 Dijkstra算法和A*算法
Dijkstra算法和A*算法
在本文中,我們將主要介紹Dijkstra算法和A*算法,從成本計算的角度出發,并逐步展開討論。
我們將從廣度優先搜索開始,然后引入Dijkstra算法,與貪心算法進行比較,最終得出A*算法。
成本計算
在路徑規劃中,成本計算的一個主要因素是距離。距離可以作為一種衡量路徑長短的度量指標,通常使用歐幾里得距離、曼哈頓距離或其他合適的距離度量方法來計算。
本文主要介紹歐幾里得距離與曼哈頓距離。

廣度優先搜索
廣度優先搜索(Breadth First Search,BFS )是一種圖遍歷算法,按照廣度方向逐層遍歷所有可達節點。
BFS的基本思想是通過維護一個隊列,逐層訪問節點。
具體步驟如下:
1、將起始節點放入隊列中,并標記為已訪問。
2、當隊列非空時,執行以下步驟:
從隊列中取出一個節點,記為當前節點,并標記為已訪問。
如果該節點是目標節點,則返回結果。
將當前節點的所有未訪問過的鄰居節點放入隊列中。
3、如果隊列為空,則表示已經遍歷完所有可達節點,算法結束。
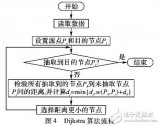
算法框圖
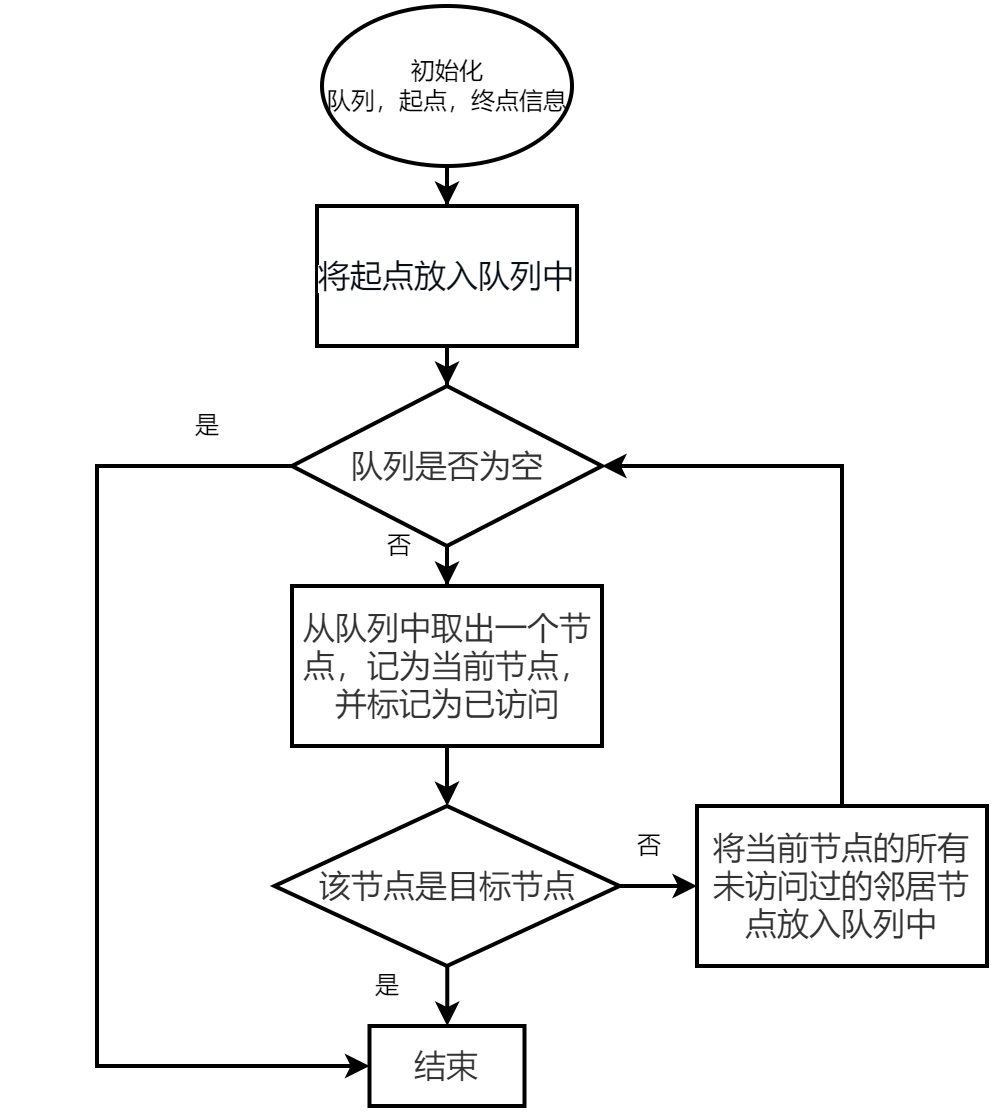
實現效果如下:
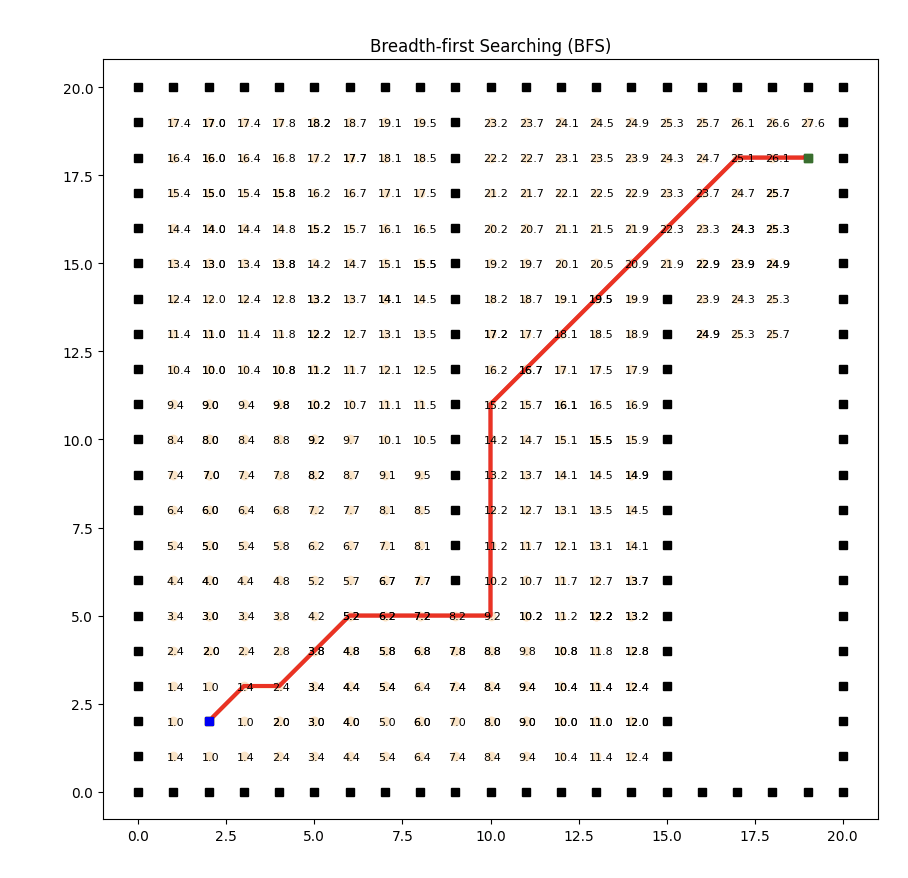
廣度優先搜索是一種基本的圖搜索算法,它按照圖的廣度方向逐層遍歷所有可達節點。然而,BFS并不考慮邊的權重,它只關注節點的層級關系。
因此,對于成本計算來說,BFS并不適用。這里為了實現到目標點的搜索,采用了曼哈頓距離計算初始點的行進成本。
代碼
def searching(self):
"""
Breadth-first Searching.
path, visited order
"""
self.PARENT[self.s_start] = self.s_start # 開始節點的父節點
