") 【AI簡報(bào)20230707】中國團(tuán)隊(duì)推出「全球首顆」AI 全自動(dòng)設(shè)計(jì) CPU!重磅,GPT-4 API 全面開放使用!
【AI簡報(bào)20230707】中國團(tuán)隊(duì)推出「全球首顆」AI 全自動(dòng)設(shè)計(jì) CPU!重磅,GPT-4 API 全面開放使用!
1. 僅用 5 小時(shí)!中國團(tuán)隊(duì)推出「全球首顆」AI 全自動(dòng)設(shè)計(jì) CPU,性能比肩 Intel 486!
原文:https://mp.weixin.qq.com/s/DNBO34Xk2nVwNiEMBjJ-Cg
在這場由 ChatGPT 掀起的 AI 熱潮下,越來越多人開始看到如今 AI 的強(qiáng)悍:AI 作圖、AI 寫論文、AI 編代碼、AI 預(yù)測完整人類蛋白質(zhì)組結(jié)構(gòu)、AI 發(fā)現(xiàn)速度提升 70% 的新排序算法……
既然 AI 看似“無所不能”,許多人便提出了疑問:“那 AI 真的能像人類一樣進(jìn)行設(shè)計(jì)工作嗎?”在預(yù)測蛋白質(zhì)結(jié)構(gòu)和生成編碼等方面,AI 確實(shí)表現(xiàn)卓越,但在設(shè)計(jì)這些物體時(shí),總體而言 AI 的搜索空間還相對(duì)較小。
為了探尋 AI 設(shè)計(jì)能力的極限,近日中國中科院計(jì)算所等機(jī)構(gòu)將目標(biāo)放在了芯片設(shè)計(jì)上,因?yàn)椤八怯?jì)算機(jī)的大腦,也是目前人類所設(shè)計(jì)的世界上最復(fù)雜的設(shè)備之一。”
結(jié)果,最終數(shù)據(jù)出人意料:中國中科院計(jì)算所等機(jī)構(gòu)利用 AI 技術(shù),設(shè)計(jì)出了全球首個(gè)無人工干預(yù)、全自動(dòng)生成的 CPU 晶片“啟蒙 1 號(hào)”——整個(gè)訓(xùn)練過程不到 5 小時(shí),驗(yàn)證測試準(zhǔn)確性卻能達(dá)到 >99.999999999%!
1. 在無人干預(yù)的情況下,讓 AI 設(shè)計(jì)出工業(yè)級(jí) CPU
根據(jù)相關(guān)論文《突破機(jī)器設(shè)計(jì)的極限:利用 AI 進(jìn)行自動(dòng)化 CPU 設(shè)計(jì)(Pushing the Limits of Machine Design: Automated CPU Design with AI)》介紹,這場研究的目的是:賦予機(jī)器自主設(shè)計(jì) CPU 的能力,以此探索機(jī)器設(shè)計(jì)的邊界。
“如果機(jī)器能夠在無人干預(yù)的情況下設(shè)計(jì)出工業(yè)級(jí) CPU,不僅可以顯著提高設(shè)計(jì)效率,還能將機(jī)器設(shè)計(jì)的極限推向接近人類性能的水平,從而推動(dòng)半導(dǎo)體產(chǎn)業(yè)的革命。”論文中還補(bǔ)充道:“自行設(shè)計(jì)機(jī)器的能力,即自我設(shè)計(jì),可以作為建立自我進(jìn)化機(jī)器的基礎(chǔ)步驟。”
有了基本方向后,即要在沒有人工編程的情況下自動(dòng)化 CPU 設(shè)計(jì),團(tuán)隊(duì)研究人員決定通過 AI 技術(shù),直接從“輸入-輸出(IO)”自動(dòng)生成 CPU 設(shè)計(jì),無需人類工程師手動(dòng)提供任何代碼或自然語言描述。
簡單來說,傳統(tǒng) CPU 設(shè)計(jì)需要投入大量人力,包括編寫代碼、設(shè)計(jì)電路邏輯、功能驗(yàn)證和優(yōu)化工作等等。但通過將 CPU 自動(dòng)設(shè)計(jì)問題轉(zhuǎn)化為“滿足輸入-輸出規(guī)范的電路邏輯生成問題”后,只需要測試用例,便可以直接生成滿足需求的電路邏輯——這使得傳統(tǒng) CPU 設(shè)計(jì)流程中極其耗時(shí)的“邏輯設(shè)計(jì)”和“驗(yàn)證環(huán)節(jié)”,都被省去了。
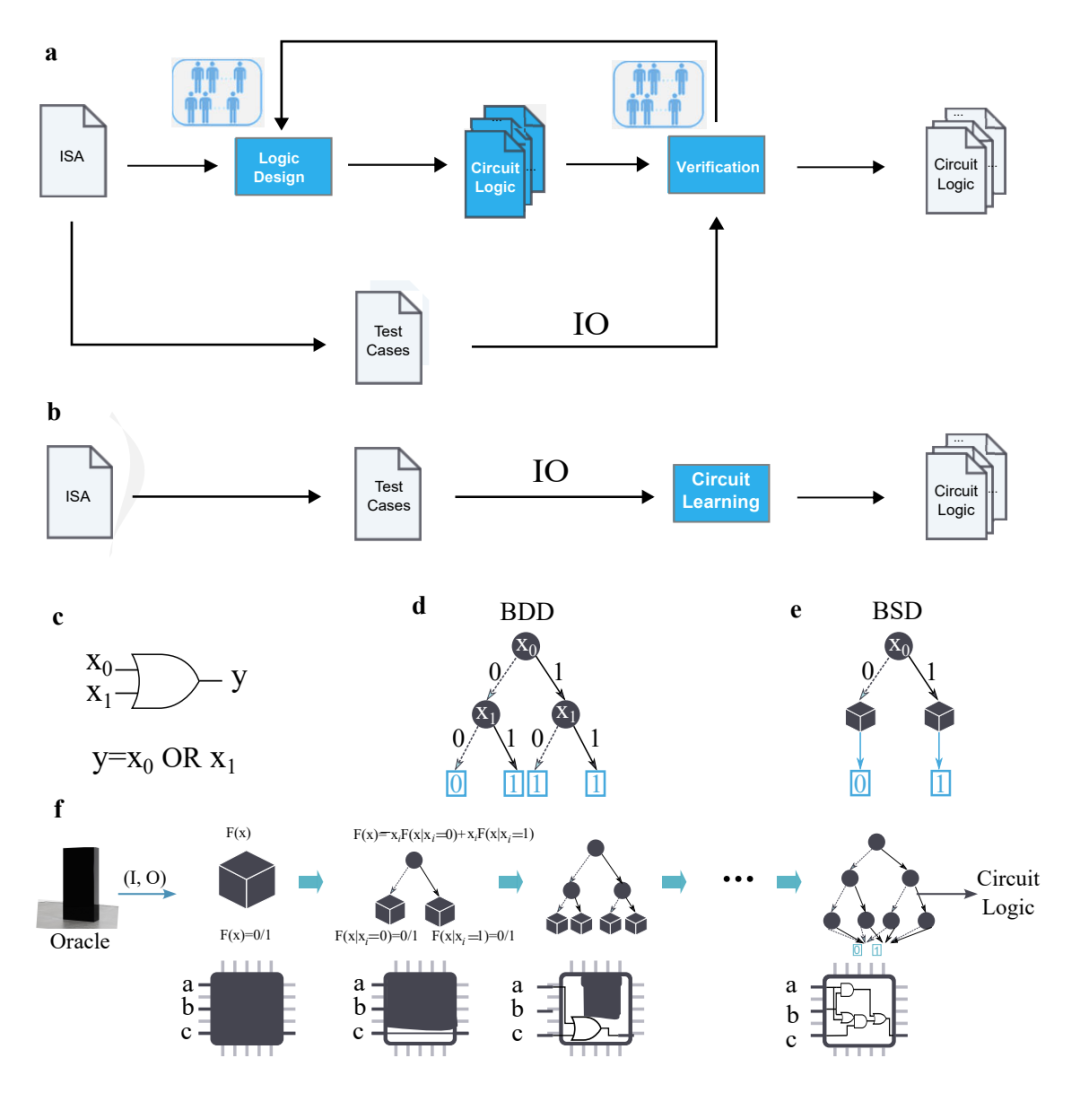
想順利開啟這樣的自動(dòng)化 CPU 設(shè)計(jì)流程,需要提前對(duì) AI 進(jìn)行訓(xùn)練,包括觀察一系列 CPU 輸入和輸出,因此論文中才強(qiáng)調(diào)該 CPU 的設(shè)計(jì)是“僅從外部輸入-輸出觀察中形成的,并非正式的程序代碼”。
從這些輸入和輸出中,研究人員生成了一個(gè) BSD 二元猜測圖(Binary Speculation Diagram,簡稱 BSD)算法,并利用基于蒙特卡羅的擴(kuò)展和布爾函數(shù)的原理,大幅提高了基于 AI 進(jìn)行 CPU 設(shè)計(jì)的準(zhǔn)確性和效率。
2. 可與 Intel 486 系列媲美
通過以上逐步地推敲,一個(gè) CPU 的自動(dòng)化 AI 設(shè)計(jì)流程就成型了:僅用 5 小時(shí)就生成 400 萬邏輯門,全球首款無需人工干預(yù)、全自動(dòng)生成的 CPU 芯片也就此誕生——啟蒙 1 號(hào)。
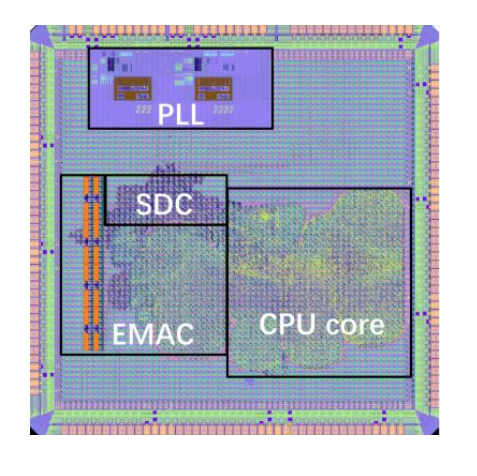
據(jù)論文介紹,啟蒙 1 號(hào)基于 RISC-V的 32 位架構(gòu),采用 65nm 工藝,頻率可達(dá) 300MHz,且可運(yùn)行 Linux 操作系統(tǒng)。另據(jù)媒體報(bào)道,相較于現(xiàn)階段 GPT-4 能設(shè)計(jì)的電路規(guī)模,啟蒙 1 號(hào)要大 4000 倍。

