 如何部署ML模型到Google云平臺
如何部署ML模型到Google云平臺
本系列介紹 開發和部署 ( M L ) 模型。在本文中, 你將學習如何部署 ML 模型到 Google 云平臺. 第 1 部分給出了 ML 工作流概括 ,考慮了使用機器學習和數據科學來實現商業價值所涉及的各個階段。在第 2 部分中,您將學習訓練并保存 ML 模型并將其部署為 ML 系統的一部分。
在為 ML 系統構建端到端管道時,最后一步是將經過訓練的模型部署到生產環境中。成功的部署意味著 ML 模型已從研究環境中移出并集成到生產環境中,例如,作為一個實時應用程序。
在本文中,您將學習使用 Google 云平臺( GCP )將 ML 模型投入生產的三種方法。雖然您可以使用其他幾種環境,例如 AWS 、 Microsoft Azure 或本地硬件,但本教程使用 GCP 部署 web 服務。
正在設置
通過您的 Google 帳戶注冊 Google Cloud Platform 。系統會提示您填寫一些信息,包括您的信用卡詳細信息。但是,您注冊該平臺將不收取任何費用。您還可以在前 90 天獲得價值 300 美元的免費信貸。
創建帳戶后, 創建新的項目并將其命名為 GCP-deployment-example 。不要將項目鏈接到組織。
確保已將當前項目更改為新創建的項目。
在 Google App Engine 上部署 ML 模型
在您可以在 GoogleAppEngine 上部署模型之前,還有一些額外的模塊要添加到代碼中。
本節中使用的代碼可以在 /kurtispykes/gcp-deployment-example GitHub repo 中找到。
第一步是在predict.py模塊中創建推理邏輯:
import joblib import pandas as pd model = joblib.load("logistic_regression_v1.pkl") def make_prediction(inputs): """ Make a prediction using the trained model """ inputs_df = pd.DataFrame( inputs, columns=["sepal_length_cm", "sepal_width_cm", "petal_length_cm", "petal_width_cm"] ) predictions = model.predict(inputs_df) return predictions
本模塊中的步驟包括:
將持久化模型加載到內存中。
創建一個將一些輸入作為參數的函數。
在函數中,將輸入轉換為 pandas DataFrame并進行預測。
接下來,推理邏輯必須封裝在 web 服務中。我用 Flask 包裝模型。有關詳細信息,請參閱main.py:
import numpy as np from flask import Flask, request from predict import make_prediction app = Flask(__name__) @app.route("/", methods=["GET"]) def index(): """Basic HTML response.""" body = ( "" "" "
Welcome to my Flask API
" "" "" ) return body @app.route("/predict", methods=["POST"]) def predict(): data_json = request.get_json() sepal_length_cm = data_json["sepal_length_cm"] sepal_width_cm = data_json["sepal_width_cm"] petal_length_cm = data_json["petal_length_cm"] petal_width_cm = data_json["petal_width_cm"] data = np.array([[sepal_length_cm, sepal_width_cm, petal_length_cm, petal_width_cm]]) predictions = make_prediction(data) return str(predictions) if __name__ == "__main__": app.run()
在代碼示例中,您創建了兩個端點:
index:可以看作是主頁
/predict:用于與部署的模型交互。
您必須創建的最后一個文件是 app.yaml ,其中包含用于運行應用程序的運行時。
runtime: python38
在 Google Cloud 控制臺中,執行以下步驟:
在切換菜單上,選擇 App Engine 。您可能必須選擇 View all products 才能訪問 App Engine ,它與 Serverless 產品一起列出)。
從 App Engine 頁面,選擇 Create Application 。
選擇要在其中創建應用程序的區域。
將應用程序語言設置為 Python 并使用 Standard 環境。