self.g[self.s_start] = 0 # 開始節點的成本
self.g[self.s_goal] = math.inf # 目標節點的成本
# 統一成本搜索,起點的成本是0
heapq.heappush(self.OPEN,
(0, self.s_start))
while self.OPEN:
_, s = heapq.heappop(self.OPEN) # 彈出最小的元素,優先級較高
self.CLOSED.append(s) # 將節點加入被訪問元素隊列,已訪問
if s == self.s_goal: # 到達目標點,即停止
break
for s_n in self.get_neighbor(s): # 得到s的鄰居節點
new_cost = self.g[s] + self.cost(s, s_n)
# 計算當前鄰居節點s_n的成本=g(s)節點s的成本+s到s_n之間的成本
if s_n not in self.g: # 當前節點沒有訪問過
self.g[s_n] = math.inf # 起點到節點s_n的成本為無窮
if new_cost < self.g[s_n]: ?# conditions for updating Cost
? ? ? ? ? ? ? ? ? ? ? ?self.g[s_n] = new_cost
? ? ? ? ? ? ? ? ? ? ? ?self.PARENT[s_n] = s
? ? ? ? ? ? ? ? ? ? ? ?# bfs, add new node to the end of the openset
? ? ? ? ? ? ? ? ? ? ? ?# 將新的節點添加到隊列的末尾
? ? ? ? ? ? ? ? ? ? ? ?prior = self.OPEN[-1][0] + 1 if len(self.OPEN) > 0 else 0
heapq.heappush(self.OPEN, (prior, s_n))
