 大模型時代的OCR,“CPU” 的味道更重了
大模型時代的OCR,“CPU” 的味道更重了
金磊 楊凈 發自 凹非寺
量子位 | 公眾號 QbitAI
經典技術OCR(光學字符識別),在大模型時代下要“變味”了。
怎么說?
我們都知道OCR這個技術在日常生活中已經普及開了,像各類文件、身份證、路標等識別,可以說統統都離不開它。
而隨著近幾年大模型的不斷發展,OCR也迎來了它的“新生機”——
憑借自身可以將文本從圖片、掃描文檔或其他圖像形式提取出來的看家本領,成為大語言模型的一個重要入口。
在這個過程中,一個關鍵問題便是“好用才是硬道理”。
過去人們會普遍認為,像OCR這種涉及圖像預處理、字符分割、特征提取等步驟的技術,堆GPU肯定是首選嘛。
不過朋友,有沒有想過成本和部署的問題?還有一些場景甚至連GPU資源都沒得可用的問題?
這時又有朋友要說了,那CPU也不見得很好用啊。
不不不。
現在,大模型時代之下,CPU或許還真是OCR落地的一種新解法。
例如在醫保AI業務中,在CPU的加持之下,醫療票據識別任務的響應延時指標,在原有基礎上提升達25倍!
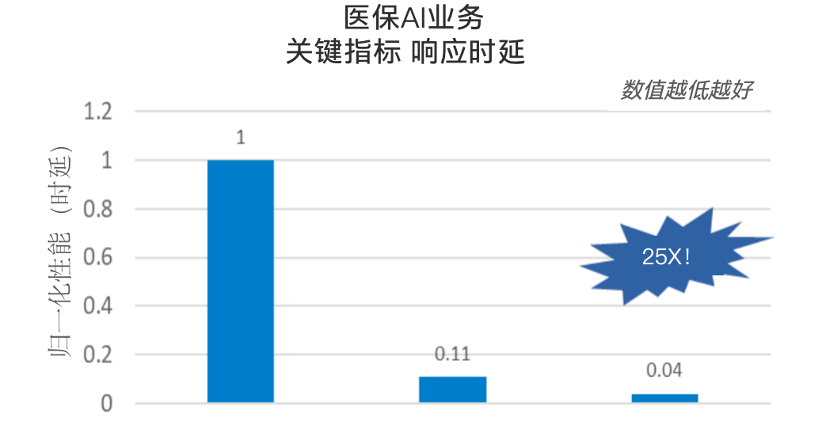
△數據來源:英特爾合作伙伴
為什么會有如此大的轉變?
一言蔽之,因為此前做OCR任務的時候,CPU的計算潛能并沒有完全釋放出來。
OCR,進入CPU時代
那么到底是誰家的CPU,能讓經典OCR產生這般變化。
不賣關子。
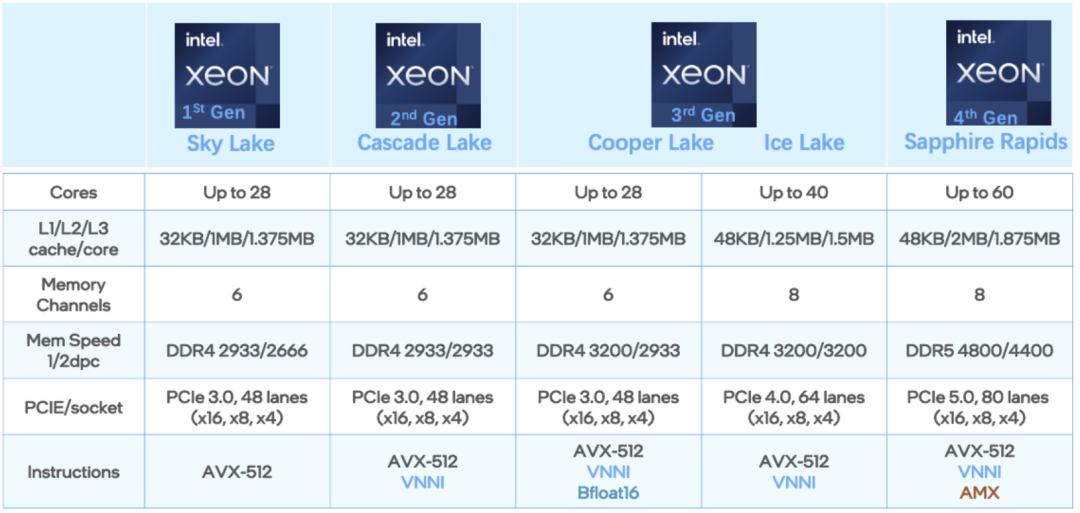
它正是來自英特爾的第四代至強可擴展處理器。
據了解,第四代至強可擴展處理器增加了每個時鐘周期的指令,每個插槽多達60個核心,支持8通道DDR5內存。
在內存寬帶方面實現了50%的性能提升,并通過每PCIe 5.0(80個通道)實現了2 倍的PCIe帶寬提升,整體可實現60%的代際性能提升。