此外在 Drystone 基準(zhǔn)測試中,啟蒙 1 號(hào)的性能不僅可比肩由人類設(shè)計(jì)的 Intel 486 系列 CPU,還比 Acorn Archimedes A3010 更快一些。
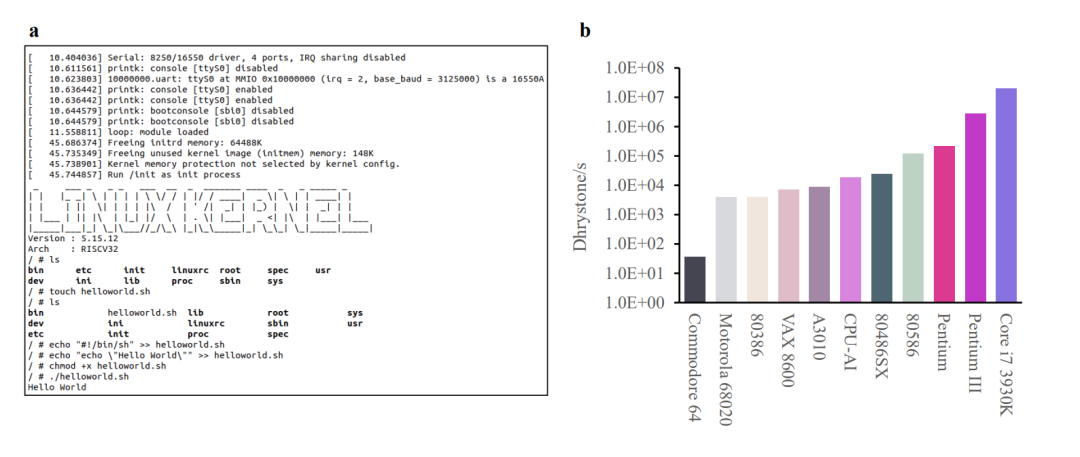 更值得一提的是,這顆完全由 AI 設(shè)計(jì)的 32 位 RISC-V CPU,其設(shè)計(jì)周期比人類團(tuán)隊(duì)完成類似 CPU 設(shè)計(jì)的速度,快了近 1000 倍,驗(yàn)證測試準(zhǔn)確性也能達(dá)到 >99.999999999%。
更值得一提的是,這顆完全由 AI 設(shè)計(jì)的 32 位 RISC-V CPU,其設(shè)計(jì)周期比人類團(tuán)隊(duì)完成類似 CPU 設(shè)計(jì)的速度,快了近 1000 倍,驗(yàn)證測試準(zhǔn)確性也能達(dá)到 >99.999999999%。
不過,有些人可能對(duì)于這款由 AI 設(shè)計(jì)的啟蒙 1 號(hào)并不在意,畢竟與它性能相近的 Intel 486 系列 CPU(Intel 80486SX),早已是誕生于上世紀(jì) 1991 年的“老芯片”了。但研究人員對(duì)于啟蒙 1 號(hào)的開發(fā)依舊很自豪:在整個(gè) AI 自動(dòng)化設(shè)計(jì)過程中,他們生成的 BSD 算法,甚至還自主發(fā)現(xiàn)了馮·諾伊曼架構(gòu)(一種將程序指令存儲(chǔ)器和數(shù)據(jù)存儲(chǔ)器合并在一起的電腦設(shè)計(jì)概念結(jié)構(gòu))。
3. 完全由 AI 生成的 CPU 有望超過人類?
平心而論,作為全球首款 AI 自動(dòng)生成的芯片,啟蒙 1 號(hào)的性能和規(guī)模根本無法與當(dāng)前頂級(jí)的主流 CPU 相比,但正如論文開篇所說,這場實(shí)驗(yàn)本身就不是為了開發(fā)高性能芯片,而是“探索機(jī)器設(shè)計(jì)的邊界”。
讓 AI 從頭開始構(gòu)建一個(gè)新 RISC-V CPU,其背后的真實(shí)意義在于:研究 AI 未來能否用于減少現(xiàn)有半導(dǎo)體行業(yè)的設(shè)計(jì)和優(yōu)化周期。
如果從這個(gè)角度來看,此次中國中科院計(jì)算所等機(jī)構(gòu)進(jìn)行的這項(xiàng)實(shí)驗(yàn),就有了初步的結(jié)論:與傳統(tǒng)人類設(shè)計(jì)的 CPU 相比,啟蒙 1 號(hào)的研發(fā)周期縮短了近 1000 倍,因?yàn)閭鹘y(tǒng) CPU 設(shè)計(jì)流程中耗時(shí)極長的手動(dòng)編程和驗(yàn)證過程完全被省略了。
“我們的方法改變了傳統(tǒng)的 CPU 設(shè)計(jì)流程,并有可能改革半導(dǎo)體行業(yè)。”在論文的最后,研究人員對(duì)于由 AI 完全設(shè)計(jì)芯片的未來做出展望:“除了提供人性化的設(shè)計(jì)能力,這種方法還發(fā)現(xiàn)了人類知識(shí)的馮·諾伊曼架構(gòu),未來更有可能產(chǎn)生積極的(甚至未知的)架構(gòu)優(yōu)化,這為建立一個(gè)自我進(jìn)化的機(jī)器、并最終擊敗人類設(shè)計(jì)的最新 CPU 提供了一些啟示。”
即研究人員認(rèn)為,未來通過不斷迭代 AI 的芯片設(shè)計(jì)方式,完全由 AI 生成的 CPU,或許有望達(dá)到甚至超越由人類設(shè)計(jì)的 CPU。那么對(duì)于這個(gè)說法,你又是否有什么看法嗎?
2. 北大法律大模型ChatLaw火了!!
原文:https://mp.weixin.qq.com/s/yFVUh5PqlhNXtJA1NLb5rg
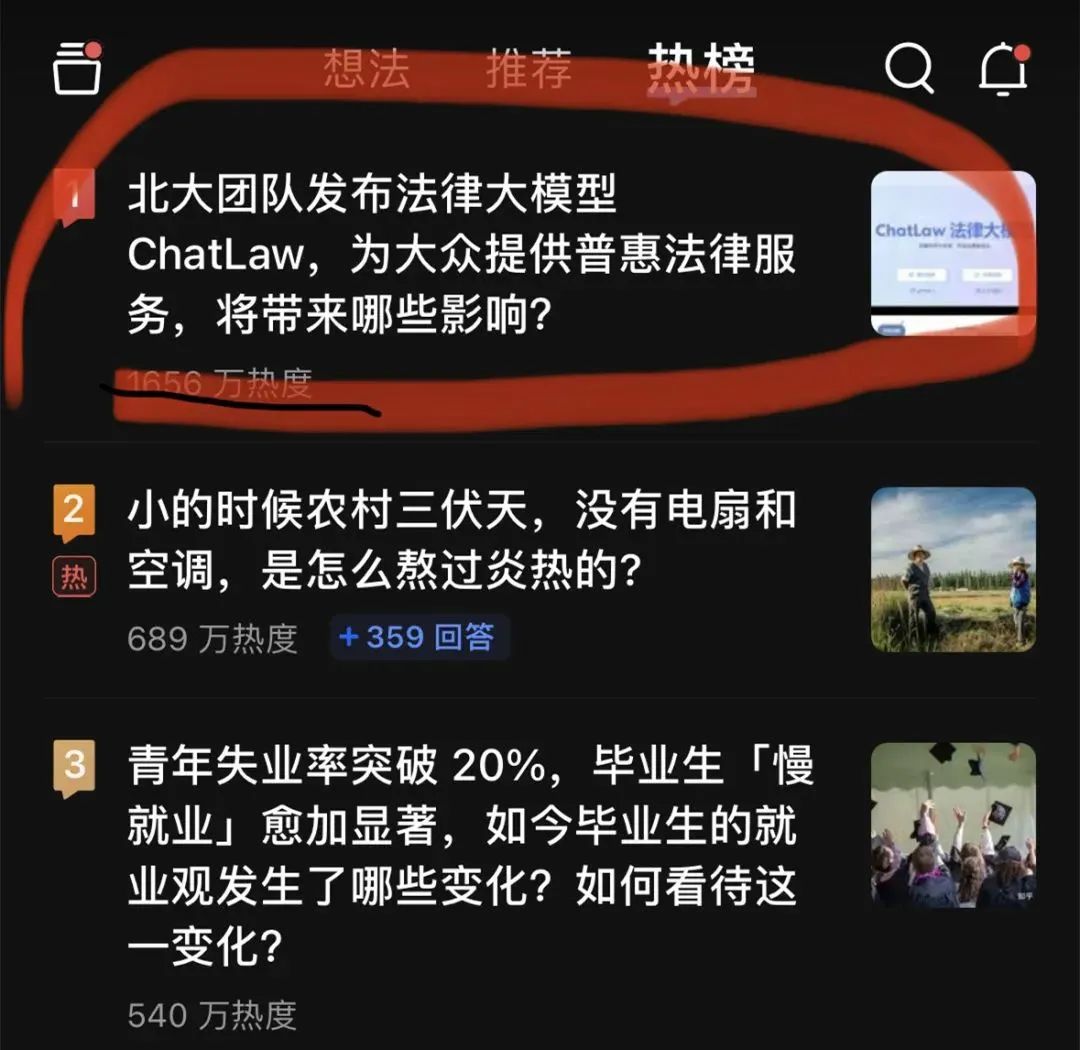
大模型又「爆了」。一個(gè)法律大模型 ChatLaw 登上了知乎熱搜榜榜首。熱度最高時(shí)達(dá)到了 2000 萬左右。
這個(gè) ChatLaw 由北大團(tuán)隊(duì)發(fā)布,致力于提供普惠的法律服務(wù)。一方面當(dāng)前全國執(zhí)業(yè)律師不足,供給遠(yuǎn)遠(yuǎn)小于法律需求;另一方面普通人對(duì)法律知識(shí)和條文存在天然鴻溝,無法運(yùn)用法律武器保護(hù)自己。
大語言模型最近的崛起正好為普通人以對(duì)話方式咨詢法律相關(guān)問題提供了一個(gè)絕佳契機(jī)。
目前,ChatLaw 共有三個(gè)版本,分別如下:
-
ChatLaw-13B,為學(xué)術(shù) demo 版,基于姜子牙 Ziya-LLaMA-13B-v1 訓(xùn)練而來,中文各項(xiàng)表現(xiàn)很好。但是,邏輯復(fù)雜的法律問答效果不佳,需要用更大參數(shù)的模型來解決;
-
ChatLaw-33B,也為學(xué)術(shù) demo 版,基于 Anima-33B 訓(xùn)練而來,邏輯推理能力大幅提升。但是,由于 Anima 的中文語料過少,問答時(shí)常會(huì)出現(xiàn)英文數(shù)據(jù);
-
ChatLaw-Text2Vec,使用 93w 條判決案例做成的數(shù)據(jù)集,基于 BERT 訓(xùn)練了一個(gè)相似度匹配模型,可以將用戶提問信息和對(duì)應(yīng)的法條相匹配。根據(jù)官方演示,ChatLaw 支持用戶上傳文件、錄音等法律材料,幫助他們歸納和分析,生成可視化導(dǎo)圖、圖表等。此外,ChatLaw 可以基于事實(shí)生成法律建議、法律文書。該項(xiàng)目在 GitHub 上的 Star 量達(dá)到了 1.1k。