self.f[s_n] = prior
return self.extract_path(self.PARENT), self.CLOSED, self.f
Dijkstra算法
迪杰斯特拉算法(Dijkstra)算法是一種單源最短路徑算法,用于在加權圖中找到從起點到所有其他節點的最短路徑。
它基于貪心策略,每次選擇當前距離起點最近的節點,并通過該節點更新與它相鄰的節點的距離。具體步驟如下:
1、初始化:初始化變量和數據結構,創建一個包含所有節點的集合,并為每個節點設置一個距離值。將起始節點的父節點設置為自身,將起始節點的距離值設置為0,其他節點的距離值設置為無窮大(表示尚未找到最短路徑)。將起始節點以成本0的優先級推入優先隊列OPEN中。
2、主循環:當OPEN非空時:
彈出優先級最小(成本最低)的節點(_, s),其中_為忽略的值,s為當前節點。
將當前節點s添加到CLOSED列表中,表示已訪問。
檢查當前節點是否為目標節點。如果是,則跳出循環。
對于當前節點的所有鄰居節點,計算通過當前節點到達鄰居節點的距離,并與鄰居節點的當前距離值進行比較。
如果計算得到的距離值小于鄰居節點的當前距離值,則更新鄰居節點的距離值為新的更小值并將鄰居節點s_n以新的成本作為優先級推入優先隊列OPEN中循環結束后,可以通過從目標節點回溯到起始節點,在PARENT字典中提取最短路徑。
3、循環結束后,可以通過從目標節點回溯到起始節點,在PARENT字典中提取最短路徑。
算法框圖
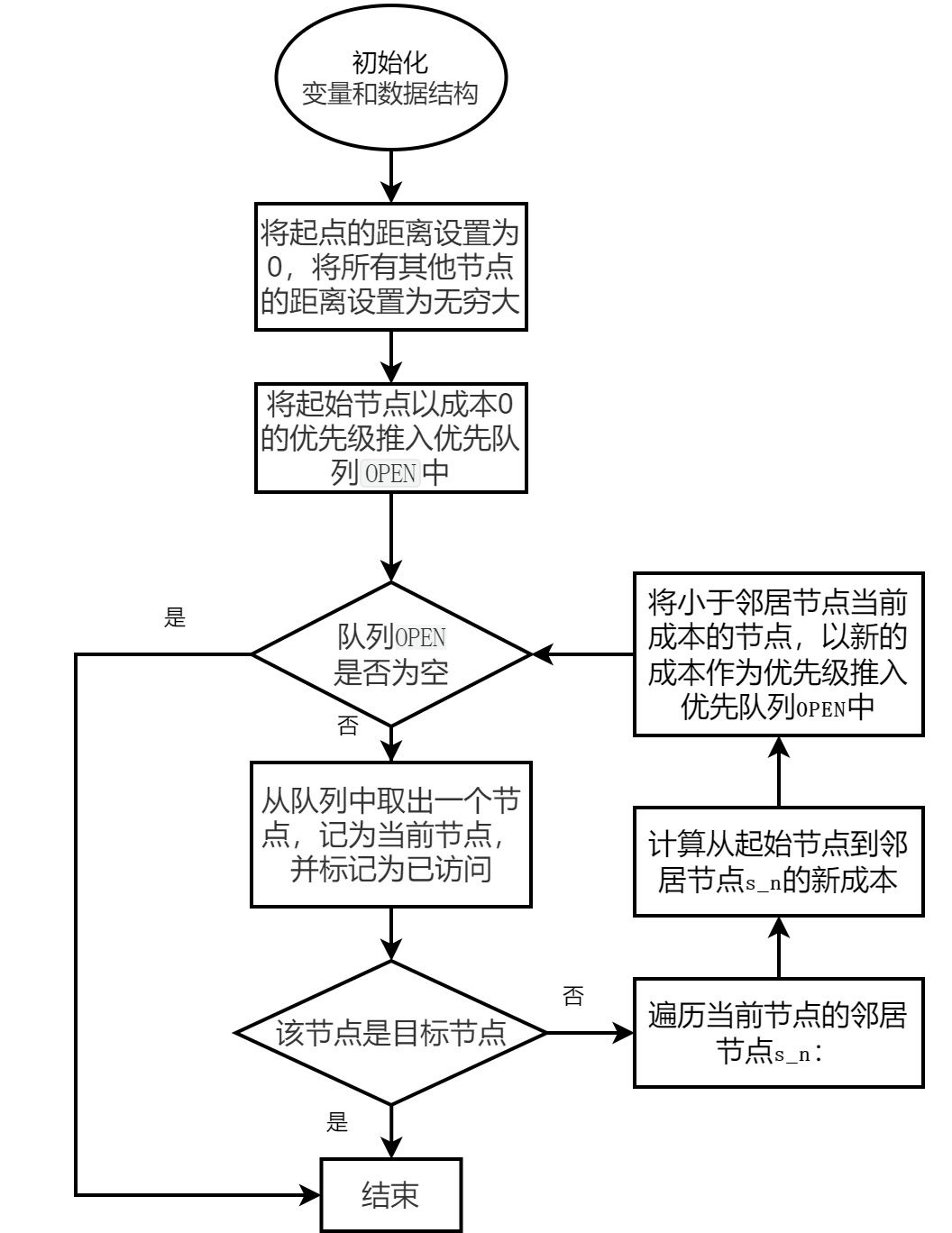
實現效果如下:
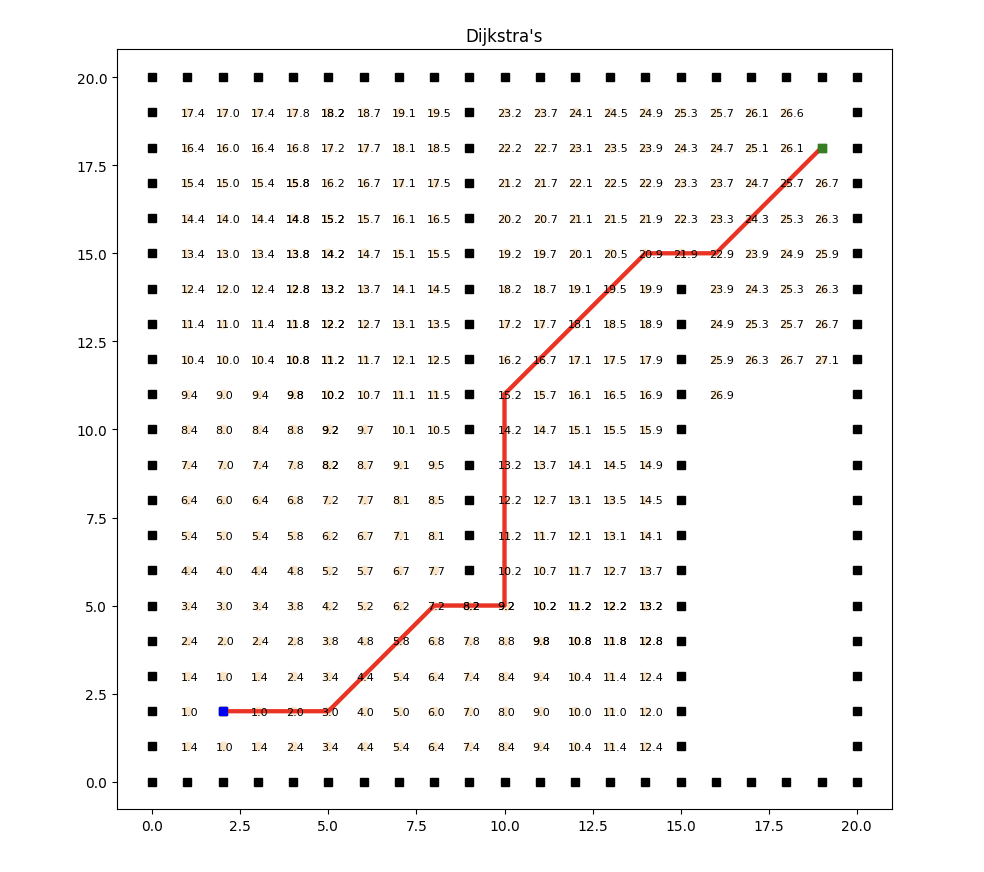
Dijkstra算法能夠正確地找到起始節點到其他所有節點的最短路徑。它基于貪婪策略,每次選擇當前最短路徑的節點,通過逐步更新節點的距離值,最終找到最短路徑。
代碼
def searching(self):
"""
Breadth-first Searching.
