") 大模型微調(diào)樣本構(gòu)造的trick
大模型微調(diào)樣本構(gòu)造的trick
開局一道面試題。
面試官:大模型微調(diào)如何組織訓(xùn)練樣本?
你:大模型訓(xùn)練一問一答,一指令一輸出,問題和指令可以作為prompt輸入,答案作為輸出,計算loss的部分要屏蔽掉pad token。
面試官:多輪對話如何組織訓(xùn)練樣本呢?
你:假設(shè)多輪為Q1A1/Q2A2/Q3A3,那么可以轉(zhuǎn)化成 Q1—>A1, Q1A1Q2->A2, Q1A1Q2A2Q3->A3三條訓(xùn)練樣本。
面試官:這樣的話一個session變成了三條數(shù)據(jù),并且上文有依次重復(fù)的情況,這樣會不會有啥問題?
你:數(shù)據(jù)中大部分都是pad token,訓(xùn)練數(shù)據(jù)利用效率低下。另外會有數(shù)據(jù)重復(fù)膨脹的問題,訓(xùn)練數(shù)據(jù)重復(fù)膨脹為 session數(shù)量*平均輪次數(shù),且上文有重復(fù)部分,訓(xùn)練效率也會低下。
面試官:你也意識到了,有什么改進(jìn)的方法嗎?
你:有沒有辦法能一次性構(gòu)造一個session作為訓(xùn)練樣本呢?(思索)
面試官:提示你下,限制在decoder-only系列的模型上,利用模型特性,改進(jìn)樣本組織形式。
對于這個問題,我們思考下decoder-only模型有啥特點(diǎn),第一點(diǎn)很關(guān)鍵的是其attention形式是casual的,casual簡單理解就是三角陣,單個token只能看到其上文的信息。
如圖所示:
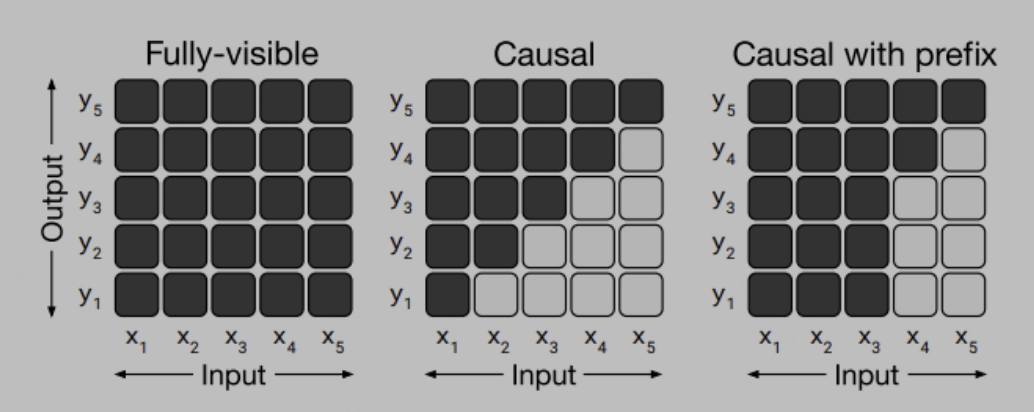
其二是postion_id是只有token次序含義而無需特定指代信息,(區(qū)別于GLM模型需要postion_id來標(biāo)識生成span的位置等特殊的要求)。
有了這兩點(diǎn)我們就可以設(shè)想,如果構(gòu)造多輪對話樣本的input為 Q1 A1
嗯為什么原來的chatglm不能用這種形式呢,雖然prefix attention可以推廣為適應(yīng)多輪訓(xùn)練的prefix attention形式,如圖:

但是由于其postition id 無法簡單按次序推廣,故不能高效訓(xùn)練,這也是chatglm初代的很大的一個問題,導(dǎo)致后續(xù)微調(diào)的效果都比較一般。
現(xiàn)在chatglm2的代碼針對這兩個問題已經(jīng)進(jìn)行了改善,可以認(rèn)為他就是典型的decoder-only模型了,具體表現(xiàn)為推斷時候attention 是casual attention的形式,position id也退化為token次序增長。
那么好了,萬事具備,只欠東風(fēng)。我們據(jù)此實現(xiàn)了chatglm2-6b的代碼微調(diào)。其核心代碼邏輯為處理樣本組織的邏輯,其他的就是大模型微調(diào),大同小異了。
conversation='' input_ids = [] labels = [] eos_id = tokenizer.eos_token_id turn_idx = 0 for sentence in examples[prompt_column][i]: sentence_from = sentence["from"].lower() sentence_value = '[Round {}] 問:'.format(turn_idx) + sentence["value"] + ' 答:' if sentence_from == 'human' else sentence["value"]+' ' conversation += sentence_value sentence_ids = tokenizer.encode(sentence_value, add_special_tokens=False) label = copy.deepcopy(sentence_ids) if sentence_from != 'human' else [-100] * len(sentence_ids) input_ids += sentence_ids labels += label if sentence_from != 'human': input_ids += [eos_id] labels += [eos_id] turn_idx += 1 input_ids=tokenizer.encode('')+input_ids#addgmaskbos labels = [-100] * 2 + labels# #add padding pad_len = max_seq_length - len(input_ids) input_ids = input_ids + [eos_id] * pad_len labels = labels + [-100] * pad_len
其中有幾個關(guān)鍵的地方,就是在開頭要加上 bos和gmask,遵循模型原來的邏輯。問答提示詞和輪次prompt,還有兩個 保持和原模型保持一致,最后屏蔽掉pad部分的loss計算。
實測訓(xùn)練效果如下:
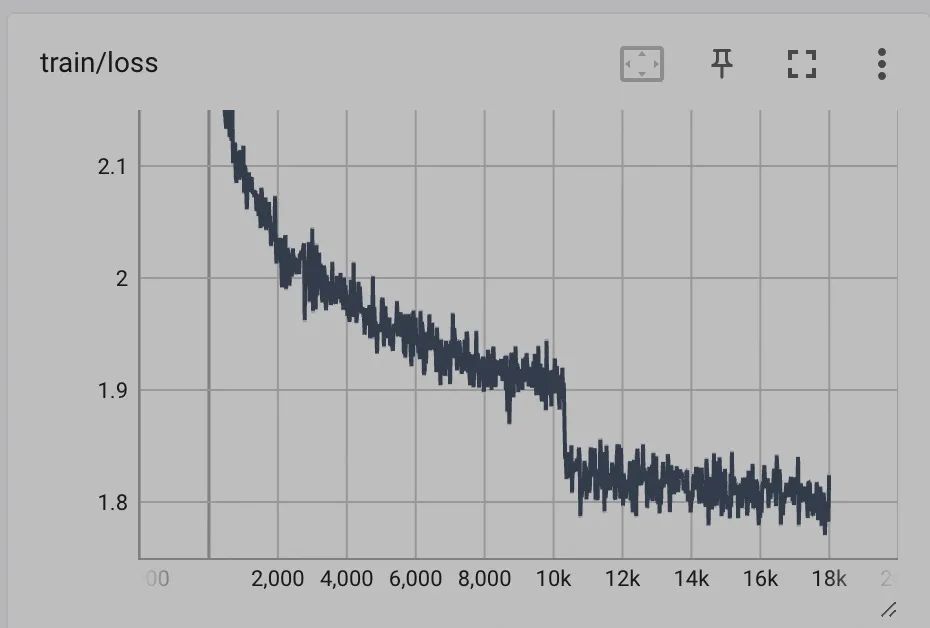
同樣的數(shù)據(jù)在chatglm1上 train loss只能降到2.x左右,同時評估測試集結(jié)果,在同樣的數(shù)據(jù)上rouge等指標(biāo)都有不小的提升。
我們再仔細(xì)回顧下,對話session級別訓(xùn)練和拆開訓(xùn)練從原理上有啥區(qū)別?
1.session級別訓(xùn)練,效果之一為等價batchsize變大(1個batch可以塞下更多樣本),且同一通對話產(chǎn)生的樣本在一個bs內(nèi)。
2. session級別的不同輪次產(chǎn)生的梯度是求平均的,拆開輪次構(gòu)造訓(xùn)練是求和的,這樣除了等價于lr會變大,還會影響不同輪次token權(quán)重的分配,另外還會影響norm的計算。
我們用一個簡化地例子定量分析下,我們假設(shè)兩條訓(xùn)練樣本分為 1.問:A 答:xx 2.問: A答:xx 問: B答:xx問: C答:xx 則session級別訓(xùn)練影響梯度為 (Ga+(Ga +Gb + Gc)/3)/2。對 A,B,C影響的權(quán)重分別為,2/3 1/6 1/6。 拆開訓(xùn)練為(Ga+Ga+ (Ga+Gb)/2+(Ga+Gb+ Gc)/3)/4。對 A,B,C影響的權(quán)重分別為,17/24 5/24 1/12。 從上面的權(quán)重分布來看,session級別靠后的輪次影響權(quán)重要比拆開更大。這也是更合理的,因為大部分場景下,開場白都是趨同和重復(fù)的。 一點(diǎn)小福利,以上面試題對應(yīng)的ChatGLM2-6B微調(diào)完整的代碼地址為: https://github.com/SpongebBob/Finetune-ChatGLM2-6B
實現(xiàn)了對于 ChatGLM2-6B 模型的全參數(shù)微調(diào),主要改進(jìn)點(diǎn)在多輪對話的交互組織方面,使用了更高效的session級別高效訓(xùn)練,訓(xùn)練效果相比原版ChatGLM-6B有較大提升。
這可能是目前全網(wǎng)效果最好的ChatGLM2-6B全參數(shù)微調(diào)代碼。
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
6892瀏覽量
88827 -
代碼
+關(guān)注
關(guān)注
30文章
4748瀏覽量
68355 -
大模型
+關(guān)注
關(guān)注
2文章
2328瀏覽量
2483
原文標(biāo)題:大模型微調(diào)樣本構(gòu)造的trick
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
一種信息引導(dǎo)的量化后LLM微調(diào)新算法IR-QLoRA

大語言模型如何開發(fā)
示波器探頭補(bǔ)償微調(diào)旋鈕的作用
大模型為什么要微調(diào)?大模型微調(diào)的原理
【大語言模型:原理與工程實踐】大語言模型的應(yīng)用
【大語言模型:原理與工程實踐】核心技術(shù)綜述
基于雙級優(yōu)化(BLO)的消除過擬合的微調(diào)方法

大模型微調(diào)開源項目全流程
大模型Reward Model的trick應(yīng)用技巧

2023年LLM大模型研究進(jìn)展
教您如何精調(diào)出自己的領(lǐng)域大模型

商湯科技與庫醇科技達(dá)成合作 為垂域大模型構(gòu)建高質(zhì)量大規(guī)模的領(lǐng)域微調(diào)數(shù)據(jù)

四種微調(diào)大模型的方法介紹
大模型微調(diào)數(shù)據(jù)選擇和構(gòu)造技巧

一種新穎的大型語言模型知識更新微調(diào)范式






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論