但解鎖如此能力的,可不僅僅是一顆CPU這么簡單,是加成了英特爾軟件層面上的優化;換言之,就是“軟硬一體”后的結果。
而且這種打法也不是停留在PPT階段,而是已經實際用起來的那種。
例如國內廠商用友便在自家OCR業務中采用了這種方案。
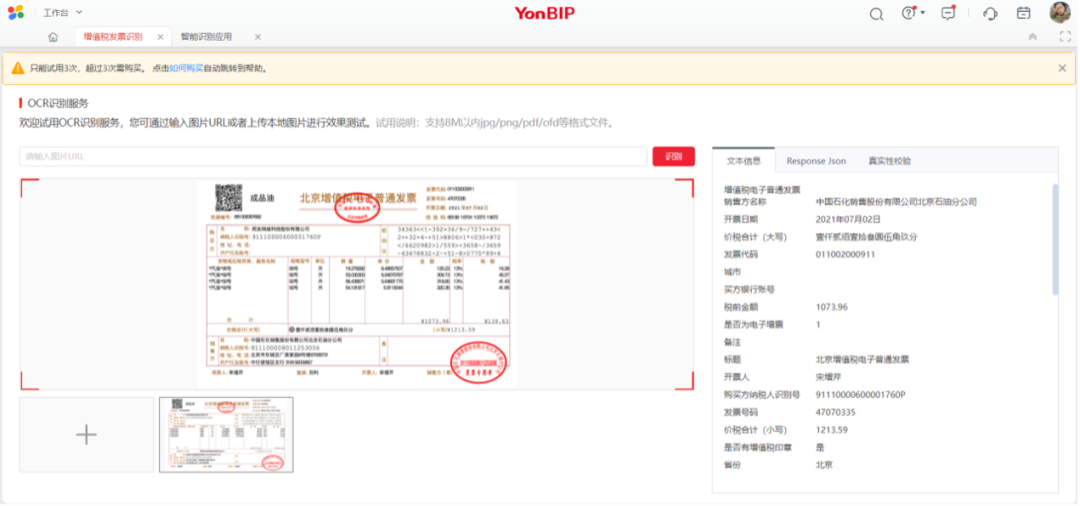
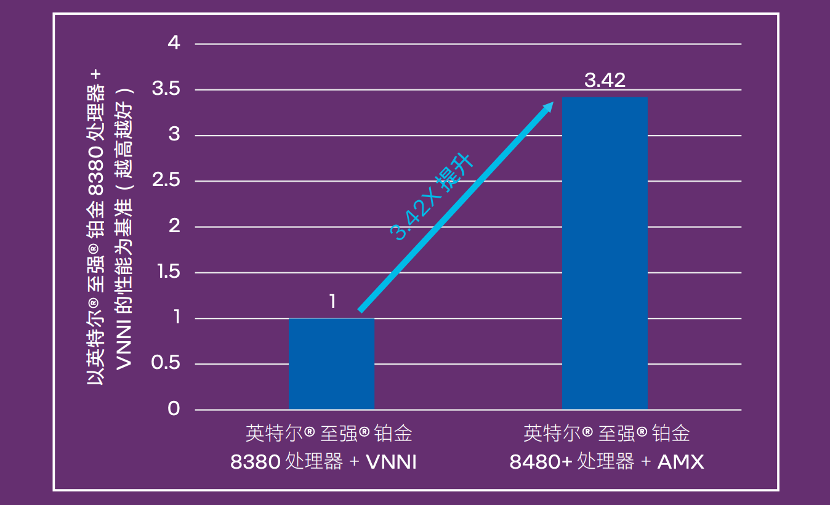
性能比較上,用友在第三/第四代英特爾至強可擴展處理器上進行了算法對比,推理性能提升達優化前的3.42倍:
而在INT8量化后的性能更是提升到原來的7.3倍:
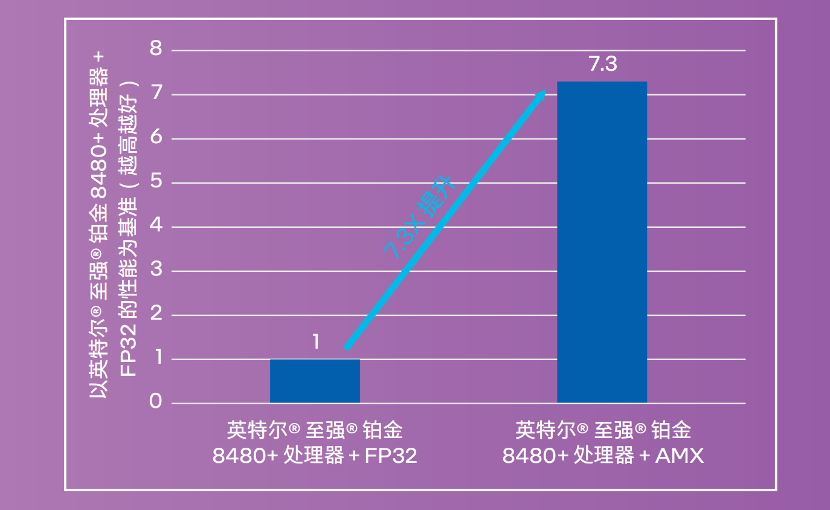
值得一提的是,OCR的響應時間直接降低到了3秒以內,還是切換架構不影響業務,用戶無感知的那種。
除了用友之外,像亞信科技在自家OCR-AIRPA方案中,也是采用了英特爾的這套打法。
與用友類似的,亞信科技實現了從FP32到INT8/BF16的量化,從而在可接受的精度損失下,增加吞吐量并加速推理。
從結果上來看,相比傳統人工方式,成本降到了1/5到1/9之間,而且效率還提升了5-10倍。
由此可見,釋放了AI加速“洪荒之力”的CPU,在OCR任務上完全不亞于傳統GPU的方案。
那么問題來了:
英特爾是如何釋放CPU計算潛力的?
實際應用過程中,企業通常選擇自己使用CPU來做OCR處理,但由于缺乏對CPU硬件加速和指令集的了解,就會發現CPU處理性能與理想峰值相差甚遠,OCR程序也就沒有得到很好的優化。
至于以往更常見的GPU解決方案,始終存在著成本和部署的難題。一來成本通常較高,且很多情況下,業務現場沒有GPU資源可以使用。
但要知道OCR本身應用廣泛、部署場景多樣,比如公有云、私有云,以及邊緣設備、終端設備上……而且隨著大模型時代的到來,作為重要入口的OCR,更多潛在場景將被挖掘。
于是,一種性價比高、硬件適配性強的解決方案成為行業剛需。