path, visited order
"""
self.PARENT[self.s_start] = self.s_start # 開始節點的父節點
self.g[self.s_start] = 0 # 開始節點的成本
self.g[self.s_goal] = math.inf # 目標節點的成本
# 統一成本搜索,起點的成本是0
heapq.heappush(self.OPEN,
(0, self.s_start))
while self.OPEN: # open_list
_, s = heapq.heappop(self.OPEN) # 彈出最小的元素,優先級較高
self.CLOSED.append(s) # 將節點加入被訪問元素隊列
if s == self.s_goal: # 到達目標點,即停止
break
for s_n in self.get_neighbor(s): # 得到s的鄰居節點
new_cost = self.g[s] + self.cost(s, s_n) # 計算當時鄰居節點s_n的成本=g(s)節點s的成本+s到s_n之間的成本
if s_n not in self.g: # 當前節點沒有訪問過
self.g[s_n] = math.inf # 起點到節點s_n的成本為無窮
if new_cost < self.g[s_n]: ?# 預估節點s_n成本
貪婪算法
貪婪算法(Greedy Algorithm)是一種常見的算法設計策略,其基本思想是在每一步選擇當前最優解,而不考慮整體的最優解。貪婪算法通常以局部最優解為目標,通過不斷做出局部最優選擇來達到整體最優解。
貪婪算法在路徑規劃問題中,根據當前位置到目標位置的成本作為啟發式評估準則,選擇最近的節點作為下一步移動的目標。具體步驟如下:
1、初始化:設置起始節點,將起始節點的父節點設置為起始節點本身,并將起始節點和目標節點的成本初始化為無窮大,將起始節點加入開放列表,其優先級根據啟發式函數值確定。
2、主循環:當OPEN非空時:
從OPEN列表中彈出具有最高優先級的節點,將其加入已訪問列表(CLOSED)中。
檢查當前節點是否為目標節點。如果是,則跳出循環。
