 中。如果數據向量需要駐留在 GPU 哈希映射的 CPU 存儲器中,這將要求首先將輸入數據移動到 GPU ,然后將結果移回 CPU 存儲器。
這可以通過顯式(異步批處理)復制或使用 CUDA 的 unified memory 概念自動頁面遷移來實現。結果表明,我們實現的吞吐量始終遠遠高于 H100 上 PCIe Gen4 甚至 PCIe Gen5 的實際可用帶寬。這意味著該方法能夠使 CPU 和 GPU 之間的鏈路完全飽和。
換句話說,即使數據不在 GPU 內存中, cuCollections 也能以系統 PCIe 帶寬的速度構建和查詢哈希表。此外,由于 GPU 和 GPU 之間的快速 NVLink-C2C 互連, NVIDIA Grace Hopper Superchip 可以提供額外的加速,釋放哈希表的全部吞吐量。相比之下, CPU 哈希映射通常實現比 PCIe 低得多的吞吐量。
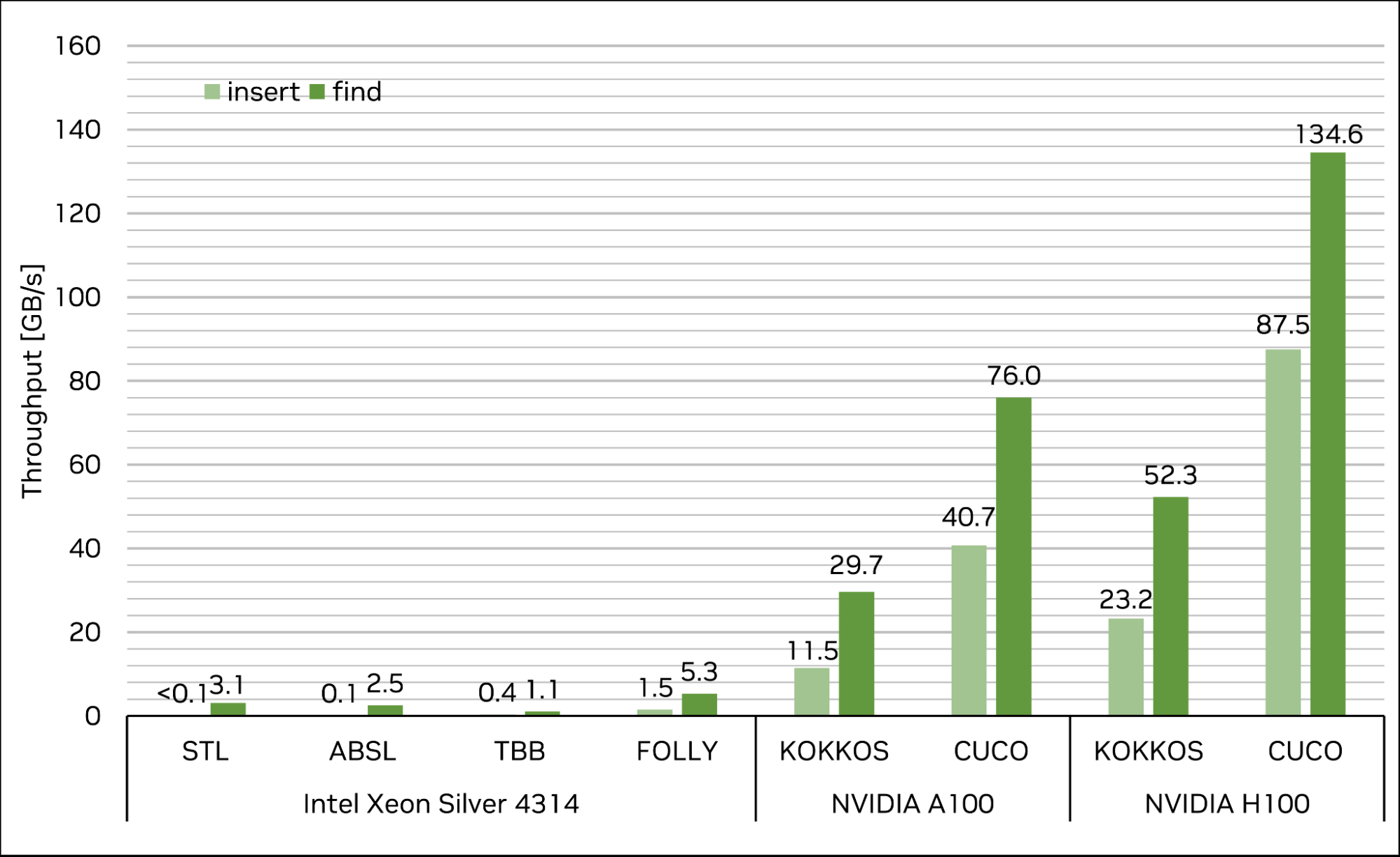 圖 5 。流行 CPU 和 GPU 哈希圖實現的性能比較
圖 5 。流行 CPU 和 GPU 哈希圖實現的性能比較
多列關系聯接示例
本節以 GPU 哈希表如何用于實現復雜算法的真實示例為特色。
cuDF 是用于數據分析的 GPU 加速庫。它為數據操作(如加載、連接和聚合)提供原語。通過利用 cuCollections 哈希表,它使用哈希連接算法來執行連接操作。
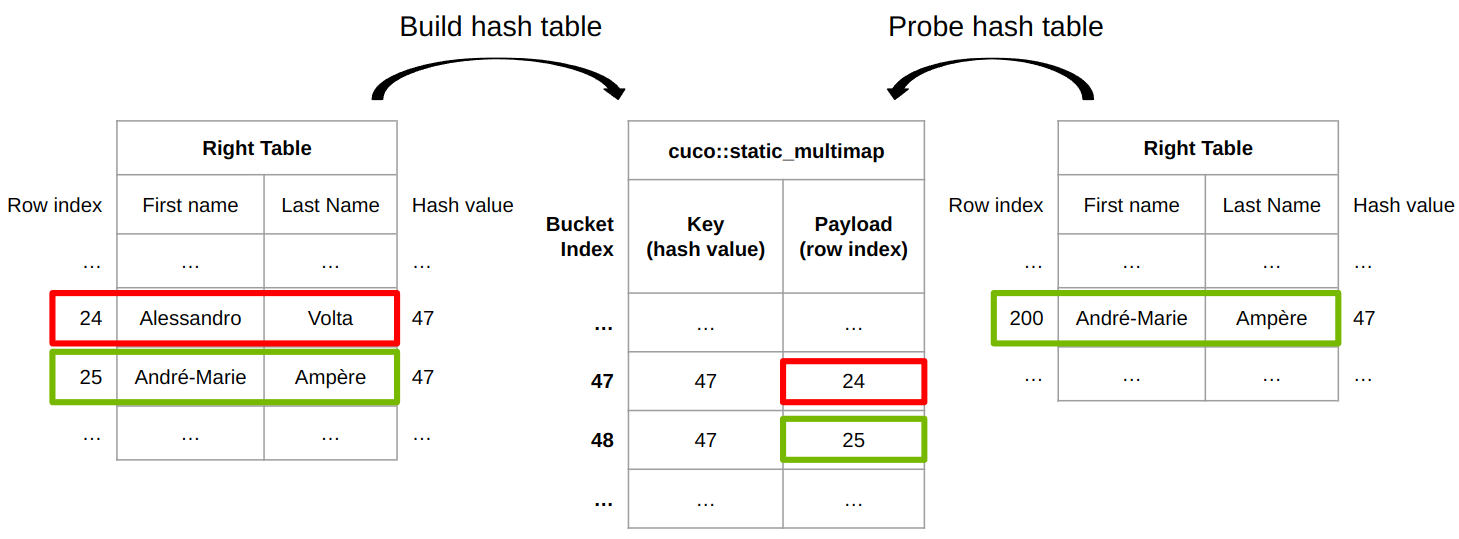 圖 6 。 RAPID cuDF 中內部連接實現的構建和探測階段
圖 6 。 RAPID cuDF 中內部連接實現的構建和探測階段
圖 6 顯示了 cuDF 連接實現如何為內部連接工作。 cuDF 提供了一個內置的哈希函數,用于將任意類型的行哈希為哈希值。不同的行可以具有相同的哈希值,因此需要行相等性檢查來確定兩行是否真正相同。
左側的表格用于填充 cuco::static_multimap 其中鍵是行的哈希值,有效載荷是關聯的行索引。行 24 插在鏟斗 47 上,行 25 插在鏟斗 48 上。在探測階段,右表中的行 200 的哈希值為 47 ,這與哈希表中的桶 47 的哈希值(或相同密鑰)相同。