既然如此,英特爾又是如何解決這一痛點的呢?
簡單歸結:第四代至強可擴展處理器及其內置的AI加速器,以及OpenVINO 推理框架打輔助。
當前影響AI應用性能的要素無非兩個:算力和數據訪問速度。第四代至強可擴展處理器的單顆CPU核數已經增長到最高60核。
而在數據訪問速度上,各級緩存大小、內存通道數、內存訪問速度等都有一定程度的優化,另外部分型號還集成了HBM高帶寬內存技術。
此外,在CPU指令集上也做了優化,內置了英特爾高級矩陣擴展(英特爾AMX)等硬件加速器,負責矩陣計算,加速深度學習工作負載。
AMX由兩部分組成,一部分是1kb大小的2D寄存器文件,另一部分是TMUL模塊,用來執行矩陣乘法指令。
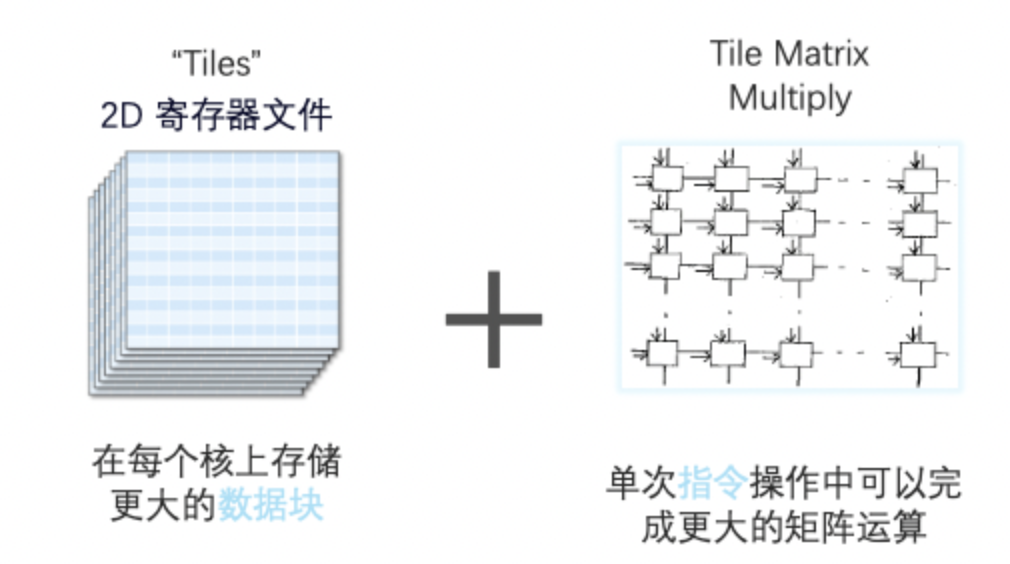
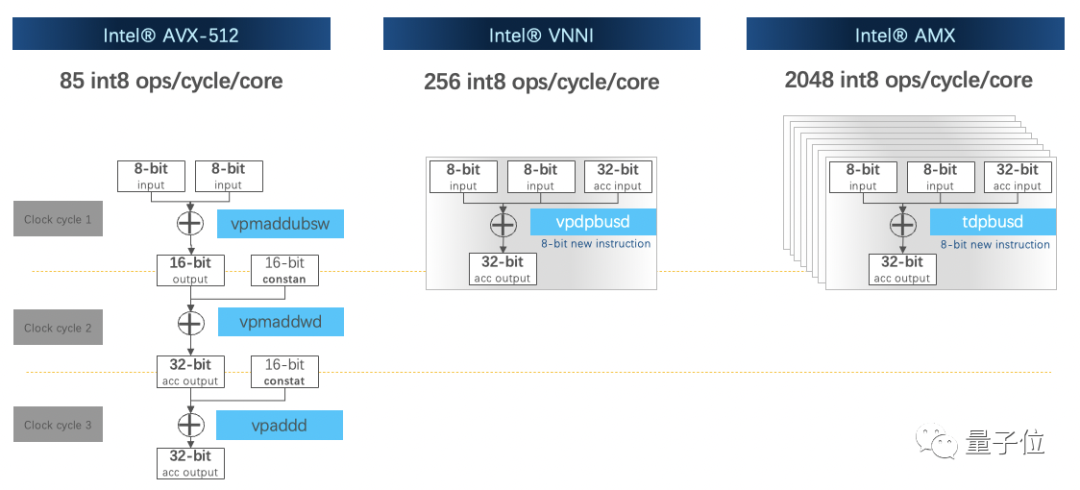
它可同時支持INT8和BF16數據類型,且BF16相較于FP32計算性能更優。
有了AMX指令集加持,性能比矢量神經網絡指令集VNNI提升達8倍。
除了核心硬件平臺外,實際情況中幫助OCR在CPU上落地的,還有推理框架OpenVINO。
市面上大部分AI框架都是同時支持訓練和推理,OpenVINO則是刪減了很多訓練部分所需的冗余計算,主要支持推理部分。
而且也是專門針對英特爾硬件打造的優化框架。框架替換也不復雜,只需5行代碼就可以完成原有框架的替換。
用戶可以針對不同業務場景,來優化OpenVINO運行參數。
比如用友OCR業務涉及文字檢測和文字識別兩個AI模型,優化方向有所不同。
前者對單次推理要求高,后者需要整個系統吞吐量的優化,那么OpenVINO分別采用單路同步模式和多路異步模式。單一模塊優化后,再針對整體流程的優化。
這樣一套軟硬件組合拳打下來,英特爾充分釋放了CPU計算潛力,在實際場景中也實現了與GPU同等性能。
不再是你以為的CPU