獲取當前節點的鄰居節點,從鄰居節點中選擇距離目標節點最近的節點,將選擇的節點加入OPEN列表,并將該節點作為當前節點。
3、循環結束后,通過從目標節點回溯到起始節點,在PARENT字典中提取最短路徑。
算法框圖
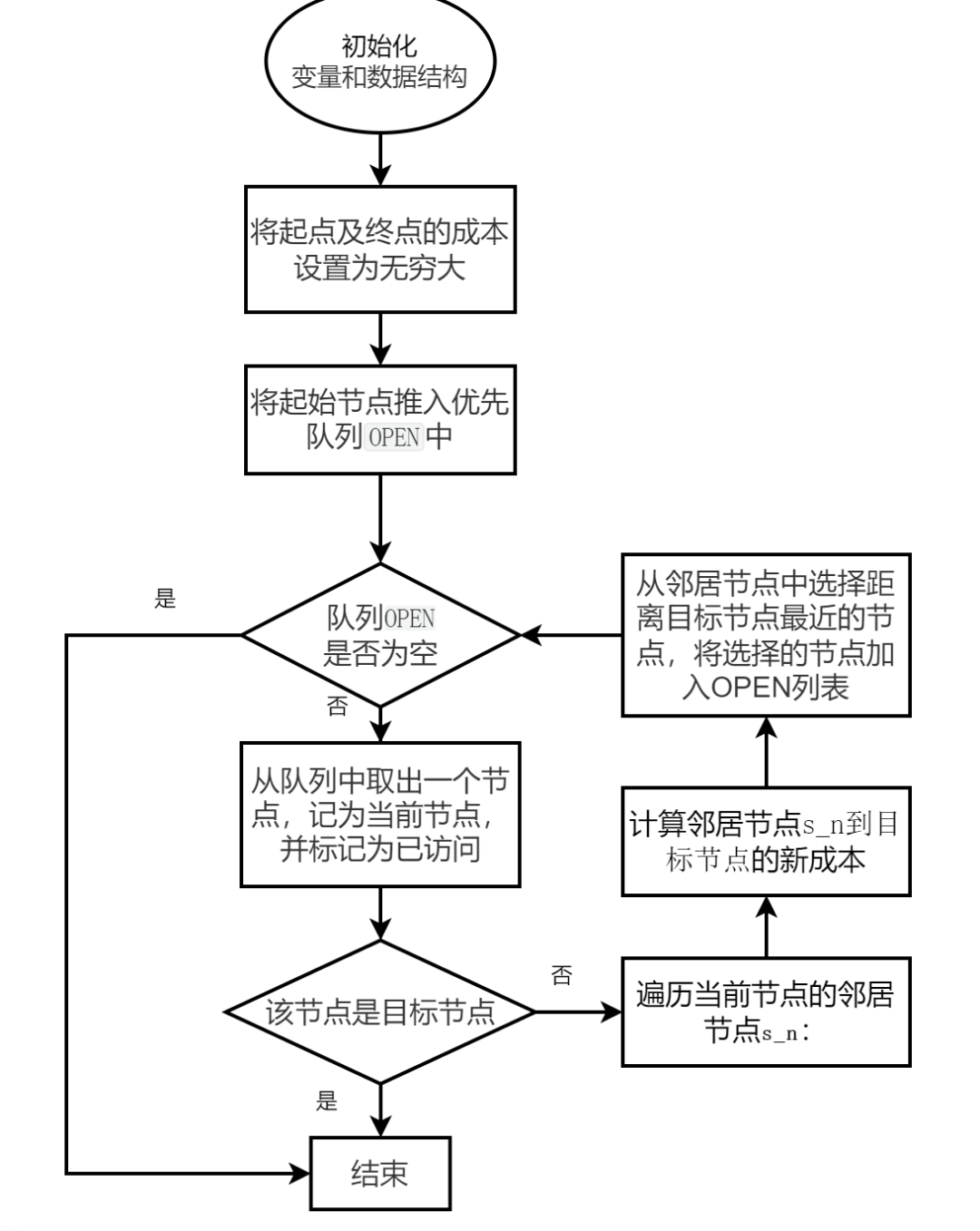
實現效果如下:
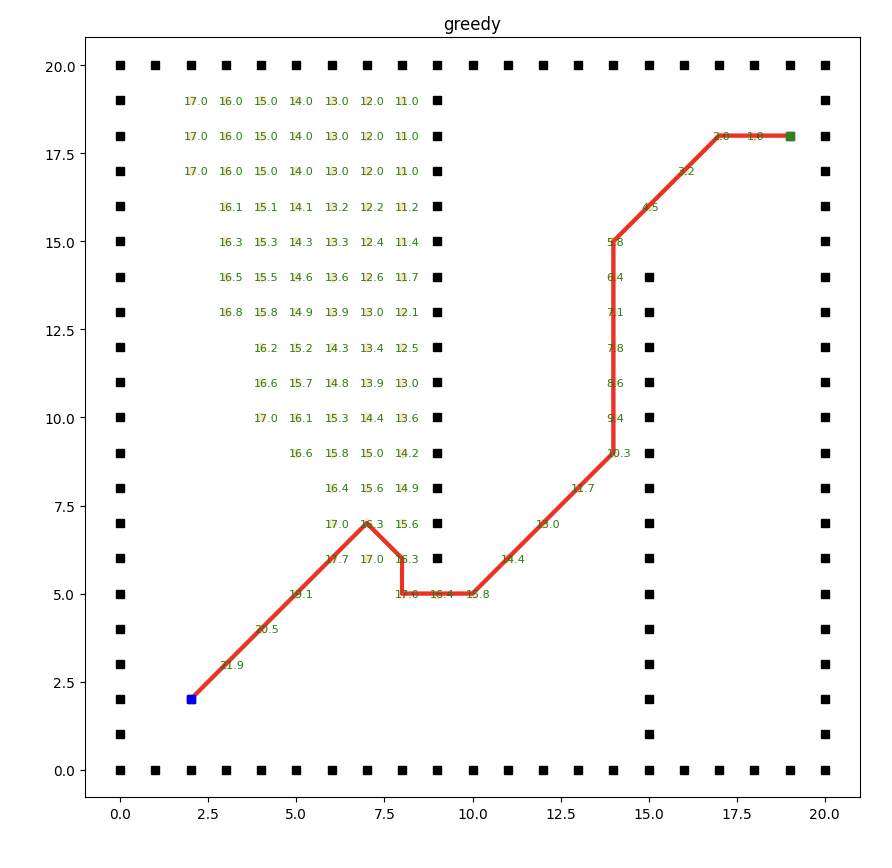
貪婪最佳優先搜索算法的局限性在于它過度依賴啟發式函數(heuristic function),該函數用于估計節點到目標節點的距離。
由于啟發式函數的估計可能不準確或不全面,算法可能會在搜索過程中陷入局部最優解,導致得到的路徑并不是最短的。
代碼
def searching(self):
self.PARENT[self.s_start] = self.s_start # 開始節點的父節點
self.h[self.s_start] = math.inf # 開始節點的成本
self.h[self.s_goal] = math.inf # 目標節點的成本
# heappush 函數能夠按照 h 值的大小來維護堆的順序,這意味著self.OPEN堆中的節點將按照 h 值的升序排列,h 值較小的節點將具有較高的優先級。
heapq.heappush(self.OPEN,
(self.heuristic(self.s_start), self.s_start))
while self.OPEN: # 當不為空時,即存在未探索區域
_, s = heapq.heappop(self.OPEN) # 彈出最小的元素,優先級較高
self.CLOSED.append(s) # 將節點加入被訪問元素隊列
if s == self.s_goal: # stop condition,到達目標點,即停止
break
for s_n in self.get_neighbor(s): # 得到s的鄰居節點
new_cost = self.heuristic(s_n) + self.cost(s, s_n) # 計算當時鄰居節點s_n的成本=g(s)節點s的成本+s到s_n之間的成本