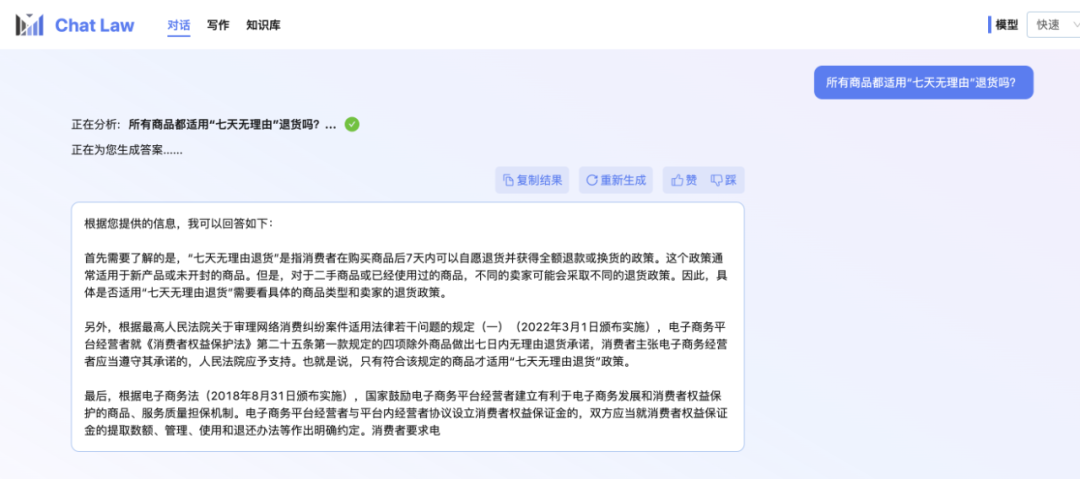
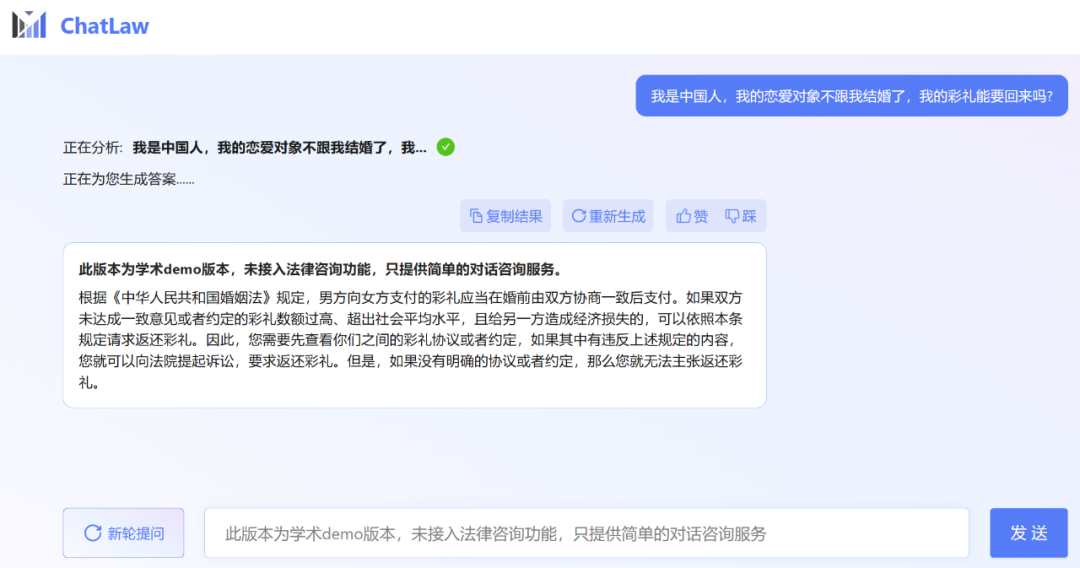
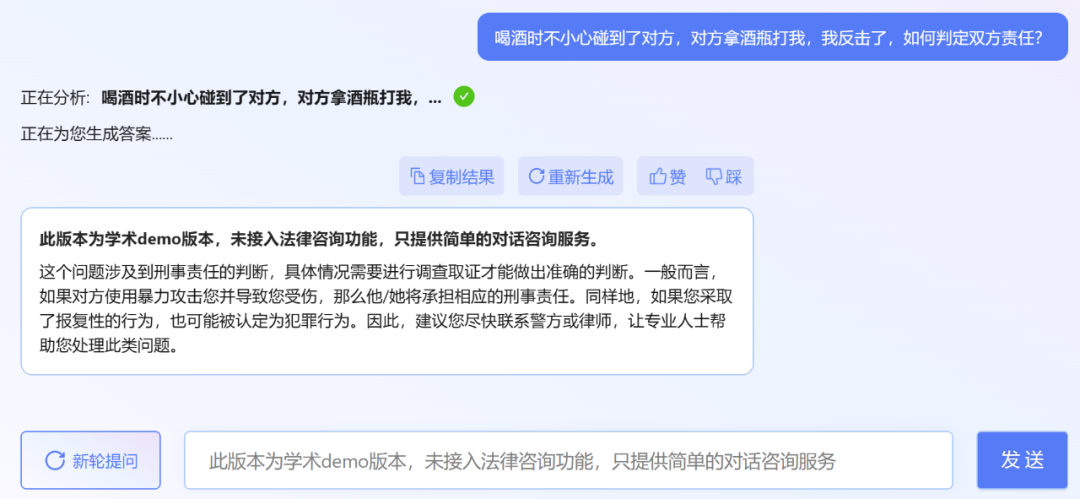
不過,小編發(fā)現(xiàn),ChatLaw 的學(xué)術(shù) demo 版本可以試用,遺憾的是沒有接入法律咨詢功能,只提供了簡單的對(duì)話咨詢服務(wù)。這里嘗試問了幾個(gè)問題。
其實(shí)最近發(fā)布法律大模型的不只有北大一家。上個(gè)月底,冪律智能聯(lián)合智譜 AI 發(fā)布了千億參數(shù)級(jí)法律垂直大模型 PowerLawGLM。據(jù)悉該模型針對(duì)中文法律場景的應(yīng)用效果展現(xiàn)出了獨(dú)特優(yōu)勢。
ChatLaw 的數(shù)據(jù)來源、訓(xùn)練框架首先是數(shù)據(jù)組成。ChatLaw 數(shù)據(jù)主要由論壇、新聞、法條、司法解釋、法律咨詢、法考題、判決文書組成,隨后經(jīng)過清洗、數(shù)據(jù)增強(qiáng)等來構(gòu)造對(duì)話數(shù)據(jù)。同時(shí),通過與北大國際法學(xué)院、行業(yè)知名律師事務(wù)所進(jìn)行合作,ChatLaw 團(tuán)隊(duì)能夠確保知識(shí)庫能及時(shí)更新,同時(shí)保證數(shù)據(jù)的專業(yè)性和可靠性。下面我們看看具體示例。
基于法律法規(guī)和司法解釋的構(gòu)建示例:

抓取真實(shí)法律咨詢數(shù)據(jù)示例:

律師考試多項(xiàng)選擇題的建構(gòu)示例:

然后是模型層面。為了訓(xùn)練 ChatLAW,研究團(tuán)隊(duì)在 Ziya-LLaMA-13B 的基礎(chǔ)上使用低秩自適應(yīng) (Low-Rank Adaptation, LoRA) 對(duì)其進(jìn)行了微調(diào)。此外,該研究還引入 self-suggestion 角色,來緩解模型產(chǎn)生幻覺問題。訓(xùn)練過程在多個(gè) A100 GPU 上進(jìn)行,并借助 deepspeed 進(jìn)一步降低了訓(xùn)練成本。
如下圖為 ChatLAW 架構(gòu)圖,該研究將法律數(shù)據(jù)注入模型,并對(duì)這些知識(shí)進(jìn)行特殊處理和加強(qiáng);與此同時(shí),他們也在推理時(shí)引入多個(gè)模塊,將通識(shí)模型、專業(yè)模型和知識(shí)庫融為一體。
該研究還在推理中對(duì)模型進(jìn)行了約束,這樣才能確保模型生成正確的法律法規(guī),盡可能減少模型幻覺。
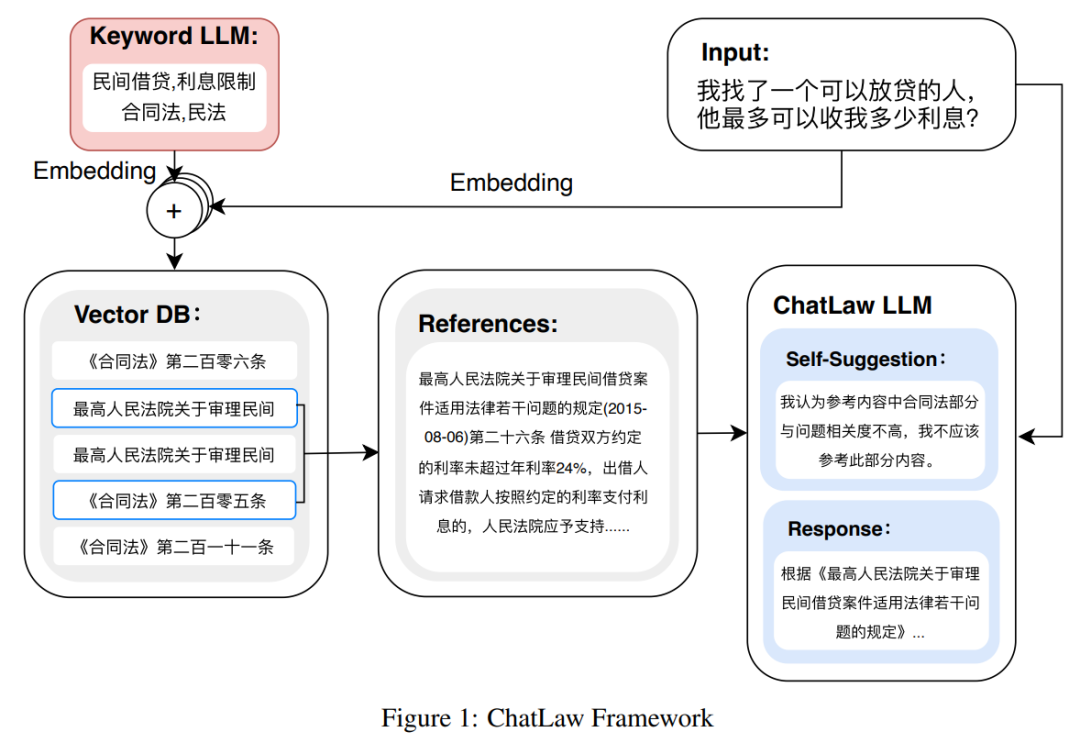
一開始研究團(tuán)隊(duì)嘗試傳統(tǒng)的軟件開發(fā)方法,如檢索時(shí)采用 MySQL 和 Elasticsearch,但結(jié)果不盡如人意。因而,該研究開始嘗試預(yù)訓(xùn)練 BERT 模型來進(jìn)行嵌入,然后使用 Faiss 等方法以計(jì)算余弦相似度,提取與用戶查詢相關(guān)的前 k 個(gè)法律法規(guī)。
當(dāng)用戶的問題模糊不清時(shí),這種方法通常會(huì)產(chǎn)生次優(yōu)的結(jié)果。因此,研究者從用戶查詢中提取關(guān)鍵信息,并利用該信息的向量嵌入設(shè)計(jì)算法,以提高匹配準(zhǔn)確性。
由于大型模型在理解用戶查詢方面具有顯著優(yōu)勢,該研究對(duì) LLM 進(jìn)行了微調(diào),以便從用戶查詢中提取關(guān)鍵字。在獲得多個(gè)關(guān)鍵字后,該研究采用算法 1 檢索相關(guān)法律規(guī)定。