為了最終確定兩行是否相等,將右側表中的{ Andr é -Marie , Amp è re }的行索引 200 與左側表中的{ Alessandro , Volta }的行索引 24 傳遞給行相等函數 row_equal(200, 24) 。
最后,這兩行并不相同,因此左側表的第 24 行不匹配。最后,左表的第 25 行與右表的第 200 行匹配,因為哈希值相同,并且行相等性檢查( row_equal(200, 25) )也通過。
基準連接操作是一個復雜的主題,因為有許多大小、選擇性等選項。有關詳細信息,請參見 How to Get the Most out of GPU Accelerated Database Operators 和 Effective, Scalable Multi-GPU Joins 。
如何在代碼中使用 GPU 哈希圖
GPU s 非常適合于哈希圖等并發數據結構。這一切都是從高帶寬存儲器架構開始的,對于許多小的隨機讀取和原子更新,該架構比 CPU 快一個數量級。這直接轉化為 GPU 上高效的哈希表插入和探測性能。
這篇文章介紹了設計大規模并行哈希圖時的幾個重要考慮事項: 1 )具有開放尋址的哈希桶的平面內存布局,以解決沖突。作為 cuCollections 庫的一部分,您可以在 GitHub 上找到快速靈活的哈希圖實現。
-
NVIDIA
+關注
關注
14文章
4793瀏覽量
102423 -
gpu
+關注
關注
27文章
4590瀏覽量
128133 -
AI
+關注
關注
87文章
28875瀏覽量
266193
發布評論請先 登錄
相關推薦
Veloce平臺在大規模SOC仿真驗證中的應用
大規模集成電路在信息系統中的廣泛應用
探討采用C6000系列多核DSP的并行計算(OpenCL、OpenMP)實現大規模電磁系統的暫態仿真及其控制系統
大規模MIMO的利弊
大規模MIMO的性能
回收Agilent/Keysight86115D大規模/并行光收發信機測試模塊
基于大規模序列比對軟件的并行優化方案
基于分段哈希碼的倒排索引樹結構
在并行測量系統中使用ADS1244和ADS1245設備時的幾個重要注意事項





 工商網監
工商網監
評論