在右上角,選擇終端圖標。這將激活云外殼,這意味著您不必下載云 SDK 。
在部署應用程序之前,必須上載所有代碼。由于通過 web 服務與 ML 模型交互所需的所有代碼都上傳到 gcp-deployment-example/app_engine/ 中的 GitHub 上,因此您可以從云外殼中克隆此存儲庫。
將代碼 URL 復制到剪貼板并導航回 GCP 上的云外殼。向 shell 輸入以下命令:
git clone https://github.com/kurtispykes/gcp-deployment-example.git
通過輸入以下命令導航到代碼存儲庫:
cd gcp-deployment-example/app_engine
接下來, initialize the application 。確保您選擇了最近創建的項目。
現在,部署應用程序。從云 shell 運行以下命令。如果系統提示您繼續,請輸入Y。
gcloud app deploy
部署完成后,您將獲得服務部署位置的 URL 。打開提供的 URL 以驗證應用程序是否正常運行。您應該看到 歡迎使用我的 Flask API 消息。
接下來,測試/predict端點。
使用 Postman 發送 POST 請求以測試成功部署
您可以使用 Postman 向/predict端點發送 POST 請求。 Postman 是開發人員設計、構建、測試和迭代 API 的 API 平臺。
要開始,請選擇 免費注冊 。有一個完整的教程,但為了本篇文章的目的,請直接跳到主頁。
從那里,選擇 Workspaces 、 My Workspace 、 New ,然后選擇 HTTP Request 。
接下來,將 HTTP 請求從GET更改為POST,并在請求 URL 中插入到已部署服務的鏈接。
之后,導航到Body標頭并選擇raw,以便插入示例實例。選擇send。
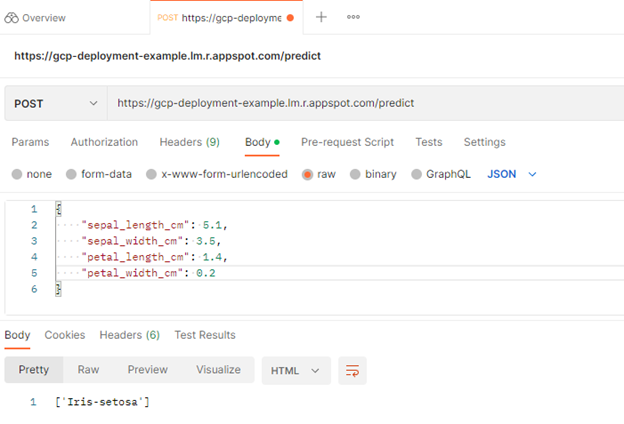 圖 1 。 Postman 測試的預測終點
圖 1 。 Postman 測試的預測終點
您向/predict端點發送了 POST 請求,其中包含一些定義模型輸入的原始數據。在響應中,模型返回[‘Iris-setosa’],這是模型成功部署的積極指示。
您還可以使用 GCP 上提供的其他服務部署模型。
在 Google 云功能上部署 ML 模型
云功能是 GCP 上可用的無服務器技術之一。我對代碼做了一些更改,以使部署到云功能無縫。第一個也是最明顯的區別是不再從本地存儲庫導入序列化模型。相反,您正在調用 Google 云存儲中的模型。
將模型上傳到 Google 云存儲
在 GCP 部署示例項目中,選擇切換菜單。導航到 Cloud Storage 并選擇 Buckets 、 Create Bucket 。這將提示您為存儲桶和其他配置提供名稱。我把我的名字命名為model-data-iris。
創建桶后,下一個任務是上傳持久化模型。選擇 Upload Files ,導航到存儲模型的位置,然后選擇它。
現在,您可以使用 Google Cloud 中的各種服務來訪問此文件。要訪問云存儲,必須從google.cloud導入storage對象。
下面的代碼示例顯示了如何從 Google 云存儲中訪問模型。您也可以在 gcp-deployment-example/cloud_functions/main.py 中看到完整的示例。
import joblib
import numpy as np
from flask import request
from google.cloud import storage
storage_client = storage.Client()
bucket = storage_client.get_bucket("model-iris-data") # remember to change the bucket name
blob = bucket.blob("logistic_regression_v1.pkl")
blob.download_to_filename("/tmp/logistic_regression_v1.pkl")
model = joblib.load("/tmp/logistic_regression_v1.pkl")
def predict(request):
data_json = request.get_json()
sepal_length_cm = data_json["sepal_length_cm"]
sepal_width_cm = data_json["sepal_width_cm"]
petal_length_cm = data_json["petal_length_cm"]
petal_width_cm = data_json["petal_width_cm"]
data = np.array([[sepal_length_cm, sepal_width_cm, petal_length_cm, petal_width_cm]])
predictions = model.predict(data)
return str(predictions)