實(shí)驗(yàn)結(jié)果該研究收集了十余年的國家司法考試題目,整理出了一個(gè)包含 2000 個(gè)問題及其標(biāo)準(zhǔn)答案的測試數(shù)據(jù)集,用以衡量模型處理法律選擇題的能力。
然而,研究發(fā)現(xiàn)各個(gè)模型的準(zhǔn)確率普遍偏低。在這種情況下,僅對(duì)準(zhǔn)確率進(jìn)行比較并無多大意義。因此,該研究借鑒英雄聯(lián)盟的 ELO 匹配機(jī)制,做了一個(gè)模型對(duì)抗的 ELO 機(jī)制,以便更有效地評(píng)估各模型處理法律選擇題的能力。以下分別是 ELO 分?jǐn)?shù)和勝率圖:
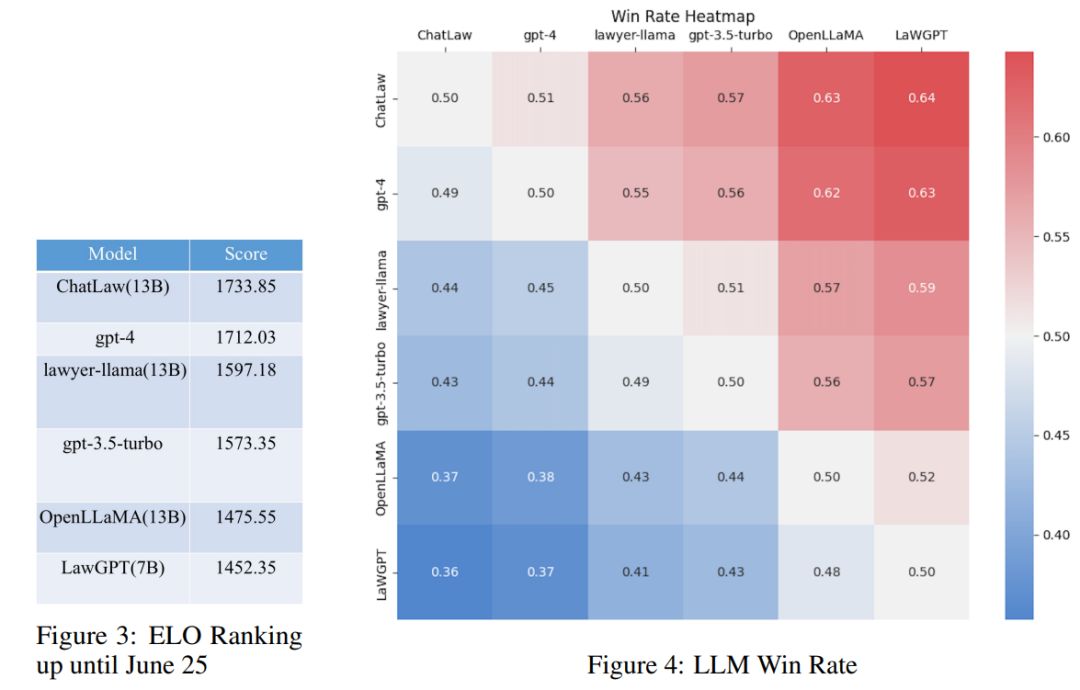
通過對(duì)上述實(shí)驗(yàn)結(jié)果的分析,我們可以得出以下觀察結(jié)果
(1)引入與法律相關(guān)的問答和法規(guī)條文的數(shù)據(jù),可以在一定程度上提高模型在選擇題上的表現(xiàn);
(2)加入特定類型任務(wù)的數(shù)據(jù)進(jìn)行訓(xùn)練,模型在該類任務(wù)上的表現(xiàn)會(huì)明顯提升。例如,ChatLaw 模型優(yōu)于 GPT-4 的原因是文中使用了大量的選擇題作為訓(xùn)練數(shù)據(jù);
(3)法律選擇題需要進(jìn)行復(fù)雜的邏輯推理,因此,參數(shù)量更大的模型通常表現(xiàn)更優(yōu)。參考知乎鏈接:
https://www.zhihu.com/question/610072848
3. 理解指向,說出坐標(biāo)!開源模型“Shikra”開啟多模態(tài)大模型“參考對(duì)話”新模式!
原文:https://mp.weixin.qq.com/s/wIkhAcHgqeQ3LA12J6oBnA
在人類的日常交流中,經(jīng)常會(huì)關(guān)注場景中不同的區(qū)域或物體,人們可以通過說話并指向這些區(qū)域來進(jìn)行高效的信息交換。這種交互模式被稱為參考對(duì)話(Referential Dialogue)。
如果 MLLM 擅長這項(xiàng)技能,它將帶來許多令人興奮的應(yīng)用。例如,將其應(yīng)用到 Apple Vision Pro 等混合現(xiàn)實(shí) (XR) 眼鏡中,用戶可以使用視線注視指示任何內(nèi)容與 AI 對(duì)話。同時(shí) AI 也可以通過高亮等形式來指向某些區(qū)域,實(shí)現(xiàn)與用戶的高效交流。
本文提出的 Shikra 模型,就賦予了 MLLM 這樣的參考對(duì)話能力,既可以理解位置輸入,也可以產(chǎn)生位置輸出。

-
論文地址:http://arxiv.org/abs/2306.15195
-
代碼地址:https://github.com/shikras/shikra
Shikra 能夠理解用戶輸入的 point/bounding box,并支持 point/bounding box 的輸出,可以和人類無縫地進(jìn)行參考對(duì)話。
Shikra 設(shè)計(jì)簡單直接,采用非拼接式設(shè)計(jì),不需要額外的位置編碼器、前 / 后目標(biāo)檢測器或外部插件模塊,甚至不需要額外的詞匯表。

如上圖所示,Shikra 能夠精確理解用戶輸入的定位區(qū)域,并能在輸出中引用與輸入時(shí)不同的區(qū)域進(jìn)行交流,像人類一樣通過對(duì)話和定位進(jìn)行高效交流。

如上圖所示,Shikra 不僅具備 LLM 所有的基本常識(shí),還能夠基于位置信息做出推理。

如上圖所示,Shikra 可以對(duì)圖片中正在發(fā)生的事情產(chǎn)生詳細(xì)的描述,并為參考的物體生成準(zhǔn)確的定位。

盡管 Shikra 沒有在 OCR 數(shù)據(jù)集上專門訓(xùn)練,但也具有基本的 OCR 能力。
更多例子

 其他傳統(tǒng)任務(wù)
其他傳統(tǒng)任務(wù) ?
?
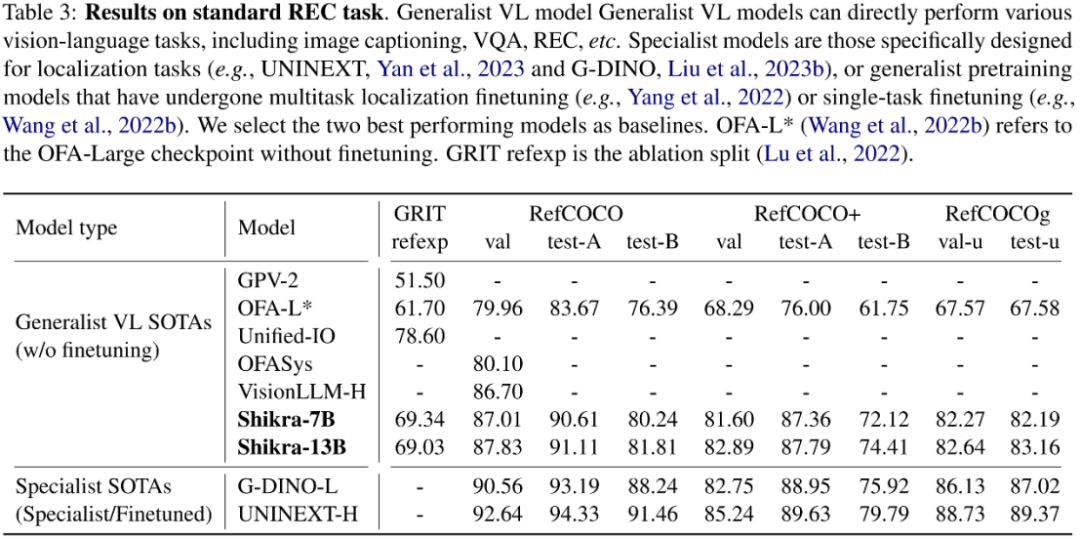
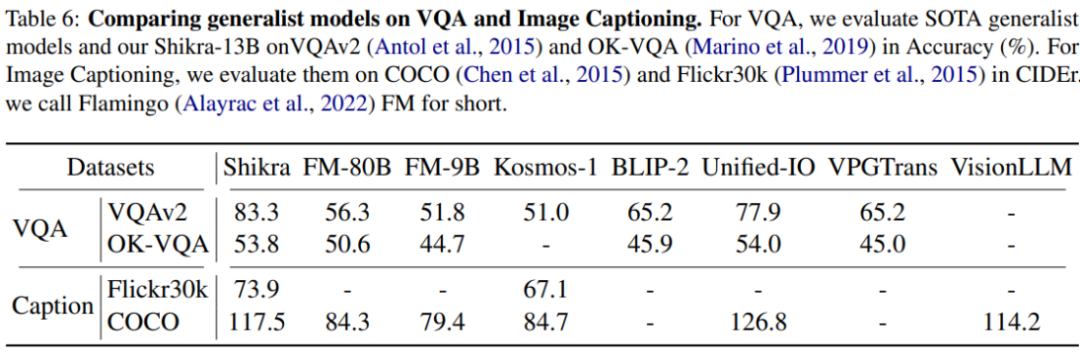
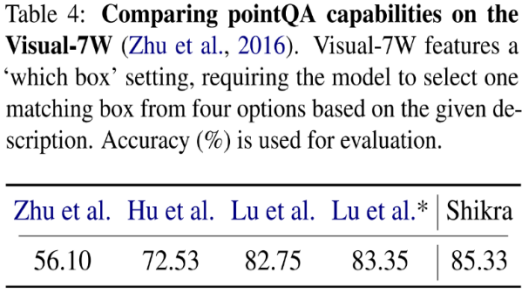
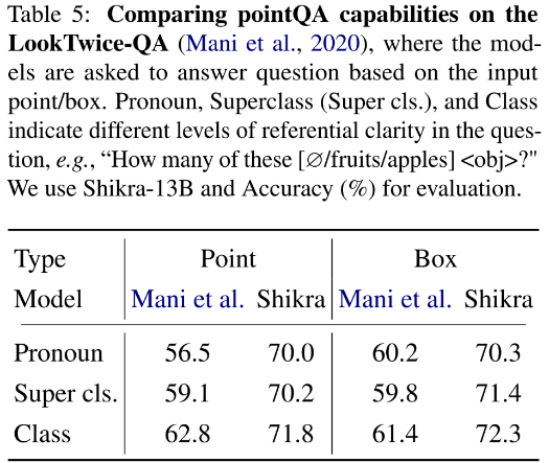
?模型架構(gòu)采用 CLIP ViT-L/14 作為視覺主干,Vicuna-7/13B 作為基語言模型,使用一層線性映射連接 CLIP 和 Vicuna 的特征空間。Shikra 直接使用自然語言中的數(shù)字來表示物體位置,使用 [xmin, ymin, xmax, ymax] 表示邊界框,使用 [xcenter, ycenter] 表示區(qū)域中心點(diǎn),區(qū)域的 xy 坐標(biāo)根據(jù)圖像大小進(jìn)行歸一化。每個(gè)數(shù)字默認(rèn)保留 3 位小數(shù)。這些坐標(biāo)可以出現(xiàn)在模型的輸入和輸出序列中的任何位置。記錄坐標(biāo)的方括號(hào)也自然地出現(xiàn)在句子中。Shikra 在傳統(tǒng) REC、VQA、Caption 任務(wù)上都能取得優(yōu)良表現(xiàn)。同時(shí)在 PointQA-Twice、Point-V7W 等需要理解位置輸入的 VQA 任務(wù)上取得了 SOTA 結(jié)果。
?
?
?模型架構(gòu)采用 CLIP ViT-L/14 作為視覺主干,Vicuna-7/13B 作為基語言模型,使用一層線性映射連接 CLIP 和 Vicuna 的特征空間。Shikra 直接使用自然語言中的數(shù)字來表示物體位置,使用 [xmin, ymin, xmax, ymax] 表示邊界框,使用 [xcenter, ycenter] 表示區(qū)域中心點(diǎn),區(qū)域的 xy 坐標(biāo)根據(jù)圖像大小進(jìn)行歸一化。每個(gè)數(shù)字默認(rèn)保留 3 位小數(shù)。這些坐標(biāo)可以出現(xiàn)在模型的輸入和輸出序列中的任何位置。記錄坐標(biāo)的方括號(hào)也自然地出現(xiàn)在句子中。Shikra 在傳統(tǒng) REC、VQA、Caption 任務(wù)上都能取得優(yōu)良表現(xiàn)。同時(shí)在 PointQA-Twice、Point-V7W 等需要理解位置輸入的 VQA 任務(wù)上取得了 SOTA 結(jié)果。
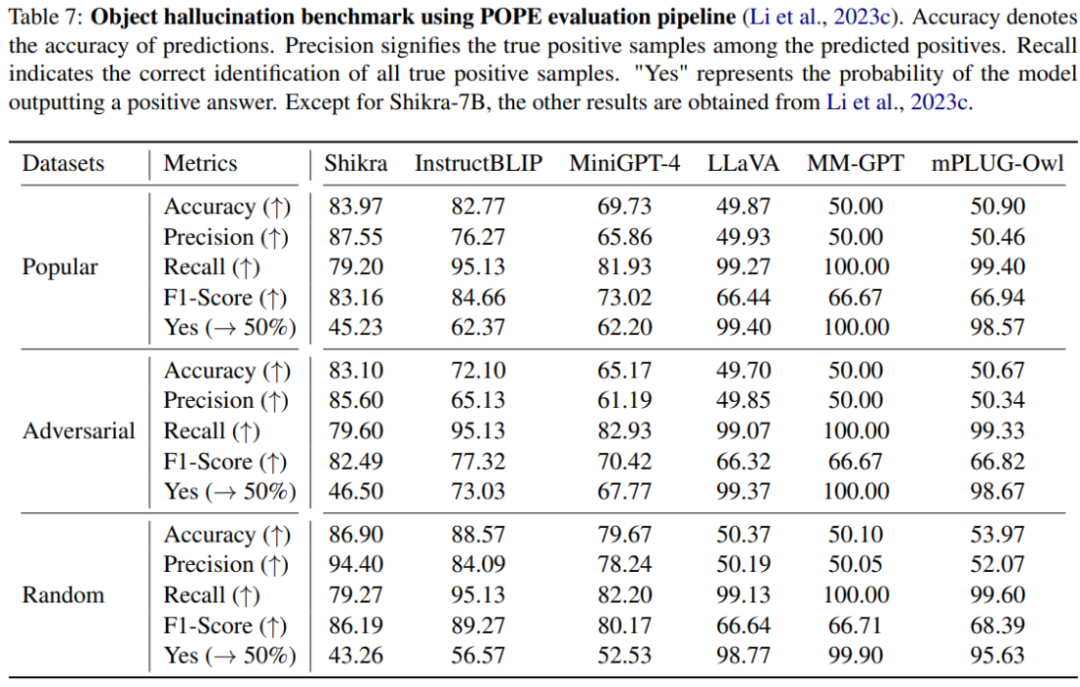
本文使用 POPE benchmark 評(píng)估了 Shikra 產(chǎn)生幻覺的程度。Shikra 得到了和 InstrcutBLIP 相當(dāng)?shù)慕Y(jié)果,并遠(yuǎn)超近期其他 MLLM。
 思想鏈(CoT),旨在通過在最終答案前添加推理過程以幫助 LLM 回答復(fù)雜的 QA 問題。這一技術(shù)已被廣泛應(yīng)用到自然語言處理的各種任務(wù)中。然而如何在多模態(tài)場景下應(yīng)用 CoT 則尚待研究。尤其因?yàn)槟壳暗?MLLM 還存在嚴(yán)重的幻視問題,CoT 經(jīng)常會(huì)產(chǎn)生幻覺,影響最終答案的正確性。通過在合成數(shù)據(jù)集 CLEVR 上的實(shí)驗(yàn),研究發(fā)現(xiàn),使用帶有位置信息的 CoT 時(shí),可以有效減少模型幻覺提高模型性能。
思想鏈(CoT),旨在通過在最終答案前添加推理過程以幫助 LLM 回答復(fù)雜的 QA 問題。這一技術(shù)已被廣泛應(yīng)用到自然語言處理的各種任務(wù)中。然而如何在多模態(tài)場景下應(yīng)用 CoT 則尚待研究。尤其因?yàn)槟壳暗?MLLM 還存在嚴(yán)重的幻視問題,CoT 經(jīng)常會(huì)產(chǎn)生幻覺,影響最終答案的正確性。通過在合成數(shù)據(jù)集 CLEVR 上的實(shí)驗(yàn),研究發(fā)現(xiàn),使用帶有位置信息的 CoT 時(shí),可以有效減少模型幻覺提高模型性能。
4. 圖視覺模型崛起 | MobileViG同等精度比MobileNetv2快4倍,同等速度精度高4%!
原文:https://mp.weixin.qq.com/s/gstvrGg2wHnFyTRXd_cT_A