if s_n not in self.h: # 下一個節點沒有遍歷過
self.h[s_n] = math.inf # 起點到節點s_n的成本為無窮
if new_cost < self.h[s_n]: ?# 預估節點s_n成本
A*算法
Dijkstra算法沒有考慮到目標節點的位置,因此可能會浪費時間在探索那些與目標節點相距較遠的方向上。貪婪最佳優先搜索算法會優先選擇離目標節點更近的節點進行擴展。
這樣做的好處是它能夠更快地找到到達目標節點的路徑,但無法保證找到的路徑是最短路徑,因為它只考慮了節點到目標節點的距離,沒有綜合考慮到起點到目標節點的實際距離。
A*算法是一種綜合了Dijkstra算法和貪婪最佳優先搜索的啟發式搜索算法。A*算法同時使用了節點到起點的實際距離(表示為g值)和節點到目標節點的估計距離(表示為h值)。
它通過綜合考慮這兩個值來評估節點的優先級,并選擇優先級最高的節點進行擴展。
A算法通過選擇合適的啟發式函數來平衡搜索的速度和路徑的優劣。當啟發式函數滿足一定條件時,A算法能夠保證找到最短路徑。
Dijkstra與貪婪搜索算法對比
在路徑規劃中,貪婪算法關注的是當前節點到目標節點的距離(啟發式函數值),它傾向于選擇離目標節點最近的節點作為下一步。
Dijkstra算法關注的是從起點到各個節點的距離,通過不斷更新節點的最短距離來逐步擴展路徑。
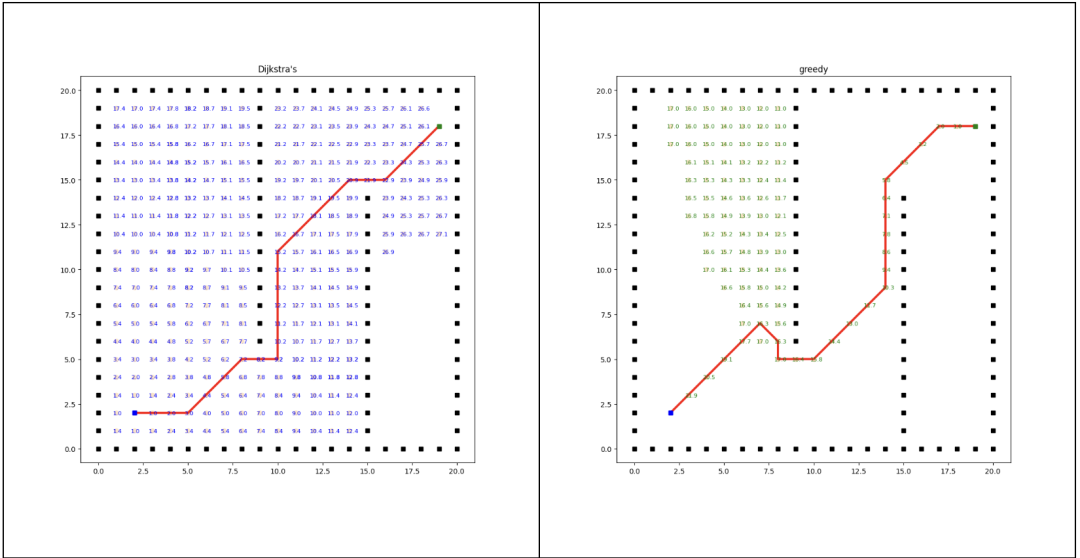
A*算法的成本函數是由兩部分組成:g(n)和h(n)。
g(n)表示從起點到達節點n的實際距離(也稱為已知最短路徑的代價),表示為g(n)。——Dijkstra
h(n)表示從節點n到目標節點的預估距離(也稱為啟發式函數),表示為h(n)。——貪婪搜索
A算法使用這兩個值來評估節點的優先級。具體地,A算法為每個節點計算一個估計總代價f(n),計算公式為:
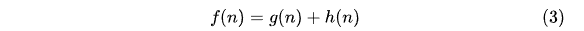
其中,f(n)表示從起點經過節點n到達目標節點的預估總代價。
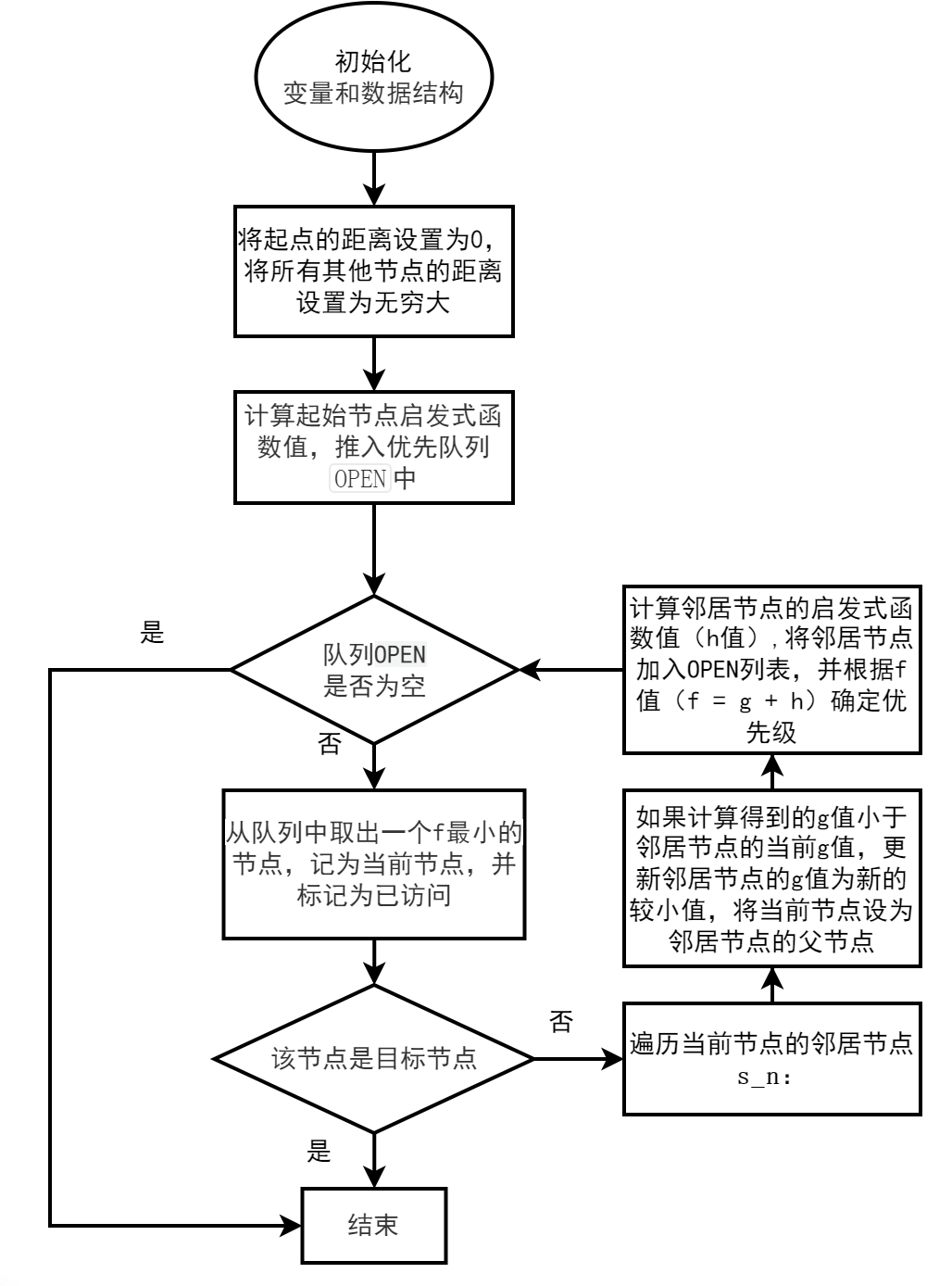