在 Google Cloud 控制臺的切換菜單上,選擇 Cloud Functions 。要查看菜單,您可能必須選擇 View all products 并展開 Serverless 類別。
接下來,選擇 Create Function 。如果這是您第一次創建云函數,則要求您啟用 API 。選擇 Enable 繼續。
還要求您進行以下配置設置:
函數名稱= Predict 。
Trigger type = HTTP 。
Allow unauthenticated invocations =已啟用。
在運行時、構建、連接和安全設置部分中還有其他配置,但對于本示例,默認值是可以的,因此選擇 Next 。
在下一頁中,要求您設置運行時并定義源代碼的來源。在 Runtime 部分,選擇您正在使用的 Python 版本。我使用的是 Python 3.8 。確保在源代碼頭中選擇了 Inline Editor 。
復制并粘貼云函數用作main.py文件入口點的以下代碼示例。
{
"sepal_length_cm" : 5.1,
"sepal_width_cm" : 3.5,
"petal_length_cm" : 1.4,
"petal_width_cm" : 0.2
}
使用內聯編輯器更新 requirements.txt :
flask >= 2.2.2, <2.3.0 numpy >= 1.23.3, <1.24.0 scitkit-learn >=1.1.2, <1.2.0 google-cloud-storage >=2.5.0, <2.6.0
確保將 Entry point 值更改為端點的名稱。在這種情況下,它是predict。
完成所有更改后,選擇 Deploy 。部署可能需要幾分鐘的時間來安裝依賴項并啟動應用程序。完成后,您會看到成功部署的模型的函數名稱旁邊有一個綠色的勾號圖標。
現在,您可以在 Testing 選項卡上測試應用程序是否正常工作。使用以下示例代碼進行測試:
{
"sepal_length_cm" : 5.1,
"sepal_width_cm" : 3.5,
"petal_length_cm" : 1.4,
"petal_width_cm" : 0.2
}
如果您使用與前面相同的輸入,則會得到相同的響應。
現在,您已經學會了使用 GoogleCloudFunctions 部署 ML 模型。使用此部署,您不必擔心服務器管理。您的云功能僅在收到請求時執行,并且 Google 管理服務器。
在 Google AI 云上部署 ML 模型
之前的兩個部署要求您編寫不同程度的代碼。在谷歌人工智能云上,你可以提供經過訓練的模型,他們為你管理一切。
在云控制臺上,從切換菜單導航到 AI Platform 。在 Models 選項卡上,選擇 Create Model 。
您可能會注意到一條警告消息,通知您 Vertex AI ,這是另一個將 AutoML 和 AI 平臺結合在一起的托管 AI 服務。這一討論超出了本文的范圍。
在下一個屏幕上,系統會提示您選擇一個區域。選擇區域后,選擇 Create Model 。為模型命名,相應地調整區域,然后選擇 Create 。
轉到創建模型的區域,您應該可以看到模型。選擇型號并選擇 Create a Version 。
接下來,您必須將模型鏈接到云存儲中存儲的模型。本節有幾個重要事項需要注意:
AI 平臺上scikit-learn的最新模型框架版本是 1.0.1 版,因此您必須使用此版本來構建模型。
模型必須存儲為model.pkl或model.joblib。
為了遵守 GCP AI 平臺的要求,我使用所需的模型版本創建了一個新的腳本,將模型序列化為model.pkl,并將其上傳到谷歌云存儲。有關更多信息,請參閱 /kurtispykes/gcp-deployment-example GitHub repo 中的更新代碼。
Model name: logistic_regression_model
選中 Use regional endpoint 復選框。
Region: 歐洲西部 2
在 models 部分,確保僅選擇 europe-west2 區域。
為要創建的模型版本選擇 Save 。創建模型版本可能需要幾分鐘的時間。
通過選擇模型版本并導航到 Test & Use 標題來測試模型。輸入輸入數據并選擇 Test 。
-
Google
+關注
關注
5文章
1757瀏覽量
57413 -
NVIDIA
+關注
關注
14文章
4935瀏覽量
102810 -
AI
+關注
關注
87文章
30106瀏覽量
268401
發布評論請先 登錄
相關推薦
使用CUBEAI部署tflite模型到STM32F0中,模型創建失敗怎么解決?
什么是云計算 云計算的定義
簡化針對云服務的語音檢測算法的部署
通過Cortex來非常方便的部署PyTorch模型
如何將ML模型部署到微控制器?
如何使用TensorFlow將神經網絡模型部署到移動或嵌入式設備上
ARIZEAI,第一個進入市場的ML觀測平臺
如何在移動設備上訓練和部署自定義目標檢測模型
ML-EXray:云到邊緣部署驗證框架
如何將pytorch的模型部署到c++平臺上的模型流程
Hugging Face LLM部署大語言模型到亞馬遜云科技Amazon SageMaker推理示例






 工商網監
工商網監
評論