傳統(tǒng)上,卷積神經(jīng)網(wǎng)絡(luò)(CNN)和Vision Transformer(ViT)主導(dǎo)了計(jì)算機(jī)視覺。然而,最近提出的Vision Graph神經(jīng)網(wǎng)絡(luò)(ViG)為探索提供了一條新的途徑。不幸的是,對(duì)于移動(dòng)端應(yīng)用程序來說,由于將圖像表示為圖結(jié)構(gòu)的開銷,ViG在計(jì)算上是比較耗時(shí)的。 在這項(xiàng)工作中,作者提出了一種新的基于圖的稀疏注意力機(jī)制,即稀疏Vision Graph注意力(SVGA),該機(jī)制是為在移動(dòng)端設(shè)備上運(yùn)行的ViG設(shè)計(jì)的。此外,作者提出了第一個(gè)用于移動(dòng)端設(shè)備上視覺任務(wù)的混合CNN-GNN架構(gòu)MobileViG,該架構(gòu)使用SVGA。 大量實(shí)驗(yàn)表明,MobileViG在圖像分類、目標(biāo)檢測和實(shí)例分割任務(wù)的準(zhǔn)確性和/或速度方面優(yōu)于現(xiàn)有的ViG模型以及現(xiàn)有的移動(dòng)端CNN和ViT架構(gòu)。作者最快的模型MobileViG-Ti在ImageNet-1K上實(shí)現(xiàn)了75.7%的Top-1準(zhǔn)確率,在iPhone 13 Mini NPU(使用CoreML編譯)上實(shí)現(xiàn)了0.78 ms 的推理延遲,這比MobileNetV2x1.4(1.02 ms ,74.7%Top-1)和MobileNetV2x1.0(0.81 ms ,71.8%Top-1。作者最大的模型MobileViG-B僅用2.30 ms 的延遲就獲得了82.6%的Top-1準(zhǔn)確率,這比類似規(guī)模的EfficientFormer-L3模型(2.77 ms ,82.4%)更快、更準(zhǔn)確。 作者的工作證明,設(shè)計(jì)良好的混合CNN-GNN架構(gòu)可以成為在移動(dòng)端設(shè)備上設(shè)計(jì)快速準(zhǔn)確模型的新探索途徑。 代碼:https://github.com/SLDGroup/MobileViG
1. 簡介
人工智能(AI)和機(jī)器學(xué)習(xí)(ML)在過去十年中取得了爆炸式的增長。在計(jì)算機(jī)視覺中,這種增長背后的關(guān)鍵驅(qū)動(dòng)力是神經(jīng)網(wǎng)絡(luò)的重新出現(xiàn),尤其是卷積神經(jīng)網(wǎng)絡(luò)(CNNs)和最近的視覺Transformer。盡管通過反向傳播訓(xùn)練的神經(jīng)網(wǎng)絡(luò)是在20世紀(jì)80年代發(fā)明的,但它們被用于更小規(guī)模的任務(wù),如字符識(shí)別。直到AlexNet被引入ImageNet競賽,神經(jīng)網(wǎng)絡(luò)reshape人工智能領(lǐng)域的潛力才得以充分實(shí)現(xiàn)。
CNN架構(gòu)的進(jìn)一步進(jìn)步提高了其準(zhǔn)確性、效率和速度。與CNN架構(gòu)一樣,多層感知器(MLP)架構(gòu)和類MLP架構(gòu)也有望成為通用視覺任務(wù)的Backbone。
盡管神經(jīng)網(wǎng)絡(luò)和MLP已在計(jì)算機(jī)視覺中得到廣泛應(yīng)用,但由于視覺和語言任務(wù)之間的差異,自然語言處理領(lǐng)域使用了遞歸神經(jīng)網(wǎng)絡(luò)(RNN),特別是長短期記憶(LSTM)網(wǎng)絡(luò)。盡管LSTM仍在使用,但在NLP任務(wù)中,它們在很大程度上已被Transformer架構(gòu)所取代。隨著視覺Transformer(ViT)的引入,引入了一種適用于語言和視覺領(lǐng)域的網(wǎng)絡(luò)架構(gòu)。通過將圖像分割成patch嵌入序列,可以將圖像轉(zhuǎn)換為Transformer模塊可用的輸入。與神經(jīng)網(wǎng)絡(luò)或MLP相比,Transformer架構(gòu)的主要優(yōu)勢之一是其全局感受野,使其能夠從圖像中的遠(yuǎn)距離物體交互中學(xué)習(xí)。
圖神經(jīng)網(wǎng)絡(luò)(GNN)已發(fā)展為在基于圖的結(jié)構(gòu)上運(yùn)行,如生物網(wǎng)絡(luò)、社交網(wǎng)絡(luò)或引文網(wǎng)絡(luò)。GNN甚至被提議用于節(jié)點(diǎn)分類、藥物發(fā)現(xiàn)、欺詐檢測等任務(wù),以及最近提出的視覺GNN(ViG)的計(jì)算機(jī)視覺任務(wù)。簡言之,ViG將圖像劃分為多個(gè)patch,然后通過K近鄰(KNN)算法連接這些patch,從而提供了處理類似于ViT的全局目標(biāo)交互的能力。
移動(dòng)端應(yīng)用的計(jì)算機(jī)視覺研究快速增長,導(dǎo)致了使用神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)空間局部表示和使用Vision Transformer(ViT)學(xué)習(xí)全局表示的混合架構(gòu)。當(dāng)前的ViG模型不適合移動(dòng)端任務(wù),因?yàn)樗鼈冊谝苿?dòng)端設(shè)備上運(yùn)行時(shí)效率低且速度慢。可以探索從CNN和ViT模型的設(shè)計(jì)中學(xué)到的概念,以確定CNN-GNN混合模型是否能夠提供基于CNN的模型的速度以及基于ViT的模型的準(zhǔn)確性。
在這項(xiàng)工作中,作者研究了用于移動(dòng)端設(shè)備上計(jì)算機(jī)視覺的混合CNN-GNN架構(gòu),并開發(fā)了一種可以與現(xiàn)有高效架構(gòu)競爭的基于圖形的注意力機(jī)制。作者的貢獻(xiàn)總結(jié)如下:
-
作者提出了一種新的基于圖的稀疏注意力方法,用于移動(dòng)端視覺。作者稱作者的注意力方法為稀疏Vision Graph注意力(SVGA)。作者的方法是輕量級(jí)的,因?yàn)榕c以前的方法相比,它不需要重新reshape,并且在圖構(gòu)建中幾乎沒有開銷。
-
作者使用作者提出的SVGA、最大相對(duì)圖卷積以及來自移動(dòng)端CNN和移動(dòng)端視覺Transformer架構(gòu)的概念(作者稱之為MobileViG),為視覺任務(wù)提出了一種新的移動(dòng)端CNN-GNN架構(gòu)。
-
作者提出的模型MobileViG在3個(gè)具有代表性的視覺任務(wù)(ImageNet圖像分類、COCO目標(biāo)檢測和COCO實(shí)例分割)上的準(zhǔn)確性和/或速度與現(xiàn)有的Vision Graph神經(jīng)網(wǎng)絡(luò)(ViG)、移動(dòng)端卷積神經(jīng)網(wǎng)絡(luò)(CNN)和移動(dòng)端Vision Transformer(ViT)架構(gòu)類似或者更優(yōu)的性能。
據(jù)作者所知,作者是第一個(gè)研究用于移動(dòng)端視覺應(yīng)用的混合CNN-GNN架構(gòu)的算法。作者提出的SVGA注意力方法和MobileViG架構(gòu)為最先進(jìn)的移動(dòng)端架構(gòu)和ViG架構(gòu)開辟了一條新的探索之路。
2. 相關(guān)工作
ViG被提議作為神經(jīng)網(wǎng)絡(luò)和ViT的替代方案,因?yàn)樗軌蛞愿`活的格式表示圖像數(shù)據(jù)。ViG通過使用KNN算法來表示圖像,其中圖像中的每個(gè)像素都關(guān)注相似的像素。ViG的性能與流行的ViT模型DeiT和SwinTransformer相當(dāng),這表明它值得進(jìn)一步研究。
盡管基于ViT的模型在視覺任務(wù)中取得了成功,但與基于CNN的輕量級(jí)模型相比,它們?nèi)匀惠^慢,相比之下,基于CNN的模型缺乏基于ViT模型的全局感受域。因此,通過提供比基于ViT的模型更快的速度和比基于CNN的模型更高的精度,基于ViG的模型可能是一種可能的解決方案。據(jù)作者所知,目前還沒有關(guān)于移動(dòng)端ViG的作品;然而,在移動(dòng)端CNN和混合模型領(lǐng)域,已有許多工作。作者將移動(dòng)端架構(gòu)設(shè)計(jì)分為兩大類:卷積神經(jīng)網(wǎng)絡(luò)(CNN)模型和混合CNN-ViT模型,它們?nèi)诤狭薈NNs和ViT的元素。
基于CNN架構(gòu)的MobileNetv2和EfficientNet系列是首批在常見圖像任務(wù)中取得成功的移動(dòng)端模型。這些模型輕,推理速度快。然而,純粹基于CNN的模型已經(jīng)被混合模型競爭對(duì)手穩(wěn)步取代。
有大量的混合移動(dòng)端模型,包括MobileViTv2、EdgeViT、LeViT和EfficientFormerv2。這些混合模型在圖像分類、目標(biāo)檢測和實(shí)例分割任務(wù)方面始終優(yōu)于MobileNetv2,但其中一些模型在延遲方面并不總是表現(xiàn)良好。延遲差異可能與包含ViT塊有關(guān),ViT塊在移動(dòng)端硬件上的速度傳統(tǒng)上較慢。
為了改善這種狀況,作者提出了MobileViG,它提供了與MobileNetv2相當(dāng)?shù)乃俣群团cEfficientFormer相當(dāng)?shù)木取?/span>
3. 文本方法
在本節(jié)中,作者將描述SVGA算法,并提供有關(guān)MobileViG架構(gòu)設(shè)計(jì)的詳細(xì)信息。更確切地說,第3.1節(jié)描述了SVGA算法。第3.2節(jié)解釋了作者如何調(diào)整ViG中的Graper模塊來創(chuàng)建SVGA塊。第3.3節(jié)描述了作者如何將SVGA塊與反向殘差塊結(jié)合起來進(jìn)行局部處理,以創(chuàng)建MobileViGTi、MobileViG-S、MobileVeg-M和MobileViG-B。
3.1. Sparse Vision Graph Attention
作者提出稀疏Vision Graph注意力(SVGA)作為Vision GNN中KNN圖注意力的一種移動(dòng)端友好的替代方案。基于KNN的圖注意力引入了2個(gè)非移動(dòng)端友好組件,KNN計(jì)算和輸入reshape,作者用SVGA去除了這兩個(gè)組件。
更詳細(xì)地說,每個(gè)輸入圖像都需要KNN計(jì)算,因?yàn)椴荒芴崆爸烂總€(gè)像素的最近鄰居。這產(chǎn)生了一個(gè)具有看似隨機(jī)連接的圖,如圖1a所示。由于KNN的非結(jié)構(gòu)化性質(zhì),KNN的作者將輸入圖像從4D張量reshape為3D張量,使他們能夠正確對(duì)齊連接像素的特征,用于圖卷積。在圖形卷積之后,對(duì)于隨后的卷積層,必須將輸入從3D重新reshape為4D。因此,基于KNN的注意力需要KNN計(jì)算和2次reshape操作,這兩種操作在移動(dòng)端設(shè)備上都是比較耗時(shí)的。
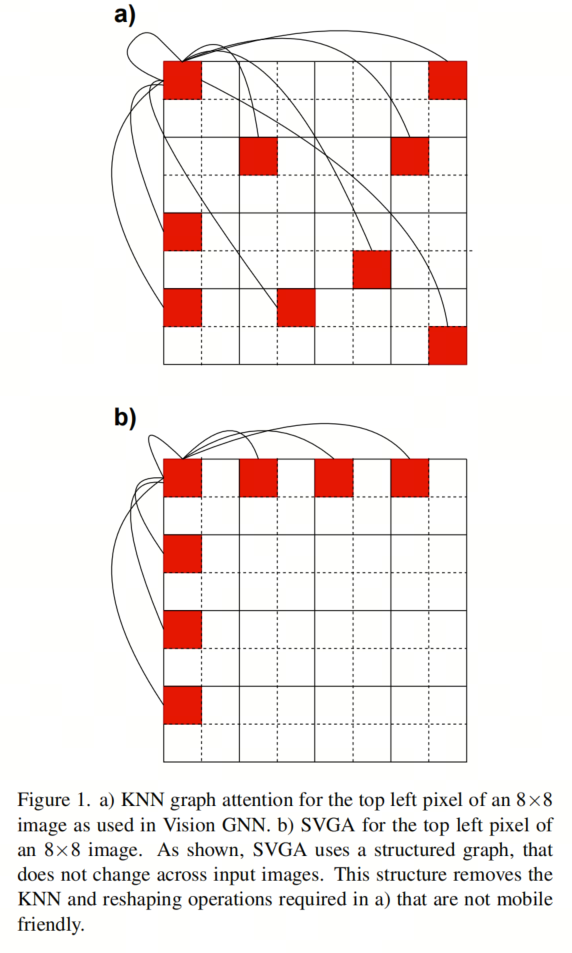
為了消除KNN計(jì)算和reshape操作的開銷,SVGA假設(shè)一個(gè)固定圖,其中每個(gè)像素都連接到其行和列中的第K個(gè)像素。例如,給定一個(gè)8×8的圖像和K=2,左上角的像素將連接到其行上的每一個(gè)像素和列下的每一個(gè)像素,如圖1b所示。對(duì)于輸入圖像中的每個(gè)像素重復(fù)這種相同的圖案。由于圖具有固定的結(jié)構(gòu)(即,對(duì)于所有8×8個(gè)輸入圖像,每個(gè)像素都具有相同的連接),因此不必對(duì)輸入圖像進(jìn)行reshape來執(zhí)行圖卷積。
相反,它可以使用跨越兩個(gè)圖像維度的滾動(dòng)操作來實(shí)現(xiàn),在算法1中表示為roll-right和roll-down。滾轉(zhuǎn)操作的第一個(gè)參數(shù)是滾轉(zhuǎn)的輸入,第二個(gè)參數(shù)是向右或向下滾轉(zhuǎn)的距離。使用圖1b中K=2的示例,通過向右滾動(dòng)圖像兩次、向右滾動(dòng)四次和向右滾動(dòng)六次,可以將左上角像素與其行中的第二個(gè)像素對(duì)齊。除了向下滾動(dòng)之外,可以對(duì)其列中的每一個(gè)像素執(zhí)行相同的操作。

