 計算機視覺六大主要技術介紹
計算機視覺六大主要技術介紹
計算機視覺的應用非常廣泛,例如人臉識別、自動駕駛、無人機、醫學影像分析、工業生產等等。本文將對計算機視覺應用中最為廣泛的六大技術進行介紹。
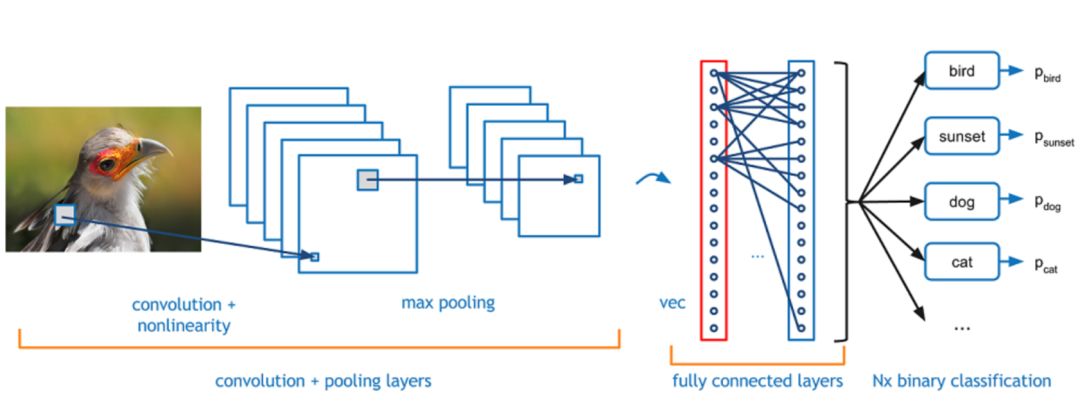
一、圖像分類
1、定義
圖像分類,根據各自在圖像信息中所反映的不同特征,把不同類別的目標區分開來的圖像處理方法。它利用計算機對圖像進行定量分析,把圖像或圖像中的每個像元或區域劃歸為若干個類別中的某一種,以代替人的視覺判讀。
2、分類方法及卷煙車間應用
2.1基于色彩特征的索引技術
常見的檢測模型包括基于直方圖的檢測方法和基于機器學習的檢測方法。基于直方圖的檢測方法是最簡單和常見的方法,它僅僅對顏色直方圖進行比較。基于機器學習的檢測方法則需要訓練一個分類器,以區分不同類別的圖像。常見的分類器包括支持向量機(SVM)和隨機森林(Random Forest)等。
實際業務中,可以用來檢測和分類卷煙制造過程中的圖像。例如,可以使用顏色直方圖來檢測卷煙生產線上的煙葉顏色分布情況,以及使用顏色矩來分析卷煙的色調和亮度等特征。這些方法可以幫助卷煙廠監控生產過程,提高生產效率和質量。
2.2基于紋理的圖像分類技術
通常使用紋理特征描述圖像的紋理信息。常見的紋理特征包括灰度共生矩陣(GLCM)、局部二值模式(LBP)和高斯方向梯度直方圖(HOG)等。這些紋理特征可以提取圖像中的紋理信息,包括紋理的顆粒度、方向、周期性等,從而用于圖像分類和識別。
常規的解決方案包括以下幾個步驟:
1)特征提取:使用紋理特征描述圖像的紋理信息。灰度共生矩陣(GLCM)是一種描述灰度紋理特征的方法,它利用灰度級之間的空間關系來描述紋理信息。局部二值模式(LBP)則是一種描述局部紋理特征的方法,它利用像素點周圍的二進制編碼來描述紋理信息。高斯方向梯度直方圖(HOG)則是一種描述方向紋理特征的方法,它利用圖像梯度方向和梯度強度來描述紋理信息。
2)特征選擇:對提取的紋理特征進行篩選和選擇,以減少特征維度和提高分類性能。常見的特征選擇方法包括主成分分析(PCA)和線性判別分析(LDA)等。
3)分類模型:選擇一種分類器或分類模型,用于將提取的紋理特征與圖像類別進行映射。常見的分類器包括支持向量機(SVM)、K近鄰算法、決策樹等。
該技術可以用于檢測和分類卷煙的表面紋理信息。例如,可以使用灰度共生矩陣(GLCM)來分析卷煙的表面紋理特征,如顆粒度、方向性等。這些方法可以幫助卷煙廠監控卷煙表面質量,提高產品質量和生產效率。
2.3基于形狀的圖像分類技術
基于形狀的圖像分類技術通常使用圖像形狀特征描述圖像中的形狀信息,常用的形狀特征包括邊緣特征、輪廓特征和區域特征等。基于形狀的圖像分類技術可以應用于許多應用領域,如醫學圖像、工業檢測和安防監控等。
常規的解決方案包括以下幾個步驟:
1)特征提取:使用形狀特征描述圖像中的形狀信息。常用的形狀特征包括邊緣特征、輪廓特征和區域特征等。其中,邊緣特征通常是指提取圖像中的邊緣信息,如Canny邊緣檢測算法。輪廓特征則是指提取圖像中的輪廓信息,如Hu不變矩特征。區域特征則是指提取圖像中的區域信息,如Zernike矩和小波矩等。
2)特征選擇:對提取的形狀特征進行篩選和選擇,以減少特征維度和提高分類性能。常見的特征選擇方法包括主成分分析(PCA)和線性判別分析(LDA)等。
3)分類模型:選擇一種分類器或分類模型,用于將提取的形狀特征與圖像類別進行映射。常見的分類器包括支持向量機(SVM)、K近鄰算法、決策樹等。
在卷煙廠相關的應用中,可以用于檢測和分類卷煙的形狀信息,如卷煙的長度、粗細和形態等。例如,可以使用輪廓特征和區域特征來描述卷煙的形狀信息,然后使用分類器對不同形狀的卷煙進行分類。這些方法可以幫助卷煙廠監控卷煙形狀質量,提高產品質量和生產效率。
2.4基于空間關系的圖像分類技術
利用圖像中不同區域之間的空間關系,來描述和分類圖像的一種方法。這種方法通常用于場景分類、物體識別和圖像標注等領域。
常規的解決方案包括以下幾個步驟:
1)特征提取:提取圖像中的區域特征,通常包括顏色、紋理、形狀等特征。