具體步驟如下:
1、初始化:設置起始節點,將起始節點的父節點設置為起始節點本身,將起始節點的成本設置為0,將目標節點的成本設置為無窮大,將起始節點加入到OPEN列表中,使用節點的f值作為優先級。
2、主循環:當OPEN非空時:
從OPEN列表中彈出具有最高優先級的節點,將其加入已訪問列表(CLOSED)中。
檢查當前節點是否為目標節點。如果是,則跳出循環。
獲取當前節點的鄰居節點。
對于每個鄰居節點,執行以下步驟:
計算從起始節點經過當前節點到達鄰居節點的實際距離,即g值。
如果鄰居節點不在g字典中,將其g值初始化為無窮大。
如果計算得到的g值小于鄰居節點的當前g值,更新鄰居節點的g值為新的更小值,并將當前節點設為鄰居節點的父節點。
計算鄰居節點的啟發式函數值,即h值。
將鄰居節點加入OPEN列表,并根據f值(f = g + h)確定其優先級。
3、循環結束后,通過從目標節點回溯到起始節點,在PARENT字典中提取最短路徑。
算法框圖
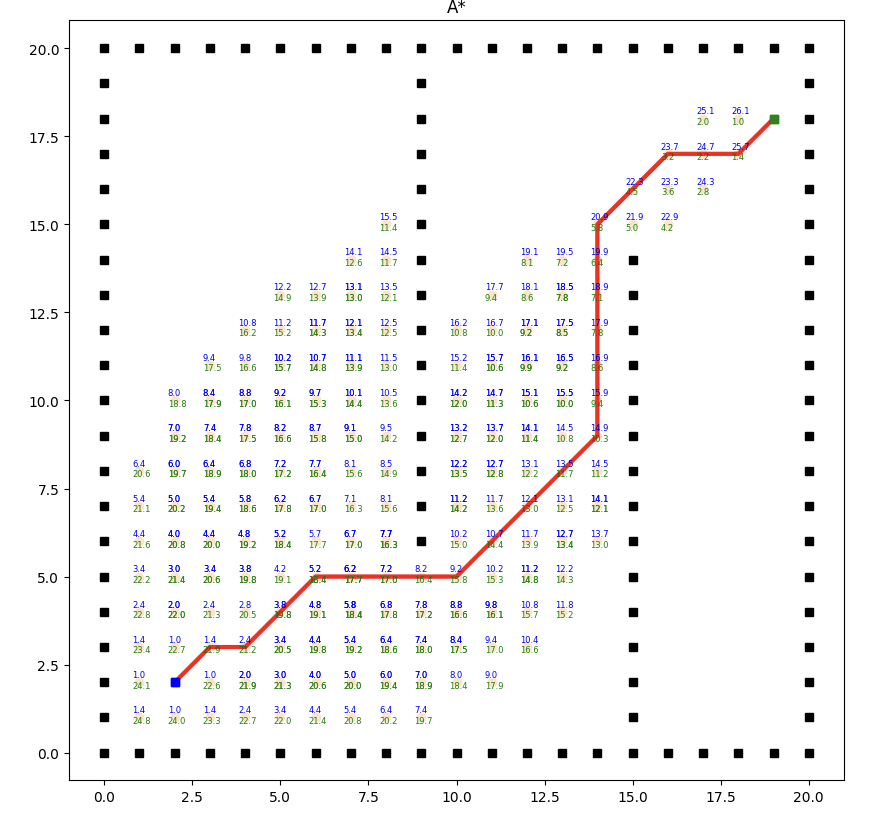
實現效果如下:
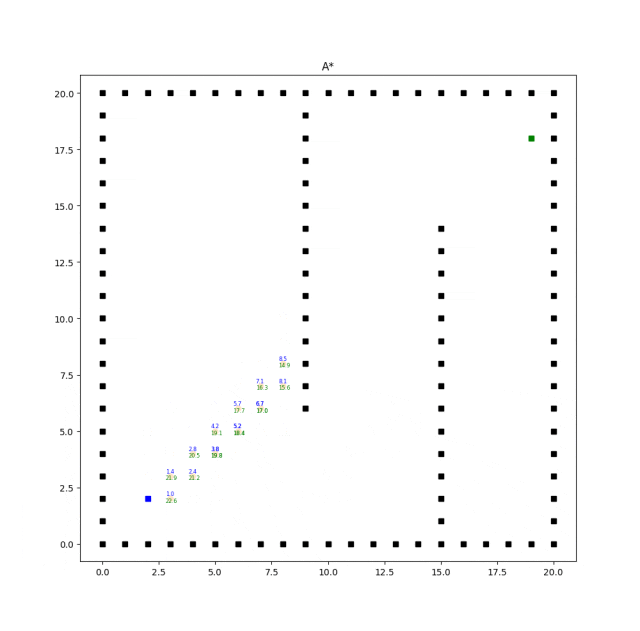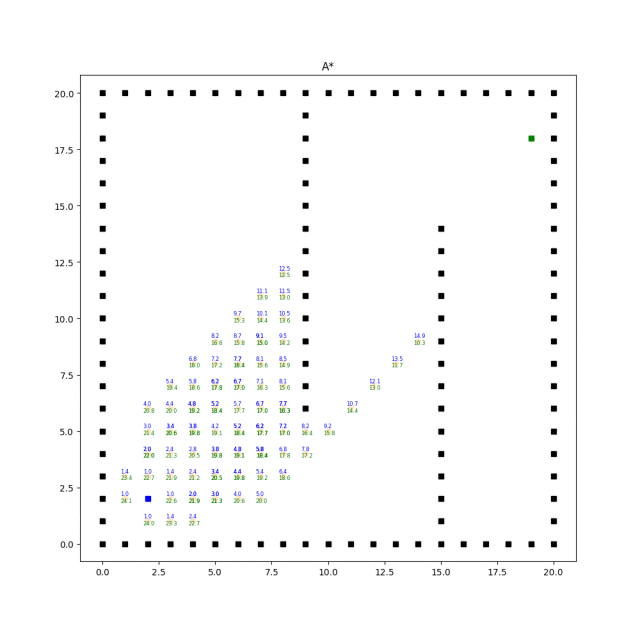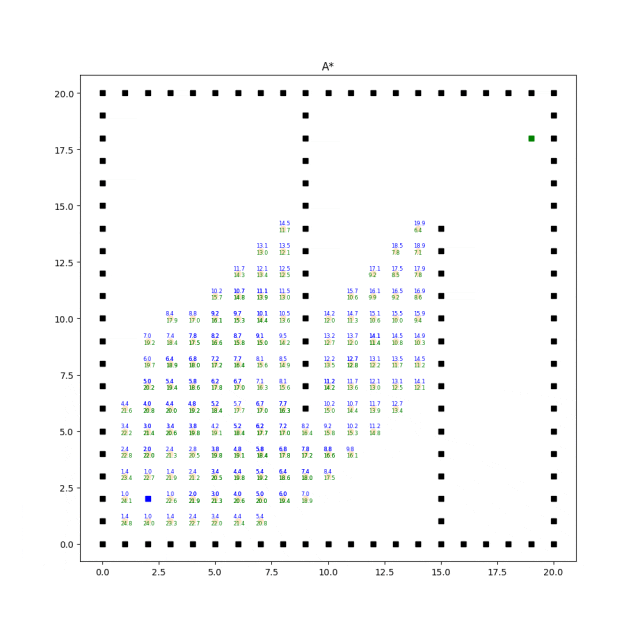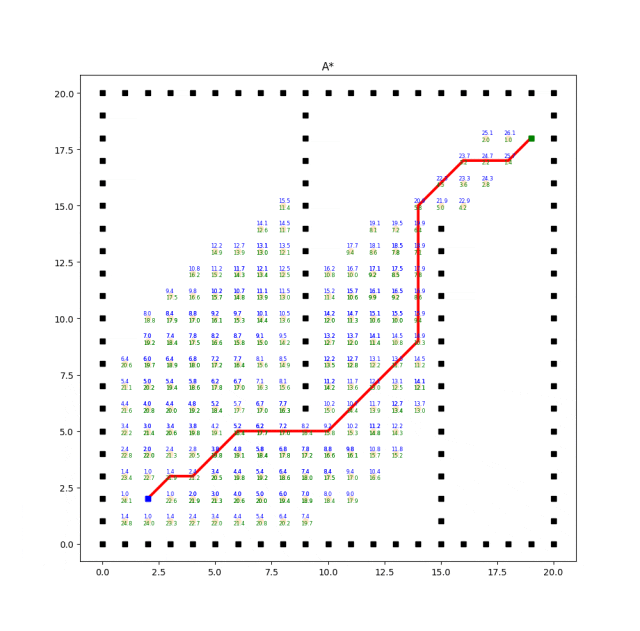
A*算法的效率和質量受啟發式函數的選擇影響較大。合理選擇啟發式函數能夠提供更好的搜索引導,但不同問題可能需要設計不同的啟發式函數。
代碼
def searching(self):
"""
A_star Searching.
path, visited order
"""
self.PARENT[self.s_start] = self.s_start # 開始節點的父節點
self.g[self.s_start] = 0 # 開始節點的成本
self.g[self.s_goal] = math.inf # 目標節點的成本