請(qǐng)注意,由于每個(gè)像素都以相同的方式連接,因此用于將左上角像素與其連接對(duì)齊的滾動(dòng)操作同時(shí)將圖像中的其他每個(gè)像素與其連接對(duì)準(zhǔn)。在MobileViG中,使用最大相對(duì)圖卷積(MRConv)來執(zhí)行圖卷積。因此,在每次向右滾動(dòng)和向下滾動(dòng)操作之后,計(jì)算原始輸入圖像和滾動(dòng)版本之間的差,在算法1中表示為Xr和Xc,并且按元素進(jìn)行最大運(yùn)算并存儲(chǔ)在Xj中,也在算法1表示。在完成滾動(dòng)和最大相對(duì)操作之后,執(zhí)行最終的Conv2d。通過這種方法,SVGA將KNN計(jì)算換成了更便宜的滾動(dòng)操作,因此不需要reshape來執(zhí)行圖卷積。
作者注意到,SVGA避開了KNN的表示靈活性,而傾向于移動(dòng)端友好。
3.2. SVGA Block
作者將SVGA和更新后的MRConv層插入到Vision GNN中提出的捕獲器塊中。給定一個(gè)輸入特征,更新后的圖形處理器表示為
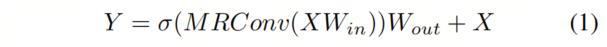
作者還在MRConv步驟中將濾波器組的數(shù)量從4(Vision GNN中使用的值)更改為1,以增加MRConv層的表達(dá)潛力,而不會(huì)顯著增加延遲。更新后的Graper模塊如圖2d所示。
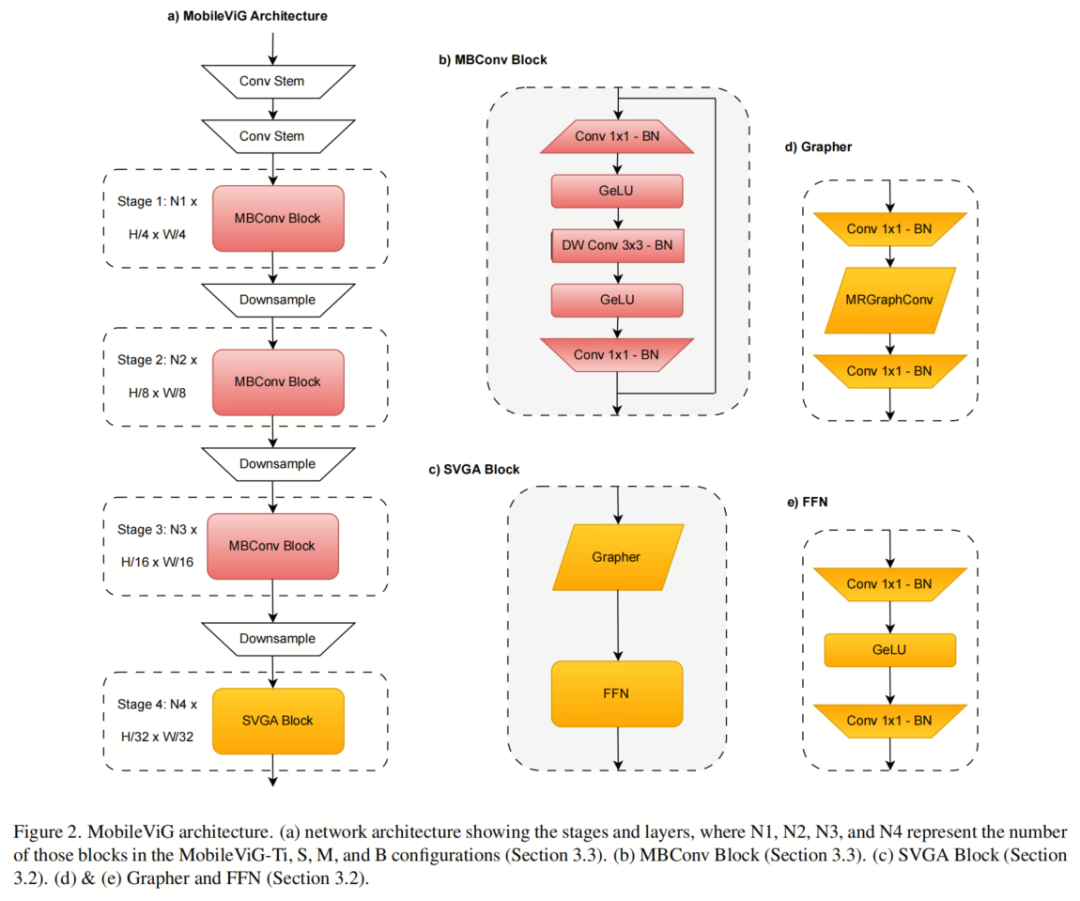
在更新的Graper之后,作者使用了Vision GNN中提出的前饋網(wǎng)絡(luò)(FFN)模塊,如圖2e所示。FFN模塊是一個(gè)兩層MLP,表示為
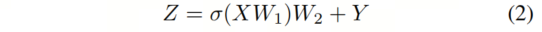
3.3. MobileViG Architecture
圖2a中所示的MobileViG架構(gòu)由卷積Backbone組成,然后是3級(jí)反向殘差塊(MBConv),其擴(kuò)展比為4,用于MobileNetv2中提出的局部處理。在MBConv塊中,作者將ReLU6替換為GeLU,因?yàn)樗驯蛔C明可以提高計(jì)算機(jī)視覺任務(wù)的性能。MBConv塊由1×1卷積加批量歸一化(BN)和GeLU、深度3×3卷積加BN和GeLU組成,最后是1×1卷積加BN和殘差連接,如圖2b所示。
在MBConv塊之后,作者使用一個(gè)Stage的SVGA塊來捕獲全局信息,如圖2a所示。作者在SVGA塊之后還有一個(gè)卷積頭用于分類。在每個(gè)MBConv階段之后,下采樣步驟將輸入分辨率減半并擴(kuò)展通道維度。每個(gè)階段由多個(gè)MBConv或SVGA塊組成,其中重復(fù)次數(shù)根據(jù)模型大小而變化。
MobileViG-Ti、MobileViG-S、MobileViG-M和MobileViG-B的通道尺寸和每個(gè)階段重復(fù)的塊的數(shù)量可以在表1中看到。
4. 實(shí)驗(yàn)
4.1. 圖像分類
作者使用PyTorch 1.12和Timm庫實(shí)現(xiàn)了該模型。作者使用8個(gè)NVIDIA A100 GPU來訓(xùn)練每個(gè)模型,有效批量大小為1024。這些模型是用AdamW優(yōu)化器在ImageNet-1K上從頭開始訓(xùn)練300個(gè)Epoch的。使用余弦退火策略將學(xué)習(xí)率設(shè)置為2e-3。作者使用標(biāo)準(zhǔn)圖像分辨率224×224進(jìn)行訓(xùn)練和測試。
與DeiT類似,作者使用RegNetY-16GF進(jìn)行知識(shí)蒸餾,Top-1準(zhǔn)確率為82.9%。對(duì)于數(shù)據(jù)擴(kuò)充,作者使用RandAugment、Mixup、Cutmix、隨機(jī)擦除和重復(fù)擴(kuò)充。
作者使用iPhone 13 Mini(iOS 16)在NPU和GPU上測試延遲。這些模型是用CoreML編譯的,延遲平均超過1000個(gè)預(yù)測。
如表2所示,對(duì)于類似數(shù)量的參數(shù),MobileViG在準(zhǔn)確性和GPU延遲方面都優(yōu)于Pyramid ViG。例如,對(duì)于3.5 M以下的參數(shù),MobileViG-S在Top-1的精度上與Pyramid-ViG-Ti匹配,同時(shí)速度快2.83倍。此外,在參數(shù)減少0.6 M的情況下,MobileViG-B在Top-1的準(zhǔn)確率上擊敗Pyramid-ViG-S 0.5%,同時(shí)速度快2.08倍。
與表3中的移動(dòng)端模型相比,MobileViG至少在NPU延遲、GPU延遲或準(zhǔn)確性方面始終優(yōu)于所有模型。MobileViG-Ti比MobileNetv2更快,Top-1的準(zhǔn)確率高3.9%。它還與Top-1的EfficientFormerv2相匹配,同時(shí)在NPU和GPU延遲方面略有優(yōu)勢。
MobileViG-S在NPU延遲方面比EfficientNet-B0快近兩倍,并比Top-1的準(zhǔn)確率高0.5%。與MobileViTv2-1.5相比,MobileViG-M的NPU延遲快3倍以上,GPU延遲快2倍,Top-1精度高0.2%。此外,MobileViG-B比DeiT-S快6倍,能夠在Top-1的精度上擊敗DeiT-S和Swin Tiny。
4.2. 目標(biāo)檢測和實(shí)例分割
作者在目標(biāo)檢測和實(shí)例分割任務(wù)上評(píng)估了MobileViG,以進(jìn)一步證明SVGA的潛力。作者在Mask RCNN中集成了MobileViG作為Backbone,并使用MS COCO 2017數(shù)據(jù)集進(jìn)行了實(shí)驗(yàn)。作者使用PyTorch 1.12和Timm庫實(shí)現(xiàn)了Backbone,并使用4個(gè)NVIDIA RTX A6000 GPU來訓(xùn)練作者的模型。
作者使用來自300個(gè)訓(xùn)練Epoch的預(yù)訓(xùn)練ImageNet-1k權(quán)重初始化模型,使用初始學(xué)習(xí)率為2e-4的AdamW優(yōu)化器,并按照NextViT、EfficientFormer和EfficientFormerV2的過程,以標(biāo)準(zhǔn)分辨率(1333 X 800)訓(xùn)練12個(gè)Epoch的模型。
如表4所示,在相似的模型大小下,MobileViG在目標(biāo)檢測和/或?qū)嵗指罘矫娴膮?shù)或改進(jìn)的平均精度(AP)方面優(yōu)于ResNet、PoolFormer、EfficientFormer和PVT。中等規(guī)模的模型MobileViG-M模型在目標(biāo)檢測任務(wù)上獲得41.3 APbox,當(dāng)50IoU時(shí)獲得62.8 APbox, 而當(dāng)IOU75時(shí)獲得45.1 APbox.
MobileViG的設(shè)計(jì)部分靈感來自Pyramid-ViG、EfficientFormer和MetaFormer的設(shè)計(jì)。在MobileViG中獲得的結(jié)果表明,混合CNN-GNN架構(gòu)是CNN、ViT和混合CNN-ViT設(shè)計(jì)的可行替代方案。混合CNN-GNN架構(gòu)可以提供基于CNN的模型的速度以及ViT模型的準(zhǔn)確性,使其成為高精度移動(dòng)端架構(gòu)設(shè)計(jì)的理想候選者。進(jìn)一步探索用于移動(dòng)端計(jì)算機(jī)視覺任務(wù)的混合CNN-GNN架構(gòu)可以改進(jìn)MobileViG概念,并引入新的最先進(jìn)的架構(gòu)。
5. 參考
[1].MobileViG: Graph-Based Sparse Attention for Mobile Vision Applications.
5. 重磅,GPT-4 API 全面開放使用!
原文:https://mp.weixin.qq.com/s/UrRtcvBIVzD_l-SXIjAxPQ
遙想今年 3 月剛推出 GPT-4 的 OpenAI 僅邀請(qǐng)了部分提交申請(qǐng)的開發(fā)者參與測試。眼瞅 OpenAI 聯(lián)合創(chuàng)始人 Greg Brockman 在當(dāng)時(shí)現(xiàn)場演示“史上最為強(qiáng)大”的 GPT-4 模型,輕松通過一張手繪草圖生成一個(gè)網(wǎng)站、60 秒就能搞定一個(gè)小游戲開發(fā)等這些功能,一眾開發(fā)者卻不能使用。
而就在今天,GPT-4 的適用性進(jìn)一步被拓展。OpenAI 正式發(fā)布 GPT-4 API,現(xiàn)對(duì)所有付費(fèi) API 的開發(fā)者全面開放!

1. OpenAI 路線圖:本月底前向新開發(fā)者拓展推出 GPT-4
在上線的這四個(gè)月里,相信很多人通過技術(shù)解析論文(https://cdn.openai.com/papers/gpt-4.pdf),對(duì)于 GPT-4 也不太陌生。

據(jù) OpenAI 透露,自今年 3 月份發(fā)布 GPT-4 以來,數(shù)以百萬計(jì)的開發(fā)者要求訪問 GPT-4 API,且利用 GPT-4 的創(chuàng)新產(chǎn)品的范圍每天都在增長。
與其前身 GPT-3.5 相比,GPT-4 的不同之處在于它增強(qiáng)了生成文本(包括代碼)的能力,同時(shí)還接受圖像和文本輸入。
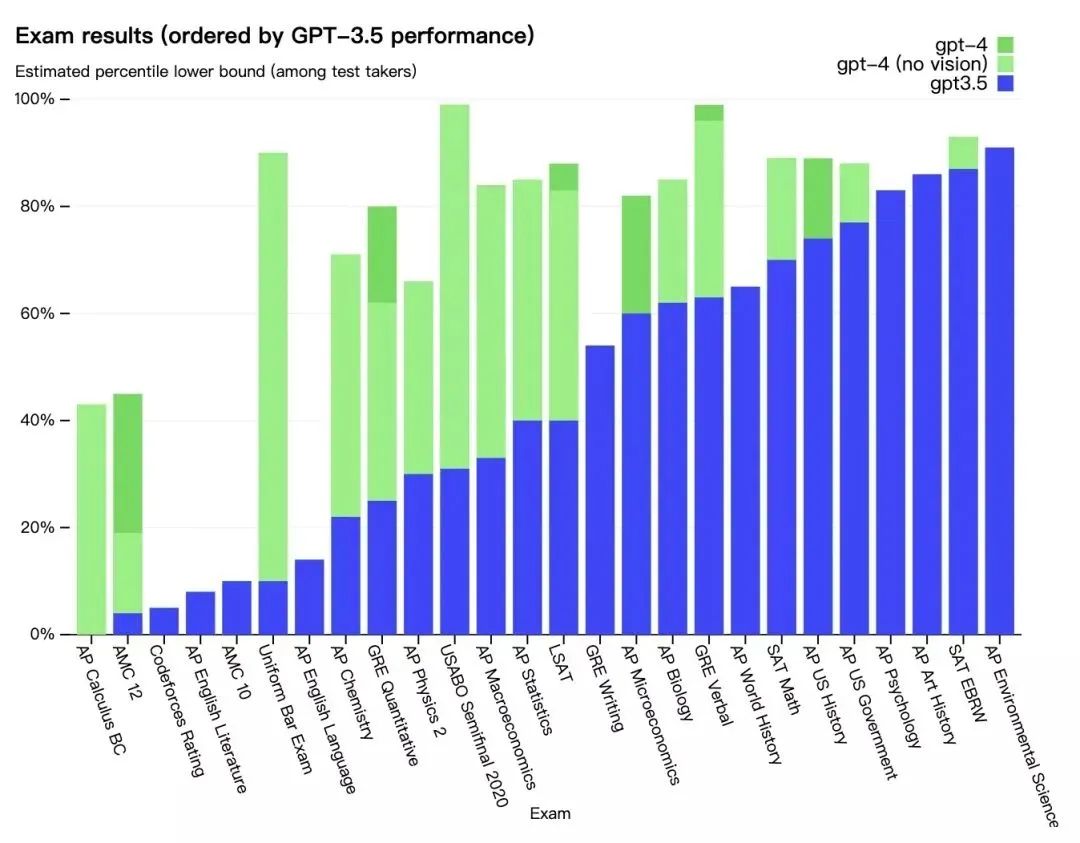
該模型在各種專業(yè)和學(xué)術(shù)基準(zhǔn)上表現(xiàn)出“人類水平”。此前,OpenAI 研究人員也做過測試,稱,如果 GPT-4 是一個(gè)僅憑應(yīng)試能力來判斷的人,它可以進(jìn)入法學(xué)院,而且很可能也能進(jìn)入許多大學(xué)。
與 OpenAI 以前的 GPT 模型一樣,GPT-4 是使用公開的數(shù)據(jù)進(jìn)行訓(xùn)練的,包括來自公共網(wǎng)頁的數(shù)據(jù),以及 OpenAI 授權(quán)的數(shù)據(jù)。從技術(shù)維度上來看,GPT-4 是一個(gè)基于 Transformer 的模型,經(jīng)過預(yù)訓(xùn)練,可以預(yù)測文檔中的下一個(gè) token。這個(gè)項(xiàng)目的一個(gè)核心部分是開發(fā)了基礎(chǔ)設(shè)施和優(yōu)化方法。這使 OpenAI 能夠根據(jù)不超過 GPT-4 的 1/1000 的計(jì)算量訓(xùn)練的模型,準(zhǔn)確地預(yù)測 GPT-4 的某些方面的性能。
不過,目前有些遺憾的是,圖像理解能力還沒有提供給所有 OpenAI 用戶。還是像今年 3 月份 OpenAI 宣布的那樣,它只是與其合作伙伴 Be My Eyes 進(jìn)行測試。截至目前,OpenAI 還沒有表明何時(shí)會(huì)向更廣泛的用戶群開放圖像理解能力。
現(xiàn)如今,所有具有成功付費(fèi)記錄的 API 開發(fā)者都可以訪問具有 8K 上下文的 GPT-4 API,當(dāng)然,這一次還不能訪問 32 K 上下文的。
同時(shí),OpenAI 也有計(jì)劃在本月底向新的開發(fā)者開放訪問權(quán)限,然后根據(jù)計(jì)算的可用性,開始提高速率限制。
值得注意的是,雖然 GPT-4 代表了生成式 AI 模型發(fā)展的一個(gè)重要里程碑,但是這并不意味著它是 100% 完美的。就 GPT-4 而言,它還有可能產(chǎn)生“幻覺”,并理直氣壯地犯一些推理性錯(cuò)誤。
在未來,OpenAI 表示也正在努力為 GPT-4 和 GPT-3.5 Turbo 安全地啟用微調(diào)功能,預(yù)計(jì)這一功能將在今年晚些時(shí)候推出。
2. Chat Completions API
在公告中,OpenAI 還宣布將普遍向開發(fā)者提供 GPT-3.5 Turbo、DALL-E 和 Whisper APIs。
同時(shí)也向開發(fā)者分享了目前廣泛使用的 Chat Completions API 現(xiàn)狀。OpenAI 表示,現(xiàn)在 Chat Completions API 占了其 API GPT 使用量的 97%。
OpenAI 指出,最初的 Completions API 是在 2020 年 6 月推出的,為語言模型進(jìn)行互動(dòng)提供了一個(gè)自由格式的文本提示。
Chat Completions API 的結(jié)構(gòu)化界面(如系統(tǒng)消息、功能調(diào)用)和多輪對(duì)話能力能夠使開發(fā)者能夠建立對(duì)話體驗(yàn)和廣泛的完成任務(wù),同時(shí)降低提示注入攻擊的風(fēng)險(xiǎn),因?yàn)橛脩籼峁┑膬?nèi)容可以從結(jié)構(gòu)上與指令分開。