2)空間關系建模:根據提取的特征,對不同區域之間的空間關系進行建模,例如使用關系圖模型或基于視覺單詞的方法。
3)分類模型:選擇一種分類器或分類模型,用于將提取的特征與圖像類別進行映射。常見的分類器包括支持向量機(SVM)、卷積神經網絡(CNN)等。
在實際應用中可以檢測和分類卷煙生產過程中的不同區域和組件,例如卷煙的過濾嘴、煙膜和濾棒等。常用的解決方案是基于視覺單詞的方法,即將圖像中的每個區域表示為一組視覺單詞,并通過計算視覺單詞之間的空間關系來描述區域之間的空間關系。然后,可以使用分類器對不同區域進行分類,以實現卷煙生產過程中的自動化檢測和分類。
二、目標檢測
目標檢測是指在圖像或視頻中,識別出目標物體所在的位置,并標注出其所屬的類別的任務。相比于圖像分類任務,目標檢測需要對目標的位置和數量進行準確的識別,因此其難度更大,但也更加實用。目標檢測通常應用于智能安防、自動駕駛、無人機等領域,能夠對目標進行追蹤、識別和分析,有助于提高智能決策和系統自主性。
常見的目標檢測模型包括:
1)Faster R-CNN:是一種基于深度神經網絡的目標檢測模型,它通過在區域提議網絡(Region Proposal Network, RPN)中引入錨點來提高檢測速度,同時采用了RoI Pooling層來實現不同大小的目標檢測。
2)YOLO(You Only Look Once):是一種基于單階段目標檢測算法的模型,它將目標檢測任務轉化為一個回歸問題,通過卷積神經網絡預測目標的類別和位置。
3)SSD(Single Shot MultiBox Detector):也是一種基于單階段目標檢測算法的模型,通過在每個特征層上應用不同大小和形狀的先驗框,從而實現對不同尺度目標的檢測。
目標檢測的適用場景包括但不限于:
1)智能安防:監控場景中的人員和車輛,實現目標追蹤和識別。
自動駕駛:通過識別道路標志、交通信號燈、行人和其他車輛等來實現自主駕駛。
2)無人機:對無人機飛行區域中的目標進行識別和跟蹤,以實現智能控制和導航。
3)工業制造:在生產過程中對產品進行檢測和分類,提高生產效率和質量。
4)醫療診斷:通過對醫學圖像中的腫瘤等異常進行識別和定位,輔助醫生進行診斷和治療。
目標檢測的性能指標主要包括準確率、召回率、F1得分等,常用的評價方法有mAP(mean Average Precision)和IoU(Intersection over Union)等。在實際應用中,可以根據具體場景和需求,選擇不同的模型和算法來實現目標檢測任務。
三、目標跟蹤
目標跟蹤是指在視頻序列中,對于已知的初始目標,在后續幀中通過對目標的特征提取和跟蹤算法進行處理,實現對目標位置、形態等信息的實時跟蹤。目標跟蹤技術適用于視頻監控、無人駕駛、智能交通等領域,可以用于目標的實時跟蹤和識別,實現自動化控制和智能化分析。
常用的目標跟蹤算法包括以下幾種:
1)基于相關濾波的跟蹤方法
這種方法是將目標與模板進行相關性計算,計算得到的結果可以表示目標在當前幀的位置。常用的相關濾波算法包括均值歸一化相關濾波(Mean Normalized Correlation,MNC)、峰值信號比相關濾波(Peak-to-Correlation Energy Ratio,PCER)等。
2)基于粒子濾波的跟蹤方法
這種方法通過在目標周圍隨機生成多個粒子,然后根據目標的運動模型,對這些粒子進行預測,再用觀測信息對預測的粒子進行權重更新,最終選擇權重最高的粒子來表示目標的位置。常用的粒子濾波算法包括卡爾曼濾波(Kalman Filter,KF)、粒子濾波(Particle Filter,PF)等。
3)基于深度學習的跟蹤方法
這種方法使用深度學習算法對目標進行特征提取和表示,然后根據目標在前一幀的位置和特征,對目標在當前幀的位置進行預測。常用的深度學習跟蹤算法包括循環神經網絡(Recurrent Neural Network,RNN)、卷積神經網絡(Convolutional Neural Network,CNN)等。
目標跟蹤技術適用于視頻監控、無人駕駛、智能交通等領域,可以用于目標的實時跟蹤和識別,實現自動化控制和智能化分析。
四、語義分割
