 機器學習構建ML模型實踐
機器學習構建ML模型實踐
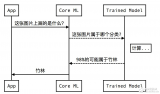
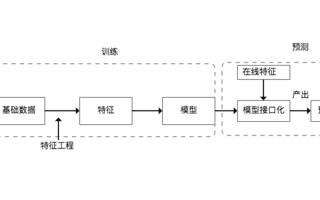
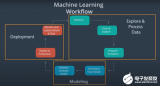
本系列介紹 開發和部署 ( M L ) 模型。在這篇文章中,您 訓練并保存 ML 模型,因此它可以作為 ML 系統的一部分部署。 第 1 部分給出了一個 ML 工作流概括 ,考慮了使用機器學習和數據科學實現商業價值所涉及的各個階段。第 3 部分介紹 如何部署 ML 模型到 Google 云平臺( GCP )。
培訓一個可以作為機器學習系統一部分的模型需要了解您的數據、業務目標以及許多其他技術和組織要求。
在本文中,您創建了一個 Python 腳本,當執行該腳本時,它訓練一個 ML 模型,然后將其保存以供將來使用。
首先,我強調了為應用程序訓練 ML 模型時的一些重要考慮事項。
培訓模型前的注意事項
從模型選擇到數據集的復雜性和大小,數據從業者必須戰略性地規劃資源和期望的需求。在培訓模型之前要考慮的因素包括:
型號的選擇
解釋能力
模型超參數
硬件的選擇
數據大小
型號的選擇
您可以使用許多類 ML 模型來解決問題。您選擇的模型取決于您的用例和可能的約束。
解釋能力
如果要將您的模型部署為在受監管行業(如金融或醫療保健)中運行的系統的一部分,則您的模型可能是 explainable 。這意味著,對于模型做出的任何預測,都可以說明模型做出該決定的原因。
在這種情況下,您可能希望使用易于解釋的 linear regression 或 logistic regression 等模型。
模型超參數
模型具有可調超參數。了解這些超參數對應于什么以及它們如何影響模型非常重要。
根據超參數的選擇,模型的性能可能會發生很大變化。
硬件的選擇
大多數數據從業者都知道,模型訓練通常可以在 GPU 上加速。但即使在您進入模型訓練階段之前, GPU 也可以極大地幫助您的數據科學工作流。
從預處理管道到數據探索和可視化,一切都可以加快。這有助于您更快地迭代并嘗試更昂貴的計算技術。
數據大小
當處理比一個內核或機器上的內存更大的數據時,重要的是要考慮充分利用所有數據的技術。
也許使用 RAPID 等工具轉移到 GPU 來加速 pandas 和 scikit-learn 風格的工作流是有意義的。或者你可能想研究一個擴展框架,比如 Dask ,它可以擴展模型訓練和數據處理,無論你是在 CPU 還是 GPU 上工作。
了解數據集
在本文中,您在一個經典數據集上訓練一個模型: UCI Machine Learning Repository 中的 Iris Dataset 。這個數據集包含 150 朵鳶尾花的花瓣長度和寬度以及萼片長度和寬度的記錄。每個虹膜屬于三種類型之一: setosa 、 virginica 或 versicolor 。
你使用這些數據來訓練分類模型,目的是根據花瓣和萼片的尺寸來預測虹膜的類型。
CPU 培訓
在部署 ML 模型之前,必須首先構建一個 ML 模型。首先下載流行的 Iris Dataset 。本示例假設虹膜數據集已下載并保存為當前工作目錄中的iris.data。
要訓練邏輯回歸模型,請執行以下步驟:
閱讀培訓數據。
將訓練數據拆分為要素和標簽。
將數據分成訓練和測試集( 75% 是訓練數據, 25% 是測試數據)。
訓練 Logistic Regression 模型。
堅持訓練后的模型。
import joblib import pandas as pd from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split def run_training(): """ Train the model """ # Read the training data dataset = pd.read_csv( filepath_or_buffer="iris.data", names=["sepal_length_cm", "sepal_width_cm", "petal_length_cm", "petal_width_cm", "class"] ) # Split into labels and targets X = dataset.drop("class", axis=1).copy() y = dataset["class"].copy() # Create train and test set X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.25, random_state=26) # Training the model model = LogisticRegression(random_state=26) model.fit(X_train, y_train) # Persist the trained model joblib.dump(model, "logistic_regression_v1.pkl") if __name__ == "__main__": run_training()
train_test_split和LogisticRegression調用中的random_state參數有助于確保該腳本每次運行時都產生相同的結果。
運行腳本會生成一個保存在文件logistic_regression_v1.pkl中的模型,您可以使用該模型根據花瓣和萼片的尺寸對其他虹膜進行分類。
GPU 加速模型訓練
在本例中,您使用的是一個小數據集,僅包含 150 行數據。由于數據的簡單性,該模型在 CPU 上幾秒鐘就能訓練。
然而,在處理真實世界數據集時,模型訓練成為瓶頸并不罕見。在這種情況下,通常可以通過使用 GPU 而不是 CPU 來加快工作流的模型訓練階段。
例如, RAPIDS 提供了一套開源軟件工具,使數據科學家和工程師能夠在 GPU 上快速運行工作負載和數據科學管道。通過模仿常見數據科學庫(如pandas和scikit-learn)的 API ,您可以通過少量代碼更改來加快機器學習模型訓練(以及探索性數據科學)。
接下來是什么?
現在您已經有了一個經過培訓的模型,可以考慮將其部署到生產環境中。在下一篇文章 Machine Learning in Practice: Deploy an ML Model on Google Cloud Platform 中,您將學習在 GCP 上部署模型的三種方法。
-
NVIDIA
+關注
關注
14文章
4949瀏覽量
102826 -
AI
+關注
關注
87文章
30239瀏覽量
268475 -
機器學習
+關注
關注
66文章
8382瀏覽量
132444
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論