OpenAI 表示,當(dāng)前也正在彌補(bǔ) Chat Completions API 的幾個(gè)不足之處,例如completion token 的日志概率和增加可引導(dǎo)性,以減少回應(yīng)的 "聊天性"。
3. 舊模型的廢棄
另外,OpenAI 也發(fā)布了舊模型的棄用計(jì)劃。即從 2024 年 1 月 4 日開始,某些舊的 OpenAI 模型,特別是 GPT-3 及其衍生模型都將不再可用,并將被新的 "GPT-3 基礎(chǔ)"模型所取代,新的模型計(jì)算效率會(huì)更高。
根據(jù)公告顯示,具體淘汰的模型包含 Completions API 中的一些舊模型,包含我們熟悉的 davinci:
-
使用基于 GPT-3 模型(ada、babbage、curie、davinci)的穩(wěn)定模型名稱的應(yīng)用程序?qū)⒃?2024 年 1 月 4 日自動(dòng)升級(jí)到上述的新模型。在未來幾周內(nèi),通過在 API 調(diào)用中指定以下模型名稱,也可以訪問新模型進(jìn)行早期測試:ada-002、babbage-002、curie-002、davinci-002。
-
使用其他舊的完成模型(如 text-davinci-003)的開發(fā)者將需要在 2024 年1月4日之前手動(dòng)升級(jí)他們的集成,在他們的 API 請(qǐng)求的 "模型 "參數(shù)中指定 gpt-3.5-turbo-instruct。gpt-3.5-turbo-instruct 是一個(gè) InstructGPT 風(fēng)格的模型,訓(xùn)練方式與 text-davinci-003 類似。這個(gè)新的模型是 Completions API 中的一個(gè)替代品,并將在未來幾周內(nèi)提供給早期測試。

與此同時(shí),OpenAI 表示,希望在 2024 年 1 月 4 日之后繼續(xù)使用他們的微調(diào)模型的開發(fā)者,需要在新的基于 GPT-3 模型(ada-002、babbag-002、curie-002、davinci-002)或更新后的模型(gpt-3.5-turbo、gpt-4)之上進(jìn)行微調(diào)替換。
隨著 OpenAI 在今年晚些時(shí)候開啟微調(diào)功能,他們將優(yōu)先為以前微調(diào)過舊型號(hào)的用戶提供 GPT-3.5 Turbo 和 GPT-4 微調(diào)服務(wù)。具體原因是,OpenAI 深諳從自己的數(shù)據(jù)上進(jìn)行微調(diào)的模型上遷移是具有挑戰(zhàn)性的,對(duì)此他們會(huì)為「以前微調(diào)過的模型的用戶提供支持,使這種過渡盡可能順利」。
除了淘汰一些 Completions API 舊模型之外,OpenAI 表示,舊的嵌入模型(如 text-search-davinci-doc-001)的用戶也需要在 2024 年 1 月 4 日前遷移到 text-embedding-ada-002。

最后,使用 Edits API 及其相關(guān)模型(如t ext-davinci-edit-001 或 code-davinci-edit-001)的用戶同樣需要在 2024 年 1 月 4 日前遷移到 GPT-3.5 Turbo。Edits API 測試版是一個(gè)早期的探索性 API,旨在使開發(fā)人員能夠根據(jù)指令返回編輯過的提示版本。

OpenAI 在公告中寫道,“我們認(rèn)識(shí)到這對(duì)使用這些舊型號(hào)的開發(fā)者來說是一個(gè)重大變化。終止這些模型不是我們輕易做出的決定。我們將承擔(dān)用戶用這些新模式重新嵌入內(nèi)容的財(cái)務(wù)成本。”
OpenAI 表示將在未來幾周,與受影響的用戶聯(lián)系,一旦新的模型準(zhǔn)備好進(jìn)行早期測試,他們也將提供更多信息。
4. 預(yù)告:下周,所有 ChatGPT Plus 用戶可用上代碼解釋器
最為值得期待的是,OpenAI 官方還在 Twitter 上預(yù)告:代碼解釋器將在下周向所有 ChatGPT Plus 用戶開放。
它允許 ChatGPT 運(yùn)行代碼,并且可以選擇訪問用戶上傳的文件。開發(fā)者可以直接要求 ChatGPT 分析數(shù)據(jù)、創(chuàng)建圖表、編輯文件、執(zhí)行數(shù)學(xué)運(yùn)算等。
5. 調(diào)用 GPT-4 API 可以做的 10 件事
最后,隨著此次 GPT-4 API 的放開,開發(fā)者再也不用費(fèi)盡心思地購買 Plus 服務(wù)了,調(diào)用迄今業(yè)界最為強(qiáng)大的 GPT-4 API,無疑也讓相關(guān)的應(yīng)用更加智能。
那么,我們到底能用 GPT-4 API 來做什么,對(duì)此外媒總結(jié)了常見的 10 種用法:
-
基于 GPT-4 API 的敘事能力,可以快速生成復(fù)雜情節(jié)、人物發(fā)展等小說內(nèi)容,徹底改變文學(xué)創(chuàng)作領(lǐng)域。
-
GPT-4 API 為模擬極其真實(shí)的對(duì)話鋪平了道路,反映了人類交互的真實(shí)性和精確性。
-
GPT-4 API 展現(xiàn)了即時(shí)語言翻譯的能力,有效地彌合了各種語言和文化之間的溝通差距。
-
GPT-4 API 在數(shù)據(jù)分析方面有很強(qiáng)的能力,可以為數(shù)據(jù)分析市場參與者提供了寶貴的洞察力。
-
GPT-4 API 能夠打造與現(xiàn)實(shí)世界動(dòng)態(tài)相呼應(yīng)的高度逼真的虛擬環(huán)境,增強(qiáng)了游戲和虛擬現(xiàn)實(shí)等領(lǐng)域的沉浸感。
-
GPT-4 API 生成復(fù)雜計(jì)算機(jī)代碼的能力,使其成為軟件開發(fā)人員不可或缺的盟友。
-
GPT-4 API 可以解釋和分析醫(yī)療數(shù)據(jù),幫助準(zhǔn)確診斷和預(yù)測各種健康狀況。
-
利用其先進(jìn)的語言生成能力,GPT-4 API 可確保快速、準(zhǔn)確地生成法律文件。
-
GPT-4 API 展示了解釋消費(fèi)者數(shù)據(jù)和生成定制營銷內(nèi)容的能力,有效地與目標(biāo)受眾產(chǎn)生共鳴。
-
GPT-4 API 有可能通過分析大量的科學(xué)數(shù)據(jù)來推動(dòng)科學(xué)創(chuàng)新,在化學(xué)、物理學(xué)和生物學(xué)等不同領(lǐng)域發(fā)現(xiàn)新的見解。
參考:
https://openai.com/blog/gpt-4-api-general-availability
https://dataconomy.com/2023/07/06/gpt-4-api-is-now-generally-available/
———————End———————
RT-Thread線下入門培訓(xùn)
7月 - 上海,南京
1.免費(fèi)2.動(dòng)手實(shí)驗(yàn)+理論3.主辦方免費(fèi)提供開發(fā)板4.自行攜帶電腦,及插線板用于筆記本電腦充電5.參與者需要有C語言、單片機(jī)(ARM Cortex-M核)基礎(chǔ),請(qǐng)?zhí)崆鞍惭b好RT-Thread Studio 開發(fā)環(huán)境
報(bào)名通道

立即掃碼報(bào)名
(報(bào)名成功即可參加)
點(diǎn)擊閱讀原文進(jìn)入官網(wǎng)
原文標(biāo)題:【AI簡報(bào)20230707】中國團(tuán)隊(duì)推出「全球首顆」AI 全自動(dòng)設(shè)計(jì) CPU!重磅,GPT-4 API 全面開放使用!
文章出處:【微信公眾號(hào):RTThread物聯(lián)網(wǎng)操作系統(tǒng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
-
RT-Thread
+關(guān)注
關(guān)注
31文章
1272瀏覽量
39922
原文標(biāo)題:【AI簡報(bào)20230707】中國團(tuán)隊(duì)推出「全球首顆」AI 全自動(dòng)設(shè)計(jì) CPU!重磅,GPT-4 API 全面開放使用!
文章出處:【微信號(hào):RTThread,微信公眾號(hào):RTThread物聯(lián)網(wǎng)操作系統(tǒng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
Llama 3 與 GPT-4 比較
科大訊飛發(fā)布訊飛星火4.0 Turbo:七大能力超GPT-4 Turbo
OpenAI API Key獲取:開發(fā)人員申請(qǐng)GPT-4 API Key教程
國內(nèi)直聯(lián)使用ChatGPT 4.0 API Key使用和多模態(tài)GPT4o API調(diào)用開發(fā)教程!

阿里云發(fā)布通義千問2.5大模型,多項(xiàng)能力超越GPT-4
商湯科技發(fā)布5.0多模態(tài)大模型,綜合能力全面對(duì)標(biāo)GPT-4 Turbo
微軟Copilot全面更新為OpenAI的GPT-4 Turbo模型
新火種AI|秒殺GPT-4,狙殺GPT-5,橫空出世的Claude 3振奮人心!

全球最強(qiáng)大模型易主,GPT-4被超越
Anthropic推出Claude 3系列模型,全面超越GPT-4,樹立AI新標(biāo)桿
智譜AI發(fā)布新一代大模型GLM-4比肩GPT-4
智譜AI推出新一代基座大模型GLM-4
ChatGPT plus有什么功能?OpenAI 發(fā)布 GPT-4 Turbo 目前我們所知道的功能

AI觀察 | 今年最火的GPT-4,正在締造科幻版妙手仁心!

新火種AI|谷歌深夜發(fā)布復(fù)仇神器Gemini,原生多模態(tài)碾壓GPT-4?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論