旨在將輸入圖像中的每個像素標記為屬于哪個語義類別。與目標檢測和圖像分類不同,語義分割不僅可以識別圖像中的物體,還可以為每個像素分配標簽,從而提供更詳細和準確的圖像理解。
語義分割適用于需要對圖像進行精細分割和像素級分類的場景,例如自動駕駛中的道路分割、醫學圖像中的病變分割、地理信息系統中的土地分類等。
常見的語義分割模型包括FCN(Fully Convolutional Network)、U-Net、DeepLab等。其中FCN模型是最早被提出并被廣泛使用的語義分割模型之一,它將全連接層轉換為卷積層,從而實現端到端的像素級分類。U-Net模型通過引入對稱的上采樣和下采樣路徑,能夠更好地處理分辨率較低的輸入圖像。DeepLab模型則通過空洞卷積(Dilated Convolution)和空間金字塔池化(Spatial Pyramid Pooling)等技術,提高了圖像語義分割的精度。
除了這些常用模型外,近年來還涌現出了許多基于深度學習的新型語義分割模型,如PSPNet、DeepLab V3+等,它們在精度和效率等方面都有所提高。
五、實例分割
實例分割是結合目標檢測和語義分割的一個更高層級的任務。
實例分割是計算機視覺中的一項任務,旨在同時檢測圖像中的物體,并將每個物體分割成精確的像素級別的區域。與語義分割不同,實例分割不僅可以分割出不同類別的物體,還可以將它們分割成獨立的、像素級別的區域。
實例分割適用于需要對圖像進行精細分割并區分不同物體的場景,例如自動駕駛中的行人和車輛分割、醫學圖像中的器官分割、遙感圖像中的建筑物分割等。
常見的實例分割模型包括Mask R-CNN、FCIS(Fully Convolutional Instance-aware Semantic Segmentation)等。其中,Mask R-CNN是一種基于 Faster R-CNN 框架的實例分割模型,通過添加分割頭網絡在目標檢測框架中增加了實例分割的功能,從而實現了同時檢測和分割的目標。FCIS模型則是一種全卷積實例分割模型,它使用了RoI pooling和RoI reshape等技術,可以在不增加計算量的情況下同時實現目標檢測和實例分割。
除了這些常用模型外,近年來還涌現出了許多基于深度學習的新型實例分割模型,如SOLO(Segmenting Objects by Locations)等,它們在精度和效率等方面都有所提高。
六、影像重建
影像重建是指通過對原始圖像進行處理和重構,生成高質量的圖像或視頻。其應用場景包括醫學影像學、遙感圖像、安全監控等領域。
在醫學影像學中,影像重建技術可以應用于CT、MRI等醫學影像的重建,幫助醫生更精準地診斷和治療病情。在遙感圖像領域,影像重建技術可以幫助提高遙感圖像的分辨率和質量,為資源管理、環境監測等提供支持。在安全監控領域,影像重建技術可以幫助提高監控圖像的清晰度和識別度,增強安全監控的效果。
影像重建技術主要包括基于插值的方法、基于統計建模的方法和基于深度學習的方法。其中,基于插值的方法是最簡單的方法之一,它通過對原始圖像進行插值操作來增加圖像的分辨率。基于統計建模的方法則通過對樣本進行統計建模來重建圖像,如主成分分析(PCA)、獨立成分分析(ICA)等。基于深度學習的方法則是當前最先進的影像重建方法之一,如卷積神經網絡(CNN)和生成對抗網絡(GAN)。這些模型通過學習大量數據來重構圖像,并且在不同的任務中取得了很好的效果。
計算機視覺是當前最熱門的研究之一,是一門多學科交叉的研究,隨著對計算機視覺研究的深入,很多科學家相信將為人工智能行業的發展奠定基礎。
文章來源:智能制造趨勢
審核編輯:湯梓紅
-
計算機
+關注
關注
19文章
7418瀏覽量
87711 -
人臉識別
+關注
關注
76文章
4005瀏覽量
81764 -
機器學習
+關注
關注
66文章
8377瀏覽量
132405
發布評論請先 登錄
相關推薦
機器視覺與計算機視覺的關系簡述
讓機器“看見”—計算機視覺入門及實戰 第二期基礎技術篇

計算機視覺突破工業化紅線,六大細分領域前途大好
計算機視覺的發展歷史_計算機視覺的應用方向
現代企業計算機視覺發展的主要趨勢是什么
計算機視覺中主要的五大技術
計算機視覺的十大算法






 工商網監
工商網監
評論