# heappush 函數能夠按照 f 值的大小來維護堆的順序,這意味著self.OPEN堆中的節點將按照 f 值的升序排列,f 值較小的節點將具有較高的優先級。
heapq.heappush(self.OPEN,
(self.f_value(self.s_start), self.s_start))
while self.OPEN: # 當不為空時,即存在未探索區域
_, s = heapq.heappop(self.OPEN) # 彈出最小的元素,優先級較高
self.CLOSED.append(s) # 將節點加入被訪問元素隊列
if s == self.s_goal: # stop condition,到達目標點,即停止
break
for s_n in self.get_neighbor(s): # 得到s的鄰居節點
new_cost = self.g[s] + self.cost(s, s_n) # 計算當時鄰居節點s_n的成本=g(s)節點s的成本+s到s_n之間的成本
if s_n not in self.g:
self.g[s_n] = math.inf # 起點到節點s_n的成本為無窮
if new_cost < self.g[s_n]: ?# 預估節點s_n成本
-
算法
+關注
關注
23文章
4601瀏覽量
92673 -
Dijkstra
+關注
關注
0文章
13瀏覽量
8432
原文標題:自動駕駛 | 路徑規劃算法Dijkstra與A*
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
經典算法大全(51個C語言算法+單片機常用算法+機器學十大算法)
基于OpenHarmony的智能助老服務系統
基于Dijkstra的PKI交叉認證路徑搜索算法
基于有向非負極圖數據DIJKSTRA算法
基于Dijkstra最短路徑的抽樣算法
基于改進Dijkstra的端端密鑰協商最優路徑選擇算法
基于Dijkstra算法的配電網孤島劃分
使用英特爾編譯器優化Dijkstra最短路徑圖算法

全文詳解A*算法及其變種

中國鐵路網的Dijkstra算法實現案例





 工商網監
工商網監
評論