以往談到AI加速、AI算力,大眾經常想到的就是GPU,又或者是專用TPU。
至于通用架構芯片CPU,受到計算單元和內存帶寬的限制,始終無法適應于計算數據龐大的深度學習。
但現在的CPU,已經不再是“你以為的你以為”了:
它可以深入到各個行業當中,輕松Hold住各種場景應用。
尤其在AMX加速引擎加持下,能將深度學習訓練和推理性能提升高達10倍。
比如,媒體娛樂場景中,能幫助個性化內容推薦速度提升達6.3倍;零售行業里,能將視頻分析速度提升高達至2.3倍,還有像工業缺陷檢測、醫療服務也都能從容應對。
即便是在前沿探索領域,CPU也已經成為不容忽視的存在:
像是在生命科學和醫藥方向,在某些場景下的表現效果甚至比GPU還要好。
英特爾用CPU速刷AlphaFold2,結果力壓AI專用加速芯片,去年發布的第三代至強可擴展處理器經過優化后就能使其端到端的通量足足提升到了原來的23.11倍。今年基于第四代至強可擴展處理器再次把性能提升到了上一代產品的3.02倍。

不過要實現CPU加速,背后也并非簡單的硬件優化。
而是軟硬件融合協同,從底層到應用的一整套技術創新,以及產業鏈上合作伙伴的支撐。
隨著大模型時代的到來和深入,這種解決思路也正在成為共識。
像一些大模型玩家要實現大模型優化和迭代,并不能依靠以往單純三駕馬車來解決,而是需要從底層芯片到模型部署端到端的系統優化。
在算力加速層面的玩家,一方面擺脫不了摩爾定律的極限,另一方面要在應用場景中充分釋放計算潛力,就需要與軟件適配快速部署。
有意思的是,在最近OCR主題的《至強實戰課》中,英特爾人工智能軟件架構師桂晟曾這樣形容英特爾的定位:
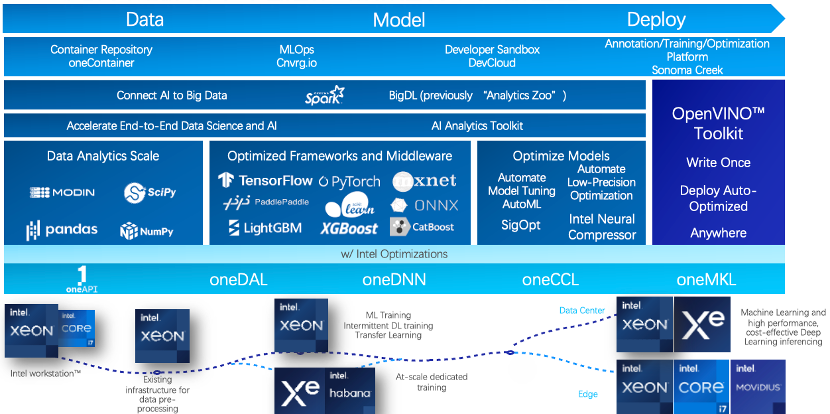
英特爾不僅僅是一個硬件公司,同時也擁有著龐大的軟件團隊。
在整個人工智能生態中,不論是從底層的計算庫,到中間的各類組件,框架和中間件,再到上層的應用,服務和解決方案都有英特爾軟件工程師的參與。
CPU加速,不再是你以為的加速。英特爾,也不再是以往所認知中的硬件公司。
但如果你以為英特爾只有CPU來加速AI,那你又單純了。
針對AI的專用加速芯片HabanaGaudi 2即將迎來首秀;而通用加速芯片,同時兼顧科學計算和AI加速的英特爾數據中心GPU Max系列也剛剛結束了它在阿貢實驗室Aurora系統中的部署,即將走近更多客戶。
以這些多樣化、異構的芯片為基石,英特爾也將形成更全面的硬件產品布局,并配之以跨異構平臺、易用的軟件工具組合(oneAPI)為整個應用鏈上的合作伙伴及客戶提供應用創新的支持,為各行各業AI應用的開發、部署、優化和普及提供全方位支持。
了解更多英特爾如何顯著提升OCR性能,可點擊文末【閱讀原文】。
更多《至強實戰課》相關內容,歡迎掃描如下海報中的二維碼注冊觀看:

—完—
-
英特爾
+關注
關注
60文章
9886瀏覽量
171524 -
cpu
+關注
關注
68文章
10825瀏覽量
211150
原文標題:大模型時代的OCR,“CPU” 的味道更重了
文章出處:【微信號:英特爾中國,微信公眾號:英特爾中國】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【「大模型時代的基礎架構」閱讀體驗】+ 第一、二章學習感受
【「大模型時代的基礎架構」閱讀體驗】+ 未知領域的感受
大模型時代的算力需求
名單公布!【書籍評測活動NO.41】大模型時代的基礎架構:大模型算力中心建設指南
明治案例 | PE編織袋【大視野】【OCR識別】


軟通動力榮獲百度智能云“大模型創新突破獎”“服務突破之星伙伴獎”
半導體發展的四個時代
半導體發展的四個時代
英特爾CPU部署Qwen 1.8B模型的過程
OCR終結了?曠視提出可以文檔級OCR的多模態大模型框架Vary,支持中英文,已開源!






 工商網監
